CQRS — довольно хорошо изученный паттерн. Часто можно слышать, что вы либо следуете CQRS, либо нет, имея ввиду что это что-то вроде бинарного выбора. В этой статье я бы хотел показать, что существует спектр вариаций этого понятия, а также как разные типы CQRS могут выглядеть на практике.
С этим типом, вы не используете паттерн CQRS вообще. Это означает, что ваша доменная модель использует доменные классы для обслуживания как команд (commands), так и запросов (queries).
Рассмотрим класс Customer как пример:
С нулевым типом CQRS вы работаете с классом CustomerRepository, который выглядит следующим образом:
Метод Search здесь является запросом. Он используется для выборки данных по кастомерам из БД и возврата этих данных клиенту (который может быть UI-ем или отдельным приложением, обращающимся к вашему приложению через API). Обратите внимание, что этот метод возвращает список доменных объектов.
Преимущество подобного подхода в том, что здесь нет оверхеда по количеству кода. Другими словами, у вас есть единственная модель, которую вы можете использовать и для команд, и для запросов, и вам не приходится дублировать код.
Недостаток здесь в том, что эта единственная модель не оптимизирована под операции чтения. Если вам необходимо показать список кастомеров на UI, вам как правило не нужно отображать их заказы (Orders). Вместо этого, в большинстве случаев вы захотите показать только краткую информацию, такую как id, имя и количество заказов.
Использование доменных классов для транспортировки данных приводит к тому, что все подобъекты (такие как Orders) кастомеров загружаются в память из базы. Это ведет к серьезных накладным расходам, т.к. UI-ю требуется всего лишь количество заказов, а не сами заказы.
Этот тип CQRS хорош для приложений с небольшими (или вообще без) требованиями по производительности. Для остальных типов приложений, мы должны использовать следующие типы CQRS.
С этим типом CQRS ваща структура классов разделена для обслуживания операций чтения и записи. Это означает, что вы создаете набор классов DTO для транспортировки данных, загружаемых из базы.
DTO для класса Customer может выглядеть так:
Метод Search в репозитории возвращает список DTO вместо списка доменных объектов:
Search может использовать как ORM, так и обычный ADO.NET для выборки необходимых данных. Это должно определяться требованиями по производительности в каждом конкретном случае. Нет необходимости откатываться к ADO.NET в случае если производительность метода удовлетворительна.
DTO добавляют некоторое дублирование в том смысле, что нам теперь нужно создавать два класса вместо одного: один раз для команд в форме доменного объекта и еще один раз для запросов в формате DTO. В то же время, они позволяют нам создавать чистые и ясные структуры данных, которые четко ложатся на нужны наших операций чтения, т.к. они содержат только то, что необходимо при отображении. А чем более ясно мы выражаем наши намерения в коде, тем лучше.
По моему мнению, этот тип CQRS достаточен для большинства enterprise приложений, т.к. он дает довольно хороший баланс между простотой и производительностью кода. Также, с этим подхом мы имеем некоторую гибкость в том, какой инструмент выбирать для запросов. Если производительность метода не критична, мы можем использовать ORM и сэкономить время разработчика. Иначе, мы можем использовать ADO.NET напрямую (или же легковесную ORM типа Dapper) и писать сложные и оптимизированные запросы вручную.
Этот тип CQRS предполагает использование отдельных моделей и набора API для обслуживания запросов на чтение и запись.
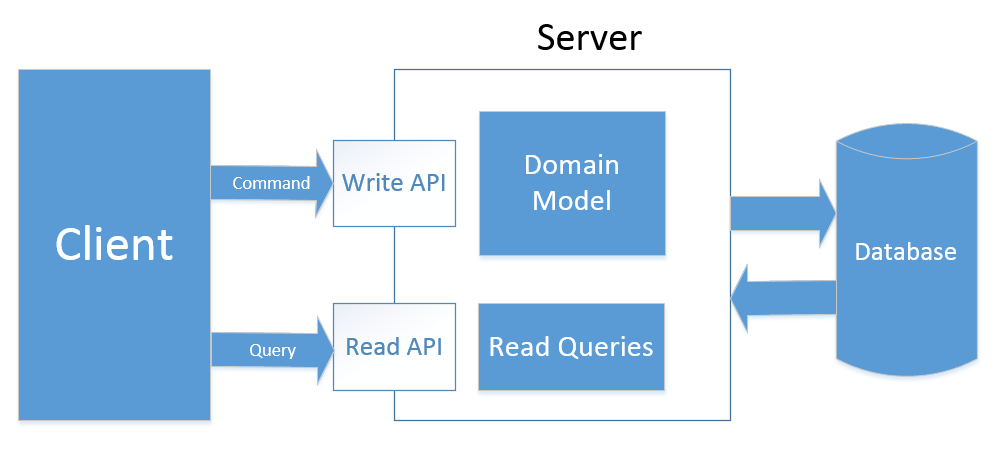
Это означает, что в дополнение к DTO, мы извлекаем все операции чтения из нашей модели. Репозитории теперь содержат только методы, которые относятся к командам:
А логика поиска находится в отдельном классе:
Этот подход добавляет больше оверхеда в сравнении с предыдущим по количеству кода, необходимого для обработки запросов, но это хорошее решение в случае если у вас имеются большие нагрузки на чтение данных.
