Для приложений Second Screen cуществует два основных способа синхронизации контента по аудиосигналу (Automatic Content Recognition, ACR): на базе аудио fingerprints и с использованием цифровых водяных знаков (ЦВЗ, digital watermark). Эти технологии имеют принципиально разные подходы.
Fingerprints — это компактное и устойчивое к искажениям представление самого контента. Процесс распознавания заключается в создании fingerprint аудиосигнала и поиске по базе эталонных образцов, с последующим извлечением требуемых данных, например, названия трека и смещения запроса относительно его начала. В случае с аудио ЦВЗ необходимая и достаточная для распознавания информация скрывается непосредственно внутри самого аудиосигнала.
Я уже писал о достигнутых нами результатах по распознаванию аудио на основе fingerprints. В этом посте хочу рассказать об аудио ЦВЗ и проблемах, с которыми мы столкнулись при построении ACR на их основе.
Прежде чем перейти к ЦВЗ, отметим ряд проблем, возникающих при использовании ACR на базе fingerprints.
Second Screen приложение производит постоянную запись аудиопотока и отправку запросов с fingerprints на сервер. Хранение базы данных и поиск по ней, как правило, реализуется на серверной стороне. Если учесть, что во Втором Экране обычно заинтересованы проекты с высокой популярностью, то мы приходим к необходимости наличия достаточного количества ресурсов для выдерживания высоких нагрузок.
Успешное распознавание на основе fingerprints возможно только при уникальности аудио фрагмента. Однако в реальном контенте могут быть аудиодубликаты, например, одинаковое музыкальное сопровождение титров или одинаковая фоновая музыка на заднем плане. В условиях шумовых искажений распознавание таких участков сопровождается высокой вероятностью ошибок второго рода (ложно-положительные срабатывания). Поэтому для правильной работы приложения Second Screen данные участки необходимо уметь заранее идентифицировать и вносить дополнительные корректировки в систему ACR.
В качестве возможного решения данных проблем довольно привлекательно выглядит переход на технологии digital watermarking. Поскольку все необходимые данные уже заранее “встроены” в аудиопоток, то распознавание можно полностью осуществлять на стороне клиента, а уникальность ЦВЗ позволила бы избавиться от проблем дубликатов и похожих аудио фрагментов.
В зависимости от того, требуется ли детектору ЦВЗ исходный сигнал или нет, алгоритмы делятся на non-blind watermarking и blind watermarking. В контексте ACR нас интересовали blind алгоритмы, т.е. допускающие извлечение знака без наличия исходного аудиосигнала. Обзор таких методов можно посмотреть в работе [1].
Внедряемый аудио watermark должен быть прозрачным (Inaudibility) — не должен вносить какие-либо искажения, заметно влияющие на качество исходного сигнала. Простой количественной характеристикой прозрачности является параметр SNR (Signal-to-Noise Ratio), определяющий отношение мощности исходного сигнала к мощности искажений вызванных ЦВЗ. В соответствии с рекомендациями IFPI (International Federation of the Phonographic Industry) SNR должен быть более 20 дБ. Наряду с SNR для оценки прозрачности используется параметр ODG (Objective Difference Grade), вычисляемый в соответствии с алгоритмом PEAQ и изменяющийся от 0, при абсолютной незаметности, до -4 — при искажениях вызывающих сильное раздражение. В отличие от SNR, параметр ODG учитывает особенности слуховой системы человека, например, такие эффекты как частотное и временное маскирование.
Для успешного распознавания watermark должен быть устойчив (robustness) к методам обработки сигналов, именуемых атаками. Он не должен стираться при сжатии с потерями, фильтрации, цифро-аналоговом/аналого-цифровом преобразовании, добавление шума и т.д. Устойчивость к атакам оценивают количеством ошибочно декодированных бит в единицу времени BER (Bit Error Rate).
Немаловажной характеристикой алгоритмов digital watermarking является пропускная способность, т.е. максимальное количество информации, которое может быть вложено в единицу времени (data rate).
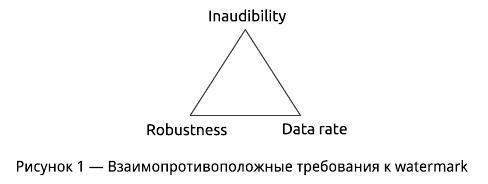
Требования к прозрачности, устойчивости и пропускной способности являются взаимно противоположными — увеличение одного непременно приводит к уменьшению двух оставшихся (рисунок 1).
Забегая вперед, отмечу, что особенностью систем автоматического распознавания контента является их относительно высокие, при прочих равных условиях, требования к устойчивости ЦВЗ. При этом алгоритм должен быть достаточно быстр, чтобы использовать его на мобильных устройствах в приложениях реального времени.
