 В предыдущей статье я рассказал о том, как построить простейшую топологию для Apache Ignite. Она состояла из одного клиента и одного сервера, клиент слал на сервер сообщение и сервер его отображал. Было рассказано о том, как настроить продукт и проконтролировать его жизнедеятельность. Теперь пришло время для более сложного примера. Будет продемонстрировано построение сложной топологии и более интересные сценарии взаимодействия. Предполагается, что читатель ознакомился с базовыми операциями с Apache Ignite, изложенными в первой статье. В результате прочтения этих двух статей у читателя могут возникнуть какие-то предположения о том, как ему применить этот, без преувеличения, мощный продукт в своих проектах. Также статья будет полезна тем, кто интересуется построением высокопроизводительных систем, и хочет подсмотреть готовое решение для своего велосипеда.
В предыдущей статье я рассказал о том, как построить простейшую топологию для Apache Ignite. Она состояла из одного клиента и одного сервера, клиент слал на сервер сообщение и сервер его отображал. Было рассказано о том, как настроить продукт и проконтролировать его жизнедеятельность. Теперь пришло время для более сложного примера. Будет продемонстрировано построение сложной топологии и более интересные сценарии взаимодействия. Предполагается, что читатель ознакомился с базовыми операциями с Apache Ignite, изложенными в первой статье. В результате прочтения этих двух статей у читателя могут возникнуть какие-то предположения о том, как ему применить этот, без преувеличения, мощный продукт в своих проектах. Также статья будет полезна тем, кто интересуется построением высокопроизводительных систем, и хочет подсмотреть готовое решение для своего велосипеда.Настройка топологии
Напомню, что топология Ignite состоит из узлов двух типов, клиентов и серверов. Клиенты, в общем случае (но не обязательно), выполняют шлют запросы, а серверы их обрабатывают. Поведение узла определяется его конфигурацией, которая является Spring-конфигурацией для соответствующего объекта Ignite. Основные моменты, связанные с настройкой узлов, описаны в предыдущей статье. Сейчас создадим две xml-конфигурации серверного типа, отличающиеся свойством «gridName», и в прочих отношениях одинаковые. В данном примере это будут имена «testGrid-server» и «testGrid-server1». Запустим, например, два узла с первой конфигурацией и один со второй. Поскольку каждый из них будет запущен в отдельной JVM стоит озаботиться конфигурированием памяти узлов, для чего можно уменьшить значения параметров -Xms и -Xmx в ignite.bat. Запустим с помощью команды ignitevisorcmd.(bat|sh) утилиту Visor, используемую для мониторинга топологии Ignite. При запуске мы должны указать какой-то из конфигов, укажите любой, результат будет один и тот же.
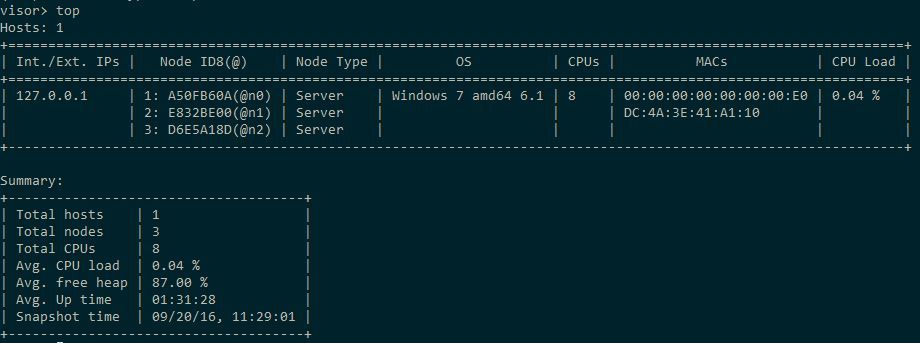
Раз у нас теперь такая сложная топология, пришло время познакомиться с главными возможностями визора. Полный список своих команд он выводит по команде help. Полный их перечень с краткими пояснениями можно увидеть на странице документации продукта. В дополнение к сказанному в документации отмечу, что к визору можно писать плагины, а сам он написан на Scala. В контексте данной статьи следует обратить внимание на команду визора config, которая выводит все значимые подробности об указанном узле. Это очень большой объём информации, поэтому я его приводить здесь не буду.
