
Сегодня мы продолжаем серию публикаций мастер-классов наших образовательных проектов и представляем вашему вниманию пост по мотивам выступлений Дмитрия Склярова, которые он провел в Техносфере и Технотреке. Тема выступления — Digital Rights Management. Видео выступления смотрите на IT.MAIL.RU, а текст — далее.
Идея этого выступления выросла из доклада, который я читал на конференции DEFCON в 2001 г., после чего у меня и у компании, в которой я работал (ElcomSoft), возникли некоторые юридические сложности. Через 1,5 года после данного выступления в США состоялся суд, в результате которого компанию признали невиновной по всем пяти пунктам обвинения, но история была достаточно громкой. Спустя годы я решил сделать новую версию того доклада, добавив информацию о новых тенденциях в сфере Digital Rights Management (DRM).
Расскажу, как возникла идея DRM. Все началось с бытового видеомагнитофона системы Betamax, который компания Sony выпустила на рынок в 1975 г. Он стал первым устройством, позволяющим самостоятельно записывать телевизионный эфир для последующего просмотра. А в 1976 г. Sony получила судебный иск от Universal Studios и The Walt Disney Company, в котором говорилось, что использование технологий бытовой видеозаписи нарушает авторские права. То есть я могу записать фильм с телевизора, и после этого, например, продать его или дать посмотреть кому-нибудь, кто никакого отношения к телевидению не имеет, или что-то в этом роде. Значит, компания Sony заранее виновна в том, что создала такое устройство, и подобные устройства надо следует запретить.

Суд первой инстанции решил, что этот иск не имеет смысла, так как нельзя запретить пользователям просматривать передачи в удобное для них время, предварительно их записав. Но апелляционный суд согласился с тем, что распространение видеомагнитофонов является нарушением авторского права. При этом общественность активно возражала против подобного решения, приводя в качестве аргумента следующее сравнение: производить оружие — законно, а производить видеомагнитофоны — почему-то является нарушением закона. Слава богу, судебная система успела вовремя одуматься, и в последней инстанции, в Верховном суде, было принято решение, что запись телепрограмм для частного просмотра не нарушает авторские права, что это так называемый Fair Use — концепция, закрепленная в законодательных актах США. То есть человек имеет право смотреть то, что ему вещают, тогда, когда он захочет, и так, как он захочет. Это была маленькая победа. Забавно, что в 1984 г. судебный процесс был выигран, а в 1989 г. компания Sony купила киностудию Columbia Pictures и сама стала правообладателем, начав производить фильмы, которые можно было копировать с помощью ее технологий.
Производители контента в итоге смирились с существованием видеомагнитофонов. Главным аргументом стало то, что при перезаписи аналогового изображения происходит потеря качества. То есть нельзя переписать одну видеокассету на другую 100 раз по очереди (с первой на вторую, со второй на третью и т.д.), потому что уже через несколько итераций смотреть это будет невозможно.

В 1982 г. на рынок вышел первый цифровой потребительский продукт — компакт-диски, которые можно было слушать в специальных плеерах. Они имели очень простую внутреннюю организацию, весьма простой формат записи без какого-либо сжатия, 16-битный стереоканал и частоту дискретизации 44,1 КГц. В этот раз первопроходцами стали Sony и Phillips.

Спустя пять лет после компакт-диска на рынок был выведен следующий носитель, предназначенный для цифровой записи звука, — Digital Audio Tape. Для них производились студийные магнитофоны и персональные плееры, которые позволяли воспроизводить ленты в этом формате. Главная особенность данных кассет заключалась в сохранении качества при перезаписи. Но разработчики, учтя полученный с видеоформатами опыт, заложили частоту дискретизации не 44 КГц, а 48 КГц. Вроде бы цель благая — повысить качество звука. Но если вы попытаетесь переписать компакт-диск на Digital Audio Tape, то не сможете этого сделать без цифро-аналогового и аналого-цифрового преобразования, то есть без потери качества. На самом деле, в спецификации была введена поддержка 44,1 КГц, но с ограничениями. Заключались они в том, что если у вас появится кассета, которую кто-то записал на частоте 44,1 КГц, то есть на частоте компакт-диска, вы сможете ее воспроизвести, но самостоятельно записать такую кассету уже не удастся.
Дальнейшая эволюция привела к тому, что возможность переписывать компакт-диск на цифровую магнитную ленту с частотой дискретизации 44,1 КГц все-таки появилась, но переписать данные после этого на другую ленту уже нельзя. То есть с 48 КГц на 48 КГц переписать можно, а с 44 КГц на 44 КГц — увы. Таким образом ограничивалось тиражирование компакт-дисков на магнитные ленты. Это стало одним из первых публичных проявлений DRM, то есть осуществилось управление цифровым контентом с запретом на проведение ряда операций.
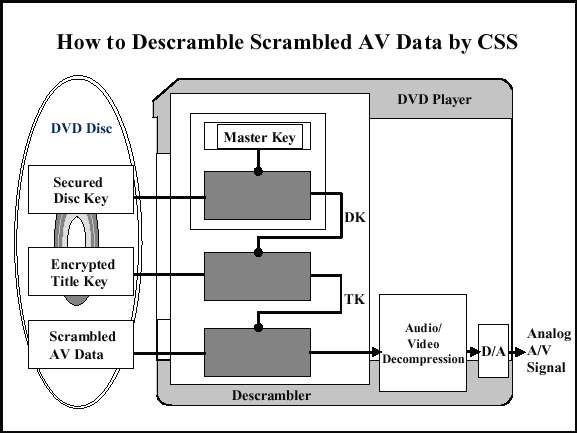
Широко известна история с попытками защитить контент на DVD-дисках. В 1996 г. компания Sony предложила рынку DVD. На этапе проектирования была заложена возможность управлять, кто сможет смотреть диск, а кто нет. Для этого мир поделили на семь регионов — семь зон. Диск и плеер должны быть выпущены для одной зоны — в этом случае на данном плеере можно воспроизвести данный диск. При не совпадении зон просмотр диска будет невозможен. Мотивация была такая: есть страны с низким доходом населения, а есть богатые Америка и Европа. Американцы могут позволить себе покупать диск за $12, а африканцы нет. Поэтому африканцам будем продавать диски за $6, но смотреть их можно только на плеерах, которые продаются в Африке. Понятно, что африканские плееры не получится массово привезти в Америку, а диск, купленный в Африке, на американском плеере воспроизводиться не будет. Также была предусмотрена защита от копирования DVD-дисков.
Вообще, копирование с диска на диск стало широко применяться с удешевлением и увеличением количества пишущих приводов. В 1994 г. я имел опыт общения с пишущим CD-приводом, который стоил тогда $1 тыс., а одна болванка к нему — $35. При этом около половины болванок портились приводом при записи. То есть чтобы записать один диск потребуется $70. Понятно, что гораздо дешевле покупать оригинальные лицензионные CD, чем пытаться их копировать в домашних условиях. Но когда стоимость болванки упала до 10 центов, а приводы до $40, вопросы бытового копирования стали насущными.
В 1996 г. на рынок были выпущены DVD с системой защиты Content Scrambling System, а уже в 1997 г. разработали программу DeCSS. Точная информация о том, кто, как и когда ее разработал, отсутствует, есть лишь догадки, что путем анализа программной реализации плеера XingDVD были получены алгоритм и ключи, необходимые для ее работы. То есть пока DVD-проигрыватели были только аппаратными, проанализировать их было сложно и дорого, поэтому никто этого не делал. Но как только появилась программная реализация, все стало достаточно просто — вы садитесь с отладчиком и дизассемблером, выясняете, как работает программа, что происходит внутри, в итоге выстраиваете точно такой же алгоритм, как в этом плеере. Данный алгоритм был извлечен и опубликован в интернете. Видеокомпании предприняли попытки запретить публикацию самого текста алгоритма, программ, которые его реализуют, а также ссылки на них. Случился небольшой скандал с изданием alt.2600, в адрес которого был направлен судебный запрет на публикацию ссылки на страницу, где можно было ознакомиться с алгоритмом. Разумеется, пользователи начали протестовать против запрета на распространение программ только потому, что кому-то так захотелось. В результате дошло до того, что тексты DeCSS стали печатать на футболках. Также была написана очень оригинальная реализация — программа на языке Perl, которая занимается расшифровкой контента DVD-диска. Всего в несколько строк люди ухитрились вместить все, что для этого нужно. Говорят, работает, хотя я не пробовал.
С момента появления технологии защиты до ее взлома прошел всего год. Как только какой-то продукт выходит на массовый рынок, его вскоре начинают исследовать, и рано или поздно находят способы обойти эту защиту.
Я занялся электронными книгами примерно в 1999 г. Параллельно писал диссертацию «Метод анализа программных средств защиты электронных документов». Cтал смотреть, какие технологии существуют на рынке и насколько тяжело их скомпрометировать.
Немного о том, как работает электронное издательство и чем оно отличается от традиционного. Когда мы говорим о публикации обыкновенной бумажной книги, то понимаем, что процесс это очень долгий: сначала автор должен написать книгу (от руки или на компьютере). Затем машинистка наберет 300 или 400 страниц текста за достаточно короткое время. После того, как текст переведен в электронный вид, нужно сверстать страницы, чтобы посмотреть, как они будут выглядеть на печати. Когда-то это делалось руками: в специальный ящик вставляли свинцовые буковки, смазывали их краской, а затем делали оттиск страницы. Потом это стали делать механические полуавтоматы, а верстальщик просто набирал текст кнопками. Сейчас же все делается на компьютере. После этого изображения сверстанных страниц выводятся на пленку и отдаются в печать. Возможно, сейчас уже есть типографии, которые печатают достаточно большие тиражи без промежуточного этапа с пленками — сразу с электронного макета.
После того, как бумажные листы будут отпечатаны, их необходимо нарезать, сброшюровать, сшить и приклеить обложку. Дальше нужно решить вопросы логистики, чтобы продукция добралась сначала до склада, а затем до магазинов, куда придет человек, найдет на полке интересующую его книгу и купит ее. Так было на протяжении последних лет 200, сколько существует активное книгопечатание и книготорговля.
Что изменилось с переходом на электронные издания? Первые два этапа остались те же: написать книгу, затем сверстать. Но зато потом можно буквально нажатием одной кнопки сделать так, чтобы эта книга оказалась в устройстве для чтения — в ридере. Тем самым исключается несколько дорогостоящих этапов: печать, логистика, оплата торговых площадей, оплата труда работников на каждом этапе. Казалось бы, электронная книга должна очень сильно подешеветь для конечного пользователя. Я сам, например, являюсь автором одной книги, и по договору получал, если не ошибаюсь, 12% от оптовой стоимости каждого экземпляра. Плюс магазин еще примерно 100% накручивал и выпускал книгу в продажу. То есть доля авторских отчислений в общей стоимости книги невелика, в основном цена складывается из себестоимости сырья, зарплат и накладных расходов.
У электронных книг масса достоинств по сравнению с бумажными. Их гораздо дешевле изготавливать, а также можно неограниченно тиражировать. Написанная мной книга выпускалась тремя тиражами по 3 тыс. экземпляров, и сейчас купить ее в магазинах уже нельзя. Правда, в сети есть отсканированная копия, и недавно начали более-менее официально торговать через Ozon электронной версией книги.
Также электронные книги быстрее попадают к читателям. Можно в одном ридере носить хоть всю энциклопедию «Британика», бумажная версия которой состоит из 50 томов. Электронные книги позволяют быстро найти нужный текст, они не изнашиваются, в них можно реализовывать механизмы навигации типа гиперссылок, вставлять мультимедиа-объекты, анимацию, звук — красота, удобство и радость как для тех, кто хочет доставить свой контент потребителям, так и для тех, кто этот контент потребляет.
Но наряду с достоинствами электронные книги имеют и недостатки. Во-первых, формат часто связан с типом ридера — то есть то, что может быть прочитано на одном ридере, на другом может быть нечитаемым (но данную проблему можно решить с помощью специального ПО — путем конвертирования в другие форматы). Во-вторых, и это самая главная проблема электронных книг, здесь навязан контроль соблюдения авторских прав. Если я хочу растиражировать бумажную книгу, то мне нужно отсканировать каждую страницу, напечатать, потом как-то сшить, приклеить обложку, и только тогда я смогу ее отдать или продать. Стоимость копии окажется высокой, наверняка даже дороже оригинала, если мы говорим о сопоставимом качестве. А электронная книга — это просто файл, который можно рассылать миллионами экземпляров. И вот уже правообладатель потерял контроль над распространением, все читают, а никто не платит деньги. Это самая большая страшилка для правообладателей, которые хотят заработать как можно больше денег. Их тоже можно понять. В итоге стали появляться технологии защиты электронных книг, которые можно читать, но при этом накладываются ограничения на некоторые операции.
Рынок электронных книг по состоянию на 2000 г. можно грубо поделить на три категории.
Несколько лет назад приятель моего начальника, сам занимающийся изданием каких-то учебных материалов, захотел защитить эти материалы. В сети он наткнулся на программу eBook Pro Compiler, которая позиционировала себя как (вольный перевод с английского языка) «Единственное ПО во Вселенной, которое делает вашу информацию практически 100%-но защищенной от взлома, идет с пожизненной гарантией возврата денег, если вам что-то не понравится. Наконец, вы можете продавать информацию онлайн и делать тысячи продаж ежедневно без опасности того, что ваша информация будет украдена или продана другими». То есть было заявлено, что данная программа является самым крутым в мире решением для издателей. Но чтобы продавать тысячи копий в день, нужно иметь настолько хороший контент, чтобы тысячи людей в день захотели его купить. Если вас зовут Дарья Донцова, то у вас есть шанс написать такую книгу, которую за первую пару месяцев будет покупать тысяча людей в день. Если же вы пишете научный учебник, то, продав всего 10 тыс. копий, можно сказать, что вам повезло, так как умные книги у нас особым спросом, к сожалению, не пользуются.
