Сколько нужно времени, чтобы просто вывести на экран большой список, используя современные фреймворки?
| Список на 2000 строк | ReactJS | AngularJS | Raw HTML | SAPUI5 | $mol |
|---|---|---|---|---|---|
| Появление списка | 170 ms | 420 ms | 260 ms | 1200 ms | 50 ms |
| Обновление всех его данных | 75 ms | 75 ms | 260 ms | 1200 ms | 10 ms |
Напишем нехитрое приложение — личный список задач. Какие у него будут характеристики?
| ToDoMVC | ReactJS | AngularJS | PolymerJS | VanillaJS | $mol |
|---|---|---|---|---|---|
| Размер ( html + js + css + templates ) * gzip | 322 KB | 326 KB | 56 KB | 20 KB | 23 KB |
| Время загрузки | 1.4 s | 1.5 s | 1.0 s | 1.7 s | 0.7 s |
| Время создания и удаления 100 задач | 1.3 s | 1.7 s | 1.4 s | 1.6 s | 0.5s |
Небольшая головоломка: перед вами синхронный код, загружающий и обрабатывающий содержимое 4 файлов, но с сервера они грузятся параллельно. Как такое может быть?
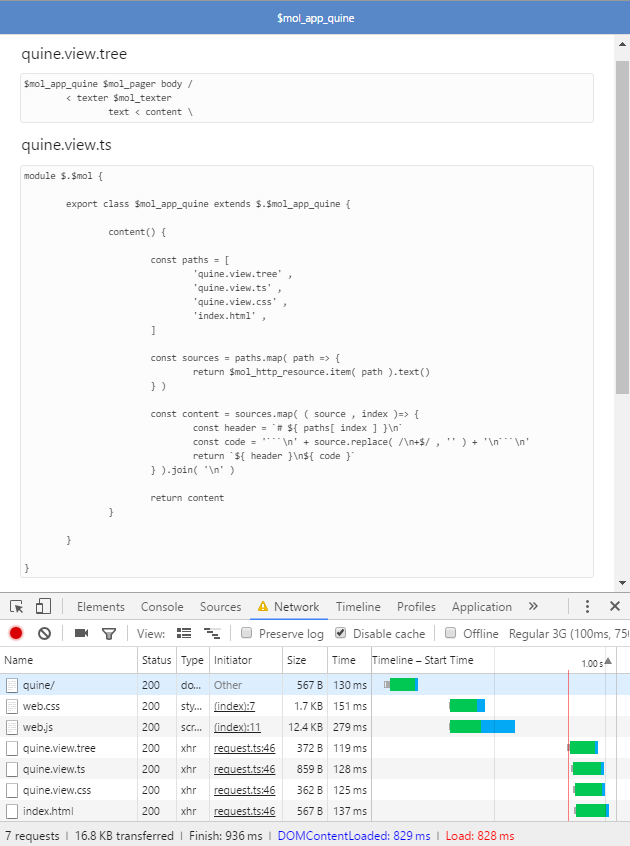
А теперь прошу за мной в кроличью нору, настало время удивительных историй...
