Эта публикация – продолжение моей статьи, в которой я рассказал, как устроена база данных Caché изнутри. В ней я описал типы блоков, как они связаны, какое отношение имеют к глобалам. В той статье была теория. Я создал проект, позволяющий визуализировать дерево блоков – и в этой статье вы всё это увидите. Добро пожаловать под кат.

Для демонстрации я создал новую БД и очистил от всех глобалов, которые Caché инициализирует по умолчанию для вновь создаваемой БД. Создадим простой глобал:

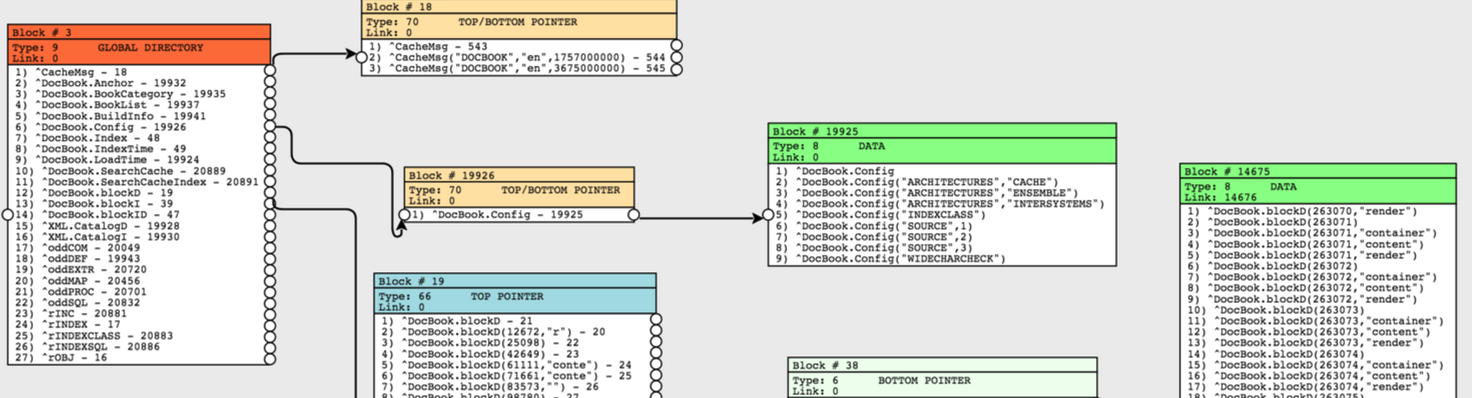
Обратите внимание на картинку, иллюстрирующую блоки созданного глобала. Глобал у нас простенький, поэтому мы, конечно, видим его описание в блоке типа 9 (блок каталога глобалов). Далее сразу идёт блок «верхнего и нижнего указателя» (тип 70), поскольку дерево глобала еще неглубокое, и можно сразу указывать ссылку на блок данных, все ещё умещающихся в один 8КБ блок.
Теперь запишем в другой глобал значений в таком количестве, чтобы они уже не смогли уместиться в один блок – и мы увидим, как в блоке указателей появятся новые узлы, которые будут ссылаться на новые блоки данных, которые не поместились в первый блок.
Мы запишем 50 значений длиной 1000 символов. Напомним, что размер блока нашей БД – 8192 байта.
Обратите внимание на следующую картинку:
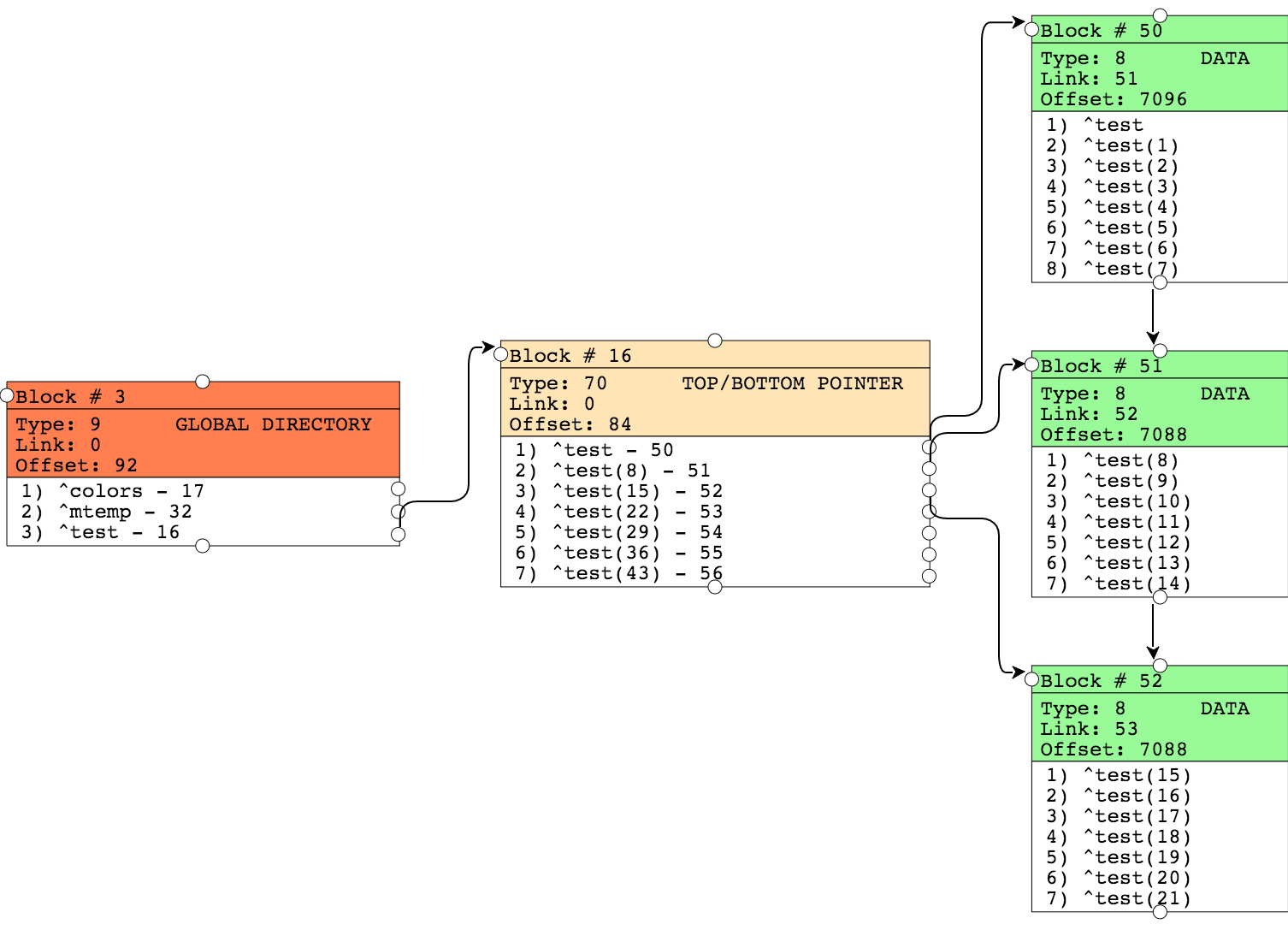
На уровне блока указателей теперь у нас несколько узлов, которые ссылаются на блоки данных. В каждом блоке данных есть ссылки на следующий блок («правая ссылка»). Offset — указывает на количество байт занятых в этом блоке данных.
