«24 Hours of PASS» — это ежегодная онлайн-конференция о MS SQL Server, проводимая по эгидой профессиональной ассоциации PASS, и длящаяся 24 часа. Вот прям буквально 24 часа: докладчики из разных частей света сменяют друг-друга в марафоне вебинаров (конечно же, это отсылка к 24 часам Ле-Мана).
Усилиями Андрея Коршиков, уже несколько лет проводится русскоязычная версия «24 часа PASS». Последняя состоялась в середине марта, и если вы ещё не успели посмотреть все 24 часа видео (кстати, вот плей-лист на YouTube), то именно для вас я и сделал этот обзор.

слайды — видео часть 1, часть 2
Сергей Олонцев (Лаборатория Касперского) на данный момент, пожалуй, главный движитель московской SQL User Group, организатор нескольких сиквельных мероприятий в Москве, участник многих конференций, MVP и обладатель раритетного статуса SQL MCM. Блог
Зачем смотреть. Про новый крутой In-Memory движок, вы наверное уже слышали. В докладе же много говорится о встречи радужных ожиданий с реальностью.

Классический движок — семейный универсал, большой багажник, кондиционер, детское кресло можно поставить… много комфорта. In-Memory — гоночный болид, способный выжать максимальную скорость, но число функций и удобств очень ограничено. В нашем случае, это: сумма полей не более 8060 байт, не более 512 Гб на базу, нет вычисляемых колонок, нельзя изменять структуру уже созданных таблиц, нет фильтрованных индексов и др.
Размер имеет значение: 10 способов уменьшить размер БД и улучшить производительность системы — скрипты и слайды — видео
Дмитрий Короткевич. Тоже MVP и MCM. Автор лучшей, по моему мнению, книги о MS SQL — «Pro SQL Server Internals» (на английском).
Зачем смотреть. Хороший набор практичных рекомендаций по ужатию ваших данных и объяснение почему это важно.

«Я люблю работать с большими базами данных, они очень интересны. Но только когда у меня почасовая оплата.»
слайды — видео часть 1 и часть 2
Дмитрий Пилюгин (TNS Gallup Media). Ещё один MVP. Знаток недокументированных флагов трассировки и необычных хинтов. Известен своей способностью вгрызаться в тему, разбирая её до мельчайших деталей. Помню, меня очень впечатлила глубина его харьковского доклада о механизме кардинальности (оценки числа строк, возвращаемых после некоторой операции). Блоги: SomewhereSomehow.ru и QueryProcessor.com
Зачем смотреть. Это один из самых сложных докладов, но вместе с тем и самых ценных. Всё о внутренней кухне логической и физической оптимизации таблиц.
С точки зрения сервера, пользовательские запросы — это рулетка:
Оптимизация SSAS кубов (multidimension and tabular): возможно ли медленный куб сделать быстрым?
слайды и скрипты — видео
Евгений Полоничко — DWH/BI архитектор, лидер SQL Server User Group Donetsk
Зачем смотреть. Вы уже работаете с OLAP и хотите посмотреть как с этим зверем управляются другие разработчики.
слайды — видео видео
Андрей Завадский — SQL, ASP.NET и Sharepoint разработчик из Краснодара
Зачем смотреть. Вы сроднились с Management Studio, но хотите взглянуть как люди используют для SQL-разработки большую Visual Studio.
слайды — видео видео
Андрей Коршиков. BI-разработчик, активист PASS, которую он представляет в Восточной Европе, организатор Global Russian Virtual Chapter, обладатель редкой награды PASSion Award.
Зачем смотреть. Вы разрабатываете SSIS-пакеты, хотите вывести разработку на новый уровень, не боитесь нестандартных технологий и не брезгуете генераторами кода.
слайды — видео видео
Сергей Лунякин — лидер PASS Local Chapter в г. Львов
Зачем смотреть. Посмотреть интерфейсы Azure, познакомиться с новыми терминами (сам продукт ещё сыроват).

слайды — видео видео
Мария Закурдаева — основатель PASS Virtual Chapter «Global Hebrew»
Зачем смотреть. Вам хочется узнать как SQL-сервер использует оперативную память, как работают очереди к ресурсам, чем страшно слово «spill». Да, и ещё презентация очень красиво оформлена.

слайды — видео видео
Денис Резник — MVP и, наверное, главный украинский организатор SQL-сообщества.
Зачем смотреть. После нескольких банальностей об уровнях блокировок, посмотреть разбор действительно сложных и даже невероятных случаев.
слайды — видео видео
Константин Хомяков — MVP, BI-разработчик из Австралии
Зачем смотреть. Запросы к данным на естественном языке — технология новая, ещё не очень популярная, но, говорят, на некоторых заказчиков производит впечатление.

слайды — видео видео
Кирилл Панов
Зачем смотреть. Убедиться, что вы действительно в курсе всех перечисленных тем. Несколько сумбурный доклад обо всём понемногу.
слайды — видео видео
Алексей Князев — DWH-специалист, лидер SQL User Group в Екатеринбурге
Зачем смотреть. Если вам нравится разбираться в сути вещей. Очень подробное погружение в структуры хранения, битовые маски, таблицы смещения. Практическая ценность очень ограничена, так как нет возможности как-либо повлиять на описанные механизмы, хотя докладчик и приводит примеры из жизни.

