Привет, Хабр.
Меня зовут Илья Гребцов, я работаю Java/JS Developer в DataArt. Хочу поделиться кое-чем полезным с теми, кто работает с Salesforce.
В Salesforce часто возникает задача массово создать/изменить/удалить группу связанных записей в нескольких объектах, аналогах таблиц в реляционной базе данных. Например, часто используемые стандартные объекты Account (информация о компании клиента), Contact (информация о самом клиенте). Проблема в том, что при сохранении записи Contact необходимо указать Id связанной записи Account, т. е. аккаунт должен существовать на момент добавления записи контакта.
В реальности связи могут быть еще сложнее, например, объект Opportunity ссылается и на Account, и на Contact. Плюс возможны ссылки на какие-либо нестандартные (custom) объекты. В любом случае, запись по ссылке должна быть создана раньше записи, на нее ссылающуюся.
Рассмотрим варианты решения этой проблемы:
Необходимо подготовить APEX-скрипт, затем выполнить его в Salesforce Developer Console. В скрипте связанные объекты заполняются последовательно. В примере ниже вставляется тестовая запись Account, затем Contact. При вставке Contact используется Id записи Account, полученный после вставки Account.
Плюсы:
Минусы:
Таким образом, способ подходит лишь для небольших простых изменений, производимых вручную.
Когда необходимо произвести изменения множества записей, которые уже внутри Salesforce, можно воспользоваться Batch APEX. В отличии от предыдущего, этот способ позволяет обработать до 10 000 записей, согласно Salesforce Limits. Batch — кастомный класс, наследуемый от Database.Batchable, написанный на языке APEX.
Вручную класс можно запустить из Developer Console:
Либо создать Job, с помощью которого процесс запустится в определенное время.
Таким образом, способ подходит для масштабных изменений данных внутри Salesforce, но весьма трудоемок. При внедрении с sandbox на продуктив класс, как и любой другой APEX-код, должен быть покрыт юнит-тестом.
Data Loader — стандартная Salesforce-утилита, устанавливающаяся локально. Позволяет обработать до 5 млн записей. Миграция с помощью Data Loader — best practise и наиболее популярный метод обработки большого количества записей. Выгрузка/загрузка записей осуществляется с помощью Salesforce API.
Утилита позволяет выбрать объект в Salesforce и экспортировать данные в CSV файл. А также наоборот, загрузить из CSV в Salesforce объект.
Обработка уже существующих данных в Salesforce выглядит следующим образом:
Пункт 2 тут — узкое место, не реализуемое самим Data Loader. Необходимо создание сторонних процедур обработки CSV файлов.
В качестве примера, чтобы вставить несколько записей контактов, данные должны пойти в связанные Account и Contact. Алгоритм действий должен быть таким:
Таким образом, способ подходит для масштабных изменений данных и внутри Salesforce, и с использованием внешних данных. Но весьма трудоемок, особенно если необходима модификация записей.
Pentaho Data Integration также известная как Kettle — универсальная ETL утилита. Не является специализированной утилитой Salesforce. В наборе — Salesforce Input- и Output-методы подключения, что позволяет прозрачно обрабатывать Salesforce данные как данные из других источников: реляционных баз данных, SAP, файлов XML, CSV и других.
С Salesforce утилита работает через Salesforce API, таким образом, возможно обработать до 5 млн записей, как и с Data Loader. Только более удобным способом.
Главная отличительная особенность — графический интерфейс. Вся трансформация разбивается на отдельные простые шаги: прочитать данные, отсортировать, соединить (join), записать данные. Шаги отображаются в виде пиктограмм, между которыми проведены стрелки. Таким образом, наглядно видно, что откуда берется и куда приходит.
Есть как минимум две версии утилиты: платная с гарантированной поддержкой и бесплатная. Бесплатную Community Edition (Apache License v2.0) можно скачать по адресу http://community.pentaho.com/.
Разработка трансформации в простейшем случае не требует навыков программирования. Но при желании можно использовать шаги, включающие подпрограммы, написанные на Java или JavaScript.