Теперь попытаемся смоделировать расщепление блока («block split»). Добавим в первый блок столько значений, чтобы был превышен общий размер блока 8КБ, что приведет к тому, что этот блок будет расщеплен на два.
Результат можно увидеть ниже:
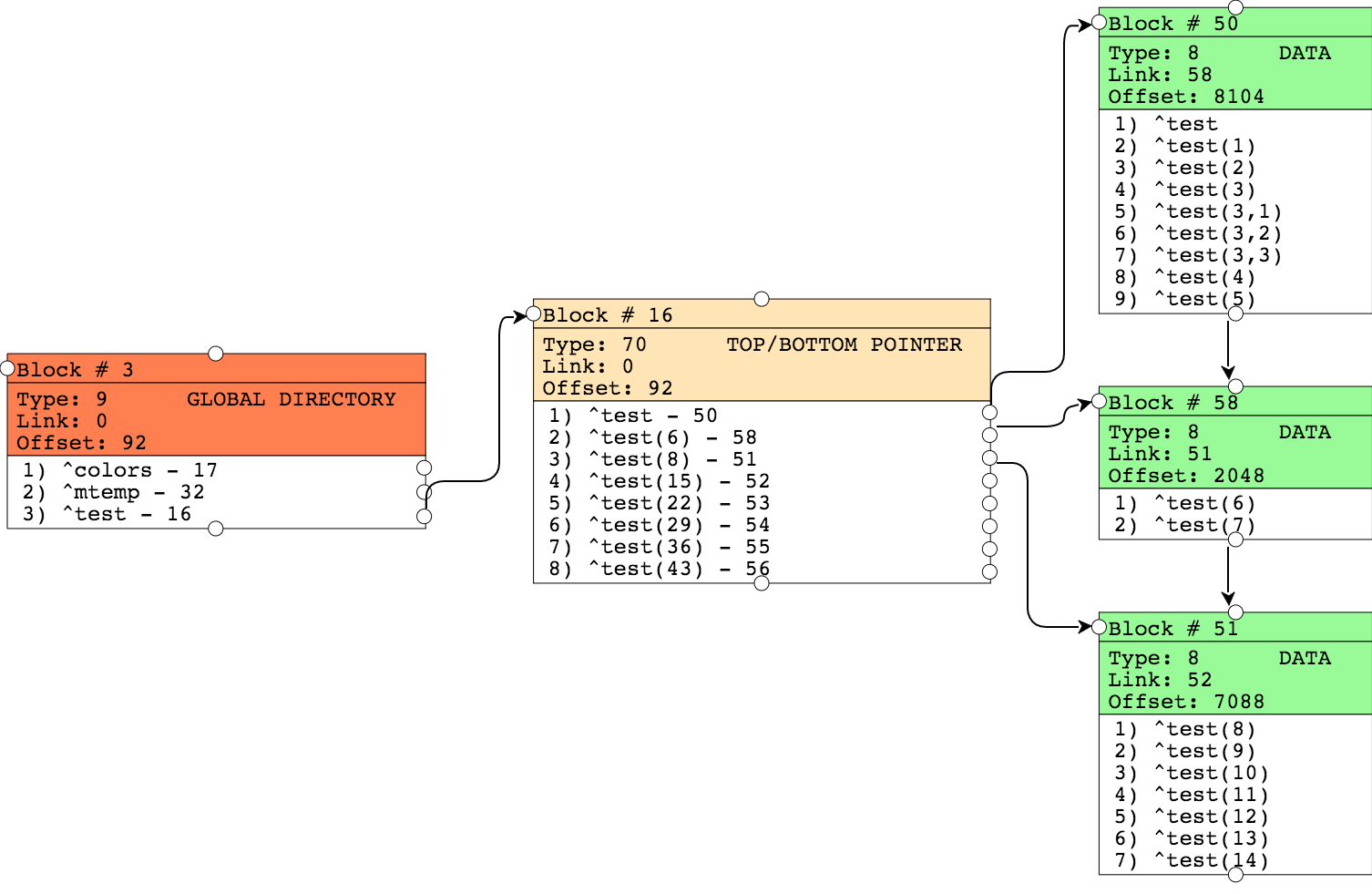
Блок 50 был расщеплен, он дополнен новыми данными, а те значения, которые были из него вытеснены, теперь находятся в блоке 58. Ссылка на этот блок появилась в блоке указателей. Другие блоки не изменялись.
