Читая о языке Go, вы часто будете слышать слово “простота”. Но разные люди трактуют это слово по разному, особенно в контексте разработки ПО, а многие, зачастую, даже не осознают, почему это вообще используется, как характеристика языка. В этой статье мы попытаемся концептуально подойти к вопросу “сложности” и “простоты” в разработке ПО, и посмотрим, почему и зачем язык Go поставил простоту как краеугольный камень своего дизайна.

Простота — это противоположность сложности.
Сложность разработки ПО — тема, давно волновавшая умы инженеров и ученых, и один из наиболее концептуальных подходов к вопросу был оформлен автором известнейшей книги “Мифический человеко-месяц”, Фредериком Бруксом, в виде отдельного труда - “Серебрянной пули нет” (“No Silver Bullet”). Этот труд написан в 1987 году, но концептуальный взгляд на тему делает его актуальным и через 30 лет.
В частности, Брукс проводит важное разделение сложности на “неотъемлемую”(essential) и “привнесенную”(или “случайную” — accidental). Неотъемлемая сложность — это та сложность, которая происходит из самой области проблемы, от её природы. Скажем, если вам нужно имплементировать протокол FTP — неважно, какой язык или инструментарий вы выберете для этого, у вас все равно есть набор команд, действий, кодов возврата и логики, которую придется реализовать. Нет такого способа, чтобы упростить задачу до имплементации в одну строчку. Сложность вам даётся как данное (в данном случае из спецификации протокола), и способа повлиять на эту составляющую у вас, в общем случае, нет.
Привнесенная сложность — напротив, это сложность, которая происходит от тех инструментов, которые мы используем. Это та сложность, которую мы создаём себе сами. На неё мы можем влиять и уменьшать.
История развития индустрии разработки ПО сводится к уменьшению именно этой, accidental, сложности.
Ответ на вопрос — “хорошо” или “плохо”? — лежит исключительно в области признания или не признания хороших и плохих практик. Нет формального способа доказать, что, скажем, “глобальные переменные” — это хорошо или плохо. Рассматривая частные примеры, сторонники каждой из сторон найдут вам сотню убедительных аргументов и “за”, и “против”. Но собрав, хотя бы частично, опыт многих и многих разработчиков ПО, работающих с самыми разными программистами и языками, вы так или иначе будете слышать утверждения про “хорошие практики” или “плохие практики”.
Только с коллективным эмпирическим опытом многих тысяч инженеров и программистов, изложивших свои мысли на бумаге, приходит понимание, что “сложность” — это то, чего стоит избегать настолько, насколько это возможно. Сложность ведёт к целой лавине не сразу очевидных эффектов, которые также зачастую сложно формально доказать и которые измеряются вероятностями — большая вероятность появления ошибок, большее время на понимание кода, большее время и усилия, необходимые для изменения дизайна ПО в случае необходимости (рефакторинг), которые, в свою очередь, порождают стимул не производить эти изменения, которые, в свою очередь, приводят к тому, что разработчики начинают искать обходные пути и так далее.
В конце концов, код — это всего лишь инструмент решения задач, и в итоге главным критерием, отделяющим «хорошее» от «плохого» является продуктивность — скорость и качество решения этих самых задач. Сложность является убийцей продуктивности, и именно потому вся индустрия разработки движется в сторону уменьшения сложности.
Выбор языка программирования — это очень удачный, если не лучший, пример “привнесённой сложности” в мире разработки ПО. Сами по себе языки программирования — это тоже инструменты для уменьшения сложности разработки. И каждый виток их развития, так или иначе решает один из аспектов сложности разработки ПО, но тем самым и привносит новые элементы сложности.
Вся история их развития — история поиска более простого инструмента для реалий того времени. Теория языков программирования — такая же развивающаяся наука, как и, допустим, нейробиология, и нет единого канонического знания, каким должен быть язык программирования. Это стохастический процесс, замешанный на законах рынка, удачных решениях, хорошего бэкапа в виде крупной компании (почти все популярные языки имели за спиной крупную компанию) и массе других факторов.
И этот процесс не стоит на месте, новые концепции порождают новые проблемы и новые уровни абстракций, растет коллективный опыт и понимание, вместе с тем, развивается и стремительно меняется экосистема железа и софта, меняются приоритеты в вопросах компромиссов и экономии ресурсов, и всё это плотно завязано на инерционности человеческого мозга и систем образования. Другими словами — это очень сложная махина. Простого и одного решения тут нет и быть не может.
Но что можно утверждать наверняка — что одни языки привносят больше сложности в общий пул сложности, а другие меньше. Одни практики и паттерны (“паттерны — это багрепорт на ваш язык”), которые навязываются языками, увеличивают суммарную сложность разработки, другие — уменьшают.
И мы, как инженеры, должны стремиться в итоге, к тому, чтобы избегать этой “привнесенной сложности”.
Go родился, как ответ на повышенную “привнесенную” сложность существующих языков. По крайней мере, той предметной области, которая волновала Google — разработки системного, сетевого и серверного софта. Его главной целью изначально было уменьшить эту сложность любой ценой. Это был главный приоритет с самого начала.
Немалую роль тут сыграл колоссальный практический опыт авторов Go — Пайка, Томпсона и компании — людей, стоявших у истоков Unix, языка C и UTF-8, а сейчас работающих над ключевыми продуктами Google. Так или иначе, но Go явился в некоторой степени радикальным языком, который качнул маятник сложности в другую сторону, пытаясь выровнять существующий ландшафт мира разработки ПО.
