В настоящий момент уже можно считать, что страсти по Big Data и Data Science немного утихли, а ожидание чуда, как обычно, было сильно скорректировано реальностью физического мира. Самое время заняться конструктивной деятельностью. Поиск тем на Хабре по различным ключевым словам выдал крайне скудный набор статей, поэтому я решил поделиться тем опытом, который был накоплен в части практического применения инструментов и подходов Data Science для решения повседневных задач в компании.
Какая связь между рутиной и интеграционными задачами?
Классический подход для автоматизации подобных задач — привлечение консультантов по бизнес-процессам; формирование предложений по переходу на единую платформу с глобальной интеграцией; анализ и выбор; RFI/RFP; тендеры; многолетнее внедрение; какой-то результат за огромные деньги на морально устаревшей за время внедрения платформе.
Конечно, я немного утрирую, но даже время и деньги, потраченные на бесконечные групповые совещания при проработке решения, стоят десятки миллионов рублей в ФОТ (фонд оплаты труда), а многие инициаторы к окончанию проекта уже работают где-то в другом месте.
Парадоксально то, что на самом деле для приемлемого удовлетворения исходных потребностей достаточно было всего лишь оперативно осуществить локальную «сшивку» данных, их обработку и доходчивую визуализацию. При этом, когда переходишь на язык аналогий реального мира и говоришь в терминах ремонта и строительства дома, то всем все очевидно и никто не предлагает из-за порванных котом обоев незамедлительно строить новый дом.
Поэтому мы решили воспользоваться для решения подобных задач теми инструментами, которые есть в сообществе Data Science. Минимальный набор, который нас полностью устроил — язык R, IDE – RStudio, интеграционный шлюз — DeployR, сервер клиентских веб-приложений — Shiny. Когда говорим о визуализации, то естественно, это никак не PieCharts, а современные эргономичные принципы подачи информации, включая интерактивные JS элементы.
Важно, что на первичном этапе все продукты используются в формате open-source или community edition. Если вдруг окажется, что задача решена суперуспешно и необходимо ее расширить и ускорить, то у каждого компонента есть коммерческая версия за очень низкую стоимость, устраняющую масштабные ограничения бесплатных продуктов.
Решая практические задачи, мы еще раз убедились, что мир Big Data крайне ограничен и востребован, в основном, большими ИТ или сетевыми компаниями. Изначальная трактовка термина Big Data, как объема данных, не вмещающихся в рамки оперативной памяти компьютера, с учетом развития вычислительных средств теряет свой смысл для рядовых задач. В ноутбук можно поставить 16 Gb, в сервер ~ 500 Gb, а в облаке можно вообще заказать сервер с 2Tb DDR4 оперативной памяти + 4 Tb SSD (Amazon EC2 X1).
Для удобства обозначения в рамках рабочих процессов таких данных, которые вроде и большие, но все равно меньше объема RAM вычислителя, мы приняли термин Compact Data.
Так вот, в реальных задачах обычных компаний Compact Data вполне достаточно для принятия решений с требуемой точностью и быстротой.
К сведению, коллеги из Google вообще переводят разговор с пространственных размерностей во временн`ые: «Для меня термин Большие Данные относится отнюдь не к размеру данных. Речь идет о трансформации часов упорной работы по анализу данных в непринужденную обработку в течении секунд», — Felipe Hoffa, Google software engineer.
В качестве первой success-story мы вынесли за неделю очередную BI систему. Совершенно неожиданно выяснилось, что руководство недовольно отчетностью из систем, которая есть в настоящий момент. Поэтому на протяжении полугода проводился отсмотр, анализ и даже пилот BI системы из числа финалисток. Договор на поставку и внедрение лежал уже на столе у руководства. В последний момент мы просунули ногу в дверь и попросили 3-4 дня на то, чтобы сделать альтернативный стенд на базе инструментов R. За эти 5 дней вдвоем мы успели повторить вчерне весь скудный пилотный функционал BI (частично на синтетических данных сторонних ИС), добавить массу дополнительной аналитики на дашборды, выявить пару дыр в эффективности работы подразделения, прикрутить прогнозную аналитику. Соответственно, через неделю договор с BI лежал там, где ему и полагается (мусорная корзина), а мы получили карт-бланш на реализацию. Через полгода проект был заморожен в развитии, как достигший вершины желаний руководства и пользователей. Попутно при разработке мы тормознули еще один тендер по расширению существующей системы (а, на секунду, это почти ~$400k) и сделали все, что было нужно для бизнеса, сами.
