В один прекрасный момент для одного из проектов появилась необходимость в хранении, обработке и визуализации большого количества логов. Необходимо было индексировать около 10-20 тысяч запросов в секунду с пиками до сотни тысяч, что, как оказалось, является нетривиальной задачей. Для решения этой проблемы мы решили использовать уже знакомый многим ELK- стек. Единственным вопросом было — «а потянет ли он». Как оказалось, потянет, но не сразу.
Краткое описание задачи было таким: имеется куча узлов, они отправляют кучу логов на сервер, где их необходимо определенным образом обработать и сохранить. Количество логов представлялось нам около 10-20 тысяч логов в секунду с краткосрочными пиками до 100-150 тысяч в секунду.
Конфигурация у нас была следующая: три сервера, на каждом Logstash+ElasticSearch. Так же написали и закинули на такой же сервер простенькую java — программу, генерирующую и отправляющую логи в виде строк на один адрес по TCP. Сервера средние, 16 ядер, 32 гб оперативной памяти и без ssd.
Запустили ES, изменив только параметр indices.memory.index_buffer_size (который задает размер буфера для индексирования) на 30% (по стандарту 10%) подсмотрев это в каком-то мануале, создали файл настроек для logstash:
Запустили генератор и получили… 11 тысяч логов в секунду. А это без какой-либо обработки логов! Непозволительно мало, мы так даже нормальную работу не переживем, не говоря уж о «взрывах» логов. Начали читать, начали смотреть, наткнулись на статью о производительности ES, где говорилось о том, что количество шардов(shards) и реплик(replicas) очень сильно влияет на скорость индексирования. За такие настройки в ElasticSearch отвечают index-templates, которые конфигурируют заново создаваемые индексы. Сказано-сделано, создали темплейт:
Изменив количество шардов на 9 и количество реплик на 0 (по стандарту 5 шардов и 1 реплика) и запустили тест. 16 тысяч в секунду! Ускорение в полтора раза: уже неплохо, но все равно мало. Путем экспериментов нашли оптимальное количество: 18 шардов, 18 тысяч логов в секунду. Дальше этого не ушло. Все еще мало. Посмотрев график загрузки сервера во время работы увидели, что процессор нагружен на 20%, load и того меньше, и в io тоже не упираемся. Значит, простор для оптимизации еще есть! Решили перейти к настройкам Logstash. В output поставили workers => 8, что показывает, что для отправки логов в ES адо использовать 8 «воркеров», после чего скорость выросла до 20 тысяч\сек. Все еще мало.
Каким-то странным образом кто-то из нашей команды вышел на обсуждение ошибки LS связанной с OOM, для ее решения рекомендовали вручную выставить переменную окружения LS_HEAP_SIZE, которая управляет количеством памяти для процесса LS (проставляя -Xmx при запуске приложения). Хотя плагин Kopf и показывал использование heap всего на 40% (200 mb из 512) попробовали выставить ее, скорее из интереса. И сработало! На тех же настройках, на которых с дефолтным LS_HEAP_SIZE было 20 тысяч с LS_HEAP_SIZE = 8gb получилось 38 тысяч логов в секунду.
Внимательный читатель, должно быть, заметил несовпадение: кластер ES состоит из 3 серверов, а генерирующее приложение одно. Так и есть, для предыдущих тестов приложение писало логи на один из трех серверов. Для полноценного теста мы скопировали настройки LS на все три сервера, выставили им всем LS_HEAP_SIZE = 8gb, запустили три генерирующих приложения и надеялись получить трехкратный прирост произволительности (38*3 = 114 тысяч логов в секунду), но получилось «всего лишь» 95 тысяч. Не забывайте: обработки логов до сих пор нет.
Дальнейшие исследования настроек ES и LS не улучшили ситуацию а текущая производительность нас не устраивала, потому что клиенты не могут писать на один сервер больше 32 тысяч логов в секунду, «стопорясь» на отправке сетевых пакетов к Logstash. Подумали мы, почитали, и решили использовать буфер между генерирующим приложением и Logstash. В качестве такового мог выступить Redis, но для начала мы решили попробовать реализовать более простую вещь.
И вот что у нас получилось: вместо того, чтобы отправлять логи напрямую в Logstash мы принимаем их Rsyslog и складываем в файл. По проведенным нами тестам, производительность Rsyslog в получении и записи логов достигает около 570 000 логов в секунду, что покрывало наши потребности несколько раз. Из файла эти логи затем читаются logstash, который их обрабатывает и отправляет в ES.