слайды — видео видео
Алексей Ковалёв — харьковчанин, автор SQL Code Guard (must have плагин к SSMS).
Зачем смотреть. Если вы не ведёте контроля версий вашей БД и не знаете как подойти к этой задаче.

Не забывайте про англоязычный 24 hours PASS и Global Russian Virtual Chapter. Следите за анонсами в Facebook.
Усилиями Андрея Коршиков, уже несколько лет проводится русскоязычная версия «24 часа PASS». Последняя состоялась в середине марта, и если вы ещё не успели посмотреть все 24 часа видео (кстати, вот плей-лист на YouTube), то именно для вас я и сделал этот обзор.

- SQL Server 2014 In-Memory OLTP — Сергей Олонцев
- Размер имеет значение: 10 способов уменьшить размер БД — Дмитрий Короткевич
- Внутри оптимизатора запросов: Соединения — Дмитрий Пилюгин
- Оптимизация SSAS-кубов — Евгений Полоничко
- Тяп-ляп и в продакшн! — Алексей Ковалёв
- Оффлайн-разработка баз данных и тестирование с SSDT — Андрей Завадский
- Deadlocks 3.0. Final Edition — Денис Резник
- BIML — лучший друг для SSIS-разработчика — Андрей Коршиков
- Power BI Q&A — Константин Хомяков
- Azure Data Factory — облачный ETL — Сергей Лунякин
- Все что вы хотели узнать о Workspace memory — Мария Закурдаева
- Быстрый анализ производительности SQL Server за 1,5 часа — Кирилл Панов
- Внутреннее устройство страниц и экстентов SQL Server — Алексей Князев
SQL Server 2014 In-Memory OLTP
слайды — видео часть 1, часть 2
Сергей Олонцев (Лаборатория Касперского) на данный момент, пожалуй, главный движитель московской SQL User Group, организатор нескольких сиквельных мероприятий в Москве, участник многих конференций, MVP и обладатель раритетного статуса SQL MCM. Блог
Зачем смотреть. Про новый крутой In-Memory движок, вы наверное уже слышали. В докладе же много говорится о встречи радужных ожиданий с реальностью.

Классический движок — семейный универсал, большой багажник, кондиционер, детское кресло можно поставить… много комфорта. In-Memory — гоночный болид, способный выжать максимальную скорость, но число функций и удобств очень ограничено. В нашем случае, это: сумма полей не более 8060 байт, не более 512 Гб на базу, нет вычисляемых колонок, нельзя изменять структуру уже созданных таблиц, нет фильтрованных индексов и др.
Заметки по докладу
- Неочевидный факт: если таблица объявлена как Memory_Optimized, это ещё не значит, что при выключении электричества данные будут потеряны, ведь они ещё пишутся и в лог-файл. Его можно отключить, и это ещё заметно прибавит скорость.
- Как устроено хранение данных: Bw-tree, однонаправленные списки. В докладе разобрана структура записей, показано что происходит при редактировании, как ведут себя индексы
- Многоверсионная модель — нет больше блокировок и латчей.
- Новые типы индексов «хешовые» и «range»
- Native compile — это сопутствующая технология, позволяющая компилировать запросы к InMem в машинный код. Раньше планы запросов тоже сохранялись в буфере и могли повторно использоваться, это позволяло не запускать заново оптимизатор. Но все планы все равно были интерпретируемыми. Теперь запросы могут быть сохранены в честном машинном коде. Это даёт огромный скачок производительности, но влечёт и чудовищные ограничения. Среди всех, назову только: нет CTE, нельзя использовать LEFT JOIN, не работает оператор CASE.
- Самый простой способ начать использовать InMem — это Memory_Optimized табличные типы. Это аналог временных таблиц и табличных переменных, но в отличие от них, действительно работающие в памяти.
- Другие сценарии, где будет полезно InMem: одновременная вставка из множества потоков, staging-таблицы для ETL, интенсивные операции чтения.
Размер имеет значение
Размер имеет значение: 10 способов уменьшить размер БД и улучшить производительность системы — скрипты и слайды — видео
Дмитрий Короткевич. Тоже MVP и MCM. Автор лучшей, по моему мнению, книги о MS SQL — «Pro SQL Server Internals» (на английском).
Зачем смотреть. Хороший набор практичных рекомендаций по ужатию ваших данных и объяснение почему это важно.
«Я люблю работать с большими базами данных, они очень интересны. Но только когда у меня почасовая оплата.»
Заметки по докладу
Доклад основан на одноимённом посте в блоге автора (рекомендую подписаться).
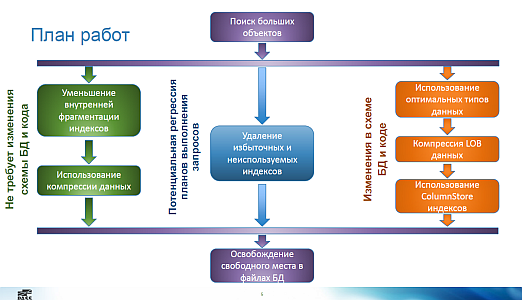
Дмитрий приводит рад полезных скриптов:
- Установите параметр «Instant file Initialization». Он позволяет серверу не делать заполнение нулями при создании и увеличении файлов данных.
