 NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений.
NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений. Инфографика Inside NGINX сверху вниз проведет вас по азам устройства процессов к иллюстрации того, как NGINX обрабатывает множество соединений в одном процессе. Данная статья рассмотрит всё это чуть более детально.
Подготавливаем сцену: модель NGINX процессов
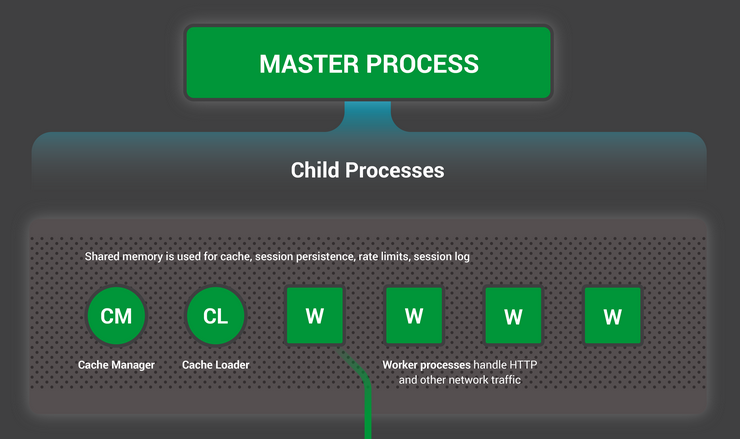
Чтобы лучше представлять устройство, сперва необходимо понять как NGINX запускается. У NGINX есть один мастер-процесс (который от имени суперпользователя выполняет такие операции, как чтение конфигурации и открытие портов), а также некоторое количество рабочих и вспомогательных процессов.
# service nginx restart
* Restarting nginx
# ps -ef --forest | grep nginx
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx \
-c /etc/nginx/nginx.conf
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader processНа 4-х ядерном сервере мастер-процесс NGINX создает 4 рабочих процесса и пару вспомогательных кэш-процессов, которые управляют содержимым кэша на жестком диске.
Почему архитектура всё же важна?
Одна из фундаментальных основ любого Unix-приложения — это процесс или поток (с точки зрения ядра Linux процессы и потоки практически одно и то же — вся разница в разделении адресного пространства). Процесс или поток — это самодостаточный набор инструкций, который операционная система может запланировать для выполнения на ядре процессора. Большинство сложных приложений параллельно запускают множество процессов или потоков по двум причинам:
- Чтобы одновременно задействовать больше вычислительных ядер;
- Процессы и потоки позволяют проще выполнять параллельные операции (например обрабатывать множество соединений одновременно).
Процессы и потоки сами по себе расходуют дополнительные ресурсы. Каждый такой процесс или поток потребляет некоторое количество памяти, а кроме того они постоянно подменяют друг друга на процессоре (т. н. переключение контекста). Современные серверы могут справляться с сотнями активных процессов и потоков, но производительность сильно страдает, как только заканчивается память или огромное количество операций ввода-вывода приводит к слишком частой смене контекста.
Наиболее типичный подход к построению сетевого приложения — это выделять для каждого соединения отдельный процесс или поток. Такая архитектура проста для понимания и легка в реализации, но при этом плохо масштабируется когда приложению приходится работать с тысячами соединений одновременно.
Как же работает NGINX?
NGINX использует модель с фиксированным числом процессов, которая наиболее эффективно задействует доступные ресурсы системы:
- Единственный мастер-процесс выполняет операции, которые требуют повышенных прав, такие, как чтение конфигурации и открытие портов, а затем порождает небольшое число дочерних процессов (следующие три типа).
- Загрузчик кэша запускается на старте чтобы загрузить данные кэша, расположенные на диске, в оперативную память, а затем завершается. Его работа спланирована так, чтобы не потреблять много ресурсов.
- Кэш-менеджер просыпается периодически и удаляет объекты кэша с жесткого диска, чтобы поддерживать его объем в рамках заданного ограничения.
- Рабочие процессы выполняют всю работу. Они обрабатывают сетевые соединения, читают данные с диска и пишут на диск, общаются с бэкенд-серверами.
Документация NGINX рекомендует в большинстве случаев настраивать число рабочих процессов равное количеству ядер процессора, что позволяет использовать системные ресурсы максимально эффективно. Вы можете задать такой режим с помощью директивы worker_processes auto в конфигурационном файле:
worker_processes auto;Когда NGINX находится под нагрузкой, то в основном заняты рабочие процессы. Каждый из них обрабатывает множество соединений в неблокирующемся режиме, минимизируя количество переключений контекста.
Каждый рабочий процесс однопоточен и работает независимо, принимая новые соединения и обрабатывая их. Процессы взаимодействуют друг с другом используя разделяемую память для данных кэша, сессий и других общих ресурсов.
Внутри рабочего процесса

Каждый рабочий процесс NGINX инициализируется с заданной конфигурацией и набором слушающих сокетов, унаследованных от мастер-процесса.
Рабочие процессы начинают с ожидания событий на слушающих сокетах (см. также accept_mutex и разделяемые сокеты). События извещают о новых соединениях. Эти соединения попадают в конечный автомат — наиболее часто используемый предназначен для обработки HTTP, но NGINX также содержит конечные автоматы для обработки потоков TCP трафика (модуль stream) и целого ряда протоколов электронной почты (SMTP, IMAP и POP3).
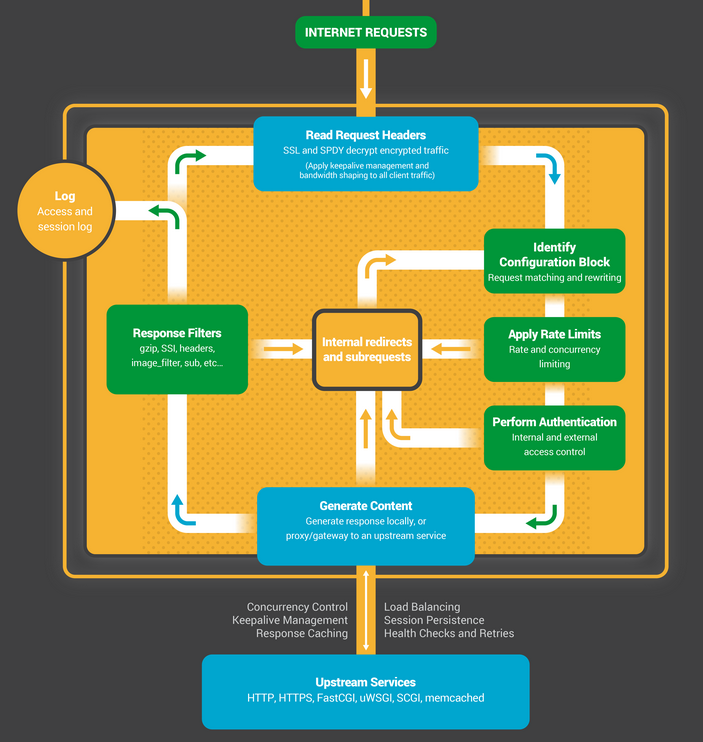
Конечный автомат в NGINX по своей сути является набором инструкций для обработки запроса. Большинство веб-серверов выполняют такую же функцию, но разница кроется в реализации.
Устройство конечного автомата
Конечный автомат можно представить себе в виде правил для игры в шахматы. Каждая HTTP транзакция — это шахматная партия. С одной стороны шахматной доски веб-сервер — гроссмейстер, который принимает решения очень быстро. На другой стороне — удаленный клиент, браузер, который запрашивает сайт или приложение по относительно медленной сети.
Как бы то ни было, правила игры могут быть очень сложными. Например, веб-серверу может потребоваться взаимодействовать с другими ресурсами (проксировать запросы на бэкенд) или обращаться к серверу аутентификации. Сторонние модули способны ещё сильнее усложнить обработку.
Блокирующийся конечный автомат
Вспомните наше определение процесса или потока, как самодостаточного набора инструкций, выполнение которых операционная система может назначать на конкретное ядро процессора. Большинство веб-серверов и веб-приложений используют модель, в которой для «игры в шахматы» приходится по одному процессу или потоку на соединение. Каждый процесс или поток содержит инструкции, чтобы сыграть одну партию до конца. Все это время процесс, выполняясь на сервере, проводит большую часть времени заблокированным в ожидании следующего хода от клиента.

- Процесс веб-сервера ожидает новых соединений (новых партий инициированных клиентами) на слушающих сокетах.
- Получив новое соединение, он играет партию, блокируясь после каждого хода в ожидании ответа от клиента.
- Когда партия сыграна, процесс веб-сервера может находиться в ожидании желания клиента начать следующую партию (это соответствует долгоживущим keepalive-соединениям). Если соединение закрыто (клиент ушел или наступил таймаут), процесс возвращается к встрече новых клиентов на слушающих сокетах.
Важный момент, который стоит отметить, заключается в том, что каждое активное HTTP-соединение (каждая партия) требует отдельного процесса или потока (гроссмейстера). Такая архитектура проста и легко расширяема с помощью сторонних модулей (новых «правил»). Однако, в ней существует огромный дисбаланс: достаточно легкое HTTP-соединение, представленное в виде файлового дескриптора и небольшого объема памяти, соотносится с отдельным процессом или потоком, достаточно тяжелым объектом в операционной системе. Это удобно для программирования, но весьма расточительно.
NGINX, как настоящий Гроссмейстер
Вероятно вы слышали о сеансах одновременной игры, когда один гроссмейстер играет на множестве шахматных полей сразу с десятками противников?