Хотя это к слову не пришлось, узлы бывают и не-Java, в настоящее время есть поддержка C++ и .NET. Также я не упомянул, что для узла можно определить обработчики жизненного цикла. Коротко говоря, есть 4 события, до/после запуска/остановки узла. Что там стоит сделать — не понятно, логирование обеспечивается стандартными средствами, возможно какие-то проверки безопасности или параметров сервера. Единственная поставляемая в составе Ignite реализация интерфейса LifecycleBean используется при инициализации .NET узлов. На первый взгляд, ничего полезного с помощью этой возможности сделать нельзя.
Подключение к серверам
В предыдущей статье мы подключались клиентом к серверу и слали сообщение «Hello World!». Немного его модифицировав код из предыдущего примера, мы будем создавать в нашем тесте два узла, клиентский и серверный; в силу способа создания они будут создаваться в одной JVM. Они конфигурируются разными xml-конфигурациями, и gridName для сервера будет «testGrid-server0». Код теста такой:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = {"/ignite/providerConfig.xml"})
public class IgniteHelloWorld {
@Autowired
@Qualifier("clientProvider")
private IgniteProvider igniteClient;
@Autowired
@Qualifier("serverProvider")
private IgniteProvider igniteServer;
@Test
public void sendHelloTest() {
try (Ignite server = igniteServer.getIgnite(); Ignite client = igniteClient.getIgnite()) {
client.compute().broadcast(() -> System.out.println("Hello World from client!"));
server.compute().broadcast(() -> System.out.println("Hello World from server!"));
}
}
}
Обратите внимание, что объекты Ignite, реализующие интерфейс AutoCloseable, по окончании использования хорошим тоном будет закрыть. Итак, у нас сейчас запущено три серверных узла через командную строку. После выполнения теста в каждой из трёх их консолей, и в консоли нашего IDE мы увидим примерно одно и то же:

К трём имеющимся серверам присоединились ещё один клиент и сервер, сказали свой привет и отключились. Каким образом обеспечивается такое поведение? Метод compute(), которым определяется группа серверов, на которых будет производиться выполнение задания, имеет две реализации. Реализация без параметров, которую мы вызываем в тесте, выглядит так:
@Override public IgniteCompute compute() {
return ((ClusterGroupAdapter)ctx.cluster().get().forServers()).compute();
}
Давайте разберёмся, что здесь происходит. На объекте ctx типа GridKernalContextImpl (слово "Kernal" разработчики используют в силу некой значимой для них традиции) вызывается метод cluster(), возвращающий объект ClusterProcessor символизирующий, судя по всему, наш узел в плане его взаимодействий с топологией. Собственно узел в виде одноэлементного кластера мы получаем дальнейшим вызовом метода get(), который нам даёт объект IgniteClusterImpl, который умеет многое. Прежде всего, строить подмножество узлов на основе применения к ним предиката, то есть некоторого условия, которое вычисляется на некотором множестве объектов и таким образом фильтрует его. В данном случае, метод forServers() возвращает предикат, возвращающий true для узлов, у которых свойство ATTR_CLIENT_MODE == false. С полным перечнем атрибутов можно ознакомиться. Помимо предикатов по атрибутам, Ignite поставляется с рядом других любопытных реализаций предикатов. Например, можно выполнять фильтрацию по содержимому кэша, с которым имеет смысл познакомить позднее, и ряд других, более экзотических.
Вооружившись этим знанием не представляет большого труда модифицировать наш тест таким образом, чтобы сообщение слалось на выбранные узлы. Для идентификации у нас есть параметр gridName, попробуем послать серверам с gridName == «testGrid-server», которых у нас 2. Выполнив вызовы
client.compute(client.cluster()
.forAttribute(ATTR_GRID_NAME, "testGrid-server")
.forServers())
.broadcast(() -> System.out.println("Hello World from client!"));
server.compute(server.cluster()
.forAttribute(ATTR_GRID_NAME, "testGrid-server1")
.forServers())
.broadcast(() -> System.out.println("Hello World from server!"));
мы получим, как и ожидалось, два сообщения от клиента и одно от сервера. Если предикат ничего вернул, будет выброшено исключение «ClusterGroupEmptyCheckedException: Cluster group is empty». Помимо forServers() есть ряд других интересных стандартных предикатов, например forRemotes(), forRandom(), forOldest() и forYoungest().
