Хочу начать со слов благодарности тому человеку, который мне вчера накинул кармы, позволив этим писать мне в персональный блог.
Долго думал, о чем же написать свой «первый» топик… Слово первый не зря взял в кавычки, так как первый топик на самом деле уже был, опыт был к сожалению неудачный — дело закончилось баном. Решил больше не копипастить. Уверенности тому, что надо написать что-то свое, придал вот этот топик. Решил твердо — пусть это будет и редко, но буду писать сам.
Ну, едем дальше!
Совсем недавно, по роду свой деятельности, мне пришлось столкнуться с таким понятием как ORM — (англ. Object-relational mapping). В двух словах ORM — это отображение объектов какого-либо объектно-ориентированного языка в структуры реляционных баз данных. Именно объектов, таких, какие они есть, со всеми полями, значениями, отношениями м/у друг другом.
ORM-решением для языка Java, является технология Hibernate, которая не только заботится о связи Java классов с таблицами базы данных (и типов данных Java в типы данных SQL), но также предоставляет средства для автоматического построения запросов и извлечения данных и может значительно уменьшить время разработки, которое обычно тратится на ручное написание SQL и JDBC кода. Hibernate генерирует SQL вызовы и освобождает разработчика от ручной обработки результирующего набора данных и конвертации объектов, сохраняя приложение портируемым во все SQL базы данных.
Итак, перед нами стоит задача написать небольшое приложение, которое бы осуществляло простое взаимодействие с базой данных, посредством технологии Hibernate.
Немного подумав, решил написать так называемый «Виртуальный автопарк». Суть парка такова: есть автобусы, есть маршруты и есть водители. Автобусы и маршруты связаны отношением один ко многим, т.е. на одном маршруте может кататься сразу несколько автобусов. Водители и автобусы связаны отношением многие ко многим, т.е. один водитель может водить разные автобусы и один автобус могут водить разные водители. Вроде ничего сложного.
Вот схема базы данных.
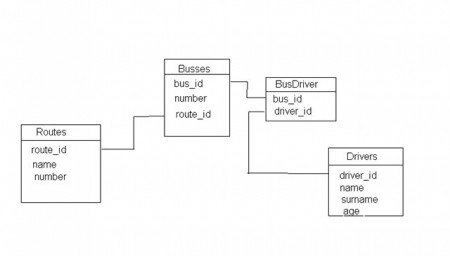
За качество не ругайте — под рукой не оказалось нормального инструмента таблички рисовать…
Вот ссылка на дамп, снятый с базы, вдруг кто-то решит все это дело поднять :)
Приступаем к коду. Во первых нам необходимо описать классы наших сущностей, т.е. класс автобуса, водителя и маршрута.
Класс автобус.
package logic;
import java.util.Set;
import java.util.HashSet;
public class Bus {
private Long id;
private String number;
private Set drivers = new HashSet();
private Long route_id;
public Bus() {
}
public void setId(Long id) {
this.id = id;
}
public void setNumber(String number) {
this.number = number;
}
public void setDrivers(Set drivers) {
this.drivers = drivers;
}
public void setRoute_id(Long route_id) {
this.route_id = route_id;
}
public Long getId() {
return id;
}
public String getNumber() {
return number;
}
public Set getDrivers() {
return drivers;
}
public Long getRoute_id() {
return route_id;
}
}* This source code was highlighted with Source Code Highlighter.
Класс водитель.
package logic;
import java.util.Set;
import java.util.HashSet;
public class Driver {
private Long id;
private String name;
private String surname;
private int age;
private Set busses = new HashSet();
public Driver() {
}
public void setBusses(Set busses) {
this.busses = busses;
}
public Set getBusses() {
return busses;
}
public void setId(Long id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setSurname(String surname) {
this.surname = surname;
}
public void setAge(int age) {
this.age = age;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
public String getSurname() {
return surname;
}
public int getAge() {
return age;
}
}* This source code was highlighted with Source Code Highlighter.
И класс маршрут.
package logic;
import java.util.Set;
import java.util.HashSet;
public class Route {
private Long id;
private String name;
private int number;
private Set busses = new HashSet();
public Route(){
}
public void setId(Long id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
public void setNumber(int number) {
this.number = number;
}
public void setBusses(Set busses) {
this.busses = busses;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
public int getNumber() {
return number;
}
public Set getBusses() {
return busses;
}
}* This source code was highlighted with Source Code Highlighter.
