В статье я расскажу как реализовать файловую систему в юзерспейсе на Java, без строчки ядерного кода. А также покажу как связать Java и нативный код без написания кода на C, при этом сохранив максимальную производительность.

Интересно? Добро пожаловать под кат!
Прежде приступить к реализации обертки нужно понять что же такое FUSE.
FUSE (Filesystem in Userspace) — файловая система в пользовательском пространстве, она позволяет пользователям без привилегий создавать их собственные файловые системы и без необходимости переписывать код ядра. Это достигается за счёт запуска кода файловой системы в пространстве пользователя, в то время как модуль FUSE только предоставляет мост для актуальных интерфейсов ядра. FUSE была официально включена в главное дерево кода Linux в версии 2.6.14.

Т.е. вы по сути реализацией нескольких методов можете легко создать свою собственную файловую систему (пример простейшей ФС). Применений этому миллион, вы можете, например, быстро написать ФС, бэкэндом для которой будет Dropbox или GitHub.
Или же, рассмотрим такой кейс, у вас есть бизнес приложение, где все пользовательские файлы храняться в БД, но клиенту, вдруг, понадобился прямой доступ к директории на сервере, где лежат все файлы. Конечно же дублировать файлы в БД и ФС решение не самое лучшее и тут как раз на помощь приходит виртуальная файловая система. Вы просто пишете свою FUSE обертку, которая при обращении к файлам ходит за ними в БД.
Отлично, но реализация FUSE начинается с “подключите заголовочный файл <fuse.h>”, а ваше бизнес-приложение написано на Java. Очевидно, нужно каким-либо образом взаимодействовать с нативным кодом.
Стандартным средством является JNI, но он вносит очень много сложности в проект, особенно учитывая, что для реализации FUSE нам придется делать колбэки из нативного кода в Java классы. Да и “write once” на самом деле страдает, хотя в случае FUSE нам это менее важно.
Собственно, если попытаться найти проекты, которые реализуют обертку для FUSE на JNI, можно найти несколько проектов, которые, однако, уже давно не поддерживаются и предоставляют кривой API.
Другой вариант, библиотека JNA. JNA (Java Native Access) позволяет довольно легко получить доступ к нативному коду без использования JNI, ограничившись написанием java-кода. Все довольно просто, объявляем интерфейс, который соответствует нативному коду, получаем его имплементацию через “Native.loadLibrary” и все, используем. Отдельный плюс JNA — это подробнейшая документация. Проект жив и активно развивается.
Более того, для FUSE уже существует отличный проект, реализующий обертку на JNA.
Однако, у JNA есть определенные проблемы с производительностью. JNA базируется на рефлекшене, и переход из нативного кода с конвертацией всех структур в java объекты очень дорог. Это не сильно заметно, если нативные вызовы будут редки, однако это не случай файловой системы. Единственный способ ускорить fuse-jna это пытаться читать файлы большими кусками, однако это сработает далеко не всегда. Например, когда нет доступа к клиентскому коду, или все файлы маленькие – большое количество текстовый файлов.
Очевидно, что должна была появиться библиотека, совмещающая производительность JNI и удобство JNA.
Вот тут и приходит JNR (Java Native Runtime). JNR, как и JNA базируется на libffi, но вместо рефлекшена используется генерация байткода, за счет чего достигается огромное преимущество в производительности.
Какой-либо информации про JNR довольно мало, самое подробное это выступление Charles Nutter на JVMLS 2013 (презентация). Однако JNR уже представляет из себя довольно крупную экосистему, которая активно используется JRuby. Многие ее части, например, unix-сокеты, posix-api также активно используются сторонними проектами.

Именно JNR является основой для разработки JEP 191 — Foreign Function Interface, который таргетится на java 10.
В отличие от JNA у JNR нет какой либо документации, все ответы на вопросы приходится искать в исходном коде, это и послужило основной причиной написания небольшого гайда.
Простейший биндинг к libc выглядит так:
Через LibraryLoader подгружаем по имени библиотеку, которая соответствует переданному интерфейсу.