- Фрагментация внутренняя и внешняя
- Типы страниц данных: IN_ROW, ROW_OVERFLOW (если есть большая колонка, не помещающаяся на страницу вместе с другими данными строки), LOB (например, для VARCHAR(MAX))
- Компрессия работает только для страниц IN_ROW
- ROW-компрессию практически всегда имеет смысл включать. Если есть колонка INT и в ней хранится значение 0, то при row-компрессии это значение занимает 1 байт, а не 4.
- PAGE-компрессия — это zip-ование страниц памяти. Меняем ресурсы процессора на ресурсы диска (быстрее прочитать, но нужно ещё распаковать).
- LOB компрессия. Вообще-то такой нет. Но можно реализовать свои CLR-функции. Они несложны и реально работают.
- обычно стоит использовать datetime2 вместо datetime
- примеры замен избыточных индексов (их можно находить автоматически):
- IDX1(A, B) & IDX2(A) -> IDX2 можно удалять, он является частью первого индекса
- IDX3(A) INCLUDE(B) & IDX4(A) INCLUDE -> IDX5(A) INCLUDE(B,C)
- ColumnStore-индекс можно рассматривать как особый вид компрессии. Порядок эффективности сжатия: исходная таблица 10 Гб, ROW-компрессия 7 Гб, PAGE-компрессия 2 Гб, COLUMNSTORE от 0,8 до 0,4 Гб
- освобождение места: CREATE INDEX WITH (DROP_EXISTING=ON) ON [NewFileGroup]
Дмитрий приводит рад полезных скриптов:
- Detecting Space Consumers
- Monitoring Splits
- LOBCompress
- Unused Indexes
- Redundant Indexes
Внутри оптимизатора запросов: соединения
слайды — видео часть 1 и часть 2
Дмитрий Пилюгин (TNS Gallup Media). Ещё один MVP. Знаток недокументированных флагов трассировки и необычных хинтов. Известен своей способностью вгрызаться в тему, разбирая её до мельчайших деталей. Помню, меня очень впечатлила глубина его харьковского доклада о механизме кардинальности (оценки числа строк, возвращаемых после некоторой операции). Блоги: SomewhereSomehow.ru и QueryProcessor.com
Зачем смотреть. Это один из самых сложных докладов, но вместе с тем и самых ценных. Всё о внутренней кухне логической и физической оптимизации таблиц.
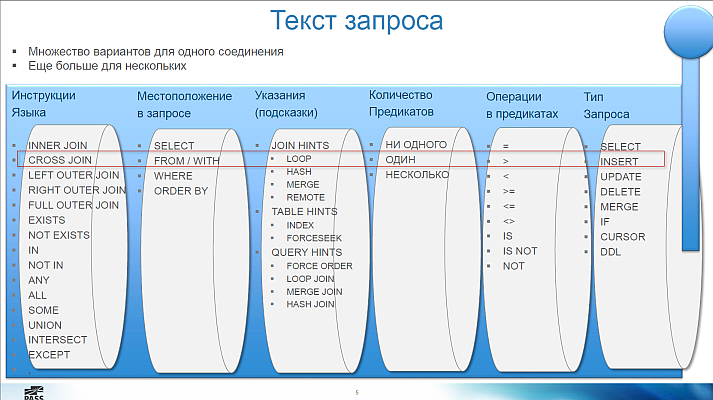
С точки зрения сервера, пользовательские запросы — это рулетка:
Заметки по докладу
Кратко пересказать невозможно, перечисляю только для того, чтобы дать представление о масштабе материала):
В целом картина выглядит так:

Основные свойства физических соединений:
И несколько практических ответов:
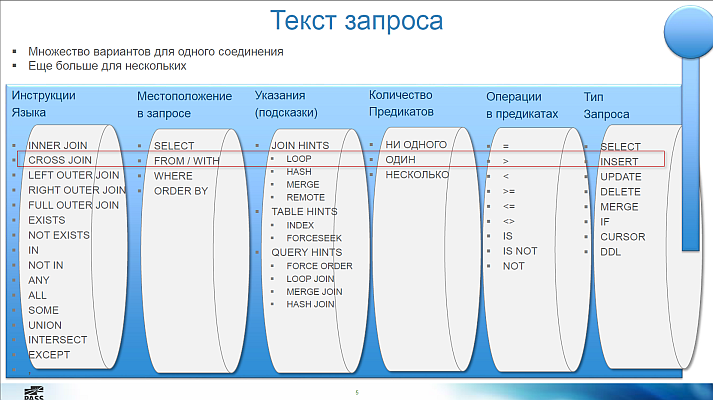
- Помимо общеизвестных INNER JOIN, LEFT OUTER JOIN и FULL JOIN, бывают и другие, например, LEFT ANTI SEMI JOIN. Это соединение таблиц производится оптимизатором в запросе следующего вида:
- операции работы с множествами, например, EXCEPT — это тоже скрытое соединение таблиц
- PREDICATE — скалярный оператор. Например: CScaOp_AggFunc, CScaOp_Arithmetic, CScaOp_Assign, CScaOp_Collate...