Клуб именованных велосипедистов
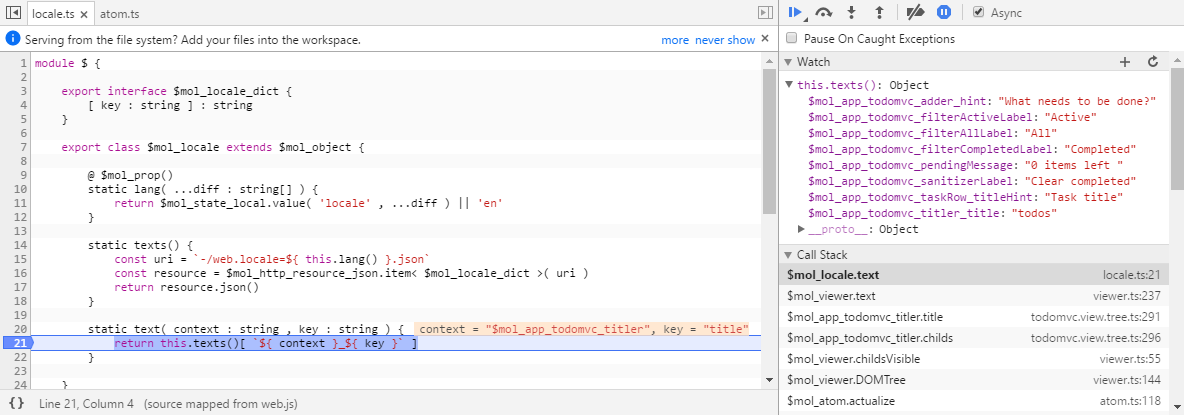
Здравствуйте, меня зовут Дмитрий Карловский и я… руководитель группы веб-разработки компании SAPRUN. Наша компания занимается преимущественно внедрением и поддержкой продуктов SAP в ведущих компаниях России и ближнего зарубежья. Сам SAP — огромная сложная система, состоящая из множества компонент.
Один из таких компонент — веб фреймворк SAPUI5, предназначенный для создания одностраничных приложений. Это — типичный представитель коробочных фреймворков, то есть таких, которые предоставляют вам не только архитектуру, но и богатую библиотеку виджетов. И как любой коробочный фреймворк, данный подвержен страшной болезни современности — ожирению.

Проявляется ожирение во всём: огромные объёмы кода из изысканной немецкой пасты; неповоротливые виджеты, еле-еле двигающие списки на 100 элементов; развесистые деревья классов, в дебрях которых заблудится даже лесной эльф. Всё это приводит к достаточно длительной разработке, а время — деньги.
В результате, довольно сложно выигрывать тендеры на разработку веб приложений, если указываешь реальные временные оценки. А если и выигрываешь, то результат, скажем так, не впечатляет: приложение получается либо слишком простым, либо слишком тормозным. Особенно всё печально на смартфонах, где каждый киловатт на счету.
Нам требовался более эффективный инструмент, позволяющий малой кровью создавать конкурентоспособные масштабные кроссплатформенные приложения, поэтому мы решились на страшное — переизобрести колесо — собственный веб фреймворк с говорящим названием $mol. Разработанный с нуля, он вобрал в себя множество свежих идей, о которых и пойдёт дальнейшее повествование.
Реактивное программирование
Изобретённое 50 лет назад, оно только недавно добралось до мира пользовательских интерфейсов в вебе. Причём добралось в достаточно куцем "push" виде: вы описываете некоторую последовательность действий, на вход подаёте некоторые данные, и эти действия, последовательно применяются к каждому элементу данных. Однако, такой подход приводит ко сложностям при реализации ленивых и динамически меняющихся вычислений.
$mol же построен на "pull" архитектуре, где инициатором любых действий выступает потребитель результата этих действий, а не источник данных. Это позволяет рендерить лишь те части приложения, что попадают в видимую область; создавать лишь те объекты, что требуются для рендеринга в текущий момент; запрашивать с сервера лишь те данные, что требуются для созданных объектов.
$mol насквозь пропитан "ленивыми вычислениями" и автоматическим освобождением ресурсов. Вы можете всего одной строчкой закешировать результат выполнения функции и не беспокоиться об инвалидации и очистке этого кеша — модуль $mol_atom сам отследит все зависимости и выполнит всю рутинную работу.
const source = new $mol_atom( 'source' , ( next? : number )=> next || Math.ceil( Math.random() * 1000 ) )
const middle = new $mol_atom( 'middle' , ()=> source.get() + 1 )
const target = new $mol_atom( 'target' , ()=> middle.get() + 1 )
console.assert( target.get() === source.get() + 2 , 'Target must be calculated from source!' )
console.assert( target.get() === target.get() , 'Value must be cached!' )
source.push( 10 )
console.assert( target.get() === 12 , 'Target value must be changed after source change!' )Тут в момент изменения source происходит инвалидация значения middle и target, так что при запросе значения target происходит вычисление его актуального значения, как бы далеко друг от друга source и target в программе ни находились.