В итоге, конфигурация LS была такой:
Тестировали сразу на трех серверах, получили 66 тысяч\сек. Зато теперь мы умеем переживать пики любого размера (главное, не слишком часто, чтобы средний поток логов не превышал 66000 логов\сек).
Остановившись на этом, добавили обработку логов. Обработка у нас была чисто символическая, просто парсинг логов через Grok-фильтр и 5 if-условий:
Тестировали сразу на 3 серверах, получили цифру 46 206 логов\сек, что уже достаточно для нормальной работы приложения, и для обработки данных из файла — буфера после пиков.
Есть, правда, одно НО: у одного из разработчиков возникла мысль, что производительность ES может деградировать со временем. Решили проверить — поставили систему работать на 9 часов без остановки. Результаты не порадовали: первые пару часов все было хорошо, затем производительность стала сильно проседать: суммарно получилось около 30 тысяч в секунду с секундными падениями до нуля.
Через 5 часов после этого мы запустили генерацию еще раз и получили уже знакомые 46 тысяч. За 9 часов мы нагенерили 1 203 453 573 лога, что в пересчете получается 37143 логов в секунду. Так как нормальная работа системы будет рассчитана на гораздо более маленькие объем, мы решили, что нас это вполне устраивает. Было высказано предположение, что такое поведение ES связано с тем, что ему необходимо «на лету» перестраивать индекс каждые 30 секунд(указано в настройках нами), а, так как, его объем при таком кол-ве информации стремится к полтерабайта, то делает он это долго. Изучение логов сервера косвенно подтвердило догадку: сервер упирался в iowait, с большим кол-вом чтения с диска.
Если кто-то знает более подробно с чем это связано и как решить — ждем ваших комментариев.
Краткое описание задачи было таким: имеется куча узлов, они отправляют кучу логов на сервер, где их необходимо определенным образом обработать и сохранить. Количество логов представлялось нам около 10-20 тысяч логов в секунду с краткосрочными пиками до 100-150 тысяч в секунду.
Конфигурация у нас была следующая: три сервера, на каждом Logstash+ElasticSearch. Так же написали и закинули на такой же сервер простенькую java — программу, генерирующую и отправляющую логи в виде строк на один адрес по TCP. Сервера средние, 16 ядер, 32 гб оперативной памяти и без ssd.
Запустили ES, изменив только параметр indices.memory.index_buffer_size (который задает размер буфера для индексирования) на 30% (по стандарту 10%) подсмотрев это в каком-то мануале, создали файл настроек для logstash:
Начальные настройки
input {
tcp {
port => "1515"
}
}
output {
elasticsearch {
cluster => "elasticsearch"
embedded => false
host => "localhost"
index => "performance_test"
}
}
Запустили генератор и получили… 11 тысяч логов в секунду. А это без какой-либо обработки логов! Непозволительно мало, мы так даже нормальную работу не переживем, не говоря уж о «взрывах» логов. Начали читать, начали смотреть, наткнулись на статью о производительности ES, где говорилось о том, что количество шардов(shards) и реплик(replicas) очень сильно влияет на скорость индексирования. За такие настройки в ElasticSearch отвечают index-templates, которые конфигурируют заново создаваемые индексы. Сказано-сделано, создали темплейт:
темплейт
template" : "performance*",
"settings" : {
"index.number_of_shards" : "9",
"index.refresh.interval" : "30s",
"index.number_of_replicas" : "0"
},
"mappings" : {
},
"aliases" : {
}
Изменив количество шардов на 9 и количество реплик на 0 (по стандарту 5 шардов и 1 реплика) и запустили тест. 16 тысяч в секунду! Ускорение в полтора раза: уже неплохо, но все равно мало. Путем экспериментов нашли оптимальное количество: 18 шардов, 18 тысяч логов в секунду. Дальше этого не ушло. Все еще мало. Посмотрев график загрузки сервера во время работы увидели, что процессор нагружен на 20%, load и того меньше, и в io тоже не упираемся. Значит, простор для оптимизации еще есть! Решили перейти к настройкам Logstash. В output поставили workers => 8, что показывает, что для отправки логов в ES адо использовать 8 «воркеров», после чего скорость выросла до 20 тысяч\сек. Все еще мало.
Каким-то странным образом кто-то из нашей команды вышел на обсуждение ошибки LS связанной с OOM, для ее решения рекомендовали вручную выставить переменную окружения LS_HEAP_SIZE, которая управляет количеством памяти для процесса LS (проставляя -Xmx при запуске приложения). Хотя плагин Kopf и показывал использование heap всего на 40% (200 mb из 512) попробовали выставить ее, скорее из интереса. И сработало! На тех же настройках, на которых с дефолтным LS_HEAP_SIZE было 20 тысяч с LS_HEAP_SIZE = 8gb получилось 38 тысяч логов в секунду.
