Технология распределения нагрузки между несколькими серверами сравнительно небольшой мощности является стандартной возможностью СУБД Caché уже достаточно давно. В её основе лежит протокол распределённого кэша ECP (Enterprise Cache Protocol); здесь имеется в виду именно «cache» («кэш»), а не «Caché» («кашЭ»). ECP открывает богатые возможности для горизонтального масштабирования прикладной системы, обеспечивая высокую производительность при не менее высокой устойчивости к отказам, оставляя при этом бюджет проекта в достаточно скромных рамках. К достоинствам сети ECP справедливо будет отнести и возможность сокрытия особенностей её архитектуры в недрах конфигурации СУБД, так что прикладные программы, изначально разработанные для традиционной (вертикальной) архитектуры, как правило, легко переносятся в горизонтальную ECP-среду. Эта лёгкость настолько завораживает, что хочется, чтобы так было всегда. Например, все привыкли к возможности управлять не только текущим, но и «чужими» процессами Caché: системная переменная $Job и связанные с ней функции и классы в умелых руках позволяют «творить чудеса». Стоп, но теперь процессы могут оказаться на разных серверах Caché… Ниже — о том, как удалось добиться почти такой же прозрачности в управлении процессами в среде ECP, как и без неё.
Прежде чем углубляться в тему, вспомним основные понятия, связанные с ECP.
ECP, или протокол распределённого кэша, лежит в основе взаимодействия серверов данных и серверов приложений. Он работает поверх TCP/IP, обеспечивающего надёжную транспортировку пакетов. Протокол ECP является собственностью фирмы InterSystems.
Серверы данных (СБД), иногда называемые серверами ECP, – это обычные установки Caché, на которых находятся локальные базы данных приложения. Глагол «находятся» не стоит понимать буквально: базы данных могут физически находиться, например, на сетевых системах хранения данных, доступных через iSCSI или FC; важно, что СУБД считает их локальными.
Серверы приложений (СП), иногда называемые клиентами ECP, – это обычные установки Caché, на которых работают процессы, обслуживающие пользователей прикладной системы. Иными словами, на серверах приложений выполняется прикладной код (отсюда их название). Поскольку это обычные установки Caché, на них имеется стандартный набор системных локальных баз данных: CACHESYS, CACHELIB, CACHETEMP и т.д. Это важно, но не это главное. Гораздо важнее, что прикладные БД, локальные по отношению к серверам данных, монтируются как удалённые базы данных на серверах приложения. В общем виде схема взаимодействия показана на рисунке.
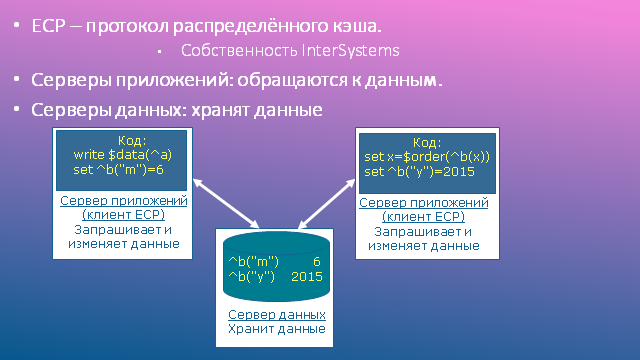
Основные компоненты ECP
Что такое кэш данных, надеюсь, объяснять не надо. Распределённый кэш, фигурирующий в названии протокола ECP, в общем-то не более, чем метафора: кэш, конечно же, всегда локален. Но если на сервере приложений происходит чтение узла удалённого глобала, соответствующий блок копируется из кэша сервера данных в кэш сервера приложений, так что повторные обращения к соседним узлам того же глобала будут происходить локально, без повторного обращения к сети и серверу данных. Чем дольше работает система, тем актуальнее становится наполнение локального кэша на СП (как говорят, тем лучше он «разогревается»), и тем реже происходят операции сетевого доступа. В идеале, повторных чтений с сервера данных требуют лишь изменённые данные; возникает иллюзия существования распределённого (между серверами) кэша.
Запись происходит несколько сложнее: запрос на запись уходит на сервер данных. Сервер данных шлёт в ответ команду «вычеркнуть блок из кэша», причём только тем серверам приложений, которые ранее прочли в свой кэш предыдущее состояние этого блока. Важно, что сам изменённый блок принудительно не шлётся, так как, возможно, он более никому не нужен. Если же в нём вновь возникает потребность, блок заново запрашивается с сервера данных и вновь попадает в локальный кэш сервера приложений, как это было описано ранее.