- PROBE — это оператор при запросах вида SELECT CASE WHEN EXISTS(SELECT ..) THEN 10 ELSE 20 END ...
- PASS THROUGH — это оператор при запросах вида SELECT CASE WHEN a=1 THEN (SELECT TOP(1)..) ELSE 0 END ...
- Строится дерево логических операторов, это такие объекты, вроде:
- LogOp_Get – получить таблицу
- LogOp_Select – фильтр («выбрать из», where, on, having, …)
- LogOp_LeftSemiJoin, LogOp_RightSemiJoin – полу соединения
- К дереву применяются упрощающие/заменяющие правила оптимизации (simplification/substitution rules)
- Логическая оптимизация «Упрощающие правила»: исключение пустых множеств, исключение избыточности, проталкивание предикатов, раскрытие подзапросов, линеаризация соединений — всех их около 150, в докладе хорошие примеры
- Примеры: отбрасываются неиспользуемые джойны таблиц, LEFT JOIN преобразуется в INNER JOIN, если есть условие по нему в WHERE и др.
- Логические операторы преобразуются в физические, в процессе применения «реализующих» правил
- Физическая оптимизация «Исследующие правила»: коммутативность соединений, группировка до соединения, сопоставление индексированных представлений, Full Outer -> Left Outer + Left Anti Semi Join и другие (всего 130 правил)
- Физическая оптимизация «Реализующие правила»: зависят от логического оператора, стоимости, hints (например, использовать LOOP JOIN или HASH JOIN)
- Работает эвристический алгоритм подбора порядка соединения таблиц, всего вариантов слишком много: для 10 таблиц даже методом Left Deep Tree будет 3 628 800 вариантов
В целом картина выглядит так:
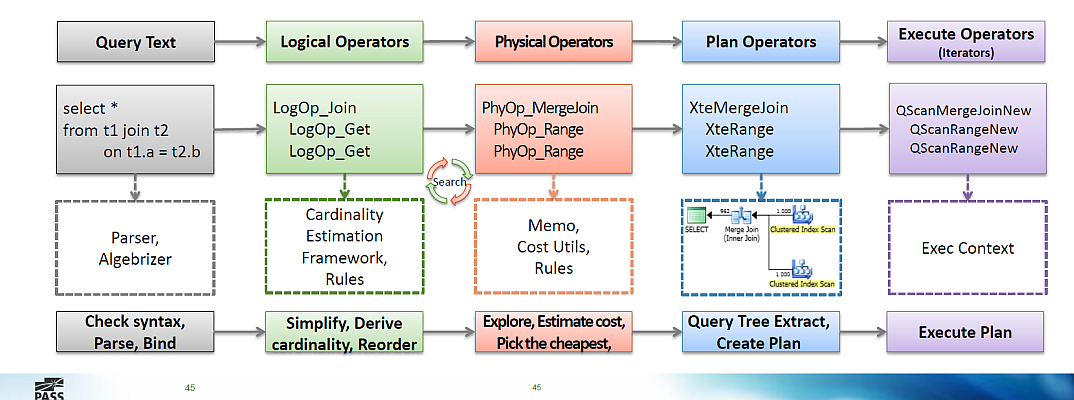
Основные свойства физических соединений:
- Nested Loops Join. Хорош для: универсальный (неблокирующий)
- Nested Loops Apply (вызов функции в цикле). Хорош для: небольшого внешнего набора и индексированного внутреннего набора; быстрое получение небольшой порции данных (TOP, FAST N, EXISTS)
- Merge Join One-To-Many: Хорош для: средних и больших наборов имеющих индекс по ключу соединения и предикат равенства
- Merge Join Many-To-Many: тоже самое, но использует tempdb (поэтому важно, чтобы оптимизатор знал какие столбцы являются уникальными)
- Hash Match. Хорош для: неиндексированные средние и большие наборы; масштабируется при параллельном выполнении
И несколько практических ответов:
- Как быстрее подзапросом или «джойном»? — Не важно, сервер сведёт оба запроса к одному плану (если не используются сложные предикаты)
- Где писать условия в on или where? — Для INNER JOIN это неважно.
- Имеет ли значение порядок написания соединений в запросе? — Нет
- Что лучше, группировка после джойна или джойн сгруппированных значений? — Оптимизатор сам протолкнёт группировку до джойна.