Внимательный читатель, должно быть, заметил несовпадение: кластер ES состоит из 3 серверов, а генерирующее приложение одно. Так и есть, для предыдущих тестов приложение писало логи на один из трех серверов. Для полноценного теста мы скопировали настройки LS на все три сервера, выставили им всем LS_HEAP_SIZE = 8gb, запустили три генерирующих приложения и надеялись получить трехкратный прирост произволительности (38*3 = 114 тысяч логов в секунду), но получилось «всего лишь» 95 тысяч. Не забывайте: обработки логов до сих пор нет.
Дальнейшие исследования настроек ES и LS не улучшили ситуацию а текущая производительность нас не устраивала, потому что клиенты не могут писать на один сервер больше 32 тысяч логов в секунду, «стопорясь» на отправке сетевых пакетов к Logstash. Подумали мы, почитали, и решили использовать буфер между генерирующим приложением и Logstash. В качестве такового мог выступить Redis, но для начала мы решили попробовать реализовать более простую вещь.
И вот что у нас получилось: вместо того, чтобы отправлять логи напрямую в Logstash мы принимаем их Rsyslog и складываем в файл. По проведенным нами тестам, производительность Rsyslog в получении и записи логов достигает около 570 000 логов в секунду, что покрывало наши потребности несколько раз. Из файла эти логи затем читаются logstash, который их обрабатывает и отправляет в ES.
В итоге, конфигурация LS была такой:
финальная конфигурация
input {
file {
path => "/root/logs/log.log"
start_position => "end"
}
}
output {
elasticsearch {
cluster => "elasticsearch"
embedded => false
host => "localhost"
index => "performance_testing"
workers => "8"
}
}
Тестировали сразу на трех серверах, получили 66 тысяч\сек. Зато теперь мы умеем переживать пики любого размера (главное, не слишком часто, чтобы средний поток логов не превышал 66000 логов\сек).
Остановившись на этом, добавили обработку логов. Обработка у нас была чисто символическая, просто парсинг логов через Grok-фильтр и 5 if-условий:
Grok фильтры
filter {
grok{
match => {"message" => "%{MONTH:month} %{NUMBER:date} %{TIME:time} %{URIHOST:sender} %{WORD:grokanchor} %{NUMBER:mstatus} %{WORD:salt}"}
remove_field => ["grokanchor"]
}
if [mstatus]{
if [mstatus] > "90"{
mutate {
add_tag => ["morethanninety"]
}
}
else if [mstatus] > "80"{
mutate {
add_tag => ["morethaneighty"]
}
}
else if [mstatus] > "70"{
mutate {
add_tag => ["morethanseventy"]
}
}
else if [mstatus] > "60"{
mutate {
add_tag => ["morethansixty"]
}
}
else if [mstatus] > "50"{
ate {
add_tag => ["morethanfifty"]
}
}
}
}
Тестировали сразу на 3 серверах, получили цифру 46 206 логов\сек, что уже достаточно для нормальной работы приложения, и для обработки данных из файла — буфера после пиков.
Есть, правда, одно НО: у одного из разработчиков возникла мысль, что производительность ES может деградировать со временем. Решили проверить — поставили систему работать на 9 часов без остановки. Результаты не порадовали: первые пару часов все было хорошо, затем производительность стала сильно проседать: суммарно получилось около 30 тысяч в секунду с секундными падениями до нуля.