Наконец, вызов broadcast() это не единственное, что мы можем выполнить. Здесь выполнить — значит передать для исполнения объект IgniteCallable. Есть также несколько версий метода call(), который в отличие от broadcast() возвращает результат.
А что же там внутри?
Любопытно будет узнать, а как же это работает. Чтобы это узнать, произведём такой эксперимент: из нашего клиента пошлём сообщение серверу, созданному в тесте, у которого gridName == «testGrid-server0» и посмотрим в дебаге, что произойдёт. Для большей познавательности, немного изменим наш тест:
int param = 1;
Integer clientResult = client.compute(client.cluster()
.forAttribute(ATTR_GRID_NAME, "testGrid-server0")
.forServers())
.call(() -> {
System.out.println("Hello World from client!");
return param + 1;
});
Первое, что происходит при вызове метода call(), это установка read-write блокировки в нашем клиенте. Интересно, что Ignite применяет для этого собственную реализацию данного механизма в классе GridSpinReadWriteLock, основанный на sun.misc.Unsafe. С одной стороны это хорошо, разработчики Ignite заботятся о производительности, но с другой стороны что будет, когда в Java 9 Unsafe выпилят? С тревогой буду следить за развитием событий… Уже без удивления можно обнаружить, что в заботе о производительности разработчики Ignite отвергли стандартный класс java.util.concurrent.Future в пользу собственных имплементаций интерфейса IgniteFuture. Не знаю, намного ли они лучше, но очевидно одно — желающие контрибьютить в Apache Ignite должны обладать весьма глубокими познаниями в concurrency… Далее на основе нашей lambda формируется таск, который передаётся на исполнение. Эта задача доверена методу startTask класса GridTaskProcessor. Тут предусмотрена, но не реализована проверка безопасности, вероятно, это появится в следующих версиях. Следующим существенным шагом является распределённый деплоймент классов, но в эту мощную фичу мы пока вдаваться не будем, отсылаю к оригинальной документации. Напомню, что Ignite должен предпринять меры для того, чтобы исполняемый код оказался на всех узлах, в которых будет происходить исполнение задачи. Для таска может быть установлен таймаут, равный по умолчанию Long.MAX_VALUE, фактически бесконечности, его можно переопределить. Можно также настроить логирование запуска тасков. Просматриваются следы enterprise-фич — настройки балансировки нагрузки, отказоустойчивости и транзакционности, об ниже. Если в какой-то момент времени обработки таска окажется, что тот сервер или серверы, на которые замапилась задача, отвалились, то обработка прерывается с исключением. Если по дороге мы нигде не свалились, то формируется job, который передаётся диспетчеру ввода-вывода GridIoManager. Он формирует сообщение и отсылает его с помощью TcpCommunicationSpi. Напомню, что этот объект можно указать в xml-конфигурации узла, то есть мы можем повлиять на процесс отсылки сообщений, реализовав наследника TcpCommunicationSpi. Дальше тоже не просто, но наконец с использованием NIO сообщение уходит. И его получает наш сервер. И вычисляет, и похожим образом отсылает ответ. И он приходит в место вызова, в данном случае это число 2.
Управление нагрузкой
Что происходит, когда задача может быть выполнена на нескольких серверах? Мы это можем проверить, отправив запрос на сервера с gridName == «testGrid-server», которых 2. Если с учётом предикатов, информации о доступности узлов, для таска доступно более 1 узла, они перемешиваются с помощью Collections.shuffle(), и этот список передаётся стандартному балансировщику нагрузки, которому надо выбрать из имеющихся в его распоряжении узлов 1. И вот тут наступает интересное. Если вы оставили всё по-умолчанию, то будет использован алгоритм Round-Robbin, предоставляемый классом RoundRobinLoadBalancingSpi. Этот SPI (в Ignite все подключаемые алгоритмы называются SPI) итерирует по узлам способом round-robin и выбирает последовательно следующий узел. Доступно два режима работы, позадачный и глобальный, устанавливаемые вызовом setPerTask(boolean). Если выбран позадачный режим, SPI выбирает в начале выполнения таска узел случайным образом, а потом циклически перебирает по мере выполнения задач (в нашем случае задача одна, но на исполнение может быть передан список задач). По умолчанию используется именно этот подход. В глобальном режиме для всех задач используется общая последовательная очередь узлов. Понятно, что выбор алгоритма в этом месте может повлиять на распределение нагрузки между узлами. Помимо Round-Robbin балансировщика доступно ещё два: адаптивный, который учитывает производительно узлов на основе настраиваемой метрики, которой по умолчанию является загрузка CPU сервера узла, и случайный выбор на основе весов узлов, которые можно указать при конфигурировании (по умолчанию все они равны 10). Наконец, можно написать свой собственный, реализовав соответствующий интерфейс. Указать балансировочные SPI можно в xml-конфиге узла (вот тут я немного не понял, их можно указать список, как тогда происходит балансировка, кто именно балансирует? Судя по коду, имена классов слепливаются в строку, и потом SPI инстанциируется по имени класса. Как это может работать? Судя по намёкам в Javadoc's, это заработает с версии 2.1.)
