Обработка TCP соединений может запросто оказаться узким местом, когда скорость приближается к 10 тыс запросов в секунду: эффективное чтение и запись становится отдельной проблемой, а большая часть вычислительных ядер простаивает.
В этой статье я предлагаю оптимизации, которые позволяют улучшить три составляющие работы с TCP: приём соединений, получение сообщений и ответ на них.
Статья адресована как Erlang программистам, так и всем, кто просто интересуется Erlang. Глубокие знания языка не требуются.
Я разделяю “Работу с TCP” на три части:
В зависимости от задачи, любая из этих частей может оказаться наиболее узким местом.
Я буду рассматривать два подхода к написанию TCP сервисов — напрямую через gen_tcp и при помощи ranch, наиболее популярной библиотеки для пулов соединений на Erlang. Некоторые из предложенных оптимизаций будут применимы только в одном из случаев.
Для того чтобы оценить изменение производительности, я использую MZBench с tcp_worker, который реализует функции connect и request плюс функции синхронизации. Будут использоваться два сценария “fast_connect” и “fast_receive”. Первый открывает соединения с линейно нарастающей скоростью, а второй пытается отправить как можно больше пакетов по уже открытым соединениям. Каждый из сценариев запускался на c4.2xlarge Amazon node. Версия Erlang — 18.
Сценарии и код функций для MZBench доступны на GitHub.
Быстрый приём соединений важен, если у вас много клиентов, которые постоянно переподключаются, например если клиентские процессы сильно ограничены по времени или не поддерживают постоянные соединения.
TCP сервисы при помощи ranch создаются довольно просто. Я поменяю код примера echo-сервиса, который идёт вместе с ranch, чтобы он отвечал “ok” на любой приходящий пакет, ниже различия:
Я начну с запуска сценария “fast_connect” (с нарастающей скоростью открытия соединений):
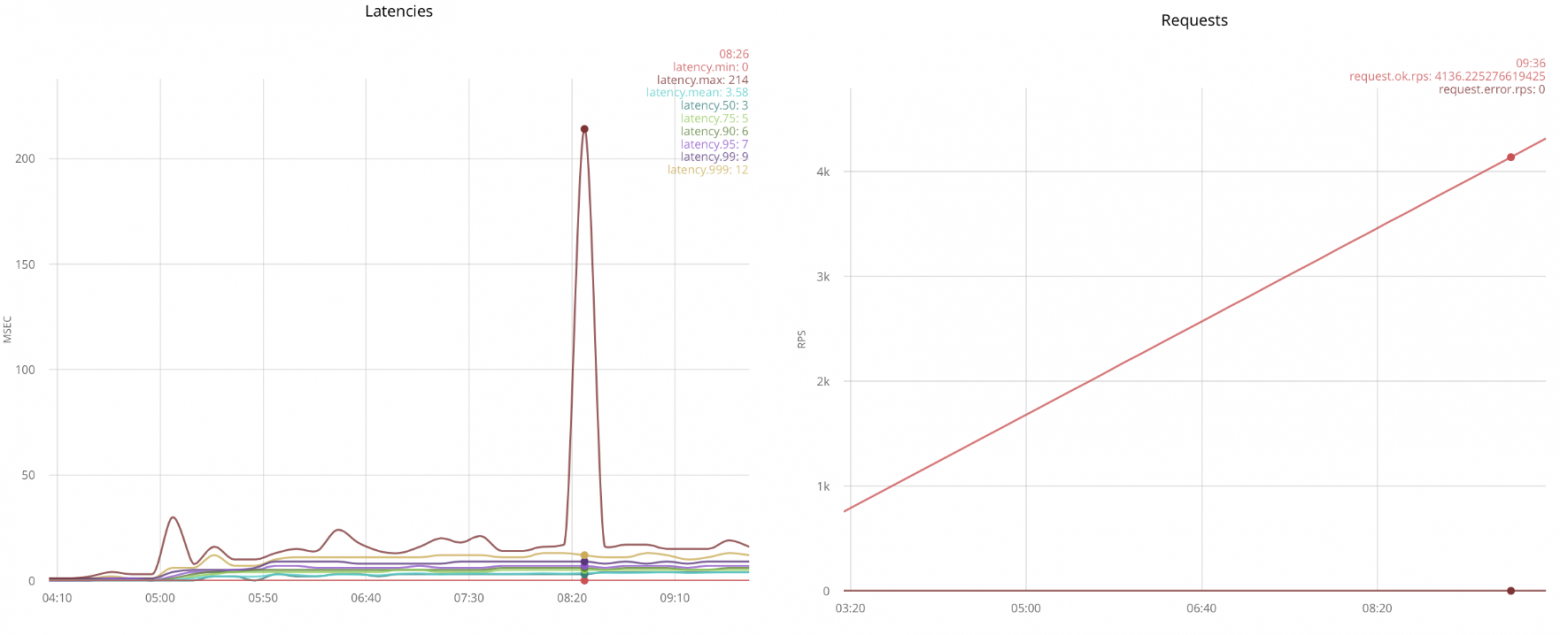
График слева показывает выброс размером в 214ms, остальные линии соответствуют персентилям временных задержек, разбитых по пятисекундным интервалам. График справа это скорость октрытия соеднинений, например в районе выброса она была около 3.5 тыс соединений в секунду. В этом сценарии каждый раз отправляется по одному сообщению, по этому количество сообщений соответствует количеству открытых соединений.
Дальнейшее увеличение скорости даёт следующие результаты:
Выбросы в 1000 msec соответствуют превышению времени ожидания. Если продолжить увеличивать скорость открытия соединений, выбросы станут более частыми. Первые выбросы появляются при скорости 5k rps и постоянно присутствуют при скорости 11k rps.
Я обнаружл, что простое исключение параметра timeout при приёме сообщения сильно повышает скорость установления соединений. Для того чтобы не опрашивать сокет с максимальной скоростью, я добавил timer:sleep(20):
С этой оптимизацией, приложение ranch может принимать больше соденинений, первый выброс появляется только при 11k rps:
Выбросов становится ещё больше, если пытаться повысить скорость дальше. Таким образом, максимальное число — 24k rps.
Вывод
С предложенной оптимизацией, я получил примерно двойной выигрыш в скорости приёма соединений, от 11k до 24k rps.
Ниже чистая реализация при помощи gen_tcp, аналогичная тому что я сделал при помощи ranch (текст доступен в виде simple.erl в репозитории с примерами):
Запустив тот же сценарий, я получил результаты:
Как можно увидеть, примерно в районе 18k rps, приём соединений становится ненадёжным. Будем считать, что получается принять 18k.
Я просто применю ту же оптимизацию, что и для ranch:
В таком случае получается обработать 23k rps:
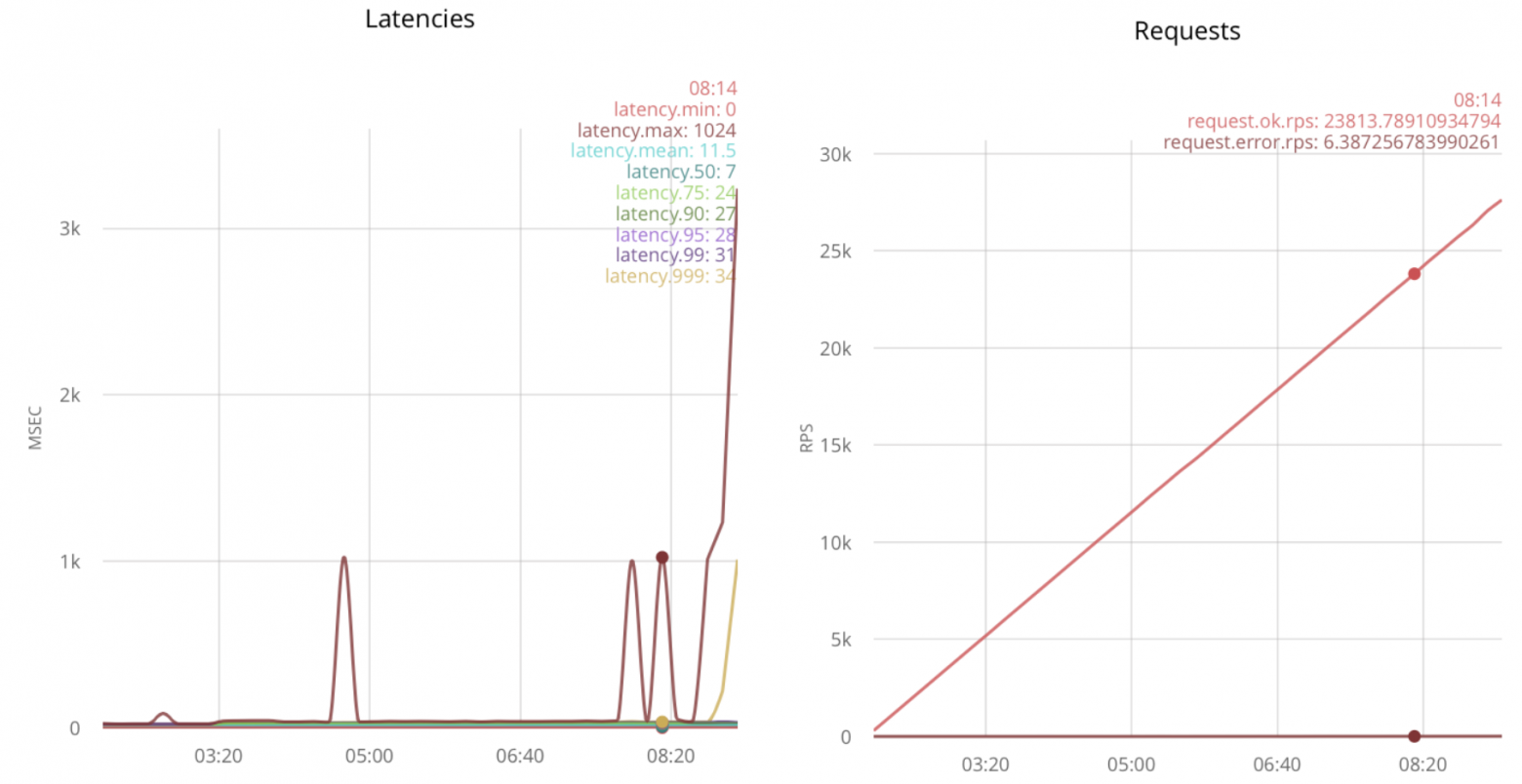
Вторая идея — увеличение количества принимающих соединение процессов. Это может быть достигнуто при помощи вызова gen_tcp:accept из нескольких процессов:
Тестирование под нагрузкой даёт 32k rps:
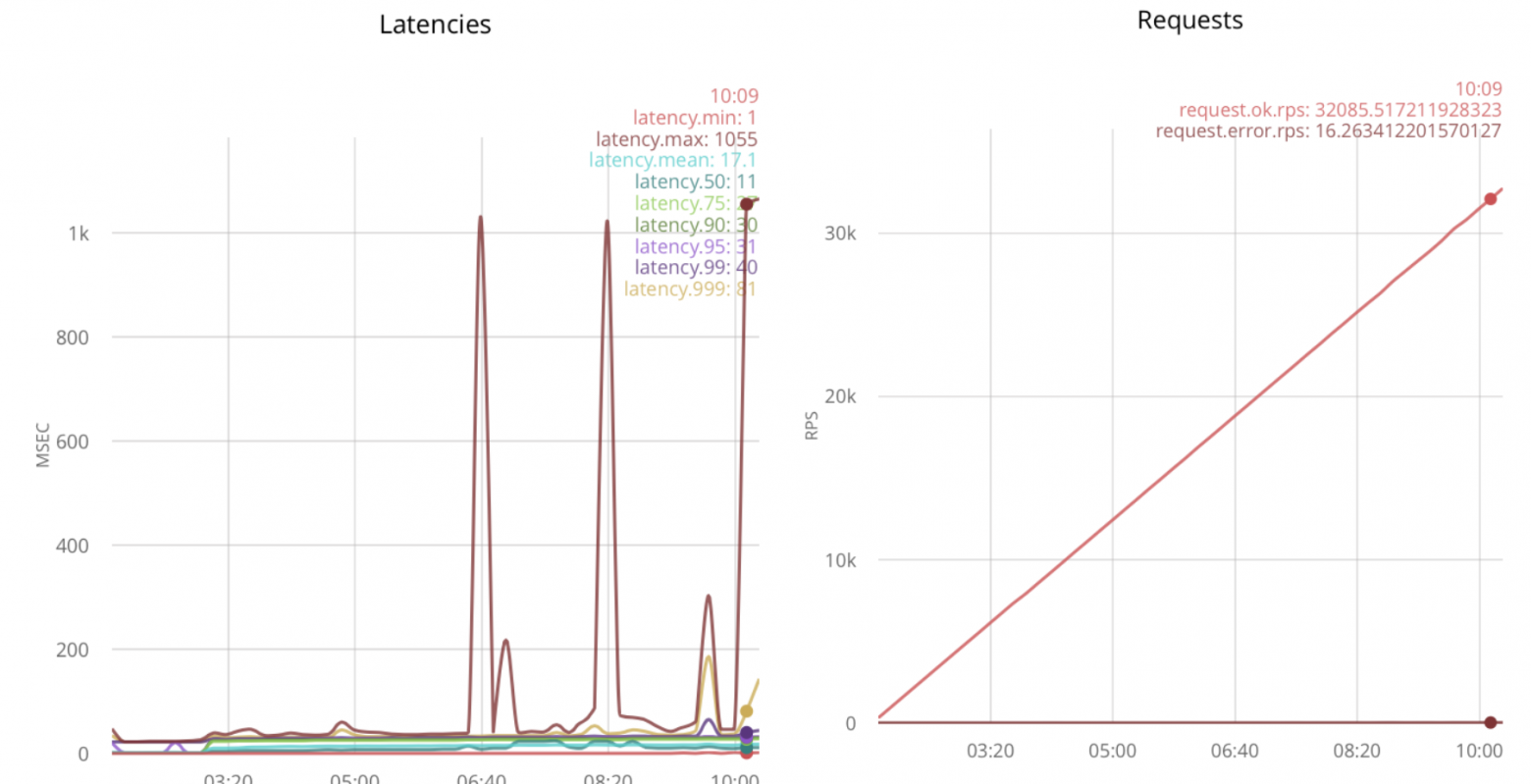
При дальнейшем увеличении нагрузки, задержки растут.
