Добрый день, коллеги.
Сегодня я расскажу о не совсем простой концепции быстрого (до часа после нескольких тренировок) развёртывания проекта для работы команды, состоящей как минимум из отдельных фронтенд и бэкенд разработчиков.
Исходные данные у нас такие: начинается разработка проекта, в которой планируется «тонкий бэкенд». Т.е. бэк у нас состоит из закешированных страниц (рендерятся любым шаблонизатором), объёмных моделей с сопутствующей логикой (ORM) и REST API, выполняющего роль контроллера. Фактически, View в такой системе редуцировано и вынесено в JS, благо есть разные реакты, ангуляры и прочие вещи, которые позволяют фронтендщикам считать себя «белыми людьми».
Среда разработки у нас выглядит так: Ubuntu LTS (14.04), PyCharm, Python любой версии (мы возьмём 2.7 для запуска виртуальной среды, на которой будет стоять аналогичная версия). Django (1.8)
Решаем мы следующие проблемы:
Для нашего приложения мы будем использовать Docker. Об этом инструменте на Хабре сказано много. Сразу оговорюсь, что мы пока не планируем усложнять Production сервер. Нам важно построить среду разработки с заделом на последующее применение концепции CI. Но, в рамках текущей статьи будем работать только с docker-compose и не затронем методы быстрого деплоймента. Благо, у Docker таковых имеется в избытке.
Docker может с переменным успехом устанавливаться на Mac и Windows машины. Но мы рассмотрим его установку на Ubuntu 14.04. Есть инструкция по установке Docker на этой системе, но она может вызвать проблемы. От части, можно списать их на нотик из этой инструкции:
Поэтому, не выпендриваемся и ставим так, как рекомендует другая инструкция:
И проверяем установку командой:
Теперь создадим виртуальную среду для запуска Docker:
Откроем PyCharm и создадим проект для работы.
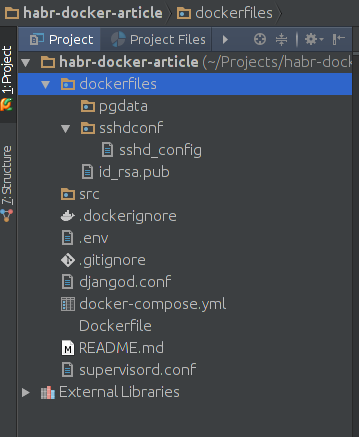
Проект создаём для любого интерпретатора. Пусть это будет pure python проект. На схеме выше вы видите минимальный состав проекта. За запуск сервера у нас будет отвечать supervisord. Файлы .gitignore и .dockerignore позволят указать те файлы, которые не будут закоммичены в репозиторий проекта или не будут смонтированы в docker контейнеры. Контейнерами будет управлять файл docker-compose.yml, поскольку он прост как палка и эффективен как автомат Калашникова. Для основного проекта мы дополнительно создадим Dockerfile, чтобы установить отсутствующие библиотеки.
Папка dockerfiles имеет подпапку pgdata — в ней у нас будет храниться БД от PostgreSQL на случай, если мы захотим перенести данные из одного места в другое. В dockerfiles/sshdconf поместим настройки для SSH сервера. Для прямого соединения он нам не понадобится, но для настройки окружения в PyCharm — ещё как. Ключ id_rsa.pub позволит PyCharm соединяться с контейнером без плясок вокруг пароля. Всё что вам нужно — это создать связку SSH ключей и скопировать (или перенести) публичный ключ в директорию dockerfiles.
Директория src — корень нашего проекта. Сейчас наша задача — развернуть контейнеры.
Файл docker-compose.yml будет у нас выглядеть так:
Обратите внимание на первый контейнер — postgresql. Ему мы однозначно передаём .env для формирования первичных данных. Директива ports отвечает за проброс портов. Первая цифра перед двоеточием — номер порта, по которому будет доступна эта база в нашей убунте. Вторая цифра — это номер порта, который пробрасывается с контейнера. Дефолтный PostgreSQL порт
Второй контейнер будем собирать из Dockerfile. Поэтому, здесь стоит build. Команда запуска идёт с небольшой задержкой — на случай, если нам нужно будет время для запуска БД и других инструментов внутри контейнеров. Здесь же видим все подключаемые директории и файлы. При пробросе портов имеем порт 2225 — для SSH и 8005 — для сервера. В sshd_config нам нужно настроить под себя вот эти директивы:
PermitRootLogin without-password
StrictModes no
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile %h/.ssh/authorized_keys
Помните, что всё это добро будет работать только у команды разработчиков. На продакшн мы это не выложим. Хотя, в принципе, ssh сервер будет доступен только локально.