Особенности миграции данных с помощью Pentaho Data Integration стоит осветить подробнее. Здесь же опишу свой опыт и трудности, с которыми столкнулся.
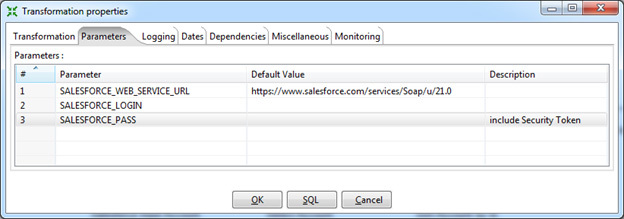
Параметры подключения к Salesforce стоит указать в параметрах Transformation Properties. Единожды сделанные настройки будут доступны во всех шагах, где это необходимо, в виде переменных.
Я рекомендую указывать:
По соображениям безопасности можно оставить поля логина и пароля пустыми, в этом случае Data Integration запросит их при запуске трансформации.
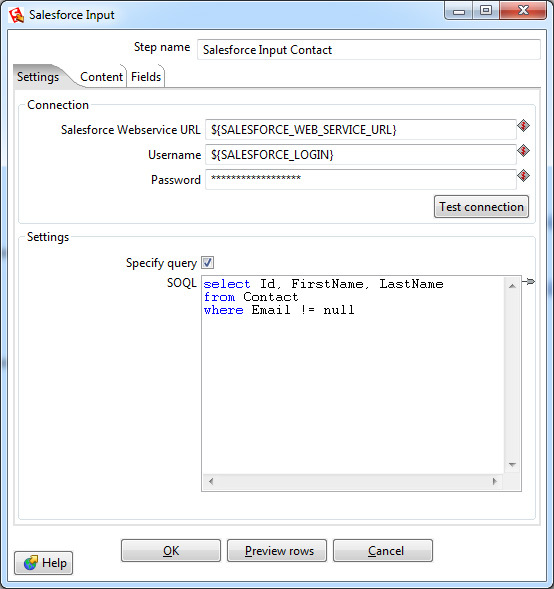
Выборка данных осуществляется шагом Salesforce Input. В настройках этого шага нужно указать параметры подключения, в данном случае используются переменные, созданные ранее. Также выбрать объект и список полей для выборки либо указать специфичный запрос, используя язык запросов SOQL (похож на язык запросов SQL, используемый в реляционных базах данных).
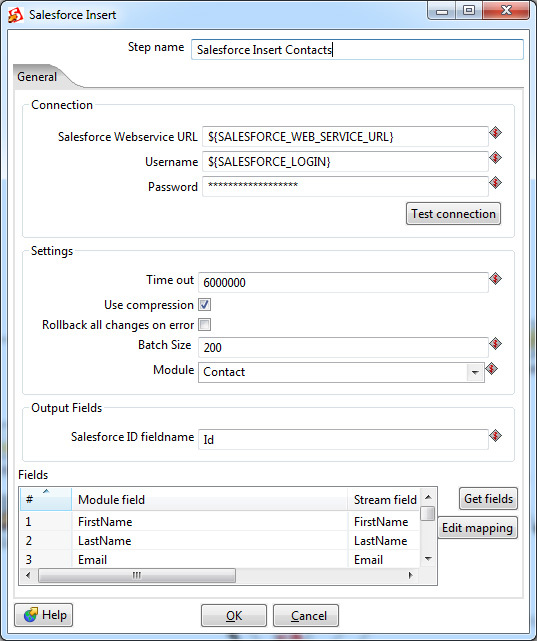
Вставка данных осуществляется с помощью одного из нескольких Output шагов:
Также возможно удаление записей с помощью
Как и в Input-шаге, необходимо указать параметры подключения, в данном случае используются переменные трансформации. Тут имеется и более тонкая настройка — параметры time out-подключения, по истечении которого трансформация завершится неуспешно. И специфичный для Salesforce параметр Batch Size — количество записей, передаваемых в одной транзакции. Увеличение Batch Size незначительно повышает скорость работы трансформации, но не может быть больше 200 (согласно ограничениям Salesforce). Кроме того, если имеются триггеры, осуществляющие дополнительную обработку данных после вставки, возможна нестабильная работа с большим значением Batch Size. Значение по умолчанию — 10.