Поверив рекламе, приятель моего начальника купил эту программу. Оказалось, что открыв скомпилированную «защищенную» книгу, с помощью комбинаций Ctrl+A и Ctrl+Insert можно в буфере обмена получить весь контент текущей страницы, вставить его в Word, и вот вы украли контент. Также можно было зайти в директорию Temp и там найти все HTML-странички и картинки как они были до того, как вы скомпилировали книгу. Причем они так и будут лежать во временной директории, потому что компилятор для просмотра электронных книг использовал движок Internet Explorer. И разработчики даже не удосужились реализовать механизм хранения исходных данных в памяти, а не на диске. То есть они их просто выгружали на диск и говорили IE: «Покажи нам эти файлы с диска». Совершенно детская реализация процесса работы с защищенным контентом. Я немножко покопался с отладчиком-дизассемблером и понял, как устроен формат. Все данные, из которых состоит книга (картинки, CSS, HTML), упаковываются в контейнер, из которого потом извлекаются в момент показа. Для упаковки используется бесплатная и открытая библиотека Zlib, а сами данные шифруются очень интересным алгоритмом: на каждый байт зашифрованных данных последовательно накладываются все байты слова «encrypted» с помощью операции XOR. Люди, которые это писали, не только ничего не понимают в криптографии, но и вообще не представляют, как работает XOR. Ведь XOR последовательно с разными байтами можно свести к XOR с одним байтом. То есть они весь контент ксорили с одной однобайтовой константой. Никакой защиты это не обеспечивает, но тем не менее спокойно утверждали обратное.
Про все системы создания электронных книг, которые я упоминал ранее, я не скажу, но думаю, что добрая половина из них была устроена примерно так же. Сфере защиты контента присуща одна особенность. Например, в качестве графического редактора вы используете Photoshop и сравниваете его с Gimp. В каких-то операциях Photoshop работает гораздо лучше или гораздо хуже — неважно. Вы на глаз видите разницу. Входные данные одни и те же, а результат разный. Но когда вы что-то защищаете, зашифровываете, то невозможно оценить результат «на глаз». Как понять, хорошая защита или плохая? Можно это взломать или нельзя, легко ли это или трудно? О том, что вас взломали, вы узнаете только тогда, когда это случится. А степень легкости взлома оценить адекватно вы не сможете, если не разбираетесь в технологиях информационной защиты. Поэтому плохих решений на рынке, к сожалению, было всегда много, они никуда не денутся и будут успешно продаваться, потому что продать хорошее решение без красивой обертки гораздо труднее, чем продать плохое решение в красивой обертке. Если у вас есть рекламный бюджет — вы на коне, и ваши продукты в сфере безопасности будут покупать независимо от их качества.
Особое внимание в своем исследовании я уделял PDF-файлам. Я изучал их устройство, заложенные в них механизмы обеспечения безопасности контента. На тот момент объем спецификации PDF составлял около 600 страниц, из которых 20—30 страниц касались безопасности и представляли самый большой интерес. С тех пор спецификация много раз переписывалась, и последние версии поддерживает, если не ошибаюсь, не Adobe, а какой-то из подкомитетов ISO. То есть PDF пытаются сделать международным стандартом. При проектировании этого формата (Portable Document Format) одной из главных задач было обеспечение одинакового отображения на всех устройствах. Почему это так важно? Наверняка вы оказывались в ситуации, когда, создавая сложный документ в Word на одном компьютере, а печатая на другом, оказывалось, что верстка «поплыла», картинки не помещаются и т.д. Причина в том, что Microsoft Word — это не издательская система, а система подготовки текстов, не предназначенная для создания полноценных макетов для печати.
PDF проектировался как более компактный, чем Postscript, формат, способный открываться и печататься на любой платформе. Также подразумевалось, что этот формат не предназначен для редактирования, но предназначен для инкрементального апдейта. То есть документ можно дополнить, что-то убрать, добавить ремарку. Для этого разработчики решили, что программа просмотра должна считывать документ с конца. Там хранится так называемый трейлер, из которого берется информация о том, где находится таблица размещения объектов Cross Reference Table. Сам файл состоит из заголовка, набора объектов, Cross Reference Table и трейлера. Имея Cross Reference Table, вы можете быстро найти в файле объект по его номеру. Если вы хотите дописать в файл что-то новое, вы дописываете новые объекты, новый Cross Reference Table и новый трейлер. При этом начало файла вы никак не модифицируете.
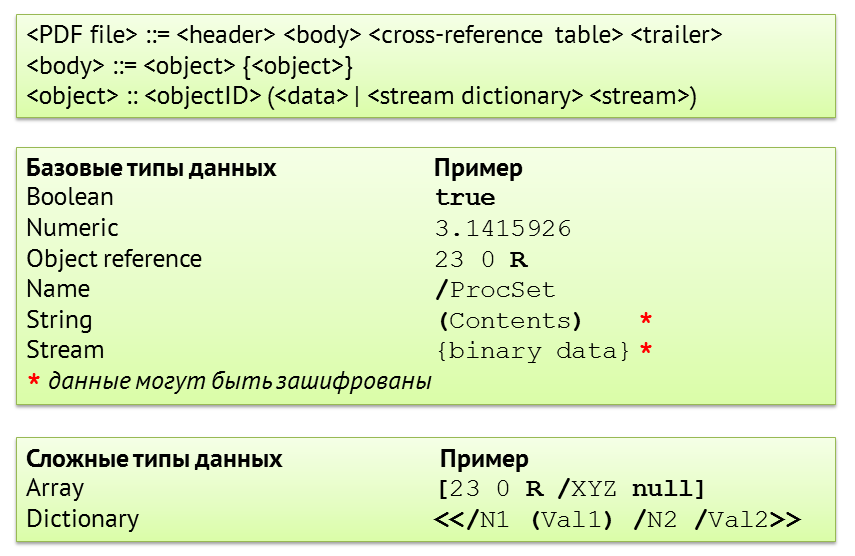
Объект может быть либо каким-то элементом данных, либо так называемым стримом. Стрим состоит из словаря, описателя, позволяющего вам задать характеристики для данных, которые будут в стриме, и некоторого двоичного набора данных, который никак стандартом не определен. Зато определены возможности его интерпретации, то есть что на самом деле может быть в стриме. В стриме может быть описание страницы на подмножестве языка Postscript, может быть картинка и т.д. Базовых типов данных совсем немного:
Согласно изначальной идее, когда вы изменяете существующий объект, тем самым записывается новая версия этого объекта, а значение generation увеличивается на единичку, хотя номер объекта остается тот же. Максимальное значение — 65 534. 65 535 означает, что этот объект удален и больше не будет использован.
На практике все системы обновления PDF удаляют старые объекты и дописывают новые с новыми номерами, потому что так проще. Я не встречал ни одного реального документа, в котором generation был бы равен единице или больше.
Есть объект типа «имя», он начинается с косой черты, дальше могут идти буквы, цифры, точка и подчеркивание. Есть объект типа «строка» — это простой набор данных. Размер имени ограничен 128 байтами, у строки нет ограничения по длине. Главный объект, который хранит весь контент, — тот самый стрим, который может быть сжат, упакован, зашифрован и т.д. Предусмотрено два сложных типа данных. Если вы пользуетесь языком Python, это вам будет знакомо. Объект типа «массив» — последовательно идущие упорядоченные элементы, к которым можно обращаться по индексам. В данном случае в массиве первым элементом идет референс на 23-й объект, потом имя XYZ, а потом нулевой объект. Словарь — это несортированные именованные значения. Идет пара «имя — значение; имя — значение». При этом значением может быть любой объект кроме стрима. То есть у вас значением может быть другой словарь или другой массив, или референс на объект, который содержит стрим.
При помощи такого простенького набора объектов можно описать сколь угодно сложную структуру данных, необходимую для представления документа.
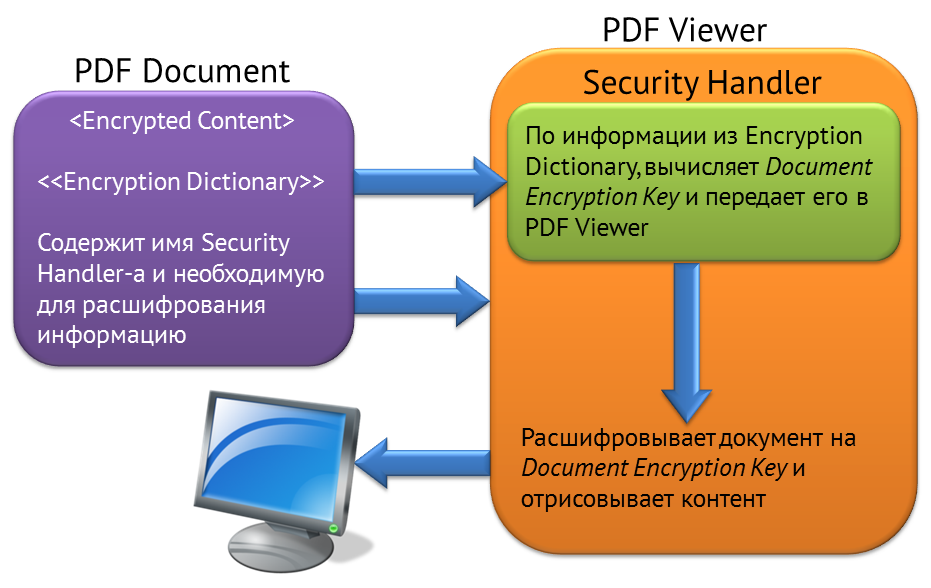
Спецификация на шифрование была разработана компанией Adobe до того, как PDF стали пытаться использовать для хранения документов, защищенных DRM. Изначально было предусмотрено, что в определенном месте документа хранится так называемый Encryption Dictionary — словарь, описывающий все параметры защиты, каким образом документ должен быть расшифрован. Один из элементов Encryption Dictionary — имя Security Handler-а. Это программа, которая берет из документа Encryption Dictionary, запрашивает дополнительную информацию, которая нужна для подтверждения права пользователя на открытие документа. Что это будет — решает программа. Можно спросить пароль, можно обратиться в интернет, можно посмотреть на текущую дату, сравнить ее с зашитой в документе и решить, просрочен ли документ.
Если программа решит, что содержимое можно показывать, она по некоему алгоритму вычисляет новую сущность, которая называется Document Encryption Key. На самом деле Security Handler работает не сам по себе, а как компонент просмотрщика. Главным просмотрщиком PDF на тот момент был Adobe Acrobat — конкурирующих решений практически не было. Acrobat можно было расширять с помощью плагинов, в том числе для обеспечения защиты данных. Если просмотрщик обнаруживал, что документ защищен, он вызывал специальную функцию из плагина и передавал ей Encryption Dictionary, плагин обрабатывал и возвращал ключ, с помощью которого просмотрщик расшифровывал контент и показывал его пользователю. С появлением Digital Rights Management менять этот подход компания Adobe не собиралась: «Мы напишем новые Security Handler-ы, которые будут реализовывать нам DRM». Security Handler-ов по состоянию на 2000 г. существовало довольно много. Расскажу о них подробнее.
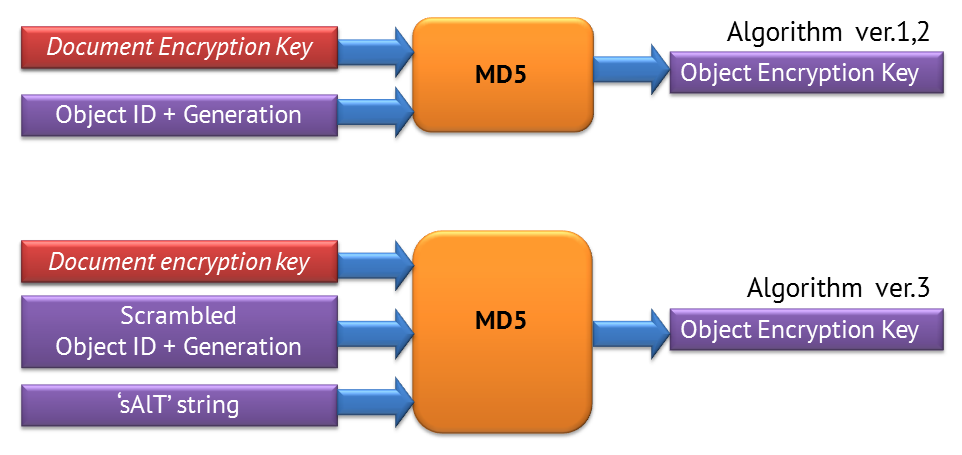
В спецификации было сказано, как из Document Encryption Key получить расшифрованный документ. Для шифрования использовался потоковый алгоритм RC4. У него есть такая особенность: если вы будете зашифровывать два разных объекта одним и тем же ключом, то зашифровываются они в режиме генератора гаммы. То есть у вас из ключа генерируется практически неограниченная по длине псевдослучайная последовательность, которая XOR накладывается на обрабатываемые данные. При шифровании двух объектов одним ключом возможна атака на основе открытого текста. Если вы знаете пару «открытый текст — шифрованный текст» для одного объекта, вы делаете между ними XOR, узнаете гамму и можете расшифровать второй объект. По слухам, в самой первой версии спецификации шифрования этот эффект разработчики не учли, и поэтому сказали: «В новой спецификации мы запрещаем старый алгоритм и вводим новый, при котором каждый объект шифруется независимо от остальных». Берется идентификатор объекта, состоящий из ID и Generation, мешается с ключом документов в хэш-функции MD5, и на выходе мы получаем ключ шифрования для конкретного объекта.
В третьей версии алгоритм был расширен и дополнен. Вместо Object ID и Generation передавались их обфусцированные версии, переставлялись байты и добавлялись некоторые константы, в том числе константная строчка sAlT. Зачем это было сделано — для меня до сих пор загадка. В криптографии есть понятие «соль» — это несекретный случайный элемент. Ключевое слово здесь — случайный. В PDF соль была константой и представляла собой… слово «соль». Что хотели сказать разработчики — я не знаю, но так у них получилось. Эта версия алгоритма не документирована, в спецификации сказано, что она пропущена по требованиям какой-то комиссии в США. В этой стране много юридических бумажек, законов, подзаконных актов, которые регламентируют применение той или иной технологии. В частности, там очень долго существовало так называемое экспортное ограничение на криптоалгоритмы, согласно которому на территории США можно было разрабатывать и использовать программы с любой длиной ключа. Но если вы планируете продавать их за рубеж, то обязаны ограничить ключ 40 битами, в противном случае требовалось разрешение какой-то комиссии. Большинство разработчиков связываться с этим не хотели, поэтому первые две версии шифрования в PDF имели максимальную длину ключа в 40 бит. Потом стали появляться более длинные ключи.