При записи строк длиннее чем 8КБ (размер блока данных) мы получим блоки «длинных данных». Можем смоделировать такую ситуацию, например, записывая строки размером 10 000 байт.
Посмотрим на результат:
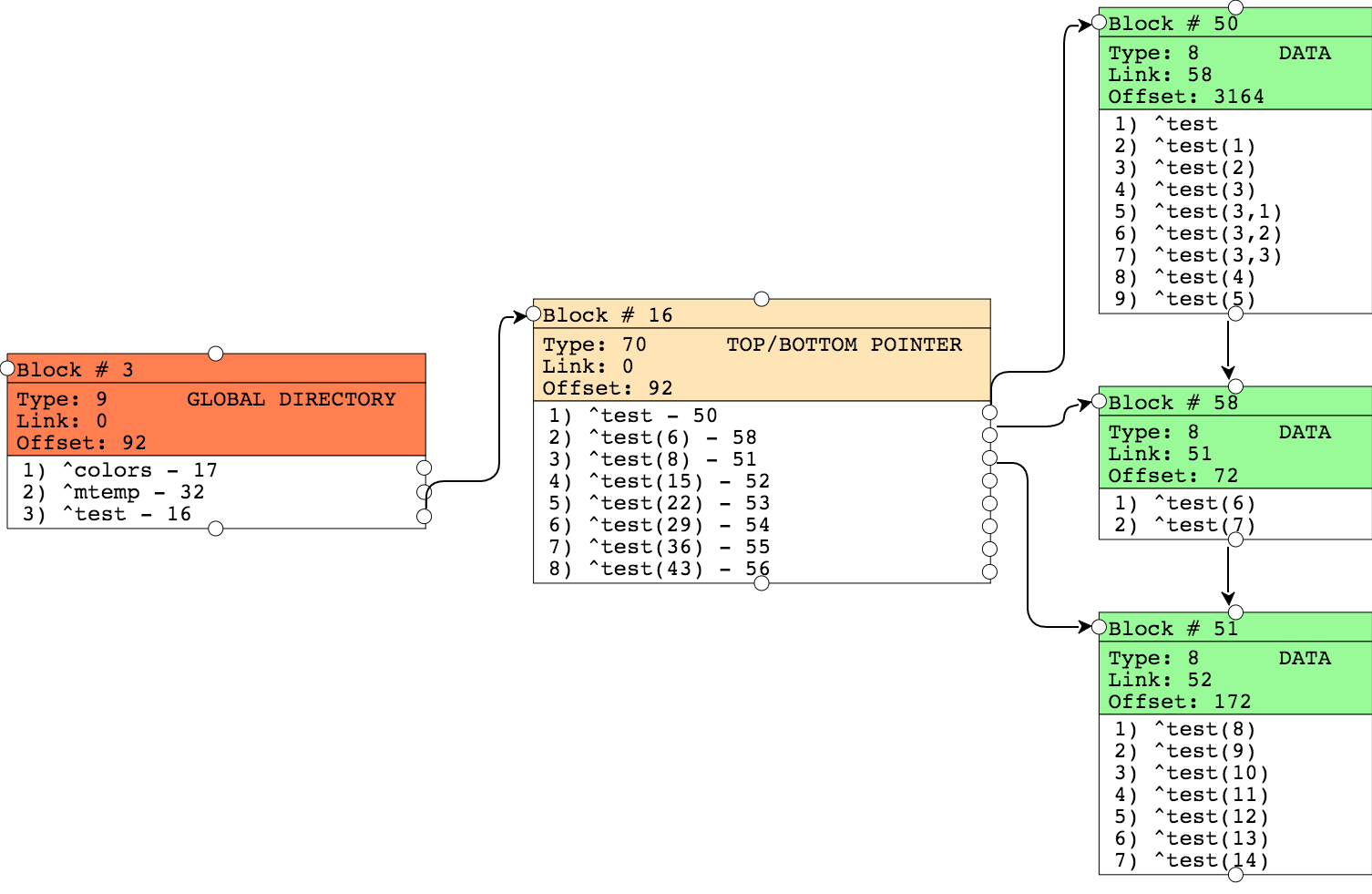
В результате структура блоков на картинке сохранилась, т.к. мы не добавляли новых узлов глобала, а только меняли значения. Но изменилось значение Offset (количество занятых байт) для всех блоков. Например, для блока №51 новое значение Offset стало 172, против 7088 в предыдущий раз. Понятно, что теперь, когда новое значение не может уместиться в блок, указатель на последний байт данных должен был бы поменяться, но где теперь хранятся наши данные? На данный момент в моём проекте пока не реализована возможность отображения информации о «больших блоках». Давайте обратимся к утилите ^REPAIR для отображения информации о новом содержимом блока №51.
