
Этот пост — небольшая шпаргалка по mongodb и немного длинных запросов с парой рецептов. Иногда бывает удобно когда какие-то мелочи собраны в одном месте, надеюсь, каждый, кто интересуется mongodb, найдет для себя что-то полезное.
Не хотелось бы, чтобы пост воспринимался в ключе холиваров на тему SQL vs. NOSQL И так понятно что везде есть свои плюсы и минусы, в данном случае это просто где-то немного справки, где-то немного примеров из того, с чем приходилось сталкиваться. Примеры на mongo shell и на python.
- Миграция в на новые версии в mongodb
- Запросы сравнения и логические
- Полнотекстовый поиск в Mongodb, regexp, индексы и пр.
- Атомарные операторы (модифицирующие данные )
- Немного о транзакциях в Mongodb
- Агрегационный фреймворк и JOIN-ы в Mongodb
- Примеры
- Небольшая песочница на Python
Миграция в mongodb
До версии 2.6
После выхода версии 2.6 в mongodb была добавлена новая система назначения прав пользователей на базы, отдельные коллекции. И, соответственно, при обновлении это нужно учитывать.
1) Необходимо переходить с версии 2.4 на версию 2.6. С 2.2 на 2.6 перейти не получится нет обратной совместимости, поэтому нужно поэтапно обновлять.
Собственно, само обновление:
apt-get update
apt-get install mongodb-org2) После того как обновились до 2.6 нужно зайти в базу admin и выполнить несколько команд, которые проверят совместимость документов.
use admin
db.upgradeCheckAllDBs()3) Поскольку c версии 2.6 в mongodb, как уже было сказано, появились разграничения по ролям и выставление прав для любого пользователя вплоть до коллекции на чтение, запись и т.д., то соответственно надо задать эти роли, иначе не сможете выполнить команду auth.
db.auth('admin','password')Для этого вначале надо создать пользователя "Администратор" в базе admin
db.createUser({user:"admin", pwd:"passwd", roles:[{role:"userAdminAnyDatabase", db:"admin"}]})4) После этого зайти в свою нужную базу, с которой собрались работать и к которой хотим подключиться, и создаем там пользователя.
use newdb
db.createUser({user:"admin", pwd:"passwd", roles:[{role:"dbAdmin", db:"newdb"}]})Автоматически запись будет создана в базе admin в коллекции system.users
Просмотреть пользователей базы можно командой:
db.runCommand( { usersInfo: [ { user: "admin", db: "newdb" } ], showPrivileges: true } )Ну и не забываем перегрузить после всего этого.
service mongod restartВ ubuntu c этой версии сервис называется не mongodb а mongod а конфиг в /etc называется mongod.conf скорее всего, это связано с отсутствием обратной совместимости чтобы при обновлении не перепутать.
С 2.6 до 3.0 версии
О новой версии 3.0 и революционных изменениях в движке хранилища было уже написано много, не буду повторяться.
Перед обновлением до 3.0 рекомендуется последовательно обновиться до версии 2.6 не перескакивая. То есть 2.2->2.4->2.6.
Последняя версия рекомендуется не ниже 2.6.5.
Сама установка для ubuntu довольно стандартна
Добавляем репозиторий 3-й версии:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.listДля Ubuntu 15.04
echo "deb http://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.listУстанавливаем:
apt-get update
apt-get install -y mongodb-orgДля каждого компонента указываем версию при установке.
apt-get install -y mongodb-org=3.0.2 mongodb-org-server=3.0.2 mongodb-org-shell=3.0.2 mongodb-org-mongos=3.0.2 mongodb-org-tools=3.0.2После этого:
service mongod stop
service mongod startСмотрим версию mongodb:
root@user-pc:~# mongo
MongoDB shell version: 3.0.2
connecting to: test
> db.version()
3.0.2
> Если версия 3 то все прошло нормально и теперь можно сменить хранилище. По умолчанию стоит MMAPv1.
Для смены в /etc/mongo.conf ставим опцию:
storageEngine = wiredTigerПодробнее про возможные опции связанные с новым хранилищем тут
И смотрим чтоб директория /var/lib/mongodb была пустой иначе mongodb не запустится, естественно перед этим для всех баз нужно сделать mongodump
service mongod restartПроверяем версию движка для хранилища:
root@user-pc:/etc# mongo
MongoDB shell version: 3.0.2
connecting to: test
> db.serverStatus()Ищем storageEngine если wiredTiger то все нормально.
"storageEngine" : {
"name" : "wiredTiger"
}Теперь нужно импортировать базы, включая admin
mongorestore --port 27017 -d admin Новое в PyMongo
Вместе с новой версией базы, вышла новая версия драйвера для Python PyMongo, в ней удалили некоторые устаревшие методы и после:
pip install -U pymongoДаже без обновления самой базы, не все будет работать как прежде. Из того, что сразу было замечено:
- Для универсализации и унификации добавлены методы
update_one, insert_many, find_one_and_deleteподробней в спецификации - Также для унификации был оставлен только один коннектор к базе
MongoClientиз него удалены такие опции как'slave_okay': True.ReplicaSetConnectionиMasterSlaveConnectionтеперь удалены.MongoReplicaSetClientоставлен на какое то время для совместимости.
Пример использования:
>>> # Connect to one standalone, mongos, or replica set member.
>>> client = MongoClient('mongodb://server')
>>>
>>> # Connect to a replica set.
>>> client = MongoClient('mongodb://member1,member2/?replicaSet=my_rs')
>>>
>>> # Load-balance among mongoses.
>>> client = MongoClient('mongodb://mongos1,mongos2')- Удален метод
copy_database - Удален метод
end_request()вместо него рекомендовано использоватьclose() - Часть сообщества ожидала, что будет нативная поддержка асинхронного программирования и
asyncioизpython3, но, к сожалению, увы. Дляtornadoесть неплохой драйвер motor А дляasyncio, к сожалению, остается только экспериментальный драйвер asyncio-mongo слабо развивающийся и с отсутствием поддержкиGridFS
В агрегационном фреймворке теперь сразу возвращается курсор, а не
result.Запросы сравнения и логические
$eq сравнивающий оператор
Оператор $eq эквивалентен db.test.find({ field: <value> })
{ _id: 1, item: { name: "ab", code: "123" }, qty: 15, tags: [ "A", "B", "C" ] }
{ _id: 2, item: { name: "cd", code: "123" }, qty: 20, tags: [ "B" ] }
db.test.find( { qty: { $eq: 20 } } )
#Аналогичен
db.test.find( { qty: 20 } )
db.test.find( { tags: { $eq: [ "A", "B" ] } } )
#Аналогичен выражению:
db.test.find( { tags: [ "A", "B" ] } ) $gt больше чем
$gt выбирает те документы, где значение поля больше (>) указанного значения.
db.test.find( { qty: { $gt: 10 } } )$gte больше или равно чем
$gte выбирает те документы, где значение поля больше или равно (>=) указанного значения.
db.test.find( { qty: { $gte: 10 } } )$lt меньше чем
$lt выбирает те документы, где значение поля меньше (<) указанного
db.test.find( { qty: { $lt: 10 } } )$lte меньше или равно чем
$lte выбирает те документы, где значение поля меньше или равно (<=) указанного
db.test.find( { qty: { $lte: 10 } } )Если прибыль продавца меньше 100, то премия аннулируется.
db.test.update({ "vendor.profit": { $lte: 100 } }, { $set: { premium: 0 } })$ne не равно
$ne выбирает документы, где значение поля не равно (! =) указанному значению.
db.test.find( { qty: { $ne: 10 } } )$in проверка на вхождение
{ _id: 1, qty: 10, tags: [ "name", "lastname" ], }
db.test.find({ tags: { $in: ["name", "lastname"] } } )Пример с регулярным выражением
db.test.find( { tags: { $in: [ /^be/, /^st/ ] } } )$nin проверка на невхождение
Тоже что и $in но наоборот, проверяет, что какое-то значение отсутствует в массиве.
db.test.find( { qty: { $nin: [ 5, 15 ] } } )$or оператор или
Классический оператор или, берет несколько значений и проверяет что условию соответствует хотя бы одно из них.
db.test.find( { $or: [ { quantity: { $lt: 10 } }, { price: 10 } ] } )Для этого запроса предлагается составить два индекса:
db.test.createIndex( { quantity: 1 } )
db.test.createIndex( { price: 1 } )Если $or используется вместе с оператором $text, предназначенным для полнотекстового поиска то индекс должен быть обязательно.