В случае FUSE нужен интерфейс с методом fuse_main_real, в который передается структура FuseOperations, которая содержит все колбэки.
Часто необходимо работать со структурами, расположенными по определенному адресу, например структурой fuse_bufvec:
Для ее реализации в JNR необходимо отнаследоваться от jnr.ffi.Struct.
Внутри каждой структуры хранится pointer, по которому она размещается в памяти. Большую часть API работы со структурами можно увидев, посмотрев на статические методы Struct.
size_t это inner класс Struct и при его создании для каждого поля запоминается offset с которым это поле размещено в памяти, за счет чего каждое поле знает по какому оффсету оно лежит в памяти. Таких inner классов уже реализовано много (например, Signed64, Unsigned32, time_t и т.д.), всегда можно реализовать свои.
Для работы с колбэками в JNR существует аннотация
После чего можно выставить в поле getattr нужную имплементацию колбэка, например.
Из некоторых неочевидных вещей также стоит отметить обертку над enum, для этого свой enum нужно отнаследовать от jnr.ffi.util.EnumMapper.IntegerEnum и реализовать метод intValue
Этих знаний хватит, чтобы без проблем реализовать простую кроссплатформенную обертку над какой-нибудь нативной библиотекой.
Что собственно я и сделал с FUSE в своем проекте jnr-fuse. Изначально использовалась библиотека fuse-jna, однако именно она была боттлнеком в реализации ФС. При разработке API я постарался максимально сохранить совместимость с fuse-jna, а также с нативной реализацией (<fuse.h>).
Для реализации своей файловой системы в юзерспейсе необходимо отнаследоваться от ru.serce.jnrfuse.FuseStubFS и реализовать нужные методы. Fuse_operations содержит множество методов, однако для того, чтобы получить рабочую ФС достаточно реализовать всего несколько основных.
Это довольно просто, вот несколько примеров рабочих ФС.
На данный момент поддерживается Linux (x86 и x64).
Библиотека лежит в jcenter, в ближайшее время добавлю зеркало в maven central.
В моем случае, FS была read-only и меня интересовал конктретно throughput. Производительность будет сильно зависеть от имплементации вашей ФС, поэтому если вдруг вы уже используте fuse-jna, вы можете легко подключить jnr-fuse, написать тест с учетом вашего профиля нагрузки и увидеть разницу. (Этот тест вам в любом случае пригодится, мы же все любим погоняться за производительностью, правда?)
Чтобы же показать порядок разницы я перенес имплементацию MemoryFS из fuse-jna в fuse-jnr с минимальными изменениями и запустил fio тест на чтение. Для теста я использовал фреймворк fio, про который не так давно была хорошая статья на хабре.

Тест лишь демонстрирует разницу в скорости чтения файла в fuse-jna и fuse-jnr, однако на его основе можно получить представление о разнице в скорости работы JNA и JNR. Желающие же всегда могут написать более подробные тесты на нативные вызовы с помощью JMH с учетом всех особенностей, мне самому было бы интересно посмотреть на эти тесты.
Разница и в throughput, и в latency в JNR и JNA ожидаемо, как и в презентации от Charles Nutter, составляет ~10 раз.
Проект jnr-fuse размещен на GitHub. Буду раз звездочкам, пул-реквестам, предложениям по улучшению проекта.
А также с радостью отвечу на все возникшие вопросы про JNR и jnr-fuse.

Интересно? Добро пожаловать под кат!
Прежде приступить к реализации обертки нужно понять что же такое FUSE.
FUSE (Filesystem in Userspace) — файловая система в пользовательском пространстве, она позволяет пользователям без привилегий создавать их собственные файловые системы и без необходимости переписывать код ядра. Это достигается за счёт запуска кода файловой системы в пространстве пользователя, в то время как модуль FUSE только предоставляет мост для актуальных интерфейсов ядра. FUSE была официально включена в главное дерево кода Linux в версии 2.6.14.