Первый из разработанных Security Handler-ов назывался Standart Security Handler. Он изначально поддерживался Acrobat и был спроектирован для защиты документов от некоторых действий пользователей. В то же время автор документа мог делать все, что угодно. Поэтому в документе было предусмотрено два вида паролей:
Для получения доступа к контенту достаточно было знать любой пароль. Чаще всего на защищенный документ ставился owner-пароль, который знал только автор документа, пользовательский же пароль оставался пустым. И когда документ открывался в просмотрщике, он автоматически открывался в пользовательском режиме, то есть с ограниченными правами, установленными автором документа. Список ограничений был достаточно обширен. Например, в настройках можно было запретить редактирование документа, копирование в буфер обмена, аннотирование и печать. Учитывая тот факт, что для расшифровки документов нужно знать хотя бы один пароль, а пароль пользователя обычно пустой, то для вывода документа на печать необходимо просто расшифровать его, сделать незашифрованную копию, и уже ее распечатать. За эту часть отвечал просмотрщик. Если он не соблюдал прописанные в документе правила, то вывод на печать не запрещался.
В пятой версии Acrobat появилось разрешение на заполнение экранных форм. То есть отредактировать документ нельзя, но можно вписать что-то в поля, специально созданные для вас. Можно было добавить цифровую подпись — на это было отдельное разрешение. Появились возможности для людей с ослабленным зрением — была зарезервирована функция аудиовоспроизведения текста. Также стало возможно редактировать порядок страниц, поворачивать их. И последняя разрешенная фича — низкокачественная печать. Например, вы можете выводить документ в 300 dpi, а в 1600 dpi уже нет.
«Противник» тоже не дремал — были разработаны атаки на поиск пароля. Если пользовательский пароль известен, то документ можно расшифровать моментально, если неизвестен, то его можно подобрать. Для проверки одного пароля требовалось выполнить одну итерацию MD5 и одну инициализацию ключа шифрования алгоритма RC4. Скорость перебора на среднем компьютере того времени достигала 190 тыс. паролей в секунду. Для проверки пароля владельца требовалось примерно вдвое больше операций, соответственно скорость составляла около 100 тыс. паролей в секунду. К третьей версии Security Handler в Adobe решили, что подбор пароля слишком прост, поэтому ввели достаточно большое количество итераций — 51 итерация MD5 и 20 итераций RC4 для пользовательского пароля. В результате скорость перебора снизилась до 3,25 тыс. паролей в секунду. А для пароля владельца — вдвое меньше. Для сравнения: если в архиве ZIP было пять или более файлов, то можно было проверять свыше 1 млн паролей в секунду. Для архиватора RAR версии 3 и выше скорость перебора на таком же компьютере (с частотой процессора 450 MHz) — порядка 30 паролей в секунду. Microsoft сделал когда-то систему шифрования диска BitLocker, и в Windows 7 появилась версия для флешек BitLocker to Go, но на такой же машине на проверку одного пароля уходило две-три секунды. Но 3,25 тыс. (на фоне 190 тыс.) для тех времен — вполне приемлемый результат. Видимо инженеры Adobe все же проводили какую-то работу над ошибками.
В 2000 г. основная масса документов имела шифрование 40 бит. Можно было найти ключ шифрования полным перебором за гарантированное время. При использовании одного компьютера на базе Pentium 3450 MHz время поиска составляло примерно 960 часов, при использовании двух компьютеров — вдвое быстрее, четырех — вчетверо быстрее. Также можно было реализовать предвычисления, если у вас был большой диск для хранения предвычисленных данных. На тот момент большим считался диск объемом 512 Гб. Но четыре компьютера, каждый с диском такого объема, могли за 15 часов гарантированно найти ключ шифрования. Стойкость защиты оказывалась ненадежной даже, по большому счету, для домашнего пользователя, потому что купить четыре компьютера при желании было реально.
Были на тот момент на рынке и другие реализации Security Handler-ов, с помощью которых документы защищались и выпускались в продажу — например, Security Handler под названием Rot13. Разрабатывался он компанией New Paradigm Resource Group, которая с его помощью защищала выпускаемые ею документы — финансовые и аналитические отчеты. Средняя цена за один документ составляла $3 тыс. При этом для работы плагина нужно было купить еще специальную аппаратную заглушку для компьютера. Потом выяснилось, что плагин был на 99% клоном sample-плагина, который идет в SDK с Acrobat. То есть вы могли бесплатно скачать SDK, ознакомиться с тем, как работает плагин, и написать свой. В него внесли минимальные изменения, чтобы он просто работал по-другому, и все документы шифровались одним константным ключом, который хранился в теле плагина в виде текста.
Другое решение предлагалось компанией FileOpen. Она чуть ли не единственная из всех, кто сохранил какое-то положение на рынке защиты PDF-документов. По большому счету, все, кроме Adobe, ушли с рынка за прошедшие годы. FileOpen обладал гибкой системой: возможность защищать паролем документ, проверять лицензию онлайн. Лицензия на издание стоила $2,5 тыс. Компания позиционировала себя как security-партнера Adobe и утверждала, что их решение совместно с Acrobat 5 обеспечивает безопасность электронных документов. Но оказалось, что их приложение версии 2.3 все документы шифровало одним константным ключом. Версия 2.4 шифровала разными ключами, но сам ключ в обфусцированном виде хранился в документе, то есть его можно было оттуда извлечь. Шифрование было 40-битовое, то есть все это очень легко могло быть взломано.
Можно вспомнить также SoftLock Security Handler. Заложенная в него идея была достаточно проста: для доступа к документу требовалось ввести пароль, который вычислялся на основании ID вашего компьютера. То есть документ мог скопировать кто угодно, но при попытке его открыть выскакивало окошко: «ID вашего компьютера такой-то. Введите пароль». Вы должны были отправить этот ID тому, у кого вы купили документ, в ответ приходил пароль. Если вы переносили документ на другой компьютер, то приходилось запрашивать новый пароль, потому что ID компьютера менялся. Пароль был жестко завязан на вычисление Document Encryption Key, и без него нельзя было открыть документ. Якобы. Но разработчики, как обычно, «постарались». Эффективная длина пароля составляла всего 24 бита вместо 40, и подобрать их можно было без оптимизации процесса за 30 часов.
Следующее решение разработано уже компанией Adobe — Adobe WebBuy (PDF Merchant). Чтобы открыть документ, нужно было иметь RMF-файл (Rights Management), в котором хранилась лицензия. Она содержала:
Беглый анализ показал, что в проверке лицензии и вычислении Document Encryption Key используются два RSA-ключа достаточной длины, чтобы их нельзя было взломать. 1024 бита публично не был взломан еще ни разу, самый же длинный взломанный на данный момент ключ — 768 бит. Это связано с очень высокой сложностью, она не полиноминальная, а субэкспоненциальная.
Не имея доступа к секретам, которыми владеет компания Adobe, сформировать свой сертификат и подписать им лицензию было бы невозможно. Клиентам приходилось раскошеливаться на выпуск сертификатов. Но если у вас есть PDF и соответствующий ему RMF, то без каких-либо ухищрений можно вычислить Document Encryption Key и расшифровать документ. А получилось так потому, что Adobe, скорее всего, руководствовалась принципом «Издатель должен заплатить нам денег. Что будет с контентом потом — нас мало беспокоит».
Одно из решений на рынке было разработано компанией GlassBook, купленной Adobe к 2000 г. Это решение было инкорпорировано в eBook Reader от Adobe. GlassBook реализовала протокол EBX (Electronic Book Exchange), который представлял собой что-то вроде стандарта. В нем описывалось, например, как можно «помещать» книги в «библиотеку», как их оттуда «брать» и как делать автоматический возврат. Например, я «беру» книгу и читаю ее на своем компьютере максимум две недели. Если я через две недели не нажал кнопку «Вернуть», она автоматически оказывается в библиотеке и перестает открываться на моем компьютере. Но я могу нажать кнопку «Вернуть» раньше.
В этой системе при активации просмотрщика генерировалась пара RSA-ключей. Открытый ключ отправлялся на сервер и хранился там, привязанный к клиентскому ID, а секретный ключ сохранялся на компьютере в специальным образом выбранном месте. В тот момент, когда вы покупали книгу, брался ее Document Encryption Key, зашифровывался вашим открытым ключом и прописывался в так называемый ваучер, который присылался вместе с зашифрованной книгой. В ваучере содержалась информация о ваших правах на этот документ, и при совпадении всех данных книга открывалась. Нюанс был в том, что для извлечения Document Encryption Key из ваучера нужно было найти секретный ключ RSA на компьютере. Но зная Document Encryption Key, можно было легко сделать ваучер для любого другого компьютера. То есть разработчики считали, что надо максимально усложнить процесс получения Document Encryption Key для потенциального злоумышленника. А самостоятельное генерирование защищенных книг их не сильно беспокоило. То есть они больше заботились о безопасности контента, чем о монетизации. Adobe действовала строго наоборот.
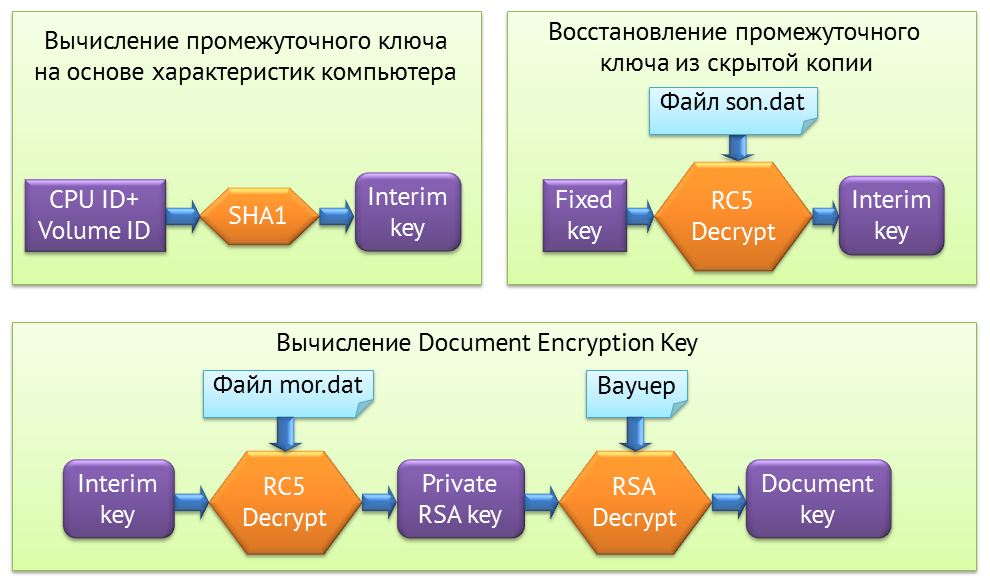
В GlassBook Reader процесс получения ключа выглядит следующим образом. Берутся характеристики компьютера, из них функцией SHA1 вычисляется хэш и получается промежуточный ключ. Он сохраняется в файле son.dat в директории с данными просмотрщика. На случай, если вы поменяете компьютер, а система не позволит вам открыть купленные книги, можно было пройти процедуру подтверждения и с помощью просмотрщика вычислить из этого son.dat тот самый промежуточный ключ.
Зная промежуточный ключ, вы берете файл mor.dat, расшифровываете его этим промежуточным ключом по алгоритму RC5, и получаете RSA Private Key. Уже используя этот ключ, вы расшифровываете ту запись в ваучере, которая содержит Document Encryption Key, и дальше расшифровываете весь контент документа. Такая многоходовая модель.
Маленькое замечание. В этих двух алгоритмах есть важный элемент — Document Encryption Key, который используется при каждом вычислении Object Encryption Key. Это главный секрет, позволяющий расшифровать весь документ. Никаких других секретов нет. Если мы получим Document Encryption Key, то получим контроль над содержимым документа. Сам Document Encryption Key передается в функцию MD5, его можно перехватить — для этого надо знать, где эта функция находится, что достигается с помощью обратного инжиниринга.
В четвертом Acrobat не было вообще никаких средств защиты от дизассемблирования, отладки и методов контроля целостности. Можно было исправлять двоичные файлы и Acrobat прекрасно работал, ни на что не обращая внимания. В пятом Acrobat обнаружение отладчика было встроено в плагин DocBox, но было достаточно слабое и легко обходилось.
В GlassBook использовался продукт PACE InterLok — специализированная технология для защиты исполняемых файлов. Но, видимо, выбрана она была потому, что у них была версия для Mac и для Windows, а у GlassBook также была версия для Mac и для Windows.
У InterLok и его режимов использования были свои забавности. Например, в API можно было включить «критичный режим». В этом случае любая попытка отладки приводила к BSOD. При этом разработчики GlassBook, видимо, не сильно беспокоились, как будет использоваться просмотрщик, поэтому прописали включение критического режима сразу после запуска, а отключение — в момент выгрузки программы. Что при этом получалось? Вы открываете электронную книгу, чтобы почитать, в соседнем окне у вас Visual Studio, вы пишете программу, компилируете, запускаете в режиме пошаговой отладки, и у вас перегружается компьютер. Потому что нельзя отлаживать программу Visual Studio, когда у вас открыта электронная книга. Не знаю, кто это придумал. Потом они это заметили и исправили, но всю защиту можно было снять достаточно просто. Сама технология PACE InterLok оказалась, на мой взгляд, не очень надежной — на тот момент на рынке были более серьезные решения.
Как найти код функции MD5? У этого алгоритма хэширования есть фактически три независимые функции, которыми обеспечивается весь функционал:
Обычно порядок действий такой: вы вызвали функцию Init, потом сразу же вызвали функцию Update, передали нужные данные, а затем вызвали Final. Найдя Init по константам, вы смотрите, откуда он вызывается, ищете, какие функции вызываются рядом. Наверное, одна из них будет Update. Также для поиска Update можно использовать эвристику. Эта функция использует 64 константы, которые также прописаны в стандарте MD5, либо их использует функция Transform, которая вызывается из Update.
И последний нюанс: третья версия стандарта шифрования, которая не была документирована компанией Adobe, содержит то самое волшебное слово sAlT. По этой последовательности символов можно найти, где она используется в программе. Находите саму строку, затем находите, где она обрабатывается. Функция, куда она передается — это MD5 Update. Дальше нужно просто перехватить управление в Update и подождать, когда туда прилетит ключ. Отличить ключ от не ключа можно разными способами, например, эвристически. Для некоторых Security Handler-ов есть и специальная процедура проверки. Но вообще у вас есть одно место, в котором обязательно появляется ключ, и место это легко найти. После перехвата ключа документ расшифровывается без проблем.