Рекламная пауза: немного о плюсах горизонтального масштабирования средствами ECP. Представьте, что требуется спланировать систему на 10000 пользователей, и известно, что на каждые 50 пользователей требуются вычислительные ресурсы в количестве 1 ядра CPU и 10 GB RAM. Сравним альтернативы. В таблице СБД&СП – традиционный сервер Caché (сервер данных и приложений «в одном флаконе»). Из соображений устойчивости к отказам их необходимо запланировать два.
В схеме с горизонтальным масштабированием из тех же соображений планируем два сервера данных, но думаю никого не надо убеждать в ценовом преимуществе этой схемы над предыдущей… В качестве бонуса получаем замечательную особенность совместного использования ECP и «зеркала» (Mirroring): при переключении серверов данных – узлов зеркальной пары – пользователи серверов приложений испытывают лишь краткую паузу в работе (измеряемую секундами), после чего их сеансы продолжаются. В вертикальной схеме клиентские процессы подключаются непосредственно к серверу данных, поэтому при переключении серверов разрывы пользовательских сеансов неизбежны.
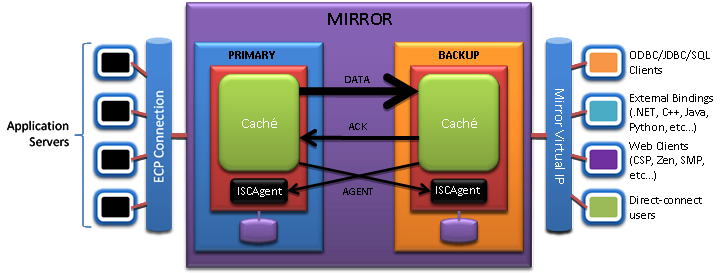
Совместное использования ECP и «зеркала»
Вспомним, что на каждом сервере приложений имеются и локальные БД, поэтому хранение промежуточных данных естественным образом перекладывается на эти БД. Такая работа может быть достаточно интенсивной, а значит, вовлечение в неё большого числа даже недорогих дисков может разгрузить центральную систему хранения данных (СХД), уменьшив время обслуживания (await) дисковых операций, без задействования ещё одной дорогостоящей СХД для промежуточных данных.
«Нормальные» программы работают в областях, следовательно, вам не придётся менять конструкции вида ^|"^^c:\intersystems\cache\mgr\qmsperf "|QNaz на ^|"^PERF^c:\intersystems\cache\mgr\qmsperf"|QNaz. Все эти частности упрятаны в конфигурации Caché в определения удалённого сервера данных и удалённой базы данных. Даже если иногда приходится обращаться к глобалам областей, отличных от текущей области процесса, синтаксис подобных обращений (^|«qmsperf»|QNaz) остаётся прежним.
Семантика работы с глобальными данными также практически не меняется, просто работая с локальными БД, мы обычно о ней не задумываемся. Перечислю основные положения:
• Все операции разделяются на синхронные (все функции чтения: $Get, $Order и т.д., а также Lock и $Increment) и асинхронные (запись данных: Set, Kill и т.д.). Дальнейшее выполнение программы не требует ожидания завершения асинхронной операции. Для синхронных операций это не так. В случае ECP они могут требовать дополнительного обращения к серверу данных, если блок данных отсутствует в локальном кэше.
• Синхронные операции не ждут завершения асинхронных операций, инициированных тем же сервером приложений.
• Команда Lock ждёт завершения записи данных, начатой предыдущим хозяином блокировки.
• Истечение таймаута Lock не гарантирует, что блокировкой владеет кто-то другой.
А вот несколько непривычных моментов:
• Строки длиннее половины размера блока не кэшируются на серверах приложений. На самом деле, этот порог несколько ниже, для 8 KB-блоков – 3900 байт. Такое решение было принято разработчиками, чтобы не забивать кэш BLOBами и CLOBами: известно, что такие данные обычно пишутся один раз и впоследствии крайне редко читаются. К сожалению, это решение негативно сказалось на обработке bitmap-индексов, которые тоже, как правило, являются длинными строками. Если вы их используете, придётся либо уменьшать размер chunk-а, либо увеличивать размер блока; оптимальный выбор можно сделать лишь на основе результатов тестирования.
• Присваивание
set i=$Increment(^a)
может оказаться дороже, чем его функционально близкий аналог:
lock +^a set (i,^a)=^a+1 lock -^a
Дело в том, что функция $Increment всегда выполняется на сервере данных, следовательно, ожидание завершения путешествия пакетов «туда-обратно» неизбежно, а блокировка (lock) вызывает подобный эффект, лишь когда её запрашивают процессы с различных серверов приложений.
