На Хабре не утихают споры о том, какие базы данных лучше и круче, дискуссии о перспективах SQL и NoSQL. Я не удержался и решил порассуждать о том, где могут быть полезны именно графовые БД.

Прежде чем начать, давайте задумаемся, какая информация имеется у нас сегодня на повестке дня? Это уже не просто данные – это весьма непредсказуемая структура, которая со временем может превратиться либо в BigData, либо в сложную семантическую сеть, и часто разработчик не может заранее сказать, какой она будет. Так как же выбрать базу данных – или хотя бы ее архитектуру, чтобы создать действительно быстрое и эффективно работающее приложение?
Чтобы ответить на этот вопрос, попробуем немножко систематизировать ту информацию о базах данных, которая есть у нас. Первый и самый известный кандидат на эксплуатацию – это реляционные базы данных с их единым языком SQL. Просто, удобно и стандартно. Именно благодаря стандартизации реляционные базы данных заработали себе популярность и доминируют на рынке. Но по факту реляционные базы данных – это же просто таблицы, где в каждой строке выстраивается однозначное соответствие между ключом и его многочисленными (или малочисленными) параметрами. Пока приложения обходились отдельными таблицами и не рассматривали особенных взаимодействий между собой и разными типами данных, этого было вполне достаточно.
Структура реляционной БД
Как альтернатива базам данных SQL где-то с начала 2000-х развивается направление NoSQL. В эту категорию объединяют все подряд – от иерархических и сетевых БД (где помимо иерархии предусмотрены дополнительные связи) до упрощенных БД ключ-значение и документарных баз данных без определенных параметров значений каждого элемента. Причина эволюции этой категории баз данных заключается в следующем: если у вас примитивные и однотипные наборы данных, а запросы касаются одной таблицы – то все ОК, и можно работать с SQL. Но если нет? Если нужно обратиться к 10, 100, 1000 таблиц, чтобы обработать запрос? Тогда реляционная база данных начинает работать медленно, а для написания запроса требуется немало строчек кода.
Пожалуй, наибольшей популярностью баз данных из категории NoSQL пользуются документарные БД, в частности, MongoDB. Они позволяют хранить объекты с произвольными наборами значений, что очень удобно – скажем, у платежного поручения будут одни поля, у приказа – другие. И все это хранится в одном и том же сегменте БД, без подразделения на примитивные таблицы. Однако и у этого подхода есть ограничения, о которых я расскажу парой абзацев ниже.
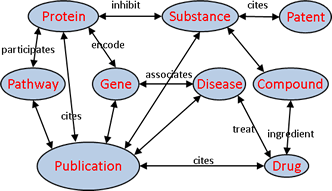
Наконец, отдельным классом, хотя их по традиции относят к NoSQL, стоят графовые базы данных. Они предлагают более естественное представление информации, основанное на той же логике, с которой мы сталкиваемся в реальной жизни. Не секрет, что каждая социальная сеть — это граф, да и сетевая модель БД – это тоже фактически граф, но без дополнительных возможностей, которые открывает современная графовая модель. Поэтому графовые базы данных представляют особый интерес для разработчиков.

Итак, про реляционную архитектуру мы уже поговорили – это прекрасное решение для тех случаев, когда все просто и однозначно, но совершенно неповоротливая архитектура для создания сложных и гибких запросов, обработки разнообразных и многократных связей между объектами. Однако, нельзя забывать о таких преимуществах SQL-баз данных, как возможность создания сложных (JOIN) запросов. Такой подход делает стандартизированные реляционные БД более универсальными, ведь пусть даже большим количеством кода, но каждый запрос может быть в них реализован. Например, найти всех людей моложе 20 лет, у которых есть автомобили красного цвета, будет достаточно легко сделать в SQL, в то время как БД из категории NoSQL потребуют массы усилий для решения этой задачи.

Иллюстрация сложного запроса в SQL
Прямая альтернатива SQL – документарные базы данных. Их главное преимущество – это отсутствие единой схемы всех элементов (schemaless). В отличие от SQL эти базы могут сохранять любой сложный объект, например, документ с большим количеством полей за одну операцию, а также за одну операцию выдавать его. Это очень удобно, например, для добавления новых категорий товаров в каталог интернет-магазина, ведь для телевизора, микроволновой печи и утюга будут применяться совершенно разные свойства. В той же MongoDB можно работать с ними через короткие запросы, в то время как в SQL для получения и обновления такой сложной записи придется создавать специальные процедуры, выполняющие множество запросов.

