Clinical Document Architecture ﴾CDA﴿ — один из стандартов HL7, разработанный для стандартизации структуры и обеспечения семантической совместимости мед систем при обмене медицинской информацией и/или мед документами. Первая версия стандарта была одобрена ANSI ещё в 2001 году. Вторая версия, котороя используется и по сей день, была утверждена ANSI в 2005. Третья версия, CDA R3, находится в стадии разработки и согласования.
CDA R2 (Release 2) гарантирует наличие следующих семи характеристик в CDA документе:
• Сохранность представленной информации;
• Управление представленной информацией;
• Поддержка требований к аутентификации всей представленной информации;
• Поддержка контекста представленной информации;
• Поддержка цельности информации;
• Возможность чтения представленной информации человеком;
• Поддержка бинарной информации, таких как мультимедийные компоненты, PDF, изображения и прочее.
Подобные характеристики делают CDA крайне гибким к использованию в различных областях. И даже несмотря на то, что в среде разработчиков мед систем CDA считается крайне сложным стандартом, он стал одним из наиболее успешных разработанных HL7 для интеграции мед данных и согласуется с требованиями Meaningful Use 1 и 2 принятыми в США. Большинство мед систем в настоящее время кодируют информацию в одном из девяти возможных шаблонов документов CDA, например, Continuity of Care Document (CCD) один из таких шаблонов.
В данной статье представлен обзор или упрощённое описание основных компонентов CDA. И так, как и любой документ, CDA содержит заголовок документа (CDA Header) и тело документа (CDA Body).
Как показано на следующей картинке, в заголовоке CDA включена некоторая административная информация на основе классов и сущностей RIM модели HL7.
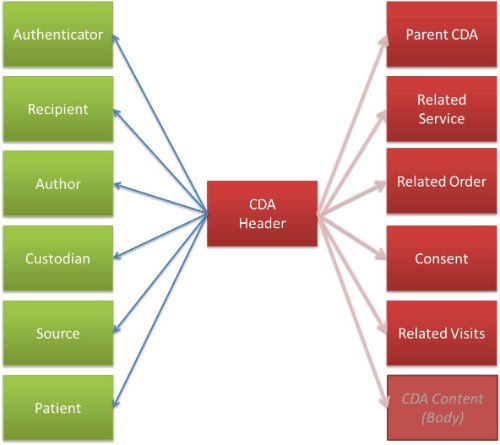
Основной класс в заголовке CDA так и называется — Clinical Document, и, в соответствии с его названием, содержит кроме всего прочего информацию для идентификации документа, заголовок, используемый язык, версию, дату публикации и уровень конфиденциальности. Далее рассмотрим назначение некоторых из выше приведённых классов. Чтобы избежать путаницы названия классов будут даны в их английской транскрипции.
Этот класс включен в документ для идентификации лица и/или организации, которые могут использоваться для проверки подлинности всего содержимого документа CDA.
Здесь всё просто, в заголовке документа recipient используется для идентификации получателя (лица и/или организации) документа и может включать такие данные как имя, адрес и прочую информацию. Получателей может быть множество.
В данном классе кодируется информация для идентификации и проверки лица или устройства, а также организации их представляющих, которые ответственны за данные в CDA документе.
Данные класс используется для идентификации и проверки организации ответственной за сохранность документа. Подобная органиация отвечает за сохранность всех данных в документе (за весь документ).
В данном классе кодируется информация о лице и/или организации поместившим данные в медицинскую систему, на основе которых и был создан документ. Подобным лицом может быть, например, Data Entry clerk.
Поскольку документ CDA может быть частью другого документа CDA, подобная информация должна быть где-то представлена. В данном классе как раз кодируется информация о взаимосвязях между двумя и более документами.
Используя данный класс в заголовке CDA документа представлена информация о главном участнике всех событий – пациенте. Имя, адрес, опекуны и всякая прочая информация для полной идентификации пациента. Стоить заметить, что некоторые типы данных запрещены в некоторых странах. Например, информация о расовой и религиозной принадлежности требуется в США, но недопустима в Европе.
