В целом, системы управления реляционными базами данных были задуманы как «один-размер-подходит-всем решение для хранения и получения данных» на протяжении десятилетий. Но растущая необходимость в масштабируемости и новые требования приложений создали новые проблемы для традиционных систем управления РСУБД, включая некоторую неудовлетворенность подходом «один-размер-подходит-всем» в ряде масштабируемых приложений.
Ответом на это было новое поколение легковесных, высокопроизводительных баз данных, созданных для того, чтобы бросить вызов господству реляционных баз данных.
Большой причиной для движения NoSQL послужил тот факт, что различные реализации веб, корпоративных и облачных приложений имеют различные требования к их базам.
Пример: для таких объемных сайтов, как eBay, Amazon, Twitter, или Facebook, масштабируемость и высокая доступность являются основными требованиями, которые не могут быть скомпрометированы. Для этих приложений даже малейшее отключение может иметь значительные финансовые последствия и влияние на доверие клиентов.
Таким образом, готовое решение базы данных зачастую должно решать вопросы не только транзакционной целостности, но более того, более высокие объемы данных, увеличение скорости и производительности данных, и растущее разнообразие форматов. Появились новые технологии, которые специализируются на оптимизации по одному, или двум из вышеупомянутых аспектов, жертвуя другими. Postgres с JSON применяет более целостный подход к потребностям пользователей, успешнее решая большинство рабочих нагрузок NoSQL.
Умный подход новой технологии опирается на тесную оценку ваших потребностей, с инструментами, доступными для достижения этих потребностей. В приведенной ниже таблице сравниваются характеристики нереляционной документо-ориентированная базы (такая как MongoDB) и характеристики Postgres'овской реляционной/документо-ориентированной базы данных, дабы помочь Вам найти правильное решение для ваших потребностей.
Источник: сайт EnterpriseDB.
Документ в MongoDB автоматически снабжается полем _id, если оно не присутствует. Когда Вы хотите получить этот документ, Вы можете использовать _id — он ведет себя в точности как первичный ключ в реляционных базах данных. PostgreSQL хранит данные в полях таблиц, MongoDB хранит их в виде JSON документов. С одной стороны, MongoDB выглядит как прекрасное решение, так как вы можете иметь все различные данные из нескольких таблиц в PostgreSQL в одном JSON документе. Эта гибкость достигается отсутствием ограничений на структуре данных, которые могут быть действительно привлекательными в первый момент и реально ужасающими на большой базе данных, в которой некоторые записи имеют неправильные значения, или пустые поля.
PostgreSQL 9.3 идет в комплекте с прекрасным функционалом, который позволяет превратить его в NoSQL базу данных, с полной поддержкой транзакций и хранением JSON документов с ограничениями на полях с данными.
Я покажу как это сделать, используя очень простой пример таблицы Служащих. Каждый Служащий имеет имя, описание, некий номер id и зарплату.
Версия PostgreSQL
Простая таблица в PostgreSQL может выглядеть следующим образом:
Эта таблица позволяет нам добавлять служащих вот так:
Увы, вышеприведенная таблица позволяет добавлять пустые строки без некоторых важных значений:
Этого можно избежать, добавив ограничения в базу данных. Предположим что мы всегда хотим иметь непустое уникальное имя, непустое описание, не негативную зарплату. Такая таблица с ограничениями будет выглядеть:
Теперь все операции, такие как добавление, или обновление записи, которые противоречат каким-то из этих ограничений, будут отваливаться с ошибкой. Давайте проверим:
NoSQL версия
В MongoDB, запись из таблицы выше будет выглядеть как следующий JSON документ:
подобным образом, в PostgreSQL мы можем сохранить эту запись как строку в таблице emp:
Это работает как в большинстве нереляционных баз данных, никаких проверок, никаких ошибок с плохими полями. В результате, вы можете преобразовывать данные как захотите, проблемы начинаются тогда, когда ваше приложение ожидает что зарплата это число, а на деле это либо строка, либо она вообще отсутствует.
Проверяя JSON
В PostgreSQL 9.2 для этих целей есть хороший тип данных, он называется JSON. Этот тип может хранить в себе только корректный JSON, перед преобразованием в этот тип происходит проверка на валидность.
Давайте изменим описание таблицы на:
Мы можем добавить какой-нибудь корректный JSON в эту таблицу:
Это сработает, а вот добавление некорректного JSONa завершится ошибкой:
Проблема с форматированием может быть трудно заметной (я добавил запятую в последнюю строку, JSONу это не нравится).