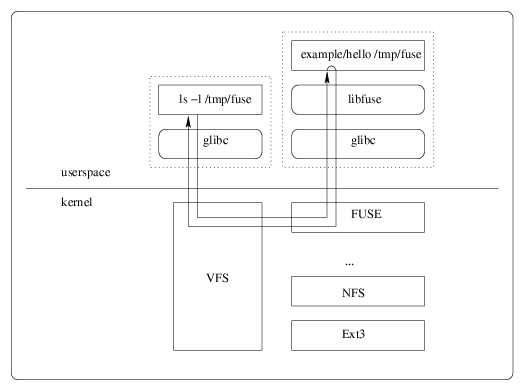
Т.е. вы по сути реализацией нескольких методов можете легко создать свою собственную файловую систему (пример простейшей ФС). Применений этому миллион, вы можете, например, быстро написать ФС, бэкэндом для которой будет Dropbox или GitHub.
Или же, рассмотрим такой кейс, у вас есть бизнес приложение, где все пользовательские файлы храняться в БД, но клиенту, вдруг, понадобился прямой доступ к директории на сервере, где лежат все файлы. Конечно же дублировать файлы в БД и ФС решение не самое лучшее и тут как раз на помощь приходит виртуальная файловая система. Вы просто пишете свою FUSE обертку, которая при обращении к файлам ходит за ними в БД.
Java и нативный код
Отлично, но реализация FUSE начинается с “подключите заголовочный файл <fuse.h>”, а ваше бизнес-приложение написано на Java. Очевидно, нужно каким-либо образом взаимодействовать с нативным кодом.
JNI
Стандартным средством является JNI, но он вносит очень много сложности в проект, особенно учитывая, что для реализации FUSE нам придется делать колбэки из нативного кода в Java классы. Да и “write once” на самом деле страдает, хотя в случае FUSE нам это менее важно.
Собственно, если попытаться найти проекты, которые реализуют обертку для FUSE на JNI, можно найти несколько проектов, которые, однако, уже давно не поддерживаются и предоставляют кривой API.
JNA
Другой вариант, библиотека JNA. JNA (Java Native Access) позволяет довольно легко получить доступ к нативному коду без использования JNI, ограничившись написанием java-кода. Все довольно просто, объявляем интерфейс, который соответствует нативному коду, получаем его имплементацию через “Native.loadLibrary” и все, используем. Отдельный плюс JNA — это подробнейшая документация. Проект жив и активно развивается.
Более того, для FUSE уже существует отличный проект, реализующий обертку на JNA.
Однако, у JNA есть определенные проблемы с производительностью. JNA базируется на рефлекшене, и переход из нативного кода с конвертацией всех структур в java объекты очень дорог. Это не сильно заметно, если нативные вызовы будут редки, однако это не случай файловой системы. Единственный способ ускорить fuse-jna это пытаться читать файлы большими кусками, однако это сработает далеко не всегда. Например, когда нет доступа к клиентскому коду, или все файлы маленькие – большое количество текстовый файлов.
Очевидно, что должна была появиться библиотека, совмещающая производительность JNI и удобство JNA.
JNR
Вот тут и приходит JNR (Java Native Runtime). JNR, как и JNA базируется на libffi, но вместо рефлекшена используется генерация байткода, за счет чего достигается огромное преимущество в производительности.
Какой-либо информации про JNR довольно мало, самое подробное это выступление Charles Nutter на JVMLS 2013 (презентация). Однако JNR уже представляет из себя довольно крупную экосистему, которая активно используется JRuby. Многие ее части, например, unix-сокеты, posix-api также активно используются сторонними проектами.
