 В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).По долгу работы я примерно 3 года занимаюсь разработкой и поддержкой нескольких проектов, которые используют MongoDB в качестве основной БД, и в этой статье хочу рассказать, почему на мой взгляд с MongoDB далеко не все так просто, как написано в мануалах, и к чему вы должны быть готовы, если вдруг решите взять MongoDB в качестве основной БД в ваш новый модный стартап :-)
Все что описано ниже можно воспроизвести с использованием библиотеки PyMongo для работы с MongoDB из языка программирования Python. Однако скорее всего с аналогичными ситуациями вы можете столкнуться и при использовании других библиотек для других языков программирования.
PyMongo, проблема с Failover и AutoReconnect exception
Практически во всех мануалах равно как и в многочисленных статьях в интернетах говорится, что Mongo поддерживает failover из коробки за счет встроенного механизма репликации. В нескольких статьях, причем даже в официальных курсах от 10gen, приводится очень популярный пример, как если развернуть на одном хосте несколько процессов mongod и настроить между ними репликацию, а потом kill-нуть один из процессов, то репликация не порушится, новый мастер переизберется и все будет ок. И это действительно так и работает… но только на localhost-е! В реальных же условиях все немного иначе.
Вот допустим проэкспериментируем с виртуалками на Amazon-е. Поднимем 5ть small машин — 3 под базы, и 2 под тестовые процессы writer и reader — один непрерывно записывает значения в базу, другой их считывает.
Берем CentOS 6.x, ставим на него mongodb из стандартных реп, ставим supervisor. Конфигурация каждого из процессов mongod в supervisor-е выглядит следующим образом:
# touch /etc/supervisord.d/mongo.conf
[program:mongo]
directory=/mnt/mongo
command=mongod --dbpath /mnt/mongo/ --logappend --logpath /mnt/mongo/log --port 27017 --replSet abc
Настраиваем репликацию:
# mongo --port 27017
> rs.initiate({
_id: 'abc',
members: [
{_id: 0, host:'db1:27017'},
{_id: 1, host:'db2:27017'},
{_id: 2, host:'db3:27017'}
]
})
Процесс writer.py выглядит так:
import datetime, random, time, pymongo
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
cl = con.test.entities
while True:
time.sleep(1)
try:
res = cl.insert({
'time': time.time(),
'value': random.random(),
'title': random.choice(['python', 'php', 'ruby', 'java', 'cpp', 'javascript', 'go', 'erlang']),
'type': random.randint(1, 5)
})
print '[', datetime.datetime.utcnow(), ']', 'wrote:', res
except pymongo.errors.AutoReconnect, e:
print '[', datetime.datetime.utcnow(), ']', 'autoreconnect error:', e
except Exception, e:
print '[', datetime.datetime.utcnow(), ']', 'error:', e
А вот процесс reader.py:
import datetime, time, random, pymongo
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
cl = con.test.entities
while True:
time.sleep(1)
try:
res = cl.find_one({'type': random.randint(1, 5)}, sort=[("time", pymongo.DESCENDING)])
print '[', datetime.datetime.utcnow(), ']', 'read:', res
except Exception, e:
print '[', datetime.datetime.utcnow(), ']', 'error'
print e
Запускаем процессы writer.py и reader.py в параллели, а потом берем и stop-аем машину с Primary-нодой в консоли Amazon-а.
Что должно произойти по логике? Согласно документации MongoDB репликсет 'abc' должен переизбрать нового мастера и это должно произойти прозрачно для скриптов writer.py и reader.py, и если вы тестируете на локали (т.е. разворачиваете все три процесса на одном хосте), то действительно так все и происходит. В нашем же случае скрипты writer.py и reader.py попросту повисают и остаются в таком подвешенном состоянии до тех пор пока вы не пошлете им сигнал прерывания (даже когда новый primary уже выбран и активен).
[ 2015-08-28 21:57:44.694668 ] wrote: 55e0d958671709042a4918b5
[ 2015-08-28 21:57:45.696838 ] wrote: 55e0d959671709042a4918b6
[ 2015-08-28 21:57:46.698918 ] wrote: 55e0d95a671709042a4918b7
[ 2015-08-28 21:57:47.703834 ] wrote: 55e0d95b671709042a4918b8
[ 2015-08-28 21:57:48.712134 ] wrote: 55e0d95c671709042a4918b9
^CTraceback (most recent call last):
File "write.py", line 18, in <module>
'type': random.randint(1, 5)
File "/usr/lib64/python2.6/site-packages/pymongo/collection.py", line 409, in insert
gen(), check_keys, self.uuid_subtype, client)
File "/usr/lib64/python2.6/site-packages/pymongo/message.py", line 393, in _do_batched_write_command
results.append((idx_offset, send_message()))
File "/usr/lib64/python2.6/site-packages/pymongo/message.py", line 345, in send_message
command=True)
File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1511, in _send_message
response = self.__recv_msg(1, rqst_id, sock_info)
File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1444, in __recv_msg
header = self.__recv_data(16, sock)
File "/usr/lib64/python2.6/site-packages/pymongo/mongo_replica_set_client.py", line 1432, in __recv_data
chunk = sock_info.sock.recv(length)
KeyboardInterrupt
Согласитесь, что не самая хорошая ситуация для системы, которая позиционирует себя как отказоустойчивая из коробки? Конечно, пример немного утрирован — например если вы используете PyMongo и MongoDB в своем web-проекте, то велика вероятность, что все python-хозяйство у вас крутится под uwsgi, а в uwsgi настроен какой-нибудь harakiri mode, который прибьет скрипты по timeout-у… Но тем не менее хотелось бы как-то перехватывать подобного рода ситуации в коде. Для этого нужно видоизменить скрипты. В скрипте reader.py нужно заменить:
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000, read_preference=pymongo.ReadPreference.SECONDARY_PREFERRED)
А в скрипте writer.py:
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc')
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000)
Что в итоге мы получим. Повторив эксперимент с вырубанием Primary ноды процесс reader.py продолжит работать как ни в чем не бывало (поскольку обращается к Secondary-ноде, которая в нашем примере остается без изменений), а вот процесс writer.py примерно на минуту уйдет в астрал при этом выкидывая ошибки типа AutoReconnect:
[ 2015-08-28 21:49:06.303250 ] wrote: 55e0d75267170904208d3e01
[ 2015-08-28 21:49:07.306277 ] wrote: 55e0d75367170904208d3e02
[ 2015-08-28 21:49:13.313476 ] autoreconnect error: timed out
[ 2015-08-28 21:49:24.315754 ] autoreconnect error: No primary available
[ 2015-08-28 21:49:33.338286 ] autoreconnect error: No primary available
[ 2015-08-28 21:49:44.340396 ] autoreconnect error: No primary available
[ 2015-08-28 21:49:53.361185 ] autoreconnect error: No primary available
[ 2015-08-28 21:50:04.363322 ] autoreconnect error: No primary available
[ 2015-08-28 21:50:13.456355 ] wrote: 55e0d79267170904208d3e09
[ 2015-08-28 21:50:14.459553 ] wrote: 55e0d79667170904208d3e0a
[ 2015-08-28 21:50:15.462317 ] wrote: 55e0d79767170904208d3e0b
[ 2015-08-28 21:50:16.465371 ] wrote: 55e0d79867170904208d3e0c
Опять-таки не слишком здорово для системы, которая позиционируется как отказоусточивая, уходить в даун на минуту (повторюсь, что если тестировать на локали, то никаких таймаутов нет — все гладко), но это неизбежное зло и об этом даже написано в документации:
It varies, but a replica set will select a new primary within a minute.Но вернемся к нашему примеру и к ошибкам AutoReconnect. Как вы наверное догадались, мы поставили таймаут 5секунд на сокет. Если через 5ть секунд драйвер PyMongo не получает от базы никакого ответа, то он сбрасывает соединение и выплевывает ошибку. Не самое классное решение — вдруг база перенагружена или запрос очень тяжелый и выполняется более 5ти секунд (какая-нибудь агрегирующая функция которая шерстит всю базу). Самый главный вопрос — почему драйвер сам не пытается перезапустить запрос в случае, когда видит, что произошел AutoReconnect Error. Первая причина — драйвер не знает, что на самом деле произошло — вдруг “лег” не один процесс, а весь репликсет. Вторая причина — дубликаты! Оказывается в случае ошибки AutoReconnect драйвер не знает, удалось ли ему записать данные или не удалось. Это немного странно звучит для базы, которая претендует на мировое господство, но это действительно так, и чтобы наш пример работал корректно, скрипт writer.py нужно переписать следующим образом:
It may take 10-30 seconds for the members of a replica set to declare a primary inaccessible. This triggers an election. During the election, the cluster is unavailable for writes.
The election itself may take another 10-30 seconds.
import datetime, time, random, pymongo
from pymongo.objectid import ObjectId
con = pymongo.MongoReplicaSetClient('db1:27017,db2:27017,db3:27017', replicaSet='abc', socketTimeoutMS=5000)
cl = con.test.entities
while True:
time.sleep(1)
data = { '_id': ObjectId(), …. }
# Try for five minutes to recover from a failed primary
for i in range(60):
try:
res = cl.insert(data)
print '[', datetime.datetime.utcnow(), ']', 'wrote:', res
break
except pymongo.errors.AutoReconnect, e:
print '[', datetime.datetime.utcnow(), ']', 'autoreconnect error:', e
time.sleep(5)
except pymongo.errors.DuplicateKeyError:
break
Проблема Global lock
Огромный подводный камень MongoDB. Наверное то, за что монгу критикуют больше всего. Под удар попадают массовые операции, производимые по группе документов. То есть грубо говоря несколько тяжелых операций update-ов по большой группе документов могут создать проблемы с производительностью и заблокировать выполнение других запросов. Конечно, начиная с версии 2.2 ситуация немного улучшилась, когда научились приспускать лок (lock yielding), а так же перевели лок с уровня процесса mongod на уровень выбранной БД. В новой версии 3.0 создатели утверждают, что с переходом на альтернативный движок WiredTiger ситуация должна улучшиться, поскольку он использует блокировки на уровне документа, а не блокирует базу целиком, как было в движке MMAPv1.
Я написал небольшой бенчмарк, для наглядного воспроизведения ситуации с global lock. При желании вы можете сделать git pull и воспроизвести все эти тесты у себя.
- Рассмотрим 1 000 пользователей (значение может быть изменено через конфиг)
- У каждого пользователя 5 000 документов. То есть всего 5 000 000 документов в базе. Каждый документ содержит поле, которое хранит некоторое булевое значение.
- Процесс тестирования представляет собой параллельное выполнение 1 000 задач — по одной на каждого пользователя. Каждая задача — обновление булевого поля всех 5 000 документов пользователя.
- В процессе тестирования по нарастающей от 1го до 30ти (опять-таки значение можно изменить через конфиг) увеличиваем количество конкурентных процессов, которые единовременно расхватывают пул задач.
- Сохраняем время выполнения каждой задачи. Строим графики. Сравниваем результаты тестирования для различных версий MongoDB.
- В качестве альтернативы рассмотрим аналогичную задачу на MySQL 5.5 (InnoDB). И сравним результаты.
В результате тестирования получилось следующее.
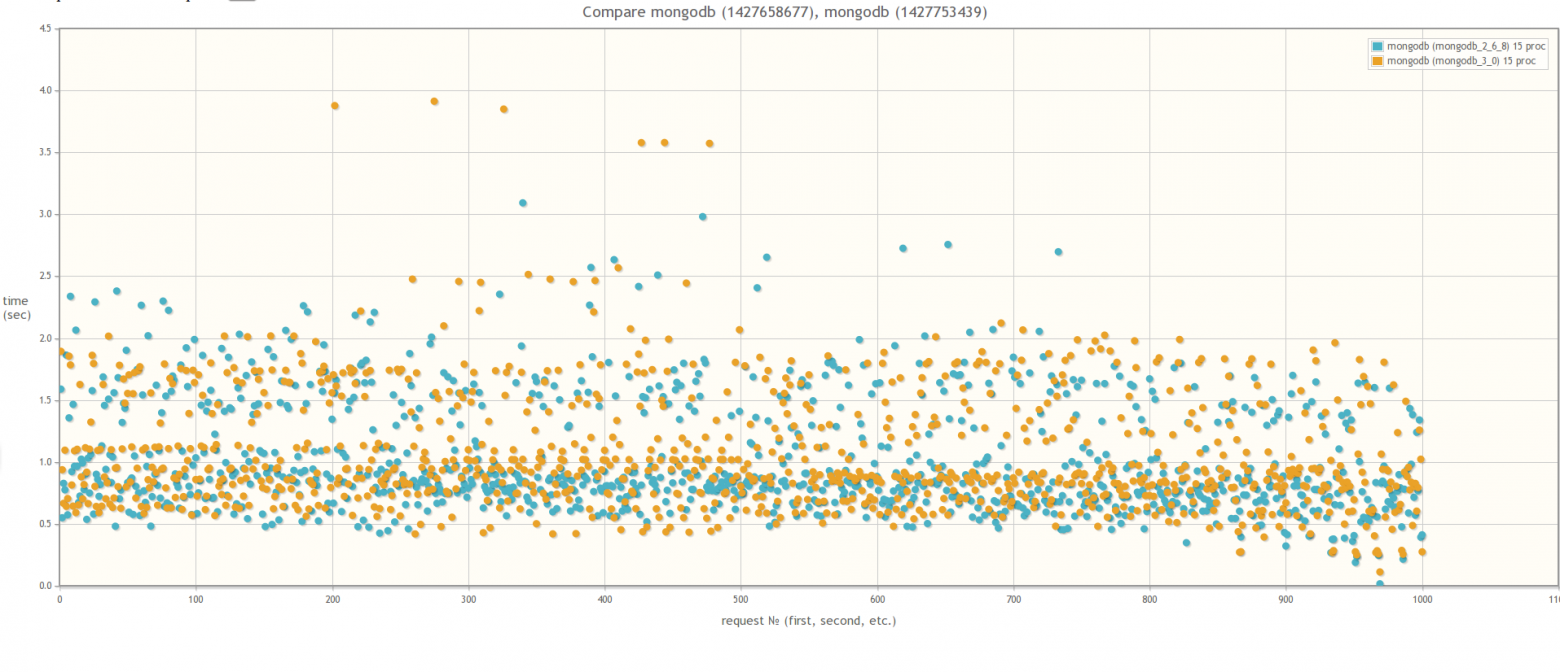
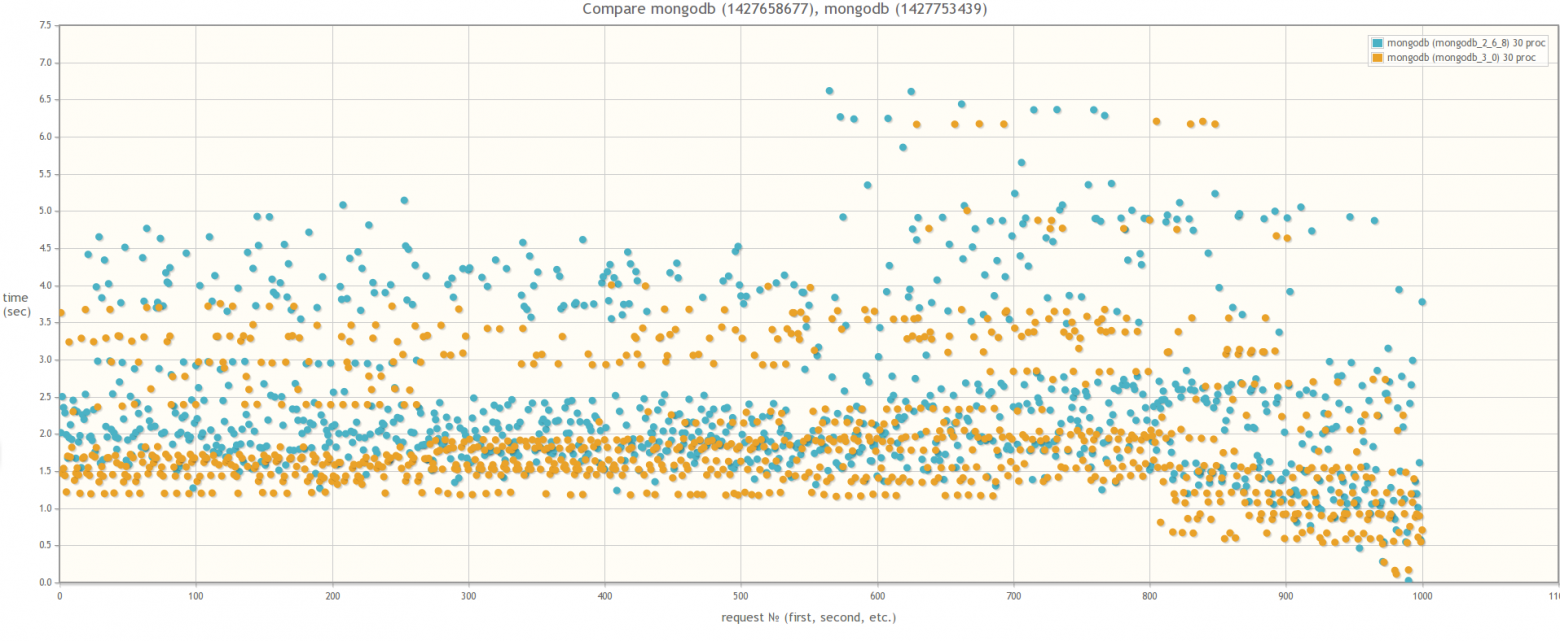
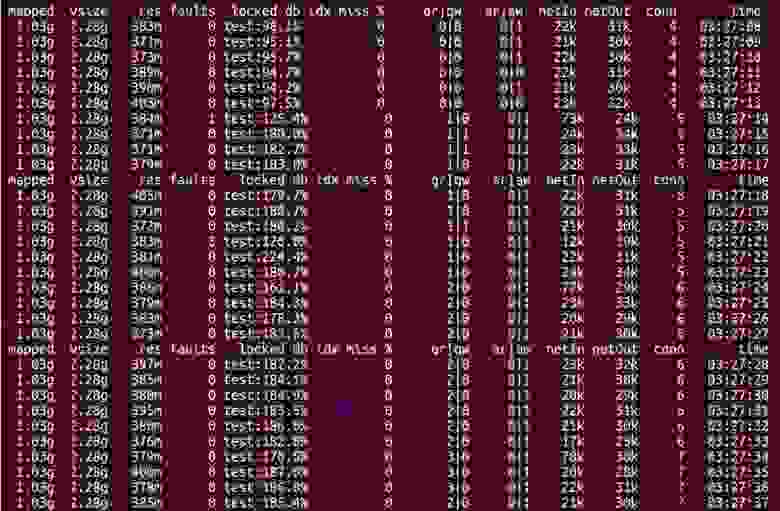
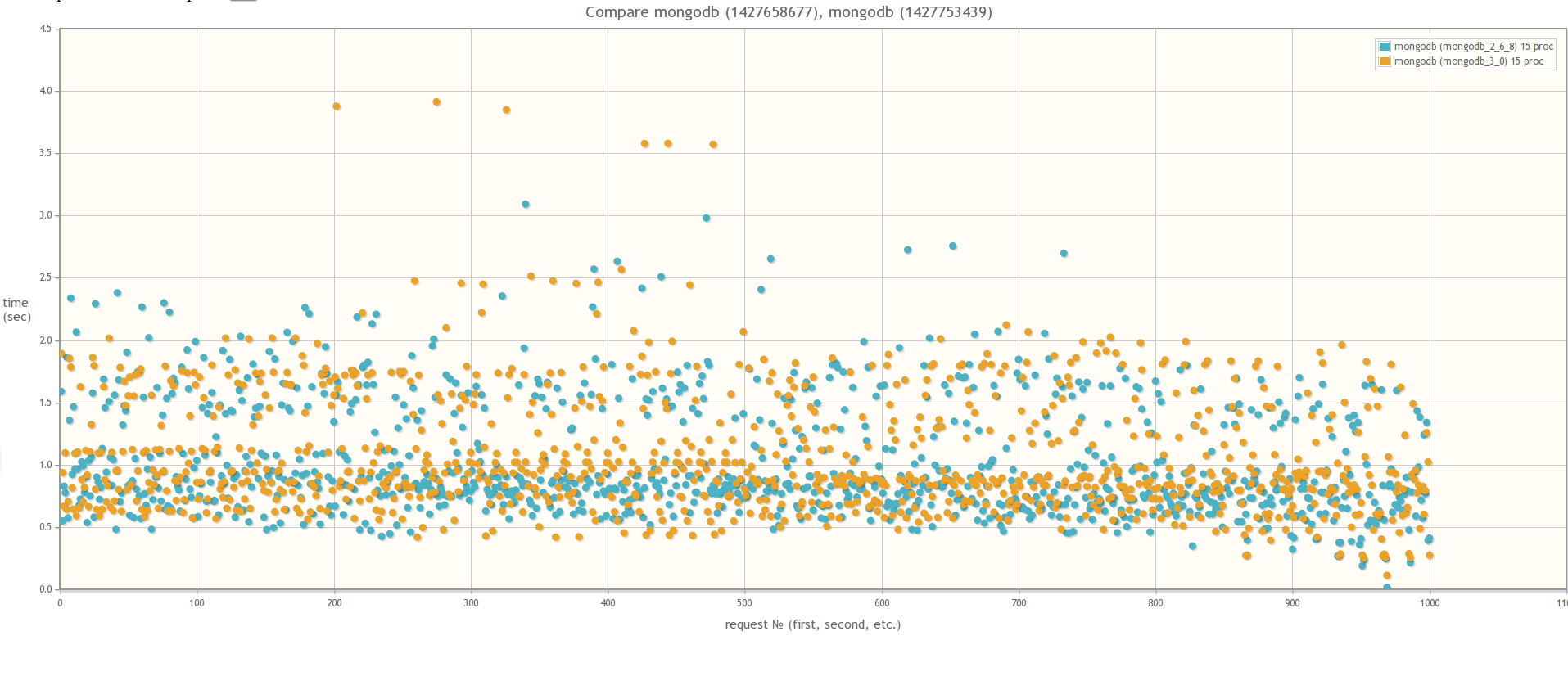
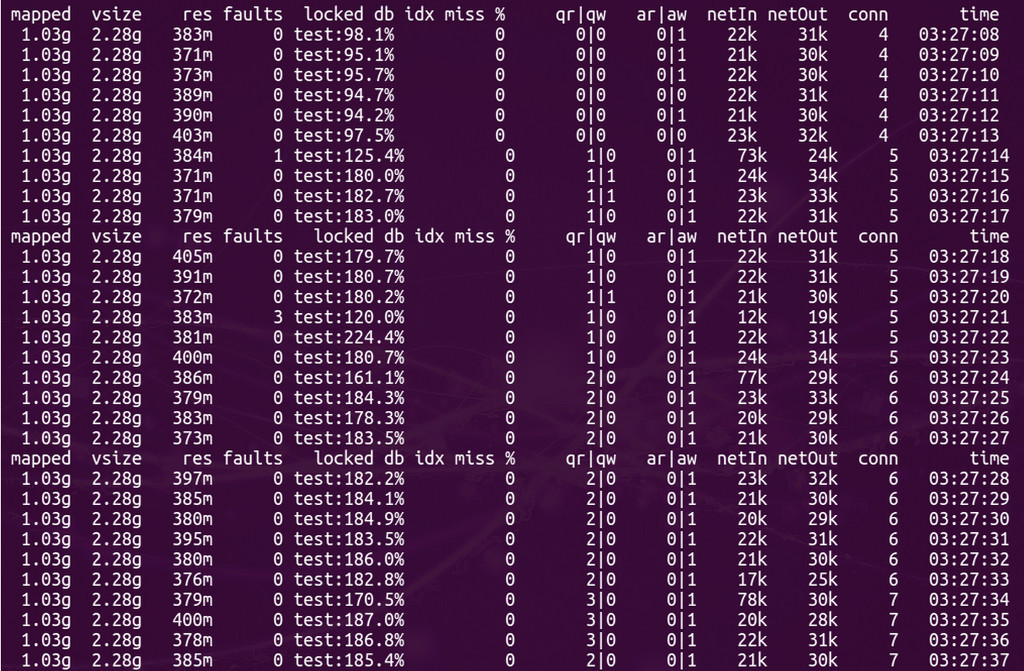
Если сравнивать версию MongoDB 2.6 и версию MongoDB 3.0 (MMAPv1, не WiredTiger), то результаты не сильно различаются, хотя в случае 30ти одновременных процессов worker-ов при использовании MongoDB 3.0 время выполнения запросов все же слегка поменьше. Кстати во время тестирования если посмотреть утилиткой mongostat на процент лока, то он будет зашкаливать:
Результат сравнения MongoDB 2.6 и MongoDB 3.0 MMAPv1
В 15ть параллельных процессов:
В 30ть параллельных процессов:
mongostat:
В 30ть параллельных процессов:
mongostat:
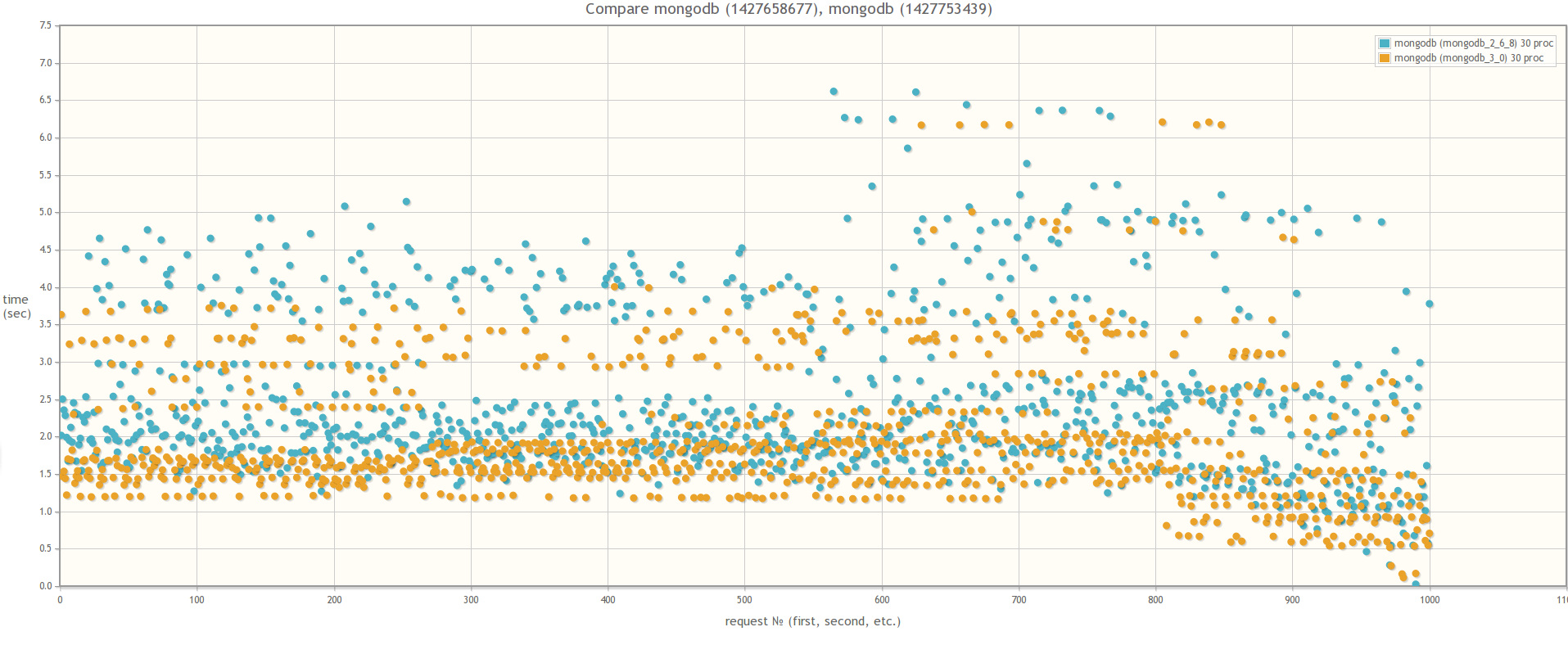
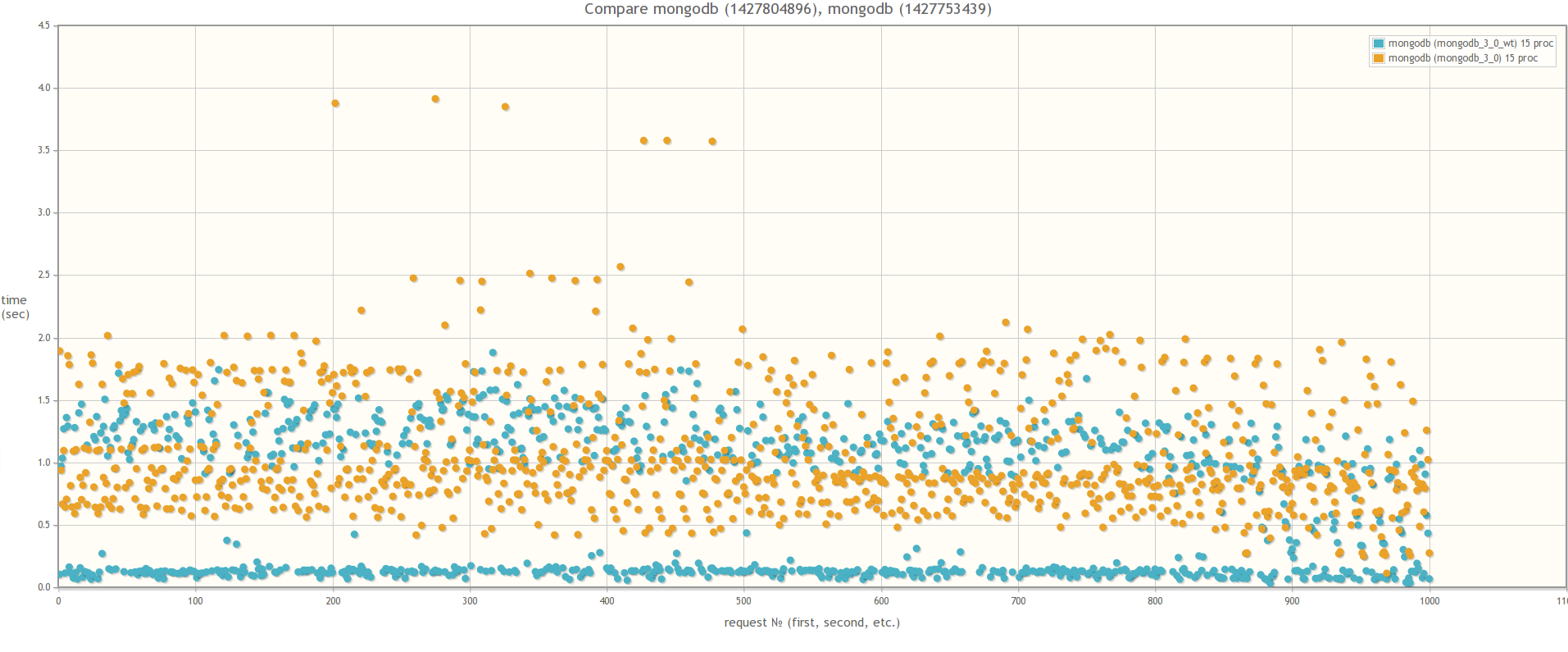
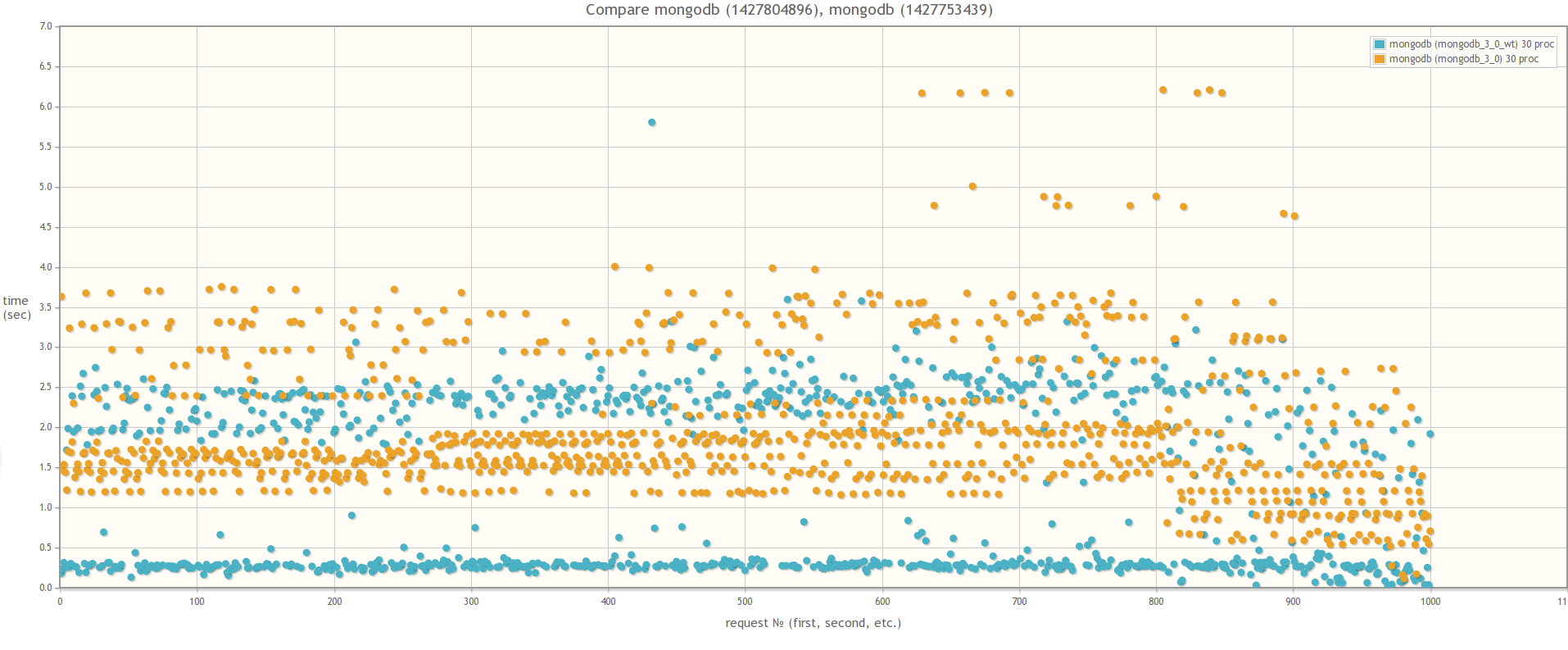
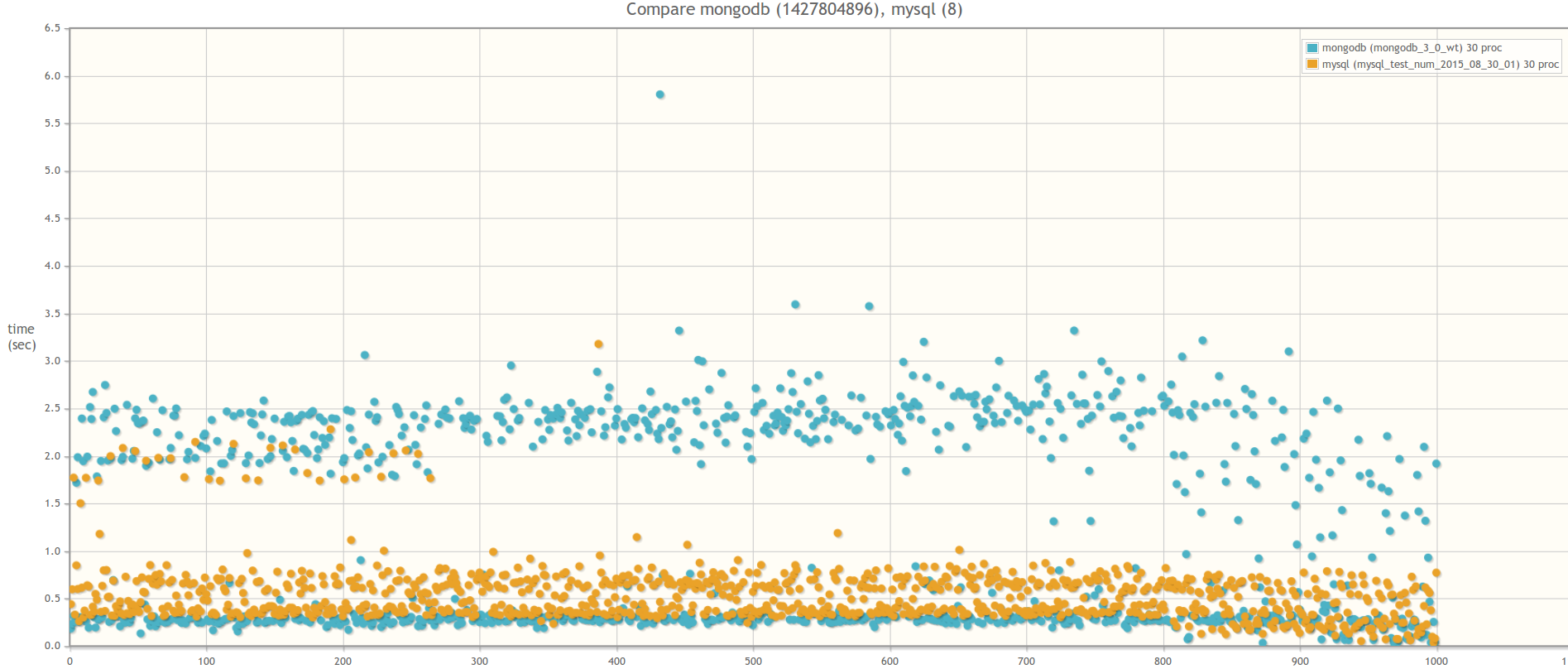
При сравнении MongoDB 3.0 MMAPv1 и MongoDB 3.0 WiredTiger результаты разительно отличаются, что свидетельствует о том, что влияние блокировок на быстродействие массовых операций действительно значительно меньше в случае использования WiredTiger:
Результат сравнения MongoDB 3.0 MMAPv1 и MongoDB 3.0 WiredTiger
В 15ть параллельных процессов:
В 30ть параллельных процессов:
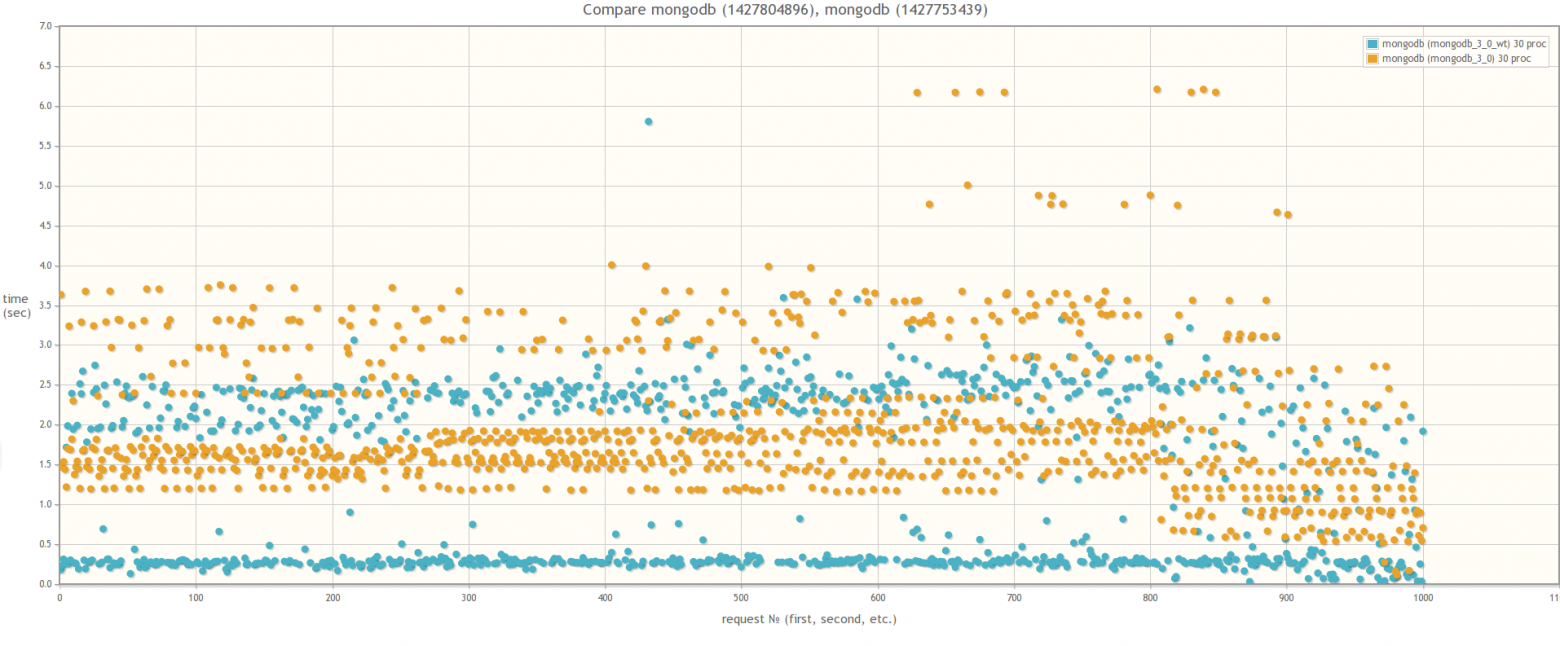
В 30ть параллельных процессов:
А теперь сравним MongoDB 3.0 WiredTiger и MySQL 5.5. База MySQL была выбран исключительно из индивидуальных предпочтений. Если у кого-то будет желание, можете провести аналогичный тест на PostgreSQL. Вся логика работы с базой инкапсулирована с специальных адаптерах. Так что для этого надо лишь написать класс, унаследовав его от абстрактного класса AbstractDBAdapter и переопределив все абстрактные методы для работы с PostgreSQL.
Как известно, тестировать базу из коробки — занятие неблагодарное и бессмысленное. Что касается MongoDB — то тут увы все плохо. База практически не тюнится, настроек по минимуму. Основной принцип MongoDB — выделять под базу отдельный сервер, а дальше база сама решит, какие данные ей сохранять в памяти, а какие сбрасывать на диск. В нескольких источниках я слышал мнение, что свободной памяти на сервере должно быть хотя бы столько, чтобы в неё умещались индексы. В случае же с MySQL настроек масса, и перед запуском бенчмарка была произведена следующая настройка:
max_connections = 10000
query_cache_limit = 32M
query_cache_size = 1024M
innodb_buffer_pool_size = 8192M
innodb_log_file_size = 512M
innodb_thread_concurrency = 16
innodb_flush_log_at_trx_commit = 2
thread_cache = 32
thread_cache_size = 16
Первое, что бросается в глаза при выполнении теста на MySQL — общее время выполнения всех задач при нарастании числа процессов-worker-ов практически не меняется:
...
Run test with 5 proceses
Test is finished! Save results
Full time: 20.7063720226
Run test with 6 proceses
Test is finished! Save results
Full time: 19.1608040333
Run test with 7 proceses
Test is finished! Save results
Full time: 19.0062150955
…
Run test with 15 proceses
Test is finished! Save results
Full time: 18.5613899231
Run test with 16 proceses
Test is finished! Save results
Full time: 18.4244360924
…
Run test with 29 proceses
Test is finished! Save results
Full time: 16.8106219769
Run test with 30 proceses
Test is finished! Save results
Full time: 19.3497707844
Результат сравнения MongoDB 3.0 WiredTiger и MySQL 5.5 InnoDB
В 15ть параллельных процессов:
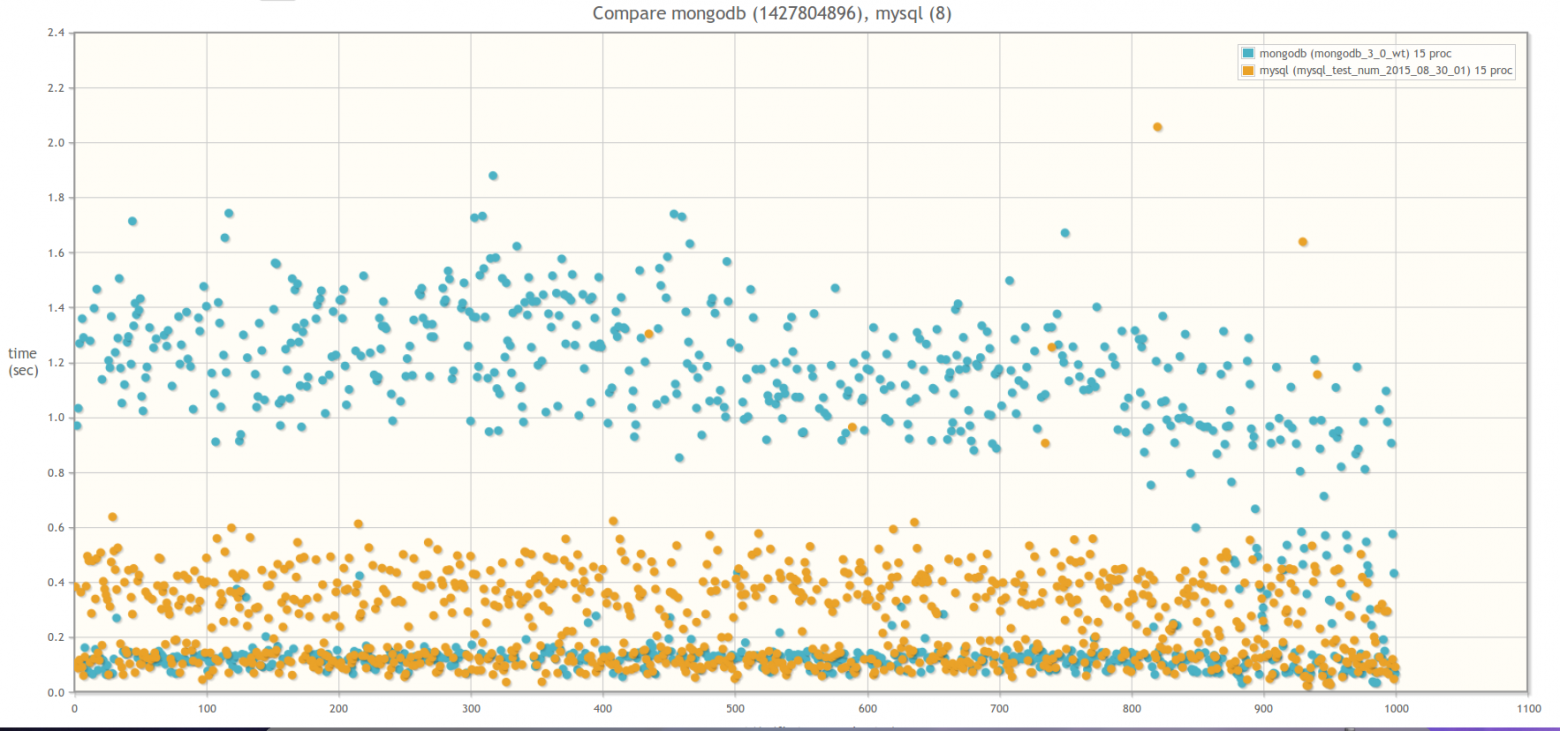
В 30ть параллельных процессов:


В 30ть параллельных процессов:
Какие выводы из этого можно сделать?
Лично я вижу для себя следующий паттерн, когда в проекте можно использовать MongoDB:
- схема данных хорошо укладывается в концепцию “толстых” слабо связных документов
- отсутствие транзакций компенсируется атомарностью операций над документами
- бизнес-логика приложения не подразумевает многочисленные массовые операции над документами.
Так же желательно, чтобы документы не удалялись часто. С этим связана еще одна небольшая проблема (я решил не выносить её в отдельный пункт). При удалении документов свободное место на диске не освобождается. MongoDB помечает блок на диске как свободный и при удобном случае использует этот блок для нового документа. По моим наблюдениям до версии 2.6 эта стратегия работала крайне неэффективно, потому как после выполнения repairDatabase на долгоживущей базе можно было уменьшить размер данных и индексов в 2 с лишним раза (!). Начиная с версии 2.6 для новых коллекций по умолчанию стала использоваться новая стратегия для преаллоцирования диска под новые документы (опция usePowerOf2Sizes) — в результате её использования размер выделяемого места под новые документы стал немного больше чем раньше, но зато свободное место после удаления документов стало использоваться более эффективно. А в версии 3.0 для движка MMAPv1 пошли еще дальше и еще раз изменили стратегию преаллоцирования, однако её эффективность в продакшене мне оценить пока не удалось. Что же происходит с движком WiredTiger в плане преаллоцирования диска, если честно, я тоже не знаю. Если у вас есть какая-либо информация по этому поводу — пишите в комментариях :-)