И это именно то, что подразумевается под термином “простота” в контексте Go. Уменьшение сложности. Уменьшение времени необходимое среднестатическому программисту для понимания среднестатического проекта, написанного другими людьми. Уменьшение рисков ошибок. Уменьшение времени и затрат на «хорошие практики». Уменьшение шансов писать код плохо и некрасиво. Уменьшение времени на освоение языка. И так далее, и тому подобное.
Но довольно слов, давайте и в самом деле попробуем оценить сложность, привносимую языками. В комментариях к предыдущим статьям, отсутствие «формального доказательства» было причиной бурных споров. Сразу скажу, что осознаю сложность этой задачи. Реальная оценка лежит в плоскости субъективного практического опыта и трудноизмеряемых вероятностей. Простого способа свести всё к одной цифре и сказать «сложность языка А больше, чем языка Б» — нет. Но тем не менее, если вы хорошо знаете какие-либо два или больше языка, вы для себя достаточно легко можете решить, какой язык для вас проще. Ваш мозг как-то умеет оценить и решить, какой из языков сложнее.
Поэтому, за неимением лучшего варианта, я попробую взять несколько методик, и посмотреть какую картину они нарисуют. У каждой методики есть серъезные недостатки, но если их результаты не будут сильно различаться, можно будет считать, что это что-то большее, чем случайное распределение.
При этом я буду анализировать языки, которые достаточно универсальны для решения большого круга задач, имеют достаточно большое сообщество и информация о них доступна. Экзотику вроде Brainfuck мы не рассматриваем.
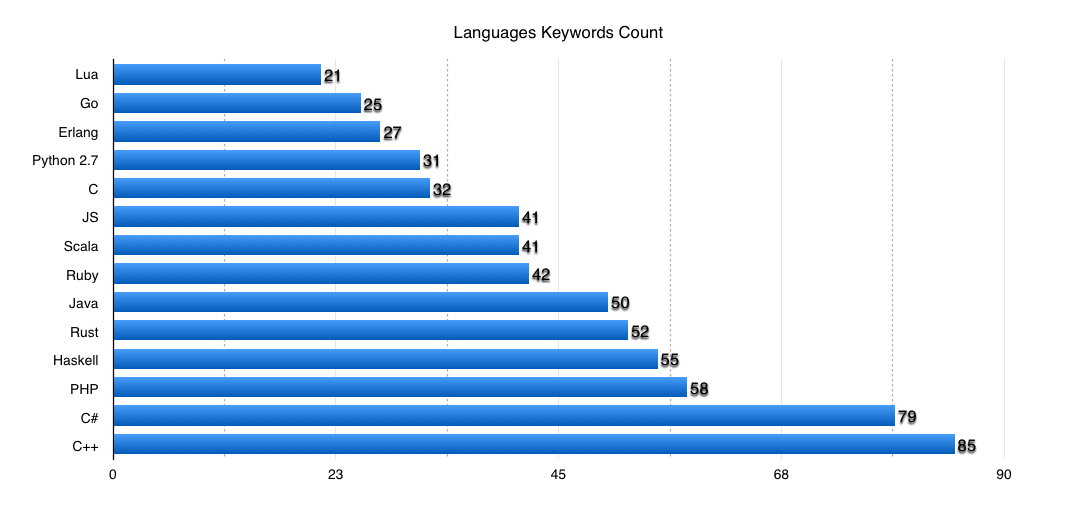
Одной из таких простейших методик является подсчет ключевых слов (keywords) языка. На самом деле точнее будет оценивать концепты, которые привносит язык — но это сложнее считается, и при этом кореллирует с количеством ключевых слов. Оценка будет очень грубая, но достаточно показательная и логичная. Логичная, потому что меньшее количество знаний равно меньшей когнитивной нагрузке на мозг.
Вот что мы имеем:
То же самое, в виде графика:
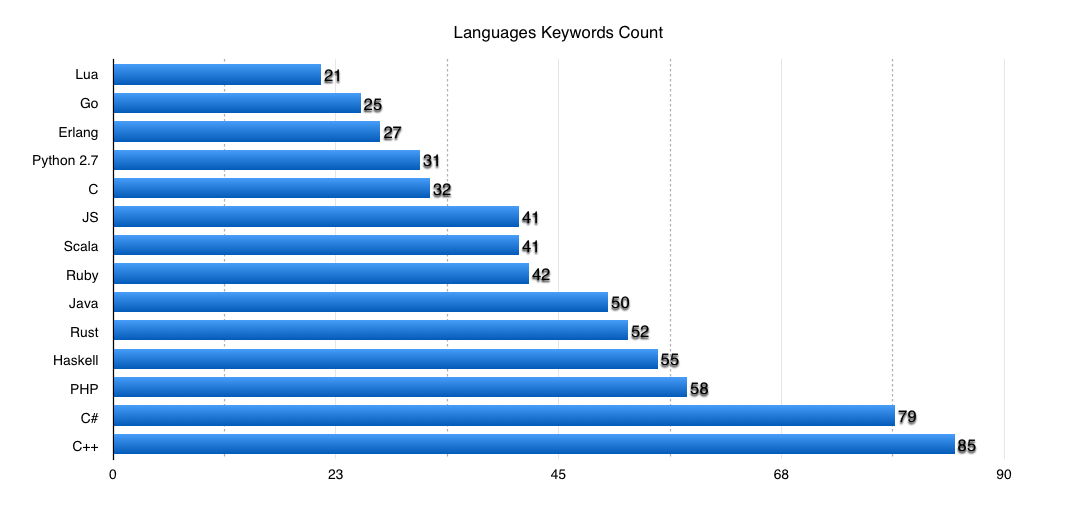
Можно попробовать оценить грамматики языка, многие из которых описаны с помощью Формы Бэкуса-Наура. Грамматики в этом формате (BNF/EBNF) есть не ко всем языкам, но в сети есть немало различных грамматик, составленных полуавтоматически. К примеру, я брал несколько грамматик отсюда: slps.github.io/zoo/index.html. Оценивать количество правил я буду простыми однострочниками. К примеру, для Go извлечь ENBF-правила очень просто прямо с официальной страницы со спецификацией языка:
Хотя в других спецификациях иногда не сильно просто подсчитать количество правил. На всякий случай, привожу команду, которой считал.