/home/USERNAME/.pycharm_helpers/:/root/.pycharm_helpers/ — Эта команда на монтирование позволит нам запускать тесты и дебаг прямо из PyCharm. Не забудьте прописать тут свой USERNAME
В supervisord.conf пропишем следующее:
[unix_http_server]
file=/opt/project/daemons/supervisor.sock; path to your socket file
[supervisord]
logfile=/opt/project/logs/supervisord.log; supervisord log file
logfile_maxbytes=50MB; maximum size of logfile before rotation
logfile_backups=10; number of backed up logfiles
loglevel=info; info, debug, warn, trace
pidfile=/opt/project/daemons/supervisord.pid; pidfile location
nodaemon=false; run supervisord as a daemon
minfds=1024; number of startup file descriptors
minprocs=200; number of process descriptors
user=root; default user
childlogdir=/opt/project/logs/; where child log files will live
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///opt/project/daemons/supervisor.sock; use unix:// schem for a unix sockets.
[include]
# Uncomment this line for celeryd for Python
files=djangod.conf
В djangod.conf:
[program:django_project]
command=python /opt/project/manage.py runserver 0.0.0.0:8000
directory=/opt/project/
stopasgroup=true
stdout_logfile=/opt/project/logs/django.log
stderr_logfile=/opt/project/logs/django_err.log
Тот кто внимательно читает конфиги, должен обратить внимание на то, что мы объявили две не созданные ещё папки. Так что создадим в src директории logs и daemons. В .gitignore добавим соответственно /src/logs/* и /src/daemons/*
Обратите внимание на то, что в django, обычно, stdout_logfile не пишется. Все логи осыпаются в stderr_logfile. Настройка была взята из какой-то готовой инструкции, а удалять строчку не слишком хочется, ведь stdout_logfile — довольно стандартная директива.
Теперь не забудем про наш .env файл:
POSTGRES_USER=habrdockerarticle
POSTGRES_DB=habrdockerarticle
POSTGRES_PASSWORD=qwerty
POSTGRES_HOST=postgresql
POSTGRES_PORT=5432
PGDATA=/var/lib/postgresql/data/pgdata
C_FORCE_ROOT=true
Его можно добавить или не добавлять в .gitignore — значения не имеет.
В конце заполним Dockerfile
FROM python:2.7
RUN apt-get update && apt-get install -y openssh-server \
&& apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false -o APT::AutoRemove::SuggestsImportant=false $buildDeps
COPY ./src/requirements.txt ./requirements.txt
