Под метдом Монте-Карло понимается численный метод решения
математических задач при помощи моделирования случайных величин. Представление об истории метода и простейшие примеры его применения можно найти в Википедии.
В самом методе нет ничего сложного. Именно эта простота объясняет популярность данного метода.
Метод имеет две основных особенности. Первая — простая структура вычислительного алгоритма. Вторая — ошибка вычислений, как правило, пропорциональна
 , где
, где  — некоторая постоянная, а
— некоторая постоянная, а  — число испытаний. Ясно, что добиться высокой точности на таком пути невозможно. Поэтому обычно говорят, что метод Монте-Карло особенно эффективен при решении тех задач, в которых результат нужен с небольшой точностью.
— число испытаний. Ясно, что добиться высокой точности на таком пути невозможно. Поэтому обычно говорят, что метод Монте-Карло особенно эффективен при решении тех задач, в которых результат нужен с небольшой точностью.
Однако одну и ту же задачу можно решать различными вариантами метода Монте-Карло, которым отвечают различные значения . Во многих задачах удается значительно увеличить точность, выбрав способ расчета, которому соответствует значительно меньшее значение .
. Во многих задачах удается значительно увеличить точность, выбрав способ расчета, которому соответствует значительно меньшее значение .
Допустим, что нам требуется вычислить какую-то неизвестную величину m. Попытаемся придумать такую случайную величину , чтобы
, чтобы  . Пусть при этом
. Пусть при этом  .
.
Рассмотрим независимых случайных величин  (реализаций), распределения которых совпадают с распределением . Если достаточно велико, то согласно центральной предельной теореме распределение суммы
(реализаций), распределения которых совпадают с распределением . Если достаточно велико, то согласно центральной предельной теореме распределение суммы  будет приблизительно нормальным с параметрами
будет приблизительно нормальным с параметрами  ,
,  .
.
На основе Центральной предельной теоремы (или если хотите предельной теоремы Муавра-Лапласа) не трудно получить соотношение:
%3DP%5Cleft(%20%5Cleft%7C%20%5Cfrac%7B1%7D%7BN%7D%5Csum%5Climits_%7Bi%7D%7B%7B%7B%5Cxi%20%7D_%7Bi%7D%7D%7D-m%20%5Cright%7C%5Cle%20k%5Cfrac%7Bb%7D%7B%5Csqrt%7BN%7D%7D%20%5Cright)%5Cto%202%5CPhi%20(k)-1%2C)
где) — функция распределения стандартного нормального распределения.
— функция распределения стандартного нормального распределения.
Это — чрезвычайно важное для метода Монте-Карло соотношение. Оно дает и метод расчета , и оценку погрешности.
, и оценку погрешности.
В самом деле, найдем значений случайной величины  . Из указанного соотношения видно, что среднее арифметическое этих значений будет приближенно равно . С вероятностью близкой к
. Из указанного соотношения видно, что среднее арифметическое этих значений будет приближенно равно . С вероятностью близкой к -1)) ошибка такого приближения не превосходит величины
ошибка такого приближения не превосходит величины  . Очевидно, эта ошибка стремится к нулю с ростом .
. Очевидно, эта ошибка стремится к нулю с ростом .
В зависимости от целей последнее соотношение используется по разному:
Как видно из приведенных выше соотношений, точность вычислений зависит от параметра и величины  – среднеквадратичного отклонения случайной величины .
– среднеквадратичного отклонения случайной величины .
В этом пункте хотелось бы указать важность именно второго параметра. Лучше всего это показать на примере. Рассмотрим вычисление определенного интеграла.
Вычисление определенного интеграла эквивалентно вычислению площадей, что дает интуитивно понятный алгоритм вычисления интеграла (см. статью в Википедии). Я рассмотрю более эффективный метод (частный случай формулы для которого, впрочем, тоже есть в статье из Википедии). Однако не все знают, что вместо равномерно распределенной случайной величины в этом методе можно использовать практически любую случайную величину, заданную на том же интервале.
Итак, требуется вычислить определенный интеграл:
dx%7D)
Выберем произвольную случайную величину с плотностью распределения ) , определенной на интервале
, определенной на интервале ) . И рассмотрим случайную величину
. И рассмотрим случайную величину %2F%7B%7Bp%7D_%7B%5Cxi%20%7D%7D(%5Cxi%20)) .
.