Команды для подсчета:
C curl -s www.cs.man.ac.uk/~pjj/bnf/c_syntax.bnf | grep ": " | wc -l
Go curl -s golang.org/ref/spec | grep pre.*ebnf | wc -l
Python manually copy text from docs.python.org/2/reference/grammar.html, then “cat py.bnf | grep ": " | wc-l”
Haskell www.haskell.org/onlinereport/haskell2010/haskellch10.html#x17-17500010
JS (ECMAScript 5.1) curl -s www.ecma-international.org/ecma-262/5.1 | grep '.*::'| tr -d ' ' | sort -u | wc -l
Ruby (для 1.4) curl -s docs.huihoo.com/ruby/ruby-man-1.4/yacc.html | grep ": " | wc -l
Java (JRE 1.9) curl -s docs.oracle.com/javase/specs/jls/se8/html/jls-19.html | grep '' | wc -l
C++ (2008) curl -s slps.github.io/zoo/cpp/iso-n2723.bnf | egrep ":$" | wc -l
C# 4.0 curl -s slps.github.io/zoo/cs/csharp-msft-ls-4.0.bnf | egrep ":$" | wc -l
Lua 5.1 curl -s wiki.luajit.org/Extended-BNF | grep "::=" | wc -l
PHP curl -s slps.github.io/zoo/php/cordy.bnf | egrep ":$" | wc -l
Rust curl -s doc.rust-lang.org/grammar.html | grep "[a-z_]* :" | wc -l
Erlang curl -s raw.githubusercontent.com/ignatov/intellij-erlang/master/grammars/erlang.bnf | grep "::=" | wc -l
Scala curl -s www.scala-lang.org/files/archive/spec/2.11/13-syntax-summary.html | grep "::=" | wc -l
В виде графика:
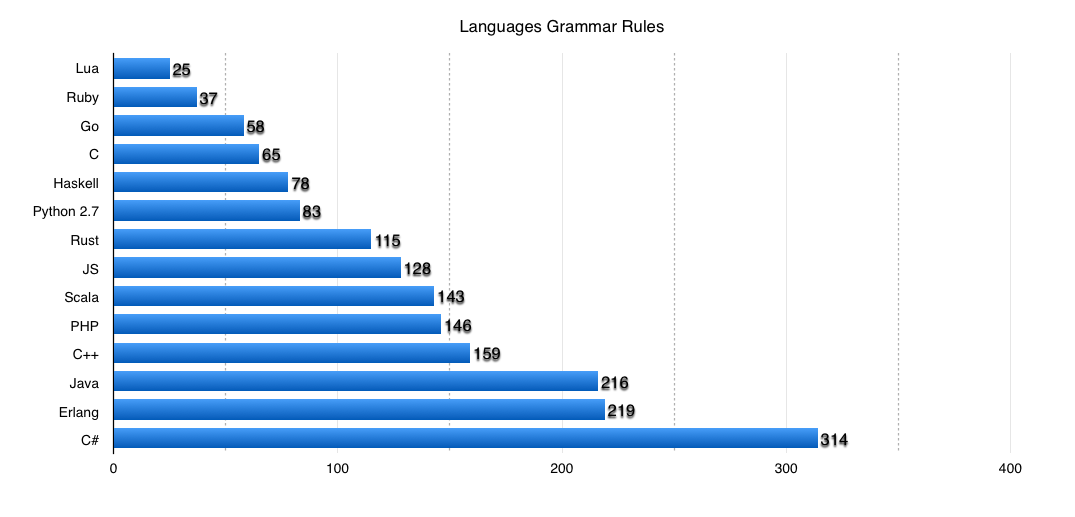
Еще раз повторюсь, эти методики не дают объективной картины и чисел, но дают грубую оценку одному из факторов сложности языка.
Третья методика оценить практическую сложность языка будет основана на статистических данных — количестве вопросов на StackOverflow с учетом коэффициента популярности языка. Предвижу критику о спорности методики, но на самом деле она имеет смысл, и ребята из RedMonk даже ведут такую статистику уже некоторое время: redmonk.com/sogrady/2015/01/14/language-rankings-1-15
StackOverflow хорош тем, что, благодаря модерации, теги по языкам проставлены достаточно аккуратно, и это, как ни крути, сейчас место, куда многие идут за вопросами даже раньше, чем на официальный сайт — даже термин такой придумали — SODD, Stack-Overflow Driven Development. Поэтому логично предположить, что чем больше вопросов — тем непонятнее, тем сложнее (хотя, безусловно, еще масса факторов влияет). Количество вопросов по тегам StackOverflow удобно предоставляет вот тут: stackoverflow.com/tags?page=2&tab=popular
При этом, разумеется, нужно учитывать абсолютное количество пишущих на том или ином языке, и для этого я возьму рейтинг по репозиториям GitHub за последний квартал 2014, доступный в замечательной форме вот тут: githut.info и количество активных репозиториев буду считать за кореллирующий показатель количества активно использующих язык.