Иллюстрация хранения различных типов данных в документарной базе
Минусы документарных баз также вытекают из их архитектурных особенностей. Например, документарная модель не подразумевает таких простых функций объединения (JOIN), а также возможности работать с двунаправленными связями. Кроме этого документарная база рассчитана на хранение отдельных элементов, не имеющих дополнительных связей между собой. Хороший пример того, с какими сложностями столкнулись создатели социальной сети Diaspora приведен тут (http://habrahabr.ru/post/231213/). Ребята сначала начали активно эксплуатировать преимущества документарной модели, но потом просто столкнулись с тем, что социальные данные имеют множество связей друг с другом и ох очень сложно представить в виде отдельных «документов». И им все равно пришлось вернуться к SQL.
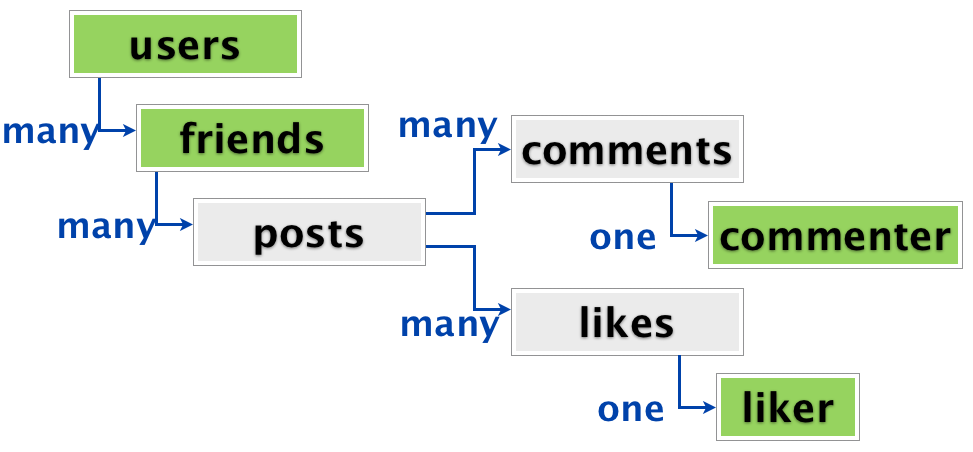
Структура социальных данных, для которых не подошла документарная модель хранения
Теперь немного о графах. Они изначально ориентированы на связи между объектами, и эти связи могут иметь разные характеристики. Например, если заказчик требует разработать базу данных сериалов, где к каждому эпизоду каждого сериала относятся различные актеры, самым очевидным образом вырисовывается иерархическая модель, которая прекрасно ложится в документарную базу данных. Однако, как только заказчик говорит: «Слушайте, а давайте наша система будет также в один клик выводить фильмографию актеров», вся иерархия рассыпается и приходится либо дорабатывать БД (долго и мучительно), либо менять формат хранения данных.
Основным преимуществом графовых баз данных в этом свете является универсальность, ведь в них можно хранить и реляционные, и документарные и сложные семантические данные. А сама модель построения БД может меняться и модифицироваться в процессе развития приложения без изменения архитектуры и исходных запросов. А значит – не нужно будет ничего переписывать!
С другой стороны, при незначительном количестве связей и больших объемах данных графовые БД демонстрируют значительно более низкую производительность, и это нужно обязательно иметь в виду. Еще одним важным ограничением является то, что в данный момент практически не существует графовых баз данных, которые бы хорошо работали в параллельных архитектурах.
Однако, раз уж мы говорим сегодня о разработке приложений, в процессе проектирования и даже на стадии «шлифовки», нередко появляются новые требования к структуре данных, и хорошая модель внезапно может стать плохой. Например, добавление новых связей делает неприемлемой документарную базу данных, а рост количества JOIN-ов катастрофически снижает производительность реляционной БД. В этом случае графы оказываются наиболее универсальным вариантом, позволяющим подстраховаться на случай изменения требований и расширения функционала в будущем. Нужно добавить к реляционным данным дополнительные связи? Без проблем! Нужно усложнить иерархическую документарную модель? Легко!

