 Началось все с того, что я оптимизировал отдачу ошибки HTTP 408 Request Timeout в сервере приложений Impress, работающем на Node.js. Как известно, у нодовского http.Server есть событие timeout, которое должно вызываться для каждого открытого сокета, если тот не закрылся за указанное время. Хочу уточнить, что не для каждого запроса т.е. не для каждого события request, функция которого имеет два аргумента (req, res), а именно для каждого сокета. Через один сокет может последовательно поступить много запросов в режиме keep-alive. Если мы задаем это событие, через server.setTimeout(2 * 60 * 1000, function(socket) {...}) то должны сами уничтожать сокет socket.destroy(). Но если не установить свой обработчик, то http.Server имеет встроенный, который уничтожит сокет через 2 минуты автоматически. На этом самом таймауте можно отдать ошибку 408 и считать инцидент исчерпанным. Если бы не одно но… С удивлением я обнаружил, что событие timeout вызывается и для тех сокетов, которые подвисли и для уже получивших ответ и для закрытых клиентской стороной, вообще для всех, находящихся в режиме keep-alive. Это странное поведение оказалось достаточно сложным, и я расскажу об этом ниже. Можно было бы вставить одну проверку в событие timeout, но со своим идеализмом я не удержался и полез исправлять баг на уровень глубже. Оказалось, что в http.Server режим keep-alive реализован не то что не по RFC, а откровенно не дописан. Вместо отдельного timeout для соединения и отдельного keep-alive timeout, там все на одном таймауте, который реализован на быстрых псевдо-таймерах (enroll/unenroll), но задан по умолчанию в 2 минуты. Это было бы не так страшно, если бы браузеры хорошо работали с keep-alive и переиспользовали его эффективно или закрывали бы неиспользуемые соединения.
Началось все с того, что я оптимизировал отдачу ошибки HTTP 408 Request Timeout в сервере приложений Impress, работающем на Node.js. Как известно, у нодовского http.Server есть событие timeout, которое должно вызываться для каждого открытого сокета, если тот не закрылся за указанное время. Хочу уточнить, что не для каждого запроса т.е. не для каждого события request, функция которого имеет два аргумента (req, res), а именно для каждого сокета. Через один сокет может последовательно поступить много запросов в режиме keep-alive. Если мы задаем это событие, через server.setTimeout(2 * 60 * 1000, function(socket) {...}) то должны сами уничтожать сокет socket.destroy(). Но если не установить свой обработчик, то http.Server имеет встроенный, который уничтожит сокет через 2 минуты автоматически. На этом самом таймауте можно отдать ошибку 408 и считать инцидент исчерпанным. Если бы не одно но… С удивлением я обнаружил, что событие timeout вызывается и для тех сокетов, которые подвисли и для уже получивших ответ и для закрытых клиентской стороной, вообще для всех, находящихся в режиме keep-alive. Это странное поведение оказалось достаточно сложным, и я расскажу об этом ниже. Можно было бы вставить одну проверку в событие timeout, но со своим идеализмом я не удержался и полез исправлять баг на уровень глубже. Оказалось, что в http.Server режим keep-alive реализован не то что не по RFC, а откровенно не дописан. Вместо отдельного timeout для соединения и отдельного keep-alive timeout, там все на одном таймауте, который реализован на быстрых псевдо-таймерах (enroll/unenroll), но задан по умолчанию в 2 минуты. Это было бы не так страшно, если бы браузеры хорошо работали с keep-alive и переиспользовали его эффективно или закрывали бы неиспользуемые соединения.Сначала результаты
После 12 строк изменений событие timeout начало срабатывать только когда сервер не отдал ответа клиенту и клиент его ждет. Таймаут соединения остался со значением по умолчанию 2 минуты, но появился еще http.Server.keepAliveTimeout со значением по умолчанию 5 секунд (как у Apache). Репозиторий с исправлениями: tshemsedinov/node (для node.js 0.12) и tshemsedinov/io.js (для io.js). Скоро я отправлю пул-реквесты соответственно в joyent/node и nodejs/node (бывший io.js, а сейчас в нем уже склеенные проекты).
Суть исправления в том, что таймаут соединения должен срабатывать если соединение зависло, оставив запрос без ответа, а если сокет открыт, но все запросы отвечены, то нужно ждать гораздо меньше, давая возможность прислать еще запрос в режиме keep-alive.
О побочном эффекте уже можно догадаться, освободилось очень много памяти и дескрипторов сокетов, что сразу вызвало в моих текущих высоконагруженных проектах повышение общей производительности более чем в 2 раза. А тут я покажу маленький тест с кодом, результаты которого видно на графиках ниже и дающий представление о том, что происходит.

Суть теста: создать 15 тыс соединений HTTP/1.1 (которые считаются keep-alive по умолчанию, даже без специальных заголовков) и проверить интенсивность создания и закрытия сокетов и расходы памяти. Тест выполнялся 200 секунд, каждые 10 секунд записывались данные. Графики слева — это Node.js 0.2.7 без исправлений, а справа — пропатченный и пересобранный Node.js. Синяя линяя — количество открытый сокетов, а красная — закрытые сокеты. Для этого, мне конечно же пришлось записать все сокеты в массив, что не позволяло полностью освобождать память. Поэтому есть два варианта клиентской части теста, с массивом сокетов, и без него, чтобы проверить память. Как и ожидалось, что сокеты освобождаются в 2 раза быстрее, а это значит, что они не занимают дескрипторов и не нагружают TCP/IP стек операционной системы, которая кроме ноды держит структуры данных и буферы для каждого дескриптора.
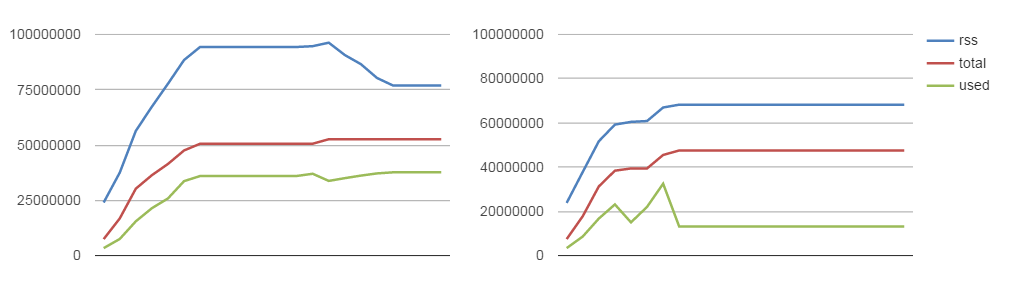
Синяя линяя — RSS (resident set size) — сколько занимает процесс всего, красная — heap total — выделенная для приложения память, зеленая — heap used — используемая память. Естественно, что вся освобожденная память может переиспользоваться для других сокетов, еще быстрее, чем при первом выделении.
Код тестов:
Клиентская часть теста
var net = require('net');
var count = 0;
keepAliveConnect();
function keepAliveConnect() {
var c = net.connect({ port: 80, allowHalfOpen: true }, function() {
c.write('GET / HTTP/1.1\r\nHost: localhost\r\n\r\n');
if (count++ < 15000) keepAliveConnect();
});
}
Серверная часть со счетчиками сокетов
var http = require('http');
var pad = '';
for (var i = 0; i < 10; i++) pad += '- - - - - - - - - - - - - - - - - ';
var sockets = [];
var server = http.createServer(function (req, res) {
var socket = req.socket;
sockets.push(socket);
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(pad + 'Hello World\n');
});
setInterval(function() {
var destroyedSockets = 0;
for (var i = 0; i < sockets.length; i++) {
if (sockets[i].destroyed) destroyedSockets++;
}
var m = process.memoryUsage(),
a = [m.rss, m.heapTotal, m.heapUsed, sockets.length, destroyedSockets];
console.log(a.join(','));
}, 10000);
server.listen(80, '127.0.0.1');
Серверная часть без счетчиков сокетов
var http = require('http');
var pad = '';
for (var i = 0; i < 10; i++) pad += '- - - - - - - - - - - - - - - - - ';
var server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(pad + 'Hello World\n');
});
setInterval(function() {
var m = process.memoryUsage();
console.log([m.rss, m.heapTotal, m.heapUsed].join(','));
}, 10000);
server.listen(80, '127.0.0.1');
Подробности проблемы
Если клиентская сторона не запрашивает keep-alive, то Node.js закрывает сокет сразу по вызову res.end() и ни какой утечки ресурсов не происходит. Поэтому все тесты в которых мы массово делаем http.get('/').on('error', function() {}) или curl http://domain.com/ или через ab (apache benchmark), показывают что все хорошо. А браузеры всегда хотят keep-alive, с которым плохо работают, как и нода. Проблема keep-alive в том, что через него можно отправлять несколько запросов только последовательно, в нем нет пакетного механизма, который бы маркировал, на какой из конкурентных запросов отвечает каждый из ответов. Согласен, это дико неудобно. В SPDY и HTTP/2 такой проблемы нет. Когда браузеры загружают страницу с множеством ресурсов, то они иногда используют keep-alive, но чаще отправляют правильные заголовки, внушая серверу, что нужно держать открытые соединения, а сами используют его совсем мало или вообще игнорируют, руководствуясь непонятной мне логикой. Вот Firebug и DevTools показывают, что запросы завершены, а сокеты висят. Даже если страница уже загрузилась полностью, при этом было создано несколько сокетов, они не закрыты, и нам нужно сделать один несчастный запрос к API, то мои наблюдения показывают, что браузеры всегда создают новое подключение, а сокеты так и держат, пока сервер их не закроет. Такие подвисшие сокеты и не считаются параллельными запросами, поэтому не влияют на ограничения браузеров (я так понимаю, что они маркируются как half-open, не используются и исключаются из счетчика). Это можно проверить, если закрыть браузер, то на сервере ноды сразу закроется целая пачка сокетов, не успевших выждать свои 2 минуты таймаута.
Со стороны ноды же установлен таймаут в 2 минуты, независимо от того, отправлен ли ответ на клиентскую сторону или нет. Понижать этот таймаут, например до 5 секунд — не выход, в результате будут обрываться соединения, которые объективно занимаю больше, чем 5 секунд. Нужен отдельный таймаут для keep-alive, отсчет которого начинается не сразу, а после последней активности в сокете, т.е. это реальное время ожидания очередного запроса от клиента.
Вообще, для полной реализации keep-alive нужно сделать гораздо больше, брать желаемое время таймаута из HTTP заголовков, присылаемых клиентом, отправлять клиенту фактическое установленное время таймаута в заголовках ответа, обрабатывать параметр max и Keep-Alive Extensions. Но современные браузеры не используют все эти вещи, во всяком случае, из проведенных мной экспериментов они игнорировали эти HTTP заголовки. Поэтому я успокоился малыми правками, давшими большие результаты.
Исправления в Node.js
Сначала я решил залатать проблему с лишними таймаутами простым способом, предотвращая emit события: ae9a1a5. Но для этого пришлось ознакомиться с кодом и мне не понравилось, как он написан. Местами есть комментарии, что так писать нельзя, что большие замыкания нужно декомпозировать, избавиться от вложенности функций, но никто не трогает эти библиотеки, потому, что потом тесты не соберешь и можно испортить уйме людей весь зависимый код. Ладно, все править не выйдет, но утечка сокетов не давала мне покоя. И я задумал решить проблему, уничтожая сокет после на ServerResponse.prototype.detachSocket, когда один res.end() уже послан, но это сломало много полезного поведения, связанного с keep-alive: 9d9484b. После экспериментов, чтения RFC и документации по другим серверам, стало очевидно, что нужно реализовывать keep-alive timeout, и что он отличается от просто таймаута соединения.
Исправления:
- Добавлен параметр server.keepAliveTimeout, который можно задавать вручную /lib/_http_server.js#L259
- Переименовал функцию события prefinish, чтобы использовать ее в другом месте /lib/_http_server.js#L455,L456
- Навесил событие finish, чтобы поймать момент, когда уже все отвечено. На нет удаляю из EventEmitter обработчики, повешенные на событие timeout сокета и вещаю событие, разрушающее сокет /lib/_http_server.js#L483,L491
- Для сервера https добавляем параметр keepAliveTimeout, потому, что он наследует все остальное из прототипа /lib/https.js#L51
Для Impress Application Server все эти изменения реализованы внутри, в виде красивой заплатки и эффект доступен даже без патча на Node.js, в его исходниках можно посмотреть, как просто это сделано. Кроме этого, на последних проектах мы добились и других, впечатляющих результатов, например, 10 млн постоянных соединений на 4 серверах, объединенных в кластер (по 2.5 млн на 1 сервер) на базе протокола SSE (Server-Sent Events), а сейчас готовимся сделать то же самое для вебсокетов. Реализовали прикладную балансировку для кластера Impress, связали узлы кластера своим протоколом на базе TCP, вместо используемого ранее ZMQ от чего получили ощутимое ускорение. Результаты этой работы я так же собираюсь частично опубликовать в следующих статьях. Многие говорят мне, что никому не нужна эта оптимизация и производительность, всем безразлично. Но, как минимум, на четырех живых высоконагруженных примерах, для моих заказчиков из КНР и для интерактивного телевизионного формата «Седьмое чувство», я наблюдаю общее повышение производительности от 2-3 раз до 1 порядка, а это уже существенно. Для этого мне пришлось отказаться и от принципа middleware, и переписать межпроцессовое взаимодействие, и реализовать прикладную балансировку (аппаратные балансировщики не справляются) и т.д. Об этом будет отдельная статья, про ужасы производительности при использовании middleware: «Что нода дала, то middleware забрал». Для чего я уже подготовил достаточно фактов, статистики и примеров, и имею что предложить взамен.
А хотите все и сразу, прямо сейчас?
Тогда нужно протестировать вот такую заплатку и не на базе своего билда, а показать ее влияние на официальную версию Node.js 0.12.7. Сейчас проверим, что будет, если добавить на событие request дополнительных 7 строк кода. Сокеты будут закрываться как нужно и даже ошибка с лишним событием timeout тоже исчезает, это понятно. А вот с памятью, ситуация конечно значительно лучше, но не настолько, как это при пересборке Node.js.
http.createServer(function (req, res) {
var socket = req.socket;
res.on('finish', function() {
socket.removeAllListeners('timeout');
socket.setTimeout(5000, function() {
socket.destroy();
});
});
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
});
Сравним результаты на графиках: слева — исходное состояние Node.js 0.12.7, посередине — добавление 7 строк в request и запущено на официальном 0.12.7, справа — пропатченный Node.js из моего репозитория. Причины этого ясны, я склонировал не 0.12.7, а немного более новую версию и от нее отталкивался. Конечно, все тесты кроме последнего проведены на моем репозитории, с патчем и без патча. А последний тест я сравнил с официальной версией 0.12.7, чтобы было понятно, как это повлияет на Ваш код уже сейчас.

Версия V8 в моем репозитории такая же, как и в 0.12.7, но очевидно, что в ноде случились оптимизации. Если подождать совсем немного, то можно будет пользоваться или приведенной выше заплаткой или исправления попадут в ноду. Результаты этих двух вариантов почти совпадают. Вообще, я собираюсь и дальше заниматься экспериментами и оптимизацией в этом направлении, а если у Вас будут идеи, то прошу — не стесняйтесь предлагать и подключаться к приведению кода самых критичных встроенных библиотек ноды в приличный вид. Поверьте, там много работы для специалиста любого уровня. Кроме того, изучение исходников — это самый лучший из известных мне способов освоения платформы.
Update: нашел еще одну проблему там с _last, его ни кто не вычислял. Теперь слил с соседними правками, протестировал и выложил пул-реквест и https://github.com/nodejs/node/pull/2534
