За недолгое время моего процесса обучения я понял одну вещь – знаниями нужно делиться. Осознал я это давно, но лень перебороть и найти время не всегда получается.
Речь в этой статье пойдет про использование различных методов машинного обучения для решения проблем, связанных с обработкой естественного языка (NLP). Одной из таких проблем является автоматическое определение эмоциональной окраски (позитивный, негативный, нейтральный) текстовых данных, то есть анализа тональности (sentiment analysis). Цель этой задачи состоит в определении, является ли данный текст (допустим обзор фильма или комментарии) положительным, отрицательным или нейтральным по своему влиянию на репутацию конкретного объекта. Трудность анализа тональности заключается в присутствии эмоционально обогащенного языка — сленг, многозначность, неопределенность, сарказм, все эти факторы вводят в заблуждение не только людей, но и компьютеров.

На хабре уже не раз появлялись статьи связанные с определением тональности 1, 2, 3. Да и вообще, эта тема является одной из самых обсуждаемых во всем мире в последнее время [1, 2, 3, 4].
Сразу обговорю, что в этой статье особо никаких новшеств вы не найдете, данный материал скорее всего может послужит туториалом для новичков в сфере машинного обучения и NLP, коим я и являюсь. Основной же материал, который я использовал вы можете найти по этой ссылке. Весь исходный код вы можете найти по этой ссылке.
Итак, в чем же состоит проблема и как ее решить?
Допустим мы имеем текстовое сообщение (описание фильма, рецензия, комментарии):
“This film made me upset. It’s just taking your free time and throwing it in a trash (((”
Или же:
“The best movie I’ve ever seen!!! Musical composition, actors, scenario, etc. all this stuff are just amazing!!!”
В первом примера система должна выдать отрицательный результат, так как комментарий негативный, а во втором соответственно положительный. Подобного рода задачи в машинном обучении называется классификацией, а метод — обучение с учителем. То есть, сначала алгоритм на обучающей выборке «тренируется», сохраняя необходимые коэффициенты и другие данные модели, затем при входе новых данных с определённой вероятностью классифицирует их. Под коэффициентом я имею ввиду нечто вроде этого:
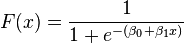
Где, бета-значения — это наши коэффициенты полученные на основе обучения на тестовых данных. Как мы видим, данная формула в конечном счете возвращает значение от 0 до 1 (см. подробнее — сигмоида), то есть чем ближе к 0, тем больше вероятности, что текст несет негативную информацию.
Для обучающей выборки мы использовали открытый набор данных с сайта www.kaggle.com, а именно, набор включающий в себя данные из 50000 обзоров фильма из сайта IMDB, специально отобранных для анализа тональности. Метрика тональности является двоичной величиной, то есть рейтинг IMDB < 5 присуждается значение 0, а рейтингу > = 7 присуждается значение 1.
Каждая запись этого набора данных состоит из следующих полей:
Итак, приступим непосредственно к решению задачи. Весь алгоритм описанный в данной статье реализован на языке python (v. 2.7). Для удобство чтения я разбил алгоритм на следующие шаги:
Перед любой обработкой данных требуется предобработка. В этой стадий удаляются все html тэги, пунктуаций, символы. Данная операция осуществляется с помощью библиотеки python — «Beautiful Soup». Также все числа и ссылки в тексте заменяются на тэги , . Далее в тексте присутствуют так называемые «стоп слова» — это частые слова в языке, которые в основном не несут никакую смысловую нагрузку (например, в английском языке это такие слова как «the, at, about…»). Стоп слова удаляются с помощью пакета Python Natural Language Toolkit (NLTK). После предобработки исходного текста мы получаем следующее:
[biography, part, feature, film, remember, going, see, cinema, originally] – То есть набор слов.
В этом этапе можно и дальше изощряться модифицируя каждое слова в начальную форму (stemming), т.д. Но для данного эксперимента я решился ограничиться и остановиться на этом.
