Сегодня я хочу рассказать вам о проекте, над которым я работал (и продолжаю работать) в Evernote с 2008 года, и которое несколько дней назад стало Свободным ПО.

Для многих разработчиков локализация ассоциируется с дополнительным пластом проблем: как поддерживать локализованные ресурсы в актуальном состоянии? А что если языков не 2-3, а 20-30? Как вовремя отправлять новые строки на перевод? А что если во время перевода разработка ушла вперед, и каких-то строк уже нет, а есть новые? Как мержить присланные переводчиками файлы ресурсов? Не секрет, что из-за этого многие просто забивают на локализацию или стараются отложить ее на потом.
Сейчас у Evernote более 150 млн пользователей по всему миру, более 70% этих пользователей находятся за пределами США, каждый месяц мы переводим по 15 тыс. новых слов в 40 с лишним проектах на более чем 26 языков, и выпускаем новые релизы наших продуктов одновременно на всех языках. При этом на техническую поддержку всей этой системы требуется один человек, и то изредка.
Когда сервис Evernote только начинал развиваться, у нас было большое желание делать компанию международной с самого начала. Это требовало оперативной локализации приложений Evernote подо все платформы на большой перечень языков. И при этом мы хотели сделать этот процесс максимально прозрачным для разработчиков. Поэтому в 2008 году, мы начали создавать платформу, которая бы упростила и автоматизировала процесс локализации, сделала бы этот процесс непрерывным.
И вот семь лет спустя эта платформа, которую мы назвали Serge (String Extraction and Resource Generation Engine), стала доступной для каждого.
Serge позволяет настроить процесс, при котором строки, будучи закоммиченными в систему контроля версий, автоматически извлекаются и отправляются на перевод, а переводы автоматически интегрируются в локализованные файлы ресурсов и автоматически же попадают в систему контроля версий. Serge избавляет разработчиков от необходимости работать с локализованным файлами вообще (их забота — править только исходные ресурсы, например, английские), он избавляет переводчиков (или ваше локализационное агентство) от необходимости возиться с разными форматами файлов. Serge может быть интегрирован в любой процесс локализации — с помощью платных переводчиков или волонтеров, онлайновый или офлайновый.
Serge — это приложение командной строки, которое принимает в качестве входного параметра команду и один или несколько конфигурационных файлов. Каждый конфигурационный файл описывает один проект локализации (с каким удаленным репозиторием синхронизироваться, как общаться с сервером переводов, в какой локальной директории и по какой маске сканировать файлы, каким парсером их обрабатывать, как именовать файлы, отправляемые на перевод, где и в какой кодировке создавать локализованные файлы, какие дополнительные плагины использовать и т.д.).
Вот что происходит, когда Serge запускает команду sync для каждого конфигурационного файла:
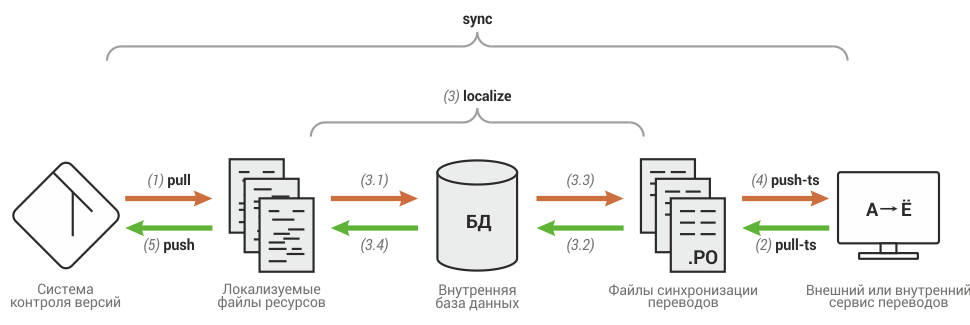
Непрерывная локализация достигается тем, что как только Serge проходит этот цикл для каждого конфигурационного файла, цикл можно запускать снова. В случае с Evernote весь цикл по всем проектам занимает порядка 15 минут. Это значит, что как только инженер закоммитил какое-то изменение в файл ресурсов, в течение 15 минут приходит коммит от локализационного робота, симметрично меняющий все локализованные копии этого ресурса; когда переводчик добавляет перевод или изменяет существующий, в течение 15 минут его изменение коммитится в репозиторий. Эти изменения вызывают запуск CI-билда и последующее автоматическое тестирование, что позволяет максимально быстро выявлять ошибки, связанные с интернационализацией и локализацией, осуществлять перевод параллельно с разработкой продукта.
Архитектура Serge построена на плагинах. Serge поддерживает несколько видов систем контроля версий, более 20 форматов файлов, а также плагины, меняющие поведение системы (например, пре- и постпроцессинг локализованных файлов, возможность задавать список языков для перевода прямо в файле и т.д.). На сайте Serge находится документация по продукту, плагинам, установке и настройке.
Мы очень надеемся, что открытие исходников Serge позволит как индивидуальным разработчикам, так и большим компаниям, по-новому взглянуть на процесс локализации и тесно интегрировать локализацию в цикл разработки. Ну и, разумеется, будем рады комментариям, пожеланиям и сообщениям об ошибках.
Локализация — это просто!

Для многих разработчиков локализация ассоциируется с дополнительным пластом проблем: как поддерживать локализованные ресурсы в актуальном состоянии? А что если языков не 2-3, а 20-30? Как вовремя отправлять новые строки на перевод? А что если во время перевода разработка ушла вперед, и каких-то строк уже нет, а есть новые? Как мержить присланные переводчиками файлы ресурсов? Не секрет, что из-за этого многие просто забивают на локализацию или стараются отложить ее на потом.