Приведенные два шага полностью покрывают возможности утилиты Data Loader. Всё, что между ними, — логика обработки данных. И ее можно реализовать непосредственно в Pentaho Data Integration.
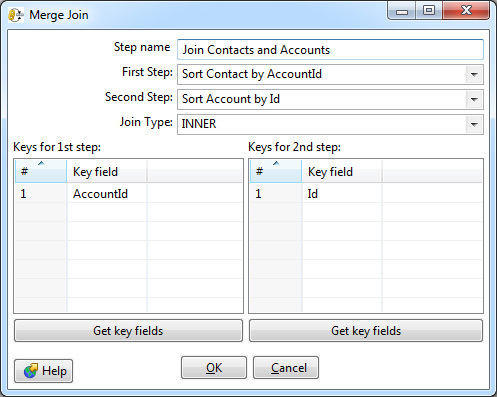
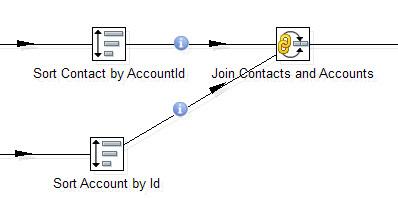
Например, один из самых востребованных шагов — объединение (join) двух потоков данных. Тот самый join из SQL, которого так не хватает в SOQL. Тут он есть.
В настройках возможно выбрать тип: Inner, Left Outer, Right Outer, Full Outer — и указать ключи соединения.
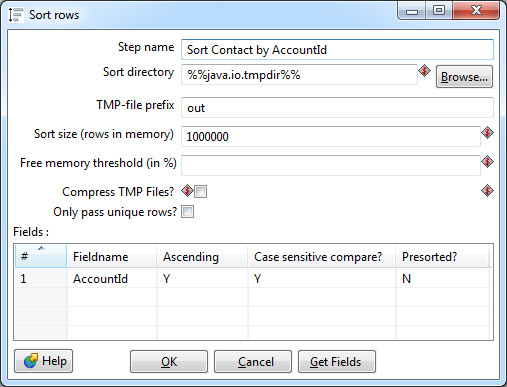
Обязательное требование — входные данные для этого шага должны быть отсортированы по ключевым полям. В Data Integration для этого применяется отдельный шаг Sorter.
Сортировка производится в оперативной памяти, тем не менее, возможна ситуация, что ее не хватит и данные будут сохраняться в промежуточный файл на диск. Большинство настроек сортера связано именно с этим кейсом. В идеале нужно избегать свопа на диск: это в десятки раз медленнее сортировки в памяти. Для этого необходимо скорректировать параметр Sort size — указать верхнюю границу количества строк, которые теоретически могут проходить через сортер.
Также в настройках можно выбрать одно или несколько ключевых полей, по которым будет производиться сортировка в порядке возрастания или убывания значений. Если тип поля строковый, имеет смысл указать чувствительность к регистру. Параметр Presorted показывает, что строки уже отсортированы по данному полю.
Join и Sorter образуют связку, встречающуюся практически в каждой трансформации.
Сортировки и соединения больше всего влияют на производительность трансформации. Стоит избегать лишних сортировок, если данные уже отсортированы несколькими шагами ранее и их порядок после не менялся. Но нужно быть аккуратным: если в Join данные придут несортированными, Data Integration не прервет работу и не покажет ошибку, просто полученный результат будет некорректным.