Количество логов в час
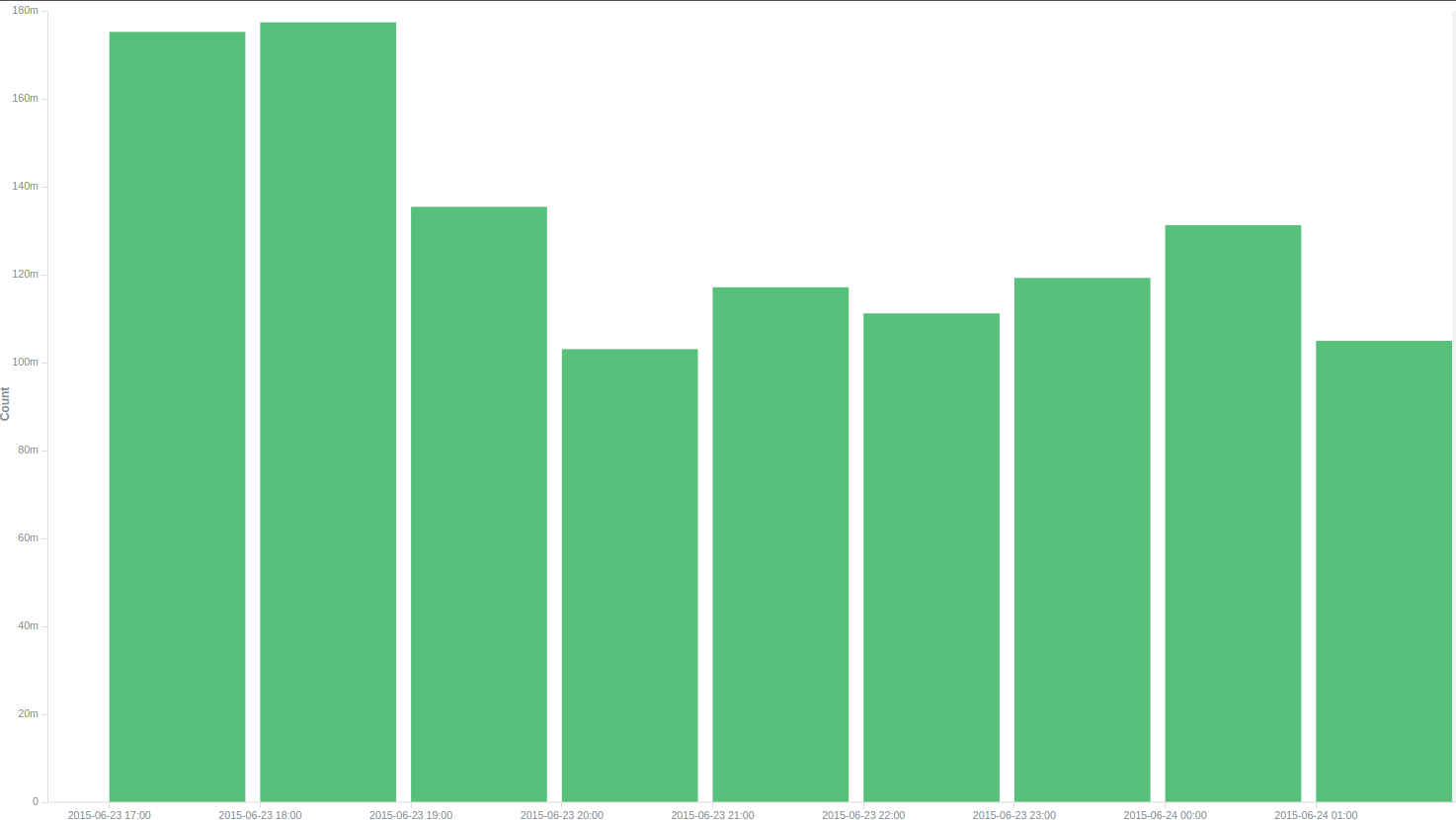
Через 5 часов после этого мы запустили генерацию еще раз и получили уже знакомые 46 тысяч. За 9 часов мы нагенерили 1 203 453 573 лога, что в пересчете получается 37143 логов в секунду. Так как нормальная работа системы будет рассчитана на гораздо более маленькие объем, мы решили, что нас это вполне устраивает. Было высказано предположение, что такое поведение ES связано с тем, что ему необходимо «на лету» перестраивать индекс каждые 30 секунд(указано в настройках нами), а, так как, его объем при таком кол-ве информации стремится к полтерабайта, то делает он это долго. Изучение логов сервера косвенно подтвердило догадку: сервер упирался в iowait, с большим кол-вом чтения с диска.
Нагрузка на сервер
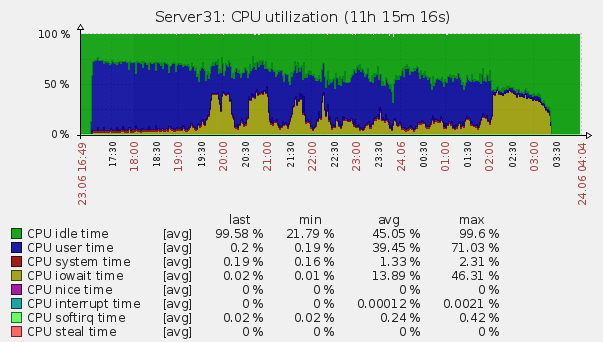
Если кто-то знает более подробно с чем это связано и как решить — ждем ваших комментариев.