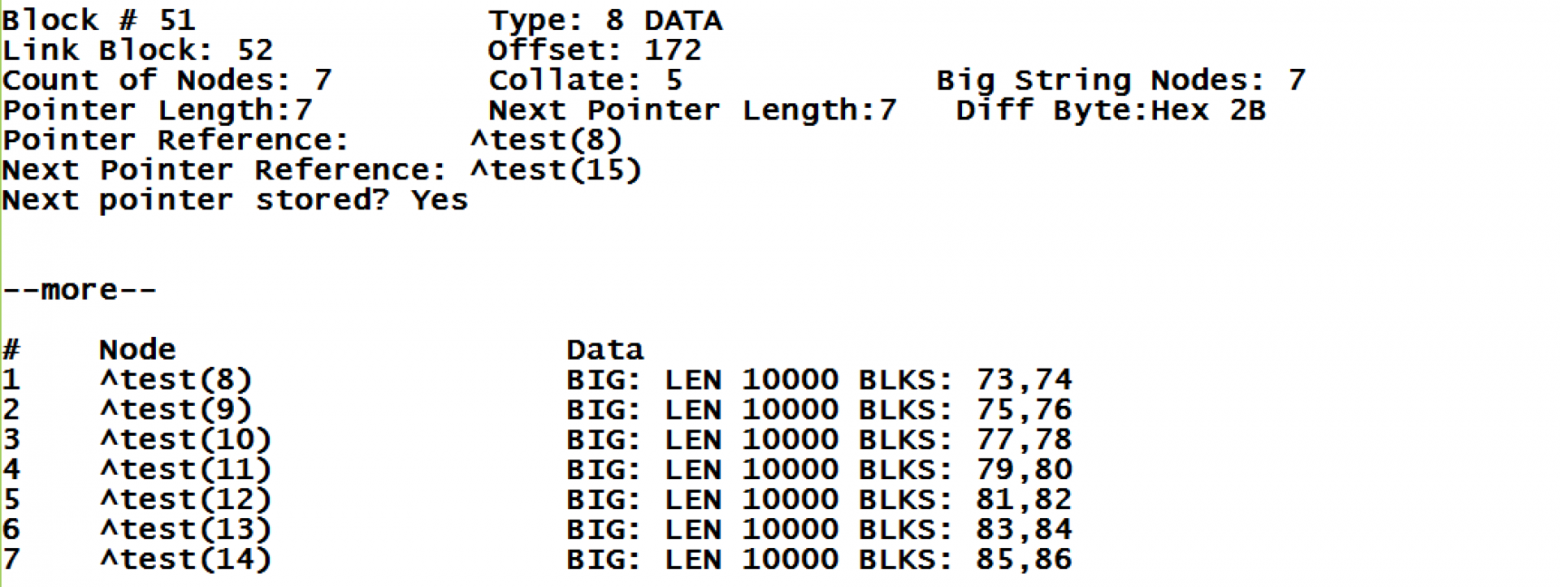
Остановлюсь поподробнее на том, что показывает нам данная утилита. Мы видим ссылку на правый блок №52, этот же номер был указан в родительском блоке указателей у следующего узла. Cортировка глобала – тип 5. Количество узлов с большими строками – 7. В некоторых случаях блок может содержать как значения данных для некоторых узлов, так и длинные строки для других, все в пределах одного блока. Так же мы видим какую глобальную ссылку следует ожидать в начале следующего блока (Next Pointer Reference).
Про блоки длинных строк: здесь мы видим, что в качестве значения для глобала указано ключевое слово BIG, что говорит нам, что данные на самом деле в «больших блоках». Далее на той же строке видим общую длину содержащейся строки, и список блоков которые хранят это значение. Можем попробовать взглянуть на «блок длинных строк», под номером 73.

К сожалению, этот блок выводится нерасшифрованным. Но здесь мы можем заметить, что после служебной информации из заголовка блока (который всегда имеет длину 28 байт) идут введенные нами данные. И зная, какие данные, несложно расшифровать то, что указано в заголовке:
Напомню о том, что данные в блоке 51 занимают только 172 байт. Это случилось в момент, когда мы сохранили большие значения. Выходит, что блок стал почти пустой — полезных данных 172 байта, а занимает 8кб! Понятно, что в такой ситуации свободное место будет со временем заполнено новыми значениями, но так же Caché предоставляет нам возможность сжать такой глобал. Для этого в классе %Library.GlobalEdit есть метод CompactGlobal. Для того чтобы убедиться в эффективности этого метода, повторим наш пример, но с большим объемом данных, например создав 500 узлов.
Выполняем метод CompactGlobal:
Посмотрим на полученный результат. Блок указателей у нас теперь имеет только 2 узла, т.е. наши значения все ушли в два блока данных, тогда как раньше у нас было 72 узла в блоке указателей. Таким образом мы избавились от 70 блоков, сократив, тем самым, время доступа к данным при полном обходе глобала, так как потребуется меньше чтений блоков.

CompactGlobal принимает на вход несколько параметров, такие как, имя глобала, базы данных и процент заполнения, который мы хотим получить, со значением по умолчанию 90. И теперь мы видим, что Offset (количество занятых байт) стало равным 7360, что составляет примерно те самые 90% заполнения. Несколько параметров функции выходные: сколько мегабайт обработано и количество мегабайт после сжатия. Ранее сжатие глобалов осуществлялось, с помощью утилиты ^GCOMPACT, которая на данный момент считается устаревшей.
Стоит заметить, что ситуация, при которой блоки могут оставаться не полностью заполненными, является вполне нормальной. Более того, сжатие глобала не всегда может быть желательным. Например, если у вас глобал чаще читается и практически не меняется, то сжатие может помочь. Но если глобал активно изменяется, то определенная разреженность в блоках данных поможет реже расщеплять блоки, и запись новых данных будет происходить быстрее.
В следующей части я расскажу про ещё одну возможность моего проекта, которая была реализована в рамках недавно прошедшего хакатона на школе InterSystems – о карте распределения блоков базы и её практическом применении.
Для демонстрации я создал новую БД и очистил от всех глобалов, которые Caché инициализирует по умолчанию для вновь создаваемой БД. Создадим простой глобал:
set ^colors(1)="red"
set ^colors(2)="blue"
set ^colors(3)="green"
set ^colors(4)="yellow"
Обратите внимание на картинку, иллюстрирующую блоки созданного глобала. Глобал у нас простенький, поэтому мы, конечно, видим его описание в блоке типа 9 (блок каталога глобалов). Далее сразу идёт блок «верхнего и нижнего указателя» (тип 70), поскольку дерево глобала еще неглубокое, и можно сразу указывать ссылку на блок данных, все ещё умещающихся в один 8КБ блок.
Теперь запишем в другой глобал значений в таком количестве, чтобы они уже не смогли уместиться в один блок – и мы увидим, как в блоке указателей появятся новые узлы, которые будут ссылаться на новые блоки данных, которые не поместились в первый блок.
