 Есть три агрегатные функции, которые чаще всего используются на практике: COUNT, SUM и AVG.
Есть три агрегатные функции, которые чаще всего используются на практике: COUNT, SUM и AVG.И если первая уже обсуждалась ранее, то с остальными есть интересные нюансы с производительностью. Но давайте обо всем по порядку…
При использовании агрегатных функций на плане выполнения, в зависимости от входного потока, может встречаться два оператора: Stream Aggregate и Hash Match.
Для выполнения первого может требоваться предварительно отсортированный входной набор значений и при этом Stream Aggregate не блокирует выполнение последующих за ним операторов.
В свою очередь, Hash Match является блокирующим оператором (за редким исключением) и не требует сортировки входного потока. Для работы Hash Match используется хеш-таблица, которая создается в памяти и в случае неправильной оценки ожидаемого количества строк, оператор может сливать результаты в tempdb.
Итого получается, что Stream Aggregate хорошо работает на небольших отсортированных наборах данных, а Hash Match хорошо справляется с большими не отсортированными наборами и хорошо поддается параллельной обработке.
Теперь, когда мы преодолели теорию начнем смотреть как работают агрегатные функции.
Предположим, что нам нужно подсчитать среднюю цену среди всех продуктов:
SELECT AVG(Price) FROM dbo.Price
По таблице с достаточно простой структурой:
CREATE TABLE dbo.Price (
ProductID INT PRIMARY KEY,
LastUpdate DATE NOT NULL,
Price SMALLMONEY NULL,
Qty INT
)
Поскольку у нас происходит скалярная агрегация, на плане выполнения мы ожидаемо увидим Stream Aggregate:

Внутри этот оператор выполняет две агрегирующие операции COUNT_BIG и SUM (хотя на физическом уровне выполняется это как одна операция) по столбцу Price:
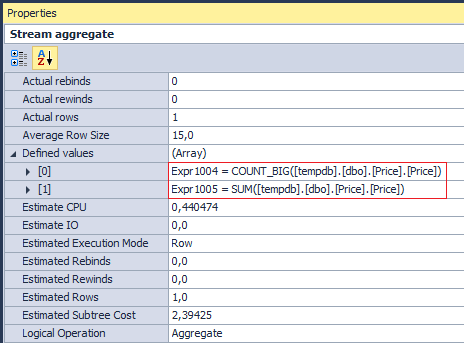
Не забываем, что среднее вычисляется только для NOT NULL, поскольку операция COUNT_BIG идет по столбцу, а не со звездочкой. Соответственно, такой запрос:
SELECT AVG(v)
FROM (
VALUES (3), (9), (NULL)
) t(v)
вернет в качестве результата не 4, а 6.
Теперь посмотрим на Compute Scalar, внутри которого есть интересное выражение для проверки деления на ноль:
Expr1003 =
CASE WHEN [Expr1004]=(0)
THEN NULL
ELSE [Expr1005]/CONVERT_IMPLICIT(money,[Expr1004],0)
END
Попробуем подсчитать общую сумму:
SELECT SUM(Price) FROM dbo.Price
План выполнения останется прежним:

Но если посмотреть на операции, которые выполняет Stream Aggregate…
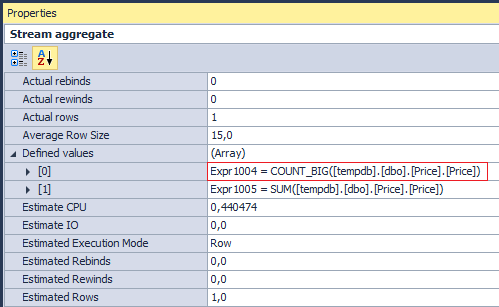
можно капельку удивиться. Зачем SQL Server подсчитывает количество, если мне нужна только сумма? Ответ кроется в Compute Scalar:
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
Если не брать во внимание COUNT, то согласно семантике языка T-SQL, когда нет строк во входном потоке, то мы должны возвращать NULL, а не 0. Такое поведение работает как для скалярной, так и для векторной агрегации:
SELECT LastUpdate, SUM(Price)
FROM dbo.Price
GROUP BY LastUpdate
OPTION(MAXDOP 1)
Expr1003 = Scalar Operator(CASE WHEN [Expr1008]=(0) THEN NULL ELSE [Expr1009] END)
Более того, такая проверка делается как для NULL, так и для NOT NULL столбцов. Теперь рассмотрим примеры в которых будут полезны описанные выше особенности SUM и AVG.
Если мы хотим посчитать среднее, то не нужно использовать COUNT + SUM:
SELECT SUM(Price) / COUNT(Price) FROM dbo.Price
Поскольку такой запрос будет менее эффективным, чем явное использование AVG.