В дополнение к возможности написания оптимизированных запросов, тип 2 позволяет нам легко оборачивать часть API, относящуюся к запросам, в некоторый механизм кеширования или даже переместить этот API в отдельный сервер или группу серверов с настроенным лоад-беленсером. Это решение великолепно подходит для приложений с большой разницей в нагрузках на чтение и на запись, т.к. позволяет хорошо масштабировать операции чтения.
Если вам необходимо еще большее увеличение производительности в части операций по чтению, вам нужно двигаться в сторону типа 3.
Это тип, который многими считается «истинным» CQRS. Для масштабирования операций чтения еще больше, мы можем использовать отдельное хранилище, оптимизированное под запросы нашей системы. Часто подобным хранилищем выступает NoSQL БД, к примеру MongoDB, либо набор реплик из нескольких инстансов:
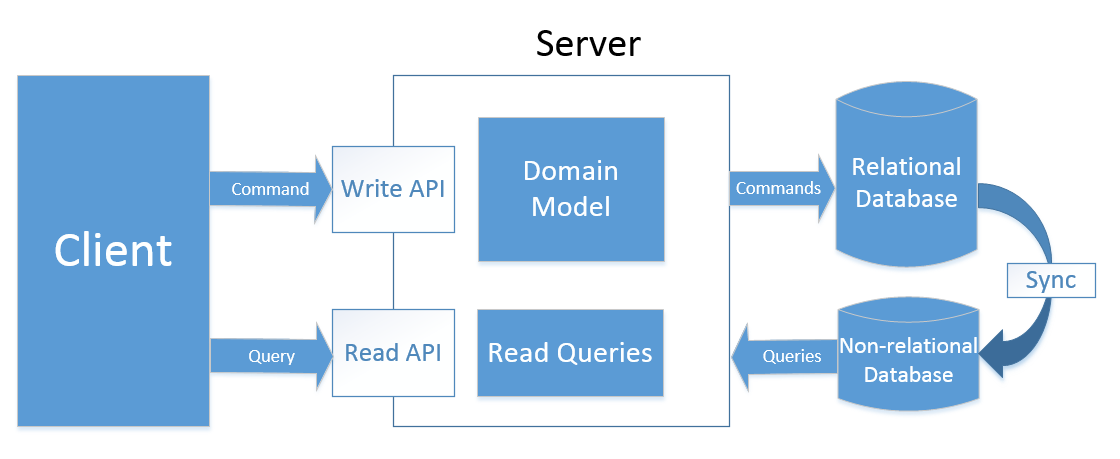
Синхронизация здесь происходит в фоновом режиме и может занимать некоторое время. Такие хранилища называются «консистентными в конечном счете» (eventually consistent).
Хорошим примером здесь является индексирование данных клиентов при помощи Elastic Search. Часто мы не хотим использовать полнотекстовый поиск, встроенный в SQL Server, т.к. он не особо хорошо масштабируется. Вместо этого, мы можем использовать нереляционные хранилища данных, оптимизированные для поиска кастомеров.
Вместе с наилучшей масштабируемостью по операциям чтения, этот тип CQRS несет в себе наибольший оверхед. Мы не только разделяем нашу модель чтения и записи логически, т.е. используем отдельные классы и даже сборки для этого, но мы еще и разделяем саму базу данных.
Существуют разные градации паттерна CQRS, которые вы можете использовать в своем приложении. Нет ничего плохого в том, чтобы придерживаться типа 1 и не двигаться в сторону типов 2 и 3 если тип 1 удовлетворяет требованиям производительности вашего приложения.
Я бы хотел подчеркнуть этот момент: CQRS не является бинарным выбором. Существуют различные вариации между тем, чтобы не разделять операции чтения и записи вообще (тип 0) и разделением их полностью (тип 3).
Следует придерживаться баланса между степенью сегрегации и сложностью, которую эта сегрегация привносит. Баланс следует искать в каждом конкретном случае отдельно, часто с применением нескольких итераций. Паттерн CQRS не должен применяться просто потому, что «мы можем».
Английская версия статьи: Types of CQRS
Тип 0: без CQRS
С этим типом, вы не используете паттерн CQRS вообще. Это означает, что ваша доменная модель использует доменные классы для обслуживания как команд (commands), так и запросов (queries).
Рассмотрим класс Customer как пример:
public class Customer
{
public int Id { get; private set; }
public string Name { get; private set; }
public IReadOnlyList<Order> Orders { get; private set; }
public void AddOrder(Order order)
{
/* … */
}
/* Other methods */
}
С нулевым типом CQRS вы работаете с классом CustomerRepository, который выглядит следующим образом:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList<Customer> Search(string name) { /* … */ }
}
Метод Search здесь является запросом. Он используется для выборки данных по кастомерам из БД и возврата этих данных клиенту (который может быть UI-ем или отдельным приложением, обращающимся к вашему приложению через API). Обратите внимание, что этот метод возвращает список доменных объектов.
Преимущество подобного подхода в том, что здесь нет оверхеда по количеству кода. Другими словами, у вас есть единственная модель, которую вы можете использовать и для команд, и для запросов, и вам не приходится дублировать код.
Недостаток здесь в том, что эта единственная модель не оптимизирована под операции чтения. Если вам необходимо показать список кастомеров на UI, вам как правило не нужно отображать их заказы (Orders). Вместо этого, в большинстве случаев вы захотите показать только краткую информацию, такую как id, имя и количество заказов.
Использование доменных классов для транспортировки данных приводит к тому, что все подобъекты (такие как Orders) кастомеров загружаются в память из базы. Это ведет к серьезных накладным расходам, т.к. UI-ю требуется всего лишь количество заказов, а не сами заказы.
Этот тип CQRS хорош для приложений с небольшими (или вообще без) требованиями по производительности. Для остальных типов приложений, мы должны использовать следующие типы CQRS.
Тип 1: отдельная иерархия классов
С этим типом CQRS ваща структура классов разделена для обслуживания операций чтения и записи. Это означает, что вы создаете набор классов DTO для транспортировки данных, загружаемых из базы.
DTO для класса Customer может выглядеть так:
public class CustomerDto
{
public int Id { get; set; }
public string Name { get; set; }
public int OrderCount { get; set; }
}
Метод Search в репозитории возвращает список DTO вместо списка доменных объектов:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList<CustomerDto> Search(string name) { /* … */ }
}
Search может использовать как ORM, так и обычный ADO.NET для выборки необходимых данных. Это должно определяться требованиями по производительности в каждом конкретном случае. Нет необходимости откатываться к ADO.NET в случае если производительность метода удовлетворительна.
DTO добавляют некоторое дублирование в том смысле, что нам теперь нужно создавать два класса вместо одного: один раз для команд в форме доменного объекта и еще один раз для запросов в формате DTO. В то же время, они позволяют нам создавать чистые и ясные структуры данных, которые четко ложатся на нужны наших операций чтения, т.к. они содержат только то, что необходимо при отображении. А чем более ясно мы выражаем наши намерения в коде, тем лучше.
По моему мнению, этот тип CQRS достаточен для большинства enterprise приложений, т.к. он дает довольно хороший баланс между простотой и производительностью кода. Также, с этим подхом мы имеем некоторую гибкость в том, какой инструмент выбирать для запросов. Если производительность метода не критична, мы можем использовать ORM и сэкономить время разработчика. Иначе, мы можем использовать ADO.NET напрямую (или же легковесную ORM типа Dapper) и писать сложные и оптимизированные запросы вручную.
Тип 2: отдельные модели
Этот тип CQRS предполагает использование отдельных моделей и набора API для обслуживания запросов на чтение и запись.