Заметьте, что все классы сущностей должны соответствовать Java naming conventions, т.е. у них должны быть обязательно геттеры, сеттеры и конструктор по умолчанию. Ничего сложного :)
Теперь для наших классов необходимо описать маппинг в виде xml-файлов, эти файлы как раз и будут отвечать за взаимодействие наших объектов с Hibernate и с базой данных.
Bus.hbm.xml
<hibernate-mapping>
<class name=«logic.Bus» table=«busses»>
<id column=«bus_id» name=«id» type=«java.lang.Long»>
<generator class=«increment»/>
</id>
<property column=«number» name=«number» type=«java.lang.String»/>
<set name=«drivers» table=«busDriver» lazy=«false»>
<key column=«bus_id»/>
<many-to-many column=«driver_id» class=«logic.Driver»/>
</set>
</class>
</hibernate-mapping>* This source code was highlighted with Source Code Highlighter.
Driver.hbm.xml
<hibernate-mapping>
<class name=«logic.Driver» table=«drivers»>
<id column=«driver_id» name=«id» type=«java.lang.Long»>
<generator class=«increment»/>
</id>
<property column=«name» name=«name» type=«java.lang.String»/>
<property column=«surname» name=«surname» type=«java.lang.String»/>
<property column=«age» name=«age» type=«java.lang.Integer»/>
<set name=«busses» table=«busDriver» lazy=«false»>
<key column=«driver_id»/>
<many-to-many column=«bus_id» class=«logic.Bus»/>
</set>
</class>
</hibernate-mapping>* This source code was highlighted with Source Code Highlighter.
Route.hbm.xml
<hibernate-mapping>
<class name=«logic.Route» table=«routes»>
<id column=«route_id» name=«id» type=«java.lang.Long»>
<generator class=«increment»/>
</id>
<property column=«name» name=«name» type=«java.lang.String»/>
<property column=«number» name=«number» type=«java.lang.Integer»/>
<set name=«busses» lazy=«false»>
<key column=«route_id»/>
<one-to-many class=«logic.Bus»/>
</set>
</class>
</hibernate-mapping>* This source code was highlighted with Source Code Highlighter.
Теперь давайте немного разберемся в этих xml-ных макаронах :)
- Тег hibernate-mapping я думаю понятен, тут ничего говорить не стоит.
- Тег class имеет два параметра: параметр name — Имя класса (необходимо указывать полный путь с учетом структуры пакетов) и параметр table — имя таблицы в базе данных, на которую будет маппиться наш класс.
- Тег id описывает идентификатор. Параметр column указывает на какую колонку в таблице будет ссылаться поле id нашего объекта, так же указываем класс и указываем generator, который отвечает за генерацию id.
- Тег property описывает простое поле нашего объекта, в качестве параметров указываем имя поля, его класс и имя колонки в таблице.
- Тег set описывает поле в котором содержится некий набор(коллекция) объектов. Тег содержит параметр name — имя поля нашего объекта, параметр table — имя таблицы связи(в случае отношения многие ко многим) и параметр lazy. Lazy, если меня не подводит моя память, с английского — ленивый. Так называемые ленивые коллекци, сейчас постараюсь объяснить понятнее. Когда мы в параметре lazy указываем значечение false, то у нас при получении объекта Route из базы вместе с объектом достается и коллекция объектов Bus, так как busses это поле объекта Route. А если в качестве параметра мы указываем значение true, то коллекция объектов Bus не вытаскивается, для ее получения надо явно вызывать метод route.getBusses(). Вот предположим такой очень хороший пример. Есть объект город, в него входит массив районов, в каждый район — массив улиц, в каждую улицу — массив домов и так далее до людей, живущих в квартирах. Предположим мы хотим вытянуть из базы названия районов. Если укажем lazy = false, то помимо районом у нас вытянется еще огромный объем «ненужных» данных, если же lazy = true, то мы получим то что надо и ничего лигнего.
- Тег key имеет параметр column, который говорит, на какую колонку в таблице связи будет ссылаться поле нашего объекта.
- Тег many-to-many описывает связь типа многие ко многим, в качестве параметров тег использует column — имя колонки второй колонки в таблице связи и параметр class, указывающий какого класса будут объеты на той стороне.
Теперь создадим главный конфигурационный файл hibernate.cfg.xml, файл, откуда он будет дергать всю необходимую ему информацию.