Следующий Data Science кейс появился в контексте модной задачи «умного земледелия», а именно контроль полива растений. Простой вопрос «сколько литров лить?» поднимет целый ворох задач. Это калибровка и сбор данных с разнообразных датчиков, которые данные собирают нерегулярно и крайне неточно (например, для измерения влажности почвы по-другому не получается) и оптимизация георазмещения этих датчиков и построение взвешенного прогноза погоды по бесплатным куцым данным и сложная физико-математическая модель обмена водой растением в зависимости от текущих условий. А еще надо все понятно и доходчиво интерактивно все это отобразить на компьютере агронома. Примерно через 3 месяца работы прототип был собран. Причем все сделано на упомянутых выше инструментах R + bash.
Чем еще привлекателен R в отличии от различных мышевозилок?
Сейчас идет активная работа еще над парами задач, но полученный опыт в целом позволяет уверенно браться почти за любую задачу в задаче локальной «сшивки». Вообще, ощущение от возможностей R обычными пользователями можно описать такой картинкой:
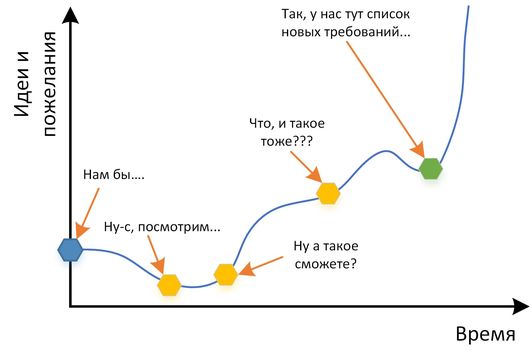
Если обобщить опыт, то подобная «сшивка» востребована практически везде. Главное посмотреть свежим взглядом (читаем литературу про ТРИЗ и про изобретения, опоздавшие на сотню-другую лет), а руководству не побояться рискнуть. Принципиальный тезис при старте такой активности — продвижение малыми шажками.
В идеальном случае в результате работ появляется небольшой компонент, который:
Рамки работ сознательно ограничены 2 месяцами максимум. Итеративная и интерактивная разработка, как правило, позволяет за этот срок концептуально решить локальные проблемы в разрыве различных ИС. После завершения работ необходимо «погонять» полученный компонент в реальных бизнес-процессах, сопоставить полученный эффект с ожидавшимся. Если остались задачи или появились новые, то расставить приоритеты и приступить к новой итерации.
Важно то, что каждая итерация:
При этом нет никаких накладных расходов на тяжеловесное проектное управление, задача обозрима по масштабу, документация создается только минимально необходимая.
Еще раз отмечу, что вряд ли речь будет идти Data Science, как сложных математических алгоритмах в применении Big Data. Реальные задачи бизнеса гораздо прозаичнее, но выгоды от их решения могут быть очень и очень большими. Инструменты R и подходы Data Science могут в этом замечательно помочь.
Самое замечательное, что интрига сохраняется до последнего. Вы никогда заранее не знаете, какой будет следующий шаг и следующий запрос после, а грамотные руки и светлая голова могут не только помочь исправить текущие недочеты, но и предложить новые бизнес-возможности.
Следующий пост: «Экосистема R как инструмент для автоматизации бизнес-задач»
Какая связь между рутиной и интеграционными задачами?
- На протяжении всего рабочего дня как обычных пользователей, так и руководителей разного ранга ИТ используется только как средство для принятия решения и исполнения набора в большинстве случаев ритуальных действий в бизнес-процессе.
- Пользователи окружены несколькими кусочно-интегрированными информационными системами и для принятия решений необходимо посмотреть в «десять» источников, немного «подточить» данные, что-то домыслить, и повозить мышкой в Excel сообразно своему уровню знакомства с MS Office и математикой.
- Для реакции, более сложной, чем «заполнить 5 экранов и прокликать Next-Next-Next» необходимо «нажать на капу», чтобы запустить мини-проект на недельку-другую, по внесению корректирующих действий.
Классический подход для автоматизации подобных задач — привлечение консультантов по бизнес-процессам; формирование предложений по переходу на единую платформу с глобальной интеграцией; анализ и выбор; RFI/RFP; тендеры; многолетнее внедрение; какой-то результат за огромные деньги на морально устаревшей за время внедрения платформе.
Конечно, я немного утрирую, но даже время и деньги, потраченные на бесконечные групповые совещания при проработке решения, стоят десятки миллионов рублей в ФОТ (фонд оплаты труда), а многие инициаторы к окончанию проекта уже работают где-то в другом месте.
Парадоксально то, что на самом деле для приемлемого удовлетворения исходных потребностей достаточно было всего лишь оперативно осуществить локальную «сшивку» данных, их обработку и доходчивую визуализацию. При этом, когда переходишь на язык аналогий реального мира и говоришь в терминах ремонта и строительства дома, то всем все очевидно и никто не предлагает из-за порванных котом обоев незамедлительно строить новый дом.
Поэтому мы решили воспользоваться для решения подобных задач теми инструментами, которые есть в сообществе Data Science. Минимальный набор, который нас полностью устроил — язык R, IDE – RStudio, интеграционный шлюз — DeployR, сервер клиентских веб-приложений — Shiny. Когда говорим о визуализации, то естественно, это никак не PieCharts, а современные эргономичные принципы подачи информации, включая интерактивные JS элементы.
Важно, что на первичном этапе все продукты используются в формате open-source или community edition. Если вдруг окажется, что задача решена суперуспешно и необходимо ее расширить и ускорить, то у каждого компонента есть коммерческая версия за очень низкую стоимость, устраняющую масштабные ограничения бесплатных продуктов.
Где же про Big Data?
Решая практические задачи, мы еще раз убедились, что мир Big Data крайне ограничен и востребован, в основном, большими ИТ или сетевыми компаниями. Изначальная трактовка термина Big Data, как объема данных, не вмещающихся в рамки оперативной памяти компьютера, с учетом развития вычислительных средств теряет свой смысл для рядовых задач. В ноутбук можно поставить 16 Gb, в сервер ~ 500 Gb, а в облаке можно вообще заказать сервер с 2Tb DDR4 оперативной памяти + 4 Tb SSD (Amazon EC2 X1).
Для удобства обозначения в рамках рабочих процессов таких данных, которые вроде и большие, но все равно меньше объема RAM вычислителя, мы приняли термин Compact Data.
Так вот, в реальных задачах обычных компаний Compact Data вполне достаточно для принятия решений с требуемой точностью и быстротой.
К сведению, коллеги из Google вообще переводят разговор с пространственных размерностей во временн`ые: «Для меня термин Большие Данные относится отнюдь не к размеру данных. Речь идет о трансформации часов упорной работы по анализу данных в непринужденную обработку в течении секунд», — Felipe Hoffa, Google software engineer.
R success stories
В качестве первой success-story мы вынесли за неделю очередную BI систему. Совершенно неожиданно выяснилось, что руководство недовольно отчетностью из систем, которая есть в настоящий момент. Поэтому на протяжении полугода проводился отсмотр, анализ и даже пилот BI системы из числа финалисток. Договор на поставку и внедрение лежал уже на столе у руководства. В последний момент мы просунули ногу в дверь и попросили 3-4 дня на то, чтобы сделать альтернативный стенд на базе инструментов R. За эти 5 дней вдвоем мы успели повторить вчерне весь скудный пилотный функционал BI (частично на синтетических данных сторонних ИС), добавить массу дополнительной аналитики на дашборды, выявить пару дыр в эффективности работы подразделения, прикрутить прогнозную аналитику. Соответственно, через неделю договор с BI лежал там, где ему и полагается (мусорная корзина), а мы получили карт-бланш на реализацию. Через полгода проект был заморожен в развитии, как достигший вершины желаний руководства и пользователей. Попутно при разработке мы тормознули еще один тендер по расширению существующей системы (а, на секунду, это почти ~$400k) и сделали все, что было нужно для бизнеса, сами.