Кирил Георгиев на турнире в Болгарии сыграл параллельно 360 партий. Его итоговый результат составил: 284 победы, 70 вничью и 6 поражений.
Таким же образом рабочий процесс NGINX «играет в шахматы». Каждый рабочий процесс (помните — обычно всего один на вычислительное ядро) является гроссмейстером, способным играть сотни (а на самом деле сотни тысяч) партий одновременно.

- Рабочий процесс ожидает событий на слушающих сокетах и сокетах соединений.
- На сокетах происходят события и процесс их обрабатывает:
- Событие на слушающем сокете означает, что пришел новый клиент для начала игры. Рабочий процесс создает новый сокет соединения.
- Событие на сокете соединений сигнализирует, что клиент сделал ход. Рабочий процесс ему мгновенно отвечает.
Рабочий процесс, обрабатывая сетевой трафик, никогда не блокируется, ожидая очередного хода от оппонента (клиента). После того как процесс сделал свой ход, он немедленно переходит к другим доскам, на которых игроки ожидают хода, или встречает новых у двери.
Почему так получается быстрее, чем блокирующаяся многопоточная архитектура?
Каждое новое соединение создает файловый дескриптор и потребляет небольшой объем памяти в рабочем процессе. Это очень малые накладные расходы на соединение. Процессы NGINX могут оставаться привязанными к конкретным ядрам процессора. Переключения контекста происходят достаточно редко и в основном когда не осталось больше работы.
В блокирующемся подходе, с отдельным процессом на каждое соединение, требуется сравнительно большой объем дополнительных ресурсов, и переключения контекста с одного процесса на другой происходят гораздо чаще.
Дополнительную информацию по теме можно также узнать из статьи об архитектуре NGINX от Андрея Алексеева, вице-президента по развитию и сооснователя компании NGINX, Inc.
С адекватной настройкой системы, NGINX прекрасно масштабируется до многих сотен тысяч параллельных HTTP cоединений на каждый рабочий процесс и уверенно поглощает всплески трафика (толпы новых игроков).
Обновление конфигурации и исполняемого кода
Архитектура NGINX с малым количеством рабочих процессов позволяет достаточно эффективно обновлять конфигурацию и даже его собственный исполняемый код на лету.

Обновление конфигурации NGINX — очень простая, легковесная и надежная процедура. Она заключается в простой отправке мастер-процессу сигнала SIGHUP.
Когда рабочий процесс получает SIGHUP, он производит несколько операций:
- Перезагружает конфигурацию и порождает новый набор рабочих процессов. Эти новые рабочие процессы сразу начинают принимать соединения и обрабатывать трафик (используя новые настройки).
- Сигнализирует старые рабочие процессы о плавном завершении. Они перестают принимать новые соединения. Как только завершается обработка текущих HTTP-запросов, соединения закрываются (никаких затянувшихся keep-alive соединений). Как только все соединения закрыты, рабочий процесс завершается.
Данная процедура может вызвать небольшой всплеск нагрузки на процессор и память, но в общем это практически незаметно на фоне затрат на обработку активных соединений. Вы можете перезагружать конфигурацию несколько раз в секунду (и есть немало пользователей NGINX, кто так делает). В редких случаях могут возникнуть проблемы, когда слишком много поколений рабочих процессов NGINX ожидают закрытия соединений, но они быстро разрешаются.
Обновление исполняемого кода NGINX — это Святой Грааль высокой доступности сервисов. Вы можете обновлять сервер на лету, без потери соединений, простоя ресурсов и каких-либо перерывов в обслуживании клиентов.

Процесс обновления исполняемого кода использует схожий с перезагрузкой конфигурации подход. Новый мастер-процесс NGINX запускается параллельно со старым и получает от него дескрипторы слушающих сокетов. Оба процесса загружены и их рабочие процессы обрабатывают трафик. Затем вы можете отдать команду старому мастер-процессу на плавное завершение.
Вся процедура подробно описана в документации.
Подведем итоги
Мы дали поверхностный обзор того, как функционирует NGINX. Под этими простыми описаниями скрывается более чем десятилетний опыт разработки и оптимизации, который позволяет NGINX демонстрировать выдающуюся производительность на широком спектре оборудования и реальных задачах, оставаясь надежным и безопасным, как того требуют современные веб-приложения.
Если вы хотите узнать больше по данной теме, то рекомендуем для ознакомления:
