As such, there’s really no “standard” benchmark that will inform you about the best technology to use for your application. Only your requirements, your data, and your infrastructure can tell you what you need to know.
Для начала немного философии. NoSql окружает и от этого никуда не убежать (хотя не очень то и хотелось). Оставим вопросы о глубинных причинах за рамками данного текста, отметим лишь, что этот тренд отражается не только в появлении новых NoSql решений и развитии старых. Еще одна грань — смешение противоположностей, а именно поддержка хранения schema-less данных в традиционных реляционных базах. В этой серой области на стыке реляционной модели хранения данных и всего остального кроется головокружительное количество возможностей. Но, как и всегда, нужно уметь найти баланс, который подходит именно для ваших данных. Это бывает трудно, в первую очередь из-за того, что приходится сравнивать мало сравнимые вещи, например, производительность NoSql решения с традиционной базой данных. В этой небольшой заметке будет предложена такая попытка и приведено сравнение производительности работы с jsonb в PostgreSQL с json в Mysql и с bson в Mongodb.
Что, черт возьми, вообще происходит?
Краткие вести с полей:
- PostgreSQL 9.4 — новый тип данных jsonb, поддержка которого будет немного расширена в грядущей PostgreSQL 9.5
- Mysql 5.7.7 — новый тип данных json
и ряд других примеров, о которых расскажу в следующий раз. Замечательно то, что эти типы данных предполагают не текстовое, а бинарное хранение json, что делает работу с ним гораздо шустрее. Базовый функционал везде идентичен, т.к. это очевидные требования — создать, выбрать, обновить, удалить. Самое древнейшее, почти пещерное, желание человека в этой ситуации — провести ряд benchmark'ов. PostgreSQL & Mysql выбраны, т.к. реализация поддержки json очень похожа в обоих случаях (к тому же они находятся в одинаковой весовой категории), ну а Mongodb — как старожил NoSql мира. Работа, проведенная EnterpriseDB, немного в этом плане устарела, но ее можно взять, в качестве первого шага для дороги в тысячу ли. На данный момент целью данной дороги является не показать, кто быстрее/медленее в искусственных условиях, а постараться дать нейтральную оценку и получить feedback.
Исходные данные и некоторые детали
pg_nosql_benchmark от EnterpriseDB предполагает достаточно очевидный путь — сначала генерируется заданный объем данных разного вида с легкими флуктуациями, который затем записывается в исследуемую базу и по нему происходят выборки.
Функционал для работы с Mysql в нем отсутствует, поэтому его понадобилось реализовать на основе аналогичного для PostgreSQL. На данном этапе есть только одна тонкость, когда мы задумываемся об индексах — дело в том, что в Mysql не реализовано
индексирование json на прямую, поэтому приходится создавать виртуальные колонки и индексировать уже их. Помимо этого, меня смутило то, что для mongodb часть сгенерированных данных размером превышает 4096 байт и не вмещается в буфер mongo shell, т.е. просто отбрасывается. В качестве хака получилось выполнять insert'ы из js файла (который еще и приходится разбивать несколько chunk'ов, т.к. один не может быть больше 2GB). Помимо этого, чтобы избежать издержек, связанных со стартом шелла, аутентификацией и проч., совершается соответствующее количество «no-op» запросов, время которых затем исключается (хотя они, на самом деле, достаточно малы).
Со всеми полученными изменениями проверки проводились для следующих случаев:
- PostgreSQL 9.5 beta1, gin
- PostgreSQL 9.5 beta1, jsonb_path_ops
- PostgreSQL 9.5 beta1, jsquery
- Mysql 5.7.9
- Mongodb 3.2.0 storage engine WiredTiger
- Mongodb 3.2.0 storage engine MMAPv1
Каждый из них был развернут на отдельном m4.xlarge инстансе с ubuntu 14.04 x64 на борту с настройками по умолчанию, тесты проводились на количестве записей, равном 1000000. Для тестов с jsquery надо прочитать readme и не забыть установить bison, flex, libpq-dev и даже postgresql-server-dev-9.5. Результаты будут сохранены в json файл, который можно визуализировать с помощью matplotlib (см. здесь).