В качестве ключевых полей всегда нужно выбирать короткое поле. Data Integration позволяет выбрать несколько ключевых полей для сортировки и соединения, но скорость обработки при этом значительно снижается. В качестве обходного пути лучше сгенерировать суррогатный ключ, в результате останется только одно поле для соединения. В простейшем случае суррогатный ключ можно получить конкатенацией строк. Например, для соединения по полям FirstName, LastName лучше соединять по FirstName + ‘ ‘+ LastName. Если идти дальше, из полученной строки можно вычислить хеш (md5, sha2). К сожалению, в Data Integration нет встроенного шага для расчета хеша строки, его можно написать самостоятельно, используя User Defined Java Class.
Кроме приведенных выше шагов, Data Integration включает множество других. Это фильтры, switch, union, шаги для обработки строк, лукапы к реляционным таблицам и веб-сервисам. И множество других. А также два универсальных шага, позволяющие выполнить код на Java или JavaScript. Не буду останавливаться на них подробно.
Неприятная особенность работы Data Integration именно с Salesforce — медленная скорость вставки записей через Salesforce API. Около 50 записей в секунду (как и у стандартного Data Loader, само по себе обращение к веб-сервису — медленная операция), что делает затруднительным обработку тысяч строк. К счастью, в Data Integration можно организовать вставку в несколько потоков. Стандартного решения нет, вот то, что я смог придумать:
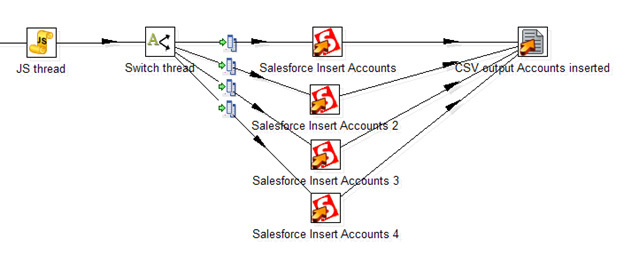
Тут JavaScript-процедура генерирует случайный номер потока. Далее шаг Switch распределяет потоки согласно его номеру. Четыре отдельных шага Salesforce Insert производят вставку записей, таким образом увеличивая общую скорость потока до 200 записей в секунду. В конечном счете, все вставленные записи с заполненным полем ID сохраняются в CSV файл.
Используя параллельную вставку, можно несколько ускорить обработку данных. Но плодить потоки бесконечно не получится: согласно ограничениям Salesforce, возможно не более 25 открытых соединений от одного пользователя.
Полученную трансформацию можно сразу же запустить на локальной машине. Прогресс пробега отображается в Step Metrics. Тут видно, какие шаги работают, сколько записей было прочитано на этом шаге и передано далее. А также скорость обработки записей на конкретном шаге, что делает простым нахождение «бутылочного горлышка» трансформации.

Для регулярных преобразований Data Integration позволяет создать Job, запускаемый по условию или расписанию на локальной машине или выделенном сервере.
Спасибо за внимание. Надеюсь, Salesforce-разработчики возьмут столь полезное средство на вооружение.
Меня зовут Илья Гребцов, я работаю Java/JS Developer в DataArt. Хочу поделиться кое-чем полезным с теми, кто работает с Salesforce.
В Salesforce часто возникает задача массово создать/изменить/удалить группу связанных записей в нескольких объектах, аналогах таблиц в реляционной базе данных. Например, часто используемые стандартные объекты Account (информация о компании клиента), Contact (информация о самом клиенте). Проблема в том, что при сохранении записи Contact необходимо указать Id связанной записи Account, т. е. аккаунт должен существовать на момент добавления записи контакта.
В реальности связи могут быть еще сложнее, например, объект Opportunity ссылается и на Account, и на Contact. Плюс возможны ссылки на какие-либо нестандартные (custom) объекты. В любом случае, запись по ссылке должна быть создана раньше записи, на нее ссылающуюся.
Рассмотрим варианты решения этой проблемы:
Anonymous APEX
Необходимо подготовить APEX-скрипт, затем выполнить его в Salesforce Developer Console. В скрипте связанные объекты заполняются последовательно. В примере ниже вставляется тестовая запись Account, затем Contact. При вставке Contact используется Id записи Account, полученный после вставки Account.
