В программировании самокритика – это умение распознать контрпродуктивные решения в дизайне, коде, процессах и поведении. Знание о вредных шаблонах решений полезно для программиста. В этой статье я опишу анти-паттерны, которые я встречал на своём личном опыте время от времени.
Некоторые из них напрямую или косвенно связаны с когнитивными искажениями человеческого сознания – в этих случаях я даю ссылки на соответствующие вики-статьи. Также интересен список известных когнитивных искажений.
Оптимизация, проводимая до того, как у вас есть вся информация, необходимая для принятия взвешенных решений по поводу того, где и как нужно её проводить.
На практике сложно предсказать, где встретится узкое место. Попытки навести оптимизацию до получения эмпирических результатов приведут к усложнению кода и появлению ошибок, а пользы не принесут.
Сначала пишите чистый, читаемый, работающий код, используя известные и проверенные алгоритмы и инструменты. При необходимости используйте инструменты для профилирования для поиска узких мест. Полагайтесь на измерения, а не на догадки и предположения.
Кэширование до того, как провели профилирование. Использование сложных и недоказанных эвристических правил вместо математически верных алгоритмов. Выбор новых, непротестированных фреймворков, которые могут повести себя плохо под нагрузкой.
Сложность в том, чтобы знать, когда оптимизация будет преждевременной. Важно заранее оставлять место для роста. Нужно выбирать решения и платформы, которые позволят легко оптимизировать и расти. Также иногда можно использовать преждевременную оптимизацию в качестве оправдания за плохой код. Например, использование алгоритма O(n2) просто потому, что алгоритм O(n) сложнее.
Сначала профилирование, потом оптимизация. Не меняйте простоту на эффективность, пока об этом не заявят эмпирически полученные данные.
(прим.перев. – англосаксы любят придумывать глаголы. Этот термин также называется «Закон тривиальности Паркинсона», и появился после того, как этот Паркинсон обратил внимание, как люди любят тратить время на совещаниях на всякую ерунду, вместо того, чтобы обсуждать насущные проблемы. Конкретно, проектировщики атомной электростанции очень долго спорили, какой материал должен пойти на навес для велосипедов – bike-shed).

Склонность тратить время на обсуждение тривиальных и субъективных вещей.
Трата времени. Подробное письмо от Пола-Хенинга Кэмпа по этому поводу.
Напоминайте другим членам команды об этой склонности, и о том, что в этих случаях главное – быстрее принять решение (бросить монетку, проголосовать, и т.п.). Если речь идёт о вещах вроде пользовательского интерфейса, обратитесь к A/B тестированию, вместо того, чтобы обсуждать это в команде.
Часы или дни проводятся в обсуждениях цвета фона или расположения кнопки в интерфейсе, или использования табуляции вместо пробелов в коде.
Байкшеддинг легче заметить и предотвратить, чем преждевременную оптимизацию. Замечайте время, требуемое для принятия решений и сопоставляйте его со сложностью задачи.
Не тратьте много времени на простейшие решения.
Переизбыток анализа до такой степени, что прогресс и действия останавливаются.
Переизбыток анализа может замедлить или остановить прогресс. В тяжёлых случаях, результаты анализа становятся не нужны к тому моменту, когда они готовы, или даже проект вообще не покидает фазу анализа. Часто кажется, что чем больше у вас информации, тем больше это поможет принятию тяжёлого решения. См. информативное искажение и иллюзию допустимости.
Наблюдайте за итерациями и улучшениями. Каждая итерация даёт обратную связь и информацию, которую можно использовать для более осмысленного анализа. Без этой информации анализ будет лишь спекулятивным.
Месяцы и годы, проведённые в анализе требований проекта, интерфейса или структуры БД.
Бывает сложно понять, когда пора переходить от планирования, анализа требований и дизайна к реализации и тестированию.
Вместо чрезмерного анализа и спекуляций используйте пошаговое развитие.
Классы, контролирующие множество других классов, имеющие много зависимостей и много ответственности.
Классы Бога разрастаются до тех пор, пока не превращаются в кошмар поддержки. Они нарушают принцип одной ответственности, с ними тяжело проводить юнит-тесты, отлаживать и документировать.