Сейчас у Evernote более 150 млн пользователей по всему миру, более 70% этих пользователей находятся за пределами США, каждый месяц мы переводим по 15 тыс. новых слов в 40 с лишним проектах на более чем 26 языков, и выпускаем новые релизы наших продуктов одновременно на всех языках. При этом на техническую поддержку всей этой системы требуется один человек, и то изредка.
Как нам это удается?
Когда сервис Evernote только начинал развиваться, у нас было большое желание делать компанию международной с самого начала. Это требовало оперативной локализации приложений Evernote подо все платформы на большой перечень языков. И при этом мы хотели сделать этот процесс максимально прозрачным для разработчиков. Поэтому в 2008 году, мы начали создавать платформу, которая бы упростила и автоматизировала процесс локализации, сделала бы этот процесс непрерывным.
И вот семь лет спустя эта платформа, которую мы назвали Serge (String Extraction and Resource Generation Engine), стала доступной для каждого.
Serge позволяет настроить процесс, при котором строки, будучи закоммиченными в систему контроля версий, автоматически извлекаются и отправляются на перевод, а переводы автоматически интегрируются в локализованные файлы ресурсов и автоматически же попадают в систему контроля версий. Serge избавляет разработчиков от необходимости работать с локализованным файлами вообще (их забота — править только исходные ресурсы, например, английские), он избавляет переводчиков (или ваше локализационное агентство) от необходимости возиться с разными форматами файлов. Serge может быть интегрирован в любой процесс локализации — с помощью платных переводчиков или волонтеров, онлайновый или офлайновый.
Как эта штука работает?
Serge — это приложение командной строки, которое принимает в качестве входного параметра команду и один или несколько конфигурационных файлов. Каждый конфигурационный файл описывает один проект локализации (с каким удаленным репозиторием синхронизироваться, как общаться с сервером переводов, в какой локальной директории и по какой маске сканировать файлы, каким парсером их обрабатывать, как именовать файлы, отправляемые на перевод, где и в какой кодировке создавать локализованные файлы, какие дополнительные плагины использовать и т.д.).
Вот что происходит, когда Serge запускает команду sync для каждого конфигурационного файла:
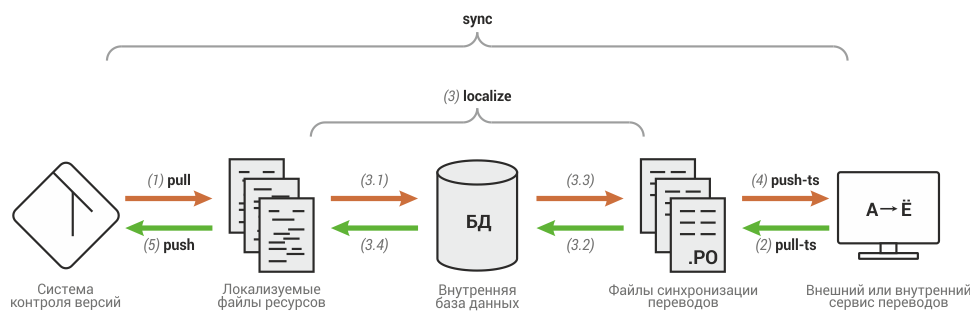
- (pull) выкачиваются изменения из удаленного репозитория с файлами ресурсов;
- (pull-ts) выкачиваются переводы из сервера переводов (обновляются локальные файлы);
- (localize) происходит, собственно, локализация:
- файлы ресурсов парсятся; сведения о файлах и строках попадают во внутреннюю базу;
- файлы с переводами парсятся; переводы попадают во внутреннюю базу;
- файлы с переводами обновляются в соответствии с изменившейся структурой исходных файлов ресурсов;
- файлы ресурсов обновляются в соответствии с изменениями в переводах;
- (push-ts) обновленные файлы с переводами выгружаются на сервер переводов;
- (push) обновленные локализованные файлы ресурсов выгружаются во внешний репозиторий.
Непрерывная локализация достигается тем, что как только Serge проходит этот цикл для каждого конфигурационного файла, цикл можно запускать снова. В случае с Evernote весь цикл по всем проектам занимает порядка 15 минут. Это значит, что как только инженер закоммитил какое-то изменение в файл ресурсов, в течение 15 минут приходит коммит от локализационного робота, симметрично меняющий все локализованные копии этого ресурса; когда переводчик добавляет перевод или изменяет существующий, в течение 15 минут его изменение коммитится в репозиторий. Эти изменения вызывают запуск CI-билда и последующее автоматическое тестирование, что позволяет максимально быстро выявлять ошибки, связанные с интернационализацией и локализацией, осуществлять перевод параллельно с разработкой продукта.
Архитектура Serge построена на плагинах. Serge поддерживает несколько видов систем контроля версий, более 20 форматов файлов, а также плагины, меняющие поведение системы (например, пре- и постпроцессинг локализованных файлов, возможность задавать список языков для перевода прямо в файле и т.д.). На сайте Serge находится документация по продукту, плагинам, установке и настройке.
Мы очень надеемся, что открытие исходников Serge позволит как индивидуальным разработчикам, так и большим компаниям, по-новому взглянуть на процесс локализации и тесно интегрировать локализацию в цикл разработки. Ну и, разумеется, будем рады комментариям, пожеланиям и сообщениям об ошибках.
Локализация — это просто!