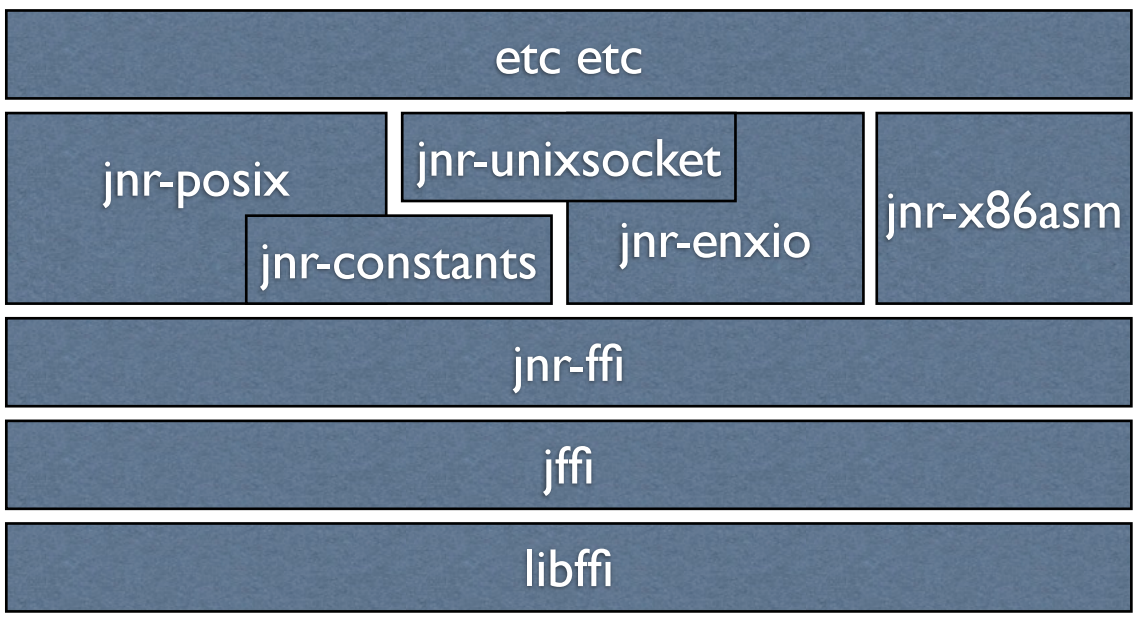
Именно JNR является основой для разработки JEP 191 — Foreign Function Interface, который таргетится на java 10.
В отличие от JNA у JNR нет какой либо документации, все ответы на вопросы приходится искать в исходном коде, это и послужило основной причиной написания небольшого гайда.
Особенность написания кода для Java Native Runtime
Биндинг функций
Простейший биндинг к libc выглядит так:
import jnr.ffi.*;
import jnr.ffi.types.pid_t;
/**
* Gets the process ID of the current process, and that of its parent.
*/
public class Getpid {
public interface LibC {
public @pid_t long getpid();
public @pid_t long getppid();
}
public static void main(String[] args) {
LibC libc = LibraryLoader.create(LibC.class).load("c");
System.out.println("pid=" + libc.getpid() + " parent pid=" + libc.getppid());
}
}
Через LibraryLoader подгружаем по имени библиотеку, которая соответствует переданному интерфейсу.
В случае FUSE нужен интерфейс с методом fuse_main_real, в который передается структура FuseOperations, которая содержит все колбэки.
public interface LibFuse {
int fuse_main_real(int argc, String argv[], FuseOperations op, int op_size, Pointer user_data);
}
Реализация struct
Часто необходимо работать со структурами, расположенными по определенному адресу, например структурой fuse_bufvec:
struct fuse_bufvec {
size_t count;
size_t idx;
size_t off;
struct fuse_buf buf[1];
};
Для ее реализации в JNR необходимо отнаследоваться от jnr.ffi.Struct.
import jnr.ffi.*;
public class FuseBufvec extends Struct {
public FuseBufvec(jnr.ffi.Runtime runtime) {
super(runtime);
}
public final size_t count = new size_t();
public final size_t idx = new size_t();
public final size_t off = new size_t();
public final FuseBuf buf = inner(new FuseBuf(getRuntime()));
}
Внутри каждой структуры хранится pointer, по которому она размещается в памяти. Большую часть API работы со структурами можно увидев, посмотрев на статические методы Struct.
size_t это inner класс Struct и при его создании для каждого поля запоминается offset с которым это поле размещено в памяти, за счет чего каждое поле знает по какому оффсету оно лежит в памяти. Таких inner классов уже реализовано много (например, Signed64, Unsigned32, time_t и т.д.), всегда можно реализовать свои.
