
Мы в «Латере» занимаемся созданием биллинга для операторов связи. В блоге на Хабре мы не только рассказываем об особенностях нашей системы и деталях ее разработки (например, обеспечении отказоустойчивости), но и публикуем материалы о работе с инфраструктурой в целом. Разработчик и системный архитектор Михаель Виттиг (Michael Wittig) написал в блоге Cloudonout интересный материал о наиболее распространенных ошибках при работе с сервисом AWS (Amazon Web Services). Мы представляем вашему вниманию основные тезисы этой заметки.
Виттиг работает консультантом по AWS и повидал много вариантов развертывания ПО, вне зависимости от размера — по большей части, это стандартные веб-приложения. Инженер составил список из 5 наиболее частых ошибок пользователей, которых следует избегать.
Как выглядит типичное веб-приложение
Стандартное веб-приложение состоит из:
- балансировщика нагрузки;
- масштабируемой серверной части (web backend’а);
- хранилища.
На схеме это выглядит примерно так:

Это общепринятая схема. На использование какого-то другого способа конструирования приложения должны быть веские причины.
Ошибка 1. Управление инфраструктурой вручную
Если установки в AWS были сделаны с помощью кликов на консоли, значит, управление инфраструктурой осуществляется вручную. Главная проблема с таким вариантом управления – эти установки невозможно воспроизвести, они нигде не зарегистрированы. Как результат – вероятна масса ошибок. К счастью, есть AWS CloudFormation, с помощью которого можно решить эту проблему задаром.
Вместо создания ресурсов (инстансов EC2, групп безопасности, подсетей) вручную можно описать их в шаблоне, создать свой или использовать готовый. CloudFormation сам позаботится о том, как интегрировать их в действующий стэк. Сервис создаст ресурсы в правильном порядке, как представлено на картинке:
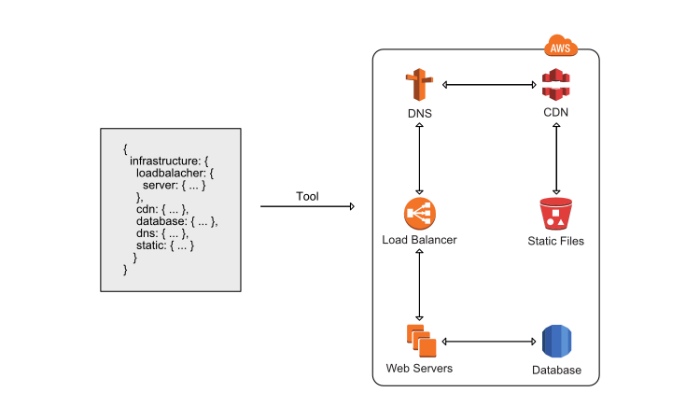
Шаблон можно обновлять. Посмотреть пример стандартного шаблона для веб-приложения можно здесь. Виттиг убежден, что управлять инфраструктурой вручную непрофессионально — слишком много проблем может принести такой способ работы.
Ошибка 2. Неиспользование Auto Scaling Groups
Некоторые наивно полагают, что могут масштабировать ресурсы самостоятельно, не прибегая к помощи специальной функции. Каждый EC2 инстанс должен быть запущен в Auto Scaling Group. Даже если это отдельный инстанс. Auto Scaling Group контролирует запуск необходимого числа инстансов. По сути, он ведет себя как логическая группа виртуальных машин. Функцией можно пользоваться бесплатно.
В стандартном веб-приложении серверы запускаются на виртуальных машинах внутри Auto Scaling Group. Существует возможность варьирования объемов вычислительных ресурсов, исходя из загрузки, ориентируясь на повышение или снижение спроса. Администратор может прописать условия, при которых будет запускаться автоматическое масштабирование. Это может быть порог производительности CPU логической группы или количество запросов в балансировке загрузки.
Ошибка 3. Пренебрежение к аналитике Amazon Cloud Watch
Интересные данные о работе сервисов AWS можно получать через Cloud Watch. Виртуальные машины оповещают о загрузке процессора, сети, работе диска. Хранилища предоставляют информацию об использовании памяти и количестве операций ввода/вывода. Вам остается только правильно использовать эту статистику. Давайте посмотрим на график работы CPU за сутки:

Видите пик загрузки? Виттиг убежден, что этот скачок происходил каждый день в одно и то же время:
Похоже на проделки планировщика задач. Так оно и есть. Учтите, что с этой машины запускался веб-сервер. Значит, каждый день время ожидания увеличивалось из-за планировщика. Запустите его на отдельной виртуальной машине, и проблема будет решена. Без Cloud Watch выявить ее было бы затруднительно.
Как только данные проанализированы, следует поставить маркеры оповещения предельных значений. Никак не наоборот!
Ошибка 4. Игнорирование Trusted Advisor
Инструмент Trusted Advisor производит проверку среды AWS, на соответствие лучшим практикам работы с сервисом. Проверяемые параметры:
- оптимизация затрат;
- производительность;
- безопасность;
- устойчивость к сбоям.
Если консоль управления Trusted Advisor выглядит следующим образом:
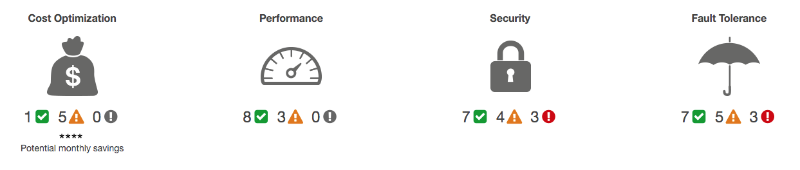
Можно смело начать оптимизировать процессы в среде уже сейчас, считает Виттиг.
Я бы посоветовал, в первую очередь, обратить внимание на безопасность. Вы можете попробовать функцию еженедельной обратной связи, и Trusted Advisor будет докладывать обо всех текущих и решенных проблемах. Вы можете активировать бесплатную версию программы. Платная поддержка откроет дополнительные возможности для проверки.
Ошибка 5. Недооценка возможностей виртуальных машин
Нет смысла не снижать размер инстанса (количество машин или категорию с c3.xlarge до c3.large), если выясняется, что существующие EC2-инстансы недоиспользуются. Узнать об этом можно, сверившись с данными Cloud Watch. Если проект применяет Auto Scaling Groups, его администраторам нужно перенастроить параметры автоматического масштабирования, масштабировать ресурсы в пользу увеличения позже, а в сторону уменьшения раньше.
Другие интересные статьи в блоге «Латеры»:
