Незаслуженно обошли вниманием появление SQL JOIN операций в проекте на основе Elasticsearch

Главное отличие Crate.io от Elasticsearch — это поддержка SQL как языка запросов и модификации данных в ES, а также API и возможность распределенно хранить двоичные данные в кластере.
Про пример использования BLOB API я давно рассказывал в размещенной на Хабре публикации «Как найти любовь или приключения с помощью crate.io и kibana». Elasticsearch позволяет хранить в кластере json документы, индексировать их и выполнять поиск по ним. Crate дополняет ES возможностью работать с данными с помощью SQL. В этой статье мы сконцентрируемся на установке crate, а также на выполнении запросов через jdbc драйвер.
Предлагаю вам подход по установке ПО из maven репозитариев, который может пригодиться в java и groovy проектах и не только для crate. В этой статье мы установим, сконфигурируем и запустим сервер базы данных для экспериментов с JOIN при помощи груви скрипта.
Для запуска скрипта нужен особенный groovy-all: groovy-grape-aether-2.4.5.1.jar и сам скрипт crate-io.groovy:
Этот скрипт создает директорию .crate-io в домашней директории пользователя, проверяет есть ли уже нужная версия базы данных crate.io внутри директории. При отсутствии из maven совместимого репозитария проекта crate скачивается сборка в формате tar.gz и распаковывается. При этом в конфигурации config/crate.yml включается Elasticsearch API. В случае успешной установки или если crate.io был установлен ранее, скрипт запускает сервер.
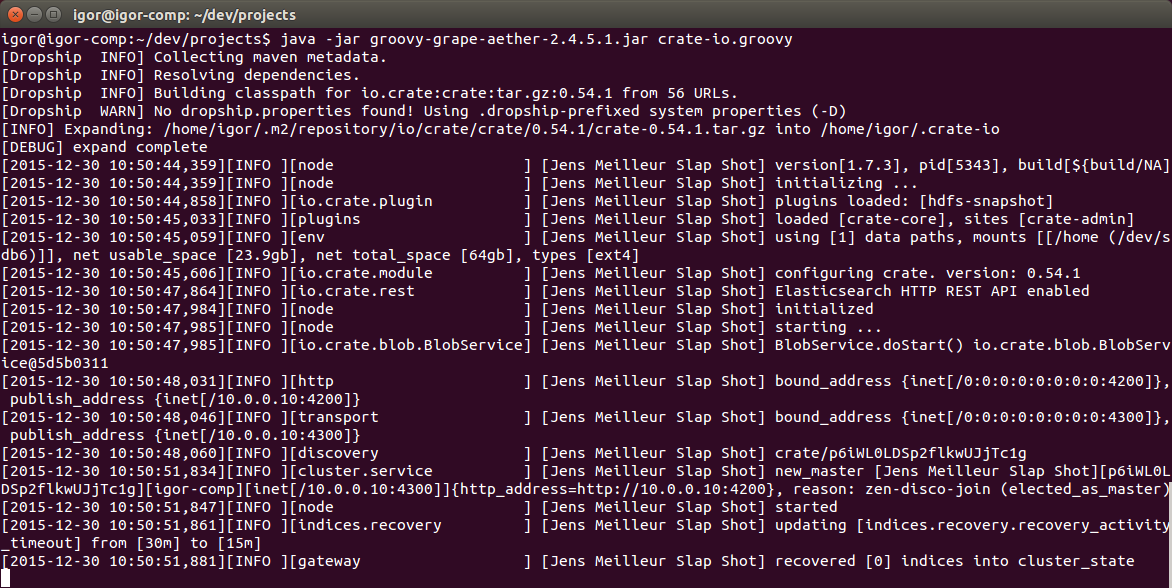
После запуска можете подключиться в браузере к веб интерфесу сервера http://localhost:4200/admin
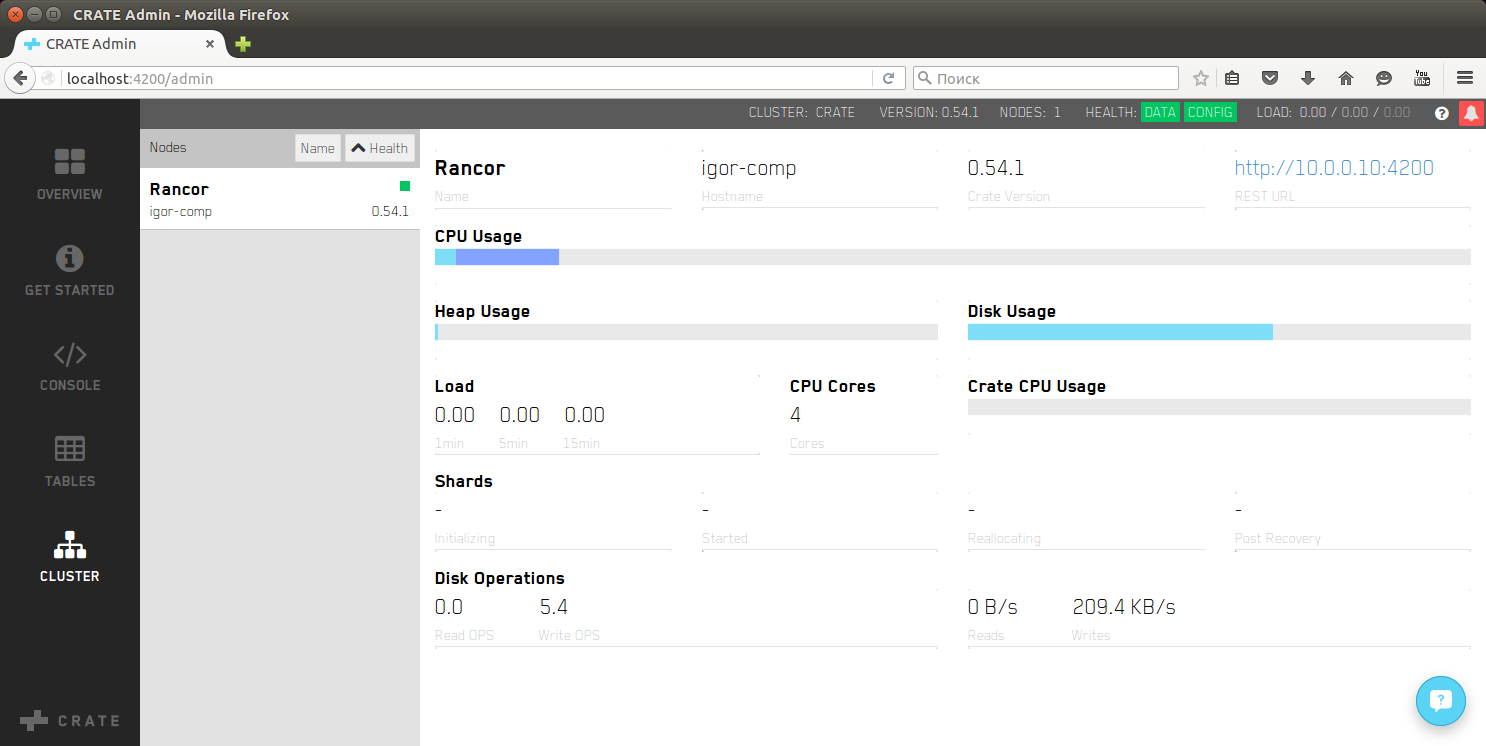
Благодаря библиотеке presto и разработчикам проекта crate.io стало возможно выполнять SQL запросы в базе данных на основе elasticsearch с архитектурой shared nothing. Из программ можно выполнять запросы с помощью клиентской библиотеки для Java, Python, PHP, Erlang, REST API.
Нас же интересует jdbc драйвер. И в момент скачивания драйвера наступает ужас от Crate JDBC standalone jar размером 23.4МБ внутри которого зачем-то запакован весь elasticsearch сервер, а не только клиентская часть его API и реализация транспорта. Ладно, трафик мне не жалко, но зачем было так беспощадно паковать все!? При наличии maven proxy repository этот драйвер будет скачан только один раз из вашей рабочей сети.
Maven зависимость для Crate JDBC standalone из репозитария проекта:
Для создания подключения к базе делал все по инструкции. Но делать то же самое можно программно, можно из другого редактора, поддерживающего jdbc драйвера.
Сконфигурировал драйвер:

Создал и проверил подключение:

Создал две таблицы:

Вставил записи в таблицы:

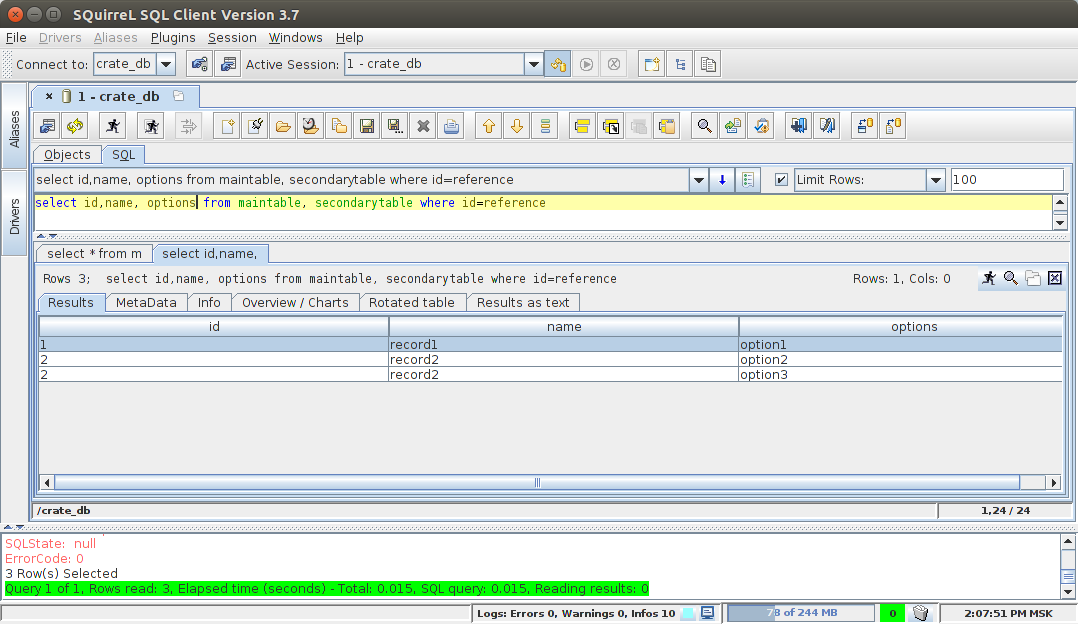
INNER JOIN:
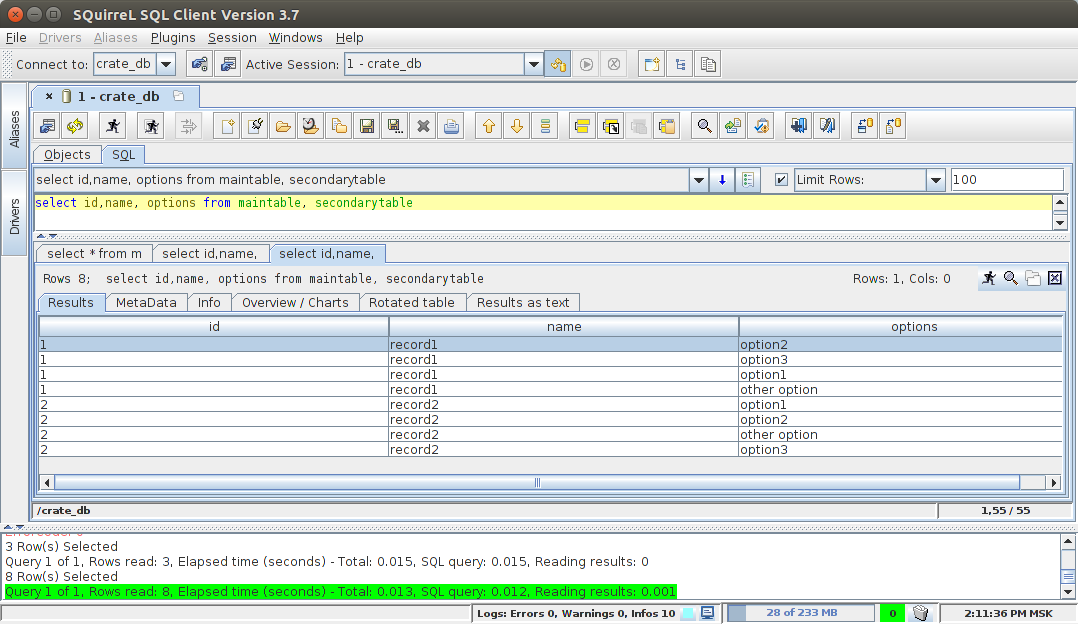
CROSS JOIN:
К сожалению, inner и cross join — это все что пока умеет crate.io. Но база развивается, поэтому ждем реализации outer join и дальнейшего улучшения существующего функционала.
Crate.io — SQL надстройка над NoSQL решением Elasticsearch, которая в последних версиях умеет делать inner и cross join. Для работы с crate можно использовать jdbc драйвер и Kibana для визуализации данных, с некоторыми ограничениями. Crate также может хранить двоичные данные распределенно, в файловых системах процессов кластера.
С помощью groovy скрипта мы можем устанавливать нужную нам версию из maven репозитария, обновлять конфигурацию при установке и запускать сервер.
Как и у каждого решения у crate.io есть свои сильные стороны:

Главное отличие Crate.io от Elasticsearch — это поддержка SQL как языка запросов и модификации данных в ES, а также API и возможность распределенно хранить двоичные данные в кластере.
Про пример использования BLOB API я давно рассказывал в размещенной на Хабре публикации «Как найти любовь или приключения с помощью crate.io и kibana». Elasticsearch позволяет хранить в кластере json документы, индексировать их и выполнять поиск по ним. Crate дополняет ES возможностью работать с данными с помощью SQL. В этой статье мы сконцентрируемся на установке crate, а также на выполнении запросов через jdbc драйвер.
Установка crate.io
Предлагаю вам подход по установке ПО из maven репозитариев, который может пригодиться в java и groovy проектах и не только для crate. В этой статье мы установим, сконфигурируем и запустим сервер базы данных для экспериментов с JOIN при помощи груви скрипта.
java -jar groovy-grape-aether-2.4.5.1.jar crate-io.groovy
Для запуска скрипта нужен особенный groovy-all: groovy-grape-aether-2.4.5.1.jar и сам скрипт crate-io.groovy:
@Grab(group='org.codehaus.plexus', module='plexus-archiver', version='2.10.2')
import org.codehaus.plexus.archiver.tar.TarGZipUnArchiver
import com.github.igorsuhorukov.smreed.dropship.MavenClassLoader;
@Grab(group='org.codehaus.plexus', module='plexus-container-default', version='1.6')
import org.codehaus.plexus.logging.console.ConsoleLogger;
def artifact = 'crate'
def version = '0.54.1'
def userHome= System.getProperty('user.home')
def destDir = new File("$userHome/.crate-io")
def crateIoDir= new File(destDir, "$artifact-$version");
if(!crateIoDir.exists()){
destDir.mkdirs()
String sourceFile = MavenClassLoader.using("https://dl.bintray.com/crate/crate/").getArtifactUrlsCollection("io.crate:$artifact:tar.gz:$version", null).get(0).getFile()
final TarGZipUnArchiver unArchiver = new TarGZipUnArchiver()
unArchiver.setSourceFile(new File(sourceFile))
unArchiver.enableLogging(new ConsoleLogger(ConsoleLogger.LEVEL_DEBUG,"Logger"))
unArchiver.setDestDirectory(destDir)
unArchiver.extract()
def crateCfg = new File("$crateIoDir.absolutePath/config/crate.yml")
crateCfgText = crateCfg.text
crateCfg.withWriter { w ->
w << crateCfgText.replace('# es.api.enabled: false', 'es.api.enabled: true')
}
}
def proc = "$crateIoDir.absolutePath/bin/crate".execute()
proc.consumeProcessOutput(System.out, System.err)
proc.waitFor()
Этот скрипт создает директорию .crate-io в домашней директории пользователя, проверяет есть ли уже нужная версия базы данных crate.io внутри директории. При отсутствии из maven совместимого репозитария проекта crate скачивается сборка в формате tar.gz и распаковывается. При этом в конфигурации config/crate.yml включается Elasticsearch API. В случае успешной установки или если crate.io был установлен ранее, скрипт запускает сервер.

После запуска можете подключиться в браузере к веб интерфесу сервера http://localhost:4200/admin

Crate.io jdbc
Благодаря библиотеке presto и разработчикам проекта crate.io стало возможно выполнять SQL запросы в базе данных на основе elasticsearch с архитектурой shared nothing. Из программ можно выполнять запросы с помощью клиентской библиотеки для Java, Python, PHP, Erlang, REST API.
Нас же интересует jdbc драйвер. И в момент скачивания драйвера наступает ужас от Crate JDBC standalone jar размером 23.4МБ внутри которого зачем-то запакован весь elasticsearch сервер, а не только клиентская часть его API и реализация транспорта. Ладно, трафик мне не жалко, но зачем было так беспощадно паковать все!? При наличии maven proxy repository этот драйвер будет скачан только один раз из вашей рабочей сети.
Maven зависимость для Crate JDBC standalone из репозитария проекта:
<dependency>
<groupId>io.crate</groupId>
<artifactId>crate-jdbc-standalone</artifactId>
<version>1.9.3</version>
<dependency>
Для создания подключения к базе делал все по инструкции. Но делать то же самое можно программно, можно из другого редактора, поддерживающего jdbc драйвера.
Сконфигурировал драйвер:

Создал и проверил подключение:

Создал две таблицы:
create table maintable(
id integer primary key,
name string
);
create table secondarytable (
reference integer,
options string
);

Вставил записи в таблицы:
insert into maintable(id,name) values(1,'record1');
insert into maintable(id,name) values(2, 'record2');
insert into secondarytable(reference,options) values(1,'option1');
insert into secondarytable(reference,options) values(2,'option2');
insert into secondarytable(reference,options) values(2,'option3');
insert into secondarytable(reference,options) values(null,'other option');

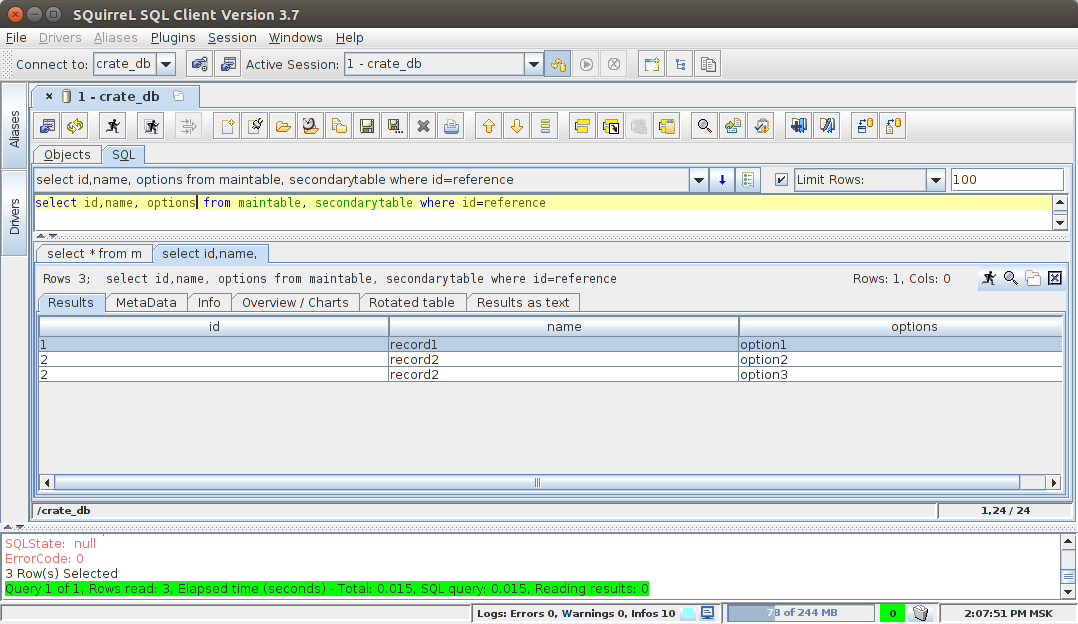
INNER JOIN:
select id, name, options from maintable, secondarytable where id=reference
CROSS JOIN:
select id,name, options from maintable, secondarytable

К сожалению, inner и cross join — это все что пока умеет crate.io. Но база развивается, поэтому ждем реализации outer join и дальнейшего улучшения существующего функционала.
Заключение
Crate.io — SQL надстройка над NoSQL решением Elasticsearch, которая в последних версиях умеет делать inner и cross join. Для работы с crate можно использовать jdbc драйвер и Kibana для визуализации данных, с некоторыми ограничениями. Crate также может хранить двоичные данные распределенно, в файловых системах процессов кластера.
С помощью groovy скрипта мы можем устанавливать нужную нам версию из maven репозитария, обновлять конфигурацию при установке и запускать сервер.
Как и у каждого решения у crate.io есть свои сильные стороны:
- Возможность горизонтального масштабирования(shared nothing архитектура)
- SQL как язык запросов и манипуляции данными, ограниченная поддержка JOIN в запросах
- Распределенное хранение двоичных данных в файловой системе и доступ к ним в кластере
- Возможность(хоть и ограниченная) применения Elasticsearch API, Kibana и существующего инструментария для ES
- Уступает объектно-реляционным базам данным по функциональности
- Из ACID Elasticsearch поддерживает только Durability