Аудио ЦВЗ можно рассматривать как модулированный шум, добавленный к исходному сигналу. Алгоритмы watermarking сводятся к определению спектральных характеристик внедряемой информации, чтобы данный watermark соответствовал предъявляемым к нему требованиям.
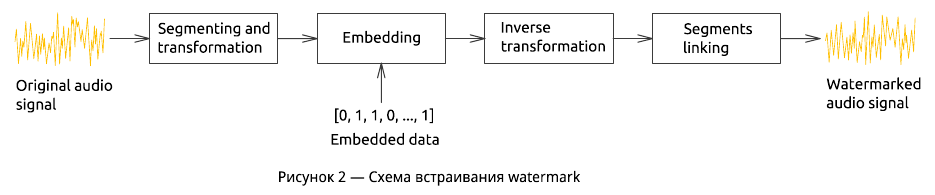
Многие схемы встраивания и извлечения аудио ЦВЗ имеют блочно-ориентированный подход и учитывают особенности исходного сигнала (рисунок 2). Watermark, если это необходимо, предварительно конвертируются в одномерную последовательность бит. Структура встраиваемого потока показана на рисунке 3. Для увеличения устойчивости в ЦВЗ может быть введена избыточность — простая репликация бит или добавление кодов коррекции (error correcting codes, ECC), например, кодов Рида-Соломона, LDPC-код (Low-density parity-check code) и др. Каждый бит потока встраивается в отдельный временной блок или сегмент аудиосигнала.

Каждый блок сигнала описывается вектором коэффициентов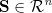 . В простейшем случае этими коэффициентами могут быть непосредственно сами семплы сигнала. В таком случае говорят о маркировании во временной области. Но, как правило, для увеличения устойчивости ЦВЗ к атакам используют частотное представление сигнала с помощью коэффициентов преобразований Фурье (DFT) [2], косинусного преобразования (DCT) [3] и вейвлет-преобразования (DWT) [4]. Существуют работы в которых применяется описание сегментов сигнала на основе эмпирической модовой декомпозиций (EMD) [5], кепстр-преобразования [6], комбинации частотных преобразований [7] и ряд других. Например, в работе [8] в качестве вектора коэффициентов выступают сингулярных числа, полученные в результате сингулярного разложения (SVD) матрицы DWT коэффициентов сегмента сигнала.
. В простейшем случае этими коэффициентами могут быть непосредственно сами семплы сигнала. В таком случае говорят о маркировании во временной области. Но, как правило, для увеличения устойчивости ЦВЗ к атакам используют частотное представление сигнала с помощью коэффициентов преобразований Фурье (DFT) [2], косинусного преобразования (DCT) [3] и вейвлет-преобразования (DWT) [4]. Существуют работы в которых применяется описание сегментов сигнала на основе эмпирической модовой декомпозиций (EMD) [5], кепстр-преобразования [6], комбинации частотных преобразований [7] и ряд других. Например, в работе [8] в качестве вектора коэффициентов выступают сингулярных числа, полученные в результате сингулярного разложения (SVD) матрицы DWT коэффициентов сегмента сигнала.
Процесс встраивания ЦВЗ или маркирование заключается в изменении вектора в соответствии с выбранной техникой кодирования бит. В аудиостеганографии широко распространены такие техники как Spread-Spectrum (SS), Quantization Index Modulation (QIM) и Patchwork.
в соответствии с выбранной техникой кодирования бит. В аудиостеганографии широко распространены такие техники как Spread-Spectrum (SS), Quantization Index Modulation (QIM) и Patchwork.
Кодирование бита методом SS описывается уравнением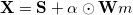 , где
, где  — маска восприятия (в ряде алгоритмов может отсутствовать), определяется как функция и слуховой системы человека (human auditory system, HAS)
— маска восприятия (в ряде алгоритмов может отсутствовать), определяется как функция и слуховой системы человека (human auditory system, HAS)  ;
;  — псевдослучайная последовательность;
— псевдослучайная последовательность; 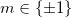 — значение встраиваемого бита;
— значение встраиваемого бита;  — поэлементное произведение двух векторов.
— поэлементное произведение двух векторов.
В QIM методе коэффициенты маркированного блока определяются функцией модуляции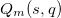 , отображающей исходное значение коэффициента
, отображающей исходное значение коэффициента  на ближайшее значение из множеств
на ближайшее значение из множеств 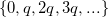 при
при 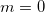 и из
и из 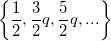 при
при 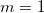 , где
, где 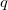 — шаг квантования [9].
— шаг квантования [9].
Широко распространены две разновидности QIM метода: distortion-compensation (DC) и dither modulation (DM). Функция встраивания бита в случае DC описывается уравнением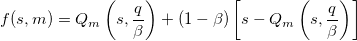 , где
, где 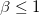 . При DM используется один квантователь, а функция встраивания определяется как
. При DM используется один квантователь, а функция встраивания определяется как 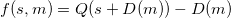 , где
, где 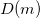 — шум, предназначенный для маскирования искажений, возникающих при квантовании, один из алгоритмов его синтеза можно посмотреть в работе [9].
— шум, предназначенный для маскирования искажений, возникающих при квантовании, один из алгоритмов его синтеза можно посмотреть в работе [9].
Метод Patchwork заключается в разбиении множества коэффициентов блока на два непересекающихся подмножества 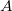 и
и 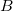 . Полагается, что разность элементов этих подмножеств имеет распределение с близким к нулю средним значением, т.е.
. Полагается, что разность элементов этих подмножеств имеет распределение с близким к нулю средним значением, т.е. 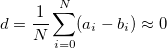 . Встраивание бит сводится к такому изменению коэффициентов, чтобы при
. Встраивание бит сводится к такому изменению коэффициентов, чтобы при 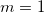 :
: 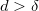 , а при
, а при  :
: 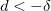 , где
, где 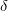 — величина порога детектирования.
— величина порога детектирования.
Для вставки и обнаружения watermark также можно использовать относительно простые стратегии, показанные на рисунке 4. Биты кодируются на основе функциональной связи между коэффициентами. Иллюстрации приведены для трех или четырех признаков, но техники легко обобщаются и на большее количество. Примеры алгоритмов, использующих такие подходы, можно посмотреть в работах [2, 10].
После встраивания бита вычисляются обратные преобразования, отображающие измененные коэффициенты соответствующего пространства маркирования во временную последовательность сигнала. Завершающим этапом встраивания ЦВЗ является склейка всех промаркированных блоков в единый сигнал, содержащий watermark.
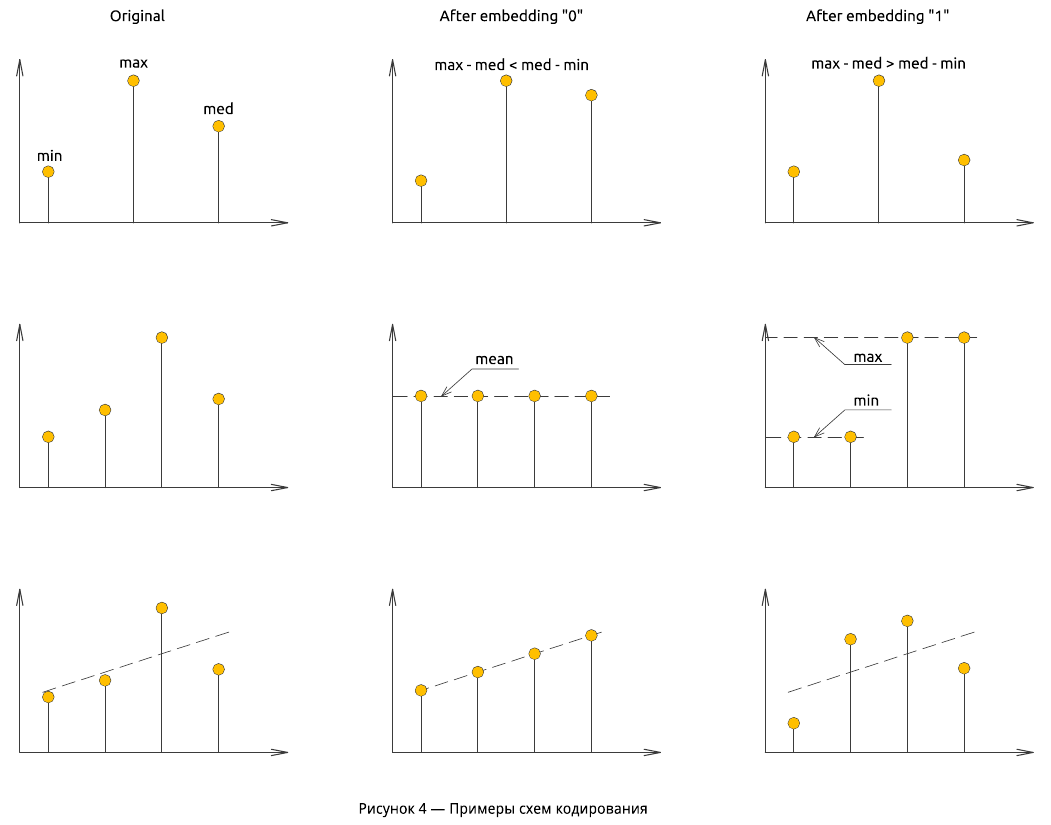
Обобщенная схема извлечения ЦВЗ представлена на рисунке 5. Одним из важных вопросов в блочно-ориентированном подходе является вопрос синхронизации. Необходимо определить точное положение каждого блока в процессе декодирования ЦВЗ. Для этого производится восстановление потока бит при различных начальных смещениях и ищется синхрокод. В качестве критерия обнаружения, как правило, используется пороговое значение коэффициента корреляции или расстояние Хемминга. Как только синхрокод найден, приступают к восстановлению watermark — устраняют введенную на этапе маркирования избыточность.