Проверяя поля
Итак, у нас имеется решение, которое выглядит почти как первое чистое PostgreSQL решение: у нас есть данные, которые проверяются. Это не значит, что данные имеют смысл. Давайте добавим проверки для валидации данных. В PostgreSQL 9.3 имеется новый мощный функционал для управления JSON объектами. Есть определенные операторы для типа JSON, которые дадут Вам легкий доступ к полям и значениям. Я буду использовать только оператор "->>", но Вы можете найти больше информации в документации Postgres.
Кроме того, мне необходимо проверять типы полей, включая поле id. Это то, что Postgres просто проверяет из-за определения типов данных. Я буду использовать другой синтаксис для проверок, так как я хочу дать ему имя. Будет намного проще искать проблему в конкретном поле, а не по всему огромному JSON документу.
Таблица с ограничениями будет выглядеть следующим образом:
Оператор "->>" позволяет мне извлекать значение из нужного поля JSON'a, проверять существует ли оно и его валидность.
Давайте добавим JSON без описания:
Осталась еще одна проблема. Поля name и id должны быть уникальными. Этого легко добиться следующим образом:
Теперь, если попробовать добавить JSON документ в базу, id которого уже содержится в базе, то появится следующая ошибка:
Производительность
PostgreSQL справляется с самыми требовательными запросами крупнейших страховых компаний, банков, брокерских, государственных учреждений, и оборонных подрядчиков в мире на сегодняшний, равно как и справлялся на протяжении многих лет. Улучшения производительности PostgreSQL непрерывны с ежегодным выпуском версий, и включают в себя улучшения и для его неструктурированных типов данных в том числе.

Источник: EnterpriseDB White Paper: Используя возможности NoSQL в Postgres
Чтобы собственноручно испытать производительность NoSQL в PostgreSQL, скачайте pg_nosql_benchmark с GitHub.
Ответом на это было новое поколение легковесных, высокопроизводительных баз данных, созданных для того, чтобы бросить вызов господству реляционных баз данных.
Большой причиной для движения NoSQL послужил тот факт, что различные реализации веб, корпоративных и облачных приложений имеют различные требования к их базам.
Пример: для таких объемных сайтов, как eBay, Amazon, Twitter, или Facebook, масштабируемость и высокая доступность являются основными требованиями, которые не могут быть скомпрометированы. Для этих приложений даже малейшее отключение может иметь значительные финансовые последствия и влияние на доверие клиентов.
Таким образом, готовое решение базы данных зачастую должно решать вопросы не только транзакционной целостности, но более того, более высокие объемы данных, увеличение скорости и производительности данных, и растущее разнообразие форматов. Появились новые технологии, которые специализируются на оптимизации по одному, или двум из вышеупомянутых аспектов, жертвуя другими. Postgres с JSON применяет более целостный подход к потребностям пользователей, успешнее решая большинство рабочих нагрузок NoSQL.
Сравнение документо-ориентированных/реляционных баз данных
Умный подход новой технологии опирается на тесную оценку ваших потребностей, с инструментами, доступными для достижения этих потребностей. В приведенной ниже таблице сравниваются характеристики нереляционной документо-ориентированная базы (такая как MongoDB) и характеристики Postgres'овской реляционной/документо-ориентированной базы данных, дабы помочь Вам найти правильное решение для ваших потребностей.
| Особенности | MongoDB | PostgreSQL |
| Начало Open Source разработки | 2009 | 1995 |
| Схемы | Динамическая | Статическая и динамическая |
| Поддержка иерархических данных | Да | Да (с 2012) |
| Поддержка «ключ-событие» данных | Да | Да (с 2006) |
| Поддержка реляционных данных / нормализованной формы хранения | Нет | Да |
| Ограничения данных | Нет | Да |
| Объединение данных и внешние ключи | Нет | Да |
| Мощный язык запросов | Нет | Да |
| Поддержка транзакций и Управление конкурентным доступом с помощью многоверсионности | Нет | Да |
| Атомарные транзакции | Внутри документа | По всей базе |
| Поддерживаемые языки веб-разработки | JavaScript, Python, Ruby, и другие… | JavaScript, Python, Ruby, и другие… |
| Поддержка общих форматов данных | JSON (Document), Key-Value, XML | JSON (Document), Key-Value, XML |
| Поддержка пространственных данных | Да | Да |
| Самый простой способ масштабирования | Горизонтальное масштабирование | Вертикальное масштабирвоание |
| Шардинг | Простой | Сложный |
| Программирование на стороне сервера | Нет | Множество процедурных языков, таких как Python, JavaScript, C,C++, Tcl, Perl и многие, многие другие |
| Простая интеграция с другими источниками данных | Нет | Внешние сборщики данных из Oracle, MySQL, MongoDB, CouchDB, Redis, Neo4j, Twitter, LDAP, File, Hadoop и других… |
| Бизнес логика | Распределена по клиентским приложениям | Централизована с триггерами и хранимыми процедурами, или распределена по клиентским приложениям |
| Доступность обучающих ресурсов | Трудно найти | Легко найти |
| Первичное использование | Большие данные (миллиарды записей) с большим количеством параллельных обновлений, где целостность и согласованность данных не требуется. | Транзакционные и операционные приложения, выгода которых в нормализованной форме, объединениях, ограничениях данных и поддержке транзакций. |
Источник: сайт EnterpriseDB.
Документ в MongoDB автоматически снабжается полем _id, если оно не присутствует. Когда Вы хотите получить этот документ, Вы можете использовать _id — он ведет себя в точности как первичный ключ в реляционных базах данных. PostgreSQL хранит данные в полях таблиц, MongoDB хранит их в виде JSON документов. С одной стороны, MongoDB выглядит как прекрасное решение, так как вы можете иметь все различные данные из нескольких таблиц в PostgreSQL в одном JSON документе. Эта гибкость достигается отсутствием ограничений на структуре данных, которые могут быть действительно привлекательными в первый момент и реально ужасающими на большой базе данных, в которой некоторые записи имеют неправильные значения, или пустые поля.
PostgreSQL 9.3 идет в комплекте с прекрасным функционалом, который позволяет превратить его в NoSQL базу данных, с полной поддержкой транзакций и хранением JSON документов с ограничениями на полях с данными.
Простой пример
Я покажу как это сделать, используя очень простой пример таблицы Служащих. Каждый Служащий имеет имя, описание, некий номер id и зарплату.
Версия PostgreSQL
Простая таблица в PostgreSQL может выглядеть следующим образом:
CREATE TABLE emp (
id SERIAL PRIMARY KEY,
name TEXT,
description TEXT,
salary DECIMAL(10,2)
);
Эта таблица позволяет нам добавлять служащих вот так:
INSERT INTO emp (name, description, salary) VALUES ('raju', ' HR', 25000.00);
Увы, вышеприведенная таблица позволяет добавлять пустые строки без некоторых важных значений:
INSERT INTO emp (name, description, salary) VALUES (null, -34, 'sdad');
Этого можно избежать, добавив ограничения в базу данных. Предположим что мы всегда хотим иметь непустое уникальное имя, непустое описание, не негативную зарплату. Такая таблица с ограничениями будет выглядеть:
CREATE TABLE emp (
id SERIAL PRIMARY KEY,
name TEXT UNIQUE NOT NULL,
description TEXT NOT NULL,
salary DECIMAL(10,2) NOT NULL,
CHECK (length(name) > 0),
CHECK (description IS NOT NULL AND length(description) > 0),
CHECK (salary >= 0.0)
);
Теперь все операции, такие как добавление, или обновление записи, которые противоречат каким-то из этих ограничений, будут отваливаться с ошибкой. Давайте проверим:
INSERT INTO emp (name, description, salary) VALUES ('raju', 'HR', 25000.00);
--INSERT 0 1
INSERT INTO emp (name, description, salary) VALUES ('raju', 'HR', -1);
--ERROR: new row for relation "emp" violates check constraint "emp_salary_check"
--DETAIL: Failing row contains (2, raju, HR, -1).
NoSQL версия
В MongoDB, запись из таблицы выше будет выглядеть как следующий JSON документ:
{
"id": 1,
"name": "raju",
"description": "HR,
"salary": 25000.00
}
подобным образом, в PostgreSQL мы можем сохранить эту запись как строку в таблице emp:
CREATE TABLE emp (
data TEXT
);
Это работает как в большинстве нереляционных баз данных, никаких проверок, никаких ошибок с плохими полями. В результате, вы можете преобразовывать данные как захотите, проблемы начинаются тогда, когда ваше приложение ожидает что зарплата это число, а на деле это либо строка, либо она вообще отсутствует.
Проверяя JSON
В PostgreSQL 9.2 для этих целей есть хороший тип данных, он называется JSON. Этот тип может хранить в себе только корректный JSON, перед преобразованием в этот тип происходит проверка на валидность.