Оптимизация SSAS кубов
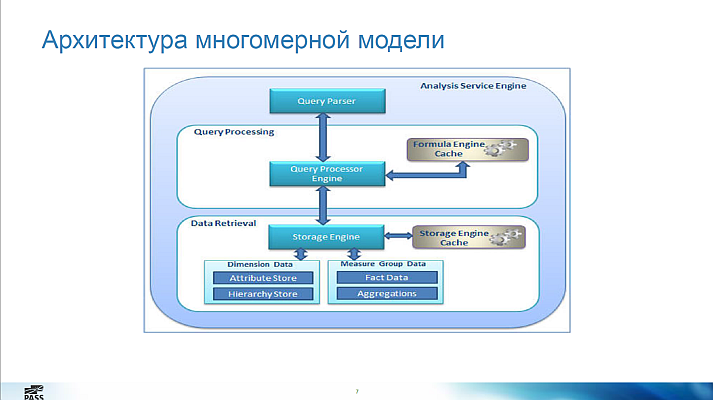
Оптимизация SSAS кубов (multidimension and tabular): возможно ли медленный куб сделать быстрым?
слайды и скрипты — видео
Евгений Полоничко — DWH/BI архитектор, лидер SQL Server User Group Donetsk
Зачем смотреть. Вы уже работаете с OLAP и хотите посмотреть как с этим зверем управляются другие разработчики.
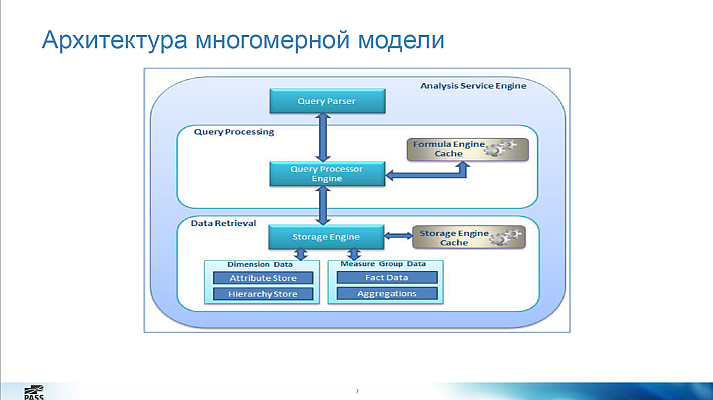
Заметки по докладу
Основные механизмы мониторинга:
На практике полезны:
В кубе можно оптимизировать:
Советы:
- старый добрый SQL Profiler (группа событий QueryProccesing)
- Extended Events (приходящая на замену Profiler технология)
- DMV — системные представления, к которым можно делать запросы
На практике полезны:
- $SYSTEM.DISCOVER_OBJECT_ACTIVITY — статистика использования объектов куба
- $SYSTEM.DISCOVER_OBJECT_MEMORY_USAGE
- $SYSTEM.DISCOVER_SESSIONS — можно найти самого прожорливого клиента
- $SYSTEM.DISCOVER_LOCK
В кубе можно оптимизировать:
- Партиции — делим данные по временным периодам
- Агрегаты
- Настройка параметров куба
- Настройка измерений: отношения и иерархии
- настройка MDX-запросов (перенос расчётов в ETL, отдельный вычисляемый элемент)
Советы:
- использование NonEmpty(), в том числе для оптимизации NON EMPTY
- AttributeHierarchyEnabled = False
- замена LastNonEmpty на LastChild
- скрипт для прогрева кеша после процессинга
- используйте DAX Studio
Оффлайн-разработка баз данных и модульное тестирование с SSDT
слайды — видео видео
Андрей Завадский — SQL, ASP.NET и Sharepoint разработчик из Краснодара
Зачем смотреть. Вы сроднились с Management Studio, но хотите взглянуть как люди используют для SQL-разработки большую Visual Studio.
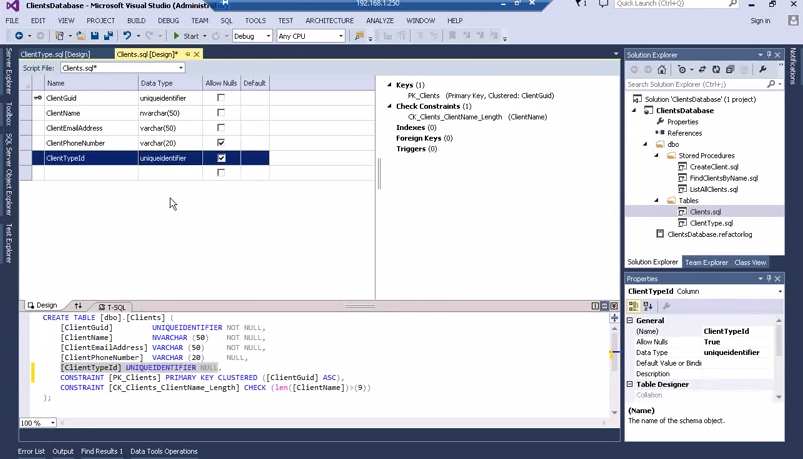
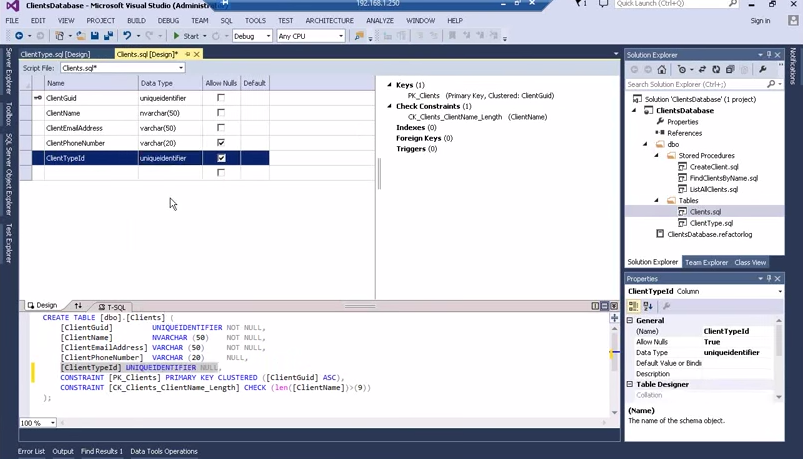
Заметки по докладу
- разделение понятий «сохранить изменения в проекте» и «применить их на сервере»
- скрипт для вставки данных
- инструменты сравнения схемы и данных в проекте и на сервере
- фокус на том, как код должен выглядеть, а не на скриптах преобразований
- готовим DACPAC-файл и отдаём его админу (data-tier application)
- интересный интерфейс создания таблиц — посмотрите 36 минуту видео
- Visual Studio удобна, когда приходится держать рядом код SQL и C#
