
Популярность языка программирования Си трудно переоценить, особенно вспоминая его былые заслуги. Наверное, каждый разработчик, как минимум, знает о его существовании, и, как максимум, пробовал на нем программировать. Си является предшественником таких языков, как C++, Objective-C, C#, Java.
Компания Microsoft для разработки родного языка к своей платформе .Net выбрала именно Си-подобный синтаксис. Более того, на Си написано множество операционных систем.
Конечно, Си не идеален: создатели языка – Кен Томпсон и Деннис Ритчи – долгое время дорабатывали его. Стандартизация Си продолжается до сих пор. Он существует более 45 лет и активно используется.
С ним часто ассоциируют не один, а два языка программирования — C/C++. Однако ниже речь пойдет именно о «чистом» Си.
Язык Си восходит корнями к языку ALGOL (расшифровывается как ALGorithmic Language), который был создан в 1958 году совместно с комитетом Европейских и Американских учёных в сфере компьютерных наук на встрече в Швейцарской высшей технической школе Цюриха. Язык был ответом на некоторые недостатки языка FORTRAN и попыткой их исправить. Кроме того, разработка Си тесно связана с созданием операционной системы UNIX, над которой также работали Кен Томпсон и Деннис Ритчи.
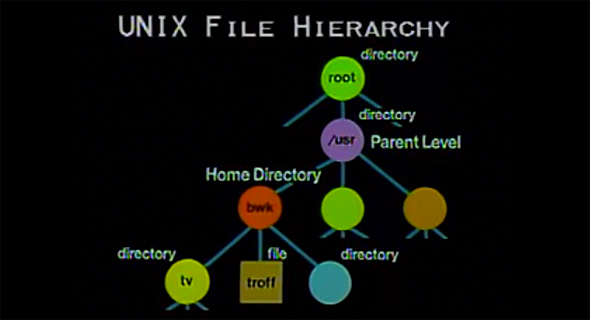
UNIX
Проект МАС (Multiple Access Computer, Machine-Aided Cognition, Man and Computer) начался как чисто исследовательский в MIT в 1963 году.
В рамках проекта МАС была разработана операционная система CTSS (Compatible Time-Sharing System). Во второй половине 60-х было создано несколько других систем с разделением времени, например, BBN, DTSS, JOSS, SDC и Multiplexed Information and Computing Service (MULTICS) в том числе.
Multics – совместная разработка MIT, Bell Telephone Laboratories (BTL) и General Electric (GE) по созданию ОС с разделением времени для компьютера GE-645. Последний компьютер под управлением Multics выключили 31 октября 2000 года.
Однако BTL отошел от этого проекта еще в начале 1969 года.
Некоторые его сотрудники (Кен Томпсон, Деннис Ритчи, Стью Фельдман, Дуг МакИлрой, Боб Моррис, Джо Оссанна) захотели продолжить работу самостоятельно. Томпсон работал над игрой Space Travel на GE-635. Ее написали сначала для Multics, а потом переписали на Фортране под GECOS на GE-635. Игра моделировала тела Солнечной системы, а игроку надо было посадить корабль куда-нибудь на планету или спутник.
Ни софт, ни железо этого компьютера не годились для такой игры. Томпсон искал альтернативу, и переписал игру под бесхозный PDP-7. Память была объемом 8К 18-битных слов, и еще был процессор векторного дисплея для вывода красивой для того времени графики.

Изображение с сайта slideshare.net
Томпсон и Ритчи полностью вели разработку на кросс-ассемблере на GE и переносили код на перфолентах. Томпсону это активно не нравилось, и он начал писать ОС для PDP-7, начиная с файловой системы. Так появилась UNIX.
Томпсон хотел создать комфортабельное вычислительное окружение, сконструированное в соответствии с его дизайном, используя любые доступные средства. Его замыслы, что очевидно оглядываясь назад, вбирали в себя многие инновации Multics, включая понятие процесса как основы управления, древовидную файловую систему, интерпретатор команд в качестве пользовательской программы, упрощённое представление текстовых файлов и обобщённый доступ к устройствам.
PDP-7 UNIX также положил начало высокоуровневому языку B, который создавался под влиянием языка BCPL. Деннис Ритчи сказал, что В — это Си без типов. BCPL помещался в 8 Кб памяти и был тщательно переработан Томпсоном. В постепенно вырос в С.