Дело в том, что компьютеру, также, как и математическим формулам легче работать с числами, а не набором слов. Поэтому нам нужно представить любой текст в виде вектора из чисел. Для этого можно составить словарь со всеми словами, т.е. объединить все слова встречающийся в текстах в один большой словарь, или же использовать готовые словари (Даля или Зализняка), и заменить слова из текста индексом в словаре. То есть допустим мы имеем всего три обзора со следующими пред-обработанными векторами слов:
Объединяя все слова из списка в один мы получим следующий отсортированный словарь (назовем его как базис вектор):
[biography, cinema, feature, film, going, originally, part, remember, see]
Заменяя предыдущие вектора на индекс слова в словаре получаем следующее:
Проделав такую работу для всех отзывов мы можем получить достаточно большой список (в моем примере я взял 5000 самые часто встречающие слова). Эти вектора называются «векторами свойств» или же «features vector». Таким образом мы получаем вектора для каждого тестового отзыва, дальше мы сможем сравнивать эти вектора с помощью стандартных метрик, таких как Евклидовое расстояние, косинусное расстояние, и т.д. Данный подход называется «мешок слов» или же “Bag-Of-Words”.
Первый подход является довольно распространённым методом и довольно прост в реализаций, но он не исключен от недостатков. При сравнений двух векторов используется точное совпадение слов, при этом мы теряем важную информацию. Одним из таких «упущенных» информаций является семантика слова. Например, мы с легкостью можем заменить слово «черный» со словом «темный», так как их смысл очень схож. Такие слова можно назвать – семантический схожие слова. В группу таких слов входят синонимы, гипонимы, гиперонимы, и т.д.
В альтернативном подходе мы попытаемся заменить каждое слово в списке номером его семантической группы. В итоге мы получим нечто вроде «мешка слов», но с более глубоким смыслом. Для этого используется технология Word2Vec от Google. Его можно найти в пакете библиотеки gensim, со встроенными моделями Word2Vec.
Суть модели Word2Vec заключается в следующем – на вход дается большой объем текста (в нашем случае примерно 10000 отзывов), на выходе мы получаем взвешенный вектор для каждого слова, фиксированный длины (длина вектора задается вручную), которая встречается в датасете. Например для слова men, сравнивая со всеми словами и сортируя в убывающем порядке я получил следующий результат (за меру близости я выбрал косинусное расстояние):
Семантический близкие слова к слову ‘man’
Подробнее как работает модель Word2Vec можно узнать по этой ссылке.
Далее для объединения близких по смыслу слов используется кластеризация. Да, тут еще один заумное слова — кластеризация. Не буду останавливаться на этом подробно, статья в вики (sigmoid) думаю хорошо все объяснит. Но скажу суть самого примитивного алгоритма кластеризации (К-средних): пусть мы имеем определенное количество кластеров N, алгоритм обучаясь на тренировочных данных делит их на кластеры и находит центры каждого из них, затем при входе тестовых данных, алгоритм присваивает ему номер кластера, центр которого ближе всех к нему. В данном случае я просто взял количество слов в словаре и поделил его на 5, считая, что в каждом кластере будет находиться в среднем по 5 слов. В среднем у меня вышло ~3000 кластеров. Далее мы делаем то же самое, как и в первом подходе “Bag-Of-Words”, заменяя каждое слово индексом кластера, только на этот раз у нас выходит что-то вроде “Bag-Of-Clusters”. Полный исходный код с объяснениями по данному методу, вы можете получить по этой ссылке.
Итак, на банном этапе мы уже удалили все ненужные вещи, преобразовали текст в вектор, и теперь выходим на финишную прямую. Алгоритм классификаций Random Forest используется для классификаций документов в этом эксперименте. Алгоритм уже реализован в пакете scikit-learn, все, что нам остается это вскормить наши текстовые данные и указать количество деревьев. Дальше алгоритм все берет на себя, тренируется на обучающей выборке, сохраняет все необходимые данные.
Вкратце, я запустил классификатор на основе обоих подходов получения собственных векторов. Получил вот такие интересные результаты:
Учитывая тот факт, что запуск Word2Vec заняло у меня 2 часа на моем старом ноуте, показал сравнительно лучше результат, чем старый добрый Bag-Of-Words.
[1] I. Chetviorkin, P. Braslavskiy, N. Loukachevich, “Sentiment Analysis Track at ROMIP 2011,” In Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialog 2012”, Bekasovo, 2012, pp. 1–14.