- есть статический анализатор кода, который будет предупреждать, например, что «SELECT *» — неудачная конструкция
- развёртывание на подключенной базе или развёртывание на отсоединённой базе
- post deployment script
- модульные тесты, например, могут проверить структуру возвращаемого датасета, число его строк
- негативные тесты, проверяющие, что должна появиться именно такая ошибка
BIML — лучший друг для SSIS разработчика
слайды — видео видео
Андрей Коршиков. BI-разработчик, активист PASS, которую он представляет в Восточной Европе, организатор Global Russian Virtual Chapter, обладатель редкой награды PASSion Award.
Зачем смотреть. Вы разрабатываете SSIS-пакеты, хотите вывести разработку на новый уровень, не боитесь нестандартных технологий и не брезгуете генераторами кода.

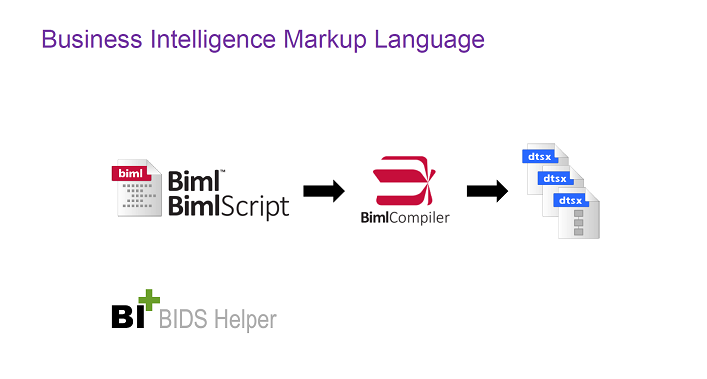
Заметки по докладу
- стандартный SSIS-пакет генерируется из BIML-файла
- работа с BIML происходит через правку XML-файла, но это очень человечный XML, совсем не похож DTSX
- есть подсказки и автодополнение при редактировании
- вставки C# кода (как когда-то встраивали PHP в HTML)
- например, можно сделать цикл по таблицам и колонкам, не описывая каждую отдельно
- удобно генерировать пакеты для однотипных задач
- повторное использование кода
- кто рискнёт использовать это в продакшене?
Azure Data Factory — облачный ETL
слайды — видео видео
Сергей Лунякин — лидер PASS Local Chapter в г. Львов
Зачем смотреть. Посмотреть интерфейсы Azure, познакомиться с новыми терминами (сам продукт ещё сыроват).
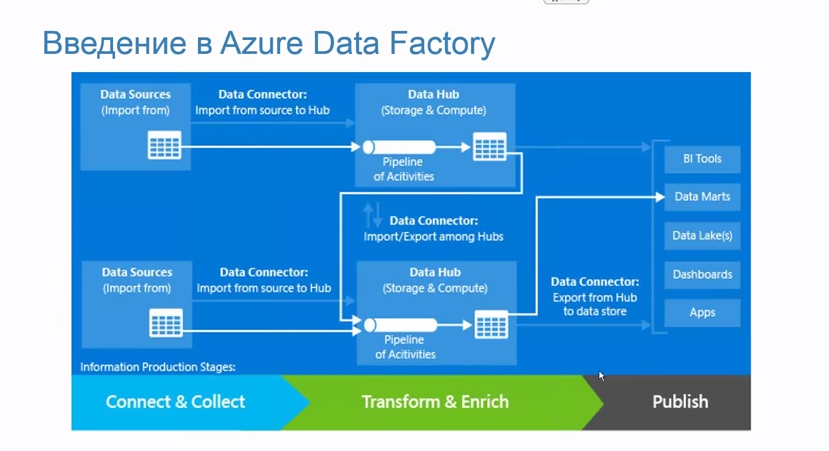
Заметки по докладу
- многие настройки через JSON
- есть неплохие туториалы и лабы от Microsoft
- удобен для совместного использования с Azure Machine Learning
- да и вообще, полезен, когда всё в Azure
- можно установить коннектор для вашей локальной базы
- последние полгода очень активно развивается
- аналог Amazon Data Pipeline
Все что вы хотели узнать о Workspace memory
слайды — видео видео
Мария Закурдаева — основатель PASS Virtual Chapter «Global Hebrew»
Зачем смотреть. Вам хочется узнать как SQL-сервер использует оперативную память, как работают очереди к ресурсам, чем страшно слово «spill». Да, и ещё презентация очень красиво оформлена.

