1. Вступление
Сталкиваясь с необходимостью контролировать работу других программистов, начинаешь понимать, что, помимо вещей, которым люди учатся достаточно легко и быстро, находятся проблемы, для устранения которых требуется существенное время.
Сравнительно быстро можно обучить человека пользоваться необходимым инструментарием и документацией, правильной коммуникации с заказчиком и внутри команды, правильному целеполаганию и расстановке приоритетов (ну, конечно, в той мере, в которой сам всем этим владеешь).
Но когда дело доходит собственно до кода, все становится гораздо менее однозначно. Да, можно указать на слабые места, можно даже объяснить, что с ними не так. И в следующий раз получить ревью с абсолютно новым набором проблем.
Профессии программиста, как и большинству других профессий, приходится учиться каждый день в течение нескольких лет, а, по большому счету, и всю жизнь. Вначале ты осваиваешь набор базовых знаний в объеме N семестровых курсов, потом долго топчешься по различным граблям, перенимаешь опыт старших товарищей, изучаешь хорошие и плохие примеры (плохие почему-то чаще).
Говоря о базовых знаниях, надо отметить, что умение писать красивый профессиональный код — это то, что по тем или иным причинам, в эти базовые знания категорически не входит. Вместо этого, в соответствующих заведениях, а также в книжках, нам рассказывают про алгоритмы, языки, принципы ООП, паттерны дизайна…
Да, все это необходимо знать. Но при этом, понимание того, как должен выглядеть достойный код, обычно появляется уже при наличии практического (чаще в той или иной степени негативного) опыта за плечами. И при условии, что жизнь “потыкала” тебя не только в сочные образцы плохого кода, но и в примеры всерьез достойные подражания.
В этом-то и заключается вся сложность: твое представление о “достойном” и “красивом” коде полностью основано на личном многолетнем опыте. Попробуй теперь передать это представление в сжатые сроки человеку с совсем другим опытом или даже вовсе без него.
Но если для нас действительно важно качество кода, который пишут люди, работающие вместе с нами, то попробовать все же стоит!
2. Зачем нам нужен красивый код?
Обычно, когда мы работаем над конкретным программным продуктом, эстетические качества кода заботят нас далеко не в первую очередь.
Нам гораздо важнее наша производительность, качество реализации функционала, стабильность его работы, возможность модификации и расширения и т.д.
Но являются ли эстетические качества кода фактором, положительно влияющим на вышеперечисленные показатели?
Мой ответ: да, и при этом, одним из самых важных!
Это так, потому что красивый код, вне зависимости от субъективной трактовки понятия о красоте, обладает следующими (в той или иной степени сводимыми друг к другу) важнейшими качествами:
- Читаемость. Т.е. возможность, глядя на код, быстро понять реализованный алгоритм, и оценить, как будет вести себя программа в том или ином частном случае.
- Управляемость. Т.е. возможность в минимальные сроки внести в код требуемые поправки, избежав при этом различных неприятных предсказуемых и непредсказуемых последствий.
Почему эти качества действительно являются важнейшими, и как они способствуют повышению показателей, указанных в начале параграфа, уверен, очевидно любому, кто занимается программированием.
А теперь, чтобы от общих слов перейти к конкретике, давайте сделаем обратный ход и скажем, что именно читаемый и управляемый код обычно воспринимается нами как красивый и профессионально написанный. Соответственно, на обсуждении того, как добиться этих качеств, мы далее и сосредоточимся.
3. Три базовых принципа.
Переходя к изложению собственного опыта, отмечу, что, работая над читаемостью и управляемостью своего и чужого кода, я постепенно пришел к следующему пониманию.
Вне зависимости от конкретного языка программирования и решаемых задач, для того, чтобы фрагмент кода в достаточной степени обладал этими двумя качествами необходимо, чтобы он был:
- максимально линейным;
- коротким;
- самодокументированным.
Можно бесконечно перечислять различные хинты и техники, с помощью которых можно сделать код красивее. Но я утверждаю, что наилучших, или, во всяком случае, достаточно хороших результатов можно достигнуть, ориентируясь именно на эти три принципа.
Поэтому дальше я постараюсь подробно пояснить их суть, а также описать набор основных техник, с помощью которых можно привести свой код в соответствие с этими принципами.
4. Линеаризация кода.
Мне кажется, что из трех базовых принципов, именно линейность является самым неочевидным, и именно ей чаще всего пренебрегают.
Наверное, потому что за годы учебы (и, возможно, научной деятельности) мы привыкли обсуждать от природы нелинейные алгоритмы с оценками типа O(n3), O(nlogn) и т.д.
Это все, конечно, хорошо и важно, но, говоря о реализации бизнес-логики в реальных проектах, обычно приходится иметь дело с алгоритмами совсем другого свойства, больше напоминающими иллюстрации к детским книжкам по программированию. Что-то типа такого (взято из гугла):
Таким образом, с линейностью я связываю не столько асимптотическую сложность алгоритма, сколько максимальное количество вложенных друг в друга блоков кода, либо же уровень вложенности максимально длинного подучастка кода.
Например, идеально линейный фрагмент:
do_a();
do_b();
do_c();
И совсем не линейный:
do_a();
if (check) {
something();
} else {
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Именно “куски” второго типа мы и будем пытаться переписать при помощи определенных техник.
Примечание: поскольку здесь и далее нам потребуется примеры кода для иллюстрации тех или иных идей, сразу условимся, что они будут написаны на абстрактном обобщенном C-like языке, кроме тех случаев, когда потребуются особенности конкретного существующего языка. Для таких случаев будет явно указано, на каком языке написан пример (конкретно будут встречаться примеры на Java и Javascript).
4.1. Техника 1. Выделяем основную ветку алгоритма.
В подавляющем большинстве случаев в качестве основной ветки имеет смысл взять максимально длинный успешный линейный сценарий алгоритма.
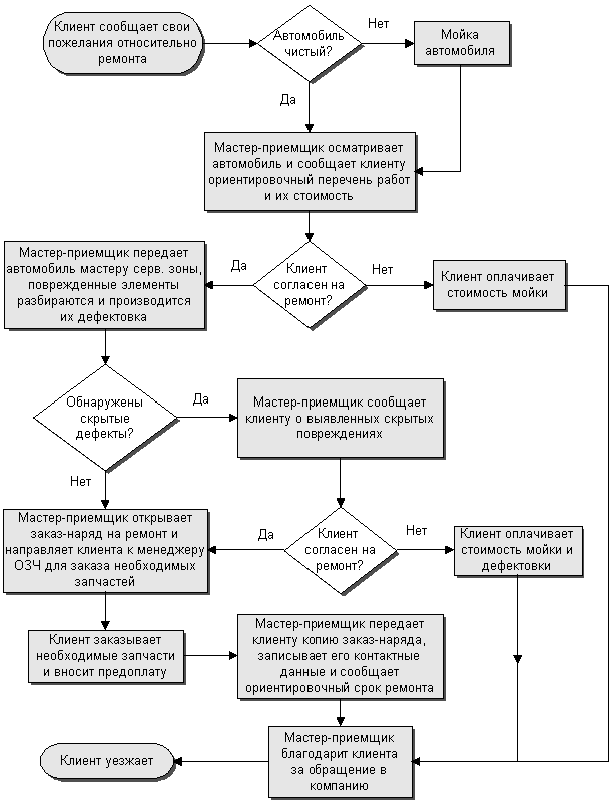
Попробуем сделать это на основе “алгоритма авторемонта” на диаграмме выше:
- Клиент сообщает пожелания.
- Мастер осматривает и говорит стоимость.
- Поиск дефектов.
- Составляем заказ на запчасти.
- Берем предоплату, обозначаем срок.
- Клиент уезжает.
Именно эта основная ветка у нас в идеале должна быть на нулевом уровне вложенности.
listen_client();
if (!is_clean()) {
...
}
check_cost();
if (!client_agree()) {
...
}
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
Давайте для сравнения рассмотрим вариант, где на нулевом уровне находится альтернативная ветка, вместо основной:
listen_client();
if (!is_clean()) {
...
}
check_cost();
if (client_agree()) {
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
} else {
...
}
bye();
Как видно, уровень вложенности значительной части кода вырос, и смотреть на код в целом уже стало менее приятно.
4.2. Техника 2. Используем break, continue, return или throw, чтобы избавиться от блока else.
Плохо:
...
if (!client_agree()) {
...
} else {
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
}
Лучше:
...
if (!client_agree()) {
...
return;
}
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
Разумеется, неверным был бы вывод, что вообще никогда не нужно использовать оператор else. Во-первых, не всегда контекст позволяет поставить break, continue, return или throw (хотя часто как раз таки позволяет). Во-вторых, выигрыш от этого может быть не столь очевиден, как в примере выше, и простой else будет выглядеть гораздо проще и понятней, чем что-либо еще.
Ну и в-третьих, существуют определенные издержки при использовании множественных return в процедурах и функциях, из-за которых многие вообще расценивают данный подход как антипаттерн (мое личное мнение: обычно преимущества все-таки покрывают эти издержки).
Поэтому эта (и любая другая) техника должна восприниматься как подсказка, а не как безусловная инструкция к действию.
4.3. Техника 3. Выносим сложные подсценарии в отдельные процедуры.
Т.к. в случае “алгоритма ремонта” мы довольно удачно выбрали основную ветку, то альтернативные ветки у нас все остались весьма короткими.
Поэтому продемонстрируем технику на основе “плохого” примера из начала главы:
Плохо:
do_a()
if (check) {
something();
} else {
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Лучше:
procedure do_on_whatever() {
for (a in b) {
if (good(a)) {
something();
}
}
}
do_a();
if (check) {
something();
} else {
anything();
if (whatever()) {
do_on_whatever();
}
}
Обратите внимание, что правильно выбрав имя выделенной процедуре, мы, кроме того, сразу же повышаем самодокументированность кода. Теперь для данного фрагмента в общих чертах должно быть понятно, что он делает и зачем нужен.
Однако следует иметь в виду, что та же самодокументированность сильно пострадает, если у вынесенной части кода нет общей законченной задачи, которую этот код выполняет. Затруднения в выборе правильного имени для процедуры могут быть индикатором именно такого случая (см. п. 6.1).
4.4. Техника 4. Выносим все, что возможно, во внешний блок, оставляем во внутреннем только то, что необходимо.
Плохо:
if (check) {
do_a();
something();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
} else {
do_a();
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Лучше:
do_a();
if (check) {
something();
} else {
anything();
}
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
4.5. Техника 5 (частный случай предыдущей). Помещаем в try...catch только то, что необходимо.
Надо отметить, что блоки try...catch вообще являются болью, когда речь идет о читаемости кода, т.к. часто, накладываясь друг на друга, они сильно повышают общий уровень вложенности даже для простых алгоритмов.
Бороться с этим лучше всего, минимизируя размер участка внутри блока. Т.е. все строки, не предполагающие появление исключения, должны быть вынесены за пределы блока. Хотя в некоторых случаях с точки зрения читаемости более выигрышным может оказаться и строго противоположный подход: вместо того, чтобы писать множество мелких блоков try..catch, лучше объединить их в один большой.
Кроме того, если ситуация позволяет не обрабатывать исключение здесь и сейчас, а выкинуть вниз по стеку, обычно лучше именно так и поступить. Но надо иметь в виду, что вариативность тут возможна только в том случае, если вы сами можете задавать или менять контракт редактируемой вами процедуры.
4.6. Техника 6. Объединяем вложенные if-ы.
Тут все очевидно. Вместо:
if (a) {
if (b) {
do_something();
}
}
пишем:
if (a && b) {
do_something();
}
4.7. Техника 7. Используем тернарный оператор (a? b: c) вместо if.
Вместо:
if (a) {
var1 = b;
} else {
var1 = c;
}
пишем:
var1 = a ? b : c;
Иногда имеет смысл даже написать вложенные тернарные операторы, хотя это предполагает от читателя знания приоритета, с которым вычисляются подвыражения тернарного оператора.
Вместо:
if (a) {
var1 = b;
} else if (aa) {
var1 = c;
} else {
var1 = d;
}
пишем:
var1 = a ? b :
aa ? c : d;
Но злоупотреблять этим, пожалуй, не стоит.
Заметим, что инициализация переменной var1 теперь осуществляется одной единственной операцией, что опять же сильно способствует самодокументированности (см п. 6.8).
4.8. Суммируя вышесказанное, попробуем написать полную реализацию алгоритма ремонта максимально линейно.
listen_client();
if (!is_clean()) {
wash();
}
check_cost();
if (!client_agree()) {
pay_for_wash();
bye();
return;
}
find_defects();
if (defects_found()) {
say_about_defects();
if (!client_agree()) {
pay_for_wash_and_dyagnosis();
bye();
return;
}
}
create_request();
take_money();
bye();
На этом можно было бы и остановиться, но не совсем здорово выглядит то, что нам приходится 3 раза вызывать bye() и, соответственно, помнить, что при добавлении новой ветки, его придется каждый раз писать перед return (собственно, издержки множественных return).
Можно было бы решить проблему через try...finally, но это не совсем правильно, т.к. в данном случае не идет речи об обработке исключений. Да и делу линеаризации такой подход бы сильно помешал.
Давайте сделаем так (на самом деле, я тут применил п. 5.1 еще до того, как его написал):
procedure negotiate_with_client() {
check_cost();
if (!client_agree()) {
pay_for_wash();
return;
}
find_defects();
if (defects_found()) {
say_about_defects();
if (!client_agree()) {
pay_for_wash_and_dyagnosis();
return;
}
}
create_request();
take_money();
}
listen_client();
if (!is_clean()) {
wash();
}
negotiate_with_client();
bye();
Если вы думаете, что мы сейчас записали что-то тривиальное, то, в принципе, так и есть. Однако уверяю, что во многих живых проектах вы увидели бы совсем другую реализацию этого алгоритма…
5. Минимизация кода.
Думаю, было бы лишним пояснять, что уменьшая количество кода, используемого для реализации заданного функционала, мы делаем код гораздо более читаемым и надежным.
В этом смысле, идеальное инженерное решение — это, когда ничего не сделано, но все работает, как требуется. Разумеется, в реальном мире крайне редко доступны идеальные решения, и поэтому у нас, программистов, пока еще есть работа. Но стремиться стоит именно к такому идеалу.
5.1. Техника 1. Устраняем дублирование кода.
О копипасте и вреде, от него исходящем, сказано уже так много, что добавить что-то новое было бы сложно. Тем не менее, программисты, поколение за поколением, интенсивно используют этот метод для реализации программного функционала.
Разумеется, самым очевидным методом борьбы с проблемой является вынесение переиспользуемого кода в отдельные процедуры и классы.
При этом всегда возникает проблема выделения общего из частного. Зачастую даже не всегда понятно, чего больше у похожих кусков кода: сходства или различий. Выбор тут делается исключительно по ситуации. Тем не менее, наличие одинаковых участков размером в пол-экрана сразу говорит о том, что данный код можно и нужно записать существенно короче.
Стоит также упомянуть весьма полезную технику устранения дублирования, описанную в п. 4.3.
Распространить ее можно дальше одних лишь операторов if. Например, вместо:
procedure proc1() {
init();
do1();
}
procedure proc2() {
init();
do2();
}
proc1();
proc2();
запишем:
init();
do1();
do2();
Или обратный вариант. Вместо:
a = new Object();
init(a);
do(a);
b = new Object();
init(b);
do(b);
запишем:
procedure proc(a) {
init(a);
do(a);
}
proc(new Object());
proc(new Object());
5.2. Техника 2. Избегаем лишних условий и проверок.
Лишние проверки — зло, которое можно встретить практически в любой программе. Сложно описать, насколько самые тривиальные процедуры и алгоритмы могут быть засорены откровенно ненужными, дублирующимися и бессмысленными проверками.
Особенно это касается, конечно же, проверок на null. Как правило, вызвано подобное извечным страхом программистов перед вездесущими NPE и желанием лишний раз от них перестраховаться.
Далеко не редким видом ненужной проверки является следующий пример:
obj = new Object();
...
if (obj != null) {
obj.call();
}
Не смотря на свою очевидную абсурдность, встречаются такие проверки с впечатляющей регулярностью. (Cразу же оговорюсь, что пример не касается тех редких языков и сред, где оператор new() может вернуть null. В большинстве случаев (в т.ч. в Java) подобное в принципе невозможно).
Сюда же можно включить десятки других видов проверок на заведомо выполненное (или заведомо не выполненное) условие.
Вот, например, такой случай:
obj = factory.getObject();
obj.call1();
// если бы obj был null, мы бы уже умерли )
if (obj != null) {
obj.call2();
}
Встречается в разы чаще, чем предыдущий тип проверок.
Третий пример чуть менее очевиден, чем первые два, но распространен просто повсеместно:
procedure proc1(obj) {
if (!is_valid(obj)) return;
obj.call1();
}
procedure proc2(obj) {
if (!is_valid(obj)) return;
obj.call2();
}
obj = factory.getObject();
if (is_valid(obj) {
proc1(obj);
proc2(obj);
}
Как видно, автор данного отрезка панически боится нарваться на невалидный объект, поэтому проверяет его перед каждым чихом. Не смотря на то, что иногда такая стратегия может быть оправдана (особенно, если proc1() и proc2() экспортируются в качестве API), во многих случаях это просто засорение кода.
Варианты тут могут быть разными:
- Для каждой процедуры обозначить входной контракт, требующий от вызывающего соблюдения определенных условий валидности. После этого удалить страхующие проверки и целиком перенести ответственность за валидность входных данных на вызывающий код. Для Java, например, хорошей практикой может быть пометка “опасных” методов и полей аннотацией @Nullable. Таким образом, мы неявно обозначим, что остальные поля и методы могут принимать/возвращать значение null.
- Вообще не создавать невалидных объектов! Этот подход предполагает выполнение всех процедур валидации на этапе создания объекта, чтобы сам факт успешного создания уже гарантировал валидность. Разумеется, для этого как минимум требуется, чтобы мы контролировали класс фабрики или иные механизмы создания объектов. Либо, чтобы имеющаяся реализация давала нам такую гарантию.
Может быть, на первый взгляд, эти варианты кажутся чем-то невозможным или даже страшным, тем не менее, в реальности с их помощью можно существенно повысить читаемость и надежность кода.
Еще одним полезным подходом является применение паттерна NullObject, предполагающего использование объекта с ничего не делающими, но и не вызывающими ошибок, методами вместо “опасного” null. Частным случаем такого подхода можно считать отказ от использования null для переменных-коллекций в пользу пустых коллекций.
Сюда же относятся специальные null-safe библиотеки, среди которых хотелось бы выделить набор библиотек apache-commons для Java. Он позволяет сэкономить огромное количество места и времени, избавив от необходимости писать бесконечные рутинные проверки на null.
5.3. Техника 3. Избегаем написания “велосипедов”. Используем по максимуму готовые решения.
Велосипеды — это почти как копипаст: все знают, что это плохо, и все регулярно их пишут. Можно лишь посоветовать хотя бы пытаться бороться с этим злом.
Большую часть времени перед нами встают задачи или подзадачи, которые уже множество раз были решены, будь то сортировка или поиск по массиву, работа с форматами 2D графики или long-polling сервера на Javascript. Общее правило заключается в том, что стандартные задачи имеют стандартное решение, и это решение дает нам возможность получить нужный результат, написав минимум своего кода.
Порой есть соблазн, вместо того, чтобы что-то искать, пробовать и подгонять, быстренько набросать на коленке свой велосипед. Иногда это может быть оправдано, но если речь идет о поддерживаемом в долгосрочной перспективе коде, минутная “экономия” может обернуться часами отладки и исправления ошибок на пропущенных корнер-кейсах.
С другой стороны, лишь слегка затрагивая достаточно обширную тему, хотелось бы сказать, что иногда “велосипедная” реализация может или даже должна быть предпочтена использованию готового решения. Обычно это верно в случае, когда доверие к качеству готового решения не выше, чем к собственному коду, либо в случае, когда издержки от внедрения новой внешней зависимости оказываются технически неприемлемы.
Тем не менее, возвращаясь к вопросу о краткости кода, безусловно, использование стандартных (например, apache-commons и guava для Java) и нестандартных библиотек является одним из наиболее действенных способов уменьшить размеры собственного кода.
5.4. Техника 4. Оставляем в коде только то, что действительно используется.
“Висящие” функции, которые никем нигде не вызываются; участки кода, которые никогда не выполняются; целые классы, которые нигде не используются, но их забыли удалить — уверен, каждый мог наблюдать такие вещи в своем проекте, и может быть, даже воспринимал их, как должное.
На деле же, любой код, в том числе неиспользуемый, требует плату за свое содержание в виде потраченного внимания и времени.
Поскольку неиспользуемый код реально не выполняется и не тестируется, в нем могут содержатся некорректные вызовы тех или иных процедур, ненужные или неправильные проверки, обращения к процедурам и внешним библиотекам, которые больше ни для чего не нужны, и множество других сбивающих с толку или просто вредных вещей.
Таким образом, удаляя ненужные и неиспользуемые участки, мы не только уменьшаем размеры кода, но и, что не менее важно, способствуем его самодокументированности.
5.5. Техника 5. Используем свои знания о языке и полагаемся на наличие этих знаний у читателя.
Одним из эффективных способов сделать свой код проще, короче и понятней является умелое использование особенностей конкретного языка: различных умолчаний, приоритетов операций, кратких форм записи и т.д.
В качестве иллюстрации приведу наиболее, с моей точки зрения, яркий пример для языка Javascript.
Очень часто при разборе строковых выражений можно увидеть такие нагромождения:
if (obj != null && obj != undefined && obj.s != null && obj.s != undefined && obj.s != '') {
// do something
}
Выглядит пугающе, в том числе и с точки зрения “а не забыл ли автор еще какую-нибудь проверку”. На самом деле, зная особенность языка Javascript, в большинстве подобных случаев всю проверку можно свести до тривиальной:
if (obj && obj.s) {
// do something
}
Дело в том, что благодаря неявному приведению к boolean, проверка if (obj) {} отсеет:
- false
- null
- undefined
- 0
- пустую строку
В общем, она отсеет большинство тривиальных значений, которые мы можем себе представить. К сожалению, повторюсь, программисты используют эту особенность достаточно редко, из-за чего их “перестраховочные” проверки выглядят весьма громоздко.
Аналогично, сравните следующие формы записи:
if (!a) {
a = defaultValue;
}
и
a = a || defaultValue;
Второй вариант выглядит проще, благодаря использованию специфичной семантики логических операций в скриптовых языках.
6. Самодокументированный код.
Термин “самодокументированность” наиболее часто употребляется при описании свойств таких форматов, как XML или JSON. В этом контексте подразумевается наличие в файле не только набора данных, но и сведений об их структуре, о названиях сущностей и полей, задаваемых этими данными.
Читая XML файл мы, даже ничего не зная о контексте, почти всегда можем составить представление о том, что описывает данный файл, что за данные в нем представлены и даже, возможно, как они будут использованы.
Распространяя эту идею на программный код, под термином “самодокументированность” хотелось бы объединить множество свойств кода, позволяющих быстро, без детального разбора и глубокого вникания в контекст понять, что делает данный код.
Хотелось бы противопоставить такой подход “внешней” документированности, которая может выражаться в наличии комментариев или отдельной документации. Не отрицая необходимости в определенных случаях того и другого, отмечу, что, когда речь идет о читаемости кода, методы самодокументирования оказываются значительно более эффективными.
6.1. Техника 1. Тщательно выбираем названия функций, переменных и классов. Не стоит обманывать людей, которые будут читать наш код.
Самое главное правило, которое следует взять за основу при написании самодокументированного кода — никогда не обманывайте своего читателя.
Если поле называется name, там должно храниться именно название объекта, а не дата его создания, порядковый номер в массиве или имя файла, в который он сериализуется. Если метод называется compare(), он должен именно сравнивать объекты, а не складывать их в хэш таблицу, обращение к которой можно будет найти где-нибудь на 1000 строк ниже по коду. Если класс называется NetworkDevice, то в его публичных методах должны быть операции, применимые к устройству, а не реализация быстрой сортировки в общем виде.
Сложно выразить словами, насколько часто, несмотря на очевидность этого правила, программисты его нарушают. Думаю, не стоит пояснять, каким образом это сказывается на читаемости их кода.
Чтобы избежать таких проблем, необходимо максимально тщательно продумывать название каждой переменной, каждого метода и класса. При этом надо стараться не только корректно, но и, по возможности, максимально полно охарактеризовать назначение каждой конструкции.
Если этого сделать не получается, причиной обычно являются мелкие или грубые ошибки дизайна, поэтому воспринять такое надо минимум как тревожный “звоночек”.
Очевидно, так же стоит минимизировать использование переменных с названиями i, j, k, s. Переменные с такими названиями могут быть только локальными и иметь только самую общепринятую семантику. В случае i, j, это могут счетчики циклов или индексы в массиве. Хотя, по возможности, и от таких счетчиков стоит избавляться в пользу циклов foreach и функциональных выражений.
Переменные же с названиями ii, i1, ijk42, asdsa и т.д, не стоит использовать никогда. Ну разве что, если вы работаете с математическими алгоритмами… Нет, лучше все-таки никогда.
6.2. Техника 2. Стараемся называть одинаковые вещи одинаково, а разные — по-разному.
Одна из самых обескураживающих трудностей, возникающих при чтении кода — это употребляемые в нем синонимы и омонимы. Иногда в ситуации, когда две разных сущности названы одинаково, приходится тратить по несколько часов, чтобы разделить все случаи их использования и понять, какая именно из сущностей подразумевается в каждом конкретном случае. Без такого разделения нормальный анализ, а следовательно и осмысленная модификация кода, невозможны в принципе. А встречаются подобные ситуации намного чаще, чем можно было бы предположить.
Примерно то же самое можно сказать и об “обратной” проблеме — когда для одной и той же сущности/операции/алгоритма используется несколько разных имен. Время на анализ такого кода может возрасти по сравнению с ожидаемым в разы.
Вывод простой: в своих программах к возникновению синонимов и омонимов надо относиться крайне внимательно и всеми силами стараться подобного избегать.
6.3. Техника 3. “Бритва Оккама”. Не создаем сущностей, без которых можно обойтись.
Как уже говорилось в п. 5.4., любой участок кода, любой объект, функция или переменная, которые вы создаете, в дальнейшем, в процессе поддержки, потребует себе платы в виде вашего (или чужого) времени и внимания.
Из этого следует самый прямой вывод: чем меньше сущностей вы введете, тем проще и лучше в итоге окажется ваш код.
Типичный пример “лишней” переменной:
...
int sum = counSum();
int increasedSum = sum + 1;
operate(increasedSum);
...
Очевидно, переменная increasedSum является лишней сущностью, т.к. описание объекта, который она хранит (sum + 1) характеризует данный объект гораздо лучше и точнее, чем название переменной. Таким образом код стоит переписать следующим образом (“заинлайнить” переменную):
...
int sum = counSum();
operate(sum + 1);
...
Если далее по коду сумма нигде не используется, можно пойти и дальше:
...
operate(countSum() + 1);
...
Инлайн ненужных переменных — это один из способов сделать ваш код короче, проще и понятней.
Однако применять его стоит лишь в случае, если этот прием способствует самодокументированности, а не противоречит ей. Например:
double descr = b * b - 4 * a *c;
double x1 = -b + sqrt(descr) / (2 * a);
В этом случае инлайн переменной descr вряд ли пойдет на пользу читаемости, т.к. данная переменная используется для представления определенной сущности из предметной области, а, следовательно, наличие переменной способствует самодокументированности кода, и сама переменная под “бритву Оккама” не попадает.
Обобщая принцип, продемонстрированный на данном примере, можно заключить следующее: желательно в своей программе создавать переменные/функции/объекты, только если они имеют прототипы в предметной области. При этом, в соответствии с п. 6.1, надо стараться, чтобы название этих объектов максимально ясно выражало это соответствие. Если же такого соответствия нет, вполне возможно, что использование переменной/функции/объекта лишь перегружает ваш код, и их удаление пойдет программе только на пользу.
6.4. Техника 4. Всегда стараемся предпочитать явное неявному, а прямое — косвенному.
Общий принцип прост: любые явно выписанные алгоритмы или условия уже являются самодокументированными, т. к. их назначение и принцип действия уже описаны ими же самими. Наоборот, любые косвенные условия и операции с сайд-эффектами сильно затрудняют понимание сути происходящего.
Можно привести грубый пример, подразумевая, что жизнь подкидывает подобные примеры совсем не редко.
Косвенное условие:
if (i == abs(i)) {
}
Прямое условие:
if (i >= 0) {
}
Оценить разницу в читаемости, думаю, несложно.
6.5. Техника 5. Все, что можно спрятать в private (protected), должно быть туда спрятано. Инкапсуляция — наше все.
Говорить о пользе и необходимости следования принципу инкапсуляции при написании программ в данной статье я считаю излишним.
Хотелось бы только подчеркнуть роль инкапсуляции, как механизма самодокументирования кода. В первую очередь, инкапсуляция позволяет четко выделить внешний интерфейс класса и обозначить его “точки входа”, т. е. методы, в которых может быть начато выполнение кода, содержащегося в классе. Это позволяет человеку, изучающему ваш код, сохранить огромное количество времени, сфокусировавшись на функциональном назначении класса и абстрагировавшись от деталей реализации.
6.6. Техника 6. (Обобщение предыдущего) Все объекты объявляем в максимально узкой области видимости.
Принцип максимального ограничения области видимости каждого объекта можно распространить шире, чем привычная нам инкапсуляция из ООП.
Простой пример:
Object someobj = createSomeObj();
if (some_check()) {
// Don't need someobj here
} else {
someobj.call();
}
Очевидно, такое объявление переменной someobj затрудняет понимание ее назначения, т. к. читающий ваш код будет искать обращения к ней в значительно более широкой области, чем она используется и реально нужна.
Нетрудно понять, как сделать этот код чуть-чуть лучше:
if (some_check()) {
// Don't need someobj here
} else {
Object someobj = createSomeObj();
someobj.call();
}
Ну или, если переменная нужна для единственного вызова, можно воспользоваться еще и п. 6.3:
if (some_check()) {
// Don't need someobj here
} else {
createSomeObj().call();
}
Отдельно хотелось бы оговорить случай, когда данная техника может не работать или работать во вред. Это переменные, инициализируемые вне циклов. Например:
Object someobj = createSomeObj();
for (int i = 0; i < 10; i++) {
someobj.call();
}
Если создание объекта через createSomeObj() — дорогая операция, внесение ее в цикл может неприятно сказаться на производительности программы, даже если читаемость от этого и улучшится.
Такие случаи не отменяют общего принципа, а просто служат иллюстрацией того, что каждая техника имеет свою область применения и должна быть использована вдумчиво.
6.7. Техника 7. Четко разделяем статический и динамический контекст. Методы, не зависящие от состояния объекта, должны быть статическими.
Смешение или вообще отсутствие разделения между статическим и динамическим контекстом — не самое страшное, но весьма распространенное зло.
Приводит оно к появлению ненужных зависимостей от состояния объекта в потенциально статических методах, либо вообще к неправильному управлению состоянием объекта. Как следствие — к затруднению анализа кода.
Поэтому необходимо стараться обращать внимание и на данный аспект, явно выделяя методы, не зависящие от состояния объекта.
6.8. Техника 8. Стараемся не разделять объявление и инициализацию объекта.
Данный прием позволяет совместить декларацию имени объекта с немедленным описанием того, что объект из себя представляет. Именно это и является ярким примером следования принципу самодокументированности.
Если данной техникой пренебречь, читателю придется для каждого объекта искать по коду, где он был объявлен, нет ли у него где-нибудь инициализации другим значением и т.д. Все это затрудняет анализ кода и увеличивает время, необходимое для того, чтобы в коде разобраться.
Именно поэтому, например, функциональные операции из apache CollectionUtils и guava Collections2 часто предпочтительней встроенных в Java foreach циклов — они позволяют совместить объявление и инициализацию коллекции.
Сравним:
// getting “somestrings” collection somehow
...
Collection<String> lowercaseStrings = new ArrayList<String>();
/* collection is uninitialized here, need to investigate the initializion */
for (String s : somestrings) {
lowercaseStrings.add(StringUtils.lowerCase(s));
}
c:
// getting “somestrings” collection somehow
...
Collection<String> lowercaseStrings = Collections2.transform(somestrings, new Function<String, String>() {
@Override
public String apply(String s) {
return StringUtils.lowerCase(s);
}
}));
Если мы используем Java 8, можно записать чуть короче:
...
Collection<String> lowercaseStrings = somestrings.stream()
.map( StringUtils::lowerCase ).collect(Collectors.toList());
Ну и стоит упомянуть случай, когда разделять объявление и инициализацию переменных так или иначе приходится. Это случай использования переменной в блоках finally и catch (например, для освобождения какого-нибудь ресурса). Тут уже ничего не остается, кроме как объявить переменную перед try, а инициализировать внутри блока try.
6.9. Техника 9. Используем декларативный подход и средства функционального программирования для обозначения, а не сокрытия сути происходящего.
Данный принцип может быть проиллюстрирован примером из предыдущего пункта, в котором мы использовали эмуляцию функционального подхода в Java с целью сделать наш код понятнее.
Для большей наглядности рассмотрим еще и пример на Javascript (взято отсюда: http://habrahabr.ru/post/154105).
Сравним:
var str = "mentioned by";
for(var i =0; l= tweeps.length; i < l; ++i){
str += tweeps[i].name;
if(i< tweeps.length-1) {str += ", "}
}
c:
var str = "mentioned by " + tweeps.map(function(t){
return t.name;
}).join(", ");
Ну а примеры использования функционального подхода, убивающие читаемость… Давайте на этот раз сэкономим свои нервы и обойдемся без них.
6.10. Техника 10. Пишем комментарии только, если без них вообще не понятно, что происходит.
Как уже говорилось выше, принцип самодокументирования кода противопоставляется документированию с помощью комментариев. Хотелось бы коротко пояснить, чем же так плохи комментарии:
- В хорошо написанном коде они не нужны.
- Если поддержка кода часто становится трудоемкой задачей, поддержкой комментариев обычно просто никто не занимается и через некоторое время комментарии устаревают и начинают обманывать людей (“comments lie”).
- Они засоряют собой пространство, тем самым ухудшая внешний вид кода и затрудняя читаемость.
- В подавляющем большинстве случаев они пишутся лично Капитаном Очевидностью.
Ну а нужны комментарии в случаях, когда написать код хорошо по тем или иным причинам не представляется возможным. Т.е. писать их надо для пояснения участков кода, без них трудночитаемых. К сожалению, в реальной жизни такое встречается регулярно, хотя расценивать это следует лишь как неизбежный компромисс.
Также как разновидность подобного компромисса следует расценивать необходимость спецификации контракта метода/класса/процедуры при помощи комментариев, если его не получается явно выразить другими языковыми средствами (см п. 5.2).
7. Философское заключение.
Закончив изложение основных техник и приемов, с помощью которых можно сделать код чуть красивее, следует еще раз явно сформулировать: ни одна из техник не является безусловным руководством к действию. Любая техника — лишь возможное средство достижения той или иной цели.
В нашем случае целью является получение максимально читаемого и управляемого кода. Который одновременно будет приятен с эстетической точки зрения.
Изучая примеры, приведенные в текущей статье, можно легко заметить, что, как сами исходные принципы (линейность, минимальность, самодокументированность), так и конкретные техники не являются независимыми друг от друга. Применяя одну технику мы можем также косвенно следовать и совсем другой. Улучшая один из целевых показателей, мы можем способствовать улучшению других.
Однако, у данного явления есть и обратная сторона: нередки ситуации, когда принципы вступают в прямое противоречие друг с другом, а также со множеством других возможных правил и догм программирования (например с принципами ООП). Воспринимать это надо совершенно спокойно.
Встречаются и такие случаи, когда однозначно хорошего решения той или иной проблемы вообще не существует, или это решение по ряду причин нереализуемо (например, заказчик не хочет принимать потенциально опасные изменения в коде, даже если они способствуют общему улучшению качества).
В программировании, как и в большинстве других областей человеческой деятельности, не может существовать универсальных инструкций к исполнению. Каждая ситуация требует отдельного рассмотрения и анализа, а решение должно приниматься исходя из понимания особенностей ситуации.
В целом, этот факт нисколько не отменяет полезности как вывода и понимания общих принципов, так и владения конкретными способами их воплощения в жизнь. Именно поэтому я надеюсь, что все изложенное в статье может оказаться действительно полезно для многих программистов.
Ну и еще пара слов о том, с чего мы начинали — о красоте нашего кода. Даже зная о “продвинутых” техниках написания красивого кода, не стоит пренебрегать самыми простыми вещами, такими, как элементарное автоформатирование и следование установленному в проекте стилю кодирования. Зачастую одно лишь форматирование способно сотворить с уродливым куском кода настоящие чудеса. Как и разумное группирование участков кода с помощью пустых строк и переносов.
Не стоит забывать и о таком средстве, как статические анализаторы кода, которые позволяют выявить множество проблем (в том числе, описанных в данной статье) автоматически, благо сейчас они встроены в большинство популярных IDE.
И самое последнее. Всегда стоит помнить о субъективности эстетического восприятия вещей. Поэтому уделяя внимание этому вопросу, следует с пониманием относиться к чужим вкусам и привычкам.
Приятного вам программирования!