$and оператор "и"
Оператор и проверяет присутствие всех перечисленных значений в искомых документах.
db.test.find( { $and: [ { price:10 }, { check: true } } ]Пример вместе с $or:
db.test.find( {
$and : [
{ $or : [ { price : 50 }, { price : 80 } ] },
{ $or : [ { sale : true }, { qty : { $lt : 20 } } ] }
]
} )$not оператор отрицания
Проверяет чтобы в выборке не было документов, соответствующих условию.
db.test.find( { price: { $not: { $gt: 10 } } } )Пример с регулярным выражением:
import re
for no_docs in db.test.find( { "item": { "$not": re.compile("^p.*") } } ):
print no_docs$nor оператор не или
db.test.find( { $nor: [ { price: 10 }, { qty: { $lt: 20 } }, { sale: true } ] } )Этот запрос в коллекции test найдет те документы в которых:
- Значение поля `price` не равно 10
- Значение поля `qty` не менее 20
- Значение `sale` не `true`
$exists проверка поля на существование
$exists извлекает те документы, в которых определенный ключ присутствует или отсутствует.
Если укажем у $exists в качестве параметра false, то запрос вернет те документы, в которых не определен ключ qty.
db.test.find( { qty: { $exists: true } } )$type проверка BSON типа
db.test.find( { field: { $type: -1 } } );| Тип | Номер | Аннотации |
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | Deprecated. |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
$mod
Оператор $mod используется для выборки полей, значения которых делятся на первый аргумент и остаток от деления равняется второму.
Например, есть документы:
{ "_id" : 1, "item" : "aa123", "qty" : 0 }
{ "_id" : 2, "item" : "bb123", "qty" : 7 }
{ "_id" : 3, "item" : "cc123", "qty" : 15 }Запрос:
db.test.find( { qty: { $mod: [ 5, 0 ] } } )Вернет следующие документы:
{ "_id" : 1, "item" : "aa123", "qty" : 0 }
{ "_id" : 3, "item" : "cc123", "qty" : 15 }Аналог из SQL
select * from t where qty % 5 = 0;C 2.6 версии запрещено передавать только один элемент, будет возращена ошибка. Также, если передать больше трех аргументов, тоже выдаст ошибку, в предыдущих версиях лишние аргументы просто игнорировались.
$all выбрать соответствующие всем
Делает выборку больше чем по одному элементу массива.
db.test.find( { tags: { $all: [ "python", "mongodb", "javascript" ] } } )$elemMatch
Используется когда нужно сравнить два и более атрибутов, принадлежащих одному поддокументу.
Проверяет, что в массиве есть элемент подпадающий под все условия.
{ _id: 1, results: [ 82, 85, 88 ] }
{ _id: 2, results: [ 75, 88, 89 ] }
db.test.find( { results: { $elemMatch: { $gte: 80, $lt: 85 } } } )Получаем результат:
{ _id: 1, results: [ 82, 85, 88 ] }Еще пример:
{ _id: 1, results: [{ product: "abc", score: 10 }, { product: "xyz", score: 5}] }
{ _id: 2, results: [{ product: "abc", score: 8 }, { product: "xyz", score: 7}] }
{ _id: 3, results: [{ product: "abc", score: 7 }, { product: "xyz", score: 8}] }
>db.test.find(
{ results: { $elemMatch: { product: "xyz", score: { $gte: 8 } } } }
)
{ "_id": 3, "results": [{ "product": "abc", "score": 7 }, { "product": "xyz", "score": 8 } ] }$size ищет по длине массива
Оператор $size находит документы, в которых количество элементов массива равно значению $size. Например, извлечем все документы, в которых в массиве laguages два элемента:
db.persons.find ({languages: {$size:2}})Такой запрос будет соответствовать, например, следующему документу:
{"name": "Alex", "age": "32", languages: ["python", "mongodb"]}$ позиционный оператор
$ может использоваться в разных случаях. Когда мы не знаем под каким индексом лежит значение в массиве но хотим его использовать, то применяем "позиционный оператор"
Например, есть документы:
{ "_id" : 3, "semester" : 1, "grades" : [ 85, 100, 90 ] }
{ "_id" : 4, "semester" : 2, "grades" : [ 79, 85, 80 ] }И мы хотим, чтобы после поиска по ним вывелось только одно значение, соответствующее запросу, а не весь документ, но заранее мы не знаем какое значение там стоит.
>db.test.find( { semester: 1, grades: { $gte: 85 } }, { "grades.$": 1 } )
{ "_id" : 3, "grades" : [ 85 ] }Пример для update:
db.test.update( { _id: 22 } , { $set: { "array.$.name" : "alex" } } )$slice находит диапазон
$slice — находит диапазон значений хранящихся в массиве.
Найти первые 10 событий:
db.test.find( { }, { "events" : { $slice: 10 } } )Найти последние 10 событий:
db.test.find( { }, { "events" : { $slice: -10 } } )Полнотекстовый поиск в Mongodb, regexp, индексы и пр.
db.test.createIndex( { title: "text", content: "text" } )Можно использовать название поля или подстановочный спецификатор:
db.text.createIndex( { "$**": "text" } )При создании индекса для полнотекстового поиска надо учитывать язык, если это не английский.
db.test.createIndex( { content : "text" }, { default_language: "russian" } )Начиная с версии 2.6 появилась возможность задания текстового индекса сразу для многих языков.
- da or danish
- nl or dutch
- en or english
- fi or finnish
- fr or french
- de or german
- hu or hungarian
- it or italian
- nb or norwegian
- pt or portuguese
- ro or romanian
- ru or russian
- es or spanish
- sv or swedish
- tr or turkish
MongoDB будет использовать указанный в документе язык при построении индекса. Язык указанный в документе перекрывает язык по умолчанию. Язык во встроенном документе переопределяет все остальные для индекса.
{ _id: 1,
language: "portuguese",
original: "A sorte protege os audazes.",
translation: [
{ language: "english", quote: "Fortune favors the bold." },
{ language: "russian", quote: "Фортуна любит смелых." }
]
}Также, есть возможность с помощью параметра language_override указывать поле с языком.
Например, для документов:
{ _id: 2, idioma: "english", quote: "Fortune favors the bold." }
{ _id: 3, idioma: "russian", quote: "Фортуна любит смелых." }Индекс будет выглядеть таким образом:
db.text.createIndex( { quote : "text" }, { language_override: "idioma" } )Индексу можно назначать специальное имя { name: "name" }, например:
db.text.createIndex( { content: "text", "users.title": "text" }, { name: "text_Index" } )Имя удобно использовать для удаления индексов:
db.text.dropIndex("text_Index")Также, для текстового индекса можно задавать значимость, вес поля для поиска.
Например установим вес для следующих полей: content - 10, keywords - 5, и title - 1.
db.test.createIndex(
{ content: "text", tags: "text", title: "text" },
{ weights: { content: 10, tags: 5, }, name: "TextIndex"}
)Через индекс можно ограничить кол-во записей в выдаче:
{ _id: 1, dept: "one", content: "red" }
{ _id: 3, dept: "one", content: "red" }
{ _id: 2, dept: "two", content: "gren" }
db.test.createIndex( { dept: 1, content: "text" } )
db.test.find( { dept: "one", $text: { $search: "green" } } )На выходе будет только один документ вместо двух, так как мы ограничили в индексе.