Тело документа или CDA Body может быть как неструктурированным для данных, которые не кодируются в XML, так и структурированным для представленных в формате XML данных. С особенностями такого кодирования тесно связано понятие уровней семантической совместимости CDA (в данной статье не рассматриваются).
В описании ниже также будут использоваться английские названия компонентов или классов.
Неструктурированное тело документа может содержать только одно вложение со ссылкой на данные вне этого CDA документа, либо Base64 кодированное бинарное вложение (PDF, изображение, аудио, видео и т.п.).
Структурированное тело документа разработано как крайне гибкий механизм для включения разнообразных клинических и административных данных. Именно это делает CDA настолько мощным в концептуальном плане, что теоретически его можно использовать для кодирования всей истории болезни пациента, какой бы сложности она не была. Обратная сторона подобной гибкости в сложности реализации всех имеющихся особенностей стандарта. Одна из причин этого в неправильности или неполноте понимания самого стандарта различными организациями.
Для устранения подобного разногласия были придуманы шаблоны CDA документов. Создание шаблонов и различных руководств разработчика нацелено на упрощение реализации и ограничения разночтений стандарта для одних и тех же клинических областей. К таким шаблоном относятся Clinical Notes, CCD, Discharge Summary и прочее). Все они представлены на официальном сайте HL7. Кроме того, существует около 70-ти шаблонов секций и ещё больше шаблонов записей.
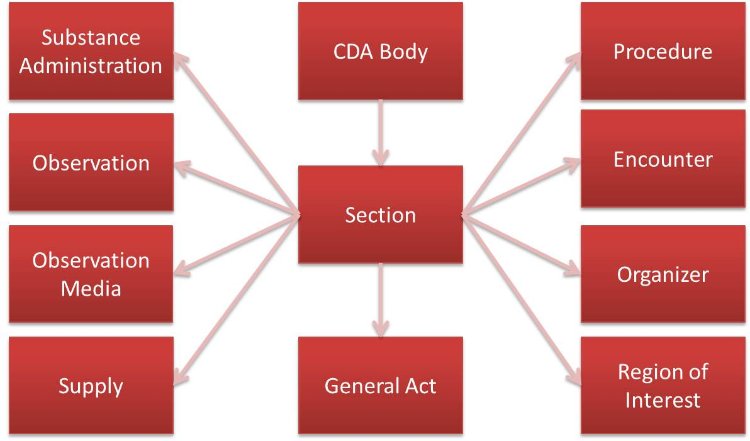
Как показано на рисунке выше, структурированное тело документа может содержать одну или более секций, каждая из которых может содержать мед или адмнистративную информацию, а также вложения. При этом в самом стандарте CDA ни чего не сказано как устанавливать отношения между подобными данными, для этого нужно обращаться к многочисленным руководствам разработчика доступным на официальном сайте HL7 либо разрабатываемых каждой огранизацией в отдельности.
CDA R2 (Release 2) гарантирует наличие следующих семи характеристик в CDA документе:
• Сохранность представленной информации;
• Управление представленной информацией;
• Поддержка требований к аутентификации всей представленной информации;
• Поддержка контекста представленной информации;
• Поддержка цельности информации;
• Возможность чтения представленной информации человеком;
• Поддержка бинарной информации, таких как мультимедийные компоненты, PDF, изображения и прочее.
Подобные характеристики делают CDA крайне гибким к использованию в различных областях. И даже несмотря на то, что в среде разработчиков мед систем CDA считается крайне сложным стандартом, он стал одним из наиболее успешных разработанных HL7 для интеграции мед данных и согласуется с требованиями Meaningful Use 1 и 2 принятыми в США. Большинство мед систем в настоящее время кодируют информацию в одном из девяти возможных шаблонов документов CDA, например, Continuity of Care Document (CCD) один из таких шаблонов.