Еще один способ атаки, который можно использовать для извлечения зашифрованного контента из PDF, был связан с системой плагинов, имеющейся в Adobe Acrobat и Adobe Reader. Компания Adobe до введения Digital Rights Management сказала, что плагины бывают двух типов:
С появлением DRM компания Adobe придумала «сертифицированные плагины». Они подписывались самой Adobe, и только им разрешалось находиться в памяти при открывании защищенного DRM документа. Если я написал плагин и подписал его своим ключом, то при открывании документа, защищенного WebBuy, плагин не может находиться в памяти. Надо поставить галочку, Reader или Acrobat перезагрузится, и там будут только те плагины, которые были подписаны Adobe. Почему? Потому что в SDK Acrobat есть API для доступа к контенту. Я могу извлечь содержимое любой страницы, если работаю из плагина. А если у меня открыт защищенный документ, то из плагина могу его «раззащитить», и это довольно просто.
Что сделала Adobe для работы функционирования этого механизма? Она проверяла цифровую подпись плагина, но ухитрялась сделать проверку не по содержимому, а только по заголовкам исполняемого файла. В итоге можно было взять уже существующий и сертифицированный, то есть подписанный Adobe, плагин, модифицировать его код и данные, не трогая заголовки, чтобы он выполнял какие-то другие функции, например, загружал какую-нибудь DLL. Достаточно было встроить буквально два десятка ассемблерных инструкций, чтобы они загрузили то, что надо. А дальше весь остальной код писался в Visual Studio, собирался при помощи компилятора C и получался плагин для Acrobat и Reader. При этом обе программы считали, что плагин сертифицирован. Таким образом можно было получить доступ к контенту, сделав маленькую манипуляцию по обходу подписей.
Сама подпись была сделана на основе RSA 512 (ключ 512 бит факторизовали первый раз в 1999 г.). Ключ для адобовской подписи точно также можно было факторизовать и самому подписывать плагины. То есть сама реализация механизма подписи была достаточно слабой. Компанию Adobe известили об этом, на что она ответила, что подделка подписи на плагине является нарушением лицензии на SDK и поэтому не является проблемой безопасности. Вы не можете писать плагины и подписывать их самостоятельно, не нарушив лицензию, значит, нет никакой проблемы безопасности.
Что успело поменяться с 2001 г. в области Digital Rights Management, что нового появилось? Например, появилась атака при помощи Rainbow Tables. Она основана на идее конца 1970-х годов, описанной Хеллманом в статье «Компромисс времени и памяти». Суть в том, что если у вас имеется большой запас времени, то некоторые операции можно предпросчитать, чтобы потом эффективнее искать ключ за более короткое время. Для 40-битового шифрования PDF была сделана реализация, которая требовала 4 Гб дискового пространства, лучше на флэшке (из-за малого времени произвольного доступа). В результате вместо 15 часов перебора на четырех компьютерах время взлома снизилось в среднем до минуты, максимум — 10 минут. То есть вы брали любое количество документов, и в среднем раз в минуту гарантированно расшифровывали любое 40-битовое шифрование.
Также компания Adobe ввела в Acrobat ключи длиной до 256 бит и алгоритм шифрования AES, который позволял с этими ключами работать. То есть появились другие алгоритмы, которые не так хорошо взламываются. Однако Adobe успела сделать пару ошибок. Я показывал, что между второй и третьей версией спецификации скорость взлома упала в 50 раз. В следующей версии спецификации они использовали другой алгоритм, с упрощенной проверкой, и скорость опять возросла, но уже в 100 раз.
Кроме того, появилась технология атаки на графических ускорителях, которая позволяла подбирать ключ еще быстрее — миллионами в секунду. В последней версии, которую выпустила Adobe, предусмотрена защита от атаки с помощью графических ускорителей — достаточно элегантное решение. Но тем не менее подбор простых паролей возможен. Если же это комбинация из 12 символов (буквы, цифры, знаки препинания), то вы его не подберете никогда. Даже восемь символов, наверное, не подберете, если поставите максимальный уровень защиты.
Перехват ключа функции MD5 в самых последних версиях Acrobat и Reader все так же успешно работает. Подделка сертификатов плагина работает условно. Adobe придумала новый способ сертификации: теперь проверяется подпись на всем файле, а не только на заголовках. Также был внедрен RSA 1024. Но для того, чтобы обеспечить обратную совместимость, разработчики оставили и старый режим. Я могу найти и исправить флаг, отвечающий за то, сертифицированный у меня режим или нет. Загружаю свой криво подписанный плагин, из плагина исправляю Acrobat, говорю, что он сертифицирован, после чего открываю файл, Acrobat его расшифровывает, и я, пользуясь SDK Acrobat, могу выгрузить контент в незащищенный файл. То есть можно обойти защиту с помощью решений, предложенных самой Adobe.
Рассмотрим еще несколько Security Handler от сторонних производителей:
Компания Adobe поменяла модель лицензирования права создания Security Handler. Теперь это стоит не $100 за любое количество плагинов, а $25 тыс. за один плагин, плюс роялти с каждой проданной электронной книги. Условия кабальные, и желающих работать по этой схеме оказалось мало, наверное, поэтому очень многие компании ушли из бизнеса. К чему это приводит? Допустим, у вас есть документ, защищенный Panasonic Crypto или NewsStand, при этом обе компании уже не обеспечивают поддержку. Но когда она еще обеспечивалась, активация документа делалась для одного компьютера. За столько лет компьютер поменялся не один раз, поэтому документ открыть уже не получится, поскольку права отсутствуют, хотя они и были когда-то оплачены. Нет уже самой компании, которая осуществляла активацию по запросу. И выхода из этой ситуации нет.
Люди обращаются к Adobe, ведь PDF — ее формат. А там отвечают, что защита не их, поэтому они не причем. Извините, вам не повезло. Вот обратная сторона Digital Rights Management: вы можете в любой момент, по несчастливому стечению обстоятельств, потерять доступ к купленному контенту, и никто не гарантирует, что вы его когда-нибудь вернете.
Компания Adobe выпустила еще один продукт — программную читалку для электронных книг. Она постепенно эволюционировала в продукт под названием Adobe Digital Editions. Он написан на C и Flash, то есть это исполняемый файл плюс контент на Flash. Поддерживается два формата документов — PDF и ePub. Для PDF точно так же работает перехват ключа шифрования в функции MD5 Update. Для алгоритма ePub работает перехват в алгоритме шифрования AES. Поскольку ePub является открытым стандартом, то известно, как зашифровывается документ, известно, где описывается разрешенный тип операций, но не сказано, где хранится ключ. Однако важно лишь, что его надо в какой-то момент передать в алгоритм шифрования AES. Найдя по сигнатурам точку входа в AES, вы можете перехватить ключ и очень быстро расшифровать документ.
Один англичанин на протяжении нескольких лет развлекался тем, что писал программу, которая позволяла из защищенных LIT-документов делать незащищенные. Microsoft выпускала обновленную версию, которая блокировала работу его программы, а через неделю он выпускал новую. Через два месяца Microsoft выпускала новую версию, а тот делал ответный ход. Он всегда легко опережал Microsoft, а потом ему, видимо, это надоело.
Была и другая идея извлечения контента из защищенных документов в формате LIT. Microsoft, видимо, решила не придумывать новый формат для электронных книг. Вместо этого взяли уже существующую технологию Compound Storage. Она использовалась в большом количестве документов Microsoft, несколько реализаций было написано ими самими. В частности, старые документы Word и Excel хранились в этом формате, в нем хранится справка CHM.
Принцип работы следующий: есть функция, которая говорит: «Хочу открыть вот этот контейнер и использовать для него протокол такого идентификатора», ей передается GUID, в ответ возвращается указатель на iStorage, то есть указатель на интерфейс, в котором есть функция «Перечислить файлы», «Перечислить поддиректории» и «Открыть файл». Получив handle файла iStream, вы можете его читать, писать, позиционировать в нем указатель. Фактически, в защищенном документе точно также в какой-то момент фигурировал указатель на iStorage. Если вы его получали, например, внедрив свою DLL в адресное пространство просмотрщика, то, пользуясь этим указателем и документированными Microsoft вызовами, можно было просто взять весь контент после того, как он открылся в просмотрщике, и сохранить. По сути, Microsoft оставила достаточно удобную дверь, чтобы любой мог войти и малыми усилиями украсть контент.
Microsoft Reader LIT мало кто использовал, и десктопная версия под Windows не обновлялась с 8 июля 2003 г. Фактически, технология мертвая, поэтому много рассуждать о ней сейчас не имеет смысла.
В 2006 г. на рынок был выведен Blu-ray, в котором использована Advanced Access Content System — замена CSS (Content Scrambling System). Там было специальное дерево секретов, и если у вас скомпрометирован какой-то из ключей, то во всех последующих дисках секрет просто шифровался другим ключом. То есть все старые диски, которые были созданы до того, как ключ утек, продолжали бы воспроизводиться, а все новые диски — нет.
Были реализованы водяные знаки. По расшифрованному и опубликованному в интернете фильму можно опознать и заблокировать украденный ключ. Также был разработан протокол для вывода контента только на сертифицированные устройства, например, по интерфейсу HDMI. Если у вас телевизор поддерживает спецификацию HDCP (High Definition Content Protection) и производитель купил право показывать защищенные фильмы, то этот интерфейс будет передавать данные. Если у вас на выходе пишущее устройство, то ему никто такой сертификат не выдаст, и привод Blu-ray не будет передавать на него контент. Но выяснилось, что и в High Definition Content Protection есть проблемы, и сама система Advanced Access Content System была взломана в январе 2007 г., то есть меньше чем через год после выхода на рынок. Как минимум у двух популярных плееров были отозваны ключи, потому что они были софтовые, и ключ легко извлекался. Идея, которая оказалась нерабочей в случае с DVD, оказалась такой же для Blu-ray.
Наверное, главная технологическая проблема — открытость платформы. Пока у меня все крутится на персональном компьютере, я имею полный контроль над происходящим, могу запустить отладчик, и производители программ для работы с защищенными документами не в силах мне помешать. То есть сделать защищенную систему на открытой платформе — это утопия.
Исключительно аппаратное решение, где шифрованием будет заниматься какая-нибудь микросхема, будет практически не поддающимся взлому. Например, в телефонах компании Apple изначально есть два ключа шифрования, которые хранятся внутри процессора, и оттуда пока никому извлечь их не удалось. К ключам можно обращаться, если вы получите доступ на уровне ядра. С джейлбрейком это более-менее реализуемо, но сами ключи узнать пока никому не удается. Было бы реализовано программно — давно вытащили бы.
Вторая проблема — универсальные форматы. Я говорил, что PDF был разработан задолго до электронных книг, как и шифрование, и интерфейсы для API плагина. А потом Adobe попыталась с минимумом дополнительных вложений сделать безопасную технологию. Так не получается. То же самое относится к Microsoft LIT, который построен на базе Compound Storage.
Еще одна проблема — так называемый Digital Millennium Copyright Act. Этот закон фактически сделал то, что не смог в 1980-х годах сделать суд с Betamax. Разработку и распространение технологий, которые могут быть использованы для нарушения авторских прав, объявили преступлением. То есть пистолеты производить все еще можно, а программы, с помощью которых можно обходить авторские права, создавать нельзя — за это можно попасть в тюрьму. Поэтому разработчики систем защиты понимают, что технология для обхода, например, защиты PDF вряд ли сможет стать публичной. А раз такую программу не выпустят на рынок, значит, мы в безопасности, можно не делать сложные системы защиты. В результате у нас иллюзия защищенности.
Если говорить про черный рынок, то электронные книги и видеофильмы взламывали, взламывают и будут взламывать. Процесс можно усложнить, но компаниям это не нужно, они все равно имеют прибыль с издателей, а не с конечных пользователей.
Во-первых, существуют другие модели ведения бизнеса. Например, можно издавать книги по главам. Первую главу электронной книги любой пользователь может получить бесплатно. Если ему понравится, то он платит за первую и получает бесплатно вторую. Если ему нравится вторая — он платит за вторую и получает бесплатно третью, и так до конца книги. Преимущество для пользователей неоспоримое. Если книга после второй главы оказалась ерундой, то не надо платить за все остальные главы.
Примерно такую же модель реализовала компания Apple, когда начала продавать музыку в iTunes. Раньше аудио компакт-диск стоил $12, содержал 12 треков. ITunes — $1 за песню. Разницы, вроде бы, никакой, но только на хорошем компакт-диске обычно четыре хороших песни, на плохом — две, а платите вы за все 12. В iTunes вы платите только за то, что нравится. Почему бы не сделать то же самое с электронными книгами?
Можно придумывать другие модели монетизации, но владельцы контента (как правило, это не авторы) обычно на это не идут. Было очень забавно, когда в 2003 г. на Amazon продавалась книга Кевина Митника в трех видах:
Сейчас электронные книжки обычно стоят дешевле, чем в мягкой обложке, но цена все равно неадекватна затратам. Такова модель лицензирования: «Мы просим столько денег, потому что считаем, что это столько стоит». С этим можно соглашаться, можно не соглашаться, но они продолжают ее продвигать, хотя электронная книга могла бы быть гораздо дешевле, чем бумажная.
Я считаю, что у водяных знаков гораздо больше перспектив, чем у DRM, от которого страдают пользователи. Watermarking позволяет вам пометить каждый экземпляр издания так, чтобы было понятно, кому он был продан. И если эта версия разойдется по сети, можно будет сразу найти и привлечь к ответственности того, кто ее выложил.
Компания Penaut Press, которая в свое время публиковала книжки для наладонников Palm, использовала очень оригинальную модель защиты контента. На первой странице каждой книги указывался номер кредитной карты человека, который эту книгу купил. Если вам нравится, чтобы ваш номер кредитной карты был доступен всем — пожалуйста, отдайте этот файл, он будет читаться на любом устройстве, никакой защиты нет. Водяные знаки также используются для психологического сдерживания. Другое дело, что наказать автора программы, выложенной в интернете, гораздо проще, чем человека, выложившего книгу. Потому что у автора программы есть какие-то зацепки — сервер, откуда пользователи качают программу, биллинг, через который ему платят. А человек, который взломал книгу и выложил ее, достаточно легко может сохранить анонимность. Он может жить в другой стране. Поэтому сегодня пытаются наказывать программистов, а не тех, кто реально нарушает закон «Об авторском праве».