Математическое ожидание последней случайной величины равно:
![M\zeta =\int\limits_{a}^{b}{[g(x)/{{p}_{\xi }}(x)]{{p}_{\xi }}(x)dx=I}](http://tex.s2cms.ru/svg/M%5Czeta%20%3D%5Cint%5Climits_%7Ba%7D%5E%7Bb%7D%7B%5Bg(x)%2F%7B%7Bp%7D_%7B%5Cxi%20%7D%7D(x)%5D%7B%7Bp%7D_%7B%5Cxi%20%7D%7D(x)dx%3DI%7D)
Таким образом, получаем:
%5Capprox%200.9973.)
Последнее соотношение означает, что если выбрать значений , то при достаточно большом :
%7D%7B%7B%7Bp%7D_%7B%5Cxi%20%7D%7D(%7B%7B%5Cxi%20%7D_%7Bi%7D%7D)%7D%5Capprox%20I%7D) .
.
Таким образом, для вычисления интеграла, можно использовать практически любую случайную величину. Но дисперсия , а вместе с ней и оценка точности, зависит от того какую случайную величину взять для проведения расчетов.
Можно показать, что будет иметь минимальное значение, когда пропорционально |g(x)|. Выбрать такое значение в общем случае очень сложно (сложность эквивалентна сложности решаемой задачи), но руководствоваться этим соображением стоит, т.е. выбирать распределение вероятностей по форме схожее с модулем интегрируемой функции.
Теория, конечно, дело хорошее, но давайте рассмотрим численный пример: ;
;  ;
; %3Dcos(x)) .
.
Вычислим значение интеграла с применением двух различных случайных величин.
В первом случае будем использовать равномерно распределенную случайную величину на [a,b], т.е.%3D2%2F%5Cpi%20) .
.
Во втором случае возьмем случайную величину с линейной плотностью на [a,b], т.е.%3D%5Cfrac%7B4%7D%7B%5Cpi%20%7D(1-2x%2F%5Cpi%20)) .
.
Вот график, указанных функций
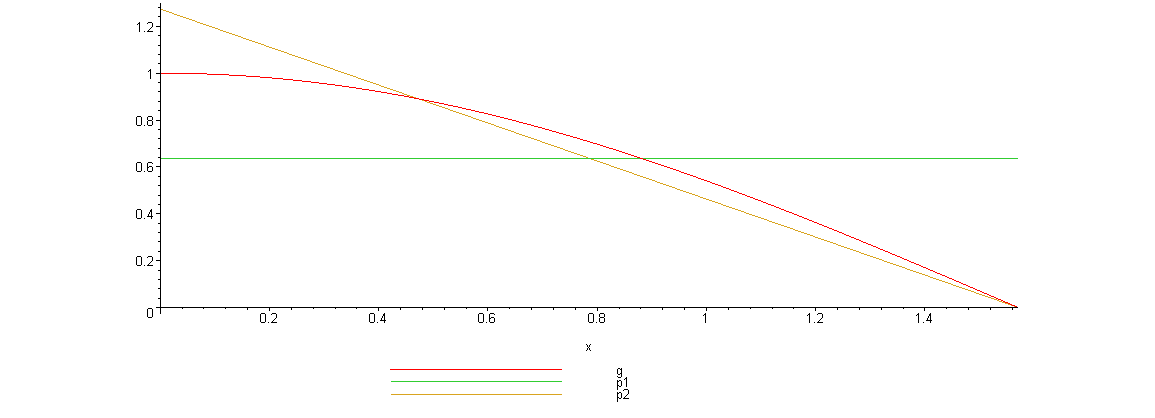
Нетрудно видеть, что линейная плотность лучше соответствует функции) .
.
Точное значение интеграла легко вычислить аналитически, оно равно 1.
Результаты одного моделирования при :
:
Для равномерно распределенной случайной величины: .
.
Для случайной величины с линейной плотностью распределения: .
.
В первом случае относительная погрешность более 21%, а во втором 2.35%. Точность в первом случае равна 0.459, а во втором – 0.123.
в первом случае равна 0.459, а во втором – 0.123.
Думаю, данный модельный пример показывает важность выбора случайной величины в методе Монте-Карло. Выбрав, правильную случайную величину, можно получить более высокую точность вычислений, при меньшем числе итераций.
Конечно, так не вычисляют одномерные интегралы, для этого есть более точные квадратурные формулы. Но ситуация меняется при переходе к многомерным интегралам, т.к. квадратурные формулы становятся громоздкими и сложными, а метод Монте-Карло применяется лишь с небольшими изменениями.
Не трудно видеть, что точность вычислений зависит от количества случайных величин включенных в сумму. Причем, для увеличения точности вычислений в 10 раз нужно увеличить в 100 раз.