А дальше схема простая — делим количество вопросов на StackOverflow на количество активных репозиториев на Github. Чем больше число, тем сложнее язык.
Вот что получается:
График:
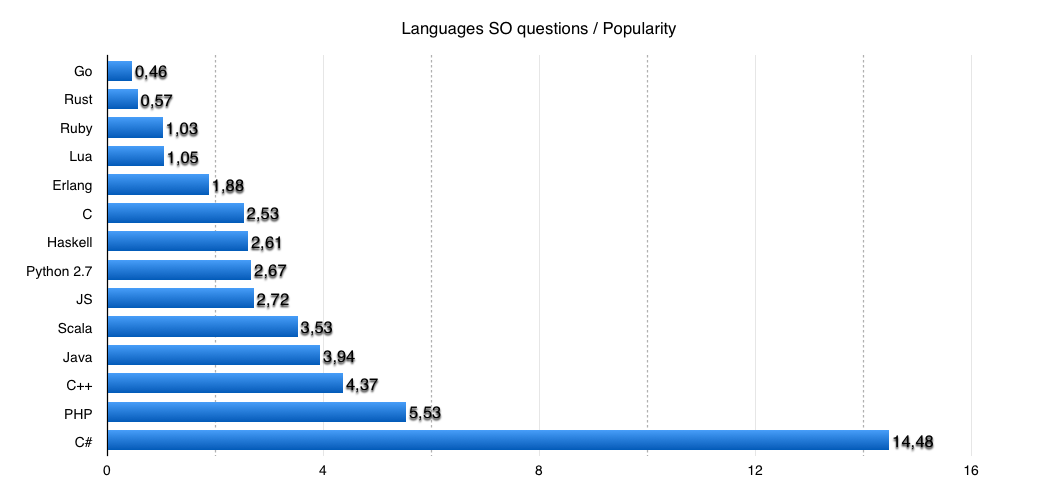
Предвосхищая комментарии, ещё раз напишу, что я прекрасно понимаю минусы и недостатки всех вышеописанных методик оценивания, но их потому и несколько, чтобы иметь возможность составить суммарную картину, минимизируя эффекты минусов всех этих подходов. Погрешность тут может быть очень большой (к примеру грамматика Руби тут проще грамматики Go, но тот скрипт однострочник лишь считает количество правил, но не их сложность — и весь синтаксический сахар Ruby, который добавляет достаточно сложности, тут не учтен). Если у кого-то есть ещё идеи, как можно оценивать объективно сложность языков программирования — пишите, буду рад услышать и обсудить.
В целом, по этим графикам видно, что данные достаточно совпадают, и сильных расхождений нет — четко видны группы “сложных”, “простых” и “средних” языков. Немного удивил результат Rust-а в последнем графике — как никак, Rust отнюдь не относится к простым языкам: скорее всего такой результат связан с молодостью языка (версия 1.0 вышла пару месяцев как), и, как следствие, высокой средней квалификации rust-девелоперов — отсюда и низкая относительная активность на Stack Overflow. В целом эти цифры у меня подкрепляются личными наблюдениями, по крайней мере в тех языках, которые я знаю лично. А те, которые не знаю, оцениваю достаточно близко.
Я предвижу критику по поводу методов выше и заявления о их несостоятельности. Поэтому сразу задаю два вопроса, ответы на которые можно прямо в комментарии с критикой оставлять:
а) какой есть метод лучше, для оценки сложности языка (в терминологии сложности данной статьи)?
б) как можно объяснить достаточно очевидную корелляцию результатов у всех трех методик, если они несостоятельны и их результаты — результат случайного распределения?
Ну и последнее — сложность языка — это лишь один из факторов успеха. Хотя статья и посвящена простоте Go, это далеко не единственная причина его успеха, хотя и одна из важных. Будь Go таким же простым, но не имей богатой стандартной библиотеки и отличного тулинга — скорее всего его путь был совсем иным.
После описания важности простоты инструментов разработки, и попытки формально доказать простоту Go относительно других популярных языков, важно напомнить, что это не случайность, а намеренное решение авторов языка. Это задумывалось вопреки популярному мнению — “чем сложнее, тем лучше” — и это принесло ожидаемый эффект. Количество людей и проектов, которые подхватили Go растёт большими темпами (сегодня без графиков, ссори)), и многие делают акцент именно на этом “освежающем” качестве Go — его простоте.
В конце концов, простота даёт людям возможность концентрироваться на логике программы, а не на управлении памятью, борьбе с компилятором и расшифровке витиеватых синтаксических конструкций языка. И это делает программирование снова интересным и увлекающим, как, возможно, в первые разы вашего знакомства с программированием вообще. Возможно вы еще помните тот фан, когда вы писали свои первые программы. Большинство отзывов людей, которые начали писать на Go заканчивается словами “Go makes programming fun again”. Но при этом вы пишете не Hello, World, а качественный современный софт, быстрый, кроссплатформенный, многопоточный и безопасный.