Пример индекса для Python:
#PyMongo
db.text.ensure_index( [ ('descr', "text" ), ( 'title.ru', "text" ) ], default_language="russian", name="full_text")Текстовый поиск
Сразу после появления текстового поиска в mongodb он осуществлялся с помощью runCommand например:
db.collection.runCommand( "text", { search: "меч" } )но, начиная с версии 2.6, появился новый оператор $text
Поиск по одному слову:
db.articles.find( { $text: { $search: "coffee" } } )Поиск по нескольким словам:
db.articles.find( { $text: { $search: "bake coffee cake" } } )Поиск по фразе:
db.articles.find( { $text: { $search: "\"coffee cake\"" } } )Исключение поля из поиска через -
db.articles.find( { $text: { $search: "bake coffee -cake" } } )Также с mongodb 2.6 появился еще один оператор $meta, показывающий точность совпадения результата с запросом.
db.text.insert([
{ "_id": 4, "descr" : "новый мировой порядок" },
{ "_id": 3, "descr" : "мы живем в стране такой-то" },
{ "_id":6, "descr" : "новый мировой порядок" },
{ "_id":7, "descr" : "лучшие технологии в мире" },
{ "_id":8, "descr" : "чего все хотят" },
{ "_id":9, "descr" : "страна, в которой мы живем" },
{ "_id":10, "descr" : "город, в котором мы живем" },
{ "_id":11, "descr" : "жизнь проходит своим чередом" }
{ "_id":12, "descr" : "просто хороший порядок" },
{ "_id":13, "descr" : "плохой порядок" },
])
db.text.createIndex( { descr : "text" }, { default_language: "russian" } )
db.text.find( { $text: { $search: "порядок" } }, { score: { $meta: "textScore" } }).sort( { score: { $meta: "textScore" } } )
{ "_id" : 13, "descr" : "плохой порядок", "score" : 0.75 }
{ "_id" : 4, "descr" : "новый мировой порядок", "score" : 0.6666666666666666 }
{ "_id" : 6, "descr" : "новый мировой порядок", "score" : 0.6666666666666666 }
{ "_id" : 12, "descr" : "просто хороший порядок", "score" : 0.6666666666666666 }Тут { score: { $meta: "textScore" } } мы создаем новое поле в его значении содержится результат и дальше оно уже участвует в сортировке.
Поиск через $regex
MongoDB использует Perl-совместимые регулярные выражения.
db.test.insert([
{ "_id" : 1, "descr" : "abc123" },
{ "_id" : 2, "descr" : "abc123" },
{ "_id" : 3, "descr" : "eee789" }
])
db.test.find( { sku: { $regex: /^ABC/i } } )
{ "_id" : 1, "sku" : "abc123", "description" : "Single line description." }
{ "_id" : 2, "sku" : "abc123", "description" : "Single line description." }i — Нечувствительность к регистру.
Аналог из PostgreSQL
select title from article where title ~ '^a'
'abc'Атомарные операторы (модифицирующие данные )
Как правило все эти модификаторы используются для операций обновления в db.test.update() и db.test.findAndModify()
$inc инкремент
Увеличивает или уменьшает поле на заданное значение
db.test.update( { _id: 1 }, { $inc: { qty: -2, "orders": 1 } } )$mul мультипликативный инкремент
Умножает значение поля на заданную величину.
{ _id: 5, item: "mac", price: 10 }
db.test.update({ _id: 1 }, { $mul: { price: 2 } } )
{ _id: 5, item: "mac", price : 20 }$rename переименование поля
{ "_id": 1, "name": "alex" }
db.test.update( { _id: 1 }, { $rename: { 'name': 'alias'} } )
{ "_id": 1, "alias": "alex" }$set изменяет значение полей
Наверно это основной модифицирующий оператор, применяемый вместе с update. Часто о нем вспоминают как о простеньких транзакциях в контексте mongodb.
db.test.save({ "_id":8, "qty":"", tags:"" })
db.test.update( { _id: 8 }, { $set: { qty: 100, tags: [ "linux", "ubuntu"] } })
{ "_id" : 8, "qty" : 100, "tags" : [ "linux", "ubuntu" ] }$setOnInsert добавляет поля в новый документ
В update третьим аргументом идет опция { upsert: true } это значит, что если документ для изменения не найден, то мы создаем новый. А опция $setOnInsert говорит нам какие поля туда вставить.
>db.test.update(
{ _id: 7 }, { $set: { item: "windows" }, $setOnInsert: { os: 'bad' } }, { upsert: true } )
{ "_id" : 7, "item" : "windows", "os" : "bad" }Поле, для которого мы выполняем $set тоже появится в новосозданном документе.
$unset удаляет ключ
{ "_id" : 8, "qty" : 100, "tags" : [ "linux", "ubuntu" ] }
db.test.update( { _id: 8 }, { $unset: { qty: "", tags: "" } } )
{ "_id" : 8 }$min обновляет, если меньше
$min обновляет поле, если указанное значение меньше текущего значения поля, $min может сравнивать значения различных типов.
> db.test.save({ _id: 9, high: 800, low: 200 })
> db.test.update( { _id:9 }, { $min: { low: 150 } } )
>db.test.findOne({_id:9})
{ "_id" : 9, "high" : 800, "low" : 150 }$max обновляет если больше
$max обновляет поле, если указанное значение больше текущего значения поля.
> db.test.save({ _id: 9, high: 800, low: 200 })
> db.test.update( { _id:9 }, { $max: { high: 900 } } )
> db.test.findOne({_id:9})
{ "_id" : 9, "high" : 900, "low" : 200 }$currentDate устанавливает текущую дату
Устанавливает значением поля текущую дату.
> db.test.save({ _id:11, status: "init", date: ISODate("2015-05-05T01:11:11.111Z") })
> db.test.update( { _id:12 }, { $currentDate: { date: true } } )
> db.test.findOne({_id:12})
{ "_id" : 12, "status" : "a", "date" : ISODate("2015-05-10T21:07:31.138Z") }Изменения массивов
$addToSet добавляет значение, если его нет
Добавляет значение в массив, если его там еще нет, а если есть, то ничего не делает.
db.test.save({ _id:1, array: ["a", "b"] })
db.test.update( { _id: 1 }, { $addToSet: {array: [ "c", "d" ] } } )
{ "_id" : 1, "array" : [ "a", "b", [ "c", "d" ] ] }
db.test.update( { _id: 1 }, { $addToSet: {array: "e" } } )
{ "_id" : 1, "array" : [ "a", "b", [ "c", "d" ], "e" ] }$pop удаляет 1-й или последний
Удаляет первый или последний элемент массива. Если указано -1 то удалит первый элемент, если указано 1, то последний.
> db.test.save({ _id: 1, scores: [ 6, 7, 8, 9, 10 ] })
{ "_id" : 1, "scores" : [ 6, 7, 8, 9, 10 ] }
> db.test.update( { _id: 1 }, { $pop: { scores: -1 } } )
> db.test.findOne({_id:1})
{ "_id" : 1, "scores" : [ 7, 8, 9, 10 ] }
> db.test.update( { _id: 1 }, { $pop: { scores: 1 } } )
> db.test.findOne({_id:1})
{ "_id" : 1, "scores" : [ 7, 8, 9 ] }$pullAll удаляет все указанные
Удаляет все указанные элементы из массива.
{ _id: 1, scores: [ 0, 2, 5, 5, 1, 0 ] }
db.test.update( { _id: 1 }, { $pullAll: { scores: [ 0, 5 ] } } )
{ "_id" : 1, "scores" : [ 2, 1 ] }$pull удаляет в соответствии с запросом
{ _id: 1, votes: [ 3, 5, 6, 7, 7, 8 ] }
> db.test.update( { _id: 1 }, { $pull: { votes: { $gte: 6 } } } )
{ _id: 1, votes: [ 3, 5 ] }$push добавляет значения
Добавляет значения в массив.
db.test.update( { _id: 1 }, { $push: { scores: 100} } )$pushAll — считается устаревшим
Модификаторы для $push
$each сразу много
Добавляет каждый из перечисленных элементов в массив
Например если мы сделаем так: { $push: { scores: [ 2, 10 ] } }
То на выходе получится такой массив: "scores" : [7, 8, 9, 90, 92, 85, [ 2, 10 ] ]
то есть добавился еще один элемент являющийся массивом.
А если через $each, то добавится каждый элемент списка как элемент массива:
> db.test.update( { _id: 1 }, { $push: {scores: { $each: [ 90, 92, 85 ] } } } )
{"_id" : 1, "scores" : [7, 8, 9, 90, 92, 85, 2, 10 ] }$slice ограничивает количество элементов при использовании $push
Ограничивает количество элементов массива при вставке с помощью $push. Обязательно использует $each если попытаться без него использовать, то вернет ошибку.
{ "_id" : 1, "scores" : [ 10, 20, 30 ] }
> db.test.update( { _id: 1 }, { $push: { scores: { $each: [50, 60, 70], $slice: -5 } } } )
{ "_id" : 1, "scores" : [ 20, 30, 50, 60, 70 ] }$slice отрезал первый элемент 20. если бы мы указали не -5 а 5 то он бы откинул последний элемент 70.