Давайте изменим описание таблицы на:
CREATE TABLE emp (
data JSON
);
Мы можем добавить какой-нибудь корректный JSON в эту таблицу:
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"salary": 25000.00
}');
--INSERT 0 1
SELECT * FROM emp;
{ +
"id": 1, +
"name": "raju", +
"description": "HR",+
"salary": 25000.00 +
}
--(1 row)
Это сработает, а вот добавление некорректного JSONa завершится ошибкой:
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"price": 25000.00,
}');
--ERROR: invalid input syntax for type json
Проблема с форматированием может быть трудно заметной (я добавил запятую в последнюю строку, JSONу это не нравится).
Проверяя поля
Итак, у нас имеется решение, которое выглядит почти как первое чистое PostgreSQL решение: у нас есть данные, которые проверяются. Это не значит, что данные имеют смысл. Давайте добавим проверки для валидации данных. В PostgreSQL 9.3 имеется новый мощный функционал для управления JSON объектами. Есть определенные операторы для типа JSON, которые дадут Вам легкий доступ к полям и значениям. Я буду использовать только оператор "->>", но Вы можете найти больше информации в документации Postgres.
Кроме того, мне необходимо проверять типы полей, включая поле id. Это то, что Postgres просто проверяет из-за определения типов данных. Я буду использовать другой синтаксис для проверок, так как я хочу дать ему имя. Будет намного проще искать проблему в конкретном поле, а не по всему огромному JSON документу.
Таблица с ограничениями будет выглядеть следующим образом:
CREATE TABLE emp (
data JSON,
CONSTRAINT validate_id CHECK ((data->>'id')::integer >= 1 AND (data->>'id') IS NOT NULL ),
CONSTRAINT validate_name CHECK (length(data->>'name') > 0 AND (data->>'name') IS NOT NULL )
);
Оператор "->>" позволяет мне извлекать значение из нужного поля JSON'a, проверять существует ли оно и его валидность.
Давайте добавим JSON без описания:
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "",
"salary": 1.0
}');
--ERROR: new row for relation "emp" violates check constraint "validate_name"
Осталась еще одна проблема. Поля name и id должны быть уникальными. Этого легко добиться следующим образом:
CREATE UNIQUE INDEX ui_emp_id ON emp((data->>'id'));
CREATE UNIQUE INDEX ui_emp_name ON emp((data->>'name'));
Теперь, если попробовать добавить JSON документ в базу, id которого уже содержится в базе, то появится следующая ошибка:
--ERROR: duplicate key value violates unique constraint "ui_emp_id"
--DETAIL: Key ((data ->> 'id'::text))=(1) already exists.
--ERROR: current transaction is aborted, commands ignored until end of transaction block
Производительность
PostgreSQL справляется с самыми требовательными запросами крупнейших страховых компаний, банков, брокерских, государственных учреждений, и оборонных подрядчиков в мире на сегодняшний, равно как и справлялся на протяжении многих лет. Улучшения производительности PostgreSQL непрерывны с ежегодным выпуском версий, и включают в себя улучшения и для его неструктурированных типов данных в том числе.
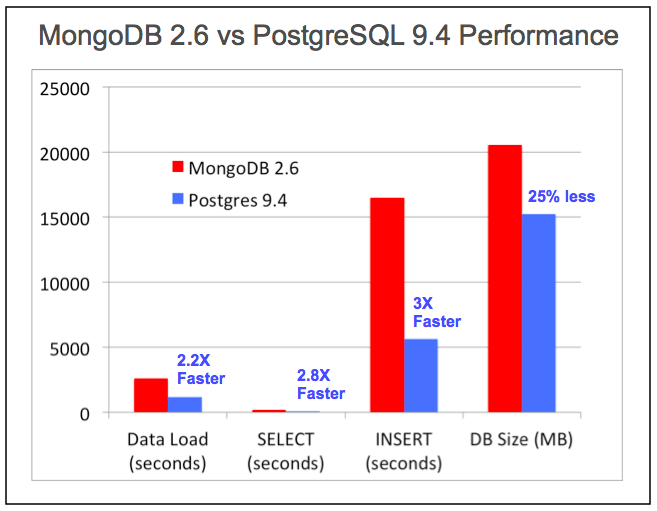
Источник: EnterpriseDB White Paper: Используя возможности NoSQL в Postgres
Чтобы собственноручно испытать производительность NoSQL в PostgreSQL, скачайте pg_nosql_benchmark с GitHub.