В данной статье представлен обзор или упрощённое описание основных компонентов CDA. И так, как и любой документ, CDA содержит заголовок документа (CDA Header) и тело документа (CDA Body).
CDA Header

Как показано на следующей картинке, в заголовоке CDA включена некоторая административная информация на основе классов и сущностей RIM модели HL7.

Основной класс в заголовке CDA так и называется — Clinical Document, и, в соответствии с его названием, содержит кроме всего прочего информацию для идентификации документа, заголовок, используемый язык, версию, дату публикации и уровень конфиденциальности. Далее рассмотрим назначение некоторых из выше приведённых классов. Чтобы избежать путаницы названия классов будут даны в их английской транскрипции.
Authenticator
Этот класс включен в документ для идентификации лица и/или организации, которые могут использоваться для проверки подлинности всего содержимого документа CDA.
Recipient
Здесь всё просто, в заголовке документа recipient используется для идентификации получателя (лица и/или организации) документа и может включать такие данные как имя, адрес и прочую информацию. Получателей может быть множество.
Author
В данном классе кодируется информация для идентификации и проверки лица или устройства, а также организации их представляющих, которые ответственны за данные в CDA документе.
Custodian
Данные класс используется для идентификации и проверки организации ответственной за сохранность документа. Подобная органиация отвечает за сохранность всех данных в документе (за весь документ).
Source
В данном классе кодируется информация о лице и/или организации поместившим данные в медицинскую систему, на основе которых и был создан документ. Подобным лицом может быть, например, Data Entry clerk.
Parent CDA
Поскольку документ CDA может быть частью другого документа CDA, подобная информация должна быть где-то представлена. В данном классе как раз кодируется информация о взаимосвязях между двумя и более документами.
Patient
Используя данный класс в заголовке CDA документа представлена информация о главном участнике всех событий – пациенте. Имя, адрес, опекуны и всякая прочая информация для полной идентификации пациента. Стоить заметить, что некоторые типы данных запрещены в некоторых странах. Например, информация о расовой и религиозной принадлежности требуется в США, но недопустима в Европе.
CDA Body
Тело документа или CDA Body может быть как неструктурированным для данных, которые не кодируются в XML, так и структурированным для представленных в формате XML данных. С особенностями такого кодирования тесно связано понятие уровней семантической совместимости CDA (в данной статье не рассматриваются).
В описании ниже также будут использоваться английские названия компонентов или классов.
Non-structured Body
Неструктурированное тело документа может содержать только одно вложение со ссылкой на данные вне этого CDA документа, либо Base64 кодированное бинарное вложение (PDF, изображение, аудио, видео и т.п.).
Structured Body
Структурированное тело документа разработано как крайне гибкий механизм для включения разнообразных клинических и административных данных. Именно это делает CDA настолько мощным в концептуальном плане, что теоретически его можно использовать для кодирования всей истории болезни пациента, какой бы сложности она не была. Обратная сторона подобной гибкости в сложности реализации всех имеющихся особенностей стандарта. Одна из причин этого в неправильности или неполноте понимания самого стандарта различными организациями.
Для устранения подобного разногласия были придуманы шаблоны CDA документов. Создание шаблонов и различных руководств разработчика нацелено на упрощение реализации и ограничения разночтений стандарта для одних и тех же клинических областей. К таким шаблоном относятся Clinical Notes, CCD, Discharge Summary и прочее). Все они представлены на официальном сайте HL7. Кроме того, существует около 70-ти шаблонов секций и ещё больше шаблонов записей.

Как показано на рисунке выше, структурированное тело документа может содержать одну или более секций, каждая из которых может содержать мед или адмнистративную информацию, а также вложения. При этом в самом стандарте CDA ни чего не сказано как устанавливать отношения между подобными данными, для этого нужно обращаться к многочисленным руководствам разработчика доступным на официальном сайте HL7 либо разрабатываемых каждой огранизацией в отдельности.