В англоязычном сегменте Интернета достаточно разного рода публикаций по аудио ЦВЗ. Попробовав некоторые из техник, мы не добились устраивающих нас результатов. При прозрачности ODG около -1 реализации алгоритмов [10 — 12] не смогли распознать watermark на мобильном устройстве даже на расстояниях около 5 см от источника звука. Также мы отметили сильную зависимость прозрачности исследуемых ЦВЗ от характера исходного сигнала. Например, watermark, не различимый на слух в рок-музыке, был слышим в речи. Бороться с этим удавалось только путем уменьшения агрессивности встраивания (увеличением SNR), что снижало и без того низкую устойчивость ЦВЗ.
Мы решили реализовать свой алгоритм, который бы позволял динамически подстраивается к спектральным характеристикам звука.
Встраивание ЦВЗ происходит в частотной области с использованием оконного преобразования Фурье (Short-time Fourier transform, STFT). В основу метода положен эффект временного маскирования — слабый сигнал, возникающий раньше или позже сильного, в течение некоторого времени остается незамеченным. Время маскировки зависит от частоты и амплитуды сигнала и может достигать сотен миллисекунд.
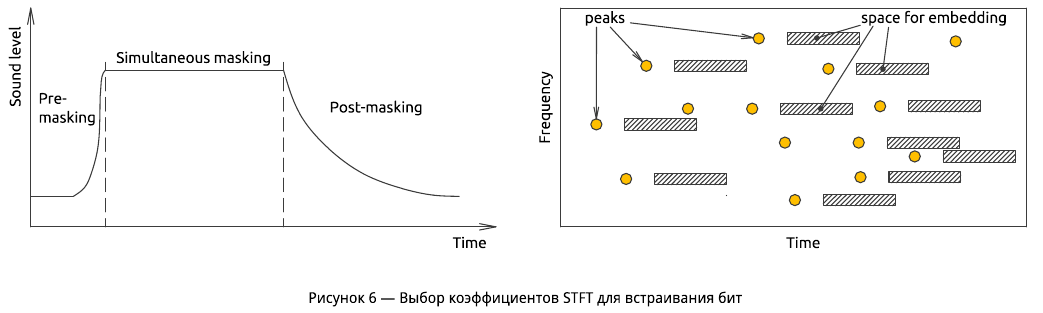
Мы прячем watermark в «тени» локальных пиков спектрограммы — в каждый конкретный интервал времени выбираем те коэффициенты STFT, которые можно относительно безвредно изменять для кодирования бит (рисунок 6).
Метод позволяет добиться пропускной способности в 50 bits/s, что является вполне достаточным для ACR. Правда, при таком решении некоторые блоки сигнала остаются не маркированными, но, как показали наши исследования, их доля составляет около 0.01%. В качестве примера в таблице 1 показаны результаты сравнительных тестов. Атаки проводились с помощью утилиты SMFA (StirMark for Audio) версии 1.3.2. Параметры сравниваемых алгоритмов подбирались так, чтобы обеспечить одинаковое, насколько это возможно, значение прозрачности; ODG лежал в диапазоне от -0.5 до -0.1.
Таблица 1 — Сравнение алгоритмов digital watermarking по параметру Bit Error Rate
Наш метод выдерживает с BER < 1 % низкочастотную фильтрацию до 4.5 кГц, высокочастотную фильтрацию до 1.9 кГц, изменение уровня звукового сигнала (от 1 % до 150 %), уменьшение частоты дискретизации до 8 кГц.
Основным тестом, в контексте решаемой задачи, конечно являлась проверка устойчивости watermark при акустическом распространении сигнала. Треки с ЦВЗ были воспроизведены на телевизоре и записаны на разные мобильные устройства (LG-P705, Samsung GT-P7510, HTC Desire 601 и др). Моносигналы записывались с частотой дискретизации 44,1 кГц на разных удалениях от источника звука.
В отличие от алгоритмов [10 — 12], наши ЦВЗ распознаются на мобильных устройствах, но их устойчивость все равно недостаточна, чтобы говорить о равноценной замене fingerprints. Например, LG-P705 на расстоянии 40 см успешно распознавал около 85 % запросов, в то время как Samsung GT-P7510 распознавал 80 % только на расстоянии до 5 см. В сигналах, записанных на расстояниях более 50 см, watermark уже не обнаруживается.