Разбивайте ответственность по мелким классам, с единственной ответственностью, которая чётко определена, юнит-тестируется и задокументирована.
Ищите классы с именами «manager», «controller», «driver», «system» или «engine». Подозрительно смотрите на классы, импортирующие или зависящие от других, контролирующие слишком много других классов или имеющие много методов, занимающихся чем-то, не связанным с основной деятельностью.
Проекты, запросы и количество программистов растет, и маленькие специализированные классы медленно превращаются в классы Бога. Рефакторинг таких классов может занять впоследствии много времени.
Избегайте больших классов со слишком большими ответственностями и зависимостями
Вера в то, что увеличение количества классов усложняет дизайн, приводит к страху перед добавлением новых классов или разбитием больших классов на мелкие.
Добавление классов уменьшает сложность. Распутать несколько мелких клубков пряжи проще, чем один крупный. Несколько простых в поддержке и документировании классов предпочтительнее одного большого и сложного класса со множеством зависимостей (класс Бога).

Замечайте те места, в которых добавление классов может упростить дизайн и разрубайте ненужные связи между частями кода
А теперь сравните со следующим:
Пример достаточно очевидный, но он демонстрирует, что большие классы с условной или сложной логикой обычно стоит разбивать на более простые. В итоговом коде будет больше классов, но они будут проще.
Добавление классов – не панацея. Упрощение дизайна разбиванием больших классов требует глубокого анализа областей ответственности и требований.
Большое число классов – не признак плохого дизайна
Тенденция сложных программных систем изобретать заново возможности платформы, на которой они работают, или языка, на котором они написаны.
Задачи уровня платформы – планировка задач, дисковый буфер и т.д. непросто реализовать правильно. В плохих решениях часто встречаются узкие места и ошибки, особенно с ростом системы. Воссоздание альтернативных конструкций для того, что уже возможно сделать при помощи языка, приводит к усложнению кода и к подъёму кривой обучения для новичков. Также это ограничивает пользу от рефакторинга и инструментов для анализа кода.
Используйте имеющиеся возможности и свойства платформы или операционки. Не создавайте языковые конструкции, конкурирующие с существующими (особенно, если вы не привыкли к новому языку и скучаете по старому).
Использование базы данных как очереди задач. Переизобретение дискового буфера вместо использования возможностей операционки. Написание менеджера задач для веб-сервера на PHP. Определение макроса в С для поддержки конструкций, напоминающих Python.
В очень редких случаях всё-таки может потребоваться воссоздание имеющихся у платформы возможностей (JVM, Firefox, Chrome и т.д.).
Избегайте переизобретения тех возможностей, которые уже есть в операционке или платформе.
Использование безымянных чисел или строковых констант вместо именованных констант в коде.
Без поясняющего имени семантика числа или строки скрыта от нас. Это усложняет понимание кода, а необходимость поменять константу может привести к ошибкам. Рассмотрим следующий код:
Что это за числа? Допустим, первое – ширина, второе – высота. Если в дальнейшем придётся поменять ширину на 800, то поиском и заменой можно будет зацепить случайно и такую же высоту.
Использование неименованных строковых констант не так подвержено ошибкам, но затрудняет возможную локализацию, и также может привести к ошибкам из-за использования одинаковых строк в разных смыслах. Слово «точка» может обозначать пиксель, знак препинания или окончание рассуждений – в результате, поиск и замена слова приведут к ошибкам. Этого можно избежать, заменяя строки механизмом получения строк извне.
Используйте именованные константы, средства для получения ресурсов извне
Даны выше. Такой анти-паттерн легко распознать.
Иногда сложно сказать, будет ли используемое число магическим. 0 в языках, в которых индексирование начинается с нуля. 100 для подсчёта процентов, 2 для проверки чётности и т.д.
Избегайте использования чисел или строковых констант без имён и пояснений.
Принятие решений на основании одних лишь чисел.
Числа – это хорошо. Первые два анти-паттерна, преждевременную оптимизацию и байкшеддинг, надо избегать при помощи A/B-тестирования и получения неких количественных результатов. Но основываться только на числах опасно. К примеру, числа переживают те модели, в которых они имели смысл, или же модели устаревают и перестают корректно отражать реальность. Это приводит к плохим решениям, в особенности, когда они принимаются автоматически (искажение автоматизации).