Мы запишем 50 значений длиной 1000 символов. Напомним, что размер блока нашей БД – 8192 байта.
set str=""
for i=1:1:1000 {
set str=str_"1"
}
for i=1:1:50 {
set ^test(i)=str
}
quit
Обратите внимание на следующую картинку:
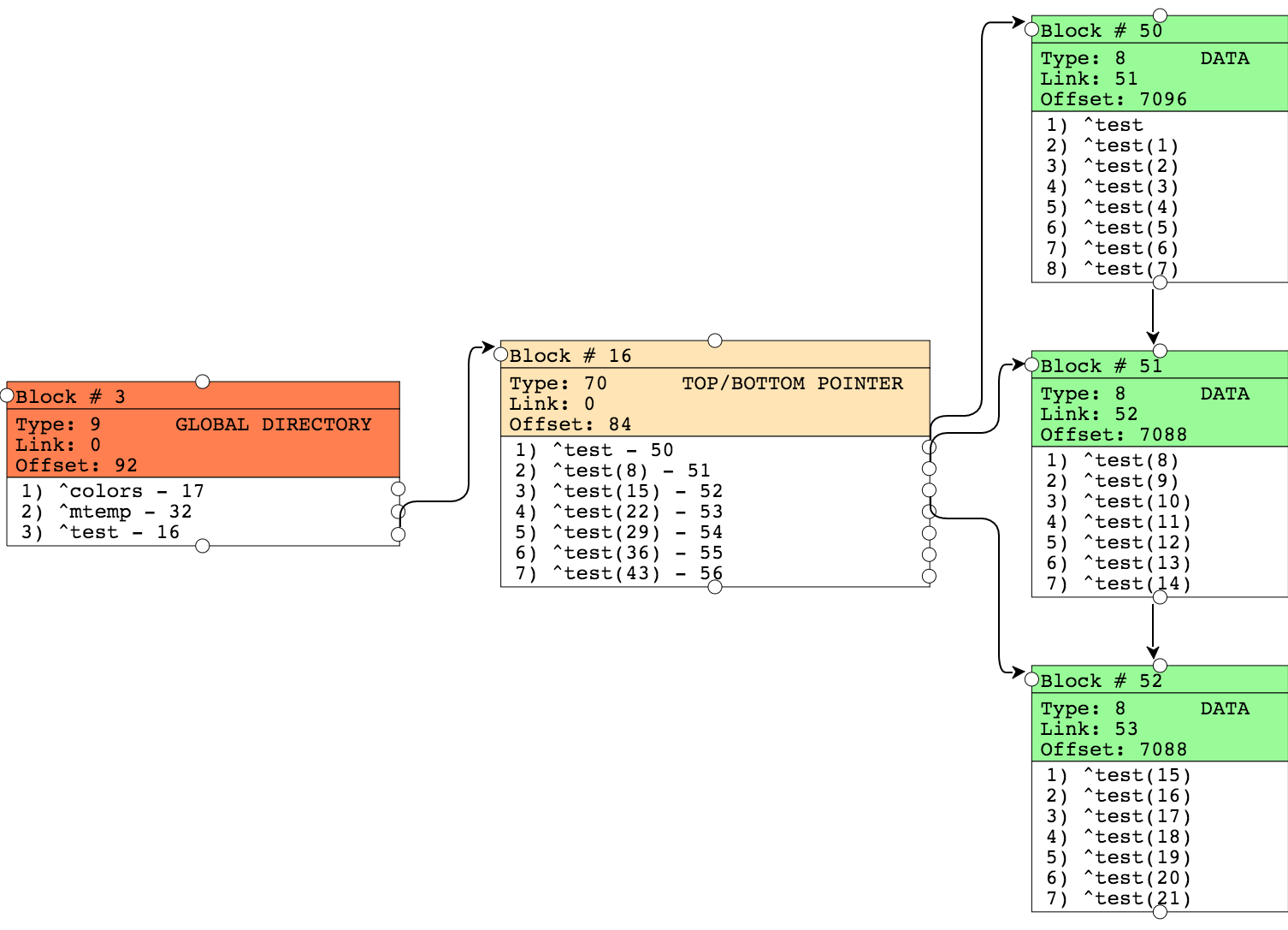
На уровне блока указателей теперь у нас несколько узлов, которые ссылаются на блоки данных. В каждом блоке данных есть ссылки на следующий блок («правая ссылка»). Offset — указывает на количество байт занятых в этом блоке данных.
Теперь попытаемся смоделировать расщепление блока («block split»). Добавим в первый блок столько значений, чтобы был превышен общий размер блока 8КБ, что приведет к тому, что этот блок будет расщеплен на два.
Пример кода
set str=""
for i=1:1:1000 {
set str=str_"1"
}
set ^test(3,1)=str
set ^test(3,2)=str
set ^test(3,3)=str
Результат можно увидеть ниже:

Блок 50 был расщеплен, он дополнен новыми данными, а те значения, которые были из него вытеснены, теперь находятся в блоке 58. Ссылка на этот блок появилась в блоке указателей. Другие блоки не изменялись.
Пример с длинными строками
При записи строк длиннее чем 8КБ (размер блока данных) мы получим блоки «длинных данных». Можем смоделировать такую ситуацию, например, записывая строки размером 10 000 байт.
Пример кода
set str=""
for i=1:1:10000 {
set str=str_"1"
}
for i=1:1:50 {
set ^test(i)=str
}
Посмотрим на результат:

В результате структура блоков на картинке сохранилась, т.к. мы не добавляли новых узлов глобала, а только меняли значения. Но изменилось значение Offset (количество занятых байт) для всех блоков. Например, для блока №51 новое значение Offset стало 172, против 7088 в предыдущий раз. Понятно, что теперь, когда новое значение не может уместиться в блок, указатель на последний байт данных должен был бы поменяться, но где теперь хранятся наши данные? На данный момент в моём проекте пока не реализована возможность отображения информации о «больших блоках». Давайте обратимся к утилите ^REPAIR для отображения информации о новом содержимом блока №51.