$sort сортировка элементов массива
Сортирует элементы массива в соответствии с указанным полем. Также обязательно использовать с оператором $each. Если нужно просто отсортировать без вставки, то $each можно оставить пустым.
{ "_id" : 2, "tests" : [ 80, 70, 80, 50 ] }
> db.test.update( { _id: 2 }, { $push: { tests: { $each: [40, 60], $sort: 1 } } })
{ "_id" : 2, "tests" : [ 40, 50, 60, 70, 80, 80 ] }Еще пример:
db.test.update( { _id: 1 }, { $push: { field: { $each: [ ], $sort: { score: 1 } } } })
{ "_id" : 1, "field" : [
{ "id" : 3, "score" : 5 },
{ "id" : 2, "score" : 6 },
{ "id" : 1, "score" : 7 },
]
}$position указывает позицию вставки
Указывает с какого по счету элемента массива вставить значения.
{ "_id" : 1, "scores" : [ 100 ] }
db.test.update({ _id: 1 }, {$push: { scores: { $each: [50, 60, 70], $position: 0 } } })
{ "_id" : 1, "scores" : [ 50, 60, 70, 100 ] }$bit побитово обновляет
Выполняет побитовое обновление поля. Оператор поддерживает побитовые and, or и xor.
{ "_id" : 1, "expdata" : 13 }
> db.bit.update({_id:1}, {$bit:{expdata:{and:NumberInt(10)} } } )
{ "_id" : 1, "expdata" : 8 }$isolated — атомизация
Блокирует документ для чтения и записи, пока с ним происходит, например, операция обновления.
Использование $isolated при удалении:
db.test.remove( { temp: { $lt: 10 }, $isolated: 1 } )Использование $isolated при обновлении:
db.test.update( {status: "init" , $isolated: 1 }, { $inc: { count : 1 }}, {multi: true } )$isolated не работает с шардированными кластерами
С версии 2.2: оператор $isolated заменил $atomic
О транзакциях в mongodb, уникальный индекс, двухфазный коммит
Естественно таких транзакций как в классических SQL решениях типа PostgreeSQL в MongoDB нет и наверно не может быть. А если появится, то это будет уже, скорее, реляционная база данных с полноценной нормализацией и контролем целостности.
Поэтому, говоря о транзакциях в mongoDB, как правило, имеют в виду атомарные операции типа $set, применяемые в update() и findAndModify() в сочетании с уникальным индексом. А также двухфазный коммит, который распространен среди реляционных баз данных, если нужно обеспечить транзакции в пределах нескольких баз.
Уникальный индекс
Уникальный индекс в mongodb является причиной отклонить все документы, которые содержат повторяющиеся значения для индексированных полей.
db.test.createIndex( { "user_id": 1 }, { unique: true } )Есть коллекция, назовем её test, в этой коллекции нет документов у которых поле name имело бы значение Nik. Предположим, что сразу несколько клиентов одновременно пытается обновить этот документ с параметром { upsert: true } (означает, что если по условию нет такого документа для обновления, то его нужно создать).
Пример:
db.test.update( { name: "Nik" }, { name: "Nik", vote: 1 }, { upsert: true } )Если все операции update() успешно выполнили запрос и нашли обновляемый документ прежде, чем любой из клиентов вставит свои данные, и нет уникального индекса на поле, то все операции обновления могут вставить данные.
Для предотвращения вставки в один и тот же документ несколько раз, нужно создать уникальный индекс на поле. Тогда одна из операций обновлений точно вставит новый документ. Остальные операции либо обновят недавно вставленный документ, либо не смогут выполнить операцию если попытаются вставить дублирующие значения.
По умолчанию unique является false в индексах MongoDB
Двухфазный коммит
Рассмотрим пример из документации, операцию по переводу денежных средств со счета A на счет B.
У нас в примере есть две коллекции:
- Коллекция `accounts` где будут хранится счета с которыми мы будем проводить операции.
- И коллекция `transactions` где будут хранится информация о переводе средств, можно сказать информация о транзакциях.
Инициализация коллекций accounts и transactions
Вставляем в коллекцию accounts два документа соответственно для счетов А и В
db.accounts.insert(
[
{ _id: "A", balance: 1000, pendingTransactions: [] },
{ _id: "B", balance: 1000, pendingTransactions: [] }
]
)В коллекцию transactions для каждого перевода средств вставляем документ с информацией о транзакции.
db.transactions.insert({ _id: 1, source: "A", destination: "B", value: 100, state: "initial", lastModified: new Date()})Где у нас есть следующие поля:
- Поля
sourceиdestinationобозначают исходящий счет и счет на который мы будем переводить средства. - Поле
value, определяет сумму которую будут переводить со счета на счет. - Поле
stateбудет сигнализировать о текущем статусе операции. Может иметь следующие состоянияinitial,pending,applied,done,canceling, иcanceled. lastModifiedполе в котором будет хранится время последней модификации.
1) Получение документа с транзакцией
Получаем документ с транзакцией, имеющей статус initial. И присваиваем его переменной t
> var t = db.transactions.findOne( { state: "initial" } )
> t
{ "_id" : 1, "source" : "A", "destination" : "B", "value" : 100, "state" : "initial", "lastModified" : ISODate("2015-05-26T16:35:54.637Z") }2) Обновление статуса транзакции до состояния pending
Меняем состояние нужной транзакции с initial на pending и устанавливаем текущую дату.
> db.transactions.update(
{ _id: t._id, state: "initial" },
{ $set: { state: "pending" }, $currentDate: { lastModified: true } }
)
> db.transactions.find()
{ "_id" : 1, "source" : "A", "destination" : "B", "value" : 100, "state" : "pending", "lastModified" : ISODate("2015-05-26T17:02:19.002Z") }
> 3) Изменение обоих счетов
Изменяем баланс у обоих документов средства, одному увеличиваем на количество, равное полю value из документа транзакции, а в поле pendingTransactions заносим _id транзакции (документа где хранится информация о транзакции).
> db.accounts.update(
{ _id: t.source, pendingTransactions: { $ne: t._id } },
{ $inc: { balance: -t.value }, $push: { pendingTransactions: t._id } }
)
> db.accounts.update(
{ _id: t.destination, pendingTransactions: { $ne: t._id } },
{ $inc: { balance: t.value }, $push: { pendingTransactions: t._id } }
)
> db.accounts.find()
{ "_id" : "A", "balance" : 900, "pendingTransactions" : [ 1 ] }
{ "_id" : "B", "balance" : 1100, "pendingTransactions" : [ 1 ] }4) Обновление транзакции до состояния applied
Обновляем документ с транзакцией и не забываем установить дату последнего изменения.
> db.transactions.update(
{ _id: t._id, state: "pending" },
{ $set: { state: "applied" }, $currentDate: { lastModified: true } }
)
> db.transactions.find()
{ "_id" : 1, "source" : "A", "destination" : "B", "value" : 100, "state" : "applied", "lastModified" : ISODate("2015-05-26T17:13:15.517Z") }5) Удаление _id транзакции из обоих документов
Находим оба документа в том числе по условию pendingTransactions: _id транзакции и очищаем у них поле pendingTransactions.
> db.accounts.update(
{ _id: t.source, pendingTransactions: t._id },
{ $pull: { pendingTransactions: t._id } }
)
> db.accounts.update(
{ _id: t.destination, pendingTransactions: t._id },
{ $pull: { pendingTransactions: t._id } }
)
> db.accounts.find()
{ "_id" : "A", "balance" : 900, "pendingTransactions" : [ ] }
{ "_id" : "B", "balance" : 1100, "pendingTransactions" : [ ] }
6) Обновление транзакции до состояния done
На этом двухфазный коммит завершён.
> db.transactions.update(
{ _id: t._id, state: "applied" },
{ $set: { state: "done" }, $currentDate: { lastModified: true } }
)
> db.transactions.find()
{ "_id" : 1, "source" : "A", "destination" : "B", "value" : 100, "state" : "done", "lastModified" : ISODate("2015-05-26T17:22:22.194Z") }Откат двухфазного коммита
Теперь рассмотрим случай если у нас остались несработавшие транзакции. В этом случае нам надо вернутся обратно и завершить.
1) Устанавливаем состояние транзакции canceling
Находим все документы, которые были в ожидании, и устанавливаем состояние canceling.
db.transactions.update(
{ _id: t._id, state: "pending" },
{$set: { state: "canceling" }, $currentDate: { lastModified: true }}
)
> db.transactions.find()
{ "_id" : 1, "source" : "A", "destination" : "B", "value" : 100, "state" : "canceling", "lastModified" : ISODate("2015-05-26T18:29:28.018Z") }2) Отменяем транзакцию для обоих счетов
Возвращаем средства обратно на счет с которого переводили.
> db.accounts.update(
{ _id: t.destination, pendingTransactions: t._id },
{ $inc: { balance: -t.value }, $pull: { pendingTransactions: t._id } }
)
> db.accounts.update(
{ _id: t.source, pendingTransactions: t._id },
{ $inc: { balance: t.value}, $pull: { pendingTransactions: t._id } }
)
> db.accounts.find()
{ "_id" : "A", "balance" : 1000, "pendingTransactions" : [ 1 ] }
{ "_id" : "B", "balance" : 1000, "pendingTransactions" : [ 1 ] }
> 3) Устанавливаем состояние транзакции cancelled
Обновляем состояние с отменяемой до отмененной.
db.transactions.update(
{ _id: t._id, state: "canceling" },
{ $set: { state: "cancelled" }, $currentDate: { lastModified: true } }
)
> db.transactions.find()
{ "_id" : 1, "source" : "A", "destination" : "B", "value" : 100, "state" : "cancelled", "lastModified" : ISODate("2015-05-26T19:14:11.830Z") }Двухфазный коммит и много приложений
Когда выполняются несколько приложений, важно чтобы только одно приложение обращалось к транзакции в одно и тоже время. Поэтому дополнительно нужно чтобы документ кроме состояния хранил еще и идентификатор приложения.
Также рекомендуется использовать метод findAndModify(), чтобы изменить транзакцию и получить документ с ней обратно в один шаг:
t = db.transactions.findAndModify({
query: { state: "initial", application: { $exists: false } },
update: {$set: { state: "pending", application: "App1"}, $currentDate:{ lastModified: true }},
new: true
})6. Агрегационный фреймворк и JOIN-ы
Когда говорят про JOIN-ы в mongo или спрашивают про них, почему-то часто речь заходит о связывании отдельных коллекций. Часто такие подобные вопросы мелькают на stackoverflow, но следует понимать, что это невозможно.
И, как правило, всегда рекомендуется документы, которые могут участвовать в одном запросе, помещать в одну коллекцию.
А если потом есть желание разбить их на какие-то группы по определённым признакам, то различать их по одному из полей, например { type: 'news' }.
Но бывают случаи когда действительно надо взять несколько документов, у которых нет практически ничего общего, и объединить их в один документ.
К сожалению, простого пути в данном случае нет и нужно делать либо несколько запросов, либо лепить довольно длинную цепочку в aggregation framework. Но на этом примере можно хорошо понять как работает pipeline. Вообще, это очень удобная штука, можно взять выборку документов и проделывать с ними любые операции, объединять, разбивать, группировать и т.д.
Предположим, у нас есть две разновидности документов, в одной находятся пользователи и перечисляется группы к которым они относятся.
db.test.insert([
{ "_id":"gomer", "type":"user", "group":["user", "author"] },
{ "_id":"vasya", "type":"user", "group":["user"] }
])И есть документы в которых находятся статьи написанные этими пользователями.
db.test.insert([
{ "_id": 1, "type": "blogs", "user": "gomer", "article": "aaa" },
{ "_id": 2, "type": "blogs", "user": "vasya", "article": "bbb" },
{ "_id": 3, "type": "blogs", "user": "gomer", "article": "ccc" }
])Задача получить на выходе в одном документе пользователя, статьи которые он написал и группы в которых состоит. Конечно если бы мы это делали несколькими запросами, то все выглядело довольно просто.
Выбрать из блогов только те статьи, где пользователь, опубликовавший материал, состоит в группе "автор".
users = [doc._id for doc in db.test.find({"type":'user', 'group': {'$all': ['author']}})]
articles = db.test.find({"type": "blogs", "user": {'$in': users})Примерный аналог c джойном из SQL если мы членство в группах храним в таблице:
SELECT
blogs.*
FROM
blogs, user, usergroup, group
WHERE
blogs.user = user.id AND usergroup.user = user.id AND usergroup.group = group.id AND group.name = 'author';Или если мы названия групп храним прямо в таблице user, если всё хранится в поле d типа jsonb. Селектами делается два списка — и дальше на них накладываются ровно те же условия:
SELECT blogs.*
FROM blogs, user
WHERE blogs.user = user.id AND user.group ? 'author';
SELECT blogs.*
FROM
(SELECT * FROM test WHERE d->type = 'blogs') blogs,
(SELECT * FROM test WHERE d->type = 'user') user
WHERE blogs.d->user = user.id AND user.d->group ? 'author';Теперь попробуем повторить примерно то же самое с помощью pipe.
db.test.aggregate([
{ $match: { $or: [ {type: "blogs"}, {type: "user"} ] } },
{ $project: {
a: 1,
blogs: {
$cond: {
if: { type: '$blogs'},
then: {_id:"$_id", user:"$user", article:"$article"},
else: null
}
},
user: {
$cond: {
if: { type: '$user' },
then: { _id:"$_id", group:"$group"},
else: null
}
}
}
},
{ $group : {
_id : { a: "$a" },
user: { $push: "$user" },
blog: { $push: "$blogs" },
}
},
{ $unwind : "$blog" },
{ $unwind : "$user" },
{ $project:{
user: "$user",
article: "$blog",
matches: { $eq:[ "$user._id", "$blog.user" ] } }
},
{ $match: { matches: true } }
])Теперь разберем по порядку что делает запрос. Запрос состоит из 7 частей.
Как правило, в справке по mongodb и статьях про pipeline приводят эту табличку. Она не совсем отражает смысл каждого оператора, но, имея её перед глазами, немного помогает ориентироваться в длинных цепочках, ну и не забывать, что порядок может быть абсолютно любой и повторяться каждый оператор может много раз.
| SQL Terms, Functions, and Concepts | MongoDB Aggregation Operators |
|---|---|
| WHERE | $match |
| GROUP BY | $group |
| HAVING | $match |
| SELECT | $project |
| ORDER BY | $sort |
| LIMIT | $limit |
| SUM() | $sum |
| COUNT() | $sum |
| join | предлагают использовать оператор $unwind |
Сначала мы находим все документы с которыми будем работать.
> db.ag.aggregate([ { $match: {$or:[{type:"blogs"},{type:"user"}]} } ])
{ "_id" : "gomer", "type" : "user", "group" : [ "user", "author" ] }
{ "_id" : "vasya", "type" : "user", "group" : [ "user" ] }
{ "_id" : 1, "type" : "blogs", "user" : "gomer", "article" : "aaa" }
{ "_id" : 2, "type" : "blogs", "user" : "vasya", "article" : "bbb" }
{ "_id" : 3, "type" : "blogs", "user" : "gomer", "article" : "ccc" }Сам по себе оператор $match похож на find(), единственное его преимущество в том, что он может встраивается в цепочку.
Дальше c помощью $project мы формируем новые документы, с основными полями blogs и users. Там мы используем появившийся с версии 2.6 оператор $cond который позволяет писать внутри себя логические выражения. Проверяем тип документа и уже по результату формируем поля blogs и users, чтобы потом было удобно группировать.
db.test.aggregate([
{ $match: {$or:[ { type:"blogs"}, { type: "user"} ] } },
{ $project: {
a: 1,
blogs: {
$cond: {
if: {type: '$blogs'},
then: {_id:"$_id", user:"$user", article:"$article"},
else: null
}
},
user: {
$cond: {
if: { type: '$user'},
then: {_id:"$_id", group:"$group"},
else: null
}
}
}
}
])
{ "_id": "gomer", "blogs": { "_id" : "gomer" }, "user": { "_id": "gomer", "group": [ "user", "author" ] } }
{ "_id": "vasya", "blogs": { "_id" : "vasya" }, "user" : { "_id" : "vasya", "group": [ "user" ] } }
{ "_id": 1, "user": { "_id": 1 }, "blogs" : { "_id": 1, "user": "gomer", "article": "aaa" } }
{ "_id": 2, "user": { "_id": 2 }, "blogs" : { "_id": 2, "user": "vasya", "article": "bbb" } }
{ "_id": 3, "user": { "_id": 3 }, "blogs" : { "_id": 3, "user": "gomer", "article": "ccc" } }Следующим этапом группируем эти документы:
...{ $group : {
_id : { a: "$a" },
user: { $push: "$user" },
blog: { $push: "$blogs" },
}
}...
{
"_id" : { "a" : null },
"user": [
{ "_id": "gomer", "group": [ "user", "author" ] }, { "_id": "vasya", "group": [ "user" ] },
{ "_id": 1 }, { "_id": 2 }, { "_id": 3 }
],
"blog": [
{ "_id": "gomer" }, { "_id": "vasya" }, { "_id": 1, "user": "gomer", "article": "aaa" },
{ "_id": 2, "user": "vasya", "article": "bbb" }, { "_id": 3, "user": "gomer", "article": "ccc"}
]
}....{ $unwind : "$blog" },
{ $unwind : "$user" } ....
{ "_id": { "a":null }, "user": { "_id": "gomer", "group": [ "user", "author" ] }, "blog": { "_id": "gomer" } }
{ "_id": { "a":null }, "user": { "_id": "vasya", "group": [ "user" ] }, "blog" : { "_id": "gomer" } }
{ "_id": { "a":null }, "user": { "_id": 1 }, "blog": { "_id" : "gomer" } }
{ "_id": { "a" : null }, "user" : { "_id" : 2 }, "blog" : { "_id" : "gomer" } }
{ "_id": { "a" : null }, "user" : { "_id" : 3 }, "blog" : { "_id" : "gomer" } }
{ "_id": { "a": null }, "user": { "_id": "gomer", "group" : [ "user", "author" ] }, "blog": { "_id": "vasya"}}
{ "_id": { "a" : null }, "user" : { "_id" : "vasya", "group" : [ "user" ] }, "blog" : { "_id" : "vasya" } }
{ "_id": { "a" : null }, "user" : { "_id" : 1 }, "blog" : { "_id" : "vasya" } }
{ "_id": { "a" : null }, "user" : { "_id" : 2 }, "blog" : { "_id" : "vasya" } }
{ "_id": { "a" : null }, "user" : { "_id" : 3 }, "blog" : { "_id" : "vasya" } }
{ "_id": { "a" : null }, "user" : { "_id" : "gomer", "group" : [ "user", "author" ] }, "blog" : { "_id" : 1, "user": "gomer", "article" : "aaa" } }
{ "_id": { "a" : null }, "user": { "_id" "vasya", "group": [ "user" ] }, "blog": { "_id": 1, "user": "gomer", "article": "aaa" } }
{ "_id": { "a" : null }, "user" : { "_id" : 1 }, "blog" : { "_id" : 1, "user" : "gomer", "article" : "aaa" } }
{ "_id" : { "a" : null }, "user" : { "_id" : 2 }, "blog" : { "_id" : 1, "user" : "gomer", "article" : "aaa" } }
{ "_id": { "a" : null }, "user" : { "_id" : 3 }, "blog" : { "_id" : 1, "user" : "gomer", "article" : "aaa" } }
{ "_id": { "a" : null }, "user" : { "_id" : "gomer", "group" : [ "user", "author" ] }, "blog" : { "_id" : 2, "user": "vasya", "article" : "bbb" } }
{ "_id": { "a" : null }, "user" : { "_id" : "vasya", "group" : [ "user" ] }, "blog" : { "_id" : 2, "user" : "vasya", "article" : "bbb" } }
{ "_id": { "a" : null }, "user" : { "_id" : 1 }, "blog" : { "_id" : 2, "user" : "vasya", "article" : "bbb" } }
{ "_id": { "a" : null }, "user" : { "_id" : 2 }, "blog" : { "_id" : 2, "user" : "vasya", "article" : "bbb" } }
{ "_id": { "a" : null }, "user" : { "_id" : 3 }, "blog" : { "_id" : 2, "user" : "vasya", "article" : "bbb" } }Еще раз создаем новые документы, где главным является условие $eq:[ "$user._id", "$blog.user" ] в котором мы сравнивая значения двух полей "user" : { "_id" : 2 } и "blog" : { "user" : "vasya" } и маркируем документы которые в последствии будут отфильтрованы и получен окончательный результат.
...{ $project:{
user:"$user",
article:"$blog",
matches:{ $eq:[ "$user._id", "$blog.user" ] } }
} .....{ "_id" : { "a" : null }, "user" : { "_id" : 1 }, "article" : { "_id" : 1, "user" : "gomer", "article" : "aaa" }, "matches" : false }
{ "_id" : { "a" : null }, "user" : { "_id" : 2 }, "article" : { "_id" : 1, "user" : "gomer", "article" : "aaa" }, "matches" : false }
{ "_id" : { "a" : null }, "user" : { "_id" : 3 }, "article" : { "_id" : 1, "user" : "gomer", "article" : "aaa" }, "matches" : false }
{ "_id" : { "a" : null }, "user" : { "_id" : "gomer", "group" : [ "user", "author" ] }, "article" : { "_id" : 2, "user" : "vasya", "article" : "bbb" }, "matches" : false }
{ "_id" : { "a" : null }, "user" : { "_id" : "vasya", "group" : [ "user" ] }, "article" : { "_id" : 2, "user" : "vasya", "article" : "bbb" }, "matches" : true }
{ "_id" : { "a" : null }, "user" : { "_id" : 1 }, "article" : { "_id" : 2, "user" : "vasya", "article" : "bbb" }, "matches" : false }
{ "_id" : { "a" : null }, "user" : { "_id" : 2 }, "article" : { "_id" : 2, "user" : "vasya", "article" : "bbb" }, "matches" : false }
{ "_id" : { "a" : null }, "user" : { "_id" : 3 }, "article" : { "_id" : 2, "user" : "vasya", "article" : "bbb" }, "matches" : false }
Type "it" for moreИ завершающая часть:
{ $match: { matches:true } }{ "_id": { "a": null }, "user": { "_id": "gomer", "group": [ "user", "author" ] }, "article": { "_id": 1, "user": "gomer", "article": "aaa" }, "matches": true }
{ "_id": { "a": null }, "user": { "_id": "vasya", "group": [ "user" ] }, "article": { "_id": 2, "user": "vasya", "article": "bbb" }, "matches": true }
{ "_id": { "a": null }, "user": { "_id": "gomer", "group": [ "user", "author" ] }, "article": { "_id": 3, "user": "gomer", "article": "ccc" }, "matches": true }
Мы просто отфильтруем те документы, которые соответствовали предыдущему условию.
И теперь у нас есть документы, в которых указано какую статью написал каждый пользователь и в какой пользовательской группе он состоит.
Конечно, запрос можно было бы написать немного компактней но задачей было показать как можно играться с данными посредством pipeline.
7. Примеры
В основном здесь речь пойдет, скорее, о структуре документов чем о запросах. Как правило есть два основных подхода обычно:
- Хранение предполагаемых поддокументов или просто полей, по которым будет поиск осуществляться внутри корневого или основного документа.
- Хранение отдельно, по возможности стараясь как можно больше заносить в них дополнительной информации.
Деревья, комментарии в Mongodb
Как правило, одна из самых распространенных задач — это различные древовидные структуры. Это и комментарии, и каталог товаров в интернет магазинах, и схемы хранения на складах, и много чего еще.