Account[] accounts;
accounts.add(new Account(
Name = ‘test’
));
insert accounts;
Contact[] contacts;
contacts.add(new Contact(
AccountId = accounts[0].Id,
FirstName = ‘test’,
LastName = ‘test’
));
insert contacts;
Плюсы:
- Developer Console всегда под рукой, ничего дополнительно устанавливать и настраивать не требуется.
- Скрипт пишется на языке APEX, близком Salesforce-разработчикам.
- Несложно реализовать простую логику.
Минусы:
- Salesforce Limits допускают изменение не более 200 записей таким способом.
- Тяжело реализовать сложную логику.
- Метод не подходит для миграции данных извне Salesforce, все данные должны быть уже загружены.
Таким образом, способ подходит лишь для небольших простых изменений, производимых вручную.
Batch APEX
Когда необходимо произвести изменения множества записей, которые уже внутри Salesforce, можно воспользоваться Batch APEX. В отличии от предыдущего, этот способ позволяет обработать до 10 000 записей, согласно Salesforce Limits. Batch — кастомный класс, наследуемый от Database.Batchable, написанный на языке APEX.
Вручную класс можно запустить из Developer Console:
Database.Batchable<sObject> batch = new myBatchClass();
Database.executeBatch(batch);
Либо создать Job, с помощью которого процесс запустится в определенное время.
Таким образом, способ подходит для масштабных изменений данных внутри Salesforce, но весьма трудоемок. При внедрении с sandbox на продуктив класс, как и любой другой APEX-код, должен быть покрыт юнит-тестом.
Data Loader
Data Loader — стандартная Salesforce-утилита, устанавливающаяся локально. Позволяет обработать до 5 млн записей. Миграция с помощью Data Loader — best practise и наиболее популярный метод обработки большого количества записей. Выгрузка/загрузка записей осуществляется с помощью Salesforce API.
Утилита позволяет выбрать объект в Salesforce и экспортировать данные в CSV файл. А также наоборот, загрузить из CSV в Salesforce объект.
Обработка уже существующих данных в Salesforce выглядит следующим образом:
- Выгрузка необходимых данных из Salesforce в CSV-файлы.
- Изменение данных в CSV-файлах.
- Загрузка данных в Salesforce из CSV-файлов.
Пункт 2 тут — узкое место, не реализуемое самим Data Loader. Необходимо создание сторонних процедур обработки CSV файлов.
В качестве примера, чтобы вставить несколько записей контактов, данные должны пойти в связанные Account и Contact. Алгоритм действий должен быть таким:
- Подготовить CSV файл со списком новых записей Account. Загрузить в Salesforce с помощью Data Loader. В результате будет получен список Account IDs.
- Подготовить CSV файл со списком новых записей Contact. В нем в поле AccountId необходимо указать ID из списка, полученного на 1-м шаге. Это можно сделать вручную, либо использовать любой язык программирования.
- Загрузить в Salesforce полученную CSV со списком Contacts.
Таким образом, способ подходит для масштабных изменений данных и внутри Salesforce, и с использованием внешних данных. Но весьма трудоемок, особенно если необходима модификация записей.
Pentaho Data Integration
Pentaho Data Integration также известная как Kettle — универсальная ETL утилита. Не является специализированной утилитой Salesforce. В наборе — Salesforce Input- и Output-методы подключения, что позволяет прозрачно обрабатывать Salesforce данные как данные из других источников: реляционных баз данных, SAP, файлов XML, CSV и других.
С Salesforce утилита работает через Salesforce API, таким образом, возможно обработать до 5 млн записей, как и с Data Loader. Только более удобным способом.
Главная отличительная особенность — графический интерфейс. Вся трансформация разбивается на отдельные простые шаги: прочитать данные, отсортировать, соединить (join), записать данные. Шаги отображаются в виде пиктограмм, между которыми проведены стрелки. Таким образом, наглядно видно, что откуда берется и куда приходит.