Если я не ошибаюсь, то несколько лет назад Apple отказалась от защиты музыки — ее можно воспроизводить на любом устройстве. Видеофильмы еще продолжают защищать, как и электронные книги в iBooks. По большому счету, у пользователя есть много прав на обращение с купленным контентом. В частности, те же американские законы подразумевают право на цитирование. Я могу прийти в любую библиотеку, взять любую бумажную книгу, отсканировать из нее две-три страницы, потом перебить их в свою какую-то научную публикацию и опубликовать, просто скопировав контент из бумажной книги — это разрешено законом. А если я всю книгу скопирую и издам — это будет являться плагиатом. Но если я делаю цитату на две страницы — это нормально, если цитата почему-то важна.
С электронной книгой так не получится, потому что автор не разрешил копировать из документа. Поэтому меня ограничили в тех правах, которые, по большому счету, предусмотрены Конституцией. По-хорошему, надо как-то это реализовывать. Как? Не знаю. Но, на мой взгляд, над этим стоит работать.
Идея этого выступления выросла из доклада, который я читал на конференции DEFCON в 2001 г., после чего у меня и у компании, в которой я работал (ElcomSoft), возникли некоторые юридические сложности. Через 1,5 года после данного выступления в США состоялся суд, в результате которого компанию признали невиновной по всем пяти пунктам обвинения, но история была достаточно громкой. Спустя годы я решил сделать новую версию того доклада, добавив информацию о новых тенденциях в сфере Digital Rights Management (DRM).
DRM в сфере аудио и видео
Расскажу, как возникла идея DRM. Все началось с бытового видеомагнитофона системы Betamax, который компания Sony выпустила на рынок в 1975 г. Он стал первым устройством, позволяющим самостоятельно записывать телевизионный эфир для последующего просмотра. А в 1976 г. Sony получила судебный иск от Universal Studios и The Walt Disney Company, в котором говорилось, что использование технологий бытовой видеозаписи нарушает авторские права. То есть я могу записать фильм с телевизора, и после этого, например, продать его или дать посмотреть кому-нибудь, кто никакого отношения к телевидению не имеет, или что-то в этом роде. Значит, компания Sony заранее виновна в том, что создала такое устройство, и подобные устройства надо следует запретить.

Суд первой инстанции решил, что этот иск не имеет смысла, так как нельзя запретить пользователям просматривать передачи в удобное для них время, предварительно их записав. Но апелляционный суд согласился с тем, что распространение видеомагнитофонов является нарушением авторского права. При этом общественность активно возражала против подобного решения, приводя в качестве аргумента следующее сравнение: производить оружие — законно, а производить видеомагнитофоны — почему-то является нарушением закона. Слава богу, судебная система успела вовремя одуматься, и в последней инстанции, в Верховном суде, было принято решение, что запись телепрограмм для частного просмотра не нарушает авторские права, что это так называемый Fair Use — концепция, закрепленная в законодательных актах США. То есть человек имеет право смотреть то, что ему вещают, тогда, когда он захочет, и так, как он захочет. Это была маленькая победа. Забавно, что в 1984 г. судебный процесс был выигран, а в 1989 г. компания Sony купила киностудию Columbia Pictures и сама стала правообладателем, начав производить фильмы, которые можно было копировать с помощью ее технологий.
Производители контента в итоге смирились с существованием видеомагнитофонов. Главным аргументом стало то, что при перезаписи аналогового изображения происходит потеря качества. То есть нельзя переписать одну видеокассету на другую 100 раз по очереди (с первой на вторую, со второй на третью и т.д.), потому что уже через несколько итераций смотреть это будет невозможно.

В 1982 г. на рынок вышел первый цифровой потребительский продукт — компакт-диски, которые можно было слушать в специальных плеерах. Они имели очень простую внутреннюю организацию, весьма простой формат записи без какого-либо сжатия, 16-битный стереоканал и частоту дискретизации 44,1 КГц. В этот раз первопроходцами стали Sony и Phillips.

Спустя пять лет после компакт-диска на рынок был выведен следующий носитель, предназначенный для цифровой записи звука, — Digital Audio Tape. Для них производились студийные магнитофоны и персональные плееры, которые позволяли воспроизводить ленты в этом формате. Главная особенность данных кассет заключалась в сохранении качества при перезаписи. Но разработчики, учтя полученный с видеоформатами опыт, заложили частоту дискретизации не 44 КГц, а 48 КГц. Вроде бы цель благая — повысить качество звука. Но если вы попытаетесь переписать компакт-диск на Digital Audio Tape, то не сможете этого сделать без цифро-аналогового и аналого-цифрового преобразования, то есть без потери качества. На самом деле, в спецификации была введена поддержка 44,1 КГц, но с ограничениями. Заключались они в том, что если у вас появится кассета, которую кто-то записал на частоте 44,1 КГц, то есть на частоте компакт-диска, вы сможете ее воспроизвести, но самостоятельно записать такую кассету уже не удастся.
Дальнейшая эволюция привела к тому, что возможность переписывать компакт-диск на цифровую магнитную ленту с частотой дискретизации 44,1 КГц все-таки появилась, но переписать данные после этого на другую ленту уже нельзя. То есть с 48 КГц на 48 КГц переписать можно, а с 44 КГц на 44 КГц — увы. Таким образом ограничивалось тиражирование компакт-дисков на магнитные ленты. Это стало одним из первых публичных проявлений DRM, то есть осуществилось управление цифровым контентом с запретом на проведение ряда операций.
Широко известна история с попытками защитить контент на DVD-дисках. В 1996 г. компания Sony предложила рынку DVD. На этапе проектирования была заложена возможность управлять, кто сможет смотреть диск, а кто нет. Для этого мир поделили на семь регионов — семь зон. Диск и плеер должны быть выпущены для одной зоны — в этом случае на данном плеере можно воспроизвести данный диск. При не совпадении зон просмотр диска будет невозможен. Мотивация была такая: есть страны с низким доходом населения, а есть богатые Америка и Европа. Американцы могут позволить себе покупать диск за $12, а африканцы нет. Поэтому африканцам будем продавать диски за $6, но смотреть их можно только на плеерах, которые продаются в Африке. Понятно, что африканские плееры не получится массово привезти в Америку, а диск, купленный в Африке, на американском плеере воспроизводиться не будет. Также была предусмотрена защита от копирования DVD-дисков.
Вообще, копирование с диска на диск стало широко применяться с удешевлением и увеличением количества пишущих приводов. В 1994 г. я имел опыт общения с пишущим CD-приводом, который стоил тогда $1 тыс., а одна болванка к нему — $35. При этом около половины болванок портились приводом при записи. То есть чтобы записать один диск потребуется $70. Понятно, что гораздо дешевле покупать оригинальные лицензионные CD, чем пытаться их копировать в домашних условиях. Но когда стоимость болванки упала до 10 центов, а приводы до $40, вопросы бытового копирования стали насущными.
В 1996 г. на рынок были выпущены DVD с системой защиты Content Scrambling System, а уже в 1997 г. разработали программу DeCSS. Точная информация о том, кто, как и когда ее разработал, отсутствует, есть лишь догадки, что путем анализа программной реализации плеера XingDVD были получены алгоритм и ключи, необходимые для ее работы. То есть пока DVD-проигрыватели были только аппаратными, проанализировать их было сложно и дорого, поэтому никто этого не делал. Но как только появилась программная реализация, все стало достаточно просто — вы садитесь с отладчиком и дизассемблером, выясняете, как работает программа, что происходит внутри, в итоге выстраиваете точно такой же алгоритм, как в этом плеере. Данный алгоритм был извлечен и опубликован в интернете. Видеокомпании предприняли попытки запретить публикацию самого текста алгоритма, программ, которые его реализуют, а также ссылки на них. Случился небольшой скандал с изданием alt.2600, в адрес которого был направлен судебный запрет на публикацию ссылки на страницу, где можно было ознакомиться с алгоритмом. Разумеется, пользователи начали протестовать против запрета на распространение программ только потому, что кому-то так захотелось. В результате дошло до того, что тексты DeCSS стали печатать на футболках. Также была написана очень оригинальная реализация — программа на языке Perl, которая занимается расшифровкой контента DVD-диска. Всего в несколько строк люди ухитрились вместить все, что для этого нужно. Говорят, работает, хотя я не пробовал.
#!/usr/bin/perl
# 472-byte qrpff, Keith Winstein and Marc Horowitz <sipb-iap-dvd@mit.edu>
# MPEG 2 PS VOB file -> descrambled output on stdout.
# usage: perl -I <k1>:<k2>:<k3>:<k4>:<k5> qrpff
# where k1..k5 are the title key bytes in least to most-significant order
s''$/=\2048;while(<>){G=29;R=142;if((@a=unqT="C*",_)[20]&48){D=89;_=unqb24,qT,@
b=map{ord qB8,unqb8,qT,_^$a[--D]}@INC;s/...$/1$&/;Q=unqV,qb25,_;H=73;O=$b[4]<<9
|256|$b[3];Q=Q>>8^(P=(E=255)&(Q>>12^Q>>4^Q/8^Q))<<17,O=O>>8^(E&(F=(S=O>>14&7^O)
^S*8^S<<6))<<9,_=(map{U=_%16orE^=R^=110&(S=(unqT,"\xb\ntd\xbz\x14d")[_/16%8]);E
^=(72,@z=(64,72,G^=12*(U-2?0:S&17)),H^=_%64?12:0,@z)[_%8]}(16..271))[_]^((D>>=8
)+=P+(~F&E))for@a[128..$#a]}print+qT,@a}';s/[D-HO-U_]/\$$&/g;s/q/pack+/g;eval
С момента появления технологии защиты до ее взлома прошел всего год. Как только какой-то продукт выходит на массовый рынок, его вскоре начинают исследовать, и рано или поздно находят способы обойти эту защиту.
DRM в сфере электронных книг
Я занялся электронными книгами примерно в 1999 г. Параллельно писал диссертацию «Метод анализа программных средств защиты электронных документов». Cтал смотреть, какие технологии существуют на рынке и насколько тяжело их скомпрометировать.
Немного о том, как работает электронное издательство и чем оно отличается от традиционного. Когда мы говорим о публикации обыкновенной бумажной книги, то понимаем, что процесс это очень долгий: сначала автор должен написать книгу (от руки или на компьютере). Затем машинистка наберет 300 или 400 страниц текста за достаточно короткое время. После того, как текст переведен в электронный вид, нужно сверстать страницы, чтобы посмотреть, как они будут выглядеть на печати. Когда-то это делалось руками: в специальный ящик вставляли свинцовые буковки, смазывали их краской, а затем делали оттиск страницы. Потом это стали делать механические полуавтоматы, а верстальщик просто набирал текст кнопками. Сейчас же все делается на компьютере. После этого изображения сверстанных страниц выводятся на пленку и отдаются в печать. Возможно, сейчас уже есть типографии, которые печатают достаточно большие тиражи без промежуточного этапа с пленками — сразу с электронного макета.
После того, как бумажные листы будут отпечатаны, их необходимо нарезать, сброшюровать, сшить и приклеить обложку. Дальше нужно решить вопросы логистики, чтобы продукция добралась сначала до склада, а затем до магазинов, куда придет человек, найдет на полке интересующую его книгу и купит ее. Так было на протяжении последних лет 200, сколько существует активное книгопечатание и книготорговля.
Что изменилось с переходом на электронные издания? Первые два этапа остались те же: написать книгу, затем сверстать. Но зато потом можно буквально нажатием одной кнопки сделать так, чтобы эта книга оказалась в устройстве для чтения — в ридере. Тем самым исключается несколько дорогостоящих этапов: печать, логистика, оплата торговых площадей, оплата труда работников на каждом этапе. Казалось бы, электронная книга должна очень сильно подешеветь для конечного пользователя. Я сам, например, являюсь автором одной книги, и по договору получал, если не ошибаюсь, 12% от оптовой стоимости каждого экземпляра. Плюс магазин еще примерно 100% накручивал и выпускал книгу в продажу. То есть доля авторских отчислений в общей стоимости книги невелика, в основном цена складывается из себестоимости сырья, зарплат и накладных расходов.
У электронных книг масса достоинств по сравнению с бумажными. Их гораздо дешевле изготавливать, а также можно неограниченно тиражировать. Написанная мной книга выпускалась тремя тиражами по 3 тыс. экземпляров, и сейчас купить ее в магазинах уже нельзя. Правда, в сети есть отсканированная копия, и недавно начали более-менее официально торговать через Ozon электронной версией книги.
Также электронные книги быстрее попадают к читателям. Можно в одном ридере носить хоть всю энциклопедию «Британика», бумажная версия которой состоит из 50 томов. Электронные книги позволяют быстро найти нужный текст, они не изнашиваются, в них можно реализовывать механизмы навигации типа гиперссылок, вставлять мультимедиа-объекты, анимацию, звук — красота, удобство и радость как для тех, кто хочет доставить свой контент потребителям, так и для тех, кто этот контент потребляет.
Но наряду с достоинствами электронные книги имеют и недостатки. Во-первых, формат часто связан с типом ридера — то есть то, что может быть прочитано на одном ридере, на другом может быть нечитаемым (но данную проблему можно решить с помощью специального ПО — путем конвертирования в другие форматы). Во-вторых, и это самая главная проблема электронных книг, здесь навязан контроль соблюдения авторских прав. Если я хочу растиражировать бумажную книгу, то мне нужно отсканировать каждую страницу, напечатать, потом как-то сшить, приклеить обложку, и только тогда я смогу ее отдать или продать. Стоимость копии окажется высокой, наверняка даже дороже оригинала, если мы говорим о сопоставимом качестве. А электронная книга — это просто файл, который можно рассылать миллионами экземпляров. И вот уже правообладатель потерял контроль над распространением, все читают, а никто не платит деньги. Это самая большая страшилка для правообладателей, которые хотят заработать как можно больше денег. Их тоже можно понять. В итоге стали появляться технологии защиты электронных книг, которые можно читать, но при этом накладываются ограничения на некоторые операции.