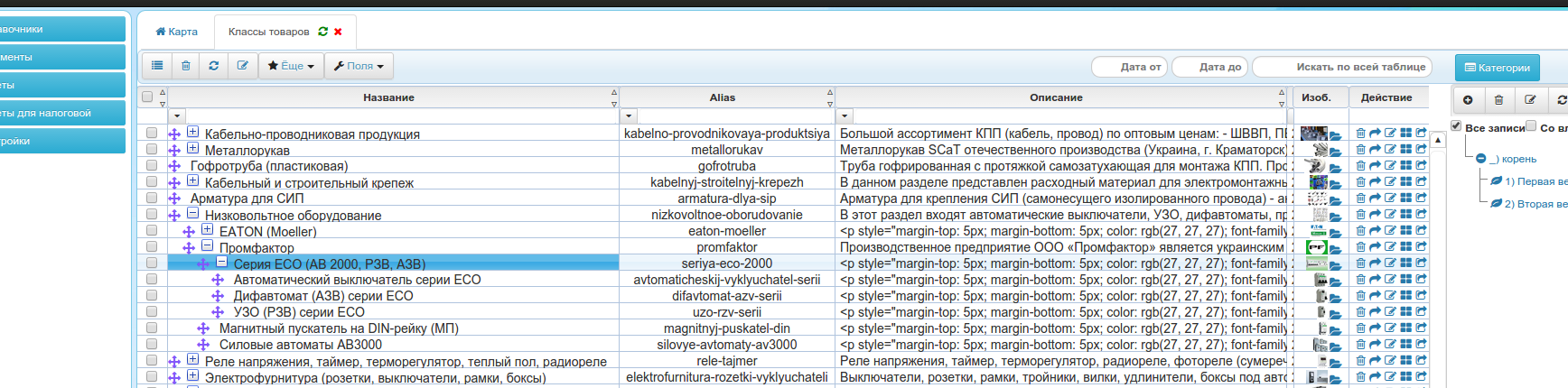
Рассмотрим пару простых примеров.
В виде субдокументов:
{
_id:1, type:"blog", title:{ru:"O MongoDB", en:""},
comments: [
{ _id: 1, title: "one", "user": "Alex", parent: "root", child: [2, 3]},
{ _id: 2, title: "two", "user": "Serg", parent: 1 },
{ _id: 3, title: "two", "user": "Andrey", parent: 1 }
]
}Просто документы:
{ _id: 1, type: "comment", title: "one", "user": "Alex", parent: "root", child: [ 2, 3 ] },
{ _id: 2, type: "comment", title: "two", "user": "Serg", parent: 1 },
{ _id: 3, type: "comment", title: "two", "user": "Andrey", parent: 1 }Сам по себе простой поиск по обоим вариантам будет работать достаточно эффективно.
Тем более, что по второму варианту можно создать индексы.
В некоторых случаях вариант с поддокументами нужен для хранения части информации, но в целом сами комментарии хранятся в поддокументах, такие варианты называют модным ныне словом "гибридная" схема.
Теперь рассмотрим несколько примеров работы с документами.
Удалить одного или несколько детей у родителя:
db.test.update( { _id: 1 }, { $pull: { child: 2 } } )
db.test.update( { _id: 1 }, { $pullAll: { child: [ 2, 3 ] } } )Добавить одного или несколько детей родителю:
db.test.update( { _id: 1 }, { $push: { child: 2 } } } )
db.test.update( { _id: 1 }, { $push: { child: { $each: [ 2, 3 ] } } } )Сформируем дерево из полученных документов:
def getTree(docs):
tree = { doc["_id"]: doc for doc in docs }
for doc in docs:
doc['child'] = []
for doc in docs:
parent = doc["parent"]
if parent != "root":
tree[parent]["child"].append(doc)
docs={"_id": "root", "child": [doc for doc in docs if doc['parent'] == "root" ]}
return docs
{ _id: 1, type: "comment", title: "one", "user": "Alex", parent: "root",
child: [
{ _id: 2, type: "comment", title: "two", "user": "Serg", parent: 1 },
{ _id: 3, type: "comment", title: "two", "user": "Andrey", parent: 1 }
]
}Посчитаем количество товаров, которые относятся к каждой категории дерева с учетом всех вложенных категорий, при условии, что в каждом товаре хранится _id категории к которой он принадлежит:
def count(cls):
db = connect()
ctr = db.test.find({'type':'goods', 'class':cls}).count()
childs = db.test.find_one({'_id':cls})
for res in childs['child']:
ctr += count(res)
return ctrНайдем путь к началу, зная _id категории, после чего останется в шаблоне просто фором пройтись по списку кортежей:
def path( id ):
p = []
parent = db.test.find_one( {"_id": id }, { "parent": 1, "alias":1, "title":1})
else:
path.append( ( parent['alias'], parent['title'] ) )
p += path( parent['parent'] )
return p
print ( path("123") )
>>>[ ("one", "Первая ветка"), ("two", "Вторая ветка") ]Теги, блоги
Чаще всего для хранения тегов используется гибридный вариант, то есть они хранятся например в поле { tags : { ru: "один, два" } }, чтобы их сразу удобно было выводить на странице под материалом. И хранятся в массиве для удобного поиска по ним { tags : [ "один", "два" ] }.
Облака тегов иногда тоже отдельно хранят, иногда формируют на лету.
Поиск по массиву тегов, если, к примеру, нужно найти список документов:
{ _id: 1, title: "Языки программирования", tags: [ "php", "python" ] }
db.test.find({ tags: { $in: ["php", "python" ] } } )Ну и теперь отфильтруем:
- По тегам, например, хотим чтобы в этом месте показывались документы с тегами `python, javascript`.
- И, в тоже время, не показывались документы где упоминаются теги, например, «реклама».
- По типу, учтем какой тип контента нужно показать, например, будем показывать новости.
- Учтем пользователей за чьим авторством можно показывать документы.
- Также установим, что больше одного документа для одного пользователя нельзя показывать.
- Установим срок давности, чтоб выводились документы, которым не более, к примеру, 5 дней давности.
- Минимальный рейтинг показа, то есть документы у которых рейтинг меньше `+2` не показывать.
- Проверим чтобы документы были опубликованы и одобрены администратором.
- Установим лимит в `10` штук для показа.
- Отсортируем по просмотрам, и те, которые промаркированы специально (иногда бывает нужно).
dt = ( datetime.today() + timedelta( days = -5 ) )
db.test.aggregate([
{ $match: {
// выбираем тип контента и срок давности
type: "news", date: { $gt: dt },
// выбираем минимальный рейтинг.
vate: { $gte: 2 },
//Материалы каких пользователей показывать.
user: { $in: [ "alex", "pavel" ] }
$and: [
// Документ разрешён к публикации и одобрен.
{ pub: true }, { accept: true },
// Выбираем по каким тегам нужно отфильтровать документы.
{ tags: { $in: ["php", "python" ] } } ,
// Теги с которыми мы не хотим видеть документы.
{ tags: { $nin: ["реклама"] } }
]
},
// Сортируем по важности и по дате.
{ $sort: {'primary': -1, view: -1}},
// Устанавливаем лимит документов, показывать не больше 5
{ $limit:3},
// Показывать не более 1 документа для каждого пользователя, группируем по пользователю.
{ $group: {
'_id':'$user',
'id': {'$first':'$_id'},
'type':{'$first':'$type'},
'title': {'$first':'$title'},
'content':{'$first':'$content'},
'count':{'$first':'$count_comm'},
'last_comm':{'$first':'$last_comm'},
'vote':{'$first':'$vote'},
'tags':{'$first':'$tags'}
}
},
// сгруппированные документы приводим в нужный нам вид.
{ $project :{
'_id':'$id', 'title':1, 'content':1, 'type':1, 'count':1, 'last_comm':1, 'tags':1, 'vote':1
}
}
])db.test.aggregate([
{ $match: {
type: "news", date: { $gt: dt }, vate: { $gte: 2 }, user: { $in: [ "alex", "pavel" ] }
$and: [
{ pub: true }, { accept: true },
{ tags: { $in: ["php", "python" ] } } ,
{ tags: { $nin: ["реклама"] } }
]
},
{ $sort: {'primary': -1, view: -1}}, { $limit:3},
{ $group: {'_id':'$user',
'id': {'$first':'$_id'}, 'type':{'$first':'$type'},
'title': {'$first':'$title'}, 'content':{'$first':'$content'},
'count':{'$first':'$count_comm'},
'last_comm':{'$first':'$last_comm'},
'vote':{'$first':'$vote'}, 'tags':{'$first':'$tags'}
}
},
{ $project :{
'_id':'$id', 'title':1, 'content':1, 'type':1, 'count':1, 'last_comm':1, 'tags':1, 'vote':1
}
}
])Теперь все, что нам нужно — разделить область видимости сайта на ячейки и для каждой из них можно предоставлять свой контент.
Е-commerce и сложные фильтры в Mongodb
Наверное, одна из основных сложностей и задач веб-магазинов и различных учётов — это все-таки фильтры. Они нужны как для создания хитрых отчетов, так и для просто показа где что лежит на складе, ну и, банально, отфильтровать ноутбуки по диагонали, цене, производителю и прочему.