Графовые данные: множество объектов, множество типов связей между ними
Более того, сегодня активно идет доработка RDF – основного стандарта, согласно которому работают графовые базы данных. И, если вспомнить, именно стандартизация SQL сделала такими популярными именно реляционные БД. При этом ряд проектов демонстрирует поддержку OData для создания стандартных веб-запросов через HTTP, а также язык SPARQL, обладающий обширными возможностями для работы с различными видами запросов и данных (тут можно провести аналогию с SQL для реляционных БД). Но и, наконец, за счет развития архитектуры производительность графовых БД растет, и, возможно, скоро окажется выше реляционной даже при небольшом количестве связей. Так что, быть может, в скором времени графовые БД станут чем-то вроде Святого Грааля для разработчиков?

Прежде чем начать, давайте задумаемся, какая информация имеется у нас сегодня на повестке дня? Это уже не просто данные – это весьма непредсказуемая структура, которая со временем может превратиться либо в BigData, либо в сложную семантическую сеть, и часто разработчик не может заранее сказать, какой она будет. Так как же выбрать базу данных – или хотя бы ее архитектуру, чтобы создать действительно быстрое и эффективно работающее приложение?
Чтобы ответить на этот вопрос, попробуем немножко систематизировать ту информацию о базах данных, которая есть у нас. Первый и самый известный кандидат на эксплуатацию – это реляционные базы данных с их единым языком SQL. Просто, удобно и стандартно. Именно благодаря стандартизации реляционные базы данных заработали себе популярность и доминируют на рынке. Но по факту реляционные базы данных – это же просто таблицы, где в каждой строке выстраивается однозначное соответствие между ключом и его многочисленными (или малочисленными) параметрами. Пока приложения обходились отдельными таблицами и не рассматривали особенных взаимодействий между собой и разными типами данных, этого было вполне достаточно.
| Город |
Год основания |
Население (чел) |
Площадь (кв. км) |
| Санкт-Петербург |
1703 |
5 131 942 |
1 439 |
| Москва |
1147 |
12 108 257 |
2 511 |
| Екатеринбург |
1723 |
1 412 346 |
495 |
| Владивосток |
1860 |
603 244 |
3 3116 |
Как альтернатива базам данных SQL где-то с начала 2000-х развивается направление NoSQL. В эту категорию объединяют все подряд – от иерархических и сетевых БД (где помимо иерархии предусмотрены дополнительные связи) до упрощенных БД ключ-значение и документарных баз данных без определенных параметров значений каждого элемента. Причина эволюции этой категории баз данных заключается в следующем: если у вас примитивные и однотипные наборы данных, а запросы касаются одной таблицы – то все ОК, и можно работать с SQL. Но если нет? Если нужно обратиться к 10, 100, 1000 таблиц, чтобы обработать запрос? Тогда реляционная база данных начинает работать медленно, а для написания запроса требуется немало строчек кода.
Пожалуй, наибольшей популярностью баз данных из категории NoSQL пользуются документарные БД, в частности, MongoDB. Они позволяют хранить объекты с произвольными наборами значений, что очень удобно – скажем, у платежного поручения будут одни поля, у приказа – другие. И все это хранится в одном и том же сегменте БД, без подразделения на примитивные таблицы. Однако и у этого подхода есть ограничения, о которых я расскажу парой абзацев ниже.
Наконец, отдельным классом, хотя их по традиции относят к NoSQL, стоят графовые базы данных. Они предлагают более естественное представление информации, основанное на той же логике, с которой мы сталкиваемся в реальной жизни. Не секрет, что каждая социальная сеть — это граф, да и сетевая модель БД – это тоже фактически граф, но без дополнительных возможностей, которые открывает современная графовая модель. Поэтому графовые базы данных представляют особый интерес для разработчиков.
Плюсы и минусы
Итак, про реляционную архитектуру мы уже поговорили – это прекрасное решение для тех случаев, когда все просто и однозначно, но совершенно неповоротливая архитектура для создания сложных и гибких запросов, обработки разнообразных и многократных связей между объектами. Однако, нельзя забывать о таких преимуществах SQL-баз данных, как возможность создания сложных (JOIN) запросов. Такой подход делает стандартизированные реляционные БД более универсальными, ведь пусть даже большим количеством кода, но каждый запрос может быть в них реализован. Например, найти всех людей моложе 20 лет, у которых есть автомобили красного цвета, будет достаточно легко сделать в SQL, в то время как БД из категории NoSQL потребуют массы усилий для решения этой задачи.

Иллюстрация сложного запроса в SQL
Прямая альтернатива SQL – документарные базы данных. Их главное преимущество – это отсутствие единой схемы всех элементов (schemaless). В отличие от SQL эти базы могут сохранять любой сложный объект, например, документ с большим количеством полей за одну операцию, а также за одну операцию выдавать его. Это очень удобно, например, для добавления новых категорий товаров в каталог интернет-магазина, ведь для телевизора, микроволновой печи и утюга будут применяться совершенно разные свойства. В той же MongoDB можно работать с ними через короткие запросы, в то время как в SQL для получения и обновления такой сложной записи придется создавать специальные процедуры, выполняющие множество запросов.
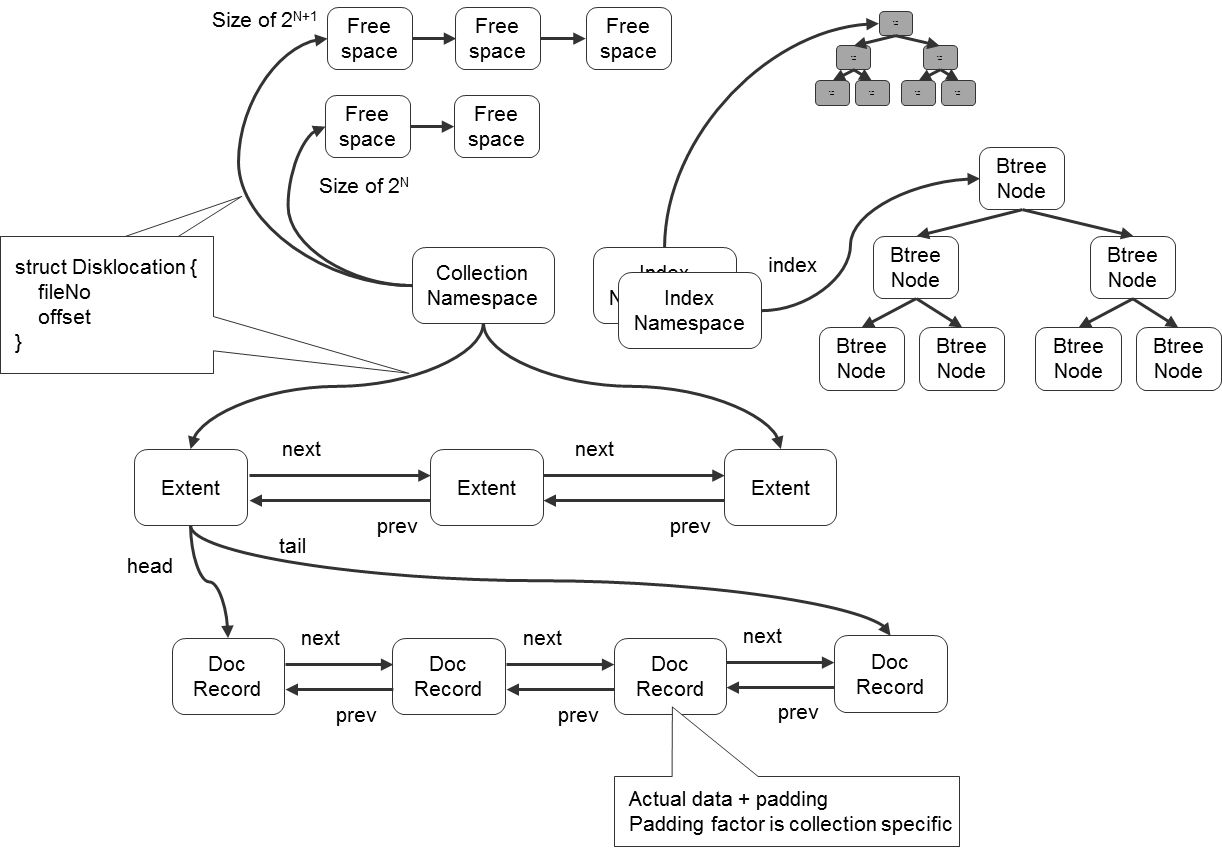
Иллюстрация хранения различных типов данных в документарной базе
Минусы документарных баз также вытекают из их архитектурных особенностей. Например, документарная модель не подразумевает таких простых функций объединения (JOIN), а также возможности работать с двунаправленными связями. Кроме этого документарная база рассчитана на хранение отдельных элементов, не имеющих дополнительных связей между собой. Хороший пример того, с какими сложностями столкнулись создатели социальной сети Diaspora приведен тут (http://habrahabr.ru/post/231213/). Ребята сначала начали активно эксплуатировать преимущества документарной модели, но потом просто столкнулись с тем, что социальные данные имеют множество связей друг с другом и ох очень сложно представить в виде отдельных «документов». И им все равно пришлось вернуться к SQL.