RUN pip install -r requirements.txt
Docker Hub не скрывает от нас того, что наш контейнер будет обслуживаться Debian Jessie. В Dockerfile мы запланировали установку ssh сервера, чистку ненужных нам списков пакетов и установку requirements. Кстати, файл зависимостей у нас ещё не создан. Надо исправить этот недочёт и создать requirements.txt в папке src:
Django==1.8
psycopg2
supervisor
Проект готов к первому запуску! Запускать будем поочерёдно. Сперва выполним:
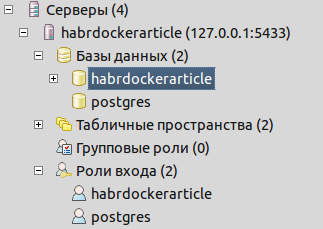
Эта операция скачает нам образ, необходимый для запуска postgresql сервера. Сервер запустится, пользователь и база, указанные в .env создадутся автоматически. Команда заблокирует нам ввод данных, но пока не будем её останавливать. Убедимся в наличии базы и ролей входа, подключившись через pgadmin
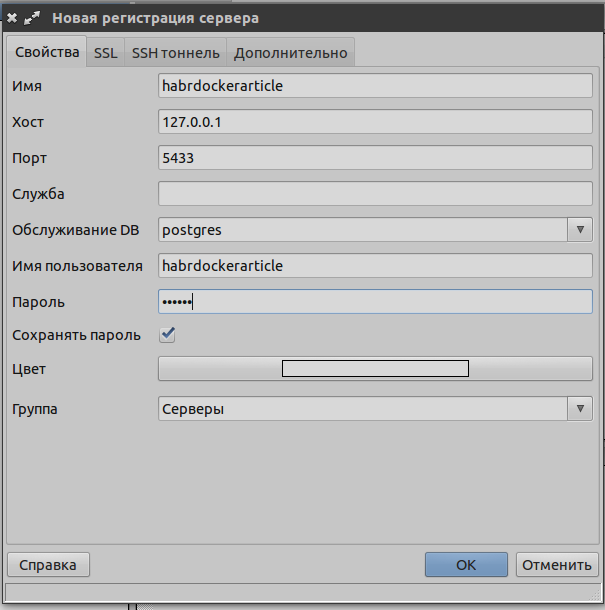
Как мы видим, всё уже создано для работы:
Теперь комбинацией клавиш ctrl+C в консоли остановим процесс. Нам надо собрать образ проекта. Так что выполним:
Эта команда соберёт нам проект, а также, выполнит все команды из Dockerfile. Т.е. у нас будет установлен ssh сервер, а также, установлены зависимости из requirements.txt. Теперь у нас возникает вопрос создания Django проекта. Создать его можно нескольким способами. Самый пуленепробиваемый — это поставить в нашу docker virtualenv на убунте нужную версию Django:
Django из venv можно удалить или оставить для других проектов. Всё что нам осталось — это перенести внутренности проекта в корень папки src.
Теперь нам следует проверить наш проект и настроить соединение с БД. Сперва поменяем настройки в settings.py:
Потом запустим контейнеры проекта:
И убедимся в положительном результате:
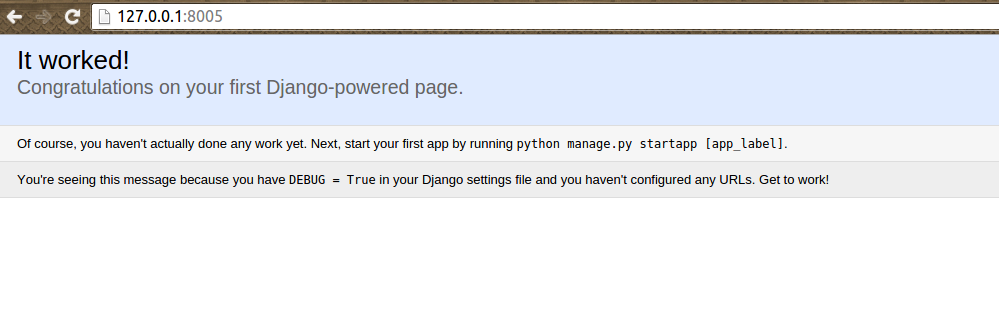
Для остановки проекта и удаления временных файлов можно использовать:
Если у нас меняется что-то в requirements.txt, используем следующую команду для быстрого пересбора
Давайте, проверим какая структура проекта у нас получилась:
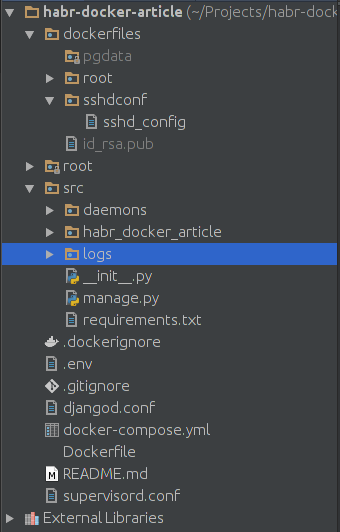
Папка root в моём коде содержит готовые helpers PyCharm'а.
Теперь можно сделать то, ради чего мы всё это и затевали — подключить Gulp для управления статикой. Файл docker-compose.yml теперь будет выглядеть так:
Я добавил новый контейнер и указал его в зависимостях к project.