[2] A.A. Pak, S.S. Narynov, A.S. Zharmagambetov, S.N. Sagyndykova, Z.E. Kenzhebayeva, I. Turemuratovich, “The method of synonyms extraction from unannotated corpus,” In proc. of DINWC2015, Moscow, 2015, pp. 1-5
[3] T. Mikolov, K. Chen, G. Corrado, J. Dean, “Efficient Estimation of Word Representations in Vector Space,” In Proc. of Workshop at ICLR, 2013.
[4] P. Bo and L. Lee, “A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts,” In Proceedings of the ACL, 2004
[5] T. Joachims, “Text categorization with support vector machines: Learning with many relevant features,” In European Conference on Machine Learning (ECML), Springer Berlin/Heidelberg, 1998, pp. 137-142
[6] P.D. Turney, “Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews,” Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL'02), Philadelphia, Pennsylvania, 2002, pp. 417-424.
[7] A. Go, R. Bhayani, L. Huang, “Twitter Sentiment Classification Using Distant Supervision,” Technical report, Stanford. 2009.
[8] J. Furnkranz, T. Mitchell, and E. Riloff, «A Case Study in Using Linguistic Phrases for Text Categorization on the WWW,» In AAAI/ICML Workshop on Learning for Text Categorization, 1998, pp. 5-12.
[9] M.F. Caropreso, S. Matwin, F. Sebastiani, “A learner-independent evaluation of the usefulness of statistical phrases for automated text categorization,” Text databases and document management: Theory and practice, 2001, pp. 78-102.
Речь в этой статье пойдет про использование различных методов машинного обучения для решения проблем, связанных с обработкой естественного языка (NLP). Одной из таких проблем является автоматическое определение эмоциональной окраски (позитивный, негативный, нейтральный) текстовых данных, то есть анализа тональности (sentiment analysis). Цель этой задачи состоит в определении, является ли данный текст (допустим обзор фильма или комментарии) положительным, отрицательным или нейтральным по своему влиянию на репутацию конкретного объекта. Трудность анализа тональности заключается в присутствии эмоционально обогащенного языка — сленг, многозначность, неопределенность, сарказм, все эти факторы вводят в заблуждение не только людей, но и компьютеров.

На хабре уже не раз появлялись статьи связанные с определением тональности 1, 2, 3. Да и вообще, эта тема является одной из самых обсуждаемых во всем мире в последнее время [1, 2, 3, 4].
Сразу обговорю, что в этой статье особо никаких новшеств вы не найдете, данный материал скорее всего может послужит туториалом для новичков в сфере машинного обучения и NLP, коим я и являюсь. Основной же материал, который я использовал вы можете найти по этой ссылке. Весь исходный код вы можете найти по этой ссылке.
Итак, в чем же состоит проблема и как ее решить?
Допустим мы имеем текстовое сообщение (описание фильма, рецензия, комментарии):
“This film made me upset. It’s just taking your free time and throwing it in a trash (((”
Или же:
“The best movie I’ve ever seen!!! Musical composition, actors, scenario, etc. all this stuff are just amazing!!!”
В первом примера система должна выдать отрицательный результат, так как комментарий негативный, а во втором соответственно положительный. Подобного рода задачи в машинном обучении называется классификацией, а метод — обучение с учителем. То есть, сначала алгоритм на обучающей выборке «тренируется», сохраняя необходимые коэффициенты и другие данные модели, затем при входе новых данных с определённой вероятностью классифицирует их. Под коэффициентом я имею ввиду нечто вроде этого:

Где, бета-значения — это наши коэффициенты полученные на основе обучения на тестовых данных. Как мы видим, данная формула в конечном счете возвращает значение от 0 до 1 (см. подробнее — сигмоида), то есть чем ближе к 0, тем больше вероятности, что текст несет негативную информацию.
Для обучающей выборки мы использовали открытый набор данных с сайта www.kaggle.com, а именно, набор включающий в себя данные из 50000 обзоров фильма из сайта IMDB, специально отобранных для анализа тональности. Метрика тональности является двоичной величиной, то есть рейтинг IMDB < 5 присуждается значение 0, а рейтингу > = 7 присуждается значение 1.
Каждая запись этого набора данных состоит из следующих полей:
- ID — уникальный идентификатор каждого обзора;
- Sentiment — тональность обзора; 1 или 0;
- Review — Текст обзора.