• Необходимо обрабатывать ошибки <NETWORK>. Такие ошибки возникают, когда сервер приложений не может восстановить утраченное ECP-соединение в течение Time to wait for recovery (по умолчанию – 1200 секунд). Правильный способ обработки: откатить начатую транзакцию и попробовать заново.
Освежив в памяти основные концепции ECP, перейдём к основной теме статьи. Управление процессами будем трактовать в широком смысле. Реальные потребности прикладных программистов, с которыми приходится сталкиваться, и системные средства, которые имеются для их удовлетворения «прямо из коробки», см. ниже.
Ответом на эти «вызовы» стала разработка API управления процессами, реализованного в виде класса Util.Proc.
Чтобы вам интереснее было читать дальше, приведу пару несложных примеров кода с использованием API.
• Вывести список процессов с указанием области и имени пользователя медицинской информационной системы (МИС), помечая «*» собственный (текущий) процесс:
set cnt=0
for {
set proc=##class(Util.Proc).NextProc(proc,.sc) quit:proc=""||'sc // следующий процесс
write proc_$select(##class(Util.Proc).ProcIsMy(proc):"*",1:"") // помечаем себя «*»
write " область: "
write ##class(Util.Proc).GetProcProp(proc,"NameSpace") // свойство процесса: текущая область
write " пользователь: "
write ##class(Util.Proc).GetProcVar(proc,$name(qARM("User"))),! // переменная процесса: имя пользователя МИС
set cnt=cnt+1
}
write "Всего: "_cnt_" процессов."
• Удалить процесс, отличный от текущего, если он выполняется под тем же именем пользователя МИС (для исключения повторного входа пользователей):
if '##class(Util.Proc).ProcIsMy(proc),
##class(Util.Proc).GetProcVar(proc,$name(qARM("User")))=$name(qARM("User")) {
set res=##class(Util.Proc).KillProc(proc)
}
При разработке API необходимо было выбрать способ адресации процессов в сети ECP, причём хотелось получить:
• уникальность адреса в локальной сети,
• возможность непосредственного использования адреса с минимальными преобразованиями,
• легко читаемый формат.
Для адресации сервера в сети можно использовать его имя (hostname) или IP-адрес. Выбор имени в качестве идентификатора хоть и заманчив, но накладывает дополнительные требования к безупречности работы службы имён. Поскольку подобные требования обычно не предъявляются при настройке конфигурации Caché, не хотелось вводить новых ограничений. К тому же в различных ОС hostname может иметь разный формат, что затруднит последующий разбор дескриптора процесса. Исходя из этих соображений, я предпочёл использовать IPv4-адрес.
Для идентификации установки Caché на сервере можно использовать её имя («CACHE», «CACHEQMS», etc.) или номер порта суперсервера (1972, 56773, etc.). Но подключиться к установке Caché по её имени нельзя, поэтому выбираем порт.
В итоге, в качестве дескриптора (уникального идентификатора) процесса было решено использовать строку в формате децимального номера: xx.yy.zz.uu.Port.PID, где
xx.yy.zz.uu – IPv4 адрес сервера Caché,
Port – tcp-порт суперсервера Caché,
PID – номер процесса на сервере Caché.
Примеры корректных дескрипторов процессов:
192.168.11.19.56773.1760 – процесс с PID=1760 на установке Caché с IP=192.168.11.19 и Port=56773.
192.168.11.77.1972.62801 – процесс с PID=62801 на установке Caché с IP=192.168.11.77 и Port=1972.
В результате был разработан класс Util.Proc, открытые методы которого перечислены ниже. Все методы являются методами класса (ClassMethod).
Сопоставляя сводку методов с таблицей Основные прикладные потребности в управлении процессами, видим, что удалось их удовлетворить теперь уже и в сетевой среде. Метод CCM() был добавлен позже: в процессе переноса нашего приложения (региональной медицинской информационной системы qMS) в среду ECP выяснилось, что некоторые функциональные блоки удобнее и правильнее выполнять непосредственно на сервере данных. Причины могут быть разные:
• Желание избежать разовой перекачки большого объёма данных на сервер приложений, характерной, например, при генерации отчёта.
• Необходимость централизованно обслуживать некий общий ресурс, например, очереди обмена сообщениями с другой системой (в нашем случае – с HealthShare).