Только с ЦВЗ вне акустической области частот нам удалось добиться синхронизации на удалениях более 1 м. Для LG-P705 и HTC Desire 601 на расстояниях 1.5 метров доля правильно обнаруженных watermark составляла 80%. Для кодирования бит применялась простая амплитудная модуляция гармоник с частотами более 20 кГц (рисунок 7).

Однако не все мобильные устройства одинаково хорошо справляются с записью высоких частот. Тот же Samsung GT-P7510 ни разу не распознал данный вид watermark. Но главным недостатком таких ЦВЗ является их неспособность пережить сжатие с потерями, что сильно ограничивает возможности применения.
Конечно, многое осталось за рамками наших экспериментов, но полученный опыт заставил нас серьезно усомниться в возможностях практического применения ACR на основе ЦВЗ. По крайне мере, если говорить о watermark в области акустических частот.
Большинство найденных нами работ по audio watermarking в своих исследованиях ограничиваются синтетическими атаками SMFA и оценкой устойчивости к сжатию. Публикаций, исследующих устойчивость ЦВЗ при акустическом распространении сигнала и записи его на микрофон, — считанные единицы, и те довольно поверхностно затрагивают этот вопрос, без достаточной конкретики.
Наше решение относительно простое и довольно успешно справляется с типовыми тестами, а также выдерживает сжатие с потерями. Однако, нам не удалось одновременно гарантировать прозрачность и достаточную для приложений Second Screen устойчивость ЦВЗ, сопоставимую с технологиями fingerprints.
Fingerprints — это компактное и устойчивое к искажениям представление самого контента. Процесс распознавания заключается в создании fingerprint аудиосигнала и поиске по базе эталонных образцов, с последующим извлечением требуемых данных, например, названия трека и смещения запроса относительно его начала. В случае с аудио ЦВЗ необходимая и достаточная для распознавания информация скрывается непосредственно внутри самого аудиосигнала.
Я уже писал о достигнутых нами результатах по распознаванию аудио на основе fingerprints. В этом посте хочу рассказать об аудио ЦВЗ и проблемах, с которыми мы столкнулись при построении ACR на их основе.
Недостатки fingerprints
Прежде чем перейти к ЦВЗ, отметим ряд проблем, возникающих при использовании ACR на базе fingerprints.
Second Screen приложение производит постоянную запись аудиопотока и отправку запросов с fingerprints на сервер. Хранение базы данных и поиск по ней, как правило, реализуется на серверной стороне. Если учесть, что во Втором Экране обычно заинтересованы проекты с высокой популярностью, то мы приходим к необходимости наличия достаточного количества ресурсов для выдерживания высоких нагрузок.
Успешное распознавание на основе fingerprints возможно только при уникальности аудио фрагмента. Однако в реальном контенте могут быть аудиодубликаты, например, одинаковое музыкальное сопровождение титров или одинаковая фоновая музыка на заднем плане. В условиях шумовых искажений распознавание таких участков сопровождается высокой вероятностью ошибок второго рода (ложно-положительные срабатывания). Поэтому для правильной работы приложения Second Screen данные участки необходимо уметь заранее идентифицировать и вносить дополнительные корректировки в систему ACR.
В качестве возможного решения данных проблем довольно привлекательно выглядит переход на технологии digital watermarking. Поскольку все необходимые данные уже заранее “встроены” в аудиопоток, то распознавание можно полностью осуществлять на стороне клиента, а уникальность ЦВЗ позволила бы избавиться от проблем дубликатов и похожих аудио фрагментов.
Требования к алгоритмам digital watermarking
В зависимости от того, требуется ли детектору ЦВЗ исходный сигнал или нет, алгоритмы делятся на non-blind watermarking и blind watermarking. В контексте ACR нас интересовали blind алгоритмы, т.е. допускающие извлечение знака без наличия исходного аудиосигнала. Обзор таких методов можно посмотреть в работе [1].
Внедряемый аудио watermark должен быть прозрачным (Inaudibility) — не должен вносить какие-либо искажения, заметно влияющие на качество исходного сигнала. Простой количественной характеристикой прозрачности является параметр SNR (Signal-to-Noise Ratio), определяющий отношение мощности исходного сигнала к мощности искажений вызванных ЦВЗ. В соответствии с рекомендациями IFPI (International Federation of the Phonographic Industry) SNR должен быть более 20 дБ. Наряду с SNR для оценки прозрачности используется параметр ODG (Objective Difference Grade), вычисляемый в соответствии с алгоритмом PEAQ и изменяющийся от 0, при абсолютной незаметности, до -4 — при искажениях вызывающих сильное раздражение. В отличие от SNR, параметр ODG учитывает особенности слуховой системы человека, например, такие эффекты как частотное и временное маскирование.
