
На глаза попалась уже вторая новость на Хабре о том, что скоро Microsoft «подружит» SQL Server и Linux. Но ни слова не сказано про SQL Server 2016 Release Candidate, который стал доступен для загрузки буквально на днях.
В следующем месяце планируется выпустить RTM, поэтому далее под катом разбор некоторых нововведений, которые будут доступны в рамках новой версии: отличия в установке, дефолтные трейс-флаги, новые функции и киллер-фича для анализа плана выполнения.
Начнем с установки экземпляра SQL Server 2016. Сам инсталлятор претерпел изменения по сравнению с предыдущей версией:
- Для установки доступна только x64 версия SQL Server-а (последний x86 билд вырезали еще в CTP2.3). Официально все звучит более лаконичнее: «SQL Server 2016 Release Candidate (RC0) is a 64-bit application. 32-bit installation is discontinued, though some elements run as 32-bit components.»
- Установка SQL Server 2016 на Windows 7 и Windows Server 2008 не поддерживается. Официальный список систем куда можно установить SQL Server: все x64 редакции Windows 8/8.1/10 и Windows Server 2012
- SSMS теперь не поставляется вместе с SQL Server и развивается отдельно. Скачать standalone редакцию SSMS можно по этой ссылке. Новая редакция SSMS поддерживает работу с SQL Server 2005..2016, поэтому теперь не нужно держать целый парк студий для каждой версии.
- Добавились два новых компонента, которые реализуют поддержку языка R и PolyBase (мост между SQL Server и Hadoop):

Для работы PolyBase требуется предварительно установить JRE7 или более свежую версию:

И не забыть потом добавить в исключения Firewall выбранный диапазон портов:

Отдельное спасибо Microsoft — теперь не нужно ковыряться в групповой политике, чтобы включить Instant File Initialization:

Также немного поменялся диалог по выбору дефолтных путей:
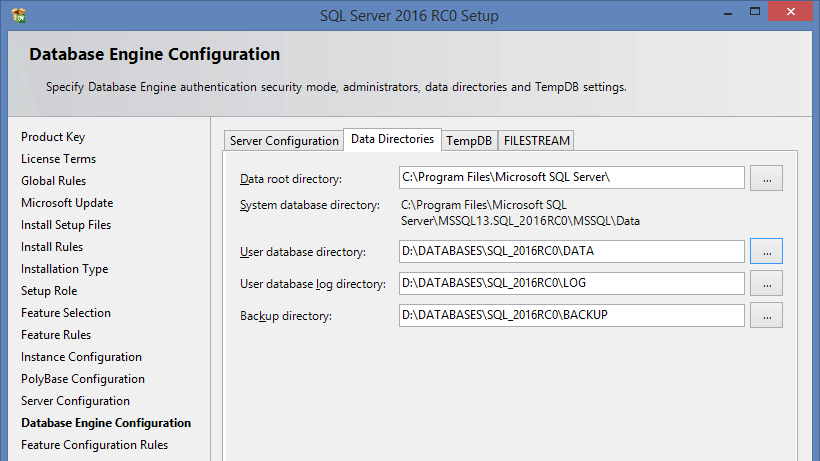
Для настройки tempdb сделали отдельную закладку на которой можно автоматически создать нужное число файлов и разнести их при необходимости по разным дискам. Но даже если этого не делать, радует, что при установке по умолчанию параметр Autogrowth будет не 1Mб (как раньше), а 64Mб.

При этом максимальный размер файла ограничен 256Мб. Можно задать и больше, но уже после установки:

На этом отличия в установке по сравнению с предыдущей версией заканчиваются.
Теперь посмотрим на то что еще поменялось…
Изменились настройки системной базы model, чтобы снизить число AutoGrow событий:

Почитать почему это плохо можно тут.
Также важно упомянуть, что некоторые Trace Flag-ги на новом SQL Server-е будут включены по умолчанию…
-T1118
SQL Server вычитывает данные с диска кусками по 64Кб (так называемыми экстентами). Экстент – это группа из восьми физически последовательных страниц (по 8Кб каждая) файлов базы данных.
Имеются два типа экстентов: смешанные и однородные. На смешанном экстенте могут храниться страницы с разных объектов. Такое поведение позволяет очень маленьким таблицам занимать минимальное количество места. Но чаще всего таблицы не ограничиваются размером в 64Кб и когда требуется более 8 страниц для хранения данных по одному объекту, то происходит переключение на выделение однородных экстентов.
Чтобы изначально выделять для объекта однородные экстенты был предусмотрен TF 1118, который рекомендовалось включать. И получалось, что работал он глобально для всех баз на сервере.
В 2016 версии такого уже не будет. Теперь для каждой пользовательской базы можно задать опцию MIXED_PAGE_ALLOCATION:
ALTER DATABASE test SET MIXED_PAGE_ALLOCATION OFF
Для системных баз данная опция включена по умолчанию, т.е. все остается, как и было ранее:
SELECT name, is_mixed_page_allocation_on
FROM sys.databases
Исключение сделано лишь для пользовательских баз и tempdb:
name is_mixed_page_allocation_on
----------------- ---------------------------
master 1
tempdb 0
model 1
msdb 1
DWDiagnostics 0
DWConfiguration 0
DWQueue 0
test 0
Приведу небольшой пример:
IF OBJECT_ID('dbo.tbl') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (ID INT DEFAULT 1)
GO
CHECKPOINT
GO
INSERT dbo.tbl DEFAULT VALUES
GO
SELECT [Current LSN], Operation, Context, AllocUnitName, [Description]
FROM sys.fn_dblog(NULL, NULL)
MIXED_PAGE_ALLOCATION=ON:

MIXED_PAGE_ALLOCATION=OFF:

-T1117
В рамках одной файловой группы может быть создано несколько файлов. Например, для базы tempdb рекомендуется создавать несколько файлов, что может в некоторых сценариях увеличить производительность системы.
Теперь предположим ситуацию: все файлы, входящие в файловую группу, имеют одинаковый размер. Создается большая временная таблица. Места в файле #1 не достаточно и разумеется происходит AutoGrow. Через время такая же таблица пересоздается, но вставка происходит в файл #2, потому что #1 временно заблокирован. Что в таком случае будет? AutoGrow для #2… и повторная задержка при выполнении запросов. Для таких случаев, был предусмотрен TF 1117. Работал он глобально и при нехватке места в одном файле вызывал AutoGrow для всех файлов в рамках одной файловой группы.
Теперь данный трейс-флаг включен по умолчанию для tempdb и может избирательно настраиваться для пользовательских баз:
ALTER DATABASE test
MODIFY FILEGROUP [PRIMARY] AUTOGROW_ALL_FILES
GO
ALTER DATABASE test
MODIFY FILEGROUP [PRIMARY] AUTOGROW_SINGLE_FILE
GO
Посмотрим на размер файлов:
USE tempdb
GO
SELECT
name
, physical_name
, current_size_mb = ROUND(size * 8. / 1024, 0)
, auto_grow =
CASE WHEN is_percent_growth = 1
THEN CAST(growth AS VARCHAR(10)) + '%'
ELSE CAST(CAST(ROUND(growth * 8. / 1024, 0) AS INT) AS VARCHAR(10)) + 'MB'
END
FROM sys.database_files
WHERE [type] = 0
name physical_name size_mb auto_grow
---------- --------------------------------------------------- -------- ------------
tempdev D:\DATABASES\SQL_2016RC0\TEMP\tempdb.mdf 8.000000 64MB
temp2 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_2.ndf 8.000000 64MB
temp3 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_3.ndf 8.000000 64MB
temp4 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_4.ndf 8.000000 64MB
Создаем временную таблицу:
IF OBJECT_ID('#t') IS NOT NULL