<hibernate-configuration>
<session-factory>
<property name=«connection.url»>jdbc:mysql://localhost/autopark</property>
<property name=«connection.driver_class»>com.mysql.jdbc.Driver</property>
<property name=«connection.username»>root</property>
<property name=«connection.password»/>
<property name=«connection.pool_size»>1</property>
<property name=«current_session_context_class»>thread</property>
<property name=«show_sql»>true</property>
<property name=«dialect»>org.hibernate.dialect.MySQL5Dialect</property>
<mapping resource=«logic/Bus.hbm.xml»/>
<mapping resource=«logic/Driver.hbm.xml»/>
<mapping resource=«logic/Route.hbm.xml»/>
</session-factory>
</hibernate-configuration>* This source code was highlighted with Source Code Highlighter.
Тут я не буду особо вдаваться в объяснение, думаю многим и так все понятно :) Скажу, что надо только в конце не забыть добавить тег mapping и указать в качестве параметра resources файлы конфигурации ваших бинов.
Теперь создадим класс, который будет хавать наш конфиг-файл и возвращать нам объект типа SessionFactory, который отвечает за создание hibernate-сессии.
package util;
import org.hibernate.cfg.Configuration;
import org.hibernate.SessionFactory;
public class HibernateUtil {
private static final SessionFactory sessionFactory;
static {
try {
sessionFactory = new Configuration().configure().buildSessionFactory();
} catch (Throwable ex) {
System.err.println(«Initial SessionFactory creation failed.» + ex);
throw new ExceptionInInitializerError(ex);
}
}
public static SessionFactory getSessionFactory() {
return sessionFactory;
}
}* This source code was highlighted with Source Code Highlighter.
Теперь нам осталось разобраться со взаимодействием нашего приложения с базой данных. Для этого для каждого класса-сущности, определим интерфейс, содержащий набор необходимых методов (Я приведу только один интерфейс и одну его реализацию, интерфейсы и реализации для др. классов подобны этим.)
package DAO;
import logic.Bus;
import logic.Driver;
import logic.Route;
import java.util.Collection;
import java.sql.SQLException;
public interface BusDAO {
public void addBus(Bus bus) throws SQLException;
public void updateBus(Long bus_id, Bus bus) throws SQLException;
public Bus getBusById(Long bus_id) throws SQLException;
public Collection getAllBusses() throws SQLException;
public void deleteBus(Bus bus) throws SQLException;
public Collection getBussesByDriver(Driver driver) throws SQLException;
public Collection getBussesByRoute(Route route) throws SQLException;
}* This source code was highlighted with Source Code Highlighter.
Теперь определим реализацию этого интерфейса в классе BusDAOImpl
package DAO.Impl;
import DAO.BusDAO;
import logic.Bus;
import logic.Driver;
import logic.Route;
import java.sql.SQLException;
import java.util.Collection;
import java.util.ArrayList;
import java.util.List;
import util.HibernateUtil;
import javax.swing.*;
import org.hibernate.Session;
import org.hibernate.Query;
public class BusDAOImpl implements BusDAO {
public void addBus(Bus bus) throws SQLException {
Session session = null;
try {
session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
session.save(bus);
session.getTransaction().commit();
} catch (Exception e) {
JOptionPane.showMessageDialog(null, e.getMessage(), «Ошибка при вставке», JOptionPane.OK_OPTION);
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
}
public void updateBus(Long bus_id, Bus bus) throws SQLException {
Session session = null;
try {
session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
session.update(bus);
session.getTransaction().commit();
} catch (Exception e) {
JOptionPane.showMessageDialog(null, e.getMessage(), «Ошибка при вставке», JOptionPane.OK_OPTION);
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
}
public Bus getBusById(Long bus_id) throws SQLException {
Session session = null;
Bus bus = null;
try {
session = HibernateUtil.getSessionFactory().openSession();
bus = (Bus) session.load(Bus.class, bus_id);
} catch (Exception e) {
JOptionPane.showMessageDialog(null, e.getMessage(), «Ошибка 'findById'», JOptionPane.OK_OPTION);
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
return bus;
}
public Collection getAllBusses() throws SQLException {
Session session = null;
List busses = new ArrayList<Bus>();
try {
session = HibernateUtil.getSessionFactory().openSession();
busses = session.createCriteria(Bus.class).list();
} catch (Exception e) {
JOptionPane.showMessageDialog(null, e.getMessage(), «Ошибка 'getAll'», JOptionPane.OK_OPTION);
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
return busses;
}
public void deleteBus(Bus bus) throws SQLException {
Session session = null;
try {
session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
session.delete(bus);
session.getTransaction().commit();
} catch (Exception e) {
JOptionPane.showMessageDialog(null, e.getMessage(), «Ошибка при удалении», JOptionPane.OK_OPTION);
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
}
public Collection getBussesByDriver(Driver driver) throws SQLException {
Session session = null;
List busses = new ArrayList<Bus>();
try {
session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Long driver_id = driver.getId();
Query query = session.createQuery(
" select b "
+ " from Bus b INNER JOIN b.drivers driver"
+ " where driver.id = :driverId "
)
.setLong(«driverId», driver_id);
busses = (List<Bus>) query.list();
session.getTransaction().commit();
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
return busses;
}
public Collection getBussesByRoute(Route route){
Session session = null;
List busses = new ArrayList<Bus>();
try {
session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
Long route_id = route.getId();
Query query = session.createQuery(«from Bus where route_id = :routeId „).setLong(“routeId», route_id);
busses = (List<Bus>) query.list();
session.getTransaction().commit();
} finally {
if (session != null && session.isOpen()) {
session.close();
}
}
return busses;
}
}* This source code was highlighted with Source Code Highlighter.