Замечу, что большинство методов API предназначены для работы в среде ECP. Без ECP они по-прежнему работоспособны, но принимают/возвращают лишь малоосмысленные дескрипторы процессов вида 127.0.0.1.Port.pid. Исключение составляют методы, ориентированные на работу с сервером данных: RunJob(), CheckJob(), CCM(), так как они возвращают/принимают не дескриптор процесса (proc), а его номер (pid) на сервере данных. Поэтому эти методы сделаны универсальными с точки зрения прикладного программиста: их интерфейс одинаков как в среде ECP, так и без неё, хотя работают они, конечно, по-разному.
Необходимо было выбрать метод взаимодействия между процессами, работающими на разных серверах. Рассматривались следующие альтернативы:
• Класс %SYSTEM.Event.
o Официально не работает в сети, поэтому поддержка его сетевой работы может быть прекращена InterSystems в любой момент.
• Собственный TCP-сервер.
o В принципе, хорошая идея.
o Необходимо задействовать дополнительный TCP-порт (кроме порта супер-сервера), что неизбежно влечёт дополнительные усилия по установке и настройке помимо стандартных настроек Caché. А хотелось обойтись минимумом настроек.
• Web-сервисы.
• Класс %Net.RemoteConnection. Для тех, кто забыл: этот класс обеспечивает удалённое выполнение кода на других серверах, используя тот же протокол, что и клиенты сервиса %Service_Bindings. Если в системе этот сервис уже задействован для подключения клиентов, то никакие дополнительные настройки не требуются, а это как раз наш случай. Накладные расходы на обмен данными незначительны, как правило, он меньше, чем в случае web-сервисов.
Исходя из этих соображений, я выбрал %Net.RemoteConnection. Из его недостатков наиболее серьёзный, на мой взгляд, состоит в том, что он не позволяет возвращать строки длиннее 32KB, но это сильно не помешало.
Другая не менее интересная проблема, с которой пришлось столкнуться: как определить, в сети работает код или нет? Ответ на этот вопрос необходим как для внутренних нужд API (чтобы правильно формировать дескрипторы процессов), так и для написания метода IsECP(), весьма востребованного прикладными программистами. Причина такой популярности довольно очевидна: желающих переписывать участки своего кода, связанного с взаимодействием между процессами, на некоем универсальном API, оказалось не очень много (хотя такое API и было реализовано). Гораздо проще и естественнее оказалось добавить ветку кода для ECP. Но как определить, в какой среде работает код? Рассматривались варианты:
1. Основная база данных области является удалённой.
2. 1 или (основная БД области смонтирована кем-то как удалённая). Минусы:
3. 1 или (по одному из сетевых интерфейсов к серверу данных подключился сервер приложений).
Остановился на варианте 3, так как он позволяет достаточно быстро получать искомый ответ на вопрос и правильно
заполнять дескрипторы процессов как на сервере приложений, так и на сервере данных. Замечу, что для дополнительного ускорения этой проверки её положительный результат для каждого сервера фиксируется в глобале.
Успешное внедрение API управления процессами в составе региональной медицинской информационной системы Красноярского края показало если не идеальную правильность, то как минимум жизнеспособность выбранных подходов. С помощью данного API нашим специалистам удалось решить ряд важных задач. Перечислю лишь некоторые из них:
• Исключение дублирующихся входов пользователей.
• Получение общесетевого списка работающих пользователей.
• Обмен сообщениями между пользователями.
• Запуск и контроль фоновых процессов, обслуживающих лабораторные анализаторы.
В заключение хочу поблагодарить моих коллег из СП.АРМ за помощь в тестировании кода, оперативную реакцию на замеченные ошибки и особенно за исправление некоторых из них. Часть методов класса Util.Proc (CCM(), RunJob(), CheckJob()) удалось сделать независимыми от нашего прикладного ПО; их можно загрузить из репозитория на гитхабе или из пользовательской базы кода InterSystems.
Да, я не сотрудник InterSystems, однако не без пользы и с удовольствием использую технологии этой компании, чего желаю и терпеливому читателю, дочитавшему до этого места.
Терминология ECP
Прежде чем углубляться в тему, вспомним основные понятия, связанные с ECP.
ECP, или протокол распределённого кэша, лежит в основе взаимодействия серверов данных и серверов приложений. Он работает поверх TCP/IP, обеспечивающего надёжную транспортировку пакетов. Протокол ECP является собственностью фирмы InterSystems.
Серверы данных (СБД), иногда называемые серверами ECP, – это обычные установки Caché, на которых находятся локальные базы данных приложения. Глагол «находятся» не стоит понимать буквально: базы данных могут физически находиться, например, на сетевых системах хранения данных, доступных через iSCSI или FC; важно, что СУБД считает их локальными.
