Пару дней назад появилась статья, которую почти никто не освещал. На мой взгляд, она замечательная, поэтому про неё расскажу в меру своих способностей. Статья о том, чего пока не было: машину научили играть в шутер, используя только картинку с экрана. Вместо тысячи слов:
Не идеально, но по мне — очень классно. 3D шутер, который играется в реальном времени — это впервые.
Подход, который применили — пересекается и с тем, как сделали бота, играющего в GO, и с тем как проходили игры Atari. По сути это «Deep reinforcement learning». Наиболее подробная статья на эту тему на русском, пожалуй здесь.
В двух словах. Пусть есть некоторая функция Q(s,a). Эта функция определяет профит, который вернёт наша система от выполнения действия a в состоянии s. Нейронную сеть обучают так, чтобы на выходах она давала аппроксимацию функции Q. В результате мы знаем цену любого действия в каждой ситуации. Чтобы понять более подробно лучше читать один из приведённых выше текстов.
Классический подход, который применялся в играх Atari для 3D-шутеров не работает. Слишком много информации, слишком много неопределённости. В играх Atari оптимальное действие можно было выполнить по последовательности из 3-4 кадров, чем там широко и пользовались, подавая их на вход. В Alpha Go авторы пользовались дополнительной системой, которая ходила и перебирала оптимальные варианты по правилам Go.
Как же авторы справились тут? Ведь не будешь прогать свой внутренний движок? Оказывается, всё очень просто и интересно. Глобально, было сделано 3 улучшения:
Теперь чуть поподробнее.
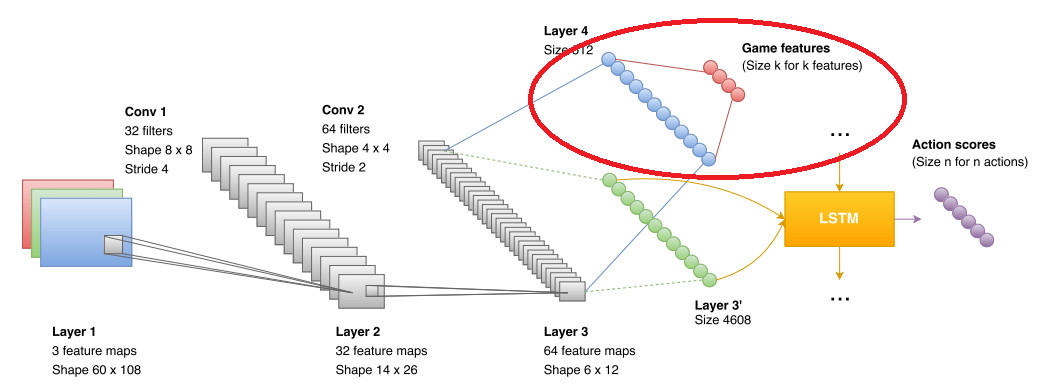
Когда человек впервые садиться за DOOM, то ему говорят: это плохой монстр, его нужно убить. У человека есть понимание что такое монстр => он быстро осваивается. Нейронная сеть никогда не видела монстра. Никогда не видела аптечки и никогда не видела бочки. Она не умеет отличать одно от другого.
Глубокое обучение с подкреплением подразумевает, что учиться система должна только по своей целевой функции. Но зачастую это невозможно. Нельзя по целевой функции понять, что массив движущихся пикселей — это враг. Ну, можно, но долго и муторно. Человек имеет априорную информацию. Нужно и в сеть её загрузить.
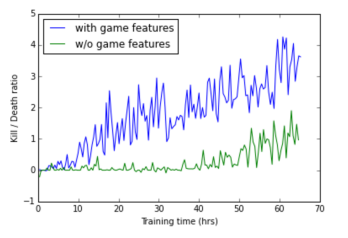
Поэтому авторы ввели дополнительный блок, который используется при обучении. В блок они подают что видит сеть (на рисунке отмечен красным эллипсом). Формат данных — boolean в стиле «вижу монстра», «вижу аптечку», «вижу амуницию». В результате свёрточная сеть явно тренируется распознавать врагов, аптечки и амуницию. В фазе игры этот блок никак не используется. Точнее используется, но об этом чуть ниже. А вот на сколько фичи повышают точность сети:

LSTM — это такая рекуррентная сеть, которая неплохо может объединять данные, которые получает свёрточная сеть. В оригинальных статьях по Atari и по Alpha GO, таких сетей не было, но их уже использовали в других DQR проектах (например, с теми же играми Atari). Так что ничего особо нового тут не было.
И опять, авторы упёрлись в неприятный момент. Рекуррентная сеть обеспечивала анализ данных и прогноз где-то на протяжении нескольких секунд (в работе обучают последовательностями длинной примерно 10 кадров, где кадр берётся несколько раз в секунду (1/5 fps, fps не указаны)). Более глобальные прогнозы для неё были неточны. Кроме того, сеть сложно обучить понятию «у нас скоро кончатся патроны, хорошо бы начинать что-то искать». В результате авторы извернулись и сделали две независимых сети. Одна сеть умела искать аптечки и патроны. Вторая делать фраги.
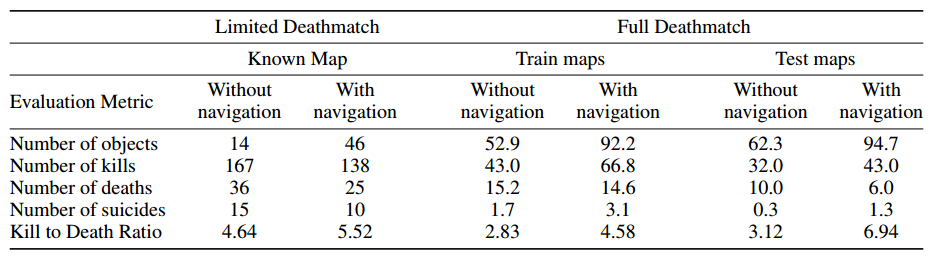
Переключение осуществляется за счёт того самого «выделения монстров», которая сеть генерит из-за особенностей обучения. Если монстров не видно, то используются решения «исследовательской сети», после появления монстра решения «боевой». Эффект от введения исследовательской сети:
Кстати, исследовательская сеть убивает у бота «кемперское поведение», которое свойственно «боевой».
Исследовательской сети при обучении выписывали плюсы за пройденное расстояние.
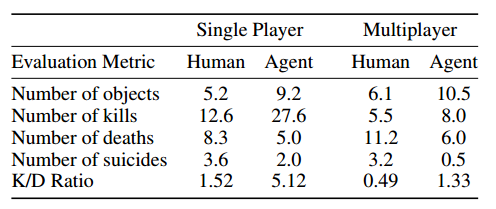
Человека сеть побеждает с неплохим отрывом. По-моему это главное.
По DQN я не специалист, возможно что-то не идеально рассказал. Было бы интересно послушать мнение специалистов. Но подборка методов, а в особенности результат меня очень впечатлили.
P.S. Ещё несколько примеров кровавого обучения:
*СР УВЧ!
Не идеально, но по мне — очень классно. 3D шутер, который играется в реальном времени — это впервые.
Подход, который применили — пересекается и с тем, как сделали бота, играющего в GO, и с тем как проходили игры Atari. По сути это «Deep reinforcement learning». Наиболее подробная статья на эту тему на русском, пожалуй здесь.
В двух словах. Пусть есть некоторая функция Q(s,a). Эта функция определяет профит, который вернёт наша система от выполнения действия a в состоянии s. Нейронную сеть обучают так, чтобы на выходах она давала аппроксимацию функции Q. В результате мы знаем цену любого действия в каждой ситуации. Чтобы понять более подробно лучше читать один из приведённых выше текстов.
Классический подход, который применялся в играх Atari для 3D-шутеров не работает. Слишком много информации, слишком много неопределённости. В играх Atari оптимальное действие можно было выполнить по последовательности из 3-4 кадров, чем там широко и пользовались, подавая их на вход. В Alpha Go авторы пользовались дополнительной системой, которая ходила и перебирала оптимальные варианты по правилам Go.
Как же авторы справились тут? Ведь не будешь прогать свой внутренний движок? Оказывается, всё очень просто и интересно. Глобально, было сделано 3 улучшения:
- При обучении использовалась некоторая дополнительная информация от движка
- Использовалась LSTM на выходе CNN
- Обучалось две сети: «Исследовательская» и «Боевая»
Теперь чуть поподробнее.