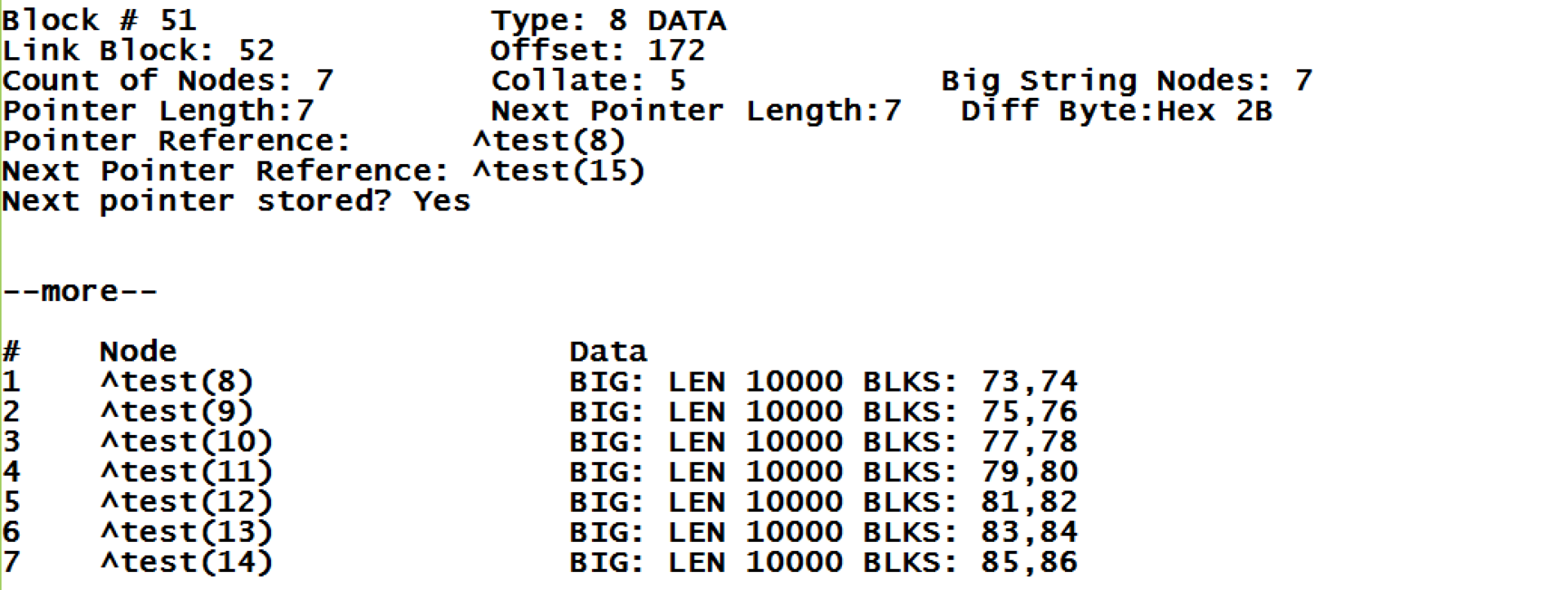
Остановлюсь поподробнее на том, что показывает нам данная утилита. Мы видим ссылку на правый блок №52, этот же номер был указан в родительском блоке указателей у следующего узла. Cортировка глобала – тип 5. Количество узлов с большими строками – 7. В некоторых случаях блок может содержать как значения данных для некоторых узлов, так и длинные строки для других, все в пределах одного блока. Так же мы видим какую глобальную ссылку следует ожидать в начале следующего блока (Next Pointer Reference).
Про блоки длинных строк: здесь мы видим, что в качестве значения для глобала указано ключевое слово BIG, что говорит нам, что данные на самом деле в «больших блоках». Далее на той же строке видим общую длину содержащейся строки, и список блоков которые хранят это значение. Можем попробовать взглянуть на «блок длинных строк», под номером 73.
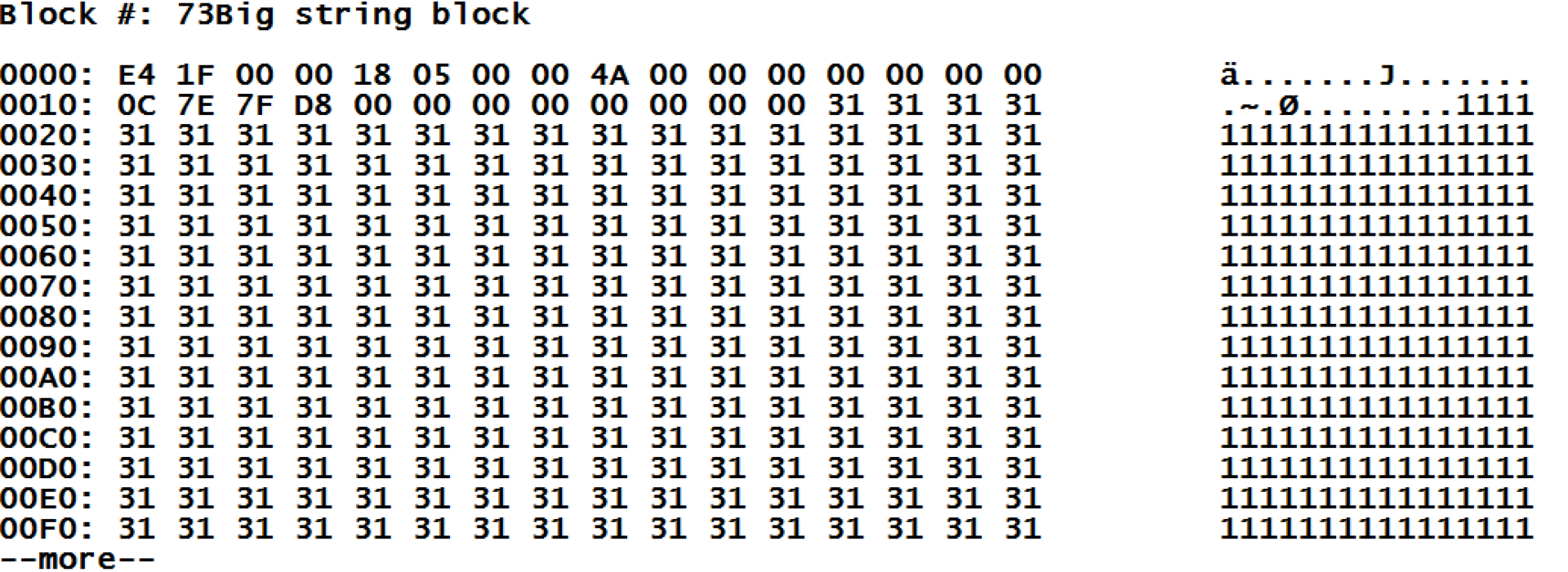
К сожалению, этот блок выводится нерасшифрованным. Но здесь мы можем заметить, что после служебной информации из заголовка блока (который всегда имеет длину 28 байт) идут введенные нами данные. И зная, какие данные, несложно расшифровать то, что указано в заголовке:
| Позиция | Значение | Описание | Подробнее |
| 0-3 | E4 1F 00 00 | смещение, указывает на конец данных | получается 8164 плюс 28 байт заголовка равно 8192 байт, блок заполнен полностью. |
| 4 | 18 | тип блока | значение 24, как мы помним — это тип для блока больших строк. |
| 5 | 05 | сортировка | сортировка 5, это «стандартные Caché» |