Рынок электронных книг по состоянию на 2000 г. можно грубо поделить на три категории.
- Первая категория достаточно большая, и, на мой взгляд, достаточно бестолковая — так называемые программные компиляторы и читалки электронных книг, которые позволяли взять текстовый файл, HTML или документ Word и превратить его в исполняемый файл. Для чтения надо было ввести пароль или осуществить активацию через интернет. То есть на выходе получалось нечто более-менее защищенное, работающее как исполняемый файл или как отдельная программа для просмотра, которая умеет показывать файлы, созданные конкретной программой. Понятно, что для пользователя сама программа для просмотра была бесплатной, а за контент надо было заплатить. Сами издатели, желавшие распространять свои книги через какие-то программы, должны были осуществлять отчисления их разработчикам.
- Вторая категория — «железные» ридеры. Сейчас они стали массовым продуктом, а на тот момент существовало всего две модели данных устройств (насколько мне известно). В то время читалки были с черно-белыми жк-экранами не слишком хорошего качества: RocketBook и eBookMan Reader. Первый был чуть популярнее. Про распространение защищенных электронных книг для этих устройств я, к сожалению, ничего не знаю.
- Третья категория — сегмент рынка, который пытались захватить две крупных компании, решившие, что у рынка есть будущее и он принесет доход. Первая — Adobe, задолго до этого разработавшая PDF. На основе данного формата она пыталась создать коммерческую технологию электронных книг, чтобы люди платили именно за содержание документа. Второй крупный игрок — Microsoft, выпускающая линейку устройств Pocket PC. Она разрабатывала технологию Reader.Lit (Literature), чтобы можно было читать защищенные документы в формате .lit либо на персональном компьютере, либо на карманном устройстве, в зависимости от способа активации.
Несколько лет назад приятель моего начальника, сам занимающийся изданием каких-то учебных материалов, захотел защитить эти материалы. В сети он наткнулся на программу eBook Pro Compiler, которая позиционировала себя как (вольный перевод с английского языка) «Единственное ПО во Вселенной, которое делает вашу информацию практически 100%-но защищенной от взлома, идет с пожизненной гарантией возврата денег, если вам что-то не понравится. Наконец, вы можете продавать информацию онлайн и делать тысячи продаж ежедневно без опасности того, что ваша информация будет украдена или продана другими». То есть было заявлено, что данная программа является самым крутым в мире решением для издателей. Но чтобы продавать тысячи копий в день, нужно иметь настолько хороший контент, чтобы тысячи людей в день захотели его купить. Если вас зовут Дарья Донцова, то у вас есть шанс написать такую книгу, которую за первую пару месяцев будет покупать тысяча людей в день. Если же вы пишете научный учебник, то, продав всего 10 тыс. копий, можно сказать, что вам повезло, так как умные книги у нас особым спросом, к сожалению, не пользуются.
Поверив рекламе, приятель моего начальника купил эту программу. Оказалось, что открыв скомпилированную «защищенную» книгу, с помощью комбинаций Ctrl+A и Ctrl+Insert можно в буфере обмена получить весь контент текущей страницы, вставить его в Word, и вот вы украли контент. Также можно было зайти в директорию Temp и там найти все HTML-странички и картинки как они были до того, как вы скомпилировали книгу. Причем они так и будут лежать во временной директории, потому что компилятор для просмотра электронных книг использовал движок Internet Explorer. И разработчики даже не удосужились реализовать механизм хранения исходных данных в памяти, а не на диске. То есть они их просто выгружали на диск и говорили IE: «Покажи нам эти файлы с диска». Совершенно детская реализация процесса работы с защищенным контентом. Я немножко покопался с отладчиком-дизассемблером и понял, как устроен формат. Все данные, из которых состоит книга (картинки, CSS, HTML), упаковываются в контейнер, из которого потом извлекаются в момент показа. Для упаковки используется бесплатная и открытая библиотека Zlib, а сами данные шифруются очень интересным алгоритмом: на каждый байт зашифрованных данных последовательно накладываются все байты слова «encrypted» с помощью операции XOR. Люди, которые это писали, не только ничего не понимают в криптографии, но и вообще не представляют, как работает XOR. Ведь XOR последовательно с разными байтами можно свести к XOR с одним байтом. То есть они весь контент ксорили с одной однобайтовой константой. Никакой защиты это не обеспечивает, но тем не менее спокойно утверждали обратное.
Про все системы создания электронных книг, которые я упоминал ранее, я не скажу, но думаю, что добрая половина из них была устроена примерно так же. Сфере защиты контента присуща одна особенность. Например, в качестве графического редактора вы используете Photoshop и сравниваете его с Gimp. В каких-то операциях Photoshop работает гораздо лучше или гораздо хуже — неважно. Вы на глаз видите разницу. Входные данные одни и те же, а результат разный. Но когда вы что-то защищаете, зашифровываете, то невозможно оценить результат «на глаз». Как понять, хорошая защита или плохая? Можно это взломать или нельзя, легко ли это или трудно? О том, что вас взломали, вы узнаете только тогда, когда это случится. А степень легкости взлома оценить адекватно вы не сможете, если не разбираетесь в технологиях информационной защиты. Поэтому плохих решений на рынке, к сожалению, было всегда много, они никуда не денутся и будут успешно продаваться, потому что продать хорошее решение без красивой обертки гораздо труднее, чем продать плохое решение в красивой обертке. Если у вас есть рекламный бюджет — вы на коне, и ваши продукты в сфере безопасности будут покупать независимо от их качества.
Структура PDF

Особое внимание в своем исследовании я уделял PDF-файлам. Я изучал их устройство, заложенные в них механизмы обеспечения безопасности контента. На тот момент объем спецификации PDF составлял около 600 страниц, из которых 20—30 страниц касались безопасности и представляли самый большой интерес. С тех пор спецификация много раз переписывалась, и последние версии поддерживает, если не ошибаюсь, не Adobe, а какой-то из подкомитетов ISO. То есть PDF пытаются сделать международным стандартом. При проектировании этого формата (Portable Document Format) одной из главных задач было обеспечение одинакового отображения на всех устройствах. Почему это так важно? Наверняка вы оказывались в ситуации, когда, создавая сложный документ в Word на одном компьютере, а печатая на другом, оказывалось, что верстка «поплыла», картинки не помещаются и т.д. Причина в том, что Microsoft Word — это не издательская система, а система подготовки текстов, не предназначенная для создания полноценных макетов для печати.
PDF проектировался как более компактный, чем Postscript, формат, способный открываться и печататься на любой платформе. Также подразумевалось, что этот формат не предназначен для редактирования, но предназначен для инкрементального апдейта. То есть документ можно дополнить, что-то убрать, добавить ремарку. Для этого разработчики решили, что программа просмотра должна считывать документ с конца. Там хранится так называемый трейлер, из которого берется информация о том, где находится таблица размещения объектов Cross Reference Table. Сам файл состоит из заголовка, набора объектов, Cross Reference Table и трейлера. Имея Cross Reference Table, вы можете быстро найти в файле объект по его номеру. Если вы хотите дописать в файл что-то новое, вы дописываете новые объекты, новый Cross Reference Table и новый трейлер. При этом начало файла вы никак не модифицируете.
Объект может быть либо каким-то элементом данных, либо так называемым стримом. Стрим состоит из словаря, описателя, позволяющего вам задать характеристики для данных, которые будут в стриме, и некоторого двоичного набора данных, который никак стандартом не определен. Зато определены возможности его интерпретации, то есть что на самом деле может быть в стриме. В стриме может быть описание страницы на подмножестве языка Postscript, может быть картинка и т.д. Базовых типов данных совсем немного:
- пустой объект (нуль);
- булево значение true или false;
- вещественное или целое число numeric;
- ссылка на другой объект по номеру. 23 0 R — ссылка на объект. R — признак референса, 23 — номер объекта, 0 — поколение объекта.
Согласно изначальной идее, когда вы изменяете существующий объект, тем самым записывается новая версия этого объекта, а значение generation увеличивается на единичку, хотя номер объекта остается тот же. Максимальное значение — 65 534. 65 535 означает, что этот объект удален и больше не будет использован.
На практике все системы обновления PDF удаляют старые объекты и дописывают новые с новыми номерами, потому что так проще. Я не встречал ни одного реального документа, в котором generation был бы равен единице или больше.
Есть объект типа «имя», он начинается с косой черты, дальше могут идти буквы, цифры, точка и подчеркивание. Есть объект типа «строка» — это простой набор данных. Размер имени ограничен 128 байтами, у строки нет ограничения по длине. Главный объект, который хранит весь контент, — тот самый стрим, который может быть сжат, упакован, зашифрован и т.д. Предусмотрено два сложных типа данных. Если вы пользуетесь языком Python, это вам будет знакомо. Объект типа «массив» — последовательно идущие упорядоченные элементы, к которым можно обращаться по индексам. В данном случае в массиве первым элементом идет референс на 23-й объект, потом имя XYZ, а потом нулевой объект. Словарь — это несортированные именованные значения. Идет пара «имя — значение; имя — значение». При этом значением может быть любой объект кроме стрима. То есть у вас значением может быть другой словарь или другой массив, или референс на объект, который содержит стрим.
При помощи такого простенького набора объектов можно описать сколь угодно сложную структуру данных, необходимую для представления документа.
Шифрование в PDF

Спецификация на шифрование была разработана компанией Adobe до того, как PDF стали пытаться использовать для хранения документов, защищенных DRM. Изначально было предусмотрено, что в определенном месте документа хранится так называемый Encryption Dictionary — словарь, описывающий все параметры защиты, каким образом документ должен быть расшифрован. Один из элементов Encryption Dictionary — имя Security Handler-а. Это программа, которая берет из документа Encryption Dictionary, запрашивает дополнительную информацию, которая нужна для подтверждения права пользователя на открытие документа. Что это будет — решает программа. Можно спросить пароль, можно обратиться в интернет, можно посмотреть на текущую дату, сравнить ее с зашитой в документе и решить, просрочен ли документ.
Если программа решит, что содержимое можно показывать, она по некоему алгоритму вычисляет новую сущность, которая называется Document Encryption Key. На самом деле Security Handler работает не сам по себе, а как компонент просмотрщика. Главным просмотрщиком PDF на тот момент был Adobe Acrobat — конкурирующих решений практически не было. Acrobat можно было расширять с помощью плагинов, в том числе для обеспечения защиты данных. Если просмотрщик обнаруживал, что документ защищен, он вызывал специальную функцию из плагина и передавал ей Encryption Dictionary, плагин обрабатывал и возвращал ключ, с помощью которого просмотрщик расшифровывал контент и показывал его пользователю. С появлением Digital Rights Management менять этот подход компания Adobe не собиралась: «Мы напишем новые Security Handler-ы, которые будут реализовывать нам DRM». Security Handler-ов по состоянию на 2000 г. существовало довольно много. Расскажу о них подробнее.
В спецификации было сказано, как из Document Encryption Key получить расшифрованный документ. Для шифрования использовался потоковый алгоритм RC4. У него есть такая особенность: если вы будете зашифровывать два разных объекта одним и тем же ключом, то зашифровываются они в режиме генератора гаммы. То есть у вас из ключа генерируется практически неограниченная по длине псевдослучайная последовательность, которая XOR накладывается на обрабатываемые данные. При шифровании двух объектов одним ключом возможна атака на основе открытого текста. Если вы знаете пару «открытый текст — шифрованный текст» для одного объекта, вы делаете между ними XOR, узнаете гамму и можете расшифровать второй объект. По слухам, в самой первой версии спецификации шифрования этот эффект разработчики не учли, и поэтому сказали: «В новой спецификации мы запрещаем старый алгоритм и вводим новый, при котором каждый объект шифруется независимо от остальных». Берется идентификатор объекта, состоящий из ID и Generation, мешается с ключом документов в хэш-функции MD5, и на выходе мы получаем ключ шифрования для конкретного объекта.
В третьей версии алгоритм был расширен и дополнен. Вместо Object ID и Generation передавались их обфусцированные версии, переставлялись байты и добавлялись некоторые константы, в том числе константная строчка sAlT. Зачем это было сделано — для меня до сих пор загадка. В криптографии есть понятие «соль» — это несекретный случайный элемент. Ключевое слово здесь — случайный. В PDF соль была константой и представляла собой… слово «соль». Что хотели сказать разработчики — я не знаю, но так у них получилось. Эта версия алгоритма не документирована, в спецификации сказано, что она пропущена по требованиям какой-то комиссии в США. В этой стране много юридических бумажек, законов, подзаконных актов, которые регламентируют применение той или иной технологии. В частности, там очень долго существовало так называемое экспортное ограничение на криптоалгоритмы, согласно которому на территории США можно было разрабатывать и использовать программы с любой длиной ключа. Но если вы планируете продавать их за рубеж, то обязаны ограничить ключ 40 битами, в противном случае требовалось разрешение какой-то комиссии. Большинство разработчиков связываться с этим не хотели, поэтому первые две версии шифрования в PDF имели максимальную длину ключа в 40 бит. Потом стали появляться более длинные ключи.
Первый из разработанных Security Handler-ов назывался Standart Security Handler. Он изначально поддерживался Acrobat и был спроектирован для защиты документов от некоторых действий пользователей. В то же время автор документа мог делать все, что угодно. Поэтому в документе было предусмотрено два вида паролей:
- user-пароль, позволяющий получить доступ к документу с теми ограничениями, которые установил владелец;
- owner-пароль, который давал полные права.
Для получения доступа к контенту достаточно было знать любой пароль. Чаще всего на защищенный документ ставился owner-пароль, который знал только автор документа, пользовательский же пароль оставался пустым. И когда документ открывался в просмотрщике, он автоматически открывался в пользовательском режиме, то есть с ограниченными правами, установленными автором документа. Список ограничений был достаточно обширен. Например, в настройках можно было запретить редактирование документа, копирование в буфер обмена, аннотирование и печать. Учитывая тот факт, что для расшифровки документов нужно знать хотя бы один пароль, а пароль пользователя обычно пустой, то для вывода документа на печать необходимо просто расшифровать его, сделать незашифрованную копию, и уже ее распечатать. За эту часть отвечал просмотрщик. Если он не соблюдал прописанные в документе правила, то вывод на печать не запрещался.