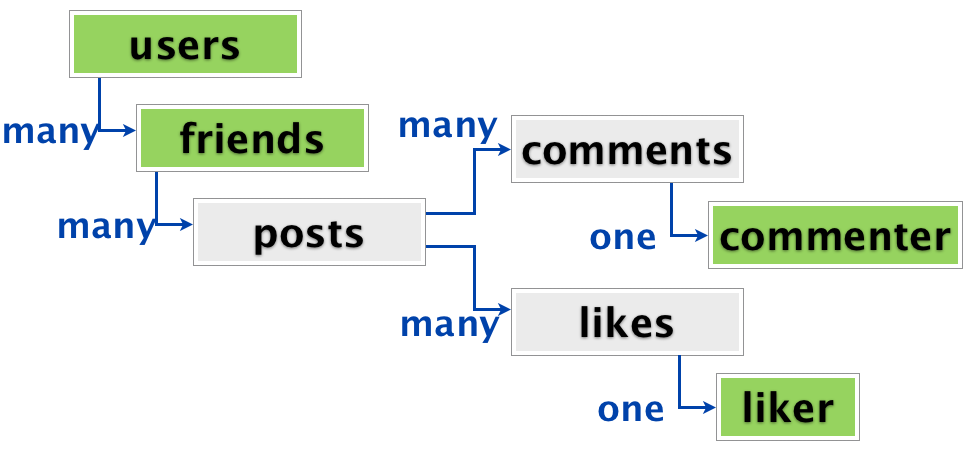
Структура социальных данных, для которых не подошла документарная модель хранения
Теперь немного о графах. Они изначально ориентированы на связи между объектами, и эти связи могут иметь разные характеристики. Например, если заказчик требует разработать базу данных сериалов, где к каждому эпизоду каждого сериала относятся различные актеры, самым очевидным образом вырисовывается иерархическая модель, которая прекрасно ложится в документарную базу данных. Однако, как только заказчик говорит: «Слушайте, а давайте наша система будет также в один клик выводить фильмографию актеров», вся иерархия рассыпается и приходится либо дорабатывать БД (долго и мучительно), либо менять формат хранения данных.
Основным преимуществом графовых баз данных в этом свете является универсальность, ведь в них можно хранить и реляционные, и документарные и сложные семантические данные. А сама модель построения БД может меняться и модифицироваться в процессе развития приложения без изменения архитектуры и исходных запросов. А значит – не нужно будет ничего переписывать!
С другой стороны, при незначительном количестве связей и больших объемах данных графовые БД демонстрируют значительно более низкую производительность, и это нужно обязательно иметь в виду. Еще одним важным ограничением является то, что в данный момент практически не существует графовых баз данных, которые бы хорошо работали в параллельных архитектурах.
Графы все же перспективны?
Однако, раз уж мы говорим сегодня о разработке приложений, в процессе проектирования и даже на стадии «шлифовки», нередко появляются новые требования к структуре данных, и хорошая модель внезапно может стать плохой. Например, добавление новых связей делает неприемлемой документарную базу данных, а рост количества JOIN-ов катастрофически снижает производительность реляционной БД. В этом случае графы оказываются наиболее универсальным вариантом, позволяющим подстраховаться на случай изменения требований и расширения функционала в будущем. Нужно добавить к реляционным данным дополнительные связи? Без проблем! Нужно усложнить иерархическую документарную модель? Легко!
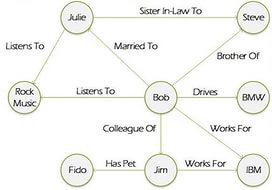
Графовые данные: множество объектов, множество типов связей между ними
Более того, сегодня активно идет доработка RDF – основного стандарта, согласно которому работают графовые базы данных. И, если вспомнить, именно стандартизация SQL сделала такими популярными именно реляционные БД. При этом ряд проектов демонстрирует поддержку OData для создания стандартных веб-запросов через HTTP, а также язык SPARQL, обладающий обширными возможностями для работы с различными видами запросов и данных (тут можно провести аналогию с SQL для реляционных БД). Но и, наконец, за счет развития архитектуры производительность графовых БД растет, и, возможно, скоро окажется выше реляционной даже при небольшом количестве связей. Так что, быть может, в скором времени графовые БД станут чем-то вроде Святого Грааля для разработчиков?