У каждого языка своя ниша, свои компромиссы и свои плюсы и минусы. Но если круг ваших задач пересекается с той областью, в которой Go уже доказал свою состоятельность — скорее всего вы получите большой плюс от простоты Go и тех эффектов, которые она оказывает на продуктивность и качество.
No Silver Bullet — faculty.salisbury.edu/~xswang/Research/Papers/SERelated/no-silver-bullet.pdf
Less Is Exponentially More — commandcenter.blogspot.com/2012/06/less-is-exponentially-more.html
Less is more — lambda-the-ultimate.org/node/4852

О сложности.
Простота — это противоположность сложности.
Сложность разработки ПО — тема, давно волновавшая умы инженеров и ученых, и один из наиболее концептуальных подходов к вопросу был оформлен автором известнейшей книги “Мифический человеко-месяц”, Фредериком Бруксом, в виде отдельного труда - “Серебрянной пули нет” (“No Silver Bullet”). Этот труд написан в 1987 году, но концептуальный взгляд на тему делает его актуальным и через 30 лет.
В частности, Брукс проводит важное разделение сложности на “неотъемлемую”(essential) и “привнесенную”(или “случайную” — accidental). Неотъемлемая сложность — это та сложность, которая происходит из самой области проблемы, от её природы. Скажем, если вам нужно имплементировать протокол FTP — неважно, какой язык или инструментарий вы выберете для этого, у вас все равно есть набор команд, действий, кодов возврата и логики, которую придется реализовать. Нет такого способа, чтобы упростить задачу до имплементации в одну строчку. Сложность вам даётся как данное (в данном случае из спецификации протокола), и способа повлиять на эту составляющую у вас, в общем случае, нет.
Привнесенная сложность — напротив, это сложность, которая происходит от тех инструментов, которые мы используем. Это та сложность, которую мы создаём себе сами. На неё мы можем влиять и уменьшать.
История развития индустрии разработки ПО сводится к уменьшению именно этой, accidental, сложности.
Почему сложность это плохо?
Все должно быть сделано так просто, как это возможно. Но не проще.
Альберт Эйнштейн
Ответ на вопрос — “хорошо” или “плохо”? — лежит исключительно в области признания или не признания хороших и плохих практик. Нет формального способа доказать, что, скажем, “глобальные переменные” — это хорошо или плохо. Рассматривая частные примеры, сторонники каждой из сторон найдут вам сотню убедительных аргументов и “за”, и “против”. Но собрав, хотя бы частично, опыт многих и многих разработчиков ПО, работающих с самыми разными программистами и языками, вы так или иначе будете слышать утверждения про “хорошие практики” или “плохие практики”.
Только с коллективным эмпирическим опытом многих тысяч инженеров и программистов, изложивших свои мысли на бумаге, приходит понимание, что “сложность” — это то, чего стоит избегать настолько, насколько это возможно. Сложность ведёт к целой лавине не сразу очевидных эффектов, которые также зачастую сложно формально доказать и которые измеряются вероятностями — большая вероятность появления ошибок, большее время на понимание кода, большее время и усилия, необходимые для изменения дизайна ПО в случае необходимости (рефакторинг), которые, в свою очередь, порождают стимул не производить эти изменения, которые, в свою очередь, приводят к тому, что разработчики начинают искать обходные пути и так далее.
В конце концов, код — это всего лишь инструмент решения задач, и в итоге главным критерием, отделяющим «хорошее» от «плохого» является продуктивность — скорость и качество решения этих самых задач. Сложность является убийцей продуктивности, и именно потому вся индустрия разработки движется в сторону уменьшения сложности.
Причем тут языки программирования?
Управление сложностью — квинтэссенция программирования.
Брайан Керниган
Выбор языка программирования — это очень удачный, если не лучший, пример “привнесённой сложности” в мире разработки ПО. Сами по себе языки программирования — это тоже инструменты для уменьшения сложности разработки. И каждый виток их развития, так или иначе решает один из аспектов сложности разработки ПО, но тем самым и привносит новые элементы сложности.
Вся история их развития — история поиска более простого инструмента для реалий того времени. Теория языков программирования — такая же развивающаяся наука, как и, допустим, нейробиология, и нет единого канонического знания, каким должен быть язык программирования. Это стохастический процесс, замешанный на законах рынка, удачных решениях, хорошего бэкапа в виде крупной компании (почти все популярные языки имели за спиной крупную компанию) и массе других факторов.
И этот процесс не стоит на месте, новые концепции порождают новые проблемы и новые уровни абстракций, растет коллективный опыт и понимание, вместе с тем, развивается и стремительно меняется экосистема железа и софта, меняются приоритеты в вопросах компромиссов и экономии ресурсов, и всё это плотно завязано на инерционности человеческого мозга и систем образования. Другими словами — это очень сложная махина. Простого и одного решения тут нет и быть не может.
Но что можно утверждать наверняка — что одни языки привносят больше сложности в общий пул сложности, а другие меньше. Одни практики и паттерны (“паттерны — это багрепорт на ваш язык”), которые навязываются языками, увеличивают суммарную сложность разработки, другие — уменьшают.
И мы, как инженеры, должны стремиться в итоге, к тому, чтобы избегать этой “привнесенной сложности”.
Сложность в Go
Go родился, как ответ на повышенную “привнесенную” сложность существующих языков. По крайней мере, той предметной области, которая волновала Google — разработки системного, сетевого и серверного софта. Его главной целью изначально было уменьшить эту сложность любой ценой. Это был главный приоритет с самого начала.