Заметки по докладу
- итераторы, требующие памяти: Sort, Hash Match, Exchange
- для сортировки требуется в 2 раза больше памяти, чем размер сортируемых данных
- пример, как два очень похожих запроса занимают 5 Мб и 108 Мб
- при выполнении запроса память не может быть дозапрошена
- 2 проблемы: недооценка необходимой памяти и расточительное резервирование памяти
- рекомендация использовать Resource Governor
- размер varchar оценивается в половину его длины
- мусорные одноразовые планы могут выесть большой кусок Buffer Pool
Deadlocks 3.0. Final Edition
слайды — видео видео
Денис Резник — MVP и, наверное, главный украинский организатор SQL-сообщества.
Зачем смотреть. После нескольких банальностей об уровнях блокировок, посмотреть разбор действительно сложных и даже невероятных случаев.
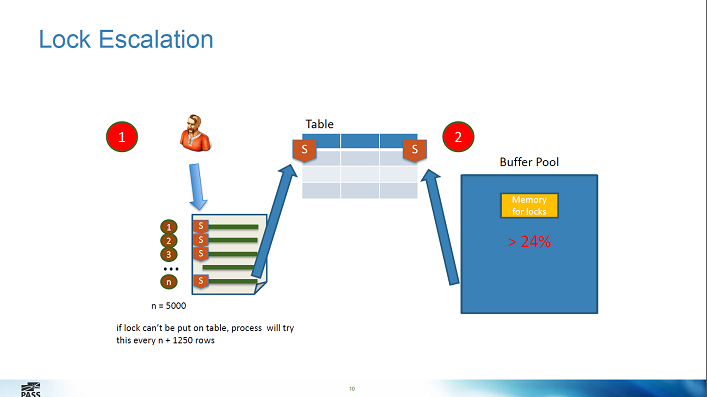
Заметки по докладу
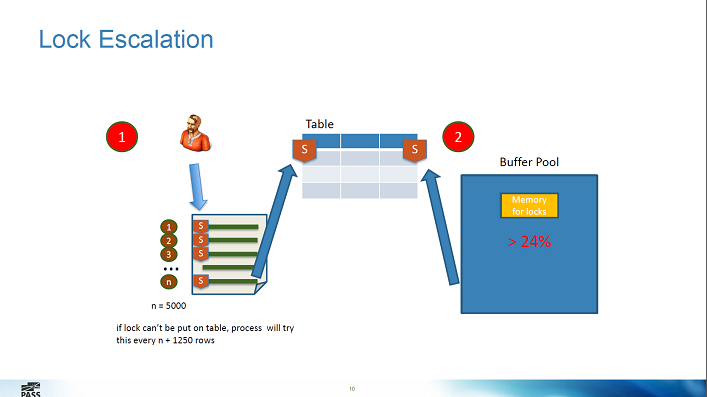
- если изменения затрагивают более 5000 строк, то эскалация блокировки до уровня всей таблицы
- но можно отключить табличные блокировки
- данные из version store не логируются
- хороший пример deadlock между UPDATE и SELECT
- в приложениях не забывать об обработке дедлоков
- нагрузочное тестирование помогает выявить проблемы
Power BI Q&A
слайды — видео видео
Константин Хомяков — MVP, BI-разработчик из Австралии
Зачем смотреть. Запросы к данным на естественном языке — технология новая, ещё не очень популярная, но, говорят, на некоторых заказчиков производит впечатление.
Заметки по докладу
- нужен Office 365 + Power BI
- «сustomers by countries as chart»
- после вывода результата, запрос можно уточнять в обычном интерфейсе
- важны связи между таблицами, хорошие наименования (CustomerName vs strCustNm)
- пока только на английском, но, вроде, делают и китайскую версию
- говорит, что клиенты в восторге, но что-то не верится
- задание синонимов
- подключение к локальным серверам из облака
- коннекторы к Salesforce, Google Analytics
Быстрый анализ производительности SQL Server за 1,5 часа
слайды — видео видео
Кирилл Панов
Зачем смотреть. Убедиться, что вы действительно в курсе всех перечисленных тем. Несколько сумбурный доклад обо всём понемногу.
