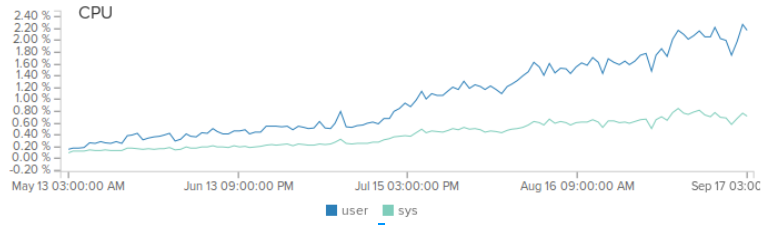
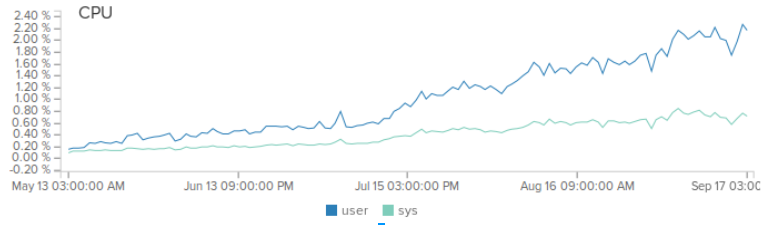
Всем привет. Этот пост о серверном решении для интернета вещей, который я написал на асинхронных сокетах с использованием всем известной Netty. Я расскажу о задаче, которую мы ставили перед собой, о том почему я выбрал Netty, почему у нее нету альтернатив, какие у нетти недостатки и преимущества и как можно выжать максимум. Сейчас наш сервер в среднем обрабатывает 1.5 млрд сообщений в месяц и нагрузка с каждым месяцем растет на 20%. Для привлечения внимания — нагрузка на один продакшн сервер с 4-мя ядрами Xeon® CPU E5-2630L v2 @ 2.40GHz при лоаде в 500 рек-сек.
Итак, поехали.
Все началось около 2-х лет назад, когда мне подарили arduino. Я всегда мечтал сделать какое-то интересное устройство своими руками. Но все эти паяльники, резисторы, вольты-амперы меня постоянно отпугивали. Так было, пока не появились arduino. С ардуиной я смог наконец-то управлять электроникой. Сказать, что это было очень круто — не сказать ничего. Я был счастлив. Но, как это часто бывает, после освоения базовых навыков в микроконтроллерах, захотелось большего — управлять устройствами через интернет с телефона. Быстрый гуглинг показал (дело было 2 года назад), что на текущий момент нет ни одного решения, которое бы решало эту задачу. Не считая IoT облака с HTTP API, которые было не очень удобно использовать.
К счастью, я не был один. Совершенно случайно, на своей работе, я познакомился с людьми, которых волновали те же проблемы. Так появился наш проект.
Отдаленно задача была ясна — управлять ардуиной через интернет с мобильного или планшета. Ну например, чтобы иметь возможность менять цвет юбки ниже.

На том этапе каких-то более понятных и четких требований банально не было. После недолгих обсуждений и анализа — мы обрисовали себе несколько важных пунктов, которые должна была бы обеспечивать архитектура проекта:
Я не считаю себя гиком. Но уже тогда у меня было 2 ардуинки, 2 телефона и планшет, которые я бы хотел использовать для управления. Небольшой опрос среди знакомых показал, что у среднего хардварщика 3-4 микроконтроллера. Стало вполне очевидно, что один потенциальный пользователь нашей системы с легкостью может открывать 5-10 соединений с разных устройств. То есть сервер должен одновременно обрабатывать тысячи параллельных соединений даже для нескольких сотен пользователей.
Не смотря на свой небольшой опыт работы с микроконтроллерами, было очевидно что серверное решение должно поддерживать 2 режима работы клиентов — pushing и polling. То есть мобильный клиент должен иметь возможность запросить с железки состояние и железка со своей стороны должна иметь возможность в любой момент послать сообщение, а мобильный клиент его получить.