Ещё одна проблема в использовании чисел для принятия решений (а не для простого информирования) – процессами измерения можно манипулировать для достижения желаемой цели (эффект наблюдателя и ожиданий). В сериале The Wire красочно показано, как полицейское управление и система образования перешли от осмысленных целей к игре с числами. Следующий график иллюстрирует этот вопрос. На нём изображено распределение оценок по тесту, в котором минимальная оценка для прохождения теста – 30.
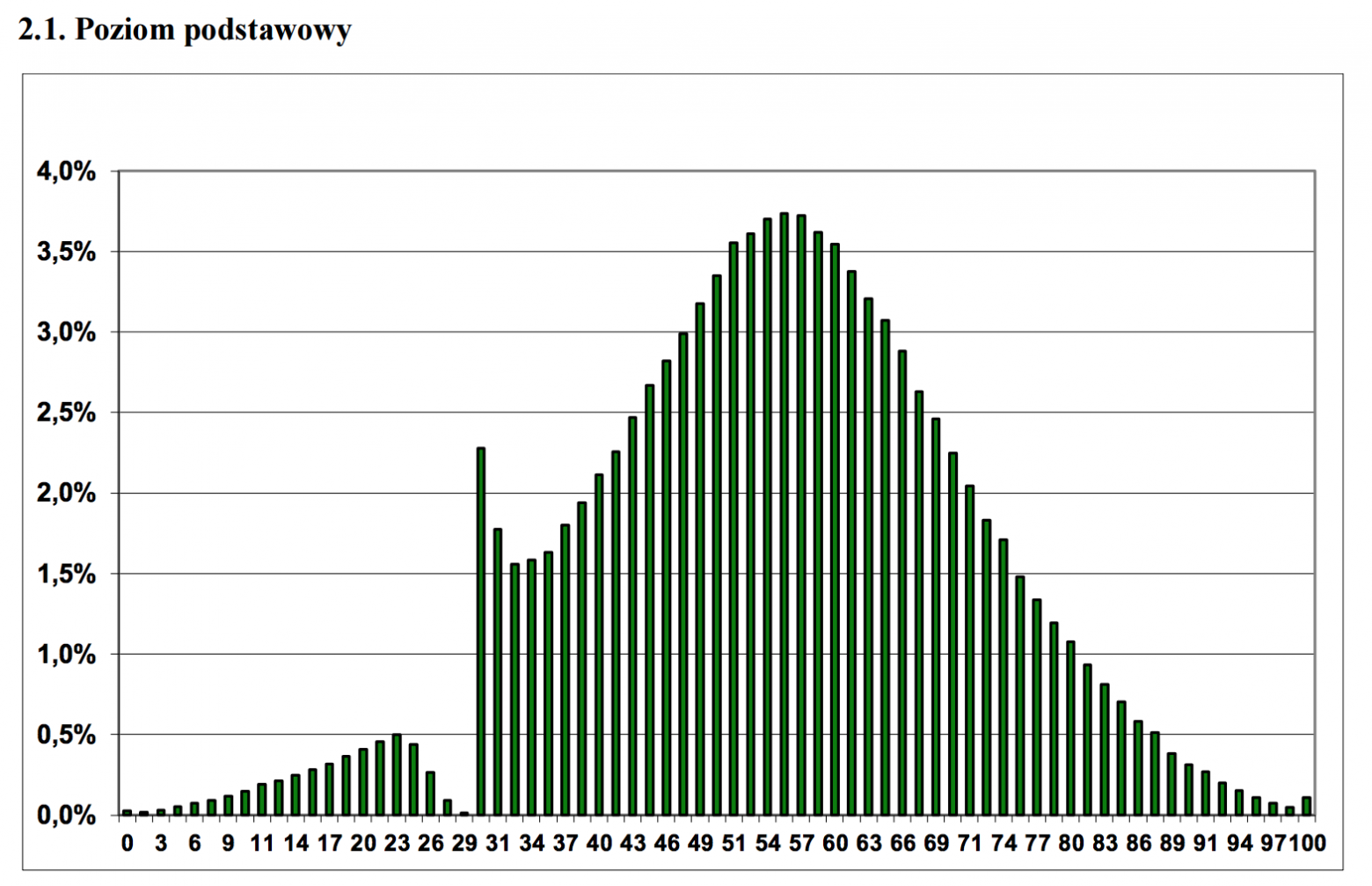
Используйте измерение и числа мудро, не слепо.