Помимо этого возникали сомнения относительно настроек, связанных с durability. Поэтому я провел пару дополнительных тестов для следующих случаев (на мой взгляд, часть из них является скорее теорией, т.к. вряди кто-то будет использовать такие настройки в живую):
- Mongodb 3.2.0 journaled (writeConcern j:true)
- Mongodb 3.2.0 fsync (transaction_sync=(enabled=true,method=fsync))
- PostgreSQL 9.5 beta 1, no fsync (fsync=off)
- Mysql 5.7.9, no fsync (innodb_flush_method=nosync)
Картинки
Все графики, связанные со временем выполнения запросов, представлены в секундах, связанные с размерами — в мегабайтах. Соответственно, для обоих случаев чем меньше величина, тем больше производительность.
Select

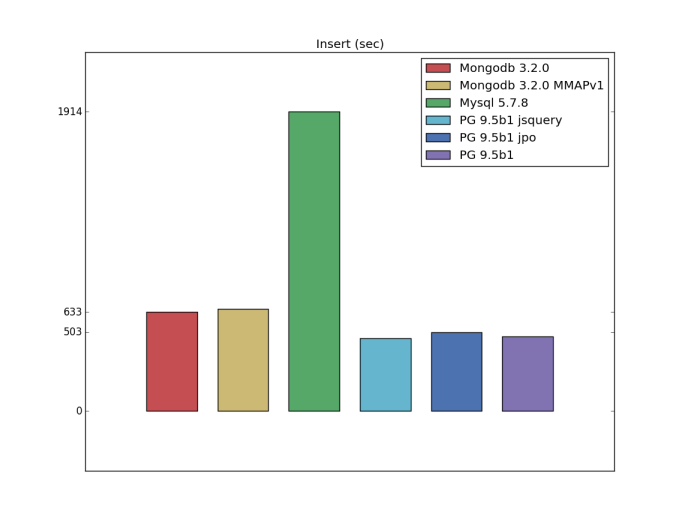
Insert
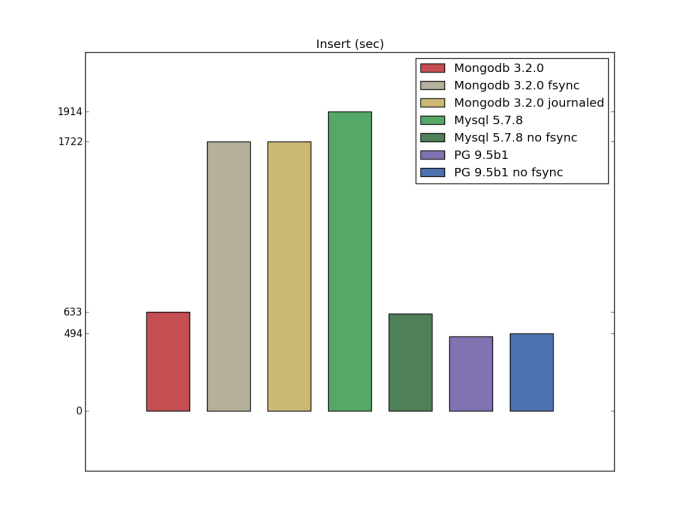
Insert (custom configuration)
Update
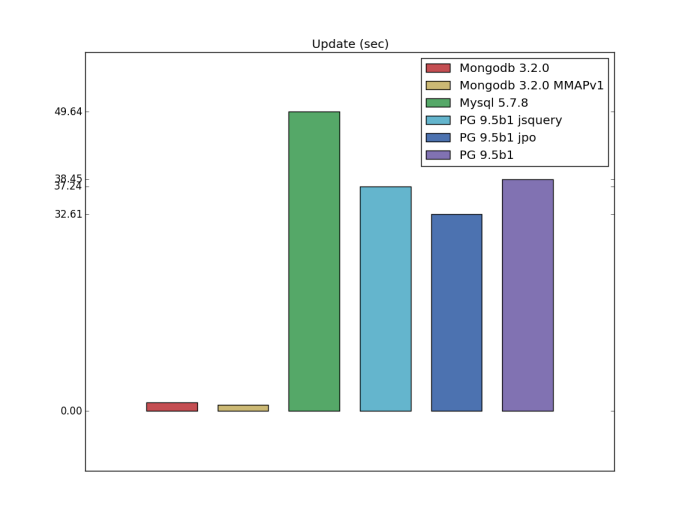
Еще одним изменением относительно оригинального кода pg_nosql_benchmark было добавление тестов на обновление. Здесь явным лидером оказалась Mongodb, скорее всего за счет того, что в PostgreSQL и Mysql обновление даже одного значения на данным момент означает перезапись всего поля.
Update (custom configuration)
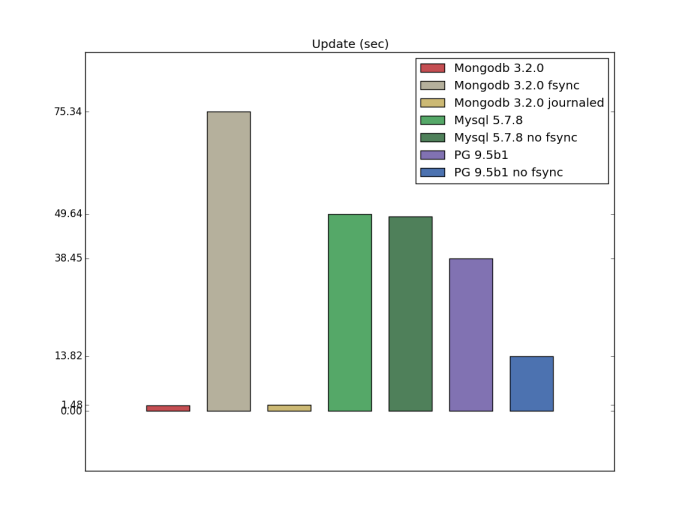
Как можно предположить из документации и подсмотреть в этом ответе, writeConcern j:true — это наивысший возможный уровень durability для одного сервера mongodb, и судя по всему он должен быть эквивалентен конфигурациям с fsync. Я не проверял durability, однако интересно, что для mongodb операции обновления с fsync получились намного медленнее.
Table/index size
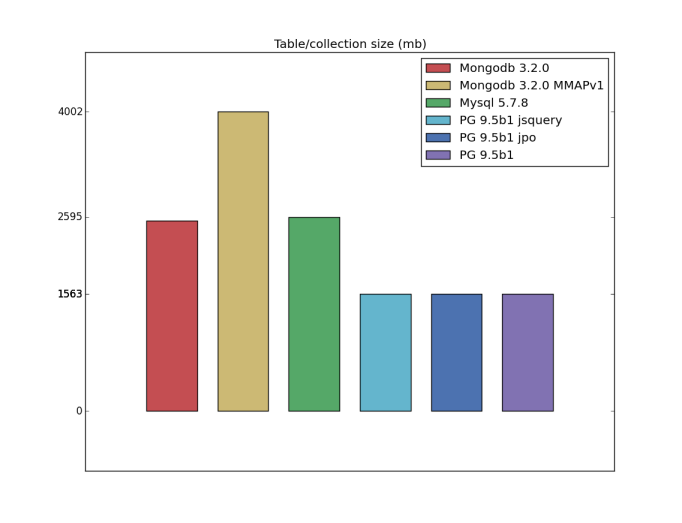
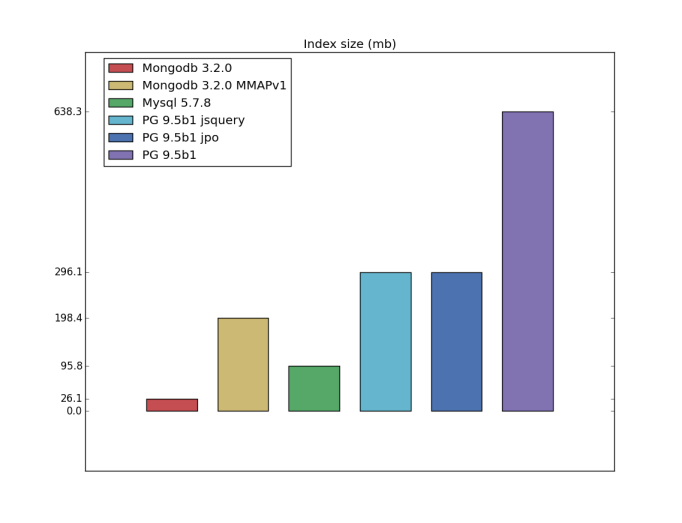
I have a bad feeling about this
Измерение производительности — слишком скользкая тема, тем более в этом случае. Все, что описано выше, нельзя считать полноценным и завершенным бенчмарком, это только первый шаг к тому, чтобы понять текущую ситуацию — что-то вроде пищи для размышлений. В данный момент мы занимаемся проведением тестов с использованием ycsb, а также, если повезет, сравним производительность кластерных конфигураций. Помимо этого, буду рад всем конструктивным предложениям, идеям и правкам (т.к. я вполне мог что-то упустить).