Выбрать протокол было трудно. Очень хотелось пойти старой протоптанной дорожкой — HTTP. Но у HTTP есть несколько архитектурных проблем. Минимально возможный пакет — 26 байт (без учета TCP/IP заголовков), но в реальной жизни минимальный пакет будет не меньше 50 байт, а учитывая слабые возможности микроконтроллеров (у Arduino UNO например 2кб RAM и 16 MHz процессора) и недолгую жизнь элементов питания это показалось излишним. Ну и если с полингом у http все хорошо, то с пушингом нужны уже web-scokets, а это по сути старый добрый TCP/IP. В среде хардварщиков очень популярен протокол MQTT. Но от него я тоже отказался. Он показался мне слишком мудренным. Да, его продумывали на все случаи жизни. Но тогда нам это было не нужно. Поэтому сервер должен был поддерживать как минимум несколько протоколов, чтобы мы могли переключится на нужный в случае, если бы наш выбор оказался не верным.
Так как проект изначально мы делали для себя, то одним из главных условий была простота настройки и деплоймента. Так, чтобы даже совершенно новый человек, без каких-либо навыков, смог бы с легкостью и в течении нескольких минут начать управлять свой железкой и в случае необходимости мог бы точно так же просто и безболезненно развернуть у себя сервер.
Немного поразмыслив, было принято решение об использовании асинхронных сокетов. Я руководствовался 2-мя факторами. Нужно обрабатывать много параллельных соединений, с чем блокирующие сокеты не очень хорошо справляются в виду большого стека (256кб) в яве и затрат на переключение контекста между потоками. Бизнес логики будет немного. Ведь всего лишь нужно переслать сообщение с одного сокета на другой (ну кто не ошибается). Все работа сервера по сути сводится к «взять сообщение из сокета А» и «послать сообщение в сокет Б» + немного бизнес логики сверху.
Быстрый анализ существующих решений показал следующее:

Вот уже как 2 года я работаю с нетти. И мне есть что сказать. Начну с минусов.
Есть отличный getting started и вроде как все хорошо. Но как только начинаешь делать шаг влево, шаг вправо, сразу возникают десятки вопросов. Ответов на которые в документации нету и ответы на которые разбросаны по всему интернету. Сейчас ситуация гораздо лучше, чем была 2 года назад. Но проблема все еще остается.
Как асинхронный фреймворк — нетти упрощает работу с асинхронными сокетами. Но все-таки с наскоку сразу перейти к бизнес логике не получится. Нужно изучить, понять и переосмыслить много моментов. Возможно в моем случаем это был результат работы многих лет с блокирующим АПИ. Не знаю. Но я до сих узнаю что-то новое о нетти.
Часто во время работы с нетти возникает необходимость заглянуть внутрь готовых обработчиков, чтобы понять как они работают. Но довольно большая и сложная иерархия наследования очень сильно усложняет понимание кода. Не знаю как у вас, но в случае если у класса иерархия больше 3-х уровней вложенности, то у меня переполняется мой и так не большой стек. Нетти вся пропитана этой сложной иерархией. В дополнение ко все всему у нетти есть свой отдельный пакет с 4-мя разными типами буферов, которые использует сама нетти.
Поначалу с нетти очень просто выстрелить себе в ногу. Небольшой пример:
Оказывается в 4-й netty (я начинал с 3-й) по дефолту используются direct буфера, поэтому за буферами надо хорошенько следить. Проблема утечек в netty вообще стоит очень остро. Как подтверждение — в нетти есть решение которое позволяет отслеживать утечки внутри фреймворка. Хотя если вы будете использовать готовые хендлеры (то есть используете готовые протоколы HTTP, MQTT, SPDY, ...), то Вы с этим не столкнетесь.
Благодаря своей популярности, в нетти довольно часто находят разного рода баги. Сейчас на гитхабе открыто около 280 тикетов. Я лично столкнулся с 2-мя, которые пришлось заводить. К счастью, с фиксами все происходит очень быстро.
Теперь о хорошем.
С нетти у вас есть абсолютно полный контроль над сетевым стеком. И это круто. Потому что у Вас есть возможность работать в абстракциях фреймворка при этом избегая всей сложности прямой работы с сокетами. Помимо этого у нетти из коробки есть куча фич, которых в принципе на рынке никто не предлагает, например возможность включать TCP_FASTOPEN, TCP_MD5SIG, TCP_CORK, SPLICE, поддержку нативного Epoll транспорта, OpenSSL и кучу других штук. И все это работает из коробки!