Использование количества строк, количества коммитов и т.д. для оценки эффективности программистов. Измерение эффективности сотрудника по количеству часов, проведённых в офисе.
Чем больше фирма, тем больше требуется принимать решений, тем сильнее их автоматизация и вера в слепые цифры начинает проникать в процесс их принятия.
Используйте числа для информирования, а не как основу для принятия решений
Бесполезные классы без зависимостей, используются для вызова методов другого класса или просто добавляют ненужный слой абстракции.
Полтергейстные классы добавляют сложность, код для поддержки и тестирования, и делают код менее читаемым. Надо определить, что делает полтергейст (а обычно – почти ничего), и натренироваться мысленно заменять его использование тем классом, который реально работает.
Не пишите бесполезные классы и избавляйтесь от них при возможности.
Несколько лет назад при работе над дипломом я обучал первокурсников программированию на Java. Для одной из лабораторных работ мне дали материал по теме стэка и использования связанных списков. И мне дали «решение». Вот такое это было решение, почти дословно:
Представьте моё замешательство, когда я его читал, пытался понять, зачем нужен класс LabStack и что студенты поймут из такого бесполезного упражнения. Если это ещё непонятно, этот класс не делает вообще ничего. Он просто передаёт вызовы в объект LinkedList. Также он меняет имена нескольких методов (makeEmpty вместо clear), что ещё больше запутывает. Логика проверки ошибок не нужна, поскольку методы в LinkedList делают то же самое (просто через другое исключение, NoSuchElementException). По сию пору не могу понять, что было в голове у авторов этого материала.
На первый взгляд, совет будет противоположен совету в разделе «Страх перед добавлением классов». Важно понимать, когда класс выполняет ценную роль и упрощает дизайн, а когда он бесполезным образом увеличивает сложность.
Избегайте классов без реальной ответственности.
Некоторые из них напрямую или косвенно связаны с когнитивными искажениями человеческого сознания – в этих случаях я даю ссылки на соответствующие вики-статьи. Также интересен список известных когнитивных искажений.
1 Преждевременная оптимизация
В 97% случаев надо забыть об эффективности малых частей программы: преждевременная оптимизация – корень всех зол. Но в 3% случаев об оптимизации забывать не нужно.
Дональд Кнут
Хотя никогда зачастую лучше, чем прямо сейчас
Тим Питерс, Зен языка Python
Что это
Оптимизация, проводимая до того, как у вас есть вся информация, необходимая для принятия взвешенных решений по поводу того, где и как нужно её проводить.
Почему плохо
На практике сложно предсказать, где встретится узкое место. Попытки навести оптимизацию до получения эмпирических результатов приведут к усложнению кода и появлению ошибок, а пользы не принесут.
Как избежать
Сначала пишите чистый, читаемый, работающий код, используя известные и проверенные алгоритмы и инструменты. При необходимости используйте инструменты для профилирования для поиска узких мест. Полагайтесь на измерения, а не на догадки и предположения.
Примеры и признаки
Кэширование до того, как провели профилирование. Использование сложных и недоказанных эвристических правил вместо математически верных алгоритмов. Выбор новых, непротестированных фреймворков, которые могут повести себя плохо под нагрузкой.
В чём сложность
Сложность в том, чтобы знать, когда оптимизация будет преждевременной. Важно заранее оставлять место для роста. Нужно выбирать решения и платформы, которые позволят легко оптимизировать и расти. Также иногда можно использовать преждевременную оптимизацию в качестве оправдания за плохой код. Например, использование алгоритма O(n2) просто потому, что алгоритм O(n) сложнее.
Слишком длинно, не читал
Сначала профилирование, потом оптимизация. Не меняйте простоту на эффективность, пока об этом не заявят эмпирически полученные данные.
2 Байкшеддинг
(прим.перев. – англосаксы любят придумывать глаголы. Этот термин также называется «Закон тривиальности Паркинсона», и появился после того, как этот Паркинсон обратил внимание, как люди любят тратить время на совещаниях на всякую ерунду, вместо того, чтобы обсуждать насущные проблемы. Конкретно, проектировщики атомной электростанции очень долго спорили, какой материал должен пойти на навес для велосипедов – bike-shed).