Есть как минимум две версии утилиты: платная с гарантированной поддержкой и бесплатная. Бесплатную Community Edition (Apache License v2.0) можно скачать по адресу http://community.pentaho.com/.
Разработка трансформации в простейшем случае не требует навыков программирования. Но при желании можно использовать шаги, включающие подпрограммы, написанные на Java или JavaScript.
Особенности миграции данных с помощью Pentaho Data Integration стоит осветить подробнее. Здесь же опишу свой опыт и трудности, с которыми столкнулся.
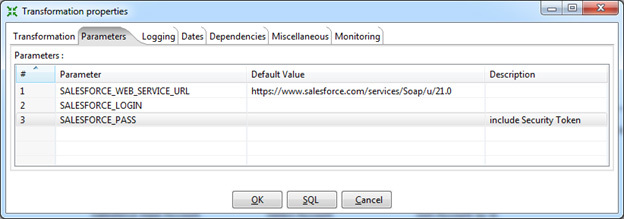
Параметры подключения к Salesforce стоит указать в параметрах Transformation Properties. Единожды сделанные настройки будут доступны во всех шагах, где это необходимо, в виде переменных.
Я рекомендую указывать:
- URL для подключения к Salesforce.
Для продуктива, включая Salesforce Developer Edition: https://www.salesforce.com/services/Soap/u/21.0
Для тестовых сред (sandbox): https://test.salesforce.com/services/Soap/u/21.0
Версию API (в данном случае 21.0) изменять по необходимости. - Логин. Пользователь должен иметь достаточные права для подключения через API. В идеале, это должен быть System Administrator.
- Пароль. Важно, помимо самого пароля необходимо указать Security Token.
По соображениям безопасности можно оставить поля логина и пароля пустыми, в этом случае Data Integration запросит их при запуске трансформации.
Выборка данных осуществляется шагом Salesforce Input. В настройках этого шага нужно указать параметры подключения, в данном случае используются переменные, созданные ранее. Также выбрать объект и список полей для выборки либо указать специфичный запрос, используя язык запросов SOQL (похож на язык запросов SQL, используемый в реляционных базах данных).
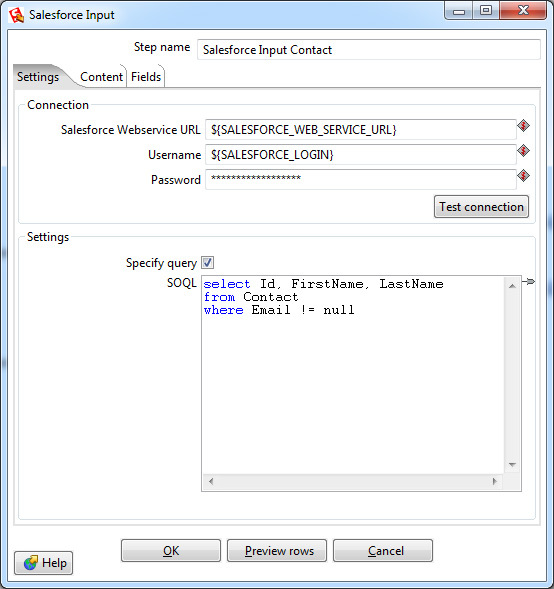
Вставка данных осуществляется с помощью одного из нескольких Output шагов:
- Salesforce Insert
- Salesforce Update
- Salesforce Upsert (объединяет insert и update: если запись есть — она будет обновлена, иначе вставлена новая)
Также возможно удаление записей с помощью
- Salesforce Delete.
Как и в Input-шаге, необходимо указать параметры подключения, в данном случае используются переменные трансформации. Тут имеется и более тонкая настройка — параметры time out-подключения, по истечении которого трансформация завершится неуспешно. И специфичный для Salesforce параметр Batch Size — количество записей, передаваемых в одной транзакции. Увеличение Batch Size незначительно повышает скорость работы трансформации, но не может быть больше 200 (согласно ограничениям Salesforce). Кроме того, если имеются триггеры, осуществляющие дополнительную обработку данных после вставки, возможна нестабильная работа с большим значением Batch Size. Значение по умолчанию — 10.