В пятой версии Acrobat появилось разрешение на заполнение экранных форм. То есть отредактировать документ нельзя, но можно вписать что-то в поля, специально созданные для вас. Можно было добавить цифровую подпись — на это было отдельное разрешение. Появились возможности для людей с ослабленным зрением — была зарезервирована функция аудиовоспроизведения текста. Также стало возможно редактировать порядок страниц, поворачивать их. И последняя разрешенная фича — низкокачественная печать. Например, вы можете выводить документ в 300 dpi, а в 1600 dpi уже нет.
«Противник» тоже не дремал — были разработаны атаки на поиск пароля. Если пользовательский пароль известен, то документ можно расшифровать моментально, если неизвестен, то его можно подобрать. Для проверки одного пароля требовалось выполнить одну итерацию MD5 и одну инициализацию ключа шифрования алгоритма RC4. Скорость перебора на среднем компьютере того времени достигала 190 тыс. паролей в секунду. Для проверки пароля владельца требовалось примерно вдвое больше операций, соответственно скорость составляла около 100 тыс. паролей в секунду. К третьей версии Security Handler в Adobe решили, что подбор пароля слишком прост, поэтому ввели достаточно большое количество итераций — 51 итерация MD5 и 20 итераций RC4 для пользовательского пароля. В результате скорость перебора снизилась до 3,25 тыс. паролей в секунду. А для пароля владельца — вдвое меньше. Для сравнения: если в архиве ZIP было пять или более файлов, то можно было проверять свыше 1 млн паролей в секунду. Для архиватора RAR версии 3 и выше скорость перебора на таком же компьютере (с частотой процессора 450 MHz) — порядка 30 паролей в секунду. Microsoft сделал когда-то систему шифрования диска BitLocker, и в Windows 7 появилась версия для флешек BitLocker to Go, но на такой же машине на проверку одного пароля уходило две-три секунды. Но 3,25 тыс. (на фоне 190 тыс.) для тех времен — вполне приемлемый результат. Видимо инженеры Adobe все же проводили какую-то работу над ошибками.
В 2000 г. основная масса документов имела шифрование 40 бит. Можно было найти ключ шифрования полным перебором за гарантированное время. При использовании одного компьютера на базе Pentium 3450 MHz время поиска составляло примерно 960 часов, при использовании двух компьютеров — вдвое быстрее, четырех — вчетверо быстрее. Также можно было реализовать предвычисления, если у вас был большой диск для хранения предвычисленных данных. На тот момент большим считался диск объемом 512 Гб. Но четыре компьютера, каждый с диском такого объема, могли за 15 часов гарантированно найти ключ шифрования. Стойкость защиты оказывалась ненадежной даже, по большому счету, для домашнего пользователя, потому что купить четыре компьютера при желании было реально.
Другие версии Security Handler
Были на тот момент на рынке и другие реализации Security Handler-ов, с помощью которых документы защищались и выпускались в продажу — например, Security Handler под названием Rot13. Разрабатывался он компанией New Paradigm Resource Group, которая с его помощью защищала выпускаемые ею документы — финансовые и аналитические отчеты. Средняя цена за один документ составляла $3 тыс. При этом для работы плагина нужно было купить еще специальную аппаратную заглушку для компьютера. Потом выяснилось, что плагин был на 99% клоном sample-плагина, который идет в SDK с Acrobat. То есть вы могли бесплатно скачать SDK, ознакомиться с тем, как работает плагин, и написать свой. В него внесли минимальные изменения, чтобы он просто работал по-другому, и все документы шифровались одним константным ключом, который хранился в теле плагина в виде текста.
Другое решение предлагалось компанией FileOpen. Она чуть ли не единственная из всех, кто сохранил какое-то положение на рынке защиты PDF-документов. По большому счету, все, кроме Adobe, ушли с рынка за прошедшие годы. FileOpen обладал гибкой системой: возможность защищать паролем документ, проверять лицензию онлайн. Лицензия на издание стоила $2,5 тыс. Компания позиционировала себя как security-партнера Adobe и утверждала, что их решение совместно с Acrobat 5 обеспечивает безопасность электронных документов. Но оказалось, что их приложение версии 2.3 все документы шифровало одним константным ключом. Версия 2.4 шифровала разными ключами, но сам ключ в обфусцированном виде хранился в документе, то есть его можно было оттуда извлечь. Шифрование было 40-битовое, то есть все это очень легко могло быть взломано.
Можно вспомнить также SoftLock Security Handler. Заложенная в него идея была достаточно проста: для доступа к документу требовалось ввести пароль, который вычислялся на основании ID вашего компьютера. То есть документ мог скопировать кто угодно, но при попытке его открыть выскакивало окошко: «ID вашего компьютера такой-то. Введите пароль». Вы должны были отправить этот ID тому, у кого вы купили документ, в ответ приходил пароль. Если вы переносили документ на другой компьютер, то приходилось запрашивать новый пароль, потому что ID компьютера менялся. Пароль был жестко завязан на вычисление Document Encryption Key, и без него нельзя было открыть документ. Якобы. Но разработчики, как обычно, «постарались». Эффективная длина пароля составляла всего 24 бита вместо 40, и подобрать их можно было без оптимизации процесса за 30 часов.
Следующее решение разработано уже компанией Adobe — Adobe WebBuy (PDF Merchant). Чтобы открыть документ, нужно было иметь RMF-файл (Rights Management), в котором хранилась лицензия. Она содержала:
- сертификат ключа издателя, который создал документ;
- идентификаторы системы, для которой этот документ предназначался;
- список ограничений;
- данные для проверки валидности лицензии.
Беглый анализ показал, что в проверке лицензии и вычислении Document Encryption Key используются два RSA-ключа достаточной длины, чтобы их нельзя было взломать. 1024 бита публично не был взломан еще ни разу, самый же длинный взломанный на данный момент ключ — 768 бит. Это связано с очень высокой сложностью, она не полиноминальная, а субэкспоненциальная.
Не имея доступа к секретам, которыми владеет компания Adobe, сформировать свой сертификат и подписать им лицензию было бы невозможно. Клиентам приходилось раскошеливаться на выпуск сертификатов. Но если у вас есть PDF и соответствующий ему RMF, то без каких-либо ухищрений можно вычислить Document Encryption Key и расшифровать документ. А получилось так потому, что Adobe, скорее всего, руководствовалась принципом «Издатель должен заплатить нам денег. Что будет с контентом потом — нас мало беспокоит».
GlassBook
Одно из решений на рынке было разработано компанией GlassBook, купленной Adobe к 2000 г. Это решение было инкорпорировано в eBook Reader от Adobe. GlassBook реализовала протокол EBX (Electronic Book Exchange), который представлял собой что-то вроде стандарта. В нем описывалось, например, как можно «помещать» книги в «библиотеку», как их оттуда «брать» и как делать автоматический возврат. Например, я «беру» книгу и читаю ее на своем компьютере максимум две недели. Если я через две недели не нажал кнопку «Вернуть», она автоматически оказывается в библиотеке и перестает открываться на моем компьютере. Но я могу нажать кнопку «Вернуть» раньше.
В этой системе при активации просмотрщика генерировалась пара RSA-ключей. Открытый ключ отправлялся на сервер и хранился там, привязанный к клиентскому ID, а секретный ключ сохранялся на компьютере в специальным образом выбранном месте. В тот момент, когда вы покупали книгу, брался ее Document Encryption Key, зашифровывался вашим открытым ключом и прописывался в так называемый ваучер, который присылался вместе с зашифрованной книгой. В ваучере содержалась информация о ваших правах на этот документ, и при совпадении всех данных книга открывалась. Нюанс был в том, что для извлечения Document Encryption Key из ваучера нужно было найти секретный ключ RSA на компьютере. Но зная Document Encryption Key, можно было легко сделать ваучер для любого другого компьютера. То есть разработчики считали, что надо максимально усложнить процесс получения Document Encryption Key для потенциального злоумышленника. А самостоятельное генерирование защищенных книг их не сильно беспокоило. То есть они больше заботились о безопасности контента, чем о монетизации. Adobe действовала строго наоборот.

В GlassBook Reader процесс получения ключа выглядит следующим образом. Берутся характеристики компьютера, из них функцией SHA1 вычисляется хэш и получается промежуточный ключ. Он сохраняется в файле son.dat в директории с данными просмотрщика. На случай, если вы поменяете компьютер, а система не позволит вам открыть купленные книги, можно было пройти процедуру подтверждения и с помощью просмотрщика вычислить из этого son.dat тот самый промежуточный ключ.
Зная промежуточный ключ, вы берете файл mor.dat, расшифровываете его этим промежуточным ключом по алгоритму RC5, и получаете RSA Private Key. Уже используя этот ключ, вы расшифровываете ту запись в ваучере, которая содержит Document Encryption Key, и дальше расшифровываете весь контент документа. Такая многоходовая модель.

Маленькое замечание. В этих двух алгоритмах есть важный элемент — Document Encryption Key, который используется при каждом вычислении Object Encryption Key. Это главный секрет, позволяющий расшифровать весь документ. Никаких других секретов нет. Если мы получим Document Encryption Key, то получим контроль над содержимым документа. Сам Document Encryption Key передается в функцию MD5, его можно перехватить — для этого надо знать, где эта функция находится, что достигается с помощью обратного инжиниринга.
В четвертом Acrobat не было вообще никаких средств защиты от дизассемблирования, отладки и методов контроля целостности. Можно было исправлять двоичные файлы и Acrobat прекрасно работал, ни на что не обращая внимания. В пятом Acrobat обнаружение отладчика было встроено в плагин DocBox, но было достаточно слабое и легко обходилось.
В GlassBook использовался продукт PACE InterLok — специализированная технология для защиты исполняемых файлов. Но, видимо, выбрана она была потому, что у них была версия для Mac и для Windows, а у GlassBook также была версия для Mac и для Windows.
У InterLok и его режимов использования были свои забавности. Например, в API можно было включить «критичный режим». В этом случае любая попытка отладки приводила к BSOD. При этом разработчики GlassBook, видимо, не сильно беспокоились, как будет использоваться просмотрщик, поэтому прописали включение критического режима сразу после запуска, а отключение — в момент выгрузки программы. Что при этом получалось? Вы открываете электронную книгу, чтобы почитать, в соседнем окне у вас Visual Studio, вы пишете программу, компилируете, запускаете в режиме пошаговой отладки, и у вас перегружается компьютер. Потому что нельзя отлаживать программу Visual Studio, когда у вас открыта электронная книга. Не знаю, кто это придумал. Потом они это заметили и исправили, но всю защиту можно было снять достаточно просто. Сама технология PACE InterLok оказалась, на мой взгляд, не очень надежной — на тот момент на рынке были более серьезные решения.
Взлом PDF
Как найти код функции MD5? У этого алгоритма хэширования есть фактически три независимые функции, которыми обеспечивается весь функционал:
- Init, задающая начальное состояние — в ней используются четыре константы;
- Update, куда вы подаете данные, нуждающиеся в хэшировании;
- Final, отвечающая за получение результата.
Обычно порядок действий такой: вы вызвали функцию Init, потом сразу же вызвали функцию Update, передали нужные данные, а затем вызвали Final. Найдя Init по константам, вы смотрите, откуда он вызывается, ищете, какие функции вызываются рядом. Наверное, одна из них будет Update. Также для поиска Update можно использовать эвристику. Эта функция использует 64 константы, которые также прописаны в стандарте MD5, либо их использует функция Transform, которая вызывается из Update.
И последний нюанс: третья версия стандарта шифрования, которая не была документирована компанией Adobe, содержит то самое волшебное слово sAlT. По этой последовательности символов можно найти, где она используется в программе. Находите саму строку, затем находите, где она обрабатывается. Функция, куда она передается — это MD5 Update. Дальше нужно просто перехватить управление в Update и подождать, когда туда прилетит ключ. Отличить ключ от не ключа можно разными способами, например, эвристически. Для некоторых Security Handler-ов есть и специальная процедура проверки. Но вообще у вас есть одно место, в котором обязательно появляется ключ, и место это легко найти. После перехвата ключа документ расшифровывается без проблем.
Еще один способ атаки, который можно использовать для извлечения зашифрованного контента из PDF, был связан с системой плагинов, имеющейся в Adobe Acrobat и Adobe Reader. Компания Adobe до введения Digital Rights Management сказала, что плагины бывают двух типов:
- простые, работающие только в Acrobat. Вы покупаете Acrobat, пишете для него плагин, и каждый, желающий использовать его, тоже должен купить Acrobat;
- подписанные плагины. Чтобы подписать плагин, вы должны купить у компании Adobe ключ сертификации. Стоил он всего $100 на любое количество плагинов. После этого вы становились разработчиком и могли распространять свои плагины так, чтобы они подгружались не только в платном Acrobat, но и в бесплатном Reader.
С появлением DRM компания Adobe придумала «сертифицированные плагины». Они подписывались самой Adobe, и только им разрешалось находиться в памяти при открывании защищенного DRM документа. Если я написал плагин и подписал его своим ключом, то при открывании документа, защищенного WebBuy, плагин не может находиться в памяти. Надо поставить галочку, Reader или Acrobat перезагрузится, и там будут только те плагины, которые были подписаны Adobe. Почему? Потому что в SDK Acrobat есть API для доступа к контенту. Я могу извлечь содержимое любой страницы, если работаю из плагина. А если у меня открыт защищенный документ, то из плагина могу его «раззащитить», и это довольно просто.
Что сделала Adobe для работы функционирования этого механизма? Она проверяла цифровую подпись плагина, но ухитрялась сделать проверку не по содержимому, а только по заголовкам исполняемого файла. В итоге можно было взять уже существующий и сертифицированный, то есть подписанный Adobe, плагин, модифицировать его код и данные, не трогая заголовки, чтобы он выполнял какие-то другие функции, например, загружал какую-нибудь DLL. Достаточно было встроить буквально два десятка ассемблерных инструкций, чтобы они загрузили то, что надо. А дальше весь остальной код писался в Visual Studio, собирался при помощи компилятора C и получался плагин для Acrobat и Reader. При этом обе программы считали, что плагин сертифицирован. Таким образом можно было получить доступ к контенту, сделав маленькую манипуляцию по обходу подписей.