Для успешного распознавания watermark должен быть устойчив (robustness) к методам обработки сигналов, именуемых атаками. Он не должен стираться при сжатии с потерями, фильтрации, цифро-аналоговом/аналого-цифровом преобразовании, добавление шума и т.д. Устойчивость к атакам оценивают количеством ошибочно декодированных бит в единицу времени BER (Bit Error Rate).
Немаловажной характеристикой алгоритмов digital watermarking является пропускная способность, т.е. максимальное количество информации, которое может быть вложено в единицу времени (data rate).
Требования к прозрачности, устойчивости и пропускной способности являются взаимно противоположными — увеличение одного непременно приводит к уменьшению двух оставшихся (рисунок 1).

Забегая вперед, отмечу, что особенностью систем автоматического распознавания контента является их относительно высокие, при прочих равных условиях, требования к устойчивости ЦВЗ. При этом алгоритм должен быть достаточно быстр, чтобы использовать его на мобильных устройствах в приложениях реального времени.
Техники Audio Watermarking
Аудио ЦВЗ можно рассматривать как модулированный шум, добавленный к исходному сигналу. Алгоритмы watermarking сводятся к определению спектральных характеристик внедряемой информации, чтобы данный watermark соответствовал предъявляемым к нему требованиям.
Многие схемы встраивания и извлечения аудио ЦВЗ имеют блочно-ориентированный подход и учитывают особенности исходного сигнала (рисунок 2). Watermark, если это необходимо, предварительно конвертируются в одномерную последовательность бит. Структура встраиваемого потока показана на рисунке 3. Для увеличения устойчивости в ЦВЗ может быть введена избыточность — простая репликация бит или добавление кодов коррекции (error correcting codes, ECC), например, кодов Рида-Соломона, LDPC-код (Low-density parity-check code) и др. Каждый бит потока встраивается в отдельный временной блок или сегмент аудиосигнала.


Каждый блок сигнала описывается вектором коэффициентов
 . В простейшем случае этими коэффициентами могут быть непосредственно сами семплы сигнала. В таком случае говорят о маркировании во временной области. Но, как правило, для увеличения устойчивости ЦВЗ к атакам используют частотное представление сигнала с помощью коэффициентов преобразований Фурье (DFT) [2], косинусного преобразования (DCT) [3] и вейвлет-преобразования (DWT) [4]. Существуют работы в которых применяется описание сегментов сигнала на основе эмпирической модовой декомпозиций (EMD) [5], кепстр-преобразования [6], комбинации частотных преобразований [7] и ряд других. Например, в работе [8] в качестве вектора коэффициентов выступают сингулярных числа, полученные в результате сингулярного разложения (SVD) матрицы DWT коэффициентов сегмента сигнала.
. В простейшем случае этими коэффициентами могут быть непосредственно сами семплы сигнала. В таком случае говорят о маркировании во временной области. Но, как правило, для увеличения устойчивости ЦВЗ к атакам используют частотное представление сигнала с помощью коэффициентов преобразований Фурье (DFT) [2], косинусного преобразования (DCT) [3] и вейвлет-преобразования (DWT) [4]. Существуют работы в которых применяется описание сегментов сигнала на основе эмпирической модовой декомпозиций (EMD) [5], кепстр-преобразования [6], комбинации частотных преобразований [7] и ряд других. Например, в работе [8] в качестве вектора коэффициентов выступают сингулярных числа, полученные в результате сингулярного разложения (SVD) матрицы DWT коэффициентов сегмента сигнала.Процесс встраивания ЦВЗ или маркирование заключается в изменении вектора
 в соответствии с выбранной техникой кодирования бит. В аудиостеганографии широко распространены такие техники как Spread-Spectrum (SS), Quantization Index Modulation (QIM) и Patchwork.
в соответствии с выбранной техникой кодирования бит. В аудиостеганографии широко распространены такие техники как Spread-Spectrum (SS), Quantization Index Modulation (QIM) и Patchwork.Кодирование бита методом SS описывается уравнением
 , где
, где  — маска восприятия (в ряде алгоритмов может отсутствовать), определяется как функция и слуховой системы человека (human auditory system, HAS)
— маска восприятия (в ряде алгоритмов может отсутствовать), определяется как функция и слуховой системы человека (human auditory system, HAS)  ;
;  — псевдослучайная последовательность;
— псевдослучайная последовательность;  — значение встраиваемого бита;
— значение встраиваемого бита;  — поэлементное произведение двух векторов.