Помимо балансировки, у разработчика есть возможность управлять ещё двумя enterprise-level фичами. Можно контролировать отказоустойчивость с помощью Failover SPI. К числу причин, когда это может понадобиться, относятся ошибка в процессе выполнения задачи, выпадение целевого узла из топологии и отказ узла от исполнения задачи. Задачей SPI этого типа является предоставить узел взамен бракованного. Из коробки предоставляется три имплементации: NeverFailoverSpi, которая никогда ничего не возвращает, и две более хитрые — AlwaysFailoverSpi и JobStealingFailoverSpi. AlwaysFailoverSpi даёт узлу несколько попыток (по умолчанию 5, можно переопределить), прежде чем предложить другой узел. При этом учитывается привязка задачи к узлу (affinity) — если задача привязана, то после заданного числа попыток происходит падение, если нет, то с учётом данных балансировщика выбирается новый узел, а бракованный помещается в чёрный список. Число попыток и чёрный список узлов хранится в контексте задачи. JobStealingFailoverSpi ещё более хитрый, и его мы рассматривать не будем. Список Failover SPI также можно указать в конфиге. Если ничего не указано, по умолчанию создаётся AlwaysFailoverSpi.
И последний SPI из этой серии, Checkpoint SPI, как не трудно догадаться, предназначен для создания точек сохранения (чекпойнтов), то есть промежуточных точек при выполнении длительной или сложной задачи. Этот тип SPI предоставляет API, с помощью которого можно сохранить, удалить и загрузить чекпойнт. Этим API, по задумке авторов Ignite, должна пользоваться только система. но технически эта возможность не закрыта и для прикладных разработчиков. В пугающие недра этой фичи мы погружаться не будем, по умолчанию подключена имплементация, которая ничего не делает.
Поиски следов
Напоследок давайте попробуем отыскать следы всех этих вызовов. В Ignite предусмотрено тотальное логирование. Если вы ничего не сделаете для изменения положения дел по-умолчанию, будет создан дефолтный логгер, который будет писать сообщения в консоль. Это обычное Java логирование, для настройки которого можно создать конфиг config/java.util.logging.properties. Если вас это не устраивает, можно имплементировать интерфейс IgniteLogger и подключить его через xml-конфиг.
А ещё можно спросить визор. С помощью команды node можно запросить детальную статистику по узлу (если вы знаете по какому спрашивать, а вы можете знать, поскольку мы добавили вывод в консоль нашему вычислению). В результате вы можете увидеть примерно такую статистику после нескольких запусков:
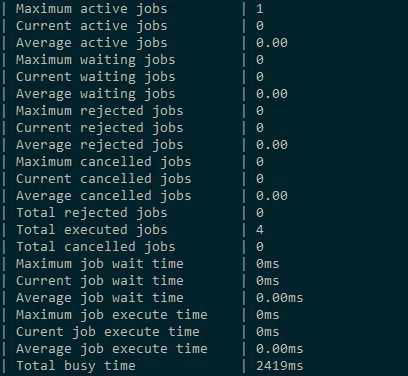
Однако о мониторинге топологии я, возможно, расскажу в другой раз.
Выводы
Достаточно очевидно, что внутри Ignite находятся хорошие, годные внутренности. Интуитивно понятно, что на основе узлов Ignite можно построить достаточно интересные решения масштаба крупного предприятия или, как минимум, позаимствовать из него интересные идеи. Надеюсь, что после прочтения данной статьи у читателя сформировалось представление, как с помощью предоставляемых Ignite средств можно выстроить реально сложную, жизненную топологию.
Ссылки
» Код тестового примера на GitHub