Изображение с сайта it-world.com
К 1973 году язык Си стал достаточно силён, и большая часть ядра UNIX, первоначально написанная на ассемблере PDP-11/20, была переписана на Си. Это было одно из самых первых ядер операционных систем, написанное на языке, отличном от ассемблера.
Получается, что Си – это «сопутствующий продукт», полученный во время создания операционной системы UNIX.
Прародители Си
Вдохновлённые языком ALGOL-60, Математическая лаборатория Кембриджского Университета совместно с Компьютерным отделом Лондонского университета создали в 1963 году язык CPL (Combined Programming Language).
Язык CPL посчитали сложным, и в ответ на это Мартином Ричардсоном был создан в 1966 году язык BCPL, основное предназначение которого заключалось в написании компиляторов. Сейчас он практически не используется, но в своё время из-за хорошей портируемости он играл важную роль.
BCPL использовался в начале 1970-х в нескольких интересных проектах, в числе которых — операционная система OS6 и частично в зарождающихся разработках Xerox PARC.
BCPL послужил предком для языка Би (B), разработанного в 1969 в уже знакомой всем AT&T Bell Telephone Laboratories, не менее знакомыми Кеном Томпсоном и Деннисом Ритчи.
Как и остальные операционные системы того времени, UNIX был написан на ассемблере. Отладка программ на ассемблере настоящая мука. Томпсон решил, что для дальнейшей разработки ОС необходим язык высокого уровня и придумал небольшой язык B. За основу Томпсон взял язык BCPL. Язык B можно рассматривать как C без типов.
Во многих деталях BCPL, B и C различаются синтаксически, но в основном они похожи. Программы состоят из последовательности глобальных деклараций и объявлений функций (процедур). В BCPL процедуры могут быть вложенными, но не могут ссылаться на нестатические объекты определённые в содержащих их процедурах. B и C избегают такого ограничения, вводя более строгое: вложенных процедур нет вообще. Каждый из языков (за исключением самых древних версий B) поддерживает раздельную компиляцию и предоставляет средства для включения текста из именованных файлов.
В противоположность повсеместному изменению синтаксиса, которое происходило во время создания B, основная семантика BCPL — его структура типов и правила вычисления выражений — осталась нетронутой. Оба языка — безтиповые, вернее имеют единственный тип данных — «слово» или «ячейка», набор битов фиксированной длины. Память в этих языках — массив таких ячеек, а смысл содержимого ячейки зависит от операции, которая к ней применяется. Например, оператор "+" просто складывает свои операнды при помощи машинной инструкции add, и другие арифметические операции также безразличны к смыслу своих операндов.
Ни BCPL, ни B, ни C не выделяют в языке символьные данные; они считают строки векторами целых чисел и дополняют общие правила несколькими соглашениями. И в BCPL, и в B строковый литерал означает адрес статической области инициализированный символами строки упакованными в ячейки.
Как создавался Си
В 1970 Bell Labs приобрела для проекта компьютер PDP-11. Так как B был готов к работе на PDP-11, Томпсон переписал часть UNIX на B.
Но модель B и BCPL подразумевала издержки при работе с указателями: правила языка, определяя указатель как индекс в массиве слов, делали указатели индексами слов. Каждое обращение к указателю при исполнении генерировало масштабирование указателя в адрес байта, который ожидал процессор.
Поэтому становилось ясно, что для того, чтобы справиться с символами и байтовой адресацией, а также подготовиться к грядущей аппаратной поддержке вычислений с плавающей точкой, нужна типизация.
В 1971 году Ритчи начал создавать расширенную версию B. Сначала он назвал её NB (New B), но когда язык стал сильно отличаться от B, название сменили на C. Вот что, писал об этом сам Ритчи:
Я хотел, чтобы структура не только характеризовала абстрактный объект, но и описывала набор бит, который мог быть прочитан из каталога. Где компилятор смог бы спрятать указатель, наname, которого требует семантика? Даже если бы структуры были бы задуманы более абстрактными, и место для указателей могло бы быть спрятано где-нибудь, как бы я решил техническую проблему корректной инициализации этих указателей при выделении памяти для сложного объекта, возможно структуры содержащей массивы, которые содержат структуры, и так до произвольной глубины?