Немалую роль тут сыграл колоссальный практический опыт авторов Go — Пайка, Томпсона и компании — людей, стоявших у истоков Unix, языка C и UTF-8, а сейчас работающих над ключевыми продуктами Google. Так или иначе, но Go явился в некоторой степени радикальным языком, который качнул маятник сложности в другую сторону, пытаясь выровнять существующий ландшафт мира разработки ПО.
И это именно то, что подразумевается под термином “простота” в контексте Go. Уменьшение сложности. Уменьшение времени необходимое среднестатическому программисту для понимания среднестатического проекта, написанного другими людьми. Уменьшение рисков ошибок. Уменьшение времени и затрат на «хорошие практики». Уменьшение шансов писать код плохо и некрасиво. Уменьшение времени на освоение языка. И так далее, и тому подобное.
Цифры
Но довольно слов, давайте и в самом деле попробуем оценить сложность, привносимую языками. В комментариях к предыдущим статьям, отсутствие «формального доказательства» было причиной бурных споров. Сразу скажу, что осознаю сложность этой задачи. Реальная оценка лежит в плоскости субъективного практического опыта и трудноизмеряемых вероятностей. Простого способа свести всё к одной цифре и сказать «сложность языка А больше, чем языка Б» — нет. Но тем не менее, если вы хорошо знаете какие-либо два или больше языка, вы для себя достаточно легко можете решить, какой язык для вас проще. Ваш мозг как-то умеет оценить и решить, какой из языков сложнее.
Поэтому, за неимением лучшего варианта, я попробую взять несколько методик, и посмотреть какую картину они нарисуют. У каждой методики есть серъезные недостатки, но если их результаты не будут сильно различаться, можно будет считать, что это что-то большее, чем случайное распределение.
При этом я буду анализировать языки, которые достаточно универсальны для решения большого круга задач, имеют достаточно большое сообщество и информация о них доступна. Экзотику вроде Brainfuck мы не рассматриваем.
Метод 1.
Одной из таких простейших методик является подсчет ключевых слов (keywords) языка. На самом деле точнее будет оценивать концепты, которые привносит язык — но это сложнее считается, и при этом кореллирует с количеством ключевых слов. Оценка будет очень грубая, но достаточно показательная и логичная. Логичная, потому что меньшее количество знаний равно меньшей когнитивной нагрузке на мозг.
Вот что мы имеем:
| Python 2.7 | 31 | docs.python.org/2.7/reference/lexical_analysis.html |
| Python 3 | 33 | docs.python.org/3.4/reference/lexical_analysis.html |
| Lua | 21 | www.lua.org/manual/5.1/manual.html |
| C (C99) | 32 | en.wikipedia.org/wiki/C_syntax#Reserved_keywords |
| C (C11) | 37 | en.wikipedia.org/wiki/C_syntax#Reserved_keywords |
| C++11 | 85 | en.cppreference.com/w/cpp/keyword |
| Go | 25 | golang.org/ref/spec |
| JS (ECMAScript 5.1) | 41 | www.ecma-international.org/ecma-262/5.1/#sec-7.6.1 |
| Haskell | 55 | www.haskell.org/haskellwiki/Keywords |
| Java | 50 | en.wikipedia.org/wiki/List_of_Java_keywords |
| C# | 79 | msdn.microsoft.com/en-us/library/x53a06bb.aspx |
| PHP | 58 | www.php.net/manual/en/reserved.keywords.php |
| Ruby 1.9 | 42 | ruby-doc.org/docs/keywords/1.9 |
| Scala | 41 | www.scala-lang.org/files/archive/spec/2.11/01-lexical-syntax.html |
| Erlang | 27? | erlang.org/doc/reference_manual/introduction.html |
То же самое, в виде графика:
Метод 2
Можно попробовать оценить грамматики языка, многие из которых описаны с помощью Формы Бэкуса-Наура. Грамматики в этом формате (BNF/EBNF) есть не ко всем языкам, но в сети есть немало различных грамматик, составленных полуавтоматически. К примеру, я брал несколько грамматик отсюда: slps.github.io/zoo/index.html. Оценивать количество правил я буду простыми однострочниками. К примеру, для Go извлечь ENBF-правила очень просто прямо с официальной страницы со спецификацией языка:
$ curl -s http://golang.org/ref/spec | grep pre.*ebnf | wc -lХотя в других спецификациях иногда не сильно просто подсчитать количество правил. На всякий случай, привожу команду, которой считал.