Периодически мы прерывали разговор, чтобы обсудить типографику и цвет страницы. После каждого обсуждения мы голосовали. Я думал, что эффективнее всего будет проголосовать за тот же цвет, который мы выбрали на предыдущей встрече, но я всегда оказывался в меньшинстве. Наконец, мы выбрали красный (а в итоге получился синий).
Ричард Фейнман, «Почему вас заботит, что о вас думают другие?»

Что это
Склонность тратить время на обсуждение тривиальных и субъективных вещей.
Почему это плохо
Трата времени. Подробное письмо от Пола-Хенинга Кэмпа по этому поводу.
Как избежать
Напоминайте другим членам команды об этой склонности, и о том, что в этих случаях главное – быстрее принять решение (бросить монетку, проголосовать, и т.п.). Если речь идёт о вещах вроде пользовательского интерфейса, обратитесь к A/B тестированию, вместо того, чтобы обсуждать это в команде.
Примеры и признаки
Часы или дни проводятся в обсуждениях цвета фона или расположения кнопки в интерфейсе, или использования табуляции вместо пробелов в коде.
В чём сложность
Байкшеддинг легче заметить и предотвратить, чем преждевременную оптимизацию. Замечайте время, требуемое для принятия решений и сопоставляйте его со сложностью задачи.
Слишком длинно, не читал
Не тратьте много времени на простейшие решения.
3 Аналитический паралич
Желание предсказать что-либо, нежелание действовать, когда это было бы просто и эффективно, недостаток ясности мысли… Всё это свойства, заставляющие бесконечно повторять историю.
Уинстон Черчилль, Дебаты в парламенте
Сейчас лучше, чем никогда
Тим Питерс, Зен языка Python
Что это
Переизбыток анализа до такой степени, что прогресс и действия останавливаются.
Почему плохо
Переизбыток анализа может замедлить или остановить прогресс. В тяжёлых случаях, результаты анализа становятся не нужны к тому моменту, когда они готовы, или даже проект вообще не покидает фазу анализа. Часто кажется, что чем больше у вас информации, тем больше это поможет принятию тяжёлого решения. См. информативное искажение и иллюзию допустимости.
Как избежать
Наблюдайте за итерациями и улучшениями. Каждая итерация даёт обратную связь и информацию, которую можно использовать для более осмысленного анализа. Без этой информации анализ будет лишь спекулятивным.
Примеры и признаки
Месяцы и годы, проведённые в анализе требований проекта, интерфейса или структуры БД.
В чём сложность
Бывает сложно понять, когда пора переходить от планирования, анализа требований и дизайна к реализации и тестированию.
Слишком длинно, не читал
Вместо чрезмерного анализа и спекуляций используйте пошаговое развитие.
4 Класс Бога
Простое лучше сложного
Тим Питерс, Зен языка Python
Что это
Классы, контролирующие множество других классов, имеющие много зависимостей и много ответственности.
Почему плохо
Классы Бога разрастаются до тех пор, пока не превращаются в кошмар поддержки. Они нарушают принцип одной ответственности, с ними тяжело проводить юнит-тесты, отлаживать и документировать.
Как избежать
Разбивайте ответственность по мелким классам, с единственной ответственностью, которая чётко определена, юнит-тестируется и задокументирована.
Примеры и признаки
Ищите классы с именами «manager», «controller», «driver», «system» или «engine». Подозрительно смотрите на классы, импортирующие или зависящие от других, контролирующие слишком много других классов или имеющие много методов, занимающихся чем-то, не связанным с основной деятельностью.
В чем сложность
Проекты, запросы и количество программистов растет, и маленькие специализированные классы медленно превращаются в классы Бога. Рефакторинг таких классов может занять впоследствии много времени.
Слишком длинно, не читал
Избегайте больших классов со слишком большими ответственностями и зависимостями
5 Страх перед добавлением классов
Разреженное лучше, чем плотное
Тим Питерс, Зен языка Python
Что это
Вера в то, что увеличение количества классов усложняет дизайн, приводит к страху перед добавлением новых классов или разбитием больших классов на мелкие.