Последним случаем, из-за слишком большого объема материала, мы и ограничимся. Остальные рассмотрим в последующих публикациях.
Существует два вида фильтров, или, если хотите, способа организации контента в веб-магазине.
- Неправильный и не требующий ничего (часто достаточно просто спарсить прайс или вообще товары с какого то сайта )
- Правильный и требующий детальной настройки пользователем.
В первом случае, поскольку наличествующие атрибуты у нас просто текстовые поля, ни с чем не связанные, то нам нужно просто по ним сгруппировать документы — и всё. Но в таком случае при неправильном заполнении, а также при развитии учета, в магазине возникнут проблемы и придется все перезаносить.
Во втором случае нам надо для каждой категории товаров настроить свои фильтры и каждый из фильтров тем или иным способом привязать к характеристикам товаров (атрибутам).
Работа с фильтрами состоит из двух этапов:
- Показ значений фильтра в зависимости от категории, то есть у категории монитор есть диагональ а у категории процессор тактовая частота.
- И поиск по этим значениям.
Начнем с показа значений фильтра, если у нас настроена привязка фильтров к характеристикам товаров, тогда все выглядит довольно просто. И делается простым запросом:
cursor = db.test.find({ "type": "filters", "category": "id_category" })Представить данные можно по разному, например, можно сделать древовидной таблицей, где первым уровнем будут названия фильтров, а вторым уровнем его характеристики.
Название => Диагональ
Характеристики=> 15.6 дюйма, 17 дюймов и тд.

Можно по другому представить, пойти как на мой взгляд немного более распространенным путем. Сделать подтаблицами по типу приходных и расходных накладных. Когда есть шапка документа с перечислением реквизитов и тд., и есть список товаров снизу.
Только в данном случае шапка — это название категории, для которой мы настраиваем фильтры, а список товаров — это список названий фильтров с атрибутами в одной из подчиненных таблиц.
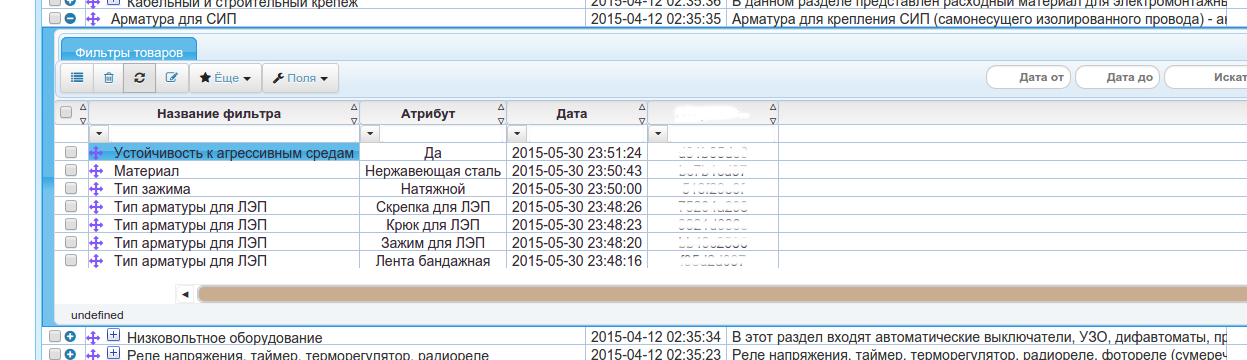
В этом случае запрос будет немного посложнее и придется группировать данные. Это уже будет похоже на аналогичный запрос к получению фильтров из самих товаров, этот запрос и опишем.
У нас есть список товаров, у каждого есть список атрибутов хранящихся или в отдельных документах, или в нем самом в субдокументах. Визуально это может выглядеть примерно так.

В нашем случае возьмем чуть более сложный вариант и предположим, что это будут отдельные документы. Желательно чтобы _id категории хранилось тогда в каждом документе с характеристикой.
Оператор $addToSet при группировке выбирает уникальные элементы из массива.
db.test.aggregate([
// находим все документы по типу справочника и по id категории
{ '$match': { type : "goods_attr", category: id_category } },
// немного переформатируем документы для более удобной группировки, отбрасывая лишние поля
{ '$project': { "title" : "$title.ru", 'value': "$attr.ru", 'category': "$category", '_id': 0 } },
{ '$group' : {
'_id': { 'category' :"$category", 'title': "$title"} ,
'filters': { '$addToSet': "$value" }
}
},
{ '$group' : {
'_id' :"$_id.category", 'title':{ '$addToSet': { 'title': "$_id.title", 'filters': "$filters" } }
}
}
])После первого group мы получаем документы такого типа:
...{ '$group' : {
'_id': { 'category' :"$category", 'title': "$title"} ,
'filters': { '$addToSet': "$value" }
}
}....
{ "_id": { "category": "id", "title": "Устойчивость к агрессивным средам" }, "filters": [ "Да" ] }
{ "_id" : { "category" : "id", "title" : "Материал" }, "filters" : [ "Нержавеющая сталь" ] }
{ "_id" : { "category" : "id", "title" : "Тип зажима" }, "filters" : [ "Натяжной" ] }После второго group мы уже получаем окончательный вариант.
...{ '$group' : {
'_id':"$_id.category", 'title':{'$addToSet': {'title': "$_id.title", 'filters': "$filters" }}
}
...}
{
"_id" : "id_category",
"title" : [
{ "title" : "Тип арматуры для ЛЭП", "filters" :
[ "Крюк для ЛЭП", "Скрепа для ЛЭП", "Лента бандажная", "Зажим для ЛЭП" ]
},
{ "title" : "Тип зажима", "filters" : [ "Натяжной" ] },
{ "title" : "Материал", "filters" : [ "Нержавеющая сталь" ] },
{ "title" : "Устойчивость к агрессивным средам", "filters" : [ "Да" ] }
]
}Теперь, когда мы уже имеем список фильтров, можно поискать по этим фильтрам. Поскольку мы ищем по субдокументам, то есть по характеристикам, то группируем по owner_id это _id документа к которому принадлежат характеристики.
db.test.aggregate([
{ '$match' :
{ 'type' : "goods_attr", "category'':"id",
'$or': [
{'title': 'Материал', 'attr': 'Нержавеющая сталь'},
{'title': 'Тип арматуры для ЛЭП', 'attr_val': 'Крюк для ЛЭП'}
]
}
},
{ '$group': {'_id': "$owner_id", "attr": { '$push': "$title" }}},
{ '$match': {"attr": {'$all': [ 'Материал', 'Тип арматуры для ЛЭП' ] }}},
{ '$project': {"_id":1 } }
])На выходе получаем список _id документов подходящих под фильтры.
Небольшая песочница для Python
Как правило при работе с различными типами данных удобно визуализировать в виде различных иерархических и других табличек.
Но часто бывает, что нужно повесить на изменение, к примеру, поля или удаление документа (читай — строки в таблице) какое либо событие. Например, мы поменяли в справочнике валют курс по которому закупаем, и хотим чтоб цены в отечественной валюте пересчитались для всех товаров.
Это достаточно стандартный функционал для различных ERP решений. И, поскольку часто неизвестно кто будет писать для песочницы код, нужна возможность запускать чужой код более-менее безопасно. На данный момент есть библиотеки, которые дают эту возможность, но точно неизвестно как хорошо они ограничивают запускаемый код.
Есть простой способ безопасно выполнять чужой код в python, он привносит некоторые ограничения, но для большинства задач его достаточно.
Пример с exec
src = '''
result = 0
for i in xrange(100):
result += i
'''
assert '__' not in src, 'Prohibited to use symbols "__"'
pr = compile(src, '<string>', mode='exec')
glob = { '__builtins__':{ 'xrange':xrange } }
exec(pr, glob)
print glob['result']Пример с eval (для вычисления выражения)
src = 'max(5,7,3)'
glob = { '__builtins__':{ 'max':max } }
assert '__' not in src, 'Prohibited to use symbols "__"'
print ( eval(src, glob) )Главное — это:
assert '__' not in src, 'Prohibited to use symbols "__"'
- запрет доступа к спец объектам, на подобии:
__class__, __base__
через которые можно получить полный доступ к python и
glob = { '__builtins__':{ 'xrange':xrange } }
тут мы заменяем весь базовый функционал (import, type...) на нужный/разрешенный функционал.
