Рано или поздно IT-проекты сталкиваются со сложностями поддержания высокого качества кода и/или увеличивающимся временем доставки изменений в production. Lingualeo испытала на себе все проблемы роста и готова поделиться своей историей повышения эффективности разработки. О том, как это происходило, рассказал teamlead инфраструктурой команды Lingualeo Михаил Кабищев.

Как и любая другая технологическая компания, Lingualeo проходила через несколько этапов:
В итоге рутинные операции начинают отнимать очень много времени, и компания думает, как автоматизировать эти процессы.
Интуитивно команда Lingualeo достаточно быстро понимала, что пора переходить на следующий этап. Иногда переход происходил в правильном русле, а иногда не очень. В какой-то момент в компании сформировались несколько команд разработки, которые работали в одной общей системе. У каждой команды был свой проект в jira, собственная CI-система (система Continuous Integration), умеющая запускать юнит-тесты, разворачивать площадки для тестирования, собирать и деплоить релизы.
Звучит вроде бы неплохо, да?
Но все равно в этом подходе были моменты, которые нам не очень нравились:
Большое количество проектов в jira. Изначально все использовали один workflow. Но потом одна команда добавила дополнительное поле, другая — промежуточный статус и так далее. Из-за этого постоянно приходилось вносить изменения в CI-систему, и иногда эти изменения конфликтовали друг с другом.
Самописная CI-система. Она была классная, полностью решала поставленные перед ней задачи до того момента, как разработчиков стало много, они почувствовали свободу и начали активно создавать новые репозитории. Система оказалась не готова к такому. Сборку приходилось ждать очень долго, просмотр логов был реализован не самым удачным образом, а еще и задания на сборку релизов висели в общей очереди.
Деплой. Механизм деплоя был заточен под релиз только одного приложения. При этом у нас была потребность в нескольких.
На очередном ретро мы поняли, что жить так дальше нельзя, и выдвинули несколько тезизов:
Учитывая свой предыдущий опыт при проектировании нового workflow, решили разделить все возможные типы задач на две группы:
Это задачи, которые не требуют написания кода и имеют простейший flow:

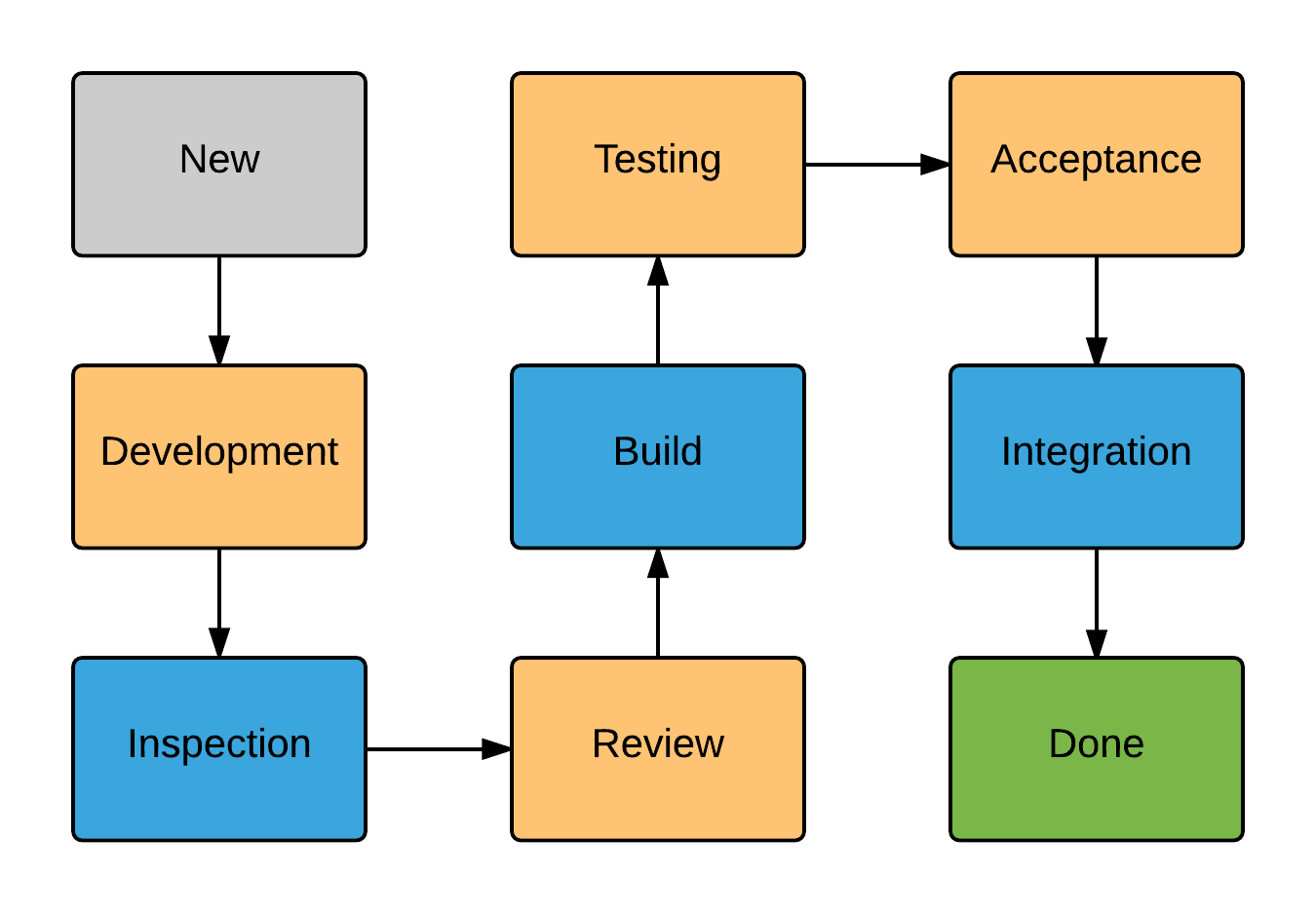
Желтым цветом на схеме указаны шаги, которые необходимо выполнять вручную, а синим те, которые нужно автоматизировать
Такие задачи уже требуют написания кода в одном из репозиториев. В качестве фреймворка для работы с кодом мы используем gitflow, поэтому разделение следующее:
Назначение типов можно прочитать в любом описании про gitflow. Мы разделили feature и bug на отдельные типы, так Lingualeo удобнее расставлять приоритеты для задач и вести аналитику. Раньше каждая команда имела свою собственную agile-доску со своими задачами, это было очень удобно, и нужно было придумать способ разделения задач по командам.
Также у нас существовали небольшие проблемы с использованием поля assignee: при некоторых переходах оно менялось, при некоторых — нет, а иногда менялось совсем не на того человека. Мы решили ввести жесткое правило: если твое имя находится в поле assignee, значит ты в этот момент отвечаешь за эту задачу. Вот список интересных полей, которые мы стали активно использовать:
Точно так же, как и все, команда Lingualeo смотрела на трех основных игроков на этом рынке: Jenkins, Teamcity, Bamboo. Потестировали все три, но больше всего понравился Teamcity: бесплатный, есть удобный REST API и приятный интерфейс.
Итак, мы получили следующую конфигурацию: jira — для ведения задач, teamcity -для прогона тестов, сборки релизов и т.д и github — для хранения кода. Нам нужно было подружить все эти системы вместе.
Для каждой пары существует несколько плагинов, но все они показались нам либо не очень удобными, либо не предоставляли нужного функционала. Поэтому мы решили написать небольшое ядро, которое будет управлять всеми системами.

При проектировании мы учли требование «безболезненно и минимальными усилиями заменить любой компонент системы”. Например, для замены build-сервера нам придется всего лишь написать новый адаптер, а не искать кучу плагинов.
Мы хотели, чтобы J.A.R.V.I.S. умел делать за нас следующие операции:
Помимо этого мы хотели как можно реже вносить изменения в исходный код системы, она должна предоставлять нам блоки (действия), из которых мы будем собирать наши процессы, а сама последовательность действий и условия, при которых их выполнять, мы решили описывать в виде yaml-файлов. Вот пример конфигурации, в котором описаны правила для запуска проверки кода:
Первое правило находит все тикеты со статусом Ready for Inspection и запускает соответствующую конфигурация в teamcity, которая проверяет код на соответствие стандартам, а также прогоняет все unit-тесты. Если запуск конфигурации удался, то к тикету применяется переход start inspection, и он переходит в статус On Inspection. Второе правило проверяет все запущенные конфигурации. Если она успешно завершилась, то тикет переходит дальше. Если во время сборки произошли ошибки, то тикет через переход Fail Inspection возвращается назад к разработчику.