Алгоритм
Итак, приступим непосредственно к решению задачи. Весь алгоритм описанный в данной статье реализован на языке python (v. 2.7). Для удобство чтения я разбил алгоритм на следующие шаги:
Шаг 1. Предобработка
Перед любой обработкой данных требуется предобработка. В этой стадий удаляются все html тэги, пунктуаций, символы. Данная операция осуществляется с помощью библиотеки python — «Beautiful Soup». Также все числа и ссылки в тексте заменяются на тэги , . Далее в тексте присутствуют так называемые «стоп слова» — это частые слова в языке, которые в основном не несут никакую смысловую нагрузку (например, в английском языке это такие слова как «the, at, about…»). Стоп слова удаляются с помощью пакета Python Natural Language Toolkit (NLTK). После предобработки исходного текста мы получаем следующее:
[biography, part, feature, film, remember, going, see, cinema, originally] – То есть набор слов.
В этом этапе можно и дальше изощряться модифицируя каждое слова в начальную форму (stemming), т.д. Но для данного эксперимента я решился ограничиться и остановиться на этом.
Шаг 2. Представление в виде вектора
Подход 1
Дело в том, что компьютеру, также, как и математическим формулам легче работать с числами, а не набором слов. Поэтому нам нужно представить любой текст в виде вектора из чисел. Для этого можно составить словарь со всеми словами, т.е. объединить все слова встречающийся в текстах в один большой словарь, или же использовать готовые словари (Даля или Зализняка), и заменить слова из текста индексом в словаре. То есть допустим мы имеем всего три обзора со следующими пред-обработанными векторами слов:
- [biography, part, feature]
- [film, remember, going]
- [see, cinema, originally]
Объединяя все слова из списка в один мы получим следующий отсортированный словарь (назовем его как базис вектор):
[biography, cinema, feature, film, going, originally, part, remember, see]
Заменяя предыдущие вектора на индекс слова в словаре получаем следующее:
- [1, 0, 1, 0, 0, 0, 1, 0, 0]
- [0, 0, 0, 1, 1, 0, 0, 1, 0]
- [0, 1, 0, 0, 1, 0, 0, 0, 1]
Проделав такую работу для всех отзывов мы можем получить достаточно большой список (в моем примере я взял 5000 самые часто встречающие слова). Эти вектора называются «векторами свойств» или же «features vector». Таким образом мы получаем вектора для каждого тестового отзыва, дальше мы сможем сравнивать эти вектора с помощью стандартных метрик, таких как Евклидовое расстояние, косинусное расстояние, и т.д. Данный подход называется «мешок слов» или же “Bag-Of-Words”.
from sklearn.feature_extraction.text import CountVectorizer
# в пакете sklearn уже есть встроенный метод по получению “Bag-Of-Words”
vectorizer = CountVectorizer(analyzer = "word", \
tokenizer = None, \
preprocessor = None, \
stop_words = None, \
max_features = 5000)
train_data_features = vectorizer.fit_transform(clean_train_reviews)
train_data_features = train_data_features.toarray()
Подход 2
Первый подход является довольно распространённым методом и довольно прост в реализаций, но он не исключен от недостатков. При сравнений двух векторов используется точное совпадение слов, при этом мы теряем важную информацию. Одним из таких «упущенных» информаций является семантика слова. Например, мы с легкостью можем заменить слово «черный» со словом «темный», так как их смысл очень схож. Такие слова можно назвать – семантический схожие слова. В группу таких слов входят синонимы, гипонимы, гиперонимы, и т.д.
В альтернативном подходе мы попытаемся заменить каждое слово в списке номером его семантической группы. В итоге мы получим нечто вроде «мешка слов», но с более глубоким смыслом. Для этого используется технология Word2Vec от Google. Его можно найти в пакете библиотеки gensim, со встроенными моделями Word2Vec.
Суть модели Word2Vec заключается в следующем – на вход дается большой объем текста (в нашем случае примерно 10000 отзывов), на выходе мы получаем взвешенный вектор для каждого слова, фиксированный длины (длина вектора задается вручную), которая встречается в датасете. Например для слова men, сравнивая со всеми словами и сортируя в убывающем порядке я получил следующий результат (за меру близости я выбрал косинусное расстояние):
Семантический близкие слова к слову ‘man’
| Words | Measures |
| woman | 0,6056 |
| guy | 0,4935 |
| boy | 0,4893 |
| men | 0,4632 |
| person | 0,4574 |
| lady | 0,4487 |
| himself | 0,4288 |
| girl | 0,4166 |
| his | 0,3853 |
| he | 0,3829 |
Подробнее как работает модель Word2Vec можно узнать по этой ссылке.
Далее для объединения близких по смыслу слов используется кластеризация. Да, тут еще один заумное слова — кластеризация. Не буду останавливаться на этом подробно, статья в вики (sigmoid) думаю хорошо все объяснит. Но скажу суть самого примитивного алгоритма кластеризации (К-средних): пусть мы имеем определенное количество кластеров N, алгоритм обучаясь на тренировочных данных делит их на кластеры и находит центры каждого из них, затем при входе тестовых данных, алгоритм присваивает ему номер кластера, центр которого ближе всех к нему. В данном случае я просто взял количество слов в словаре и поделил его на 5, считая, что в каждом кластере будет находиться в среднем по 5 слов. В среднем у меня вышло ~3000 кластеров. Далее мы делаем то же самое, как и в первом подходе “Bag-Of-Words”, заменяя каждое слово индексом кластера, только на этот раз у нас выходит что-то вроде “Bag-Of-Clusters”. Полный исходный код с объяснениями по данному методу, вы можете получить по этой ссылке.
Шаг 3. Классификация текстов
Итак, на банном этапе мы уже удалили все ненужные вещи, преобразовали текст в вектор, и теперь выходим на финишную прямую. Алгоритм классификаций Random Forest используется для классификаций документов в этом эксперименте. Алгоритм уже реализован в пакете scikit-learn, все, что нам остается это вскормить наши текстовые данные и указать количество деревьев. Дальше алгоритм все берет на себя, тренируется на обучающей выборке, сохраняет все необходимые данные.
from sklearn.ensemble import RandomForestClassifier
# Инициализируем количество деревьев - 100
forest = RandomForestClassifier(n_estimators = 100)
forest = forest.fit( train_data_features, train["sentiment"] )
Результаты
Вкратце, я запустил классификатор на основе обоих подходов получения собственных векторов. Получил вот такие интересные результаты:
| Method | precision | recall | F-measure | accuracy |
| bag-of-words | 85.2% | 83.7% | 84.4% | 84.5% |
| Word2Vec | 90.3% | 87.2% | 88.7% | 89.8% |
Учитывая тот факт, что запуск Word2Vec заняло у меня 2 часа на моем старом ноуте, показал сравнительно лучше результат, чем старый добрый Bag-Of-Words.
Использованные материалы:
[1] I. Chetviorkin, P. Braslavskiy, N. Loukachevich, “Sentiment Analysis Track at ROMIP 2011,” In Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialog 2012”, Bekasovo, 2012, pp. 1–14.
[2] A.A. Pak, S.S. Narynov, A.S. Zharmagambetov, S.N. Sagyndykova, Z.E. Kenzhebayeva, I. Turemuratovich, “The method of synonyms extraction from unannotated corpus,” In proc. of DINWC2015, Moscow, 2015, pp. 1-5
[3] T. Mikolov, K. Chen, G. Corrado, J. Dean, “Efficient Estimation of Word Representations in Vector Space,” In Proc. of Workshop at ICLR, 2013.
[4] P. Bo and L. Lee, “A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts,” In Proceedings of the ACL, 2004
[5] T. Joachims, “Text categorization with support vector machines: Learning with many relevant features,” In European Conference on Machine Learning (ECML), Springer Berlin/Heidelberg, 1998, pp. 137-142
[6] P.D. Turney, “Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews,” Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL'02), Philadelphia, Pennsylvania, 2002, pp. 417-424.
[7] A. Go, R. Bhayani, L. Huang, “Twitter Sentiment Classification Using Distant Supervision,” Technical report, Stanford. 2009.
[8] J. Furnkranz, T. Mitchell, and E. Riloff, «A Case Study in Using Linguistic Phrases for Text Categorization on the WWW,» In AAAI/ICML Workshop on Learning for Text Categorization, 1998, pp. 5-12.
[9] M.F. Caropreso, S. Matwin, F. Sebastiani, “A learner-independent evaluation of the usefulness of statistical phrases for automated text categorization,” Text databases and document management: Theory and practice, 2001, pp. 78-102.