— поэлементное произведение двух векторов.В QIM методе коэффициенты маркированного блока определяются функцией модуляции
 , отображающей исходное значение коэффициента
, отображающей исходное значение коэффициента  на ближайшее значение из множеств
на ближайшее значение из множеств  при
при  и из
и из  при
при  , где
, где  — шаг квантования [9].
— шаг квантования [9].Широко распространены две разновидности QIM метода: distortion-compensation (DC) и dither modulation (DM). Функция встраивания бита в случае DC описывается уравнением
 , где
, где  . При DM используется один квантователь, а функция встраивания определяется как
. При DM используется один квантователь, а функция встраивания определяется как  , где
, где  — шум, предназначенный для маскирования искажений, возникающих при квантовании, один из алгоритмов его синтеза можно посмотреть в работе [9].
— шум, предназначенный для маскирования искажений, возникающих при квантовании, один из алгоритмов его синтеза можно посмотреть в работе [9].Метод Patchwork заключается в разбиении множества коэффициентов блока
на два непересекающихся подмножества  и
и  . Полагается, что разность элементов этих подмножеств имеет распределение с близким к нулю средним значением, т.е.
. Полагается, что разность элементов этих подмножеств имеет распределение с близким к нулю средним значением, т.е.  . Встраивание бит сводится к такому изменению коэффициентов, чтобы при
. Встраивание бит сводится к такому изменению коэффициентов, чтобы при  :
:  , а при
, а при  :
:  , где
, где  — величина порога детектирования.
— величина порога детектирования.Для вставки и обнаружения watermark также можно использовать относительно простые стратегии, показанные на рисунке 4. Биты кодируются на основе функциональной связи между коэффициентами
. Иллюстрации приведены для трех или четырех признаков, но техники легко обобщаются и на большее количество. Примеры алгоритмов, использующих такие подходы, можно посмотреть в работах [2, 10].
После встраивания бита вычисляются обратные преобразования, отображающие измененные коэффициенты соответствующего пространства маркирования во временную последовательность сигнала. Завершающим этапом встраивания ЦВЗ является склейка всех промаркированных блоков в единый сигнал, содержащий watermark.
Обобщенная схема извлечения ЦВЗ представлена на рисунке 5. Одним из важных вопросов в блочно-ориентированном подходе является вопрос синхронизации. Необходимо определить точное положение каждого блока в процессе декодирования ЦВЗ. Для этого производится восстановление потока бит при различных начальных смещениях и ищется синхрокод. В качестве критерия обнаружения, как правило, используется пороговое значение коэффициента корреляции или расстояние Хемминга. Как только синхрокод найден, приступают к восстановлению watermark — устраняют введенную на этапе маркирования избыточность.

Результаты наших исследований
В англоязычном сегменте Интернета достаточно разного рода публикаций по аудио ЦВЗ. Попробовав некоторые из техник, мы не добились устраивающих нас результатов. При прозрачности ODG около -1 реализации алгоритмов [10 — 12] не смогли распознать watermark на мобильном устройстве даже на расстояниях около 5 см от источника звука. Также мы отметили сильную зависимость прозрачности исследуемых ЦВЗ от характера исходного сигнала. Например, watermark, не различимый на слух в рок-музыке, был слышим в речи. Бороться с этим удавалось только путем уменьшения агрессивности встраивания (увеличением SNR), что снижало и без того низкую устойчивость ЦВЗ.
Мы решили реализовать свой алгоритм, который бы позволял динамически подстраивается к спектральным характеристикам звука.
Встраивание ЦВЗ происходит в частотной области с использованием оконного преобразования Фурье (Short-time Fourier transform, STFT). В основу метода положен эффект временного маскирования — слабый сигнал, возникающий раньше или позже сильного, в течение некоторого времени остается незамеченным. Время маскировки зависит от частоты и амплитуды сигнала и может достигать сотен миллисекунд.

Мы прячем watermark в «тени» локальных пиков спектрограммы — в каждый конкретный интервал времени выбираем те коэффициенты STFT, которые можно относительно безвредно изменять для кодирования бит (рисунок 6).
Метод позволяет добиться пропускной способности в 50 bits/s, что является вполне достаточным для ACR. Правда, при таком решении некоторые блоки сигнала остаются не маркированными, но, как показали наши исследования, их доля составляет около 0.01%. В качестве примера в таблице 1 показаны результаты сравнительных тестов. Атаки проводились с помощью утилиты SMFA (StirMark for Audio) версии 1.3.2. Параметры сравниваемых алгоритмов подбирались так, чтобы обеспечить одинаковое, насколько это возможно, значение прозрачности; ODG лежал в диапазоне от -0.5 до -0.1.