Вывод
Оптимизация timeout для gen_tcp увеличивает скорость приёма на 5k rps, от 18k до 23k.
С несколькими принимающими процессами, gen_tcp обрабатывает 32k rps, это в 1.8 раз больше, чем без оптимизаций.
Это часть о том как получать большое количество коротких сообщений по уже установленым соединениям. Новые соединения открываются редко, требуется читать и отвечать на сообщения максимально быстро. Этот сценарий реализуется в нагруженных приложениях с web-сокетами.
Я открываю 25k соединений с нескольких узлов и постепенно увеличиваю скорость отправки сообщений.
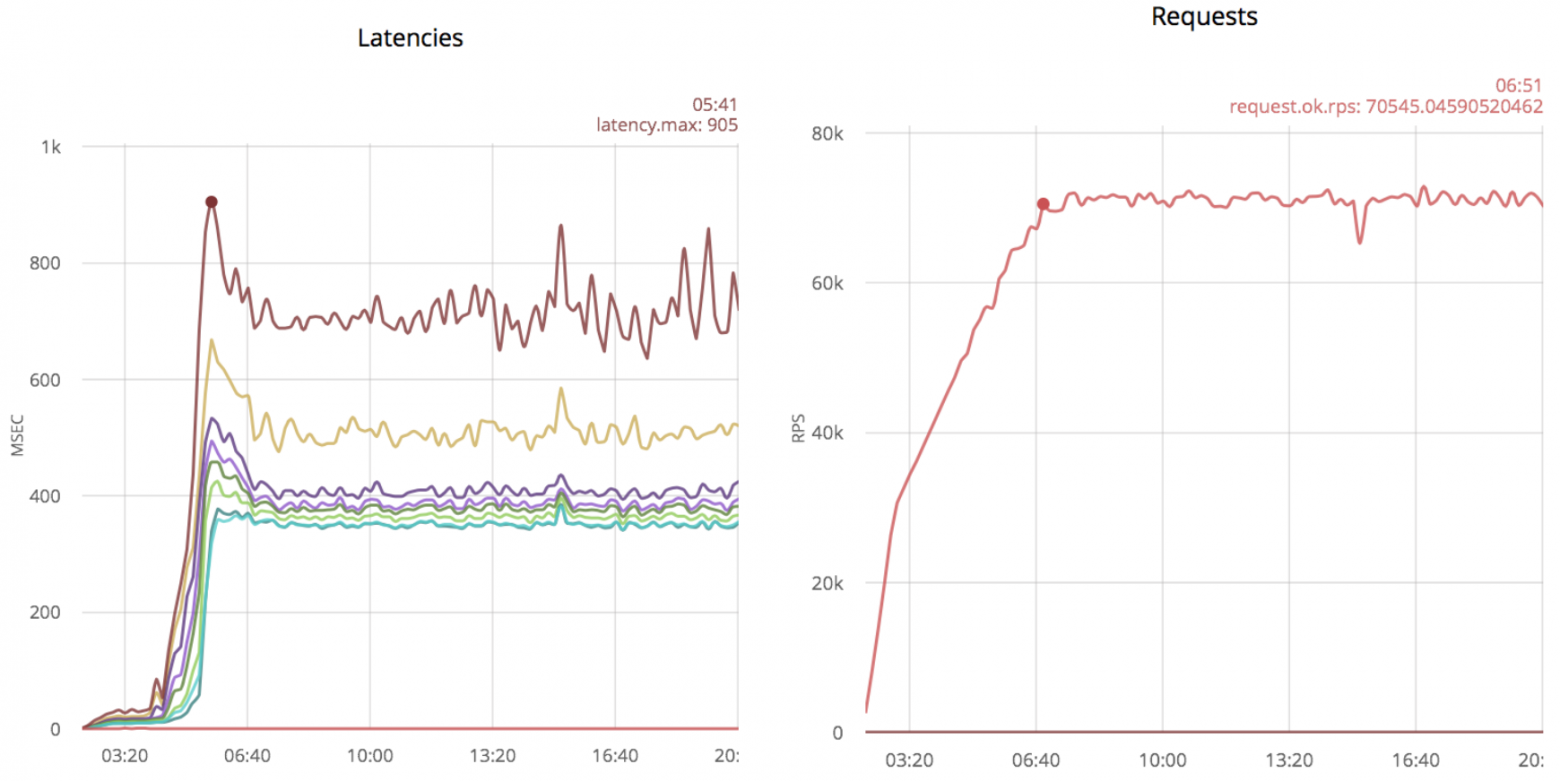
Ниже результаты для неоптимизированного кода с использованием ranch (слева временные задержки, справа скорость обработки сообщений):
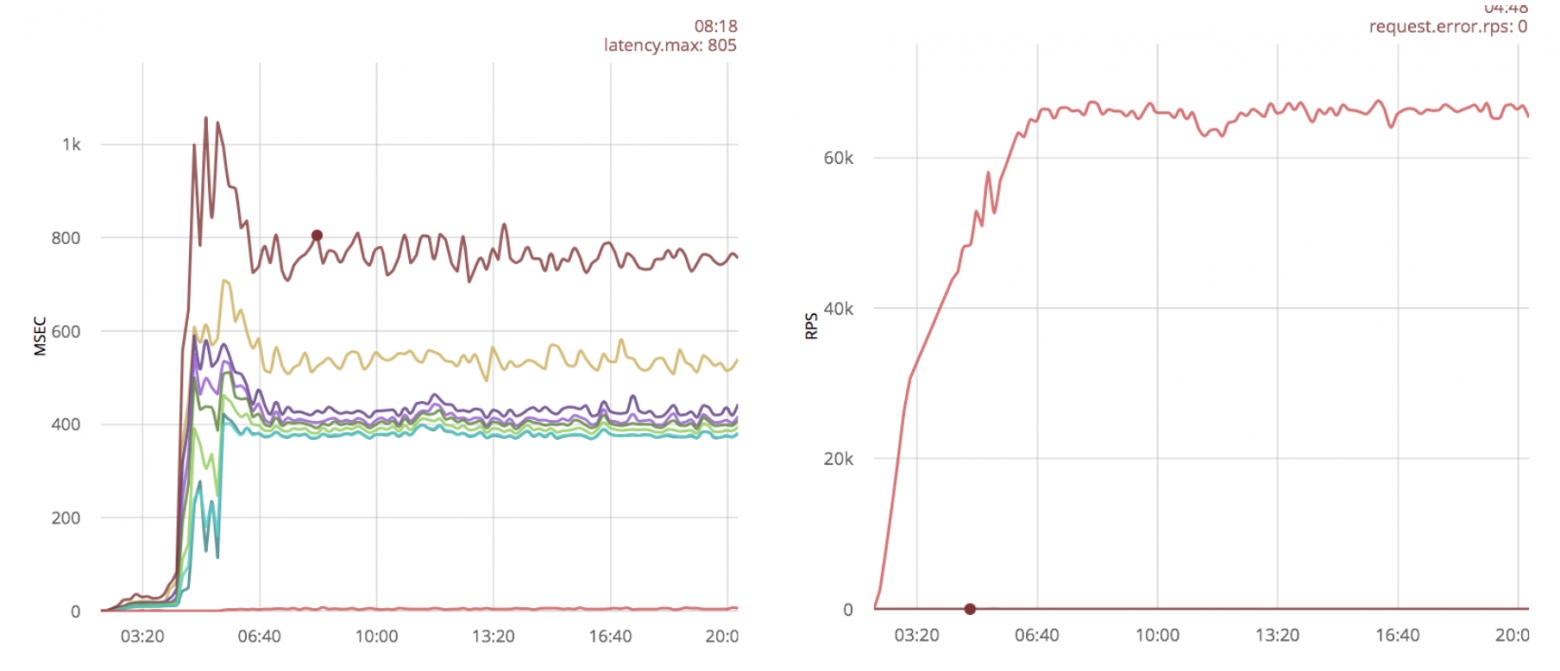
Без оптимизаций, ranch обрабатывает 70k rps с максимальной временной задержкой в 800ms.
Довольно популярной оптимизацией является увеличение linux буферов для сокетов. Посмотрим, как эта оптимизация скажется на результатах:
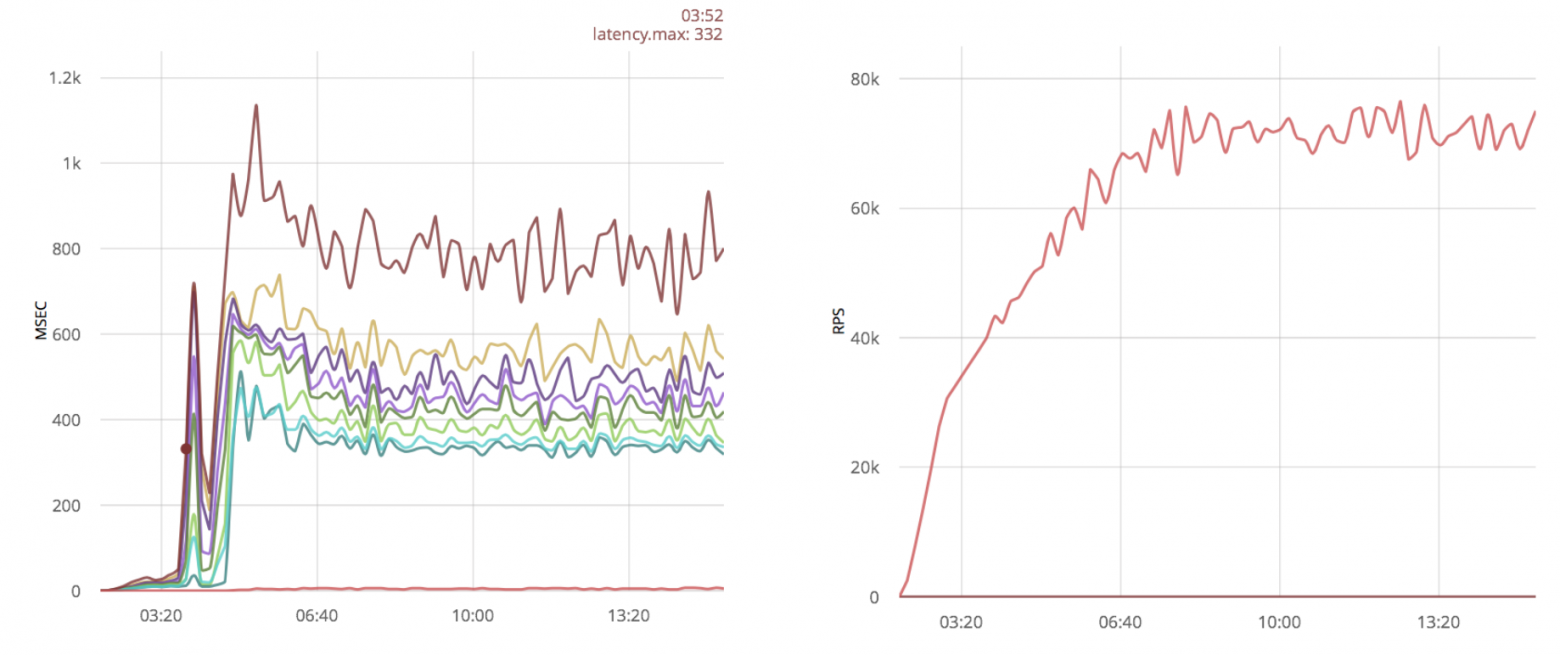
Вывод
В данном случае увеличение буферов не даёт большого выигрыша.