Информация от движка
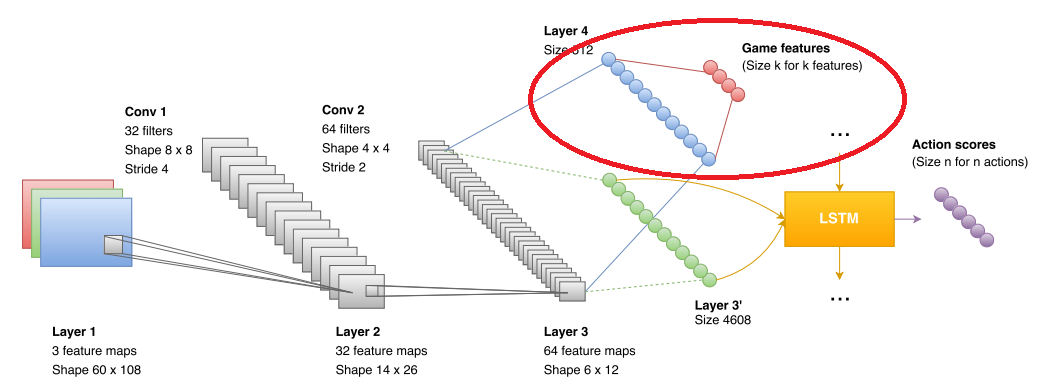
Когда человек впервые садиться за DOOM, то ему говорят: это плохой монстр, его нужно убить. У человека есть понимание что такое монстр => он быстро осваивается. Нейронная сеть никогда не видела монстра. Никогда не видела аптечки и никогда не видела бочки. Она не умеет отличать одно от другого.
Глубокое обучение с подкреплением подразумевает, что учиться система должна только по своей целевой функции. Но зачастую это невозможно. Нельзя по целевой функции понять, что массив движущихся пикселей — это враг. Ну, можно, но долго и муторно. Человек имеет априорную информацию. Нужно и в сеть её загрузить.
Поэтому авторы ввели дополнительный блок, который используется при обучении. В блок они подают что видит сеть (на рисунке отмечен красным эллипсом). Формат данных — boolean в стиле «вижу монстра», «вижу аптечку», «вижу амуницию». В результате свёрточная сеть явно тренируется распознавать врагов, аптечки и амуницию. В фазе игры этот блок никак не используется. Точнее используется, но об этом чуть ниже. А вот на сколько фичи повышают точность сети:
LSTM
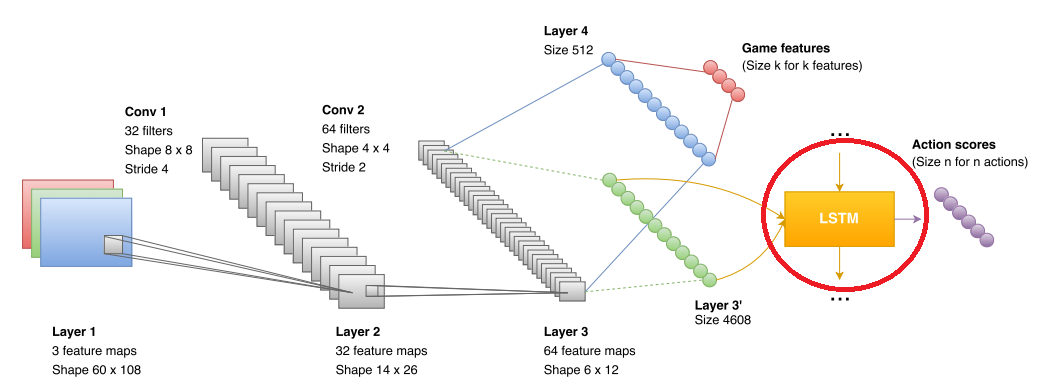
LSTM — это такая рекуррентная сеть, которая неплохо может объединять данные, которые получает свёрточная сеть. В оригинальных статьях по Atari и по Alpha GO, таких сетей не было, но их уже использовали в других DQR проектах (например, с теми же играми Atari). Так что ничего особо нового тут не было.
Две сети
И опять, авторы упёрлись в неприятный момент. Рекуррентная сеть обеспечивала анализ данных и прогноз где-то на протяжении нескольких секунд (в работе обучают последовательностями длинной примерно 10 кадров, где кадр берётся несколько раз в секунду (1/5 fps, fps не указаны)). Более глобальные прогнозы для неё были неточны. Кроме того, сеть сложно обучить понятию «у нас скоро кончатся патроны, хорошо бы начинать что-то искать». В результате авторы извернулись и сделали две независимых сети. Одна сеть умела искать аптечки и патроны. Вторая делать фраги.
Переключение осуществляется за счёт того самого «выделения монстров», которая сеть генерит из-за особенностей обучения. Если монстров не видно, то используются решения «исследовательской сети», после появления монстра решения «боевой». Эффект от введения исследовательской сети:
Кстати, исследовательская сеть убивает у бота «кемперское поведение», которое свойственно «боевой».
Исследовательской сети при обучении выписывали плюсы за пройденное расстояние.
Что в итоге вышло
Человека сеть побеждает с неплохим отрывом. По-моему это главное.
По DQN я не специалист, возможно что-то не идеально рассказал. Было бы интересно послушать мнение специалистов. Но подборка методов, а в особенности результат меня очень впечатлили.
P.S. Ещё несколько примеров кровавого обучения:
*СР УВЧ!