Теперь мне нужно создать папку gulp в src для исходников и static/scripts для скомпилированных файлов. В папке src/gulp создадим файл package.json со следующим содержимым:
Создадим gulpfile.js. в папке src/gulp. Я использовал свой старый файл для образца:
Как мы видим из конфига, нам следует залить в папку src/gulp/front некоторые популярные библиотеки и создать папку src/gulp/front/project для написанных JS программистом скриптов. Также, не забываем о создании Dockerfile в src/gulp
FROM neo9polska/nodejs-bower-gulp
COPY package.json ./package.json
COPY node_modules ./node_modules
RUN npm install --verbose
Теперь довольно важный вопрос — node_modules. Без этой папки контейнер с Gulp будет откровенно лажать. Здесь у нас два варианта получения этой папки:
Однако, менять права не обязательно. Просто разработчики будут вынуждены постоянно выполнять команду на пересборку gulp. Впрочем, весь код, описанный в статье, я выложу на Github и можно взять node_modules оттуда. Проблема эта связана с docker-compose. Но победить её легко.
Итак, в результате запуска контейнеров
Мы должны получить вот такой скомпилированный файл:
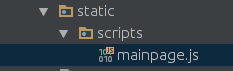 .
.
Готово! Проект можно залить в git и начинать работать с ним.
Полная команда перезапуска с пересборкой выглядит так:
Для запуска проекта у нового участника процесса достаточно выполнить:
Для просмотра основного журнала контейнера с запущенным приложением:
Логи Django из project пишутся в папку src/logs.
Исходный код проекта вы можете посмотреть в моём GitHub.
P.S. Ещё один важный аспект — настройка интерпретатора python в PyCharm. Для этой настройки достаточно добавить remote interpreter:
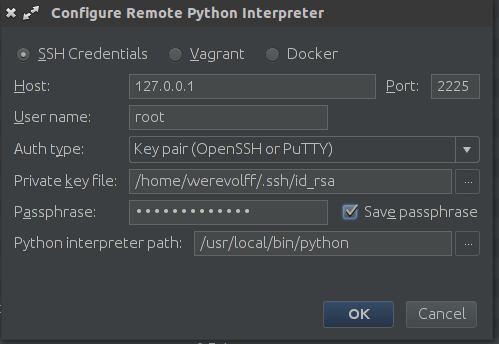
И обратите внимание на то, что PyCharm имеет плагин для интеграции с Docker. Мы же используем SSH соединение, поскольку не затрагивали вопрос развёртывания проекта на docker-machine.
Сегодня я расскажу о не совсем простой концепции быстрого (до часа после нескольких тренировок) развёртывания проекта для работы команды, состоящей как минимум из отдельных фронтенд и бэкенд разработчиков.
Исходные данные у нас такие: начинается разработка проекта, в которой планируется «тонкий бэкенд». Т.е. бэк у нас состоит из закешированных страниц (рендерятся любым шаблонизатором), объёмных моделей с сопутствующей логикой (ORM) и REST API, выполняющего роль контроллера. Фактически, View в такой системе редуцировано и вынесено в JS, благо есть разные реакты, ангуляры и прочие вещи, которые позволяют фронтендщикам считать себя «белыми людьми».
Среда разработки у нас выглядит так: Ubuntu LTS (14.04), PyCharm, Python любой версии (мы возьмём 2.7 для запуска виртуальной среды, на которой будет стоять аналогичная версия). Django (1.8)
Решаем мы следующие проблемы:
- Необходимо полностью эмулировать пространство Production, а ещё лучше — поставлять код участникам процесса разработки вместе со средой.
- Необходимо отделить среду выполнения нашего проекта от среды операционной системы. Нам нафиг не нужны проблемы с версиями пайтона, настройками node.js или развёртыванием БД. Пусть наша настольная система будет чистой и светлой.
- Необходимо автоматизировать развёртывание проекта, над которым будет трудиться ещё и гуру JS, и, возможно, крутой верстальщик. Да так, чтобы проект можно было поднять и у тестировщика, и у менеджера с начальными знаниями в технической области.
- Необходимо без особых проблем отделить dev версию от production. Даунтайм должен быть минимальным. Никто не будет ждать, пока ведущий программист исправит все переменные в settings и пофиксит прочие проблемы.
- Нужно сделать так, чтобы участники разработки не решали проблемы друг-друга. JS разработчик не должен вникать в тонкости запуска Celery, слияния JS файлов и т.д. Верстальщика не должно интересовать что компилирует его Sass код и т.д. Это относится к автоматизации развёртывания, но важно подчеркнуть, что эти проблемы могут создать неудобство и потребуется тратить время на написание подробной инструкции по развёртыванию, если оно будет происходить в ручном режиме.
Установка Docker
Для нашего приложения мы будем использовать Docker. Об этом инструменте на Хабре сказано много. Сразу оговорюсь, что мы пока не планируем усложнять Production сервер. Нам важно построить среду разработки с заделом на последующее применение концепции CI. Но, в рамках текущей статьи будем работать только с docker-compose и не затронем методы быстрого деплоймента. Благо, у Docker таковых имеется в избытке.
Docker может с переменным успехом устанавливаться на Mac и Windows машины. Но мы рассмотрим его установку на Ubuntu 14.04. Есть инструкция по установке Docker на этой системе, но она может вызвать проблемы. От части, можно списать их на нотик из этой инструкции:
Note: Ubuntu Utopic 14.10 exists in Docker’s apt repository but it is no longer officially supported.
Поэтому, не выпендриваемся и ставим так, как рекомендует другая инструкция:
$ sudo apt-get update
$ sudo apt-get install wget
wget -qO- https://get.docker.com/ | sh
И проверяем установку командой:
$ docker run hello-world
Теперь создадим виртуальную среду для запуска Docker:
$ mkdir ~/venvs
$ virtualenv ~/venvs/docker
$ source ~/venvs/docker/bin/activate
(docker) $ pip install docker-compose
(docker) $ docker-compose -v
Создаём проект
Откроем PyCharm и создадим проект для работы.

Проект создаём для любого интерпретатора. Пусть это будет pure python проект. На схеме выше вы видите минимальный состав проекта. За запуск сервера у нас будет отвечать supervisord. Файлы .gitignore и .dockerignore позволят указать те файлы, которые не будут закоммичены в репозиторий проекта или не будут смонтированы в docker контейнеры. Контейнерами будет управлять файл docker-compose.yml, поскольку он прост как палка и эффективен как автомат Калашникова. Для основного проекта мы дополнительно создадим Dockerfile, чтобы установить отсутствующие библиотеки.
Папка dockerfiles имеет подпапку pgdata — в ней у нас будет храниться БД от PostgreSQL на случай, если мы захотим перенести данные из одного места в другое. В dockerfiles/sshdconf поместим настройки для SSH сервера. Для прямого соединения он нам не понадобится, но для настройки окружения в PyCharm — ещё как. Ключ id_rsa.pub позволит PyCharm соединяться с контейнером без плясок вокруг пароля. Всё что вам нужно — это создать связку SSH ключей и скопировать (или перенести) публичный ключ в директорию dockerfiles.
Директория src — корень нашего проекта. Сейчас наша задача — развернуть контейнеры.