Ниже я проверил скорость обработки пакетов решением на gen_tcp из предыдущей части статьи:
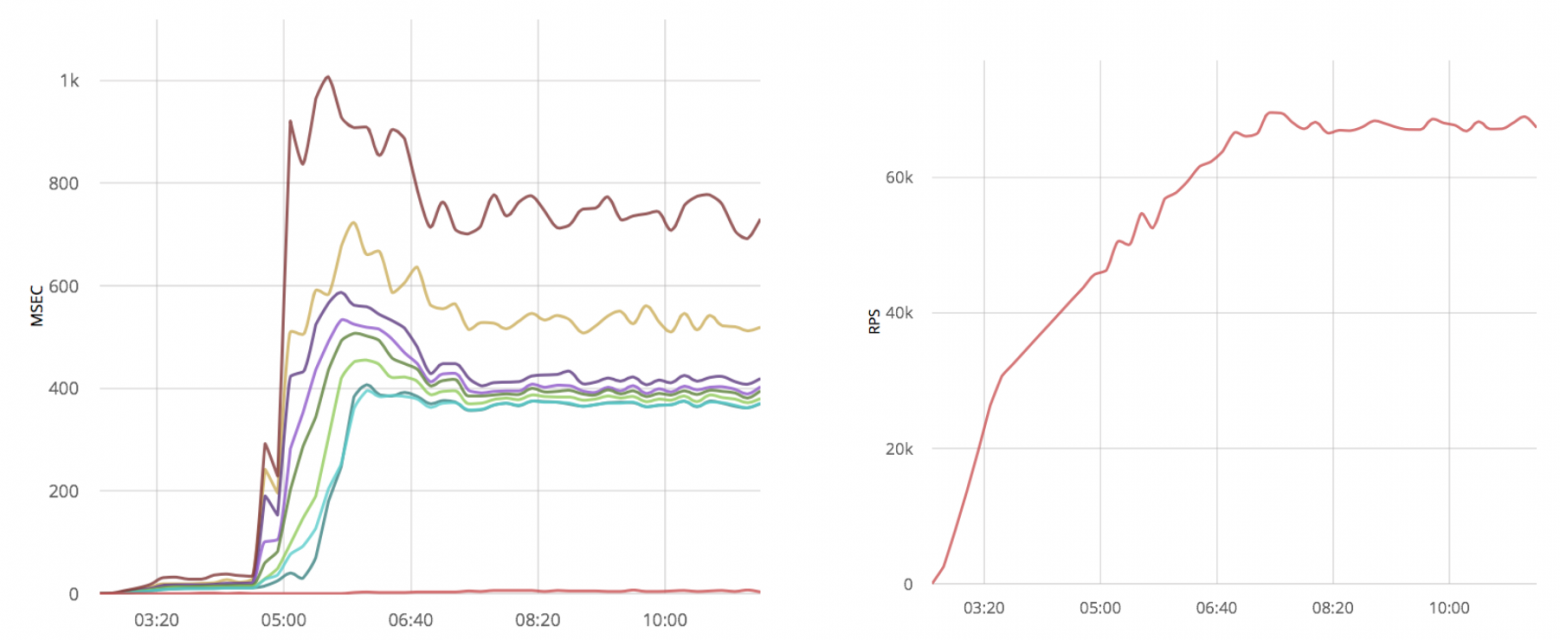
70k rps, так же, как и ranch.
В предыдущем случае, у меня 25k процессов читают из сокетов — один процесс на каждое соединение. Теперь я попробую уменьшить это количество и проверить результаты.
Я создам 100 процессов и буду распределять новые сокеты между ними:
Эта оптимизация даёт существенный прирост производительности:
Кроме увеличения скорости, временные задержки выглядят гораздо лучше, a количество обрабатываемых пакетов около 100k, кроме того, можно обработать даже 120k сообщений, но с большими временными задержками. В то время как без оптимизации этого сделать не получалось.
Вывод
Обработка нескольких соединений из одного процесса даёт как минимум 50% увеличение производительности для чистого gen_tcp сервера.
Я применю ту же оптимизацию к системе с ванильным gen_tcp скриптом:
Как и в случае с ranch, каких-то существенных результатов не видно, только появились дополнительные выбросы в виде больших временных задержек.
Применяя оптимизацию к уже оптимизированному gen_tcp я получаю множество выбросов временных задержек:
Вывод
Решения на чистом gen_tcp также не выигрывают от увеличения Linux буферов. Понижение количество читающих из сокетов процессов даёт 50% выигрыш в скорости обработки.
Формально, в предыдущих главах цикл обработки сообщения предполагал ответ на него, но я не делал чего-то для оптимизации этой части. Я попробую применить те же самые идеи к функциям отправки сообщения. Здесь я использую сценарий из предыдущей главы, в котором пакеты идут по уже установленым соединениям.
Те же идеи, которые я использовал в предыдущих главах можно применить к функции отправки: убрать timeout и отвечать из меньшего количества процессов. Такого параметра как timeout в функции send нет, нужно установить опцию {send_timeout, 0} при открытии соединения.
К сожалению, это оптимизация практически ничего не меняет, а изменение кода сводится к простому добавлению опции, по этой причине я решил не утруждать читателя diff-ом и графиком.
Для проверки того как влияет количество процессов, я использовал следующий скрипт:
Здесь отвечающие процессы разделены с читающими; У меня 25000 читающих и 200 отвечающих.
Но опять, эта оптимизация не показывает существенного прироста производительности в сравнении с решением на gen_tcp из предыдущего раздела:
В случае если один процесс используется для работы с несколькими сокетами, один медленный клиент может затормозить всех остальных. Для того чтобы избежать такой ситуации, можно установить {send_timeout, 0} при открытии сокета и в случае неудачи повторять отправку следующим циклом.
К сожалению, функция send не возвращает количество отправленых байт. Возвращается только ошибка POSIX, либо атом “ok”. Это делает невозможным отправку с последнего успешно отправленого байта. Кроме того, зная это количество можно использовать сеть более эффективно, что становится особенно важно, если клиенты имеют плохие каналы.
Далее я привожу пример как это можно исправить:
И всё, теперь функция gen_tcp:send будет возвращать {ok, Number} в случае успеха. Приведённый фрагмент кода выведет “9”:
Вывод
Если вы обрабатываете несколько соединений из одного процесса, необходимо использовать опцию {send_timeout, 0} при создании сокета, в противном случае один медленный клиент может затормозить отправку всем остальным.
Если ваш протокол может обрабатывать частичные сообщения, лучше пропатчить OTP и учитывать количество отправленных байт.
В этой статье я предлагаю оптимизации, которые позволяют улучшить три составляющие работы с TCP: приём соединений, получение сообщений и ответ на них.
Статья адресована как Erlang программистам, так и всем, кто просто интересуется Erlang. Глубокие знания языка не требуются.
Я разделяю “Работу с TCP” на три части:
- Приём соединений
- Получение сообщений
- Ответ на сообщения
В зависимости от задачи, любая из этих частей может оказаться наиболее узким местом.
Я буду рассматривать два подхода к написанию TCP сервисов — напрямую через gen_tcp и при помощи ranch, наиболее популярной библиотеки для пулов соединений на Erlang. Некоторые из предложенных оптимизаций будут применимы только в одном из случаев.
Для того чтобы оценить изменение производительности, я использую MZBench с tcp_worker, который реализует функции connect и request плюс функции синхронизации. Будут использоваться два сценария “fast_connect” и “fast_receive”. Первый открывает соединения с линейно нарастающей скоростью, а второй пытается отправить как можно больше пакетов по уже открытым соединениям. Каждый из сценариев запускался на c4.2xlarge Amazon node. Версия Erlang — 18.
Сценарии и код функций для MZBench доступны на GitHub.
Приём соединений
Быстрый приём соединений важен, если у вас много клиентов, которые постоянно переподключаются, например если клиентские процессы сильно ограничены по времени или не поддерживают постоянные соединения.
Оптимизации ranch
TCP сервисы при помощи ranch создаются довольно просто. Я поменяю код примера echo-сервиса, который идёт вместе с ranch, чтобы он отвечал “ok” на любой приходящий пакет, ниже различия:
--- a/examples/tcp_echo/src/echo_protocol.erl
+++ b/examples/tcp_echo/src/echo_protocol.erl
@@ -16,8 +16,8 @@ init(Ref, Socket, Transport, _Opts = []) ->
loop(Socket, Transport) ->
case Transport:recv(Socket, 0, 5000) of
- {ok, Data} ->
- Transport:send(Socket, Data),
+ {ok, _Data} ->
+ Transport:send(Socket, <<"ok">>),
loop(Socket, Transport);
_ ->
ok = Transport:close(Socket)
--- a/examples/tcp_echo/src/tcp_echo_app.erl
+++ b/examples/tcp_echo/src/tcp_echo_app.erl
@@ -11,8 +11,8 @@
%% API.
start(_Type, _Args) ->
- {ok, _} = ranch:start_listener(tcp_echo, 1,
- ranch_tcp, [{port, 5555}], echo_protocol, []),
+ {ok, _} = ranch:start_listener(tcp_echo, 100,
+ ranch_tcp, [{port, 5555}, {max_connections, infinity}], echo_protocol, []),
tcp_echo_sup:start_link().
Я начну с запуска сценария “fast_connect” (с нарастающей скоростью открытия соединений):

График слева показывает выброс размером в 214ms, остальные линии соответствуют персентилям временных задержек, разбитых по пятисекундным интервалам. График справа это скорость октрытия соеднинений, например в районе выброса она была около 3.5 тыс соединений в секунду. В этом сценарии каждый раз отправляется по одному сообщению, по этому количество сообщений соответствует количеству открытых соединений.