Lingualeo использует эту схему не только для основного репозитория, но и для всех внутренних библиотек и для мобильных приложений. В этом случае создание тестовых стендов и деплой заменяется на сборку тестовых и production версий приложений. Добавление нового репозитория занимает всего несколько минут, и для него мы получаем автоматическую проверку качества кода, создание review, сборку билдов и релиз.
Сам J.A.R.V.I.S. разрабатывается и собирается тоже с помощью J.A.R.V.I.S.`a :)
Благодаря унификации процесса разработки в компании и создании J.A.R.V.I.S.`a мы смогли повысить качество выпускаемого нами кода и уменьшить время доставки изменений в production, уменьшили время разработчиков, которое тратилось на рутинные операции.

Как и любая другая технологическая компания, Lingualeo проходила через несколько этапов:
- Начало разработки продукта. Разработка и отладка происходит на одном-единственном сервере, где запущено все, что нужно проекту. Ошибки бывают часто, но это не страшно, т.к. это все лишь прототип, и живых пользователей там еще нет.
- Появление первых пользователей. Компания начинает ощущать цену ошибок и проблем на продакшене. Уже нельзя править все на продакшене, приходит понимание того, что нужно мыслить релизами. Разработчики внедряют workflow для работы с кодовой базой, появляется что-то вроде stage-сервера, на котором тестируются релизы.
- Рост проекта и команды. В разработке одновременно находится большое количество задач. Требования к процессу и качеству кода сильно возрастают. За всем очень тяжело следить: кто-то забывает запустить юнит-тесты, кто-то не знает, куда и как нужно задеплоить очередную задачу для тестирования.
В итоге рутинные операции начинают отнимать очень много времени, и компания думает, как автоматизировать эти процессы.
Интуитивно команда Lingualeo достаточно быстро понимала, что пора переходить на следующий этап. Иногда переход происходил в правильном русле, а иногда не очень. В какой-то момент в компании сформировались несколько команд разработки, которые работали в одной общей системе. У каждой команды был свой проект в jira, собственная CI-система (система Continuous Integration), умеющая запускать юнит-тесты, разворачивать площадки для тестирования, собирать и деплоить релизы.
Звучит вроде бы неплохо, да?
Но все равно в этом подходе были моменты, которые нам не очень нравились:
Большое количество проектов в jira. Изначально все использовали один workflow. Но потом одна команда добавила дополнительное поле, другая — промежуточный статус и так далее. Из-за этого постоянно приходилось вносить изменения в CI-систему, и иногда эти изменения конфликтовали друг с другом.
Самописная CI-система. Она была классная, полностью решала поставленные перед ней задачи до того момента, как разработчиков стало много, они почувствовали свободу и начали активно создавать новые репозитории. Система оказалась не готова к такому. Сборку приходилось ждать очень долго, просмотр логов был реализован не самым удачным образом, а еще и задания на сборку релизов висели в общей очереди.
Деплой. Механизм деплоя был заточен под релиз только одного приложения. При этом у нас была потребность в нескольких.
На очередном ретро мы поняли, что жить так дальше нельзя, и выдвинули несколько тезизов:
- Вся разработка должна “переехать” в единый проект в jira с единым для всех workflow
- Можно использовать готовый build-сервер вместо самописного
- Система деплоя должна быть универсальной, чтобы деплоить разные приложения
Единый проект в Jira
Учитывая свой предыдущий опыт при проектировании нового workflow, решили разделить все возможные типы задач на две группы:
Task
Это задачи, которые не требуют написания кода и имеют простейший flow:

- Task. Просто задача. Это может быть research, добавление нового репозитория, написание документации и т.д.
- Migration. Все миграции для базы данных мы выполняем вручную. Вручную не означает, что мы делаем это прямо в sql-консоли, для этого есть ряд инструментов, но их запуск происходит вручную.
CI-unit

Желтым цветом на схеме указаны шаги, которые необходимо выполнять вручную, а синим те, которые нужно автоматизировать
Такие задачи уже требуют написания кода в одном из репозиториев. В качестве фреймворка для работы с кодом мы используем gitflow, поэтому разделение следующее:
- feature
- bug
- hotfix
Назначение типов можно прочитать в любом описании про gitflow. Мы разделили feature и bug на отдельные типы, так Lingualeo удобнее расставлять приоритеты для задач и вести аналитику. Раньше каждая команда имела свою собственную agile-доску со своими задачами, это было очень удобно, и нужно было придумать способ разделения задач по командам.