Создаём контейнеры
Файл docker-compose.yml будет у нас выглядеть так:
postgresql:
image: postgres:9.3
env_file: .env
volumes:
- ./dockerfiles/pgdata:/var/lib/postgresql/data/pgdata
ports:
- "5433:5432"
project:
build: ./
env_file: .env
working_dir: /opt/project
command: bash -c "sleep 3 && /etc/init.d/ssh start && supervisord -n"
volumes:
- ./src:/opt/project
- ./dockerfiles/sshdconf/sshd_config:/etc/ssh/sshd_config
- ./dockerfiles/id_rsa.pub:/root/.ssh/authorized_keys
- /home/USERNAME/.pycharm_helpers/:/root/.pycharm_helpers/
- ./supervisord.conf:/etc/supervisord.conf
- ./djangod.conf:/etc/djangod.conf
links:
- postgresql
ports:
- "2225:22"
- "8005:8000"
Обратите внимание на первый контейнер — postgresql. Ему мы однозначно передаём .env для формирования первичных данных. Директива ports отвечает за проброс портов. Первая цифра перед двоеточием — номер порта, по которому будет доступна эта база в нашей убунте. Вторая цифра — это номер порта, который пробрасывается с контейнера. Дефолтный PostgreSQL порт
Второй контейнер будем собирать из Dockerfile. Поэтому, здесь стоит build. Команда запуска идёт с небольшой задержкой — на случай, если нам нужно будет время для запуска БД и других инструментов внутри контейнеров. Здесь же видим все подключаемые директории и файлы. При пробросе портов имеем порт 2225 — для SSH и 8005 — для сервера. В sshd_config нам нужно настроить под себя вот эти директивы:
PermitRootLogin without-password
StrictModes no
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile %h/.ssh/authorized_keys
Помните, что всё это добро будет работать только у команды разработчиков. На продакшн мы это не выложим. Хотя, в принципе, ssh сервер будет доступен только локально.
/home/USERNAME/.pycharm_helpers/:/root/.pycharm_helpers/ — Эта команда на монтирование позволит нам запускать тесты и дебаг прямо из PyCharm. Не забудьте прописать тут свой USERNAME
В supervisord.conf пропишем следующее:
[unix_http_server]
file=/opt/project/daemons/supervisor.sock; path to your socket file
[supervisord]
logfile=/opt/project/logs/supervisord.log; supervisord log file
logfile_maxbytes=50MB; maximum size of logfile before rotation
logfile_backups=10; number of backed up logfiles
loglevel=info; info, debug, warn, trace
pidfile=/opt/project/daemons/supervisord.pid; pidfile location
nodaemon=false; run supervisord as a daemon
minfds=1024; number of startup file descriptors
minprocs=200; number of process descriptors
user=root; default user
childlogdir=/opt/project/logs/; where child log files will live
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///opt/project/daemons/supervisor.sock; use unix:// schem for a unix sockets.
[include]
# Uncomment this line for celeryd for Python
files=djangod.conf
В djangod.conf:
[program:django_project]
command=python /opt/project/manage.py runserver 0.0.0.0:8000
directory=/opt/project/
stopasgroup=true
stdout_logfile=/opt/project/logs/django.log
stderr_logfile=/opt/project/logs/django_err.log
Тот кто внимательно читает конфиги, должен обратить внимание на то, что мы объявили две не созданные ещё папки. Так что создадим в src директории logs и daemons. В .gitignore добавим соответственно /src/logs/* и /src/daemons/*
Обратите внимание на то, что в django, обычно, stdout_logfile не пишется. Все логи осыпаются в stderr_logfile. Настройка была взята из какой-то готовой инструкции, а удалять строчку не слишком хочется, ведь stdout_logfile — довольно стандартная директива.
Теперь не забудем про наш .env файл:
POSTGRES_USER=habrdockerarticle
POSTGRES_DB=habrdockerarticle
POSTGRES_PASSWORD=qwerty
POSTGRES_HOST=postgresql
POSTGRES_PORT=5432
PGDATA=/var/lib/postgresql/data/pgdata
C_FORCE_ROOT=true
Его можно добавить или не добавлять в .gitignore — значения не имеет.