Колбэки
struct fuse_operations {
int (*getattr) (const char *, struct stat *);
}
Для работы с колбэками в JNR существует аннотация
@Delegate
public interface GetAttrCallback {
@Delegate
int getattr(String path, Pointer stbuf);
}
public class FuseOperations extends Struct {
public FuseOperations(Runtime runtime) {
super(runtime);
}
public final Func<GetAttrCallback> getattr = func(GetAttrCallback.class);
}
После чего можно выставить в поле getattr нужную имплементацию колбэка, например.
fuseOperations.getattr.set((path, stbuf) -> 0);
Enum
Из некоторых неочевидных вещей также стоит отметить обертку над enum, для этого свой enum нужно отнаследовать от jnr.ffi.util.EnumMapper.IntegerEnum и реализовать метод intValue
enum fuse_buf_flags {
FUSE_BUF_IS_FD = (1 << 1),
FUSE_BUF_FD_SEEK = (1 << 2),
FUSE_BUF_FD_RETRY = (1 << 3),
};
public enum FuseBufFlags implements EnumMapper.IntegerEnum {
FUSE_BUF_IS_FD(1 << 1),
FUSE_BUF_FD_SEEK(1 << 2),
FUSE_BUF_FD_RETRY(1 << 3);
private final int value;
FuseBufFlags(int value) {
this.value = value;
}
@Override
public int intValue() {
return value;
}
}
Работа с памятью
- Для прямой работы с памятью существует обертка над сырым указателем jnr.ffi.Pointer
- Аллоцировать память можно с помощью jnr.ffi.Memory
- Отправной точкой по API JNR можно считать jnr.ffi.Runtime
Этих знаний хватит, чтобы без проблем реализовать простую кроссплатформенную обертку над какой-нибудь нативной библиотекой.
jnr-fuse
Что собственно я и сделал с FUSE в своем проекте jnr-fuse. Изначально использовалась библиотека fuse-jna, однако именно она была боттлнеком в реализации ФС. При разработке API я постарался максимально сохранить совместимость с fuse-jna, а также с нативной реализацией (<fuse.h>).
Для реализации своей файловой системы в юзерспейсе необходимо отнаследоваться от ru.serce.jnrfuse.FuseStubFS и реализовать нужные методы. Fuse_operations содержит множество методов, однако для того, чтобы получить рабочую ФС достаточно реализовать всего несколько основных.
Это довольно просто, вот несколько примеров рабочих ФС.
На данный момент поддерживается Linux (x86 и x64).
Библиотека лежит в jcenter, в ближайшее время добавлю зеркало в maven central.
Gradle
repositories {
jcenter()
}
dependencies {
compile 'com.github.serceman:jnr-fuse:0.1'
}
Maven
<repositories>
<repository>
<id>central</id>
<name>bintray</name>
<url>http://jcenter.bintray.com</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.github.serceman</groupId>
<artifactId>jnr-fuse</artifactId>
<version>0.1</version>
</dependency>
</dependencies>
Сравниваем производительность fuse-jna и jnr-fuse
В моем случае, FS была read-only и меня интересовал конктретно throughput. Производительность будет сильно зависеть от имплементации вашей ФС, поэтому если вдруг вы уже используте fuse-jna, вы можете легко подключить jnr-fuse, написать тест с учетом вашего профиля нагрузки и увидеть разницу. (Этот тест вам в любом случае пригодится, мы же все любим погоняться за производительностью, правда?)
Чтобы же показать порядок разницы я перенес имплементацию MemoryFS из fuse-jna в fuse-jnr с минимальными изменениями и запустил fio тест на чтение. Для теста я использовал фреймворк fio, про который не так давно была хорошая статья на хабре.