Почему это плохо
Добавление классов уменьшает сложность. Распутать несколько мелких клубков пряжи проще, чем один крупный. Несколько простых в поддержке и документировании классов предпочтительнее одного большого и сложного класса со множеством зависимостей (класс Бога).

Как избежать
Замечайте те места, в которых добавление классов может упростить дизайн и разрубайте ненужные связи между частями кода
Примеры и признаки
class Shape:
def __init__(self, shape_type, *args):
self.shape_type = shape_type
self.args = args
def draw(self):
if self.shape_type == "круг":
center = self.args[0]
radius = self.args[1]
# Draw a circle...
elif self.shape_type == "квадрат":
pos = self.args[0]
width = self.args[1]
height = self.args[2]
# Draw rectangle...
А теперь сравните со следующим:
class Shape:
def draw(self):
raise NotImplemented("Подклассам Shape необходимо определить метод 'draw'.")
class Circle(Shape):
def __init__(self, center, radius):
self.center = center
self.radius = radius
def draw(self):
# Нарисовать круг...
class Rectangle(Shape):
def __init__(self, pos, width, height):
self.pos = pos
self.width = width
self.height = height
def draw(self):
# Нарисовать квадрат...
Пример достаточно очевидный, но он демонстрирует, что большие классы с условной или сложной логикой обычно стоит разбивать на более простые. В итоговом коде будет больше классов, но они будут проще.
В чем сложность
Добавление классов – не панацея. Упрощение дизайна разбиванием больших классов требует глубокого анализа областей ответственности и требований.
Слишком длинно, не читал
Большое число классов – не признак плохого дизайна
6 Эффект внутренней платформы
Те, кто не понимает Unix, обречены на переизобретение его плохих копий
Генри Спенсер
Любая достаточно сложная программа на Си или Фортране содержит заново написанную, неспецифицированную, глючную и медленную реализацию половины языка Common Lisp.
Десятое правило Гринспена
Что это
Тенденция сложных программных систем изобретать заново возможности платформы, на которой они работают, или языка, на котором они написаны.
Почему это плохо
Задачи уровня платформы – планировка задач, дисковый буфер и т.д. непросто реализовать правильно. В плохих решениях часто встречаются узкие места и ошибки, особенно с ростом системы. Воссоздание альтернативных конструкций для того, что уже возможно сделать при помощи языка, приводит к усложнению кода и к подъёму кривой обучения для новичков. Также это ограничивает пользу от рефакторинга и инструментов для анализа кода.
Как избежать
Используйте имеющиеся возможности и свойства платформы или операционки. Не создавайте языковые конструкции, конкурирующие с существующими (особенно, если вы не привыкли к новому языку и скучаете по старому).
Примеры и признаки
Использование базы данных как очереди задач. Переизобретение дискового буфера вместо использования возможностей операционки. Написание менеджера задач для веб-сервера на PHP. Определение макроса в С для поддержки конструкций, напоминающих Python.
В чём сложность
В очень редких случаях всё-таки может потребоваться воссоздание имеющихся у платформы возможностей (JVM, Firefox, Chrome и т.д.).
Слишком длинно, не читал
Избегайте переизобретения тех возможностей, которые уже есть в операционке или платформе.
7 Магические числа и строчки
Явное лучше, чем неявное
Тим Питерс, Зен языка Python
Что это
Использование безымянных чисел или строковых констант вместо именованных констант в коде.
Почему это плохо
Без поясняющего имени семантика числа или строки скрыта от нас. Это усложняет понимание кода, а необходимость поменять константу может привести к ошибкам. Рассмотрим следующий код:
def create_main_window():
window = Window(600, 600)
# и т.д....
Что это за числа? Допустим, первое – ширина, второе – высота. Если в дальнейшем придётся поменять ширину на 800, то поиском и заменой можно будет зацепить случайно и такую же высоту.
Использование неименованных строковых констант не так подвержено ошибкам, но затрудняет возможную локализацию, и также может привести к ошибкам из-за использования одинаковых строк в разных смыслах. Слово «точка» может обозначать пиксель, знак препинания или окончание рассуждений – в результате, поиск и замена слова приведут к ошибкам. Этого можно избежать, заменяя строки механизмом получения строк извне.