Также у нас существовали небольшие проблемы с использованием поля assignee: при некоторых переходах оно менялось, при некоторых — нет, а иногда менялось совсем не на того человека. Мы решили ввести жесткое правило: если твое имя находится в поле assignee, значит ты в этот момент отвечаешь за эту задачу. Вот список интересных полей, которые мы стали активно использовать:
- Team. Имя команды, владеющей задачей.
- Component. В нашем случае component однозначно указывает на репозиторий. Хотя jira и позволяет указывать несколько значений в поле component, проблем с этим у нас не возникало.
- FixVersion. Номер релиза, в который попадет(попала) задача.
- Reporter. Человек, который создал задачу.
- Customer. Это заказчик задачи. По умолчанию он равен reporter`у, но может быть изменен. Именно он производит приемку задачи.
- Developer. Разработчик, ответственный за задачу. У задачи могут подзадачи, которые будут делать разные люди, но именно developer отвечает за задачу целиком.
- QA Engineer. По аналогии c developer`ом, этот человек отвечает за тестировании задачи целиком.
- Code reviewer. Все задачи (ну ладно, почти все) у нас проходят code-review, и это тот человек, который этим занимается.
Build-сервер
Точно так же, как и все, команда Lingualeo смотрела на трех основных игроков на этом рынке: Jenkins, Teamcity, Bamboo. Потестировали все три, но больше всего понравился Teamcity: бесплатный, есть удобный REST API и приятный интерфейс.
Так кто такой J.A.R.V.I.S.?
Итак, мы получили следующую конфигурацию: jira — для ведения задач, teamcity -для прогона тестов, сборки релизов и т.д и github — для хранения кода. Нам нужно было подружить все эти системы вместе.
Для каждой пары существует несколько плагинов, но все они показались нам либо не очень удобными, либо не предоставляли нужного функционала. Поэтому мы решили написать небольшое ядро, которое будет управлять всеми системами.
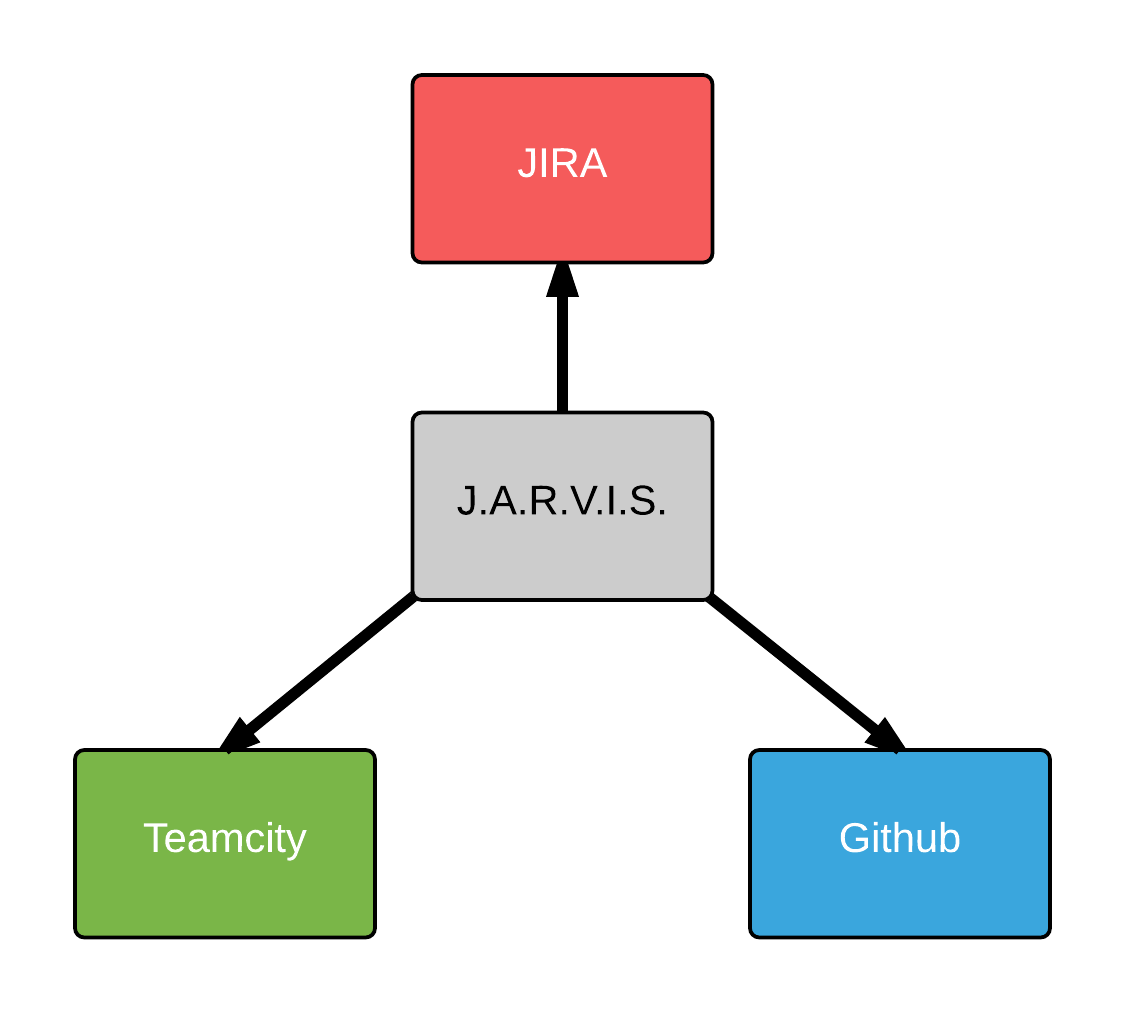
При проектировании мы учли требование «безболезненно и минимальными усилиями заменить любой компонент системы”. Например, для замены build-сервера нам придется всего лишь написать новый адаптер, а не искать кучу плагинов.
Мы хотели, чтобы J.A.R.V.I.S. умел делать за нас следующие операции:
- проверять код на соответствие стандартам