В конце заполним Dockerfile
FROM python:2.7
RUN apt-get update && apt-get install -y openssh-server \
&& apt-get purge -y --auto-remove -o APT::AutoRemove::RecommendsImportant=false -o APT::AutoRemove::SuggestsImportant=false $buildDeps
COPY ./src/requirements.txt ./requirements.txt
RUN pip install -r requirements.txt
Docker Hub не скрывает от нас того, что наш контейнер будет обслуживаться Debian Jessie. В Dockerfile мы запланировали установку ssh сервера, чистку ненужных нам списков пакетов и установку requirements. Кстати, файл зависимостей у нас ещё не создан. Надо исправить этот недочёт и создать requirements.txt в папке src:
Django==1.8
psycopg2
supervisor
Первый запуск
Проект готов к первому запуску! Запускать будем поочерёдно. Сперва выполним:
(docker) $ docker-compose run --rm --service-ports postgresql
Эта операция скачает нам образ, необходимый для запуска postgresql сервера. Сервер запустится, пользователь и база, указанные в .env создадутся автоматически. Команда заблокирует нам ввод данных, но пока не будем её останавливать. Убедимся в наличии базы и ролей входа, подключившись через pgadmin

Как мы видим, всё уже создано для работы:
Теперь комбинацией клавиш ctrl+C в консоли остановим процесс. Нам надо собрать образ проекта. Так что выполним:
(docker) $ docker-compose build project
Эта команда соберёт нам проект, а также, выполнит все команды из Dockerfile. Т.е. у нас будет установлен ssh сервер, а также, установлены зависимости из requirements.txt. Теперь у нас возникает вопрос создания Django проекта. Создать его можно нескольким способами. Самый пуленепробиваемый — это поставить в нашу docker virtualenv на убунте нужную версию Django:
(docker) $ pip install django==1.8
(docker) $ cd ./src
(docker) $ django-admin startproject projectname
(docker) $ cd ../
Django из venv можно удалить или оставить для других проектов. Всё что нам осталось — это перенести внутренности проекта в корень папки src.
Теперь нам следует проверить наш проект и настроить соединение с БД. Сперва поменяем настройки в settings.py:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': os.getenv('POSTGRES_DB'),
'USER': os.getenv('POSTGRES_USER'),
'PASSWORD': os.getenv('POSTGRES_PASSWORD'),
'HOST': os.getenv('POSTGRES_HOST'),
'PORT': int(os.getenv('POSTGRES_PORT'))
}
}
Потом запустим контейнеры проекта:
(docker) $ docker-compose up -d
И убедимся в положительном результате:
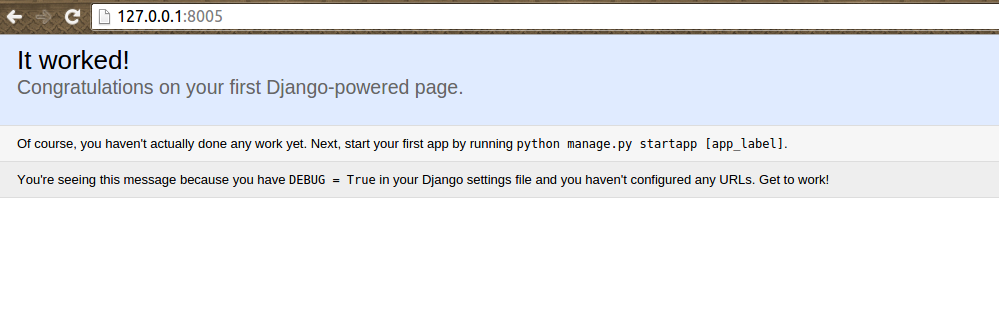
Для остановки проекта и удаления временных файлов можно использовать:
(docker) $ docker-compose stop && docker-compose rm -f
Если у нас меняется что-то в requirements.txt, используем следующую команду для быстрого пересбора
(docker) $ docker-compose stop && docker-compose rm -f && docker-compose build --no-cache project && docker-compose up -d
Давайте, проверим какая структура проекта у нас получилась:
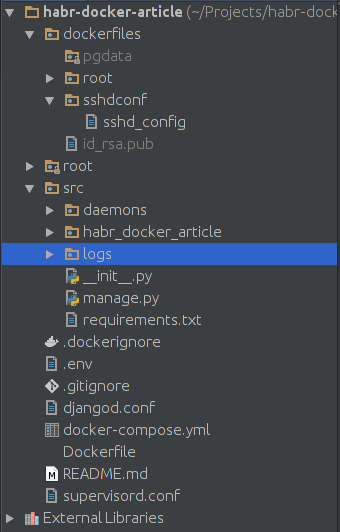
Папка root в моём коде содержит готовые helpers PyCharm'а.
Подключаем контейнер для JS программиста
Теперь можно сделать то, ради чего мы всё это и затевали — подключить Gulp для управления статикой. Файл docker-compose.yml теперь будет выглядеть так:
...
gulp:
build: ./src/gulp
command: bash -c "sleep 3 && gulp"
volumes:
- ./src/gulp:/app
- ./src/static/scripts:/app/build
project:
...
links:
- postgresql
- gulp
...