Далее… Явно передавать NULL в агрегатную функцию нет необходимости:
SELECT
SUM(CASE WHEN Price < 100 THEN Qty ELSE NULL END),
SUM(CASE WHEN Price > 100 THEN Qty ELSE NULL END)
FROM dbo.Price
Поскольку в такой конструкции:
SELECT
SUM(CASE WHEN Price < 100 THEN Qty END),
SUM(CASE WHEN Price > 100 THEN Qty END)
FROM dbo.Price
Оптимизатор подстановку делает автоматически:
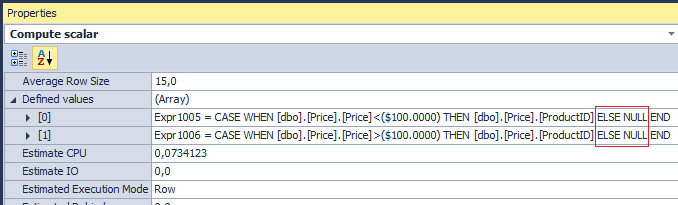
Но что, если я хочу получить 0 в результатах вместо NULL? Очень часто используют ELSE и не задумываются:
SELECT
SUM(CASE WHEN Price < 100 THEN Qty ELSE 0 END),
SUM(CASE WHEN Price > 100 THEN Qty ELSE 0 END)
FROM dbo.Price
Очевидно, что в таком случае мы достигнем желаемого… да и одно предупреждение перестанет мозолить глаза:
Warning: Null value is eliminated by an aggregate or other SET operation.
Хотя лучше всего писать запрос вот так:
SELECT
ISNULL(SUM(CASE WHEN Price < 100 THEN Qty END), 0),
ISNULL(SUM(CASE WHEN Price > 100 THEN Qty END), 0)
FROM dbo.Price
И это хорошо не потому, что оператор CASE станет работать быстрее. Мы то уже знаем, что оптимизатор туда подставляет ELSE NULL автоматом… Так в чем же преимущества последнего варианта?
Как оказалось, операции агрегирования, в которых преобладают NULL значения обрабатываются быстрее.
SET STATISTICS TIME ON
DECLARE @i INT = NULL
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(@i),(@i),(@i),(@i),(@i),
(@i),(@i),(@i),(@i),(@i)
) t(N)
),
E2(N) AS (SELECT @i FROM E1 a, E1 b),
E4(N) AS (SELECT @i FROM E2 a, E2 b),
E8(N) AS (SELECT @i FROM E4 a, E4 b)
SELECT SUM(N) -- 100.000.000
FROM E8
OPTION (MAXDOP 1)
Выполнение у меня заняло:
SQL Server Execution Times:
CPU time = 5985 ms, elapsed time = 5989 ms.
Теперь меняем:
DECLARE @i INT = 0
И выполняем повторно:
SQL Server Execution Times:
CPU time = 6437 ms, elapsed time = 6451 ms.
Не так существенно, но повод для оптимизации тем не менее это дает в определенных ситуациях.
Конец спектакля и занавес? Нет. Это еще не все…
Как говорил один мой знакомый: «Нет ни черного, ни белого… Мир многоцветен» и поэтому напоследок приведу интересный пример, когда NULL может вредить.
Создадим медленную функцию и тестовую таблицу:
USE tempdb
GO
IF OBJECT_ID('dbo.udf') IS NOT NULL
DROP FUNCTION dbo.udf
GO
CREATE FUNCTION dbo.udf (@a INT)
RETURNS VARCHAR(MAX)
AS BEGIN
DECLARE @i INT = 1000
WHILE @i > 0 SET @i -= 1
RETURN REPLICATE('A', @a)
END
GO
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b)
SELECT *
INTO #temp
FROM E4
И выполним запрос:
SET STATISTICS TIME ON
SELECT SUM(LEN(dbo.udf(N)))
FROM #temp
SQL Server Execution Times:
CPU time = 9109 ms, elapsed time = 11603 ms.
Теперь попробуем результат выражения, который передается в SUM, обернуть в ISNULL:
SELECT SUM(ISNULL(LEN(dbo.udf(N)), 0))
FROM #temp
SQL Server Execution Times:
CPU time = 4562 ms, elapsed time = 5719 ms.
Скорость выполнения сократилась в 2 раза. Сразу скажу, что это не магия… А баг в движке SQL Server-а, который Microsoft уже «вроде как» исправила в SQL Server 2012 CTP.
Суть проблемы в следующем: результат выражения внутри функций SUM или AVG может выполняться дважды, если оптимизатор считает, что может вернуться NULL.
Все тестировалось на Microsoft SQL Server 2012 (SP3) (KB3072779) — 11.0.6020.0 (X64).
Если хотите поделиться этой статьей с англоязычной аудиторией:
What is faster inside SUM & AVG: 0 or NULL?