Серверы приложений (СП), иногда называемые клиентами ECP, – это обычные установки Caché, на которых работают процессы, обслуживающие пользователей прикладной системы. Иными словами, на серверах приложений выполняется прикладной код (отсюда их название). Поскольку это обычные установки Caché, на них имеется стандартный набор системных локальных баз данных: CACHESYS, CACHELIB, CACHETEMP и т.д. Это важно, но не это главное. Гораздо важнее, что прикладные БД, локальные по отношению к серверам данных, монтируются как удалённые базы данных на серверах приложения. В общем виде схема взаимодействия показана на рисунке.
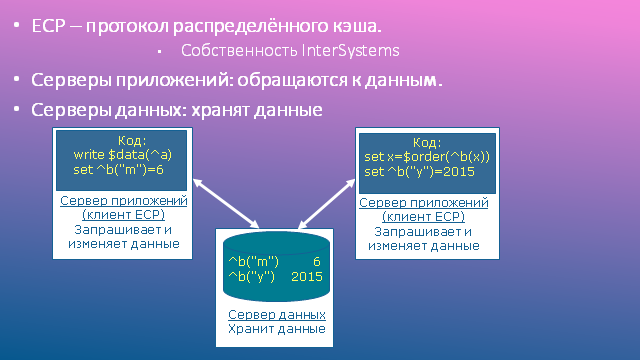
Основные компоненты ECP
Что такое кэш данных, надеюсь, объяснять не надо. Распределённый кэш, фигурирующий в названии протокола ECP, в общем-то не более, чем метафора: кэш, конечно же, всегда локален. Но если на сервере приложений происходит чтение узла удалённого глобала, соответствующий блок копируется из кэша сервера данных в кэш сервера приложений, так что повторные обращения к соседним узлам того же глобала будут происходить локально, без повторного обращения к сети и серверу данных. Чем дольше работает система, тем актуальнее становится наполнение локального кэша на СП (как говорят, тем лучше он «разогревается»), и тем реже происходят операции сетевого доступа. В идеале, повторных чтений с сервера данных требуют лишь изменённые данные; возникает иллюзия существования распределённого (между серверами) кэша.
Запись происходит несколько сложнее: запрос на запись уходит на сервер данных. Сервер данных шлёт в ответ команду «вычеркнуть блок из кэша», причём только тем серверам приложений, которые ранее прочли в свой кэш предыдущее состояние этого блока. Важно, что сам изменённый блок принудительно не шлётся, так как, возможно, он более никому не нужен. Если же в нём вновь возникает потребность, блок заново запрашивается с сервера данных и вновь попадает в локальный кэш сервера приложений, как это было описано ранее.
ECP глазами архитектора
Рекламная пауза: немного о плюсах горизонтального масштабирования средствами ECP. Представьте, что требуется спланировать систему на 10000 пользователей, и известно, что на каждые 50 пользователей требуются вычислительные ресурсы в количестве 1 ядра CPU и 10 GB RAM. Сравним альтернативы. В таблице СБД&СП – традиционный сервер Caché (сервер данных и приложений «в одном флаконе»). Из соображений устойчивости к отказам их необходимо запланировать два.
Вертикальное vs. горизонтальное масштабирование
| Вертикальное масштабирование | Горизонтальное масштабирование | ||
|---|---|---|---|
| Параметры сервера | Количество серверов | Параметры сервера | Количество серверов |
| 200 ядер CPU, 2 TB RAM | 2 СБД&СП | 16 ядер CPU, 160 GB RAM | 13 СП, 2 СБД |
В схеме с горизонтальным масштабированием из тех же соображений планируем два сервера данных, но думаю никого не надо убеждать в ценовом преимуществе этой схемы над предыдущей… В качестве бонуса получаем замечательную особенность совместного использования ECP и «зеркала» (Mirroring): при переключении серверов данных – узлов зеркальной пары – пользователи серверов приложений испытывают лишь краткую паузу в работе (измеряемую секундами), после чего их сеансы продолжаются. В вертикальной схеме клиентские процессы подключаются непосредственно к серверу данных, поэтому при переключении серверов разрывы пользовательских сеансов неизбежны.

Совместное использования ECP и «зеркала»
Вспомним, что на каждом сервере приложений имеются и локальные БД, поэтому хранение промежуточных данных естественным образом перекладывается на эти БД. Такая работа может быть достаточно интенсивной, а значит, вовлечение в неё большого числа даже недорогих дисков может разгрузить центральную систему хранения данных (СХД), уменьшив время обслуживания (await) дисковых операций, без задействования ещё одной дорогостоящей СХД для промежуточных данных.
ECP глазами программиста
«Нормальные» программы работают в областях, следовательно, вам не придётся менять конструкции вида ^|"^^c:\intersystems\cache\mgr\qmsperf "|QNaz на ^|"^PERF^c:\intersystems\cache\mgr\qmsperf"|QNaz. Все эти частности упрятаны в конфигурации Caché в определения удалённого сервера данных и удалённой базы данных. Даже если иногда приходится обращаться к глобалам областей, отличных от текущей области процесса, синтаксис подобных обращений (^|«qmsperf»|QNaz) остаётся прежним.
Семантика работы с глобальными данными также практически не меняется, просто работая с локальными БД, мы обычно о ней не задумываемся. Перечислю основные положения:
• Все операции разделяются на синхронные (все функции чтения: $Get, $Order и т.д., а также Lock и $Increment) и асинхронные (запись данных: Set, Kill и т.д.). Дальнейшее выполнение программы не требует ожидания завершения асинхронной операции. Для синхронных операций это не так. В случае ECP они могут требовать дополнительного обращения к серверу данных, если блок данных отсутствует в локальном кэше.
• Синхронные операции не ждут завершения асинхронных операций, инициированных тем же сервером приложений.
• Команда Lock ждёт завершения записи данных, начатой предыдущим хозяином блокировки.
• Истечение таймаута Lock не гарантирует, что блокировкой владеет кто-то другой.
А вот несколько непривычных моментов:
• Строки длиннее половины размера блока не кэшируются на серверах приложений. На самом деле, этот порог несколько ниже, для 8 KB-блоков – 3900 байт. Такое решение было принято разработчиками, чтобы не забивать кэш BLOBами и CLOBами: известно, что такие данные обычно пишутся один раз и впоследствии крайне редко читаются. К сожалению, это решение негативно сказалось на обработке bitmap-индексов, которые тоже, как правило, являются длинными строками. Если вы их используете, придётся либо уменьшать размер chunk-а, либо увеличивать размер блока; оптимальный выбор можно сделать лишь на основе результатов тестирования.
• Присваивание
set i=$Increment(^a)
может оказаться дороже, чем его функционально близкий аналог:
lock +^a set (i,^a)=^a+1 lock -^a
Дело в том, что функция $Increment всегда выполняется на сервере данных, следовательно, ожидание завершения путешествия пакетов «туда-обратно» неизбежно, а блокировка (lock) вызывает подобный эффект, лишь когда её запрашивают процессы с различных серверов приложений.
• Необходимо обрабатывать ошибки <NETWORK>. Такие ошибки возникают, когда сервер приложений не может восстановить утраченное ECP-соединение в течение Time to wait for recovery (по умолчанию – 1200 секунд). Правильный способ обработки: откатить начатую транзакцию и попробовать заново.
ECP и управление процессами
Освежив в памяти основные концепции ECP, перейдём к основной теме статьи. Управление процессами будем трактовать в широком смысле. Реальные потребности прикладных программистов, с которыми приходится сталкиваться, и системные средства, которые имеются для их удовлетворения «прямо из коробки», см. ниже.
Основные прикладные потребности в управлении процессами
| Функция | Без ECP | С ECP |
|---|---|---|
| Запуск фоновых процессов. | job $job, $zchild, $zparent |
Команда Job работает в сети, но без передачи параметров. Номера процессов уникальны лишь в пределах каждого сервера. |
| Отслеживание «живости» процессов. | $data(^$job(pid)) | Доступа к таблице процессов другого сервера нет. |
| Получение списка процессов. | $order(^$job(pid)) $zjob(pid) |
См. выше. |
| Доступ к свойствам других процессов. | См. выше. | |
| Завершение другого процесса. | Class SYS.Process | Завершить процесс на другом сервере невозможно. |
Ответом на эти «вызовы» стала разработка API управления процессами, реализованного в виде класса Util.Proc.
Чтобы вам интереснее было читать дальше, приведу пару несложных примеров кода с использованием API.
Примеры использования API Util.Proc
• Вывести список процессов с указанием области и имени пользователя медицинской информационной системы (МИС), помечая «*» собственный (текущий) процесс:
set cnt=0
for {
set proc=##class(Util.Proc).NextProc(proc,.sc) quit:proc=""||'sc // следующий процесс
write proc_$select(##class(Util.Proc).ProcIsMy(proc):"*",1:"") // помечаем себя «*»
write " область: "
write ##class(Util.Proc).GetProcProp(proc,"NameSpace") // свойство процесса: текущая область
write " пользователь: "
write ##class(Util.Proc).GetProcVar(proc,$name(qARM("User"))),! // переменная процесса: имя пользователя МИС
set cnt=cnt+1
}
write "Всего: "_cnt_" процессов."
• Удалить процесс, отличный от текущего, если он выполняется под тем же именем пользователя МИС (для исключения повторного входа пользователей):
if '##class(Util.Proc).ProcIsMy(proc),
##class(Util.Proc).GetProcVar(proc,$name(qARM("User")))=$name(qARM("User")) {
set res=##class(Util.Proc).KillProc(proc)
}
Адресация процессов в сети
При разработке API необходимо было выбрать способ адресации процессов в сети ECP, причём хотелось получить:
• уникальность адреса в локальной сети,
• возможность непосредственного использования адреса с минимальными преобразованиями,
• легко читаемый формат.
Для адресации сервера в сети можно использовать его имя (hostname) или IP-адрес. Выбор имени в качестве идентификатора хоть и заманчив, но накладывает дополнительные требования к безупречности работы службы имён. Поскольку подобные требования обычно не предъявляются при настройке конфигурации Caché, не хотелось вводить новых ограничений. К тому же в различных ОС hostname может иметь разный формат, что затруднит последующий разбор дескриптора процесса. Исходя из этих соображений, я предпочёл использовать IPv4-адрес.
Для идентификации установки Caché на сервере можно использовать её имя («CACHE», «CACHEQMS», etc.) или номер порта суперсервера (1972, 56773, etc.). Но подключиться к установке Caché по её имени нельзя, поэтому выбираем порт.
В итоге, в качестве дескриптора (уникального идентификатора) процесса было решено использовать строку в формате децимального номера: xx.yy.zz.uu.Port.PID, где
xx.yy.zz.uu – IPv4 адрес сервера Caché,
Port – tcp-порт суперсервера Caché,
PID – номер процесса на сервере Caché.
Примеры корректных дескрипторов процессов:
192.168.11.19.56773.1760 – процесс с PID=1760 на установке Caché с IP=192.168.11.19 и Port=56773.
192.168.11.77.1972.62801 – процесс с PID=62801 на установке Caché с IP=192.168.11.77 и Port=1972.
Методы класса Util.Proc
В результате был разработан класс Util.Proc, открытые методы которого перечислены ниже. Все методы являются методами класса (ClassMethod).
Сводка методов API управления процессами
| Метод | Функция |
|---|---|
| IsECP() As %Bolean | В сети ECP выполняется код или нет. |
| NextProc(proc, ByRef sc As %Status) As %String | Следующий процесс после процесса с дескриптором proc. |
| DataProc(proc, ByRef sc As %Status) As %Integer |
If ##class(Util.Proc).DataProc(proc), процесс с дескриптором proc существует. |
| Получить свойство с именем Prop процесса с дескриптором proc. Возможен опрос следующих свойств (см. класс %SYS.ProcessQuery): Pid, ClientNodeName, UserName, ClientIPAddress, NameSpace, MemoryUsed, State, ClientExecutableName |
|
| GetProcVar(proc, var, ByRef sc As %Status) As %String |
Получить значение переменной var процесса с дескриптором proc. |
| KillProc(proc, ByRef sc As %Status) As %String |
Завершить процесс с дескриптором proc. |
| RunJob(EntryRef, Argv...) As %List |
Запустить процесс на сервере данных с точки входа EntryRef, передав ему требуемое количество фактических параметров (Argv). Возвращает $lb(%Status, pid), где pid – номер процесса на сервере данных. |
| CheckJob(pid) As %List |
Проверить, «жив» ли процесс с номером pid на сервере данных. |
| CCM(ClassMethodName, Argv...) As %String |
Выполнить на сервере данных произвольный метод класса ClassMethodName (или $$-функцию), передав требуемое количество фактических параметров (Argv), и получив результат выполнения. |
Сопоставляя сводку методов с таблицей Основные прикладные потребности в управлении процессами, видим, что удалось их удовлетворить теперь уже и в сетевой среде. Метод CCM() был добавлен позже: в процессе переноса нашего приложения (региональной медицинской информационной системы qMS) в среду ECP выяснилось, что некоторые функциональные блоки удобнее и правильнее выполнять непосредственно на сервере данных. Причины могут быть разные:
• Желание избежать разовой перекачки большого объёма данных на сервер приложений, характерной, например, при генерации отчёта.