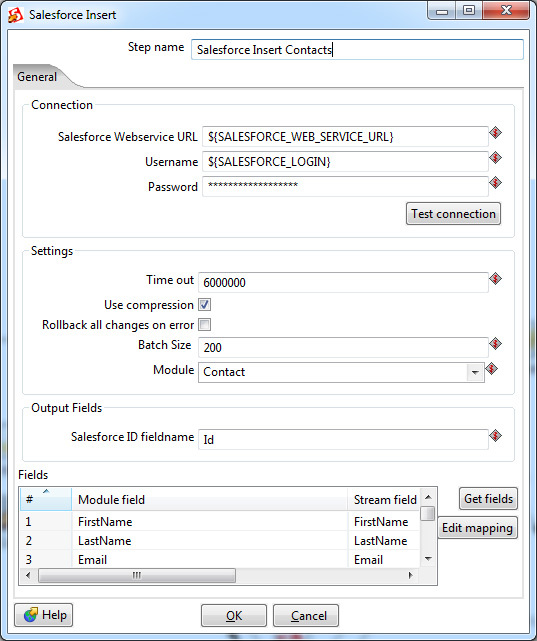
Приведенные два шага полностью покрывают возможности утилиты Data Loader. Всё, что между ними, — логика обработки данных. И ее можно реализовать непосредственно в Pentaho Data Integration.
Например, один из самых востребованных шагов — объединение (join) двух потоков данных. Тот самый join из SQL, которого так не хватает в SOQL. Тут он есть.
В настройках возможно выбрать тип: Inner, Left Outer, Right Outer, Full Outer — и указать ключи соединения.
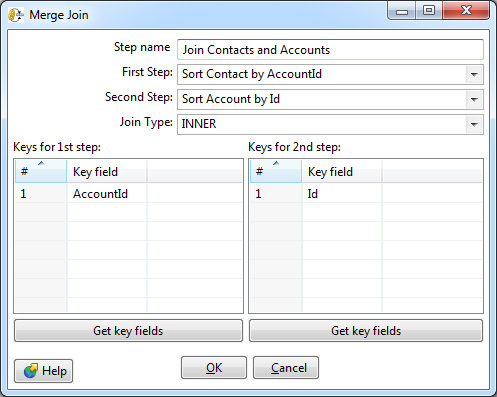
Обязательное требование — входные данные для этого шага должны быть отсортированы по ключевым полям. В Data Integration для этого применяется отдельный шаг Sorter.
Сортировка производится в оперативной памяти, тем не менее, возможна ситуация, что ее не хватит и данные будут сохраняться в промежуточный файл на диск. Большинство настроек сортера связано именно с этим кейсом. В идеале нужно избегать свопа на диск: это в десятки раз медленнее сортировки в памяти. Для этого необходимо скорректировать параметр Sort size — указать верхнюю границу количества строк, которые теоретически могут проходить через сортер.
Также в настройках можно выбрать одно или несколько ключевых полей, по которым будет производиться сортировка в порядке возрастания или убывания значений. Если тип поля строковый, имеет смысл указать чувствительность к регистру. Параметр Presorted показывает, что строки уже отсортированы по данному полю.
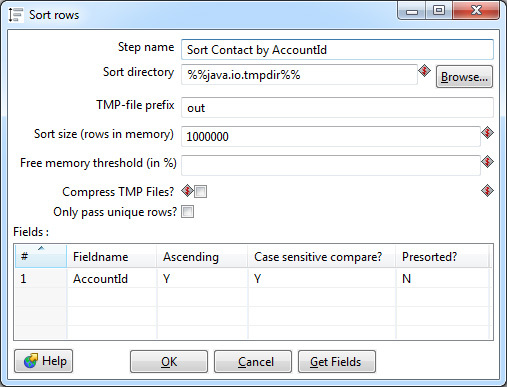
Join и Sorter образуют связку, встречающуюся практически в каждой трансформации.