Как избежать
Используйте именованные константы, средства для получения ресурсов извне
Примеры и признаки
Даны выше. Такой анти-паттерн легко распознать.
В чем сложность
Иногда сложно сказать, будет ли используемое число магическим. 0 в языках, в которых индексирование начинается с нуля. 100 для подсчёта процентов, 2 для проверки чётности и т.д.
Слишком длинно, не читал
Избегайте использования чисел или строковых констант без имён и пояснений.
8 Управление через количество
Измерение прогресса программиста по количеству строк кода – то же самое, что измерение прогресса строительства самолёта по весу.
Билл Гейтс
Что это
Принятие решений на основании одних лишь чисел.
Почему это плохо
Числа – это хорошо. Первые два анти-паттерна, преждевременную оптимизацию и байкшеддинг, надо избегать при помощи A/B-тестирования и получения неких количественных результатов. Но основываться только на числах опасно. К примеру, числа переживают те модели, в которых они имели смысл, или же модели устаревают и перестают корректно отражать реальность. Это приводит к плохим решениям, в особенности, когда они принимаются автоматически (искажение автоматизации).

Ещё одна проблема в использовании чисел для принятия решений (а не для простого информирования) – процессами измерения можно манипулировать для достижения желаемой цели (эффект наблюдателя и ожиданий). В сериале The Wire красочно показано, как полицейское управление и система образования перешли от осмысленных целей к игре с числами. Следующий график иллюстрирует этот вопрос. На нём изображено распределение оценок по тесту, в котором минимальная оценка для прохождения теста – 30.
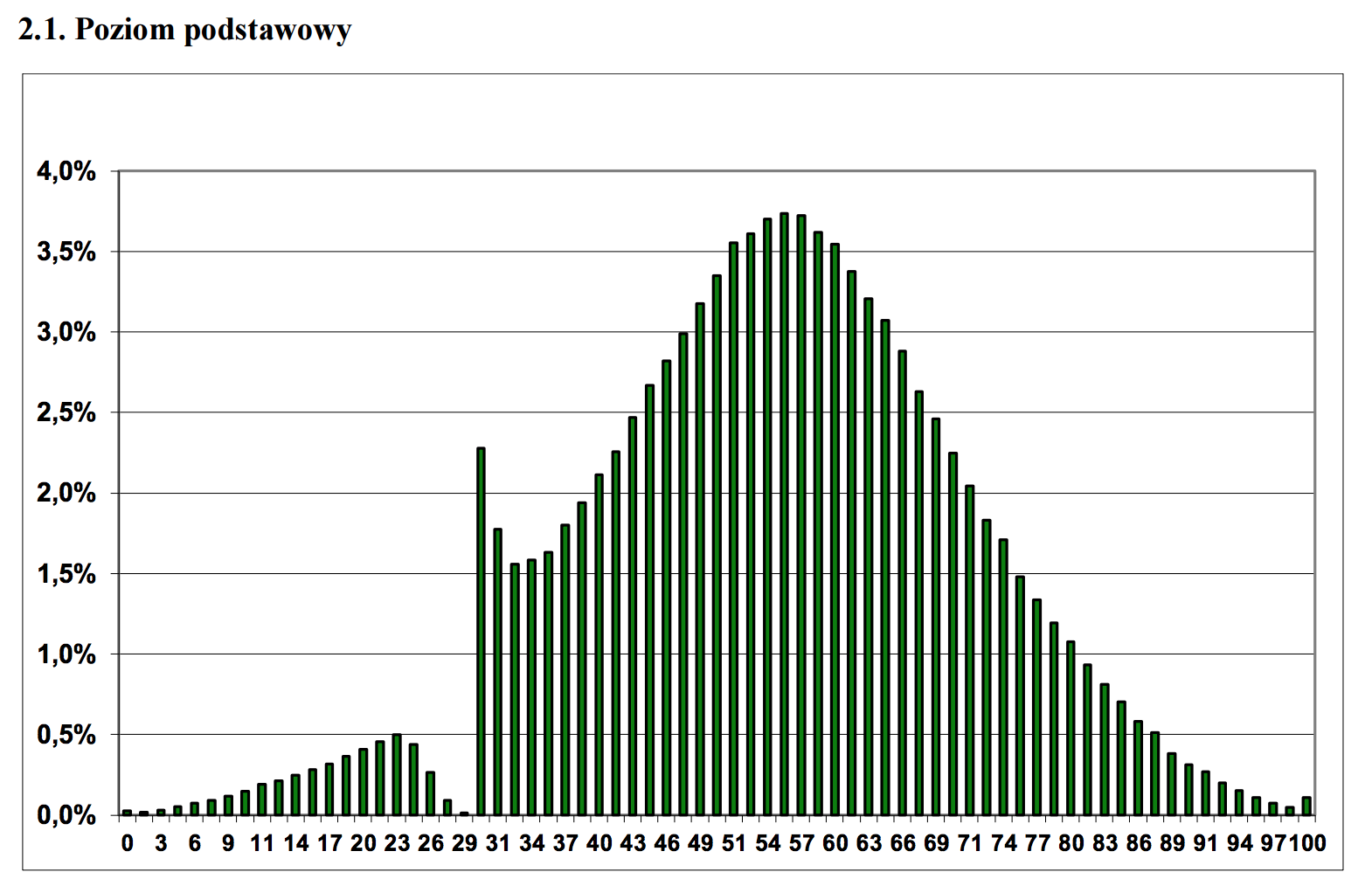
Как избежать
Используйте измерение и числа мудро, не слепо.
Примеры и признаки
Использование количества строк, количества коммитов и т.д. для оценки эффективности программистов. Измерение эффективности сотрудника по количеству часов, проведённых в офисе.
В чём сложность
Чем больше фирма, тем больше требуется принимать решений, тем сильнее их автоматизация и вера в слепые цифры начинает проникать в процесс их принятия.
Слишком длинно, не читал
Используйте числа для информирования, а не как основу для принятия решений
9 Бесполезные (полтергейстные) классы
По-видимому, совершенства достигают не тогда, когда нечего добавить, а тогда, когда нечего отнять.