| 8-11 | 4A 00 00 00 | правая связь | здесь получилось 74, как мы помним наше значение хранится в 73 и 74 блоке |
Напомню о том, что данные в блоке 51 занимают только 172 байт. Это случилось в момент, когда мы сохранили большие значения. Выходит, что блок стал почти пустой — полезных данных 172 байта, а занимает 8кб! Понятно, что в такой ситуации свободное место будет со временем заполнено новыми значениями, но так же Caché предоставляет нам возможность сжать такой глобал. Для этого в классе %Library.GlobalEdit есть метод CompactGlobal. Для того чтобы убедиться в эффективности этого метода, повторим наш пример, но с большим объемом данных, например создав 500 узлов.
Вот что у нас получилось.
Ниже мы отобразили не все блоки, но смысл должен быть понятен. У нас много блоков с данными, но с небольшим количеством узлов.

kill ^test
for l=1000,10000 {
set str=""
for i=1:1:l {
set str=str_"1"
}
for i=1:1:500 {
set ^test(i)=str
}
}
quit
Ниже мы отобразили не все блоки, но смысл должен быть понятен. У нас много блоков с данными, но с небольшим количеством узлов.
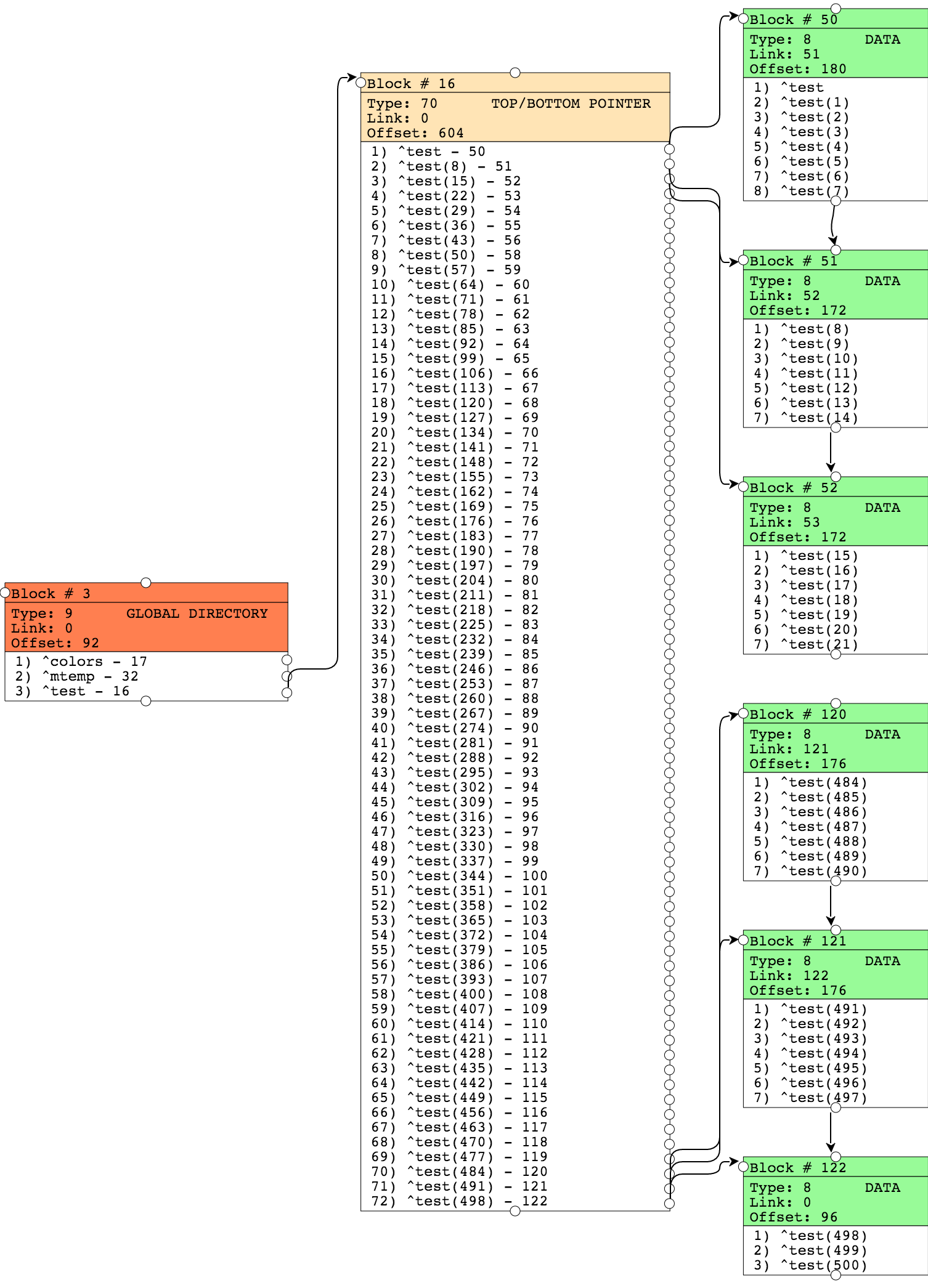
Выполняем метод CompactGlobal:
w ##class(%GlobalEdit).CompactGlobal("test","c:\intersystems\ensemble\mgr\habr")Посмотрим на полученный результат. Блок указателей у нас теперь имеет только 2 узла, т.е. наши значения все ушли в два блока данных, тогда как раньше у нас было 72 узла в блоке указателей. Таким образом мы избавились от 70 блоков, сократив, тем самым, время доступа к данным при полном обходе глобала, так как потребуется меньше чтений блоков.
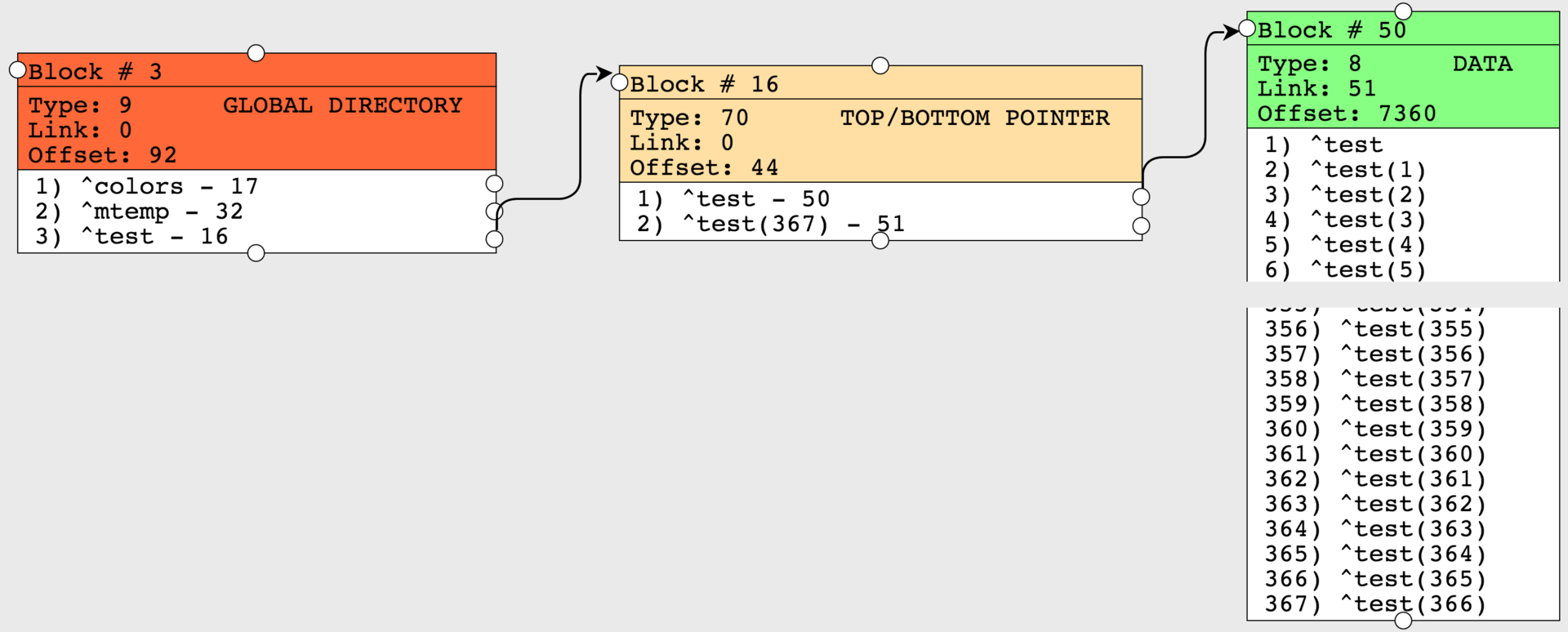
CompactGlobal принимает на вход несколько параметров, такие как, имя глобала, базы данных и процент заполнения, который мы хотим получить, со значением по умолчанию 90. И теперь мы видим, что Offset (количество занятых байт) стало равным 7360, что составляет примерно те самые 90% заполнения. Несколько параметров функции выходные: сколько мегабайт обработано и количество мегабайт после сжатия. Ранее сжатие глобалов осуществлялось, с помощью утилиты ^GCOMPACT, которая на данный момент считается устаревшей.
Стоит заметить, что ситуация, при которой блоки могут оставаться не полностью заполненными, является вполне нормальной. Более того, сжатие глобала не всегда может быть желательным. Например, если у вас глобал чаще читается и практически не меняется, то сжатие может помочь. Но если глобал активно изменяется, то определенная разреженность в блоках данных поможет реже расщеплять блоки, и запись новых данных будет происходить быстрее.
В следующей части я расскажу про ещё одну возможность моего проекта, которая была реализована в рамках недавно прошедшего хакатона на школе InterSystems – о карте распределения блоков базы и её практическом применении.