Конфигурация теста
[readtest]
blocksize=4k
directory=/tmp/mnt/
rw=randread
direct=1
buffered=0
ioengine=libaio
time_based=60
size=16M
runtime=60
blocksize=4k
directory=/tmp/mnt/
rw=randread
direct=1
buffered=0
ioengine=libaio
time_based=60
size=16M
runtime=60
Результат fuse-jna
serce@SerCe-FastLinux:~/git/jnr-fuse/bench$ fio read.ini
readtest: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file(s) (1 file(s) / 16MB)
Jobs: 1 (f=1): [r] [100.0% done] [24492KB/0KB/0KB /s] [6123/0/0 iops] [eta 00m:00s]
readtest: (groupid=0, jobs=1): err= 0: pid=10442: Sun Jun 21 14:49:13 2015
read: io=1580.2MB, bw=26967KB/s, iops=6741, runt= 60000msec
slat (usec): min=46, max=29997, avg=146.55, stdev=327.68
clat (usec): min=0, max=69, avg= 0.47, stdev= 0.66
lat (usec): min=47, max=30002, avg=147.26, stdev=327.88
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 0], 20.00th=[ 0],
| 30.00th=[ 0], 40.00th=[ 0], 50.00th=[ 0], 60.00th=[ 1],
| 70.00th=[ 1], 80.00th=[ 1], 90.00th=[ 1], 95.00th=[ 1],
| 99.00th=[ 2], 99.50th=[ 2], 99.90th=[ 3], 99.95th=[ 12],
| 99.99th=[ 14]
bw (KB /s): min=17680, max=32606, per=96.09%, avg=25913.26, stdev=3156.20
lat (usec): 2=97.95%, 4=1.96%, 10=0.02%, 20=0.06%, 50=0.01%
lat (usec): 100=0.01%
cpu: usr=1.98%, sys=5.94%, ctx=405302, majf=0, minf=28
IO depths: 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued: total=r=404511/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=1580.2MB, aggrb=26967KB/s, minb=26967KB/s, maxb=26967KB/s, mint=60000msec, maxt=60000msec
readtest: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file(s) (1 file(s) / 16MB)
Jobs: 1 (f=1): [r] [100.0% done] [24492KB/0KB/0KB /s] [6123/0/0 iops] [eta 00m:00s]
readtest: (groupid=0, jobs=1): err= 0: pid=10442: Sun Jun 21 14:49:13 2015
read: io=1580.2MB, bw=26967KB/s, iops=6741, runt= 60000msec
slat (usec): min=46, max=29997, avg=146.55, stdev=327.68
clat (usec): min=0, max=69, avg= 0.47, stdev= 0.66
lat (usec): min=47, max=30002, avg=147.26, stdev=327.88
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 0], 20.00th=[ 0],
| 30.00th=[ 0], 40.00th=[ 0], 50.00th=[ 0], 60.00th=[ 1],
| 70.00th=[ 1], 80.00th=[ 1], 90.00th=[ 1], 95.00th=[ 1],
| 99.00th=[ 2], 99.50th=[ 2], 99.90th=[ 3], 99.95th=[ 12],
| 99.99th=[ 14]
bw (KB /s): min=17680, max=32606, per=96.09%, avg=25913.26, stdev=3156.20
lat (usec): 2=97.95%, 4=1.96%, 10=0.02%, 20=0.06%, 50=0.01%
lat (usec): 100=0.01%
cpu: usr=1.98%, sys=5.94%, ctx=405302, majf=0, minf=28
IO depths: 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued: total=r=404511/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=1580.2MB, aggrb=26967KB/s, minb=26967KB/s, maxb=26967KB/s, mint=60000msec, maxt=60000msec
Результат jnr-fuse
serce@SerCe-FastLinux:~/git/jnr-fuse/bench$ fio read.ini
readtest: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file(s) (1 file(s) / 16MB)
Jobs: 1 (f=1): [r] [100.0% done] [208.5MB/0KB/0KB /s] [53.4K/0/0 iops] [eta 00m:00s]
readtest: (groupid=0, jobs=1): err= 0: pid=10153: Sun Jun 21 14:45:17 2015