Решение состояло в решительном скачке в эволюционной цепочке между безтиповым BCPL и типизированным C. Он исключал материализацию указателя в хранилище, а вместо этого порождал его создание, когда имя массива упоминалось в выражении. Правило, которое сохранилось и в сегодняшнем C, состоит в том, что значения–массивы, когда они упоминаются в выражении, конвертируются в указатели на первый из объектов, составляющих этот массив.
Второе нововведение, которое наиболее ясно отличает C от его предшественников, — вот эта более полная структура типов и особенно её выразительность в синтаксисе деклараций. NB предлагал основные типы int и char совместно с массивами из них и указателями на них, но никаких других способов скомпоновать их.
Требовалось обобщение: для объекта любого типа должно быть возможным описать новый объект, который объединяет несколько таких объектов в массив, получает его из функции или является указателем на него.
Изображение из книги «Язык Си»: M. Уэйт, С. Прата, Д. Мартин
Для любого объекта такого составного типа, уже был способ указать на объект, который является его частью: индексировать массив, вызвать функцию, использовать с указателем оператор косвенного обращения. Аналогичное рассуждение приводило к синтаксису объявления имён, который отражает синтаксис выражения, где эти имена используются. Так
int i, *pi, **ppi;объявляет целое, указатель на целое и указатель на указатель на целое. Синтаксис этих объявлений отражает тот факт, что i, *pi, и **ppi все в результате дают тип int, когда используются в выражении. Похожим образом
int f(), *f(), (*f)();объявляют функцию, возвращающую целое, функцию возвращающую указатель на целое, указатель на функцию возвращающую целое;
int *api[10], (*pai)[10];объявляют массив указателей на целое, указатель на массив целых.
Во всех этих случаях объявление переменной напоминает её использование в выражении, чей тип – это то, что находится в начале объявления.
70-е годы: «смутное время» и лже-диалекты
Язык к 1973 стал достаточно стабилен для того, чтобы на нём можно было переписать UNIX. Переход на C обеспечил важное преимущество: переносимость. Написав компилятор C для каждой из машин в Bell Labs, команда разработчиков могла портировать на них UNIX.
По поводу возникновения языка Си Питер Мойлан в своей книге «The case against C» пишет: «Нужен был язык, способный обойти некоторые жесткие правила, встроенные в большинство языков высокого уровня и обеспечивающие их надежность. Нужен был такой язык, который позволил бы делать то, что до него можно было реализовать только на ассемблере или на уровне машинного кода».
C продолжил развиваться в 70-х. В 1973–1980-х годах язык немного подрос: структура типов получила беззнаковые, длинные типы, объединение и перечисление, структуры стали близкими к объектам–классам (не хватало только нотации для литералов).
Первая книга по Cи. Книга «Язык программирования Си», написанная Брайаном Керниганом и Деннисом Ритчи и опубликованная в 1978 году, стала библией программистов на Си. При отсутствии официального стандарта эта книга – известная также как K&R, или «Белая Книга», как любят называть поклонники си – фактически стала стандартом.

Изображение с сайта learnc.info
В 70-х программистов на Cи было немного и большинство из них были пользователями UNIX. Тем не менее, в 80-х Cи вышел за узкие рамки мира UNIX. Компиляторы Cи стали доступны на различных машинах, работающих под управлением разных операционных систем. В частности, Си стал распространяться на быстро развивающейся платформе IBM PC.
K&R ввёл следующие особенности языка:
• структуры (тип данных struct);
• длинное целое (тип данных long int);
• целое без знака (тип данных unsigned int);
• оператор += и подобные ему (старые операторы =+ вводили анализатор лексики компилятора Си в заблуждение, например, при сравнении выражений i =+ 10 и i = +10).
K&R C часто считают самой главной частью языка, которую должен поддерживать компилятор Си. Многие годы даже после выхода ANSI Cи он считался минимальным уровнем, которого следовало придерживаться программистам, желающим добиться от своих программ максимальной переносимости, потому что не все компиляторы тогда поддерживали ANSI C, а хороший код на K&R C был верен и для ANSI C.