Антуан де Сент-Экзюпери
Что это
Бесполезные классы без зависимостей, используются для вызова методов другого класса или просто добавляют ненужный слой абстракции.
Почему плохо
Полтергейстные классы добавляют сложность, код для поддержки и тестирования, и делают код менее читаемым. Надо определить, что делает полтергейст (а обычно – почти ничего), и натренироваться мысленно заменять его использование тем классом, который реально работает.
Как избежать
Не пишите бесполезные классы и избавляйтесь от них при возможности.
Примеры и признаки
Несколько лет назад при работе над дипломом я обучал первокурсников программированию на Java. Для одной из лабораторных работ мне дали материал по теме стэка и использования связанных списков. И мне дали «решение». Вот такое это было решение, почти дословно:
import java.util.EmptyStackException;
import java.util.LinkedList;
public class LabStack<T> {
private LinkedList<T> list;
public LabStack() {
list = new LinkedList<T>();
}
public boolean empty() {
return list.isEmpty();
}
public T peek() throws EmptyStackException {
if (list.isEmpty()) {
throw new EmptyStackException();
}
return list.peek();
}
public T pop() throws EmptyStackException {
if (list.isEmpty()) {
throw new EmptyStackException();
}
return list.pop();
}
public void push(T element) {
list.push(element);
}
public int size() {
return list.size();
}
public void makeEmpty() {
list.clear();
}
public String toString() {
return list.toString();
}
}
Представьте моё замешательство, когда я его читал, пытался понять, зачем нужен класс LabStack и что студенты поймут из такого бесполезного упражнения. Если это ещё непонятно, этот класс не делает вообще ничего. Он просто передаёт вызовы в объект LinkedList. Также он меняет имена нескольких методов (makeEmpty вместо clear), что ещё больше запутывает. Логика проверки ошибок не нужна, поскольку методы в LinkedList делают то же самое (просто через другое исключение, NoSuchElementException). По сию пору не могу понять, что было в голове у авторов этого материала.
В чём сложность
На первый взгляд, совет будет противоположен совету в разделе «Страх перед добавлением классов». Важно понимать, когда класс выполняет ценную роль и упрощает дизайн, а когда он бесполезным образом увеличивает сложность.
Слишком длинно, не читал
Избегайте классов без реальной ответственности.