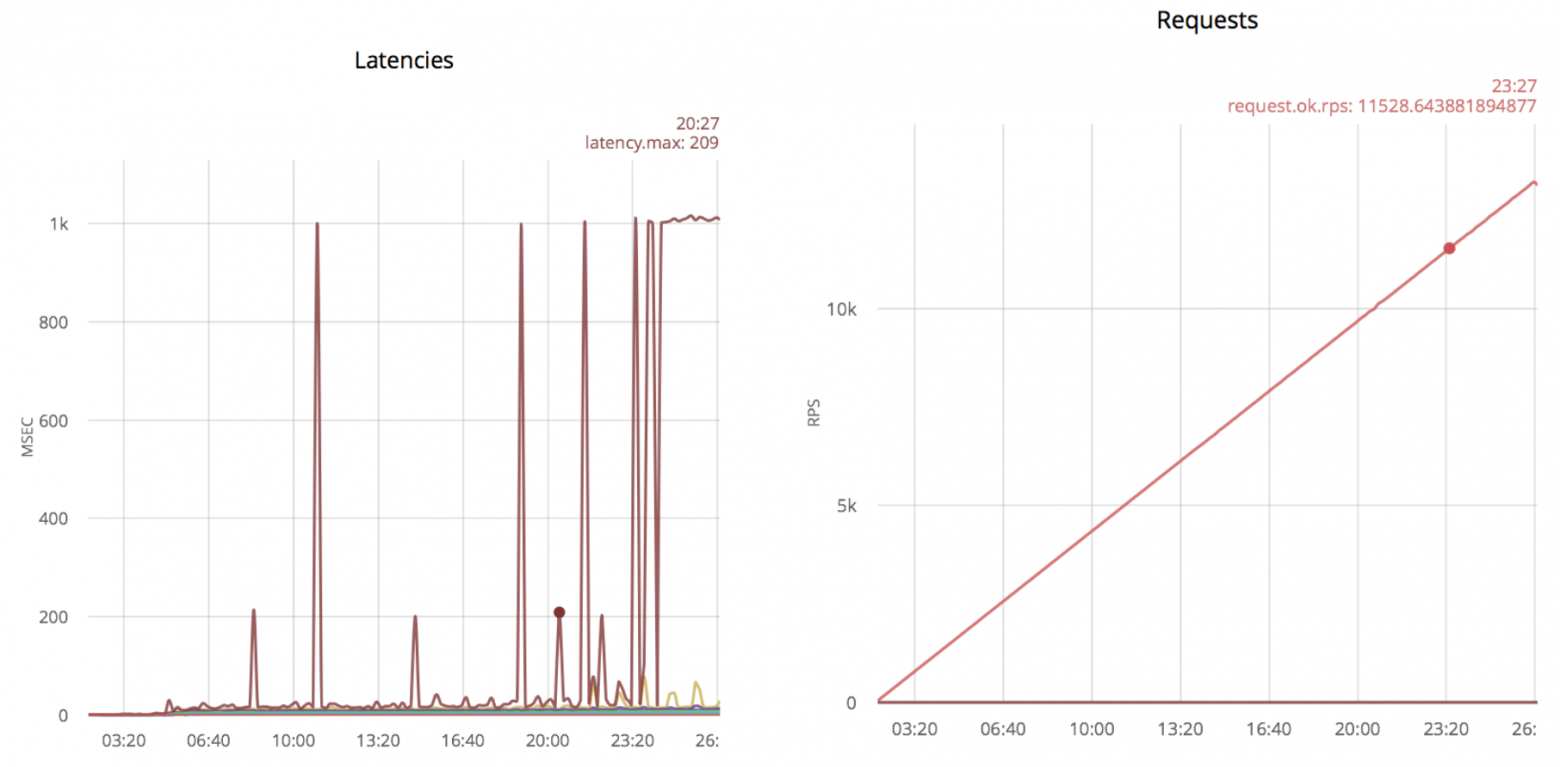
Дальнейшее увеличение скорости даёт следующие результаты:
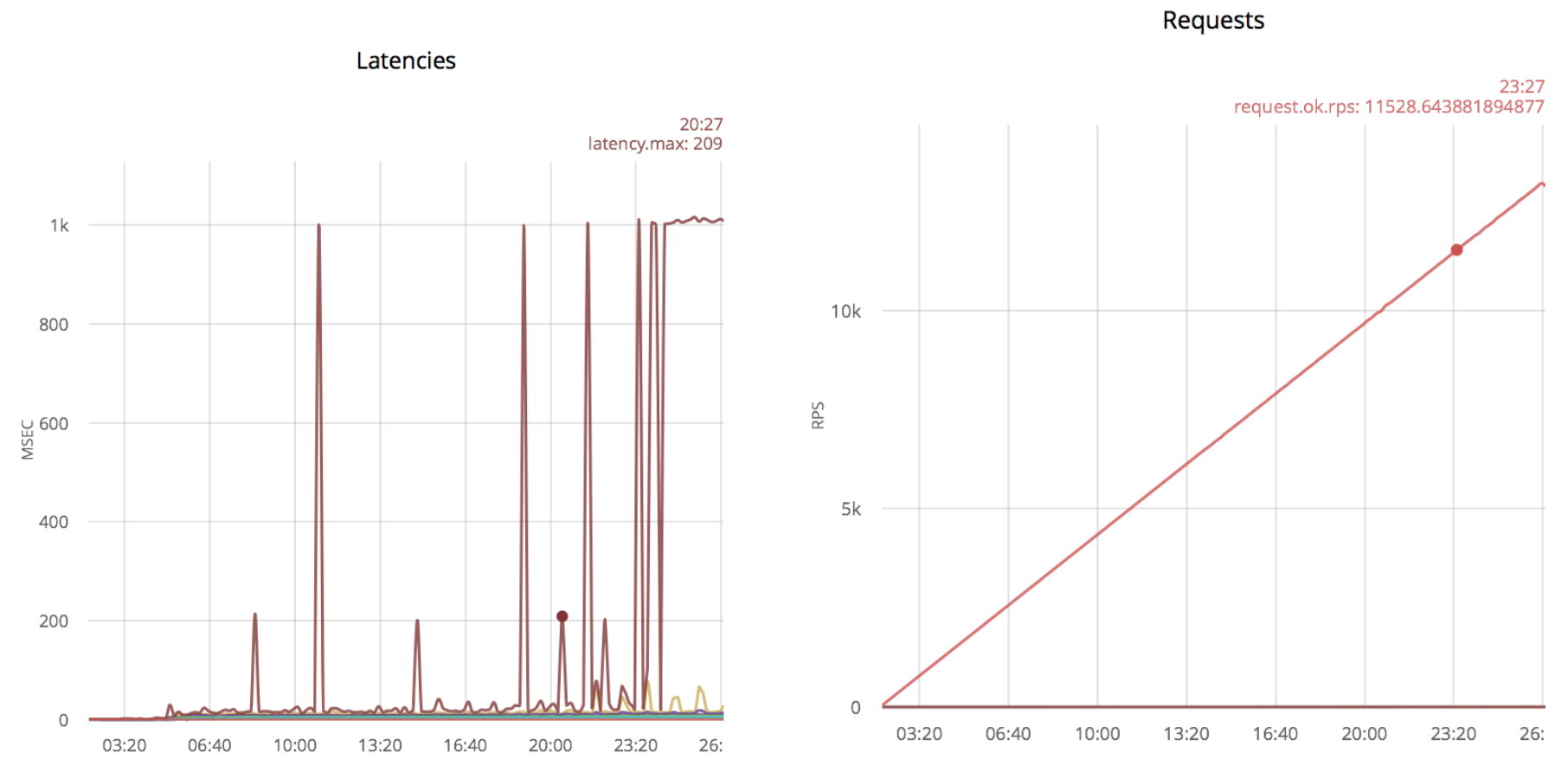
Выбросы в 1000 msec соответствуют превышению времени ожидания. Если продолжить увеличивать скорость открытия соединений, выбросы станут более частыми. Первые выбросы появляются при скорости 5k rps и постоянно присутствуют при скорости 11k rps.
Замена timeout при приёме пакета на timer:sleep()
Я обнаружл, что простое исключение параметра timeout при приёме сообщения сильно повышает скорость установления соединений. Для того чтобы не опрашивать сокет с максимальной скоростью, я добавил timer:sleep(20):
--- a/examples/tcp_echo/src/echo_protocol.erl
+++ b/examples/tcp_echo/src/echo_protocol.erl
@@ -15,10 +15,11 @@ init(Ref, Socket, Transport, _Opts = []) ->
loop(Socket, Transport).
loop(Socket, Transport) ->
- case Transport:recv(Socket, 0, 5000) of
- {ok, Data} ->
- Transport:send(Socket, Data),
+ case Transport:recv(Socket, 0, 0) of
+ {ok, _Data} ->
+ Transport:send(Socket, <<"ok">>),
loop(Socket, Transport);
+ {error, timeout} -> timer:sleep(20), loop(Socket, Transport);
_ ->
ok = Transport:close(Socket)
end.
С этой оптимизацией, приложение ranch может принимать больше соденинений, первый выброс появляется только при 11k rps:

Выбросов становится ещё больше, если пытаться повысить скорость дальше. Таким образом, максимальное число — 24k rps.
Вывод
С предложенной оптимизацией, я получил примерно двойной выигрыш в скорости приёма соединений, от 11k до 24k rps.
Оптимизация gen_tcp
Ниже чистая реализация при помощи gen_tcp, аналогичная тому что я сделал при помощи ranch (текст доступен в виде simple.erl в репозитории с примерами):
-export([service/1]).
-define(Options, [
binary,
{backlog, 128},
{active, false},
{buffer, 65536},
{keepalive, true},
{reuseaddr, true}
]).
-define(Timeout, 5000).
main([Port]) ->
{ok, ListenSocket} = gen_tcp:listen(list_to_integer(Port), ?Options),
accept(ListenSocket).
accept(ListenSocket) ->
case gen_tcp:accept(ListenSocket) of
{ok, Socket} -> erlang:spawn(?MODULE, service, [Socket]), accept(ListenSocket);
{error, closed} -> ok
end.
service(Socket) ->
case gen_tcp:recv(Socket, 0, ?Timeout) of
{ok, _Binary} -> gen_tcp:send(Socket, <<"ok">>), service(Socket);
_ -> gen_tcp:close(Socket)
end.
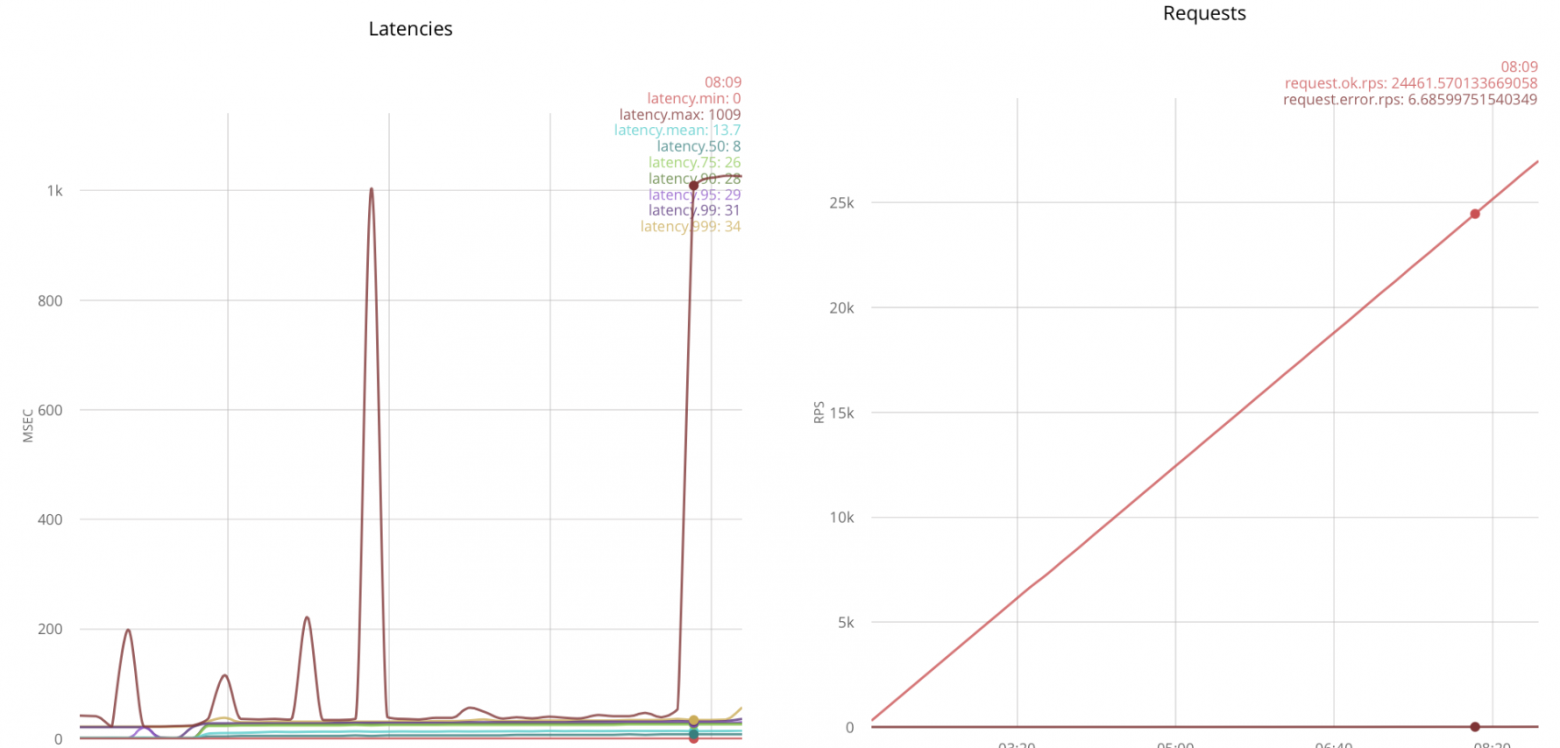
Запустив тот же сценарий, я получил результаты:

Как можно увидеть, примерно в районе 18k rps, приём соединений становится ненадёжным. Будем считать, что получается принять 18k.
Замена timeout при приёме пакета на timer:sleep()
Я просто применю ту же оптимизацию, что и для ranch:
service(Socket) ->
case gen_tcp:recv(Socket, 0, 0) of
{ok, _Binary} -> gen_tcp:send(Socket, <<"ok">>), service(Socket);
{error, timeout} -> timer:sleep(20), service(Socket);
_ -> gen_tcp:close(Socket)
end.
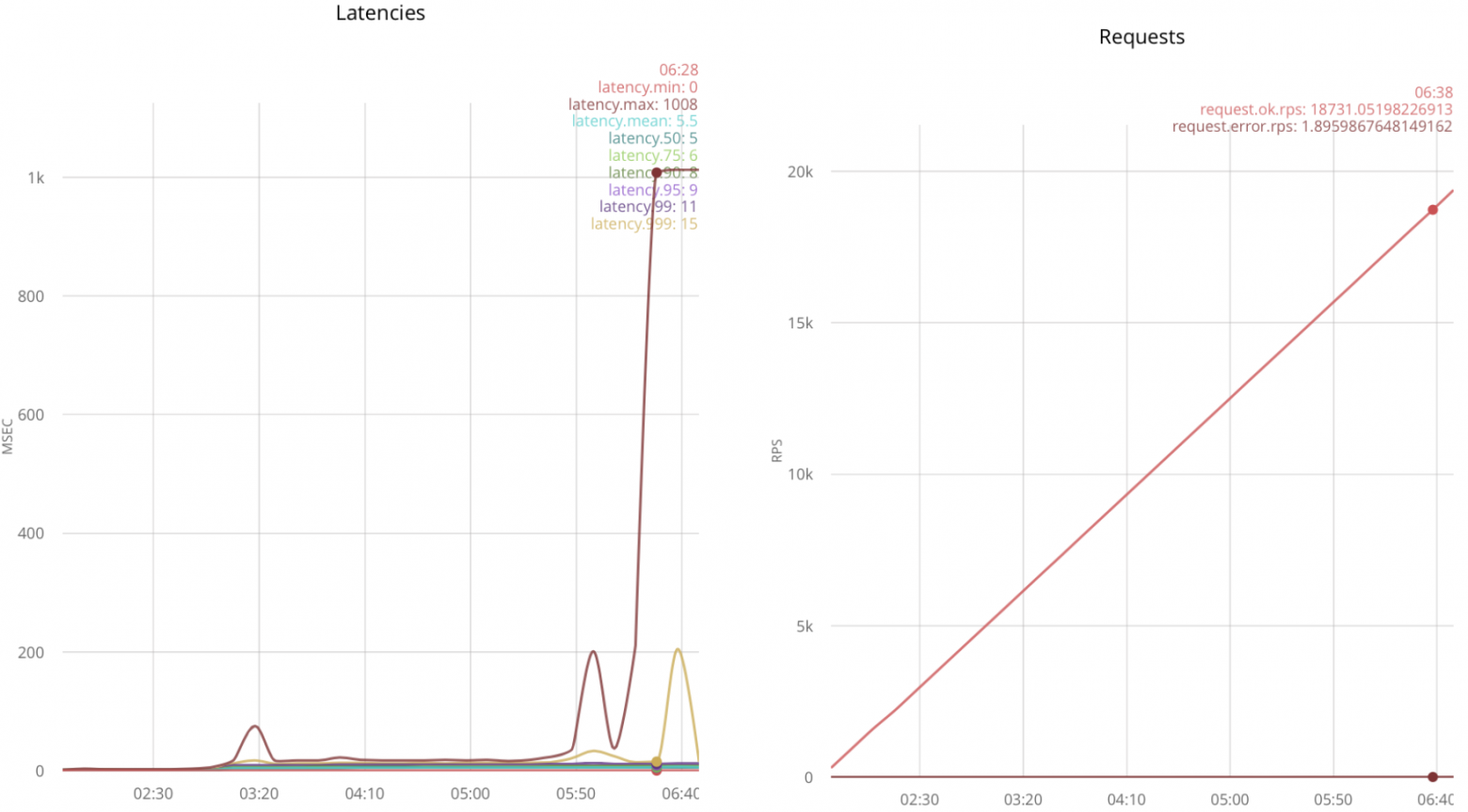
В таком случае получается обработать 23k rps:
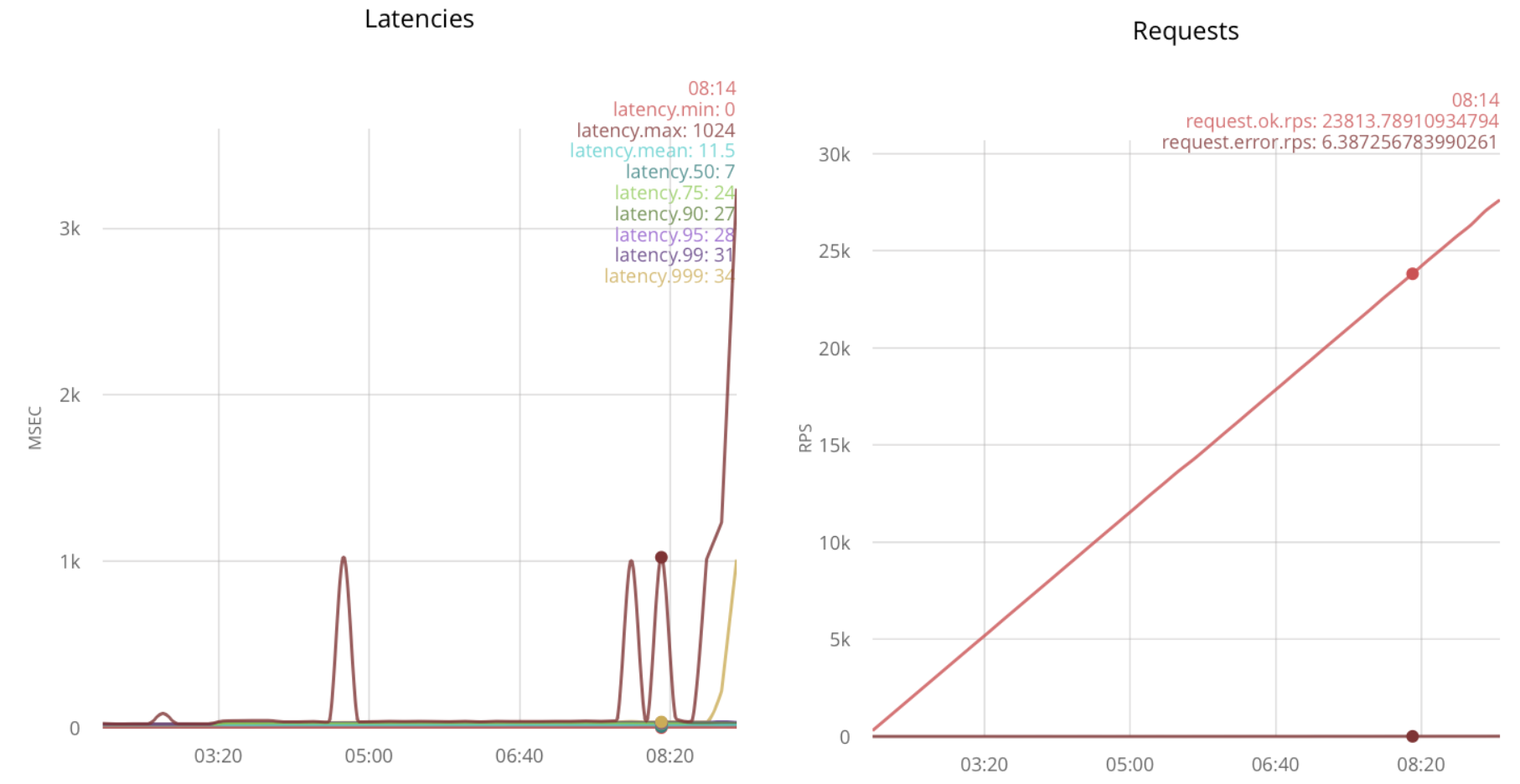
Добавление принимающих процессов
Вторая идея — увеличение количества принимающих соединение процессов. Это может быть достигнуто при помощи вызова gen_tcp:accept из нескольких процессов:
main([Port]) ->
{ok, ListenSocket} = gen_tcp:listen(list_to_integer(Port), ?Options),
erlang:spawn(?MODULE, accept, [ListenSocket]),
erlang:spawn(?MODULE, accept, [ListenSocket]),
accept(ListenSocket).
Тестирование под нагрузкой даёт 32k rps:
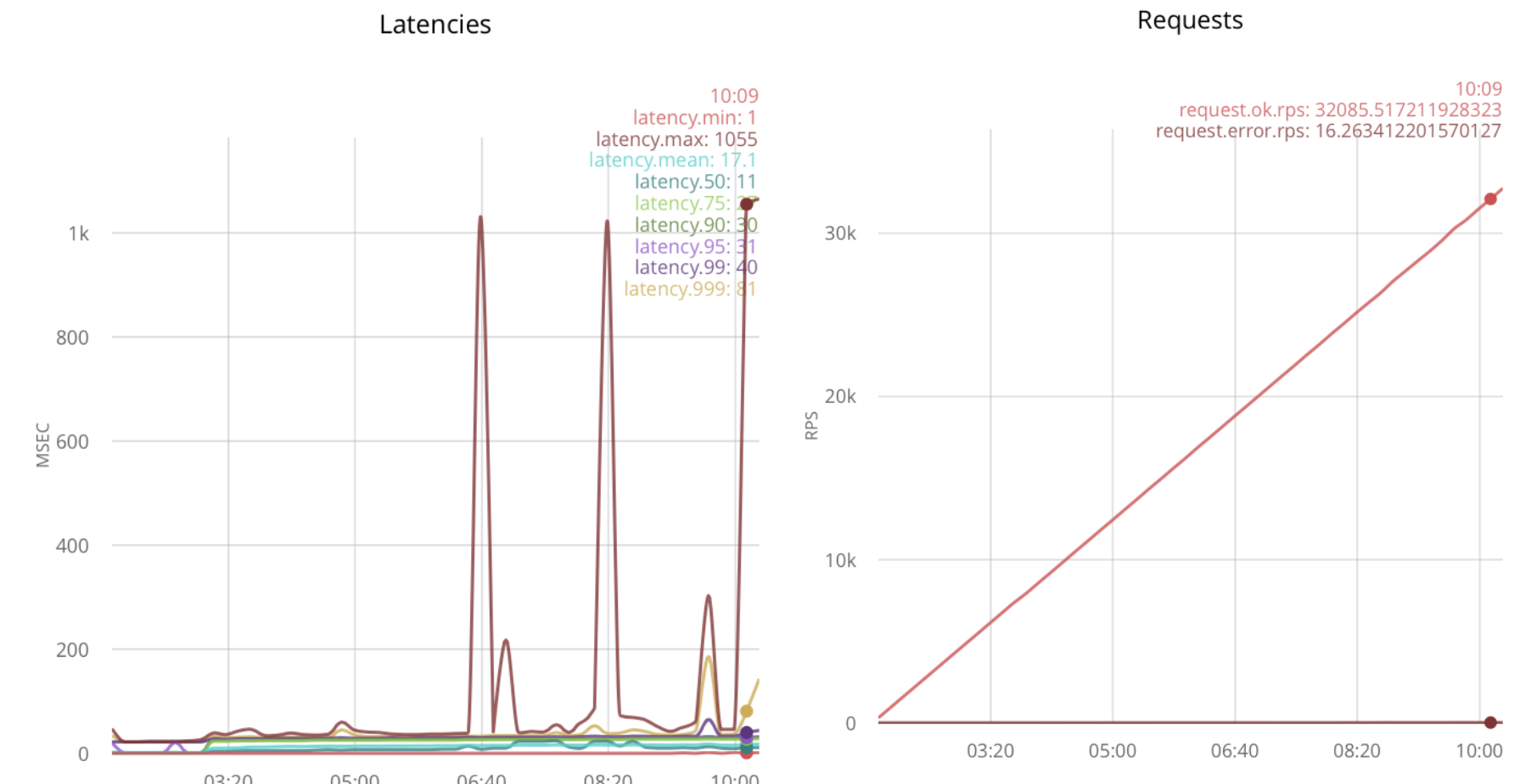
При дальнейшем увеличении нагрузки, задержки растут.
Вывод
Оптимизация timeout для gen_tcp увеличивает скорость приёма на 5k rps, от 18k до 23k.
С несколькими принимающими процессами, gen_tcp обрабатывает 32k rps, это в 1.8 раз больше, чем без оптимизаций.
Итоги
- Лучше не использовать параметр timeout в функции вызова, timer:sleep — лучше. Это применимо и к ranch и к чистому gen_tcp. Для ranch это удваивает скорость приёма соединений.
- Из нескольких процессов, соединения принимаются быстрей. Это применимо только для чистого gen_tcp. В моём случае это дало 40% улучшение в скорости приёма соединений в совокупности с заменой timeout на timer:sleep().
Получение сообщений
Это часть о том как получать большое количество коротких сообщений по уже установленым соединениям. Новые соединения открываются редко, требуется читать и отвечать на сообщения максимально быстро. Этот сценарий реализуется в нагруженных приложениях с web-сокетами.
Я открываю 25k соединений с нескольких узлов и постепенно увеличиваю скорость отправки сообщений.
Оптимизация ranch
Ниже результаты для неоптимизированного кода с использованием ranch (слева временные задержки, справа скорость обработки сообщений):

Без оптимизаций, ranch обрабатывает 70k rps с максимальной временной задержкой в 800ms.
Увеличение буферов linux
Довольно популярной оптимизацией является увеличение linux буферов для сокетов. Посмотрим, как эта оптимизация скажется на результатах:
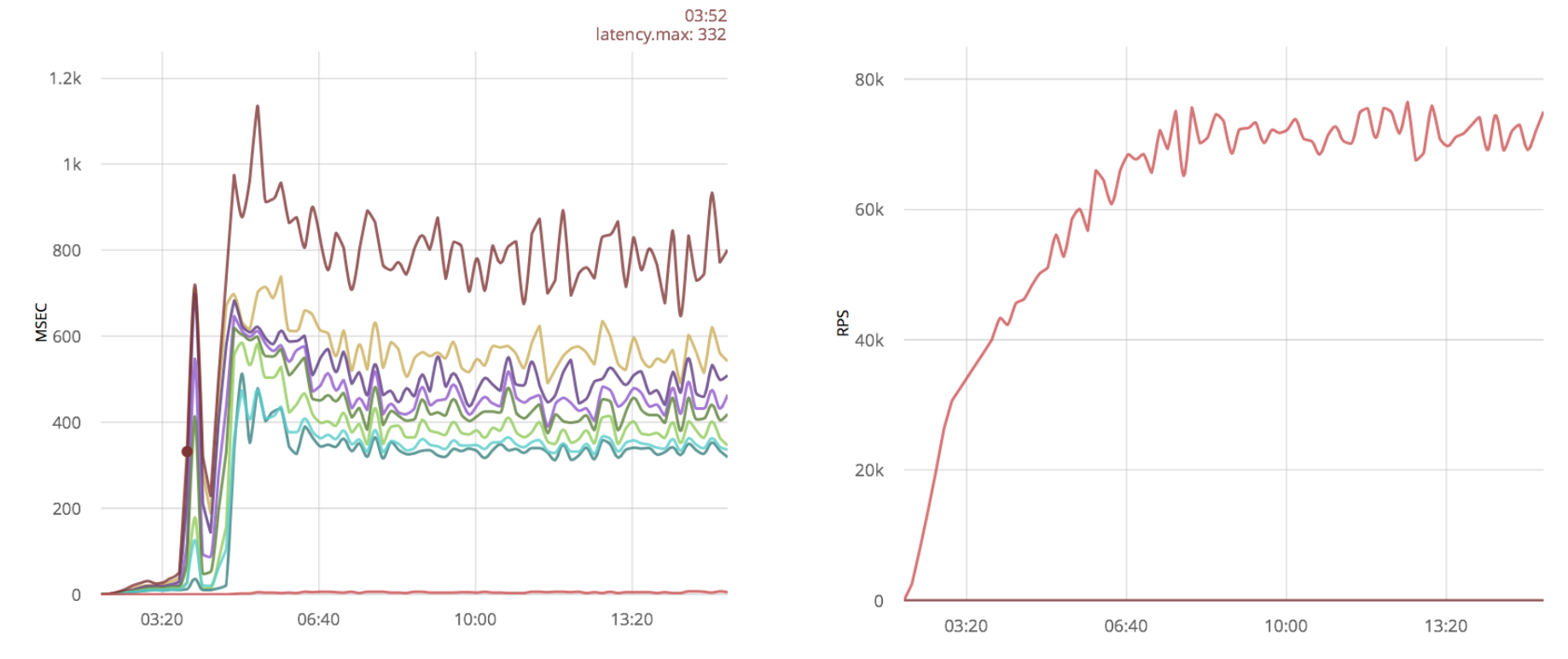
Вывод
В данном случае увеличение буферов не даёт большого выигрыша.
Оптимизация get_tcp
Ниже я проверил скорость обработки пакетов решением на gen_tcp из предыдущей части статьи:

70k rps, так же, как и ranch.
Уменьшение количества читающих процессов
В предыдущем случае, у меня 25k процессов читают из сокетов — один процесс на каждое соединение. Теперь я попробую уменьшить это количество и проверить результаты.
Я создам 100 процессов и буду распределять новые сокеты между ними:
main([Port]) ->
{ok, ListenSocket} = gen_tcp:listen(list_to_integer(Port), ?Options),
Readers = [erlang:spawn(?MODULE, reader, []) || _X <- lists:seq(1, ?Readers)],
accept(ListenSocket, Readers, []).
accept(ListenSocket, [], Reversed) -> accept(ListenSocket, lists:reverse(Reversed), []);
accept(ListenSocket, [Reader | Rest], Reversed) ->
case gen_tcp:accept(ListenSocket) of
{ok, Socket} -> Reader ! Socket, accept(ListenSocket, Rest, [Reader | Reversed]);
{error, closed} -> ok
end.
reader() -> reader([]).
read_socket(S) ->
case gen_tcp:recv(S, 0, 0) of
{ok, _Binary} -> gen_tcp:send(S, <<"ok">>), true;
{error, timeout} -> true;
_ -> gen_tcp:close(S), false
end.
reader(Sockets) ->
Sockets2 = lists:filter(fun read_socket/1, Sockets),
receive
S -> reader([S | Sockets2])
after ?SmallTimeout -> reader(Sockets)
end.
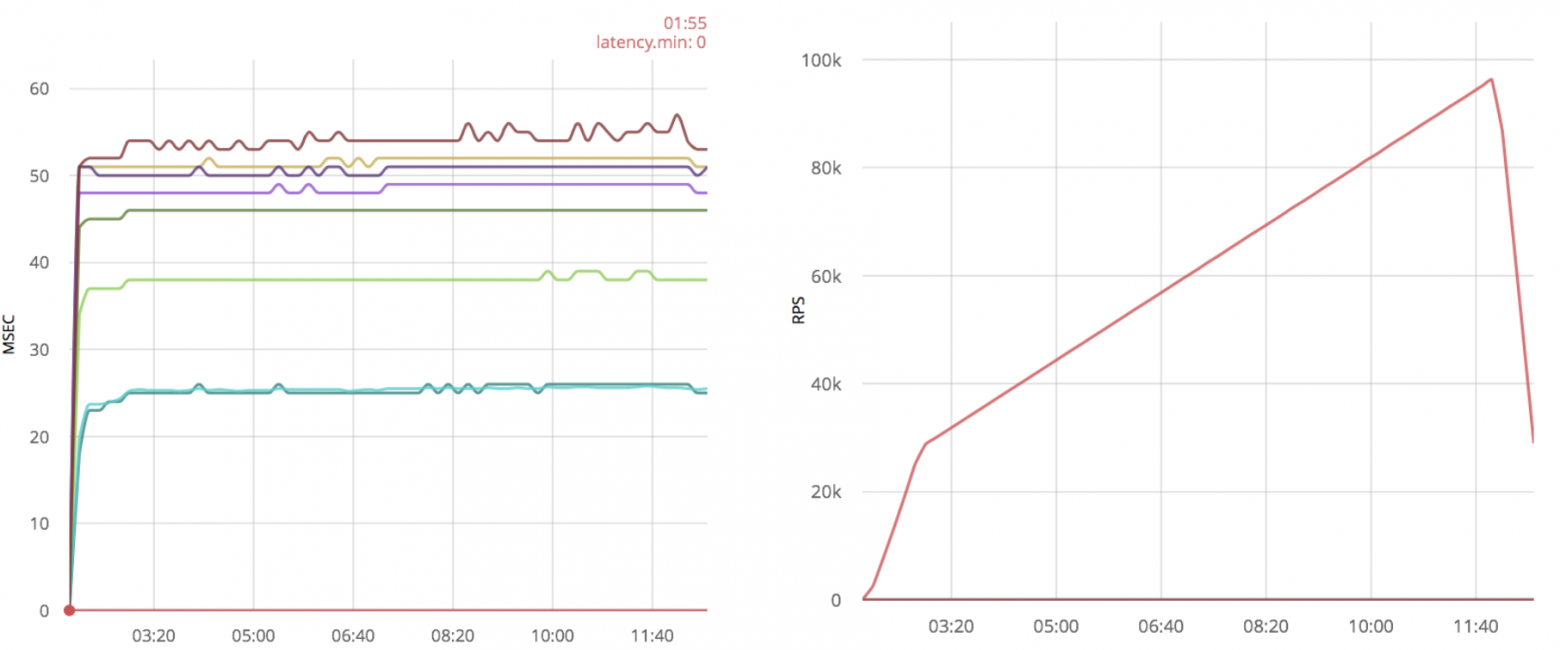
Эта оптимизация даёт существенный прирост производительности:
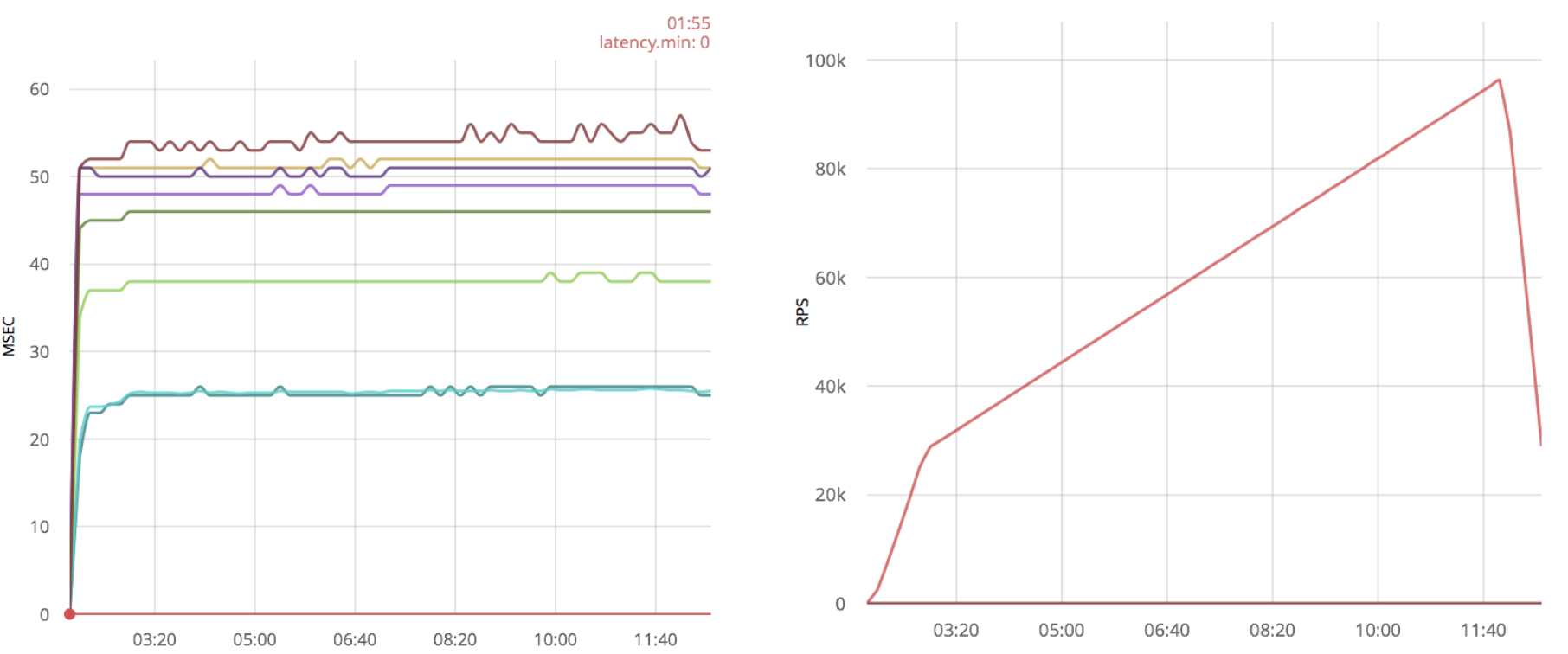
Кроме увеличения скорости, временные задержки выглядят гораздо лучше, a количество обрабатываемых пакетов около 100k, кроме того, можно обработать даже 120k сообщений, но с большими временными задержками. В то время как без оптимизации этого сделать не получалось.
Вывод
Обработка нескольких соединений из одного процесса даёт как минимум 50% увеличение производительности для чистого gen_tcp сервера.
Увеличение буферов Linux
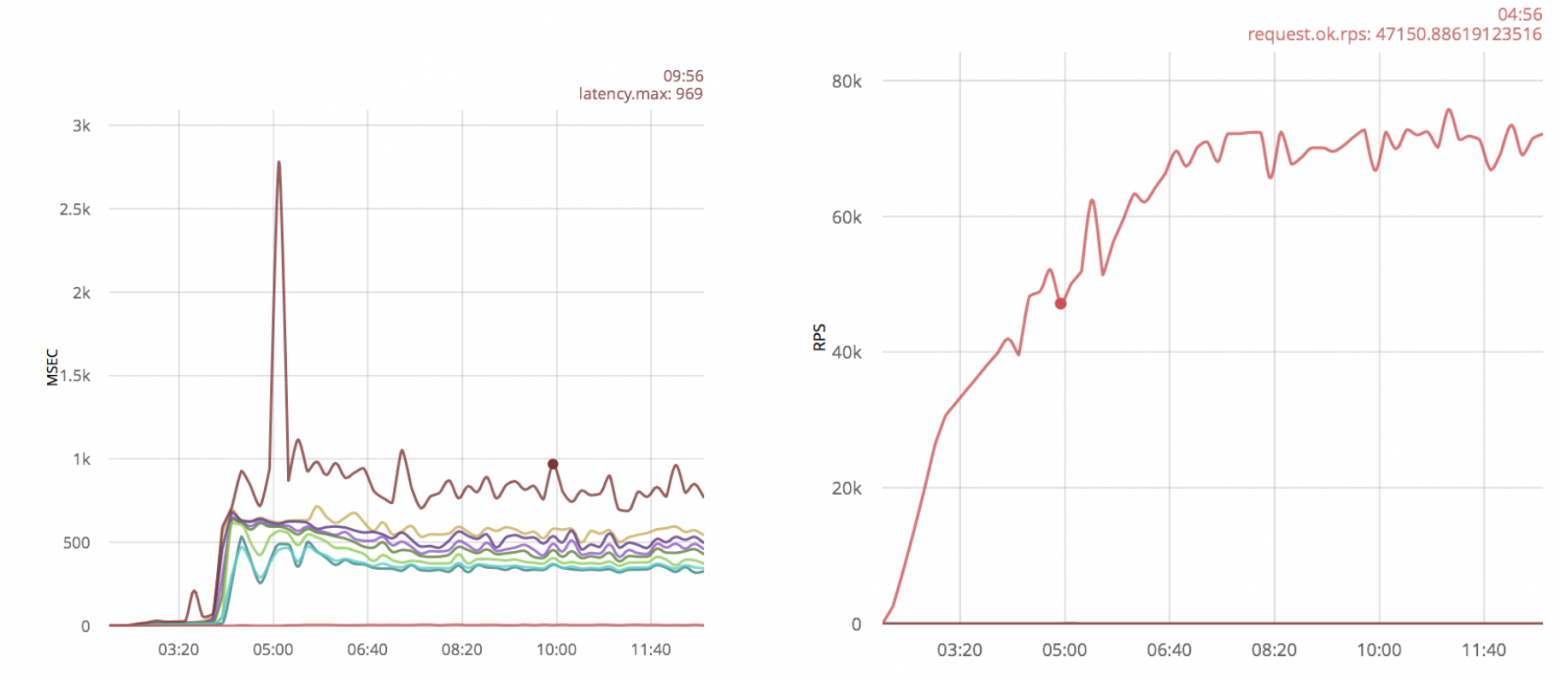
Я применю ту же оптимизацию к системе с ванильным gen_tcp скриптом:
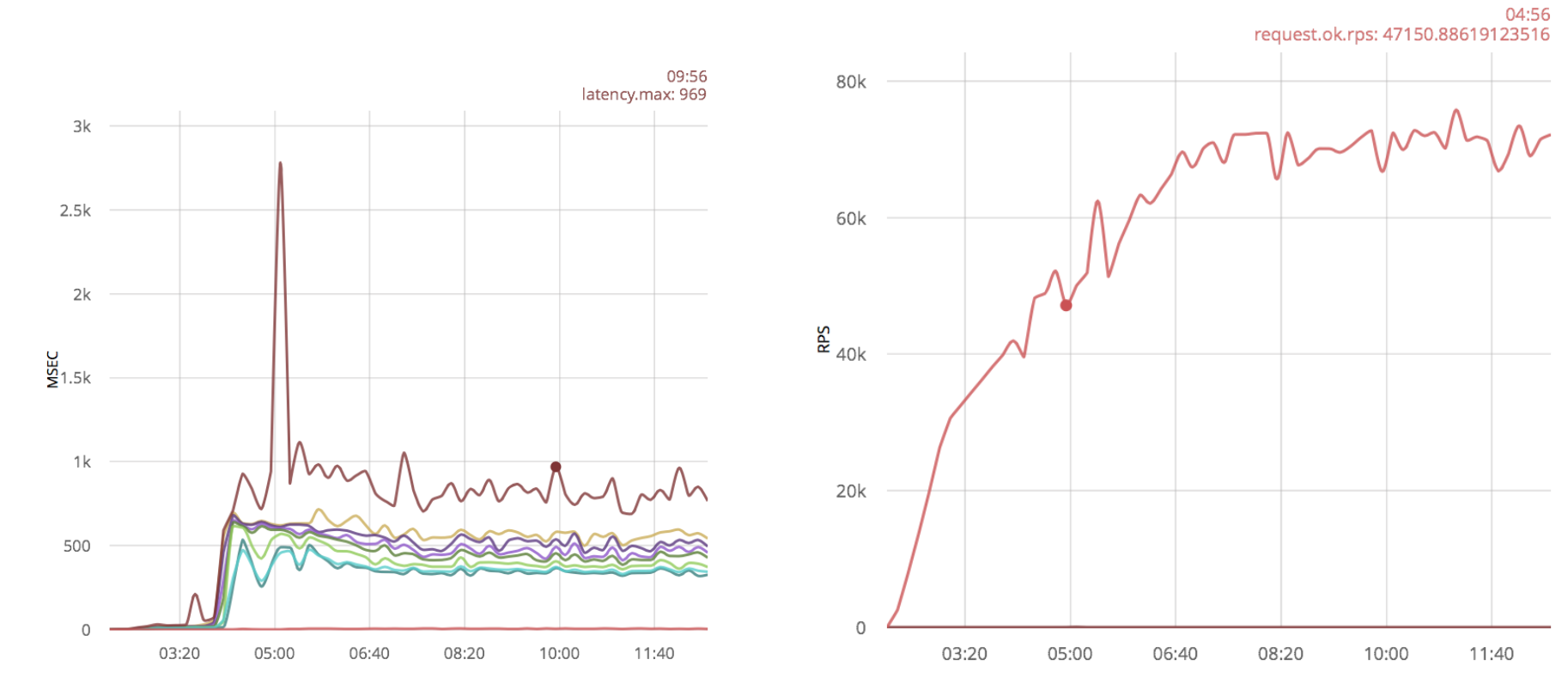
Как и в случае с ranch, каких-то существенных результатов не видно, только появились дополнительные выбросы в виде больших временных задержек.