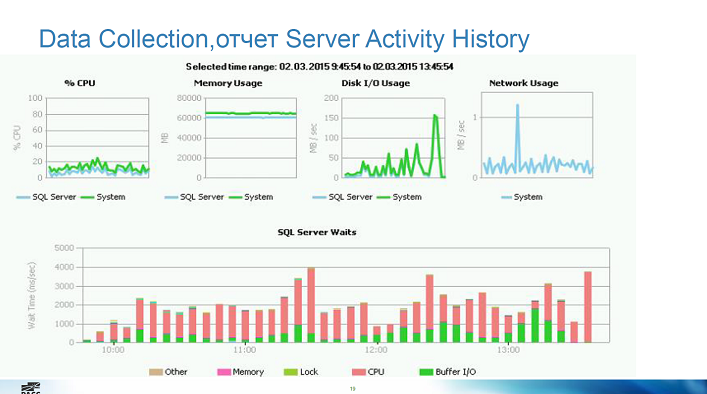
Заметки по докладу
- SARG, кластерный индекс, покрывающий индекс, RCSI и другие банальности
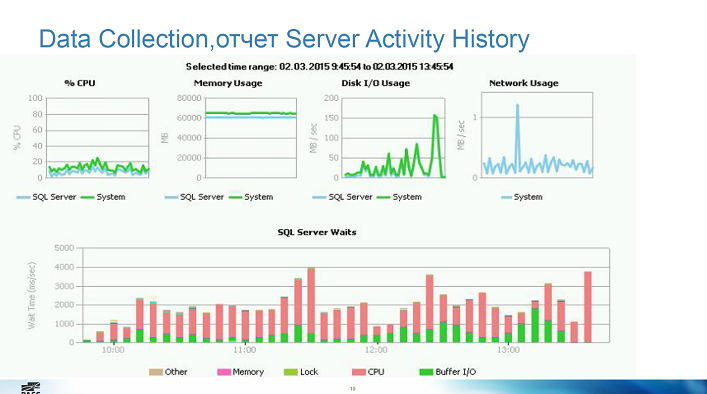
- Paul Randal's wait statistics script
- Data Compression Best Practices — подсчитать процент изменений и сканов
- Data collections и его стандартные отчёты
- попробуйте разложение на UNION вместо OR в WHERE
- пробуйте также разбивать большие запросы на несколько, используя временные таблицы
- скрипт Александра Гладченко для дефрагментации индексов
- 3-х кратное повышение производительности при использовании SORT_IN_TEMPDB=ON
- Блог инженеров технической поддержки SQL Server. Microsoft. Россия
Внутреннее устройство страниц и экстентов SQL Server
слайды — видео видео
Алексей Князев — DWH-специалист, лидер SQL User Group в Екатеринбурге
Зачем смотреть. Если вам нравится разбираться в сути вещей. Очень подробное погружение в структуры хранения, битовые маски, таблицы смещения. Практическая ценность очень ограничена, так как нет возможности как-либо повлиять на описанные механизмы, хотя докладчик и приводит примеры из жизни.
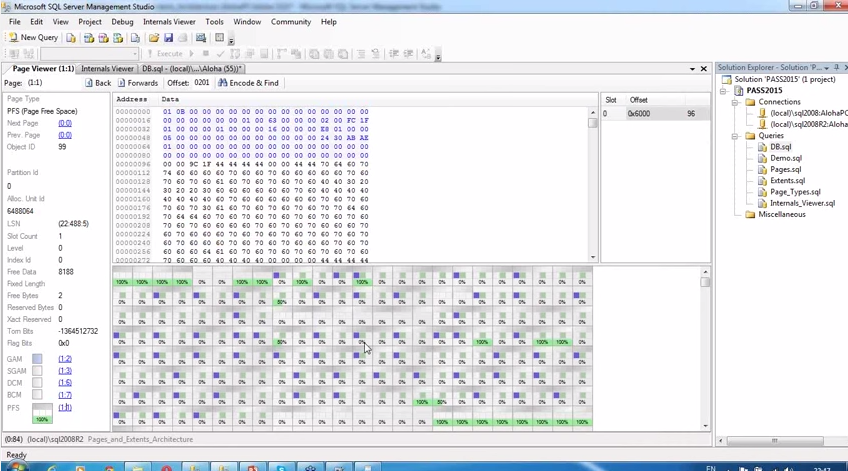
Заметки по докладу
- контрольная сумма рассчитывается только в момент записи на диск
- хранение datetime как двух INT
- Bulk Change Map — отслеживает изменения с неполным протоколированием для бекапа
- Internals Viewer for SQL Server — плагин для визуализации распределения страниц в файле
- Пример: что происходит при изменении колонки NULL на not NULL?
- Пример: что будет, если поля обычного индекса частично повторяют поля кластерного индекса
Тяп-ляп и в продакшн!
слайды — видео видео
Алексей Ковалёв — харьковчанин, автор SQL Code Guard (must have плагин к SSMS).
Зачем смотреть. Если вы не ведёте контроля версий вашей БД и не знаете как подойти к этой задаче.

Заметки по докладу
- делайте всё на скриптах, не используйте магию Reg gate
- хранение и загрузка справочников в виде XML для гибкости
- подстановка переменных, например, «create database [$(dbname)];» и потом запуск как «Sqlcmd -i final.sql -v dbname=MyDB»
- старайтесь писать скрипты так, чтобы их можно было безболезненно запускать на разных исторических версиях вашей БД
- бренчевание по разработчикам или по фичам
И ещё...
Не забывайте про англоязычный 24 hours PASS и Global Russian Virtual Chapter. Следите за анонсами в Facebook.