read: io=13826MB, bw=235955KB/s, iops=58988, runt= 60002msec
slat (usec): min=6, max=23671, avg=15.80, stdev=19.97
clat (usec): min=0, max=1028, avg= 0.37, stdev= 0.78
lat (usec): min=7, max=23688, avg=16.29, stdev=20.03
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 0], 20.00th=[ 0],
| 30.00th=[ 0], 40.00th=[ 0], 50.00th=[ 0], 60.00th=[ 0],
| 70.00th=[ 1], 80.00th=[ 1], 90.00th=[ 1], 95.00th=[ 1],
| 99.00th=[ 1], 99.50th=[ 1], 99.90th=[ 2], 99.95th=[ 2],
| 99.99th=[ 10]
lat (usec): 2=99.88%, 4=0.10%, 10=0.01%, 20=0.01%, 50=0.01%
lat (usec): 100=0.01%, 250=0.01%
lat (msec): 2=0.01%
cpu: usr=9.33%, sys=34.01%, ctx=3543137, majf=0, minf=28
IO depths: 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued: total=r=3539449/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=13826MB, aggrb=235955KB/s, minb=235955KB/s, maxb=235955KB/s, mint=60002msec, maxt=60002msec
readtest: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=libaio, iodepth=1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file(s) (1 file(s) / 16MB)
Jobs: 1 (f=1): [r] [100.0% done] [208.5MB/0KB/0KB /s] [53.4K/0/0 iops] [eta 00m:00s]
readtest: (groupid=0, jobs=1): err= 0: pid=10153: Sun Jun 21 14:45:17 2015
read: io=13826MB, bw=235955KB/s, iops=58988, runt= 60002msec
slat (usec): min=6, max=23671, avg=15.80, stdev=19.97
clat (usec): min=0, max=1028, avg= 0.37, stdev= 0.78
lat (usec): min=7, max=23688, avg=16.29, stdev=20.03
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 0], 20.00th=[ 0],
| 30.00th=[ 0], 40.00th=[ 0], 50.00th=[ 0], 60.00th=[ 0],
| 70.00th=[ 1], 80.00th=[ 1], 90.00th=[ 1], 95.00th=[ 1],
| 99.00th=[ 1], 99.50th=[ 1], 99.90th=[ 2], 99.95th=[ 2],
| 99.99th=[ 10]
lat (usec): 2=99.88%, 4=0.10%, 10=0.01%, 20=0.01%, 50=0.01%
lat (usec): 100=0.01%, 250=0.01%
lat (msec): 2=0.01%
cpu: usr=9.33%, sys=34.01%, ctx=3543137, majf=0, minf=28
IO depths: 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete: 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued: total=r=3539449/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=13826MB, aggrb=235955KB/s, minb=235955KB/s, maxb=235955KB/s, mint=60002msec, maxt=60002msec
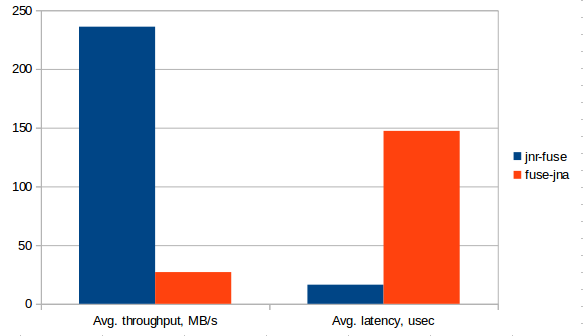
Тест лишь демонстрирует разницу в скорости чтения файла в fuse-jna и fuse-jnr, однако на его основе можно получить представление о разнице в скорости работы JNA и JNR. Желающие же всегда могут написать более подробные тесты на нативные вызовы с помощью JMH с учетом всех особенностей, мне самому было бы интересно посмотреть на эти тесты.
Разница и в throughput, и в latency в JNR и JNA ожидаемо, как и в презентации от Charles Nutter, составляет ~10 раз.
Ссылки
- Fuse на sourceforge
- JNR на github
- Презентация от Charles Nutter про JNR
- JEP 191
- hello-fuse на java / hello-fuse на С
Проект jnr-fuse размещен на GitHub. Буду раз звездочкам, пул-реквестам, предложениям по улучшению проекта.
А также с радостью отвечу на все возникшие вопросы про JNR и jnr-fuse.