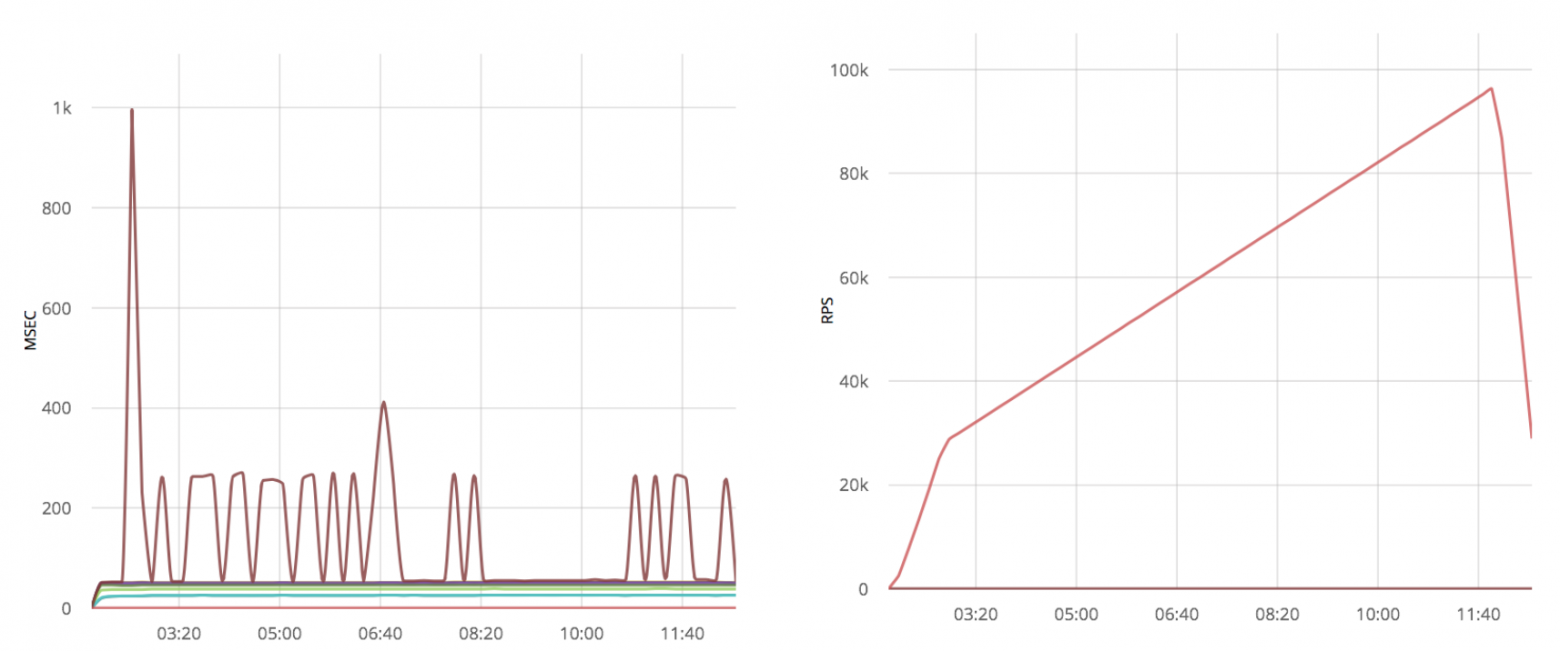
Применяя оптимизацию к уже оптимизированному gen_tcp я получаю множество выбросов временных задержек:
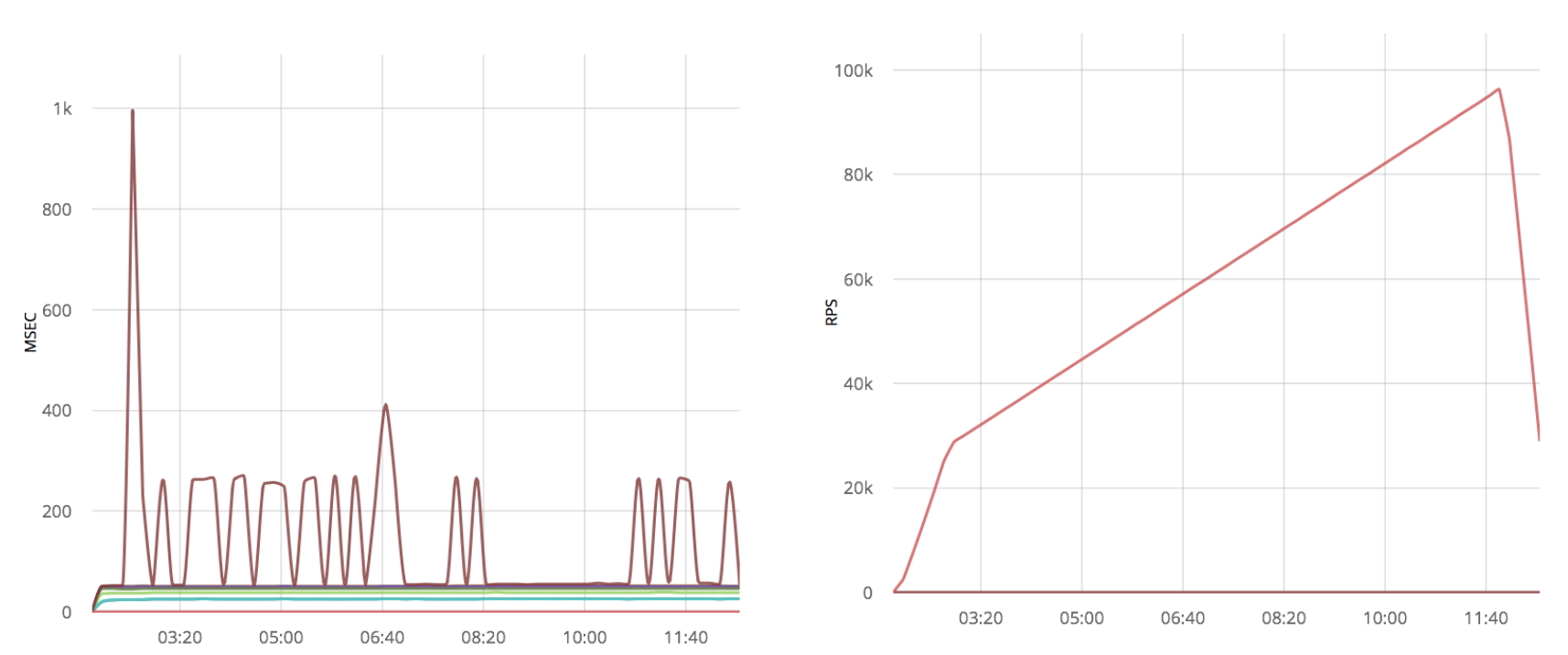
Вывод
Решения на чистом gen_tcp также не выигрывают от увеличения Linux буферов. Понижение количество читающих из сокетов процессов даёт 50% выигрыш в скорости обработки.
Итоги
- Изначально оба решения позволяют обрабатывать примерно одинаковое количество сообщений, около 70k rps.
- Увеличение буферов не позволяет существенным образом повысить скорость обработки и в случае с чистым gen_tcp добавляет выборосы в виде больших временных задержек.
- Gen_tcp решение с несколькими сокетами на один процесс работает как минимум в 1.5 раза быстрей чем неоптимизированное и имеет гораздо лучшие временные задержки. К сожалению, это оптимизация не применима к ranch без изменения его архитектуры.
Ответ на сообщения
Формально, в предыдущих главах цикл обработки сообщения предполагал ответ на него, но я не делал чего-то для оптимизации этой части. Я попробую применить те же самые идеи к функциям отправки сообщения. Здесь я использую сценарий из предыдущей главы, в котором пакеты идут по уже установленым соединениям.
Оптимизации таймаутов и процессов
Те же идеи, которые я использовал в предыдущих главах можно применить к функции отправки: убрать timeout и отвечать из меньшего количества процессов. Такого параметра как timeout в функции send нет, нужно установить опцию {send_timeout, 0} при открытии соединения.
К сожалению, это оптимизация практически ничего не меняет, а изменение кода сводится к простому добавлению опции, по этой причине я решил не утруждать читателя diff-ом и графиком.
Для проверки того как влияет количество процессов, я использовал следующий скрипт:
-export([responder/0, service/2]).
-define(Options, [
binary,
{backlog, 128},
{active, false},
{buffer, 65536},
{keepalive, true},
{send_timeout, 0},
{reuseaddr, true}
]).
-define(SmallTimeout, 50).
-define(Timeout, 5000).
-define(Responders, 200).
main([Port]) ->
{ok, ListenSocket} = gen_tcp:listen(list_to_integer(Port), ?Options),
Responders = [erlang:spawn(?MODULE, responder, []) || _X <- lists:seq(1, ?Responders)],
accept(ListenSocket, Responders, []).
accept(ListenSocket, [], Reversed) -> accept(ListenSocket, lists:reverse(Reversed), []);
accept(ListenSocket, [Responder | Rest], Reversed) ->
case gen_tcp:accept(ListenSocket) of
{ok, Socket} -> erlang:spawn(?MODULE, service, [Socket, Responder]), accept(ListenSocket, Rest, [Responder | Reversed]);
{error, closed} -> ok
end.
responder() ->
receive
S -> gen_tcp:send(S, <<"ok">>), responder()
after ?SmallTimeout -> responder()
end.
service(Socket, Responder) ->
case gen_tcp:recv(Socket, 0, ?Timeout) of
{ok, _Binary} -> Responder ! Socket, service(Socket, Responder);
_ -> gen_tcp:close(Socket)
end.
Здесь отвечающие процессы разделены с читающими; У меня 25000 читающих и 200 отвечающих.
Но опять, эта оптимизация не показывает существенного прироста производительности в сравнении с решением на gen_tcp из предыдущего раздела:

Тюнинг Erlang
В случае если один процесс используется для работы с несколькими сокетами, один медленный клиент может затормозить всех остальных. Для того чтобы избежать такой ситуации, можно установить {send_timeout, 0} при открытии сокета и в случае неудачи повторять отправку следующим циклом.
К сожалению, функция send не возвращает количество отправленых байт. Возвращается только ошибка POSIX, либо атом “ok”. Это делает невозможным отправку с последнего успешно отправленого байта. Кроме того, зная это количество можно использовать сеть более эффективно, что становится особенно важно, если клиенты имеют плохие каналы.
Далее я привожу пример как это можно исправить:
- Скачаем исходники Erlang с официального сайта:
$ wget http://erlang.org/download/otp_src_18.2.1.tar.gz $ tar -xf otp_src_18.2.1.tar.gz $ cd otp_src_18.2.1
- Обновим функцию драйвера inet erts/emulator/drivers/common/inet_drv.c:
- Добавим возможность отвечать числом:
static int inet_reply_ok_int(inet_descriptor* desc, int Val) { ErlDrvTermData spec[2*LOAD_ATOM_CNT + 2*LOAD_PORT_CNT + 2*LOAD_TUPLE_CNT]; ErlDrvTermData caller = desc->caller; int i = 0; i = LOAD_ATOM(spec, i, am_inet_reply); i = LOAD_PORT(spec, i, desc->dport); i = LOAD_ATOM(spec, i, am_ok); i = LOAD_INT(spec, i, Val); i = LOAD_TUPLE(spec, i, 2); i = LOAD_TUPLE(spec, i, 3); ASSERT(i == sizeof(spec)/sizeof(*spec)); desc->caller = 0; return erl_drv_send_term(desc->dport, caller, spec, i); }
- Уберём отправку атома “ok” из функции tcp_inet_commandv:
else inet_reply_error(INETP(desc), ENOTCONN); } else if (desc->tcp_add_flags & TCP_ADDF_PENDING_SHUTDOWN) tcp_shutdown_error(desc, EPIPE); >> else tcp_sendv(desc, ev); DEBUGF(("tcp_inet_commandv(%ld) }\r\n", (long)desc->inet.port)); }
- Добавим отправку int вместо возврата 0 in в функции tcp_sendv:
default: if (len == 0) >> return inet_reply_ok_int(desc, 0); h_len = 0; break; } ----------------------------------- else if (n == ev->size) { ASSERT(NO_SUBSCRIBERS(&INETP(desc)->empty_out_q_subs)); >> return inet_reply_ok_int(desc, n); } else { DEBUGF(("tcp_sendv(%ld): s=%d, only sent " LLU"/%d of "LLU"/%d bytes/items\r\n", (long)desc->inet.port, desc->inet.s, (llu_t)n, vsize, (llu_t)ev->size, ev->vsize)); } DEBUGF(("tcp_sendv(%ld): s=%d, Send failed, queuing\r\n", (long)desc->inet.port, desc->inet.s)); driver_enqv(ix, ev, n); if (!INETP(desc)->is_ignored) sock_select(INETP(desc),(FD_WRITE|FD_CLOSE), 1); } >> return inet_reply_ok_int(desc, n);
- Добавим возможность отвечать числом:
- Запустим /configure && make && make install.
И всё, теперь функция gen_tcp:send будет возвращать {ok, Number} в случае успеха. Приведённый фрагмент кода выведет “9”:
{ok, Sock} = gen_tcp:connect(SomeHostInNet, 5555,
[binary, {packet, 0}]),
{ok, N} = gen_tcp:send(Sock, "Some Data"),
io:format("~p", [N])
Вывод
Если вы обрабатываете несколько соединений из одного процесса, необходимо использовать опцию {send_timeout, 0} при создании сокета, в противном случае один медленный клиент может затормозить отправку всем остальным.
Если ваш протокол может обрабатывать частичные сообщения, лучше пропатчить OTP и учитывать количество отправленных байт.
Кратко
- Если вам нужно быстро принимать соединения, нужно принимать их из нескольких процессов.
- Если нужно быстро читать из сокетов, нужно обрабатывать несколько сокетов из одного процесса и не пользоваться ranch.
- Увеличение буферов linux приводит к понижению стабильности системы и не даёт существенного выигрыша производительности.
- При использовании нескольких сокетов из одного процесса необходимо убирать таймаут на отправку.
- Если нужно знать точное количество отправленных байт — можно пропатчить OTP.
Ссылки
- Библиотека, которая позволяет обрабатывать сокеты по сценарию, описанному выше: https://github.com/parsifal-47/socketpool
- Примеры из статьи: https://github.com/parsifal-47/server-examples