• Необходимость централизованно обслуживать некий общий ресурс, например, очереди обмена сообщениями с другой системой (в нашем случае – с HealthShare).
Замечу, что большинство методов API предназначены для работы в среде ECP. Без ECP они по-прежнему работоспособны, но принимают/возвращают лишь малоосмысленные дескрипторы процессов вида 127.0.0.1.Port.pid. Исключение составляют методы, ориентированные на работу с сервером данных: RunJob(), CheckJob(), CCM(), так как они возвращают/принимают не дескриптор процесса (proc), а его номер (pid) на сервере данных. Поэтому эти методы сделаны универсальными с точки зрения прикладного программиста: их интерфейс одинаков как в среде ECP, так и без неё, хотя работают они, конечно, по-разному.
Немного о реализации
Необходимо было выбрать метод взаимодействия между процессами, работающими на разных серверах. Рассматривались следующие альтернативы:
• Класс %SYSTEM.Event.
o Официально не работает в сети, поэтому поддержка его сетевой работы может быть прекращена InterSystems в любой момент.
• Собственный TCP-сервер.
o В принципе, хорошая идея.
o Необходимо задействовать дополнительный TCP-порт (кроме порта супер-сервера), что неизбежно влечёт дополнительные усилия по установке и настройке помимо стандартных настроек Caché. А хотелось обойтись минимумом настроек.
• Web-сервисы.
• Класс %Net.RemoteConnection. Для тех, кто забыл: этот класс обеспечивает удалённое выполнение кода на других серверах, используя тот же протокол, что и клиенты сервиса %Service_Bindings. Если в системе этот сервис уже задействован для подключения клиентов, то никакие дополнительные настройки не требуются, а это как раз наш случай. Накладные расходы на обмен данными незначительны, как правило, он меньше, чем в случае web-сервисов.
Исходя из этих соображений, я выбрал %Net.RemoteConnection. Из его недостатков наиболее серьёзный, на мой взгляд, состоит в том, что он не позволяет возвращать строки длиннее 32KB, но это сильно не помешало.
Другая не менее интересная проблема, с которой пришлось столкнуться: как определить, в сети работает код или нет? Ответ на этот вопрос необходим как для внутренних нужд API (чтобы правильно формировать дескрипторы процессов), так и для написания метода IsECP(), весьма востребованного прикладными программистами. Причина такой популярности довольно очевидна: желающих переписывать участки своего кода, связанного с взаимодействием между процессами, на некоем универсальном API, оказалось не очень много (хотя такое API и было реализовано). Гораздо проще и естественнее оказалось добавить ветку кода для ECP. Но как определить, в какой среде работает код? Рассматривались варианты:
1. Основная база данных области является удалённой.
- Плюсы: это очень просто, всего-навсего:
- Минусы: это справедливо только на сервере приложений и исключает сетевую работу на сервере данных.
2. 1 или (основная БД области смонтирована кем-то как удалённая). Минусы:
- Это дорого.
- Это ненадёжно из-за динамичной природы ECP.
3. 1 или (по одному из сетевых интерфейсов к серверу данных подключился сервер приложений).
Остановился на варианте 3, так как он позволяет достаточно быстро получать искомый ответ на вопрос и правильно
заполнять дескрипторы процессов как на сервере приложений, так и на сервере данных. Замечу, что для дополнительного ускорения этой проверки её положительный результат для каждого сервера фиксируется в глобале.
Некоторые выводы
Успешное внедрение API управления процессами в составе региональной медицинской информационной системы Красноярского края показало если не идеальную правильность, то как минимум жизнеспособность выбранных подходов. С помощью данного API нашим специалистам удалось решить ряд важных задач. Перечислю лишь некоторые из них:
• Исключение дублирующихся входов пользователей.
• Получение общесетевого списка работающих пользователей.
• Обмен сообщениями между пользователями.
• Запуск и контроль фоновых процессов, обслуживающих лабораторные анализаторы.
В заключение хочу поблагодарить моих коллег из СП.АРМ за помощь в тестировании кода, оперативную реакцию на замеченные ошибки и особенно за исправление некоторых из них. Часть методов класса Util.Proc (CCM(), RunJob(), CheckJob()) удалось сделать независимыми от нашего прикладного ПО; их можно загрузить из репозитория на гитхабе или из пользовательской базы кода InterSystems.
Да, я не сотрудник InterSystems, однако не без пользы и с удовольствием использую технологии этой компании, чего желаю и терпеливому читателю, дочитавшему до этого места.