Таблица 1 — Сравнение алгоритмов digital watermarking по параметру Bit Error Rate
| Вид атаки | Алгоритм | |||
| [10] | [11] | [12] | Наше решение | |
| AddNoise (9 дБ) | 0.11 | 0.09 | 0.2 | 0.007 |
| AddDynNoise (10 дБ) | 0.51 | 0.4 | 0.51 | 0.010 |
| AddFFTNoise (12 дБ) | 0.06 | 0.01 | 0.13 | 0.008 |
| MP3 сжатие 128 kbps | 0.01 | 0.01 | 0.10 | 0.005 |
| MP3 сжатие 32 kbps | 0.36 | 0.3 | 0.48 | 0.005 |
| AAC сжатие 32 kbps | 0.36 | 0.3 | 0.46 | 0.005 |
| Примечание: в скобках указан параметр SNR после применения атаки; атака AddFFTNoise проводилась при параметре FFTSIZE = 128. | ||||
Наш метод выдерживает с BER < 1 % низкочастотную фильтрацию до 4.5 кГц, высокочастотную фильтрацию до 1.9 кГц, изменение уровня звукового сигнала (от 1 % до 150 %), уменьшение частоты дискретизации до 8 кГц.
Основным тестом, в контексте решаемой задачи, конечно являлась проверка устойчивости watermark при акустическом распространении сигнала. Треки с ЦВЗ были воспроизведены на телевизоре и записаны на разные мобильные устройства (LG-P705, Samsung GT-P7510, HTC Desire 601 и др). Моносигналы записывались с частотой дискретизации 44,1 кГц на разных удалениях от источника звука.
В отличие от алгоритмов [10 — 12], наши ЦВЗ распознаются на мобильных устройствах, но их устойчивость все равно недостаточна, чтобы говорить о равноценной замене fingerprints. Например, LG-P705 на расстоянии 40 см успешно распознавал около 85 % запросов, в то время как Samsung GT-P7510 распознавал 80 % только на расстоянии до 5 см. В сигналах, записанных на расстояниях более 50 см, watermark уже не обнаруживается.
Только с ЦВЗ вне акустической области частот нам удалось добиться синхронизации на удалениях более 1 м. Для LG-P705 и HTC Desire 601 на расстояниях 1.5 метров доля правильно обнаруженных watermark составляла 80%. Для кодирования бит применялась простая амплитудная модуляция гармоник с частотами более 20 кГц (рисунок 7).

Однако не все мобильные устройства одинаково хорошо справляются с записью высоких частот. Тот же Samsung GT-P7510 ни разу не распознал данный вид watermark. Но главным недостатком таких ЦВЗ является их неспособность пережить сжатие с потерями, что сильно ограничивает возможности применения.
Заключение
Конечно, многое осталось за рамками наших экспериментов, но полученный опыт заставил нас серьезно усомниться в возможностях практического применения ACR на основе ЦВЗ. По крайне мере, если говорить о watermark в области акустических частот.
Большинство найденных нами работ по audio watermarking в своих исследованиях ограничиваются синтетическими атаками SMFA и оценкой устойчивости к сжатию. Публикаций, исследующих устойчивость ЦВЗ при акустическом распространении сигнала и записи его на микрофон, — считанные единицы, и те довольно поверхностно затрагивают этот вопрос, без достаточной конкретики.
Наше решение относительно простое и довольно успешно справляется с типовыми тестами, а также выдерживает сжатие с потерями. Однако, нам не удалось одновременно гарантировать прозрачность и достаточную для приложений Second Screen устойчивость ЦВЗ, сопоставимую с технологиями fingerprints.
Список литературы
- Harleen Kaur «Blind Audio Watermarking schemes: A Literature Review»
- Mehdi Fallahpour «High capacity robust audio watermarking scheme based on fft and linear regression»
- Baiying Lei «A multipurpose audio watermarking algorithm with synchronization and encryption»
- Hong Oh Kim «Wavelet-based audio watermarking techniques: robustness and fast synchronization»
- Shaik Jameer «A scheme for digital audio watermarking using empirical mode decomposition with IFM»
- Alok Kumar Chowdhury «A roust audio watermarking in cepsrum domain comosed of samples relation dependent embedding and computationally simple extraction phase»
- Hooman Nikmehr «A new approach to audio watermarking using discrete wavelet and cosine transforms»
- Vivekananda Bhat K «An adaptive audio watermarking based on the singular value decomposition in the wavelet domain»
- Brian Chen «Quantization Index Modulation: A Class of Provably Good Methods for Digital Watermarking and Information Embedding»
- Shijun Xiang «Audio watermarking robust against D/A and A/D conversions»
- Hong Oh Kim «Wavelet-based Audio Watermarking Techniques: Robustness and Fast Synchronization»
- Jong-Tzy Wang «Adaptive Wavelet Quantization Index Modulation Technique for AudioWatermarking»