Я добавил новый контейнер и указал его в зависимостях к project.
Теперь мне нужно создать папку gulp в src для исходников и static/scripts для скомпилированных файлов. В папке src/gulp создадим файл package.json со следующим содержимым:
{
"name": "front",
"version": "3.9.0",
"description": "",
"main": "gulpfile.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "BSD-2-Clause",
"devDependencies": {
"gulp": "~3.9.0",
"gulp-uglify": "~1.4.2",
"gulp-concat": "~2.6.0",
"gulp-livereload": "~3.8.1",
"gulp-jade": "~1.1.0",
"gulp-imagemin": "~2.3.0",
"tiny-lr": "0.2.1"
}
}
Создадим gulpfile.js. в папке src/gulp. Я использовал свой старый файл для образца:
/**
* Created by werevolff on 18.10.15.
*/
var gulp = require('gulp'),
uglify = require('gulp-uglify'),
concat = require('gulp-concat'),
refresh = require('gulp-livereload'),
lr = require('tiny-lr'),
server = lr();
/**
* Mainpage
*/
gulp.task('mainpage', function () {
gulp.src(['./front/jquery/*.js', './front/bootstrap/*.js', './front/angularjs/angular.min.js',
'./front/angularjs/i18n/angular-locale_ru-ru.js', './front/project/**/*.js'])
.pipe(uglify())
.pipe(concat('mainpage.js'))
.pipe(gulp.dest('./build'))
.pipe(refresh(server));
});
/**
* Rebuild JS files
*/
gulp.task('lr-server', function () {
server.listen(35729, function (err) {
if (err) return console.log(err);
});
});
/**
* Gulp Tasks
*/
gulp.task('default', ['mainpage', 'lr-server'], function () {
gulp.watch('./front/**/*.js', ['mainpage']);
});
Как мы видим из конфига, нам следует залить в папку src/gulp/front некоторые популярные библиотеки и создать папку src/gulp/front/project для написанных JS программистом скриптов. Также, не забываем о создании Dockerfile в src/gulp
FROM neo9polska/nodejs-bower-gulp
COPY package.json ./package.json
COPY node_modules ./node_modules
RUN npm install --verbose
Теперь довольно важный вопрос — node_modules. Без этой папки контейнер с Gulp будет откровенно лажать. Здесь у нас два варианта получения этой папки:
- Собрать проект на локальной машине и перенести из него папку с модулями
- Убрать из Dockerfile всё что ниже директивы FROM, выполнить docker-compose run --rm gulp npm install --verbose, а потом поменять права на директорию с node_modules и вернуть то, что было ниже FROM обратно.
Однако, менять права не обязательно. Просто разработчики будут вынуждены постоянно выполнять команду на пересборку gulp. Впрочем, весь код, описанный в статье, я выложу на Github и можно взять node_modules оттуда. Проблема эта связана с docker-compose. Но победить её легко.
Итак, в результате запуска контейнеров
(docker) $ docker-compose up -d
Мы должны получить вот такой скомпилированный файл:
 .
.Готово! Проект можно залить в git и начинать работать с ним.
Полная команда перезапуска с пересборкой выглядит так:
(docker) $ docker-compose stop && docker-compose rm -f && docker-compose build --no-cache gulp && docker-compose build --no-cache project && docker-compose up -d
Для запуска проекта у нового участника процесса достаточно выполнить:
(docker) $ docker-compose build --no-cache gulp && docker-compose build --no-cache project && docker-compose up -d
Для просмотра основного журнала контейнера с запущенным приложением:
(docker) $ docker-compose logs CONTAINER NAME
Логи Django из project пишутся в папку src/logs.
Исходный код проекта вы можете посмотреть в моём GitHub.
P.S. Ещё один важный аспект — настройка интерпретатора python в PyCharm. Для этой настройки достаточно добавить remote interpreter:

И обратите внимание на то, что PyCharm имеет плагин для интеграции с Docker. Мы же используем SSH соединение, поскольку не затрагивали вопрос развёртывания проекта на docker-machine.