DROP TABLE #t
GO
CREATE TABLE #t (
ID INT DEFAULT 1,
Value CHAR(8000) DEFAULT 'X'
)
GO
INSERT INTO #t
SELECT TOP(10000) 1, 'X'
FROM [master].dbo.spt_values c1
CROSS APPLY [master].dbo.spt_values c2
Места чтобы вставить данные не хватит и произойдет AutoGrow.
AUTOGROW_SINGLE_FILE:
name physical_name size_mb auto_grow
---------- --------------------------------------------------- ----------- ------------
tempdev D:\DATABASES\SQL_2016RC0\TEMP\tempdb.mdf 72.000000 64MB
temp2 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_2.ndf 8.000000 64MB
temp3 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_3.ndf 8.000000 64MB
temp4 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_4.ndf 8.000000 64MB
AUTOGROW_ALL_FILES:
name physical_name size_mb auto_grow
---------- --------------------------------------------------- ----------- ------------
tempdev D:\DATABASES\SQL_2016RC0\TEMP\tempdb.mdf 72.000000 64MB
temp2 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_2.ndf 72.000000 64MB
temp3 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_3.ndf 72.000000 64MB
temp4 D:\DATABASES\SQL_2016RC0\TEMP\tempdb_mssql_4.ndf 72.000000 64MB
-T2371
До 2016 версии для автоматического пересчета статистики использовалось магическое число «20% + 500 строк». Просто покажу на примере:
USE [master]
GO
SET NOCOUNT ON
IF DB_ID('test') IS NOT NULL BEGIN
ALTER DATABASE [test] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [test]
END
GO
CREATE DATABASE [test]
GO
USE [test]
GO
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL
DROP TABLE dbo.tbl
GO
CREATE TABLE dbo.tbl (
ID INT IDENTITY(1,1) PRIMARY KEY,
Value CHAR(1)
)
GO
CREATE NONCLUSTERED INDEX ix ON dbo.tbl (Value)
GO
INSERT INTO dbo.tbl
SELECT TOP(10000) 'x'
FROM [master].dbo.spt_values c1
CROSS APPLY [master].dbo.spt_values c2
Чтобы обновилась статистика, нужно изменить:
SELECT [>=] = COUNT(1) * .20 + 500
FROM dbo.tbl
HAVING COUNT(1) >= 500
В нашем случае это 2500 строк. При этом не за один раз, а вообще… это значение кумулятивное. Выполняем сперва запрос:
UPDATE dbo.tbl
SET Value = 'a'
WHERE ID <= 2000
Смотрим:
DBCC SHOW_STATISTICS('dbo.tbl', 'ix') WITH HISTOGRAM
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
------------ ------------- ------------- -------------------- --------------
x 0 10000 0 1
Статистика старая… Выполняем еще один запрос:
UPDATE dbo.tbl
SET Value = 'b'
WHERE ID <= 500
Ура! Статистика обновилась:
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
------------ ------------- ------------- -------------------- --------------
a 0 1500 0 1
b 0 500 0 1
x 0 8000 0 1
А теперь предположим, что таблица у нас огромная… 10-20-30 миллионов строк. Чтобы пересчиталась статистика нам нужно изменить внушительный объём данных или вручную следить за обновлением статистики.
Начиная с SQL Server 2008R2 SP1 появился TF 2371, который вот тот «магический» процент занижал динамически в зависимости от общего числа строк:
< 25k = 20%
> 30k = 18%
> 40k = 15%
> 100k = 10%
> 500k = 5%
> 1000k = 3.2%
В SQL Server 2016 этот трейс флаг включен по умолчанию.
-T8048
В случае, если в вашей системе более 8 логических процессоров и наблюдается большое число ожиданий CMEMTHREAD и кратковременных блокировок:
SELECT waiting_tasks_count
FROM sys.dm_os_wait_stats
WHERE wait_type = 'CMEMTHREAD'
AND waiting_tasks_count > 0
SELECT spins
FROM sys.dm_os_spinlock_stats
WHERE name = 'SOS_SUSPEND_QUEUE'
AND spins > 0
то использование TF 8048 помогало избавиться от проблем с производительностью. В SQL Server 2016 данный трейс флаг включен по умолчанию.
SCOPED CONFIGURATION
На уровне базы появилась новая группа настроек:

Получить их можно из нового системного представления sys.database_scoped_configurations. Лично меня очень радует, что степень параллелизма менять можно не глобально как раньше, а настраивать персонально для каждой базы:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0
Включать старый Cardinality Estimation (раньше приходилось включать TF 9481 либо понижать compatibility level до 2012):
ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ON
Отключать Parameter Sniffing (раньше для этого включали TF 4136 или хардкодили OPTIMIZE FOR UNKNOWN)
ALTER DATABASE SCOPED CONFIGURATION SET PARAMETER_SNIFFING = OFF
Также добавили возможность включать TF 4199, который объединяет в себе внушительный список самых разных оптимизаций.
ALTER DATABASE SCOPED CONFIGURATION SET QUERY_OPTIMIZER_HOTFIXES = ON
Для любителей вызывать вызывать команду DBCC FREEPROCCACHE предусмотрели команду для очистки процедурного кеша:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE
Аналог команды:
DECLARE @id INT = DB_ID()
DBCC FLUSHPROCINDB(@id)
Также думаю будет полезно добавить запрос, по которому можно отслеживать обьем процедурного кеша в разрезе баз:
SELECT db = DB_NAME(t.[dbid]), plan_cache_kb = SUM(size_in_bytes / 1024)
FROM sys.dm_exec_cached_plans p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) t
WHERE t.[dbid] < 32767
GROUP BY t.[dbid]
ORDER BY 2 DESC
Теперь рассмотрим новые функции:
JSON_MODIFY
В RC0 добавили возможность модифицировать JSON c помощью функции JSON_MODIFY:
DECLARE @js NVARCHAR(100) = '{
"id": 1,
"name": "JC",
"skills": ["T-SQL"]
}'
SET @js = JSON_MODIFY(@js, '$.name', 'Paul') -- update
SET @js = JSON_MODIFY(@js, '$.surname', 'Denton') -- insert
SET @js = JSON_MODIFY(@js, '$.id', NULL) -- delete
SET @js = JSON_MODIFY(@js, 'append $.skills', 'JSON') -- append
PRINT @js
{
"name": "Paul",
"skills": ["T-SQL","JSON"],
"surname":"Denton"
}
STRING_ESCAPE
Также появилась функция STRING_ESCAPE, которая экранирует спецсимволы в тексте:
SELECT STRING_ESCAPE(N'JS/Denton "Deus Ex"', N'JSON')
------------------------
JS\/Denton \"Deus Ex\"
STRING_SPLIT
Срочно радоваться! Наконец появилась функция STRING_SPLIT, которая избавляет нас от прежних извращений с XML и CTE:
SELECT * FROM STRING_SPLIT(N'1,2,3,,4', N',')
value
---------
1
2
3
4
Но есть и «ложка дегтя», функция работает только с разделителем в один символ:
SELECT * FROM STRING_SPLIT(N'1--2--3--4', N'--')
Msg 214, Level 16, State 11, Line 3
Procedure expects parameter 'separator' of type 'nchar(1)/nvarchar(1)'.
С точки зрения производительности сравним старые методы сплита и новые:
SET STATISTICS TIME ON
DECLARE @x VARCHAR(MAX) = 'x' + REPLICATE(CAST(',x' AS VARCHAR(MAX)), 500000)
;WITH cte AS
(
SELECT
s = 1,
e = COALESCE(NULLIF(CHARINDEX(',', @x, 1), 0), LEN(@x) + 1),
v = SUBSTRING(@x, 1, COALESCE(NULLIF(CHARINDEX(',', @x, 1), 0), LEN(@x) + 1) - 1)
UNION ALL
SELECT
s = CONVERT(INT, e) + 1,
e = COALESCE(NULLIF(CHARINDEX(',', @x, e + 1), 0), LEN(@x) + 1),
v = SUBSTRING(@x, e + 1, COALESCE(NULLIF(CHARINDEX(',', @x, e + 1), 0), LEN(@x) + 1)- e - 1)
FROM cte
WHERE e < LEN(@x) + 1
)
SELECT v
FROM cte
WHERE LEN(v) > 0
OPTION (MAXRECURSION 0)
SELECT t.c.value('(./text())[1]', 'VARCHAR(100)')
FROM
(
SELECT x = CONVERT(XML, '<i>' + REPLACE(@x, ',', '</i><i>') + '</i>').query('.')
) a
CROSS APPLY x.nodes('i') t(c)
SELECT *
FROM STRING_SPLIT(@x, N',')
Результаты выполнения:
(CTE)
SQL Server Execution Times:
CPU time = 18719 ms, elapsed time = 19109 ms.
(XML)
SQL Server Execution Times:
CPU time = 4672 ms, elapsed time = 4958 ms.
(STRING_SPLIT)
SQL Server Execution Times:
CPU time = 2828 ms, elapsed time = 2941 ms.
Live Query Statistics
Что еще понравилось… В новой версии SSMS появилась возможность отслеживать как выполняется запрос в режиме реального времени:

Данный функционал поддерживается, не только в SQL Server 2016, но и для SQL Server 2014. На уровне метаданных данный функционал реализован посредством выборки из sys.dm_exec_query_profiles:
SELECT
p.[sql_handle]
, s.[text]
, p.physical_operator_name
, p.row_count
, p.estimate_row_count
, percent_complete = 100 * p.row_count / p.estimate_row_count
FROM sys.dm_exec_query_profiles p
CROSS APPLY sys.dm_exec_sql_text(p.[sql_handle]) s
Чтобы сохранить читабельность, за бортом этого обзора я оставил некоторые новые возможности SQL Server (Temporal Tables, Dynamic Data Masking и улучшения в In-Memory), которые планирую добавить после того как выйдет RTM версия.
Если хотите поделиться этой статьей с англоязычной аудиторией:
SQL Server 2016 RC0