При решении некоторых задач для получения приемлемой точности оценки требуется брать очень большое число. А учитывая, что метод зачастую работает очень быстро, то реализовать последнее при современных вычислительных возможностях совсем не сложно. И возникает соблазн просто увеличить число .
Если в качестве источника случайности используется некоторое физическое явление (физический датчик случайных чисел), то все работает отлично.
Часто для вычислений по методу Монте-Карло применяют датчики псевдослучайных чисел. Главная особенность таких генераторов – наличие некоторого периода.
Метод Монте-Карло можно использовать при значениях не превышающих (лучше много меньших) период вашего генератора псевдослучайных чисел. Последний факт вытекает из условия независимости случайных величин, используемых при моделировании.
При проведении больших расчетов нужно убедиться, что свойства генератора случайных чисел позволяют вам провести эти расчеты. В стандартных генераторах случайных чисел (в большинстве языков программирования) период чаще всего не превосходит 2 в степени разрядности операционной системы, а то и еще меньше. При использовании таких генераторов нужно быть чрезвычайно осторожным. Лучше изучить рекомендации Д.Кнута, и построить свой генератор, имеющий наперед известный и достаточно большой период.
Популярные лекции по математике 1968. Выпуск 46. Соболь И.М. Метод Монте-Карло. М.: Наука, 1968. — 64 с.
математических задач при помощи моделирования случайных величин. Представление об истории метода и простейшие примеры его применения можно найти в Википедии.
В самом методе нет ничего сложного. Именно эта простота объясняет популярность данного метода.
Метод имеет две основных особенности. Первая — простая структура вычислительного алгоритма. Вторая — ошибка вычислений, как правило, пропорциональна
Однако одну и ту же задачу можно решать различными вариантами метода Монте-Карло, которым отвечают различные значения
Общая схема метода
Допустим, что нам требуется вычислить какую-то неизвестную величину m. Попытаемся придумать такую случайную величину
Рассмотрим
На основе Центральной предельной теоремы (или если хотите предельной теоремы Муавра-Лапласа) не трудно получить соотношение:
где
Это — чрезвычайно важное для метода Монте-Карло соотношение. Оно дает и метод расчета
В самом деле, найдем
В зависимости от целей последнее соотношение используется по разному:
- Если взять k=3, то получим так называемое «правило
»:
- Если требуется конкретный уровень надежности вычислений
,
Точность вычислений
Как видно из приведенных выше соотношений, точность вычислений зависит от параметра
В этом пункте хотелось бы указать важность именно второго параметра
Вычисление определенного интеграла эквивалентно вычислению площадей, что дает интуитивно понятный алгоритм вычисления интеграла (см. статью в Википедии). Я рассмотрю более эффективный метод (частный случай формулы для которого, впрочем, тоже есть в статье из Википедии). Однако не все знают, что вместо равномерно распределенной случайной величины в этом методе можно использовать практически любую случайную величину, заданную на том же интервале.
Итак, требуется вычислить определенный интеграл:
Выберем произвольную случайную величину
Математическое ожидание последней случайной величины равно:
Таким образом, получаем:
Последнее соотношение означает, что если выбрать
Таким образом, для вычисления интеграла, можно использовать практически любую случайную величину
Можно показать, что
Численный пример
Теория, конечно, дело хорошее, но давайте рассмотрим численный пример:
Вычислим значение интеграла с применением двух различных случайных величин.
В первом случае будем использовать равномерно распределенную случайную величину на [a,b], т.е.
Во втором случае возьмем случайную величину с линейной плотностью на [a,b], т.е.
Вот график, указанных функций
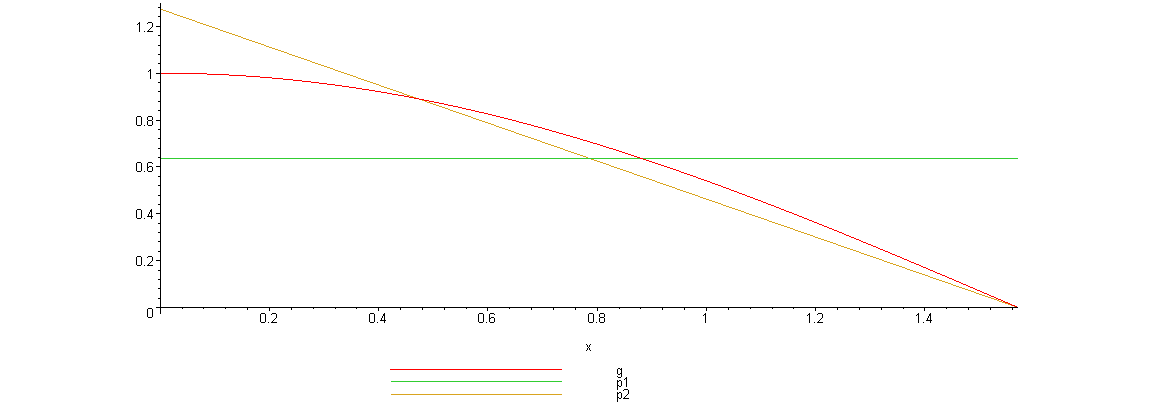
Нетрудно видеть, что линейная плотность лучше соответствует функции
Код программы модельного примера в математическом пакете Maple
Файл с данной программой можно взять тут
restart;
with(Statistics):
with(plots):
#исходные функции
g:=x->cos(x):
a:=0:
b:=Pi/2:
N:=10000:
#плотности распределений
p1:=x->piecewise(x>=a and x<b,1/(b-a)):
p2:=x->piecewise(x>=a and x<b,4/Pi-8*x/Pi^2):
#графики
plot([g(x),p1(x),p2(x)],x=a..b, legend=[g,p1,p2]);
#Точное значение интеграла
I_ab:=int(g(x),x=0..b);
#функция метода Монте-Карло для вычисления приближенного вычисления интеграла
#не стоит ее использовать при реальных расчетах
INT:=proc(g,p,N)
local xi;
xi:=Sample(RandomVariable(Distribution(PDF = p)),N);
evalf(add(g(xi[i])/p(xi[i]),i=1..N)/N);
end proc:
#Приближенное значение интеграла
I_p1:=INT(g,p1,N);#c равномерной плотностью
I_p2:=INT(g,p2,N);#c линейной плотностью
#Абсолютная погрешность
Delta1:=abs(I_p1-I_ab);#c равномерной плотностью
Delta2:=abs(I_p2-I_ab);#c линейной плотностью
#Относительные погрешности в процентах
delta1:=Delta1/I_ab*100;#c равномерной плотностью
delta2:=Delta2/I_ab*100;#c линейной плотностью
#Вычисление дисперсий
Dzeta1:=evalf(int(g(x)^2/p1(x),x=a..b)-1);
Dzeta2:=evalf(int(g(x)^2/p2(x),x=a..b)-1);
#Оценка погрешности в первом случае
3*sqrt(Dzeta1)/sqrt(N);
#Оценка погрешности во втором случае
3*sqrt(Dzeta2)/sqrt(N);
Файл с данной программой можно взять тут
Точное значение интеграла легко вычислить аналитически, оно равно 1.
Результаты одного моделирования при
Для равномерно распределенной случайной величины:
Для случайной величины с линейной плотностью распределения:
В первом случае относительная погрешность более 21%, а во втором 2.35%. Точность
Думаю, данный модельный пример показывает важность выбора случайной величины в методе Монте-Карло. Выбрав, правильную случайную величину, можно получить более высокую точность вычислений, при меньшем числе итераций.
Конечно, так не вычисляют одномерные интегралы, для этого есть более точные квадратурные формулы. Но ситуация меняется при переходе к многомерным интегралам, т.к. квадратурные формулы становятся громоздкими и сложными, а метод Монте-Карло применяется лишь с небольшими изменениями.
Количество итераций и генераторы случайных чисел
Не трудно видеть, что точность вычислений зависит от количества
При решении некоторых задач для получения приемлемой точности оценки требуется брать очень большое число
Если в качестве источника случайности используется некоторое физическое явление (физический датчик случайных чисел), то все работает отлично.
Часто для вычислений по методу Монте-Карло применяют датчики псевдослучайных чисел. Главная особенность таких генераторов – наличие некоторого периода.
Метод Монте-Карло можно использовать при значениях
При проведении больших расчетов нужно убедиться, что свойства генератора случайных чисел позволяют вам провести эти расчеты. В стандартных генераторах случайных чисел (в большинстве языков программирования) период чаще всего не превосходит 2 в степени разрядности операционной системы, а то и еще меньше. При использовании таких генераторов нужно быть чрезвычайно осторожным. Лучше изучить рекомендации Д.Кнута, и построить свой генератор, имеющий наперед известный и достаточно большой период.
Литература
Популярные лекции по математике 1968. Выпуск 46. Соболь И.М. Метод Монте-Карло. М.: Наука, 1968. — 64 с.