Вместе с ростом популярности появились проблемы. Программисты, писавшие новые компиляторы брали за основу язык, описанный в K&R. К сожалению, в K&R некоторые особенности языка были описаны расплывчато, поэтому компиляторы часто трактовали их на своё усмотрение. Кроме того, в книге не было чёткого разделения между тем, что является особенностью языка, а что особенностью операционной системы UNIX.
После публикации K&R C в язык было добавлено несколько возможностей, поддерживаемых компиляторами AT&T, и некоторых других производителей:
• функции, не возвращающие значение (с типом void), и указатели, не имеющие типа (с типом void *);
• функции, возвращающие объединения и структуры;
• имена полей данных структур в разных пространствах имён для каждой структуры;
• присваивания структур;
• спецификатор констант (const);
• стандартная библиотека, реализующая большую часть функций, введённых различными производителями;
• перечислимый тип (enum);
• дробное число одинарной точности (float).
Ухудшало ситуацию и то, что после публикации K&R Си продолжал развиваться: в него добавлялись новые возможности и из него вырезались старые. Вскоре появилась очевидная необходимость в исчерпывающем, точном и соответствующем современным требованиям описании языка. Без такого стандарта стали появляться диалекты языка, которые мешали переносимости – сильнейшей стороне языка.
Стандарты
В конце 1970-х годов, язык Си начал вытеснять BASIC, который в то время был ведущим в области программирования микрокомпьютеров. В 1980-х годах он был адаптирован под архитектуру IBM-PC, что привело к значительному скачку его популярности.

Разработкой стандарта языка Си занялся Американский национальный институт стандартов (ANSI). При нём в 1983 году был сформирован комитет X3J11, который занялся разработкой стандарта. Первая версия стандарта была выпущена в 1989 году и получила название С89. В 1990, внеся небольшие изменения в стандарт, его приняла Международная Организация Стандартизации ISO. Тогда он стал известен под кодом ISO/IEC 9899:1990, но в среде программистов закрепилось название, связанное с годом принятия стандарта: С90. Последней на данный момент версией стандарта является стандарт ISO/IEC 9899:1999, также известный как С99, который был принят в 2000 году.

Среди новшеств стандарта С99 стоит обратить внимание на изменение правила, касающегося места объявления переменных. Теперь новые переменные можно было объявлять посреди кода, а не только в начале составного блока или в глобальной области видимости.
Некоторые особенности C99:
• подставляемые функции (inline);
• объявление локальных переменных в любом операторе программного текста (как в C++);
• новые типы данных, такие, как long long int (для облегчения перехода от 32- к 64-битным числам), явный булевый тип данных _Bool и тип complex для представления комплексных чисел;
• массивы переменной длины;
• поддержка ограниченных указателей (restrict);
• именованная инициализация структур: struct { int x, y, z; } point = { .y=10, .z=20, .x=30 };
• поддержка однострочных комментариев, начинающихся на //, заимствованных из C++ (многие компиляторы Си поддерживали их и ранее в качестве дополнения);
• несколько новых библиотечных функций, таких, как snprintf;
• несколько новых заголовочных файлов, таких, как stdint.h.
Стандарт С99 сейчас в большей или меньшей степени поддерживается всеми современными компиляторами языка Си. В идеале, код написанный на Си с соблюдением стандартов и без использования аппаратно- и системно-зависимых вызовов, становился как аппаратно- так и платформенно-независимым кодом.
В 2007 году начались работы над следующим стандартом языка Си. 8 декабря 2011 опубликован новый стандарт для языка Си (ISO/IEC 9899:2011). Некоторые возможности нового стандарта уже поддерживаются компиляторами GCC и Clang.
Основные особенности С11:
• поддержка многопоточности;
• улучшенная поддержка Юникода;
• обобщенные макросы (type-generic expressions, позволяют статичную перегрузку);
• анонимные структуры и объединения (упрощают обращение ко вложенным конструкциям);
• управление выравниванием объектов;
• статичные утверждения (static assertions);
• удаление опасной функции gets (в пользу безопасной gets_s);
• функция quick_exit;
• спецификатор функции _Noreturn;
• новый режим эксклюзивного открытия файла.
Несмотря на наличие стандарта 11 года, многие компиляторы до сих пор не поддерживают полностью даже версии C99.
За что критикуют Си
У него достаточно высокий порог вхождения, что затрудняет его использование в обучении в качестве первого языка программирования. Программируя на Си, нужно учитывать множество деталей. «Будучи рождён в среде хакеров, он стимулирует соответствующий стиль программирования, часто небезопасный, и поощряющий написание запутанного кода», пишет Википедия.
Более глубокую и аргументированную критику высказал Питер Мойлан. Он посвятил критике Си целых 12 страниц. Приведем пару фрагментов:
Проблемы с модульностью
Модульное программирование на языке Си возможно, но лишь в том случае, когда программист придерживается ряда довольно жестких правил:
• На каждый модуль должен приходиться ровно один header-файл. Он должен содержать лишь экспортируемые прототипы функций, описания и ничего другого (кроме комментариев).
• Внешней вызывающей процедуре об этом модуле должны быть известны только комментарии в header-файле.
• Для проверки целостности каждый модуль должен импортировать свой собственный header-файл.
• Для импорта любой информации из другого модуля каждый модуль должен содержать строки #include, а также комментарии, показывающие, что, собственно, импортируется.
• Прототипы функций можно использовать только в header-файлах. (Это правило необходимо, поскольку язык Си не имеет механизма проверки того, что функция реализуется в том же модуле, что и ее прототип; так что использование прототипа может маскировать ошибку «отсутствия функции» — «missing function»).
• Любая глобальная переменная в модуле, и любая функция, кроме той, что импортируется через header-файл, должны быть объявлены статическими.
• Следует предусмотреть предупреждение компилятора «вызов функции без прототипа» (function call without prototype); такое предупреждение всегда нужно рассматривать как ошибку.
• Программист должен удостовериться в том, что каждому прототипу, заданному в header- файле, соответствует реализованная под таким же именем в том же модуле неприватная (т.е. нестатическая в обычной терминологии Си) функция. К сожалению, природа языка Си автоматическую проверку этого делает невозможной.
• Следует с подозрением относиться к любому использованию утилиты grep. Если прототип расположен не на своем месте, то это, скорее всего, ошибка.
• В идеале программисты, работающие в одной команде, не должны иметь доступа к исходным файлам друг друга. Они должны совместно использовать лишь объектные модули и header-файлы.
Очевидная трудность в том, что мало кто будет следовать этим правилам, ибо компилятор не требует их неукоснительно соблюдать. Модульный язык программирования по меньшей мере частично защищает хороших программистов от того хаоса, который создают плохие программисты. А язык Си этого сделать не в силах.

Изображение с сайта smartagilee.com
Проблемы с указателями
Несмотря на все достижения в теории и практике структур данных, указатели остаются для программистов настоящим камнем преткновения. На работу с указателями приходится значительная часть времени, расходуемого на отладку программы, и именно они создают большинство проблем, осложняющих ее разработку.
Можно различать важные и неважные указатели. Важным в нашем понимании считается указатель, необходимый для создания и поддержания структуры данных.
Указатель считается неважным, если он не является необходимым для реализации структуры данных. В типичной программе на языке Си неважных указателей намного больше, чем важных. Причины тому две.
Первая состоит в том, что в среде программистов, использующих язык Си, стало традицией создавать указатели даже там, где уже существуют иные ничем не уступающие им методы доступа, например, при просмотре элементов массива.
Вторая причина — правило языка Си, согласно которому все параметры функций должны передаваться по значению. Когда вам нужен эквивалент VAR-параметра языка Паскаль или inout- параметра языка Ada, единственное решение состоит в том, чтобы передать указатель. Этим во многом объясняется плохая читаемость программ на языке Си.
Ситуация усугубляется, когда бывает необходимо передать важный указатель в качестве входного/выходного параметра. В этом случае функции надо передать указатель на указатель, что создает затруднения даже для самых опытных программистов.
Си – жив
Согласно данным на июнь 2016 года, индекс TIOBE, который измеряет рост популярности языков программирования, показал, что C занимает 2 место:

Пусть кто-то скажет, что Си устарел, что его широкое распространение — следствие удачи и активного PR. Пусть кто-то скажет, что без UNIX язык Си никогда бы не создали.
Тем не менее, Си стал своего рода стандартом. Он, так или иначе, прошел испытание временем в отличие от многих других языков. Си-разработчики до сих пор востребованы, а создателей языка IT-сообщество вспоминает добрым словом.