- запускать unit-тесты
- создавать и мерджить pull request`ы в github`e
- создавать тестовые стенды для тестирования задач
- создавать релизные и хотфиксные ветки
- производить деплой
Помимо этого мы хотели как можно реже вносить изменения в исходный код системы, она должна предоставлять нам блоки (действия), из которых мы будем собирать наши процессы, а сама последовательность действий и условия, при которых их выполнять, мы решили описывать в виде yaml-файлов. Вот пример конфигурации, в котором описаны правила для запуска проверки кода:
start inspection:
search:
jql: 'project="DEV" AND status="Ready for Inspection"'
action:
type: 'run-build'
params:
buildTypeId: 'CodeInspection_%component%'
success:
transition: 'start inspection'
fail:
transition: 'fail inspection'
complete inspection:
search:
jql: 'project="DEV" and status="On inspection"'
action:
type: 'check-build'
params:
buildTypeId: 'CodeInspection_%component%'
success:
transition: 'complete inspection'
fail:
transition: 'fail inspection'
Первое правило находит все тикеты со статусом Ready for Inspection и запускает соответствующую конфигурация в teamcity, которая проверяет код на соответствие стандартам, а также прогоняет все unit-тесты. Если запуск конфигурации удался, то к тикету применяется переход start inspection, и он переходит в статус On Inspection. Второе правило проверяет все запущенные конфигурации. Если она успешно завершилась, то тикет переходит дальше. Если во время сборки произошли ошибки, то тикет через переход Fail Inspection возвращается назад к разработчику.
Lingualeo использует эту схему не только для основного репозитория, но и для всех внутренних библиотек и для мобильных приложений. В этом случае создание тестовых стендов и деплой заменяется на сборку тестовых и production версий приложений. Добавление нового репозитория занимает всего несколько минут, и для него мы получаем автоматическую проверку качества кода, создание review, сборку билдов и релиз.
Сам J.A.R.V.I.S. разрабатывается и собирается тоже с помощью J.A.R.V.I.S.`a :)
Благодаря унификации процесса разработки в компании и создании J.A.R.V.I.S.`a мы смогли повысить качество выпускаемого нами кода и уменьшить время доставки изменений в production, уменьшили время разработчиков, которое тратилось на рутинные операции.