TCP, UDP, UDT, SCTP? Легко. HTTP, HTTPS, HTTP/2, SPDY, Memcached, MQTT? Уже есть. Подключить любой из этих протоколов вопрос нескольких десятков минут. И все это уже давно написано, оптимизировано и протестировано. Интересный момент с HTTP/2. Его добавили в нетти уже около 3-х месяцев назад. В nginx например его поддержка появилась буквально 2 недели назад. Я думаю это о многом говорит.
Нужно добавить SSL? Пожалуйста — SslHandler. Нужно сжимать весь трафик? Выбирайте любой — JdkZlibEncoder, ZlibEncoder, SnappyFramedEncoder. Нужно парсить джейсон на ходу? — JsonObjectDecoder. Нужно закрывать неактивные сокеты? Пожалуйста — ReadTimeoutHandler. Нужно полностью вычитать из сокета данные и только потом передать управление в бизнес логику? — ну вы поняли…
100к рек-сек на ядро для простейшего HTTP GET? С нетти это действительно так.

В основном благодаря тому факту, что она используется в таких монстрах как Facebook, Twitter, поэтому оптимизациям в нетти уделяется очень много внимания. Еще один немаловажный фактор почему нетти быстрая — это использования direct буферов, что очень сильно снижает нагрузку на GC. При этом всю сложность управления этими буферами берет на себя нетти.
Еще одна из причин, почему нетти довольна быстрая — это ее асинхронная природа, а значит фактически полное отсутствие блокировок внутри обработчиков IO операций (workers) и отсутствие потерь при переключении контекста между потоками. Сама природа нетти вынуждает Вас писать код, которые должен быть потокобезопасным. Конечно полностью избежать синхронизаций у Вас вряд ли получится, но ниже я расскажу, как этого максимально избежать.
Завести тикет и получить ответ в течении часа — норма для нетти. Это очень классно и сильно помогает в разработке. Особенно на фоне недостаточной документации. Вообще, обсудить любой вопрос об архитектуре, производительности или мелком рефакторинге — совершенно не проблема для разработчиков.
Продолжение следует…
Итак, поехали.
Все началось около 2-х лет назад, когда мне подарили arduino. Я всегда мечтал сделать какое-то интересное устройство своими руками. Но все эти паяльники, резисторы, вольты-амперы меня постоянно отпугивали. Так было, пока не появились arduino. С ардуиной я смог наконец-то управлять электроникой. Сказать, что это было очень круто — не сказать ничего. Я был счастлив. Но, как это часто бывает, после освоения базовых навыков в микроконтроллерах, захотелось большего — управлять устройствами через интернет с телефона. Быстрый гуглинг показал (дело было 2 года назад), что на текущий момент нет ни одного решения, которое бы решало эту задачу. Не считая IoT облака с HTTP API, которые было не очень удобно использовать.
К счастью, я не был один. Совершенно случайно, на своей работе, я познакомился с людьми, которых волновали те же проблемы. Так появился наш проект.
Проблема
Отдаленно задача была ясна — управлять ардуиной через интернет с мобильного или планшета. Ну например, чтобы иметь возможность менять цвет юбки ниже.

На том этапе каких-то более понятных и четких требований банально не было. После недолгих обсуждений и анализа — мы обрисовали себе несколько важных пунктов, которые должна была бы обеспечивать архитектура проекта:
Много параллельных соединений
Я не считаю себя гиком. Но уже тогда у меня было 2 ардуинки, 2 телефона и планшет, которые я бы хотел использовать для управления. Небольшой опрос среди знакомых показал, что у среднего хардварщика 3-4 микроконтроллера. Стало вполне очевидно, что один потенциальный пользователь нашей системы с легкостью может открывать 5-10 соединений с разных устройств. То есть сервер должен одновременно обрабатывать тысячи параллельных соединений даже для нескольких сотен пользователей.
Pushing / Polling
Не смотря на свой небольшой опыт работы с микроконтроллерами, было очевидно что серверное решение должно поддерживать 2 режима работы клиентов — pushing и polling. То есть мобильный клиент должен иметь возможность запросить с железки состояние и железка со своей стороны должна иметь возможность в любой момент послать сообщение, а мобильный клиент его получить.
Поддержка разных протоколов
Выбрать протокол было трудно. Очень хотелось пойти старой протоптанной дорожкой — HTTP. Но у HTTP есть несколько архитектурных проблем. Минимально возможный пакет — 26 байт (без учета TCP/IP заголовков), но в реальной жизни минимальный пакет будет не меньше 50 байт, а учитывая слабые возможности микроконтроллеров (у Arduino UNO например 2кб RAM и 16 MHz процессора) и недолгую жизнь элементов питания это показалось излишним. Ну и если с полингом у http все хорошо, то с пушингом нужны уже web-scokets, а это по сути старый добрый TCP/IP. В среде хардварщиков очень популярен протокол MQTT. Но от него я тоже отказался. Он показался мне слишком мудренным. Да, его продумывали на все случаи жизни. Но тогда нам это было не нужно. Поэтому сервер должен был поддерживать как минимум несколько протоколов, чтобы мы могли переключится на нужный в случае, если бы наш выбор оказался не верным.
Простота
Так как проект изначально мы делали для себя, то одним из главных условий была простота настройки и деплоймента. Так, чтобы даже совершенно новый человек, без каких-либо навыков, смог бы с легкостью и в течении нескольких минут начать управлять свой железкой и в случае необходимости мог бы точно так же просто и безболезненно развернуть у себя сервер.
Выбираем решение
Немного поразмыслив, было принято решение об использовании асинхронных сокетов. Я руководствовался 2-мя факторами. Нужно обрабатывать много параллельных соединений, с чем блокирующие сокеты не очень хорошо справляются в виду большого стека (256кб) в яве и затрат на переключение контекста между потоками. Бизнес логики будет немного. Ведь всего лишь нужно переслать сообщение с одного сокета на другой (ну кто не ошибается). Все работа сервера по сути сводится к «взять сообщение из сокета А» и «послать сообщение в сокет Б» + немного бизнес логики сверху.
Что на рынке?
Быстрый анализ существующих решений показал следующее:
- Apache MINA — мертвый проект, который не развивается уже года 4.
- Grizzly — Я его отбросил так как я не нашел проектов, которые его используют.
- Xnio — отбросил по причине 60-ти звезд на гитхабе. И те, судя по всему разработчики.
- Vert.x — на тот момент позиционировался как прямой конкурент Netty. И тогда у него было то ли закрытое то ли платное ядро. Дело было 2 года назад и я уже подзабыл детали. Сейчас ситуация поменялась. Так что может имеет смысл опять присмотреться.
- Akka — очень интересная штука. И вполне годное решение, отдал предпочтение netty по простой причине — на netty построить Akka можно, а на Akke netty — нет. Ну и сам факт того что распределенные акторы в Акке используют нетти, как бы намекает. Ну и netty используют тысячи проектов по всему миру включая фейсбук, линкедин и твиттер.
- Netty — выбор очевиден

Недостатки Netty
Вот уже как 2 года я работаю с нетти. И мне есть что сказать. Начну с минусов.
Плохая документация
Есть отличный getting started и вроде как все хорошо. Но как только начинаешь делать шаг влево, шаг вправо, сразу возникают десятки вопросов. Ответов на которые в документации нету и ответы на которые разбросаны по всему интернету. Сейчас ситуация гораздо лучше, чем была 2 года назад. Но проблема все еще остается.
Сложность
Как асинхронный фреймворк — нетти упрощает работу с асинхронными сокетами. Но все-таки с наскоку сразу перейти к бизнес логике не получится. Нужно изучить, понять и переосмыслить много моментов. Возможно в моем случаем это был результат работы многих лет с блокирующим АПИ. Не знаю. Но я до сих узнаю что-то новое о нетти.
Слишком много абстракций
Часто во время работы с нетти возникает необходимость заглянуть внутрь готовых обработчиков, чтобы понять как они работают. Но довольно большая и сложная иерархия наследования очень сильно усложняет понимание кода. Не знаю как у вас, но в случае если у класса иерархия больше 3-х уровней вложенности, то у меня переполняется мой и так не большой стек. Нетти вся пропитана этой сложной иерархией. В дополнение ко все всему у нетти есть свой отдельный пакет с 4-мя разными типами буферов, которые использует сама нетти.
Легко выстрелить в ногу
Поначалу с нетти очень просто выстрелить себе в ногу. Небольшой пример:
ByteBuf in ...
in.readBytes(length); // утечка памяти
ByteBuf in ...
in.readSlice(length); // все ок
Оказывается в 4-й netty (я начинал с 3-й) по дефолту используются direct буфера, поэтому за буферами надо хорошенько следить. Проблема утечек в netty вообще стоит очень остро. Как подтверждение — в нетти есть решение которое позволяет отслеживать утечки внутри фреймворка. Хотя если вы будете использовать готовые хендлеры (то есть используете готовые протоколы HTTP, MQTT, SPDY, ...), то Вы с этим не столкнетесь.
До сих пор есть баги
Благодаря своей популярности, в нетти довольно часто находят разного рода баги. Сейчас на гитхабе открыто около 280 тикетов. Я лично столкнулся с 2-мя, которые пришлось заводить. К счастью, с фиксами все происходит очень быстро.
Плюсы Netty
Теперь о хорошем.
Полный контроль
С нетти у вас есть абсолютно полный контроль над сетевым стеком. И это круто. Потому что у Вас есть возможность работать в абстракциях фреймворка при этом избегая всей сложности прямой работы с сокетами. Помимо этого у нетти из коробки есть куча фич, которых в принципе на рынке никто не предлагает, например возможность включать TCP_FASTOPEN, TCP_MD5SIG, TCP_CORK, SPLICE, поддержку нативного Epoll транспорта, OpenSSL и кучу других штук. И все это работает из коробки!
Поддержка разных протоколов
TCP, UDP, UDT, SCTP? Легко. HTTP, HTTPS, HTTP/2, SPDY, Memcached, MQTT? Уже есть. Подключить любой из этих протоколов вопрос нескольких десятков минут. И все это уже давно написано, оптимизировано и протестировано. Интересный момент с HTTP/2. Его добавили в нетти уже около 3-х месяцев назад. В nginx например его поддержка появилась буквально 2 недели назад. Я думаю это о многом говорит.
Много готовых обработчиков
Нужно добавить SSL? Пожалуйста — SslHandler. Нужно сжимать весь трафик? Выбирайте любой — JdkZlibEncoder, ZlibEncoder, SnappyFramedEncoder. Нужно парсить джейсон на ходу? — JsonObjectDecoder. Нужно закрывать неактивные сокеты? Пожалуйста — ReadTimeoutHandler. Нужно полностью вычитать из сокета данные и только потом передать управление в бизнес логику? — ну вы поняли…
Быстрая
100к рек-сек на ядро для простейшего HTTP GET? С нетти это действительно так.

В основном благодаря тому факту, что она используется в таких монстрах как Facebook, Twitter, поэтому оптимизациям в нетти уделяется очень много внимания. Еще один немаловажный фактор почему нетти быстрая — это использования direct буферов, что очень сильно снижает нагрузку на GC. При этом всю сложность управления этими буферами берет на себя нетти.
Нет synchronize
Еще одна из причин, почему нетти довольна быстрая — это ее асинхронная природа, а значит фактически полное отсутствие блокировок внутри обработчиков IO операций (workers) и отсутствие потерь при переключении контекста между потоками. Сама природа нетти вынуждает Вас писать код, которые должен быть потокобезопасным. Конечно полностью избежать синхронизаций у Вас вряд ли получится, но ниже я расскажу, как этого максимально избежать.
Отличное сообщество
Завести тикет и получить ответ в течении часа — норма для нетти. Это очень классно и сильно помогает в разработке. Особенно на фоне недостаточной документации. Вообще, обсудить любой вопрос об архитектуре, производительности или мелком рефакторинге — совершенно не проблема для разработчиков.
Продолжение следует…