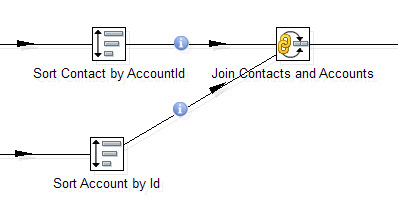
Сортировки и соединения больше всего влияют на производительность трансформации. Стоит избегать лишних сортировок, если данные уже отсортированы несколькими шагами ранее и их порядок после не менялся. Но нужно быть аккуратным: если в Join данные придут несортированными, Data Integration не прервет работу и не покажет ошибку, просто полученный результат будет некорректным.
В качестве ключевых полей всегда нужно выбирать короткое поле. Data Integration позволяет выбрать несколько ключевых полей для сортировки и соединения, но скорость обработки при этом значительно снижается. В качестве обходного пути лучше сгенерировать суррогатный ключ, в результате останется только одно поле для соединения. В простейшем случае суррогатный ключ можно получить конкатенацией строк. Например, для соединения по полям FirstName, LastName лучше соединять по FirstName + ‘ ‘+ LastName. Если идти дальше, из полученной строки можно вычислить хеш (md5, sha2). К сожалению, в Data Integration нет встроенного шага для расчета хеша строки, его можно написать самостоятельно, используя User Defined Java Class.
Кроме приведенных выше шагов, Data Integration включает множество других. Это фильтры, switch, union, шаги для обработки строк, лукапы к реляционным таблицам и веб-сервисам. И множество других. А также два универсальных шага, позволяющие выполнить код на Java или JavaScript. Не буду останавливаться на них подробно.
Неприятная особенность работы Data Integration именно с Salesforce — медленная скорость вставки записей через Salesforce API. Около 50 записей в секунду (как и у стандартного Data Loader, само по себе обращение к веб-сервису — медленная операция), что делает затруднительным обработку тысяч строк. К счастью, в Data Integration можно организовать вставку в несколько потоков. Стандартного решения нет, вот то, что я смог придумать:
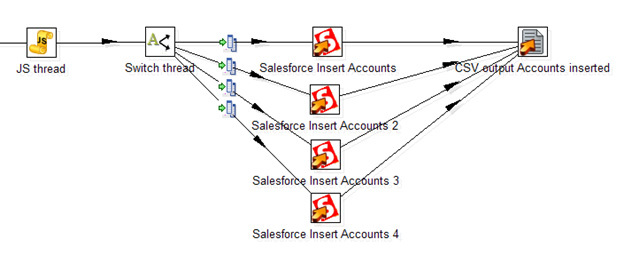
Тут JavaScript-процедура генерирует случайный номер потока. Далее шаг Switch распределяет потоки согласно его номеру. Четыре отдельных шага Salesforce Insert производят вставку записей, таким образом увеличивая общую скорость потока до 200 записей в секунду. В конечном счете, все вставленные записи с заполненным полем ID сохраняются в CSV файл.
Используя параллельную вставку, можно несколько ускорить обработку данных. Но плодить потоки бесконечно не получится: согласно ограничениям Salesforce, возможно не более 25 открытых соединений от одного пользователя.
Полученную трансформацию можно сразу же запустить на локальной машине. Прогресс пробега отображается в Step Metrics. Тут видно, какие шаги работают, сколько записей было прочитано на этом шаге и передано далее. А также скорость обработки записей на конкретном шаге, что делает простым нахождение «бутылочного горлышка» трансформации.

Для регулярных преобразований Data Integration позволяет создать Job, запускаемый по условию или расписанию на локальной машине или выделенном сервере.
Спасибо за внимание. Надеюсь, Salesforce-разработчики возьмут столь полезное средство на вооружение.