Следующий Data Science кейс появился в контексте модной задачи «умного земледелия», а именно контроль полива растений. Простой вопрос «сколько литров лить?» поднимет целый ворох задач. Это калибровка и сбор данных с разнообразных датчиков, которые данные собирают нерегулярно и крайне неточно (например, для измерения влажности почвы по-другому не получается) и оптимизация георазмещения этих датчиков и построение взвешенного прогноза погоды по бесплатным куцым данным и сложная физико-математическая модель обмена водой растением в зависимости от текущих условий. А еще надо все понятно и доходчиво интерактивно все это отобразить на компьютере агронома. Примерно через 3 месяца работы прототип был собран. Причем все сделано на упомянутых выше инструментах R + bash.
Чем еще привлекателен R в отличии от различных мышевозилок?
- Это полноценный язык программирования. Последние пакеты Hadley Wickham подняли R по удобству работы с данными почти на космическую орбиту. Также активно расширяется поддержка функционального программирования.
- Широчайший спектр математических пакетов и алгоритмов.
- Элементарно встраиваем в devops. Исходники в git, есть механизм автотестов, возможность самодокументирования (R Markdown). Совместная работа и применение agile методологий.
- StackOverflow community.
- … и много других плюшек.
Выводы
Сейчас идет активная работа еще над парами задач, но полученный опыт в целом позволяет уверенно браться почти за любую задачу в задаче локальной «сшивки». Вообще, ощущение от возможностей R обычными пользователями можно описать такой картинкой:

Если обобщить опыт, то подобная «сшивка» востребована практически везде. Главное посмотреть свежим взглядом (читаем литературу про ТРИЗ и про изобретения, опоздавшие на сотню-другую лет), а руководству не побояться рискнуть. Принципиальный тезис при старте такой активности — продвижение малыми шажками.
В идеальном случае в результате работ появляется небольшой компонент, который:
- собирает данные из всех необходимых источников и проводит закулисную сложную обработку;
- выдает пользователю красивую интерактивную картинку (wow эффект желателен, но не самоцель);
- в дополнение к картинке выдает развернутый интерактивный отчет и рекомендации по выбору оптимального решения;
- по мере возможности самостоятельно выполняет требуемые изменения в других информационных системах (зачатки операционной аналитики).
Рамки работ сознательно ограничены 2 месяцами максимум. Итеративная и интерактивная разработка, как правило, позволяет за этот срок концептуально решить локальные проблемы в разрыве различных ИС. После завершения работ необходимо «погонять» полученный компонент в реальных бизнес-процессах, сопоставить полученный эффект с ожидавшимся. Если остались задачи или появились новые, то расставить приоритеты и приступить к новой итерации.
Важно то, что каждая итерация:
- основана на реальных бизнес-потребностях;
- приносит реальный эффект для бизнеса;
- закончена и самодостаточна.
При этом нет никаких накладных расходов на тяжеловесное проектное управление, задача обозрима по масштабу, документация создается только минимально необходимая.
Еще раз отмечу, что вряд ли речь будет идти Data Science, как сложных математических алгоритмах в применении Big Data. Реальные задачи бизнеса гораздо прозаичнее, но выгоды от их решения могут быть очень и очень большими. Инструменты R и подходы Data Science могут в этом замечательно помочь.
Самое замечательное, что интрига сохраняется до последнего. Вы никогда заранее не знаете, какой будет следующий шаг и следующий запрос после, а грамотные руки и светлая голова могут не только помочь исправить текущие недочеты, но и предложить новые бизнес-возможности.
Следующий пост: «Экосистема R как инструмент для автоматизации бизнес-задач»