Еще рас скажу, что реализации DriverDAOImpl и RouteDAOImpl будут аналогичны этой.
Наибольший интерес для нас представляют два последних метода, взгляните на них повнимательнее. Как происходит общение с базой? От объекта SessionFactory создается новая или получается текущая сессия, зачем начинается транзакция, выполняются необходимые действия, коммит транзакции и закрытие сессии. Вроде ничего сложного :) Обратите внимание, на то, каким синтаксисом описан запрос к базе. Это так называемый HQL (Hibernate Query Language) HQL представляет собой объектно-ориентированный язык запросов, возможности его широки, но мной настолько широко еще не осилены :) Помимо save, load, update, delete и HQL, можно пользоваться и обычным SQL. Например:
String query = "SELECT driver_id, name, surname, age FROM drivers";
List drivers = new ArrayList();
drivers = (List) session.createSQLQuery(query).list();
Теперь создадим класс фабрики, к которой будем обращаться за нашими реализациями DAO, от которых и будем вызывать необходимые нам методы.
public class Factory {
private static BusDAO busDAO = null;
private static DriverDAO driverDAO = null;
private static RouteDAO routeDAO = null;
private static Factory instance = null;
public static synchronized Factory getInstance(){
if (instance == null){
instance = new Factory();
}
return instance;
}
public BusDAO getBusDAO(){
if (busDAO == null){
busDAO = new BusDAOImpl();
}
return busDAO;
}
public DriverDAO getDriverDAO(){
if (driverDAO == null){
driverDAO = new DriverDAOImpl();
}
return driverDAO;
}
public RouteDAO getRouteDAO(){
if (routeDAO == null){
routeDAO = new RouteDAOImpl();
}
return routeDAO;
}
}* This source code was highlighted with Source Code Highlighter.
Теперь нам осталось создать какой-либо демонстрационный класс, для того, чтобы посмотреть и опробовать все то, что мы написали. Ну, не будем тянуть, вот этот класс, возможно не самый удачный, но все же :)
public class Main {
public static void main(String[] args) throws SQLException {
Collection routes = Factory.getInstance().getRouteDAO().getAllRoutes();
Iterator iterator = routes.iterator();
System.out.println("========Все маршруты=========");
while (iterator.hasNext()) {
Route route = (Route) iterator.next();
System.out.println("Маршрут : " + route.getName() + " Номер маршрута : " + route.getNumber());
Collection busses = Factory.getInstance().getBusDAO().getBussesByRoute(route);
Iterator iterator2 = busses.iterator();
while (iterator2.hasNext()) {
Bus bus = (Bus) iterator2.next();
System.out.println("Автобус № " + bus.getNumber());
}
}
Collection busses = Factory.getInstance().getBusDAO().getAllBusses();
iterator = busses.iterator();
System.out.println("========Все автобусы=========");
while (iterator.hasNext()) {
Bus bus = (Bus) iterator.next();
Collection drivers = Factory.getInstance().getDriverDAO().getDriversByBus(bus);
Iterator iterator2 = drivers.iterator();
System.out.println("Автобус № " + bus.getNumber());
while (iterator2.hasNext()) {
Driver driver = (Driver) iterator2.next();
System.out.println("Имя : " + driver.getName() + " Фамилия: " + driver.getSurname());
}
}
}
}* This source code was highlighted with Source Code Highlighter.
Еще раз скажу, что может не самый удачный вариант использования всего нами написанного, но для этого уже лучше GUI писать или Web-интерфейс, а это уже другая песня :)
P.S.. Скажу, что на 100%-ую правильность я не претендую, это мое личное имхо, однако очень надеюсь, что это станет для кого-то полезным материалом.
P.S.S. Все библиотеки и файлы качать тут.