| Язык | Количество правил |
|---|---|
| C | 65 |
| Go | 58 |
| Python | 83 |
| Haskell | 78 |
| JS (ECMAScript 5.1) | 128 |
| Ruby (для 1.4) | 37 |
| Java (JRE 1.9) | 216 |
| C++ (2008) | 159 |
| C# 4.0 | 314 |
| Lua 5.1 | 25 |
| PHP | 146 |
| Rust | 115 |
| Erlang | 219 |
| Scala | 143 |
Команды для подсчета:
C curl -s www.cs.man.ac.uk/~pjj/bnf/c_syntax.bnf | grep ": " | wc -l
Go curl -s golang.org/ref/spec | grep pre.*ebnf | wc -l
Python manually copy text from docs.python.org/2/reference/grammar.html, then “cat py.bnf | grep ": " | wc-l”
Haskell www.haskell.org/onlinereport/haskell2010/haskellch10.html#x17-17500010
JS (ECMAScript 5.1) curl -s www.ecma-international.org/ecma-262/5.1 | grep '.*::'| tr -d ' ' | sort -u | wc -l
Ruby (для 1.4) curl -s docs.huihoo.com/ruby/ruby-man-1.4/yacc.html | grep ": " | wc -l
Java (JRE 1.9) curl -s docs.oracle.com/javase/specs/jls/se8/html/jls-19.html | grep '' | wc -l
C++ (2008) curl -s slps.github.io/zoo/cpp/iso-n2723.bnf | egrep ":$" | wc -l
C# 4.0 curl -s slps.github.io/zoo/cs/csharp-msft-ls-4.0.bnf | egrep ":$" | wc -l
Lua 5.1 curl -s wiki.luajit.org/Extended-BNF | grep "::=" | wc -l
PHP curl -s slps.github.io/zoo/php/cordy.bnf | egrep ":$" | wc -l
Rust curl -s doc.rust-lang.org/grammar.html | grep "[a-z_]* :" | wc -l
Erlang curl -s raw.githubusercontent.com/ignatov/intellij-erlang/master/grammars/erlang.bnf | grep "::=" | wc -l
Scala curl -s www.scala-lang.org/files/archive/spec/2.11/13-syntax-summary.html | grep "::=" | wc -l
В виде графика:
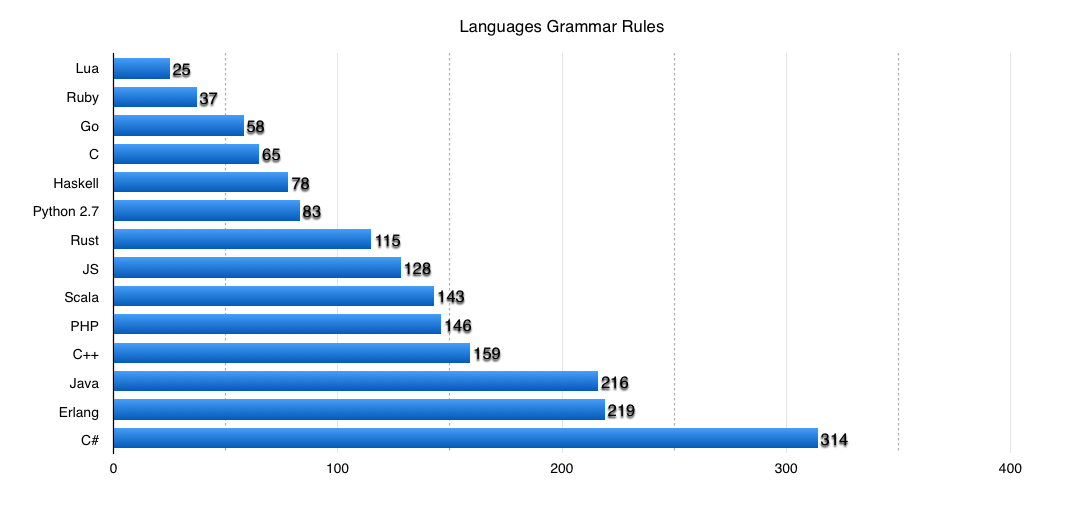
Еще раз повторюсь, эти методики не дают объективной картины и чисел, но дают грубую оценку одному из факторов сложности языка.
Метод 3.
Третья методика оценить практическую сложность языка будет основана на статистических данных — количестве вопросов на StackOverflow с учетом коэффициента популярности языка. Предвижу критику о спорности методики, но на самом деле она имеет смысл, и ребята из RedMonk даже ведут такую статистику уже некоторое время: redmonk.com/sogrady/2015/01/14/language-rankings-1-15
StackOverflow хорош тем, что, благодаря модерации, теги по языкам проставлены достаточно аккуратно, и это, как ни крути, сейчас место, куда многие идут за вопросами даже раньше, чем на официальный сайт — даже термин такой придумали — SODD, Stack-Overflow Driven Development. Поэтому логично предположить, что чем больше вопросов — тем непонятнее, тем сложнее (хотя, безусловно, еще масса факторов влияет). Количество вопросов по тегам StackOverflow удобно предоставляет вот тут: stackoverflow.com/tags?page=2&tab=popular
При этом, разумеется, нужно учитывать абсолютное количество пишущих на том или ином языке, и для этого я возьму рейтинг по репозиториям GitHub за последний квартал 2014, доступный в замечательной форме вот тут: githut.info и количество активных репозиториев буду считать за кореллирующий показатель количества активно использующих язык.
А дальше схема простая — делим количество вопросов на StackOverflow на количество активных репозиториев на Github. Чем больше число, тем сложнее язык.
Вот что получается:
| Язык | Репозиториев на GitHub | Вопросы на SO | Соотношение |
|---|---|---|---|
| Go | 22264 | 10272 | 0,46 |
| Ruby | 132848 | 136920 | 1,03 |
| Lua | 8123 | 8502 | 1,04 |
| Rust | 4383 | 2478 | 1,76 |
| C | 73075 | 184984 | 2,53 |
| Haskell | 8789 | 22930 | 2,60 |
| Python 2.7 | 164852 | 439994 | 2,66 |
| JS | 323938 | 880188 | 2,71 |
| Java | 222852 | 879064 | 3,94 |
| C++ | 86505 | 377834 | 4,36 |
| PHP | 138771 | 768018 | 5,53 |
| C# | 56062 | 811952 | 14,48 |
| Erlang | 2961 | 5571 | 1,88 |
| Scala | 10853 | 38302 | 3,52 |
График:
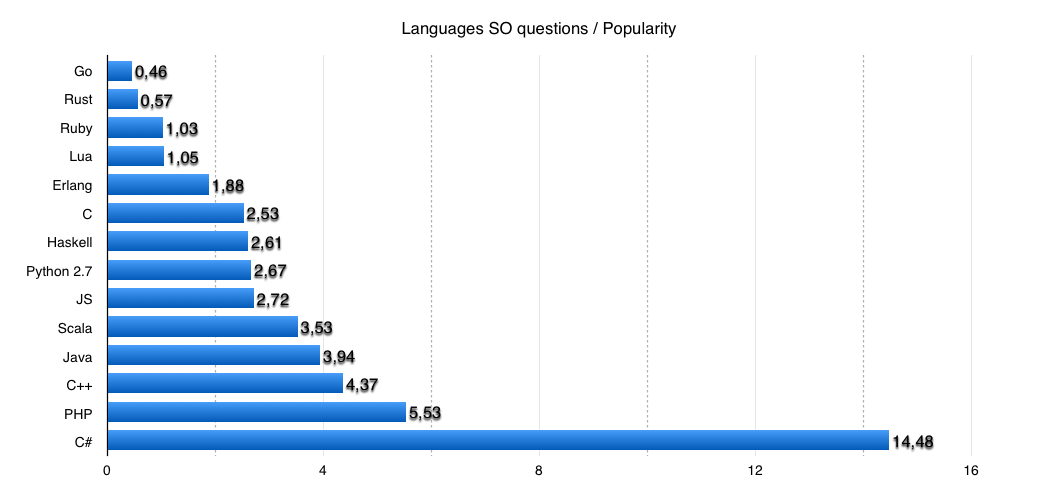
Выводы
Предвосхищая комментарии, ещё раз напишу, что я прекрасно понимаю минусы и недостатки всех вышеописанных методик оценивания, но их потому и несколько, чтобы иметь возможность составить суммарную картину, минимизируя эффекты минусов всех этих подходов. Погрешность тут может быть очень большой (к примеру грамматика Руби тут проще грамматики Go, но тот скрипт однострочник лишь считает количество правил, но не их сложность — и весь синтаксический сахар Ruby, который добавляет достаточно сложности, тут не учтен). Если у кого-то есть ещё идеи, как можно оценивать объективно сложность языков программирования — пишите, буду рад услышать и обсудить.
В целом, по этим графикам видно, что данные достаточно совпадают, и сильных расхождений нет — четко видны группы “сложных”, “простых” и “средних” языков. Немного удивил результат Rust-а в последнем графике — как никак, Rust отнюдь не относится к простым языкам: скорее всего такой результат связан с молодостью языка (версия 1.0 вышла пару месяцев как), и, как следствие, высокой средней квалификации rust-девелоперов — отсюда и низкая относительная активность на Stack Overflow. В целом эти цифры у меня подкрепляются личными наблюдениями, по крайней мере в тех языках, которые я знаю лично. А те, которые не знаю, оцениваю достаточно близко.
Я предвижу критику по поводу методов выше и заявления о их несостоятельности. Поэтому сразу задаю два вопроса, ответы на которые можно прямо в комментарии с критикой оставлять:
а) какой есть метод лучше, для оценки сложности языка (в терминологии сложности данной статьи)?
б) как можно объяснить достаточно очевидную корелляцию результатов у всех трех методик, если они несостоятельны и их результаты — результат случайного распределения?
Ну и последнее — сложность языка — это лишь один из факторов успеха. Хотя статья и посвящена простоте Go, это далеко не единственная причина его успеха, хотя и одна из важных. Будь Go таким же простым, но не имей богатой стандартной библиотеки и отличного тулинга — скорее всего его путь был совсем иным.
Заключение
После описания важности простоты инструментов разработки, и попытки формально доказать простоту Go относительно других популярных языков, важно напомнить, что это не случайность, а намеренное решение авторов языка. Это задумывалось вопреки популярному мнению — “чем сложнее, тем лучше” — и это принесло ожидаемый эффект. Количество людей и проектов, которые подхватили Go растёт большими темпами (сегодня без графиков, ссори)), и многие делают акцент именно на этом “освежающем” качестве Go — его простоте.
В конце концов, простота даёт людям возможность концентрироваться на логике программы, а не на управлении памятью, борьбе с компилятором и расшифровке витиеватых синтаксических конструкций языка. И это делает программирование снова интересным и увлекающим, как, возможно, в первые разы вашего знакомства с программированием вообще. Возможно вы еще помните тот фан, когда вы писали свои первые программы. Большинство отзывов людей, которые начали писать на Go заканчивается словами “Go makes programming fun again”. Но при этом вы пишете не Hello, World, а качественный современный софт, быстрый, кроссплатформенный, многопоточный и безопасный.
У каждого языка своя ниша, свои компромиссы и свои плюсы и минусы. Но если круг ваших задач пересекается с той областью, в которой Go уже доказал свою состоятельность — скорее всего вы получите большой плюс от простоты Go и тех эффектов, которые она оказывает на продуктивность и качество.
Ссылки
No Silver Bullet — faculty.salisbury.edu/~xswang/Research/Papers/SERelated/no-silver-bullet.pdf
Less Is Exponentially More — commandcenter.blogspot.com/2012/06/less-is-exponentially-more.html
Less is more — lambda-the-ultimate.org/node/4852