Сама подпись была сделана на основе RSA 512 (ключ 512 бит факторизовали первый раз в 1999 г.). Ключ для адобовской подписи точно также можно было факторизовать и самому подписывать плагины. То есть сама реализация механизма подписи была достаточно слабой. Компанию Adobe известили об этом, на что она ответила, что подделка подписи на плагине является нарушением лицензии на SDK и поэтому не является проблемой безопасности. Вы не можете писать плагины и подписывать их самостоятельно, не нарушив лицензию, значит, нет никакой проблемы безопасности.
Дальнейшее развитие DRM
Что успело поменяться с 2001 г. в области Digital Rights Management, что нового появилось? Например, появилась атака при помощи Rainbow Tables. Она основана на идее конца 1970-х годов, описанной Хеллманом в статье «Компромисс времени и памяти». Суть в том, что если у вас имеется большой запас времени, то некоторые операции можно предпросчитать, чтобы потом эффективнее искать ключ за более короткое время. Для 40-битового шифрования PDF была сделана реализация, которая требовала 4 Гб дискового пространства, лучше на флэшке (из-за малого времени произвольного доступа). В результате вместо 15 часов перебора на четырех компьютерах время взлома снизилось в среднем до минуты, максимум — 10 минут. То есть вы брали любое количество документов, и в среднем раз в минуту гарантированно расшифровывали любое 40-битовое шифрование.
Также компания Adobe ввела в Acrobat ключи длиной до 256 бит и алгоритм шифрования AES, который позволял с этими ключами работать. То есть появились другие алгоритмы, которые не так хорошо взламываются. Однако Adobe успела сделать пару ошибок. Я показывал, что между второй и третьей версией спецификации скорость взлома упала в 50 раз. В следующей версии спецификации они использовали другой алгоритм, с упрощенной проверкой, и скорость опять возросла, но уже в 100 раз.
Кроме того, появилась технология атаки на графических ускорителях, которая позволяла подбирать ключ еще быстрее — миллионами в секунду. В последней версии, которую выпустила Adobe, предусмотрена защита от атаки с помощью графических ускорителей — достаточно элегантное решение. Но тем не менее подбор простых паролей возможен. Если же это комбинация из 12 символов (буквы, цифры, знаки препинания), то вы его не подберете никогда. Даже восемь символов, наверное, не подберете, если поставите максимальный уровень защиты.
Перехват ключа функции MD5 в самых последних версиях Acrobat и Reader все так же успешно работает. Подделка сертификатов плагина работает условно. Adobe придумала новый способ сертификации: теперь проверяется подпись на всем файле, а не только на заголовках. Также был внедрен RSA 1024. Но для того, чтобы обеспечить обратную совместимость, разработчики оставили и старый режим. Я могу найти и исправить флаг, отвечающий за то, сертифицированный у меня режим или нет. Загружаю свой криво подписанный плагин, из плагина исправляю Acrobat, говорю, что он сертифицирован, после чего открываю файл, Acrobat его расшифровывает, и я, пользуясь SDK Acrobat, могу выгрузить контент в незащищенный файл. То есть можно обойти защиту с помощью решений, предложенных самой Adobe.
Рассмотрим еще несколько Security Handler от сторонних производителей:
- в NewStand использовался 20-битовый секрет, он очень быстро подбирался;
- в Panasonic Crypto, который использовался для защиты сервисной документации компании Panasonic, использовалось всего два константных ключа на выбор;
- в каждом из четырех плагинов компании Normex использовался свой, но константный ключ шифрования.
Компания Adobe поменяла модель лицензирования права создания Security Handler. Теперь это стоит не $100 за любое количество плагинов, а $25 тыс. за один плагин, плюс роялти с каждой проданной электронной книги. Условия кабальные, и желающих работать по этой схеме оказалось мало, наверное, поэтому очень многие компании ушли из бизнеса. К чему это приводит? Допустим, у вас есть документ, защищенный Panasonic Crypto или NewsStand, при этом обе компании уже не обеспечивают поддержку. Но когда она еще обеспечивалась, активация документа делалась для одного компьютера. За столько лет компьютер поменялся не один раз, поэтому документ открыть уже не получится, поскольку права отсутствуют, хотя они и были когда-то оплачены. Нет уже самой компании, которая осуществляла активацию по запросу. И выхода из этой ситуации нет.
Люди обращаются к Adobe, ведь PDF — ее формат. А там отвечают, что защита не их, поэтому они не причем. Извините, вам не повезло. Вот обратная сторона Digital Rights Management: вы можете в любой момент, по несчастливому стечению обстоятельств, потерять доступ к купленному контенту, и никто не гарантирует, что вы его когда-нибудь вернете.
Компания Adobe выпустила еще один продукт — программную читалку для электронных книг. Она постепенно эволюционировала в продукт под названием Adobe Digital Editions. Он написан на C и Flash, то есть это исполняемый файл плюс контент на Flash. Поддерживается два формата документов — PDF и ePub. Для PDF точно так же работает перехват ключа шифрования в функции MD5 Update. Для алгоритма ePub работает перехват в алгоритме шифрования AES. Поскольку ePub является открытым стандартом, то известно, как зашифровывается документ, известно, где описывается разрешенный тип операций, но не сказано, где хранится ключ. Однако важно лишь, что его надо в какой-то момент передать в алгоритм шифрования AES. Найдя по сигнатурам точку входа в AES, вы можете перехватить ключ и очень быстро расшифровать документ.
Один англичанин на протяжении нескольких лет развлекался тем, что писал программу, которая позволяла из защищенных LIT-документов делать незащищенные. Microsoft выпускала обновленную версию, которая блокировала работу его программы, а через неделю он выпускал новую. Через два месяца Microsoft выпускала новую версию, а тот делал ответный ход. Он всегда легко опережал Microsoft, а потом ему, видимо, это надоело.
Была и другая идея извлечения контента из защищенных документов в формате LIT. Microsoft, видимо, решила не придумывать новый формат для электронных книг. Вместо этого взяли уже существующую технологию Compound Storage. Она использовалась в большом количестве документов Microsoft, несколько реализаций было написано ими самими. В частности, старые документы Word и Excel хранились в этом формате, в нем хранится справка CHM.
Принцип работы следующий: есть функция, которая говорит: «Хочу открыть вот этот контейнер и использовать для него протокол такого идентификатора», ей передается GUID, в ответ возвращается указатель на iStorage, то есть указатель на интерфейс, в котором есть функция «Перечислить файлы», «Перечислить поддиректории» и «Открыть файл». Получив handle файла iStream, вы можете его читать, писать, позиционировать в нем указатель. Фактически, в защищенном документе точно также в какой-то момент фигурировал указатель на iStorage. Если вы его получали, например, внедрив свою DLL в адресное пространство просмотрщика, то, пользуясь этим указателем и документированными Microsoft вызовами, можно было просто взять весь контент после того, как он открылся в просмотрщике, и сохранить. По сути, Microsoft оставила достаточно удобную дверь, чтобы любой мог войти и малыми усилиями украсть контент.
Microsoft Reader LIT мало кто использовал, и десктопная версия под Windows не обновлялась с 8 июля 2003 г. Фактически, технология мертвая, поэтому много рассуждать о ней сейчас не имеет смысла.
Blue-ray
В 2006 г. на рынок был выведен Blu-ray, в котором использована Advanced Access Content System — замена CSS (Content Scrambling System). Там было специальное дерево секретов, и если у вас скомпрометирован какой-то из ключей, то во всех последующих дисках секрет просто шифровался другим ключом. То есть все старые диски, которые были созданы до того, как ключ утек, продолжали бы воспроизводиться, а все новые диски — нет.
Были реализованы водяные знаки. По расшифрованному и опубликованному в интернете фильму можно опознать и заблокировать украденный ключ. Также был разработан протокол для вывода контента только на сертифицированные устройства, например, по интерфейсу HDMI. Если у вас телевизор поддерживает спецификацию HDCP (High Definition Content Protection) и производитель купил право показывать защищенные фильмы, то этот интерфейс будет передавать данные. Если у вас на выходе пишущее устройство, то ему никто такой сертификат не выдаст, и привод Blu-ray не будет передавать на него контент. Но выяснилось, что и в High Definition Content Protection есть проблемы, и сама система Advanced Access Content System была взломана в январе 2007 г., то есть меньше чем через год после выхода на рынок. Как минимум у двух популярных плееров были отозваны ключи, потому что они были софтовые, и ключ легко извлекался. Идея, которая оказалась нерабочей в случае с DVD, оказалась такой же для Blu-ray.
Проблемы Digital Rights Management
Наверное, главная технологическая проблема — открытость платформы. Пока у меня все крутится на персональном компьютере, я имею полный контроль над происходящим, могу запустить отладчик, и производители программ для работы с защищенными документами не в силах мне помешать. То есть сделать защищенную систему на открытой платформе — это утопия.
Исключительно аппаратное решение, где шифрованием будет заниматься какая-нибудь микросхема, будет практически не поддающимся взлому. Например, в телефонах компании Apple изначально есть два ключа шифрования, которые хранятся внутри процессора, и оттуда пока никому извлечь их не удалось. К ключам можно обращаться, если вы получите доступ на уровне ядра. С джейлбрейком это более-менее реализуемо, но сами ключи узнать пока никому не удается. Было бы реализовано программно — давно вытащили бы.
Вторая проблема — универсальные форматы. Я говорил, что PDF был разработан задолго до электронных книг, как и шифрование, и интерфейсы для API плагина. А потом Adobe попыталась с минимумом дополнительных вложений сделать безопасную технологию. Так не получается. То же самое относится к Microsoft LIT, который построен на базе Compound Storage.
Еще одна проблема — так называемый Digital Millennium Copyright Act. Этот закон фактически сделал то, что не смог в 1980-х годах сделать суд с Betamax. Разработку и распространение технологий, которые могут быть использованы для нарушения авторских прав, объявили преступлением. То есть пистолеты производить все еще можно, а программы, с помощью которых можно обходить авторские права, создавать нельзя — за это можно попасть в тюрьму. Поэтому разработчики систем защиты понимают, что технология для обхода, например, защиты PDF вряд ли сможет стать публичной. А раз такую программу не выпустят на рынок, значит, мы в безопасности, можно не делать сложные системы защиты. В результате у нас иллюзия защищенности.
Если говорить про черный рынок, то электронные книги и видеофильмы взламывали, взламывают и будут взламывать. Процесс можно усложнить, но компаниям это не нужно, они все равно имеют прибыль с издателей, а не с конечных пользователей.
Альтернативны Digital Rights Management в книгоиздании
Во-первых, существуют другие модели ведения бизнеса. Например, можно издавать книги по главам. Первую главу электронной книги любой пользователь может получить бесплатно. Если ему понравится, то он платит за первую и получает бесплатно вторую. Если ему нравится вторая — он платит за вторую и получает бесплатно третью, и так до конца книги. Преимущество для пользователей неоспоримое. Если книга после второй главы оказалась ерундой, то не надо платить за все остальные главы.
Примерно такую же модель реализовала компания Apple, когда начала продавать музыку в iTunes. Раньше аудио компакт-диск стоил $12, содержал 12 треков. ITunes — $1 за песню. Разницы, вроде бы, никакой, но только на хорошем компакт-диске обычно четыре хороших песни, на плохом — две, а платите вы за все 12. В iTunes вы платите только за то, что нравится. Почему бы не сделать то же самое с электронными книгами?
Можно придумывать другие модели монетизации, но владельцы контента (как правило, это не авторы) обычно на это не идут. Было очень забавно, когда в 2003 г. на Amazon продавалась книга Кевина Митника в трех видах:
- в твердой обложке — самое дорогое издание;
- в мягкой обложке — подешевле;
- электронная версия, чтобы ее можно было читать только на одном устройстве, для которого вы ее купите. Электронная версия стоила столько же, сколько в твердой обложке, несмотря на то, что не было никаких затрат на печать.
Сейчас электронные книжки обычно стоят дешевле, чем в мягкой обложке, но цена все равно неадекватна затратам. Такова модель лицензирования: «Мы просим столько денег, потому что считаем, что это столько стоит». С этим можно соглашаться, можно не соглашаться, но они продолжают ее продвигать, хотя электронная книга могла бы быть гораздо дешевле, чем бумажная.
Я считаю, что у водяных знаков гораздо больше перспектив, чем у DRM, от которого страдают пользователи. Watermarking позволяет вам пометить каждый экземпляр издания так, чтобы было понятно, кому он был продан. И если эта версия разойдется по сети, можно будет сразу найти и привлечь к ответственности того, кто ее выложил.
Компания Penaut Press, которая в свое время публиковала книжки для наладонников Palm, использовала очень оригинальную модель защиты контента. На первой странице каждой книги указывался номер кредитной карты человека, который эту книгу купил. Если вам нравится, чтобы ваш номер кредитной карты был доступен всем — пожалуйста, отдайте этот файл, он будет читаться на любом устройстве, никакой защиты нет. Водяные знаки также используются для психологического сдерживания. Другое дело, что наказать автора программы, выложенной в интернете, гораздо проще, чем человека, выложившего книгу. Потому что у автора программы есть какие-то зацепки — сервер, откуда пользователи качают программу, биллинг, через который ему платят. А человек, который взломал книгу и выложил ее, достаточно легко может сохранить анонимность. Он может жить в другой стране. Поэтому сегодня пытаются наказывать программистов, а не тех, кто реально нарушает закон «Об авторском праве».
Концепция FairPlay — честной игры
Если я не ошибаюсь, то несколько лет назад Apple отказалась от защиты музыки — ее можно воспроизводить на любом устройстве. Видеофильмы еще продолжают защищать, как и электронные книги в iBooks. По большому счету, у пользователя есть много прав на обращение с купленным контентом. В частности, те же американские законы подразумевают право на цитирование. Я могу прийти в любую библиотеку, взять любую бумажную книгу, отсканировать из нее две-три страницы, потом перебить их в свою какую-то научную публикацию и опубликовать, просто скопировав контент из бумажной книги — это разрешено законом. А если я всю книгу скопирую и издам — это будет являться плагиатом. Но если я делаю цитату на две страницы — это нормально, если цитата почему-то важна.
С электронной книгой так не получится, потому что автор не разрешил копировать из документа. Поэтому меня ограничили в тех правах, которые, по большому счету, предусмотрены Конституцией. По-хорошему, надо как-то это реализовывать. Как? Не знаю. Но, на мой взгляд, над этим стоит работать.