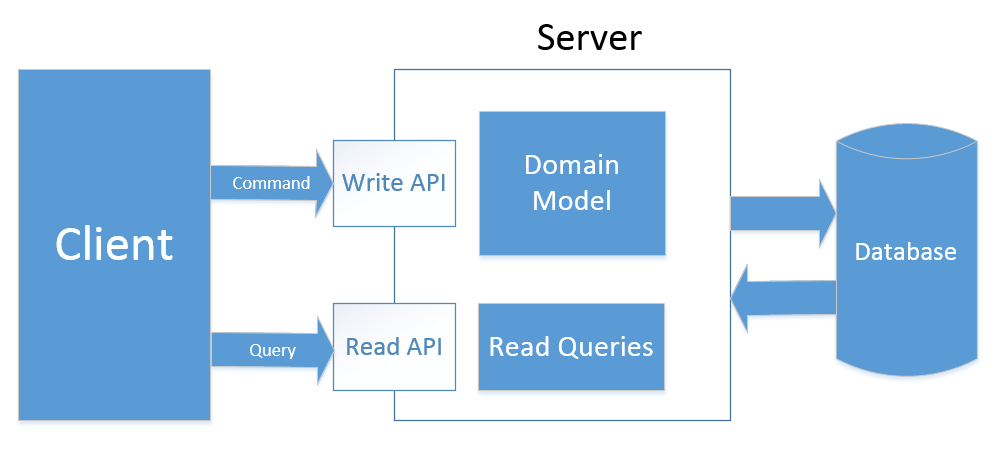
Это означает, что в дополнение к DTO, мы извлекаем все операции чтения из нашей модели. Репозитории теперь содержат только методы, которые относятся к командам:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
}
А логика поиска находится в отдельном классе:
public class SearchCustomerQueryHandler
{
public IReadOnlyList<CustomerDto> Execute(SearchCustomerQuery query)
{
/* … */
}
}
Этот подход добавляет больше оверхеда в сравнении с предыдущим по количеству кода, необходимого для обработки запросов, но это хорошее решение в случае если у вас имеются большие нагрузки на чтение данных.
В дополнение к возможности написания оптимизированных запросов, тип 2 позволяет нам легко оборачивать часть API, относящуюся к запросам, в некоторый механизм кеширования или даже переместить этот API в отдельный сервер или группу серверов с настроенным лоад-беленсером. Это решение великолепно подходит для приложений с большой разницей в нагрузках на чтение и на запись, т.к. позволяет хорошо масштабировать операции чтения.
Если вам необходимо еще большее увеличение производительности в части операций по чтению, вам нужно двигаться в сторону типа 3.
Тип 3: раздельное хранилище
Это тип, который многими считается «истинным» CQRS. Для масштабирования операций чтения еще больше, мы можем использовать отдельное хранилище, оптимизированное под запросы нашей системы. Часто подобным хранилищем выступает NoSQL БД, к примеру MongoDB, либо набор реплик из нескольких инстансов:

Синхронизация здесь происходит в фоновом режиме и может занимать некоторое время. Такие хранилища называются «консистентными в конечном счете» (eventually consistent).
Хорошим примером здесь является индексирование данных клиентов при помощи Elastic Search. Часто мы не хотим использовать полнотекстовый поиск, встроенный в SQL Server, т.к. он не особо хорошо масштабируется. Вместо этого, мы можем использовать нереляционные хранилища данных, оптимизированные для поиска кастомеров.
Вместе с наилучшей масштабируемостью по операциям чтения, этот тип CQRS несет в себе наибольший оверхед. Мы не только разделяем нашу модель чтения и записи логически, т.е. используем отдельные классы и даже сборки для этого, но мы еще и разделяем саму базу данных.
Заключение
Существуют разные градации паттерна CQRS, которые вы можете использовать в своем приложении. Нет ничего плохого в том, чтобы придерживаться типа 1 и не двигаться в сторону типов 2 и 3 если тип 1 удовлетворяет требованиям производительности вашего приложения.
Я бы хотел подчеркнуть этот момент: CQRS не является бинарным выбором. Существуют различные вариации между тем, чтобы не разделять операции чтения и записи вообще (тип 0) и разделением их полностью (тип 3).
Следует придерживаться баланса между степенью сегрегации и сложностью, которую эта сегрегация привносит. Баланс следует искать в каждом конкретном случае отдельно, часто с применением нескольких итераций. Паттерн CQRS не должен применяться просто потому, что «мы можем».
Английская версия статьи: Types of CQRS
