Эта статья продолжает цикл об особенностях, слабых сторонах и непосредственно о распознавании популярных капчей.
В предыдущей публикации мы затронули готовое решение KCAPTCHA, которое несмотря на неплохую защищенность было распознано без сколько-нибудь серьезной предварительной обработки и сегментации, обычным многослойным персептроном.
Теперь на очереди кириллическая Яндекс капча, с которой, уверен, многие из нас отлично знакомы.
Итак, мы имеем такую капчу:

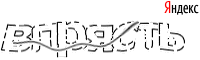
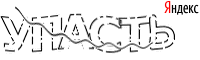
Условно разделим распознавание на следующие этапы:
Убираем логотип Яндекса и автокадрируем изображение:
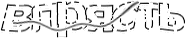
Нормализуем входные данные:
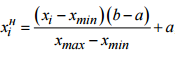
Где x — значения цвета пикселей, [a,b] – интервал допустимых значений входных сигналов. В нашем случае от -1 до 1.
За распознавание длины капчи отвечает сеть с 4-мя нейронами выходного слоя, каждый из которых соответствует значению длины от 4 до 7.
Теперь, зная длину капчи, остается лишь разделить изображение на равные части, для дальнейшего распознавания:

Для распознавания букв используется сеть из двух слоев.
Первый слой обучаемый и состоит из 900 нейронов, выходной состоит из 31 нейрона, каждому из которых соответствует буква на картинке.
Первоначальная обучающая выборка подготовлена благодаряотряду русскоязычных индусов antigate и составила 2,000 капч, после недолгого обучения сети, в роли учителя выступал уже сам Яндекс и подготовленный ранее словарь из 387,143 слов от 4 до 7 символов, сформированный на основе данных из Яндекс словарей.
Потенциально верные ответы сети, присутствующие в словаре, отправлялись на проверку Яндексу, по результатам которой и происходило обучение, что значительно сократило расходы на дальнейшее формирование выборки.
В течение суток получена точность распознавания каждого символа в 70%.
После получения результата распознавания проверяется наличие оного в словаре.
Если результат распознавания отсутствует в словаре, скорее всего он не верен.
Часто возникают ошибки между схожими символами, к примеру н — и, с — е, ь — ы, п — л.
В таком случае, исходя из ответов сети, выбираем наиболее вероятные буквы и ищем соответствующие слова в словаре.
Если слов не существует, выбираем варианты с аналогичной длиной и минимальным расстоянием Левенштейна.
Такой вариант дает 18% точность распознавания капчи.
Также можно задействовать частоту распределения букв и их сочетаний в русском языке, не говоря уже о готовых решениях для проверки орфографии, в любом случае вариантов множество.
Даже простое прюнинг результатов, отсутствующих в словаре отбрасывает значительную часть неверных вариантов.
Как я говорил ранее, при желании и должном числе примеров, любая понятная [и не только] человеку капча поддается распознаванию. Упор нужно делать не на усложнении самого изображения, а на технологиях выявления ботов, пока они сами не начали выявлять и отсеивать людей.
Кириллическая Яндекс капча довольно слабая, однако порядком более дружелюбна для русскоязычных пользователей, нежели, к примеру, kcaptcha или recaptcha (особенно первой версии).
Я уверен, что в ближайшее время ребята из Яндекса поработают над своей капчей и смогут достичь компромисса между надежностью и удобством для простых людей.
Если желаете протестировать или разобраться в работе сети — добро пожаловать на GitHub.
P.S. Если у вас есть интересные задачи в этой области — буду рад помочь.
В предыдущей публикации мы затронули готовое решение KCAPTCHA, которое несмотря на неплохую защищенность было распознано без сколько-нибудь серьезной предварительной обработки и сегментации, обычным многослойным персептроном.
Теперь на очереди кириллическая Яндекс капча, с которой, уверен, многие из нас отлично знакомы.
Итак, мы имеем такую капчу:
Особенности
- Переменная длина
- Искажения
- Шумы (кривая)
- Кириллические буквы
- Модный логотип в правом-верхнем углу
Слабые стороны
- Искажения незначительны, не препятствуют сегментации
- Шумы лишь незначительно усложняют распознавание
- Ограниченный словарь позволяет отсеять неверные варианты и скорректировать ответы сети
Решение
Условно разделим распознавание на следующие этапы:
- Предварительная обработка
- Поиск расположения и сегментация текста
- Распознавание
- Финальная обработка результата
Предварительная обработка
Убираем логотип Яндекса и автокадрируем изображение:
Нормализуем входные данные:
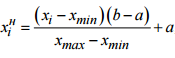
Где x — значения цвета пикселей, [a,b] – интервал допустимых значений входных сигналов. В нашем случае от -1 до 1.
Поиск расположения и сегментация текста
За распознавание длины капчи отвечает сеть с 4-мя нейронами выходного слоя, каждый из которых соответствует значению длины от 4 до 7.
Теперь, зная длину капчи, остается лишь разделить изображение на равные части, для дальнейшего распознавания:
Распознавание
Для распознавания букв используется сеть из двух слоев.
Первый слой обучаемый и состоит из 900 нейронов, выходной состоит из 31 нейрона, каждому из которых соответствует буква на картинке.
Первоначальная обучающая выборка подготовлена благодаря
Потенциально верные ответы сети, присутствующие в словаре, отправлялись на проверку Яндексу, по результатам которой и происходило обучение, что значительно сократило расходы на дальнейшее формирование выборки.
В течение суток получена точность распознавания каждого символа в 70%.
Финальная обработка результата
После получения результата распознавания проверяется наличие оного в словаре.
Если результат распознавания отсутствует в словаре, скорее всего он не верен.
Часто возникают ошибки между схожими символами, к примеру н — и, с — е, ь — ы, п — л.
В таком случае, исходя из ответов сети, выбираем наиболее вероятные буквы и ищем соответствующие слова в словаре.
Если слов не существует, выбираем варианты с аналогичной длиной и минимальным расстоянием Левенштейна.
Такой вариант дает 18% точность распознавания капчи.
Также можно задействовать частоту распределения букв и их сочетаний в русском языке, не говоря уже о готовых решениях для проверки орфографии, в любом случае вариантов множество.
Даже простое прюнинг результатов, отсутствующих в словаре отбрасывает значительную часть неверных вариантов.
Заключение
Как я говорил ранее, при желании и должном числе примеров, любая понятная [и не только] человеку капча поддается распознаванию. Упор нужно делать не на усложнении самого изображения, а на технологиях выявления ботов, пока они сами не начали выявлять и отсеивать людей.
Кириллическая Яндекс капча довольно слабая, однако порядком более дружелюбна для русскоязычных пользователей, нежели, к примеру, kcaptcha или recaptcha (особенно первой версии).
Я уверен, что в ближайшее время ребята из Яндекса поработают над своей капчей и смогут достичь компромисса между надежностью и удобством для простых людей.
Исходники
Если желаете протестировать или разобраться в работе сети — добро пожаловать на GitHub.
P.S. Если у вас есть интересные задачи в этой области — буду рад помочь.