Синхронное программирование
Нет ничего проще, чем синхронное программирование. Код получается коротким, понятным и вы можете свободно использовать все возможности языка по управлению потоком исполнения (if, for, while, switch, case, break, continue, throw, try, catch, finally).
К сожалению, JS — однопоточный язык, поэтому, для обеспечения конкурентного исполнения множества задач, код приходится писать асинхронный, что порождает множество проблем: начиная лапшой из мелких функций и заканчивая ненадёжной обработкой исключительных ситуаций. node-fibers позволяет писать синхронный код не блокируя системный поток, но работает только в NodeJS. async/await/generators позволяют создавать асинхронные функции, которые могут вызывать друг друга синхронно, но из-за несовместимости с обычными синхронными функциями, приходится чуть ли не все функции делать асинхронными. Кроме того, для них требуется специальная поддержка со стороны браузера или транспиляция в адскую машину состояний.
Модель реактивности же, используемая в $mol, позволяет элегантно абстрагировать код от асинхронности. Посмотрите, например, на исходный код Куайна из начала статьи:
content() {
const paths = [
'/mol/app/quine/quine.view.tree' ,
'/mol/app/quine/quine.view.ts' ,
'/mol/app/quine/quine.view.css' ,
'/mol/app/quine/index.html' ,
]
const sources = paths.map( path => {
return $mol_http.resource( path ).text()
} )
const content = sources.map( ( source , index )=> {
const header = `# ${ paths[ index ] }\n`
const code = '```\n' + source.replace( /\n+$/ , '' ) + '\n```\n'
return `${ header }\n${ code }`
} ).join( '\n' )
return content
}Тут вы видите вполне себе синхронную генерацию содержимого страницы. Однако, системный поток не блокируется, а загрузка всех 4 файлов происходит параллельно. При этом, пока идёт загрузка данных, вместо них выводится индикатор загрузки. Формируется он автоматически, избавляя разработчика и от этой головной боли тоже.
Компонентное программирование
Разбиение приложения на компоненты позволяет разделять одну большую задачу, на задачи поменьше. Компоненты могут быть реализованы разными людьми одновременно, после чего собраны вместе. Поэтому важно, чтобы компоненты с одной стороны были самодостаточны, а с другой — очень гибко настраиваемы.
Конструктор LEGO содержит множество самых разнообразных деталей, но любые из них стыкуются вместе благодаря стандартизированному соединительному интерфейсу. В $mol в роли такого интерфейса выступают свойства. Когда родительский компонент создаёт дочерний, он переопределяет у того ряд свойств, настраивая его поведение под свои требования. А благодаря реактивности, риск что-либо непреднамеренно сломать в дочернем компоненте — минимален.
Вы можете легко и просто заменить какое-либо свойство моком, чтобы протестировать логику работы компонента; задать всем свойствам константные значения для проверки вёрстки; указать дочернему компоненту использовать какое-либо свойство родительского, и связать через него несколько дочерних компонент вместе.
Родительский компонент имеет полный контроль над дочерними, что позволяет делать компоненты очень простыми, без необходимости реализации всех возможных сценариев с огромными конфигами для их настройки.
В примере с Куайном используется компонент $mol_pager, рисующий типичную страничку с заголовком в шапке, скроллящимся телом и подвалом:
$mol_page $mol_view
sub /
<= Head $mol_view
sub <= head /
<= Title $mol_view
sub /
<= title -
<= Body $mol_scroll
sub <= body /
< Foot $mol_view
sub <= foot /Но на базе него вы можете создать новый компонент, который в шапку добавляет иконку, тело заменяет компонентом из родителя, а подвал вообще удаляет:
$mol_app_quine $mol_page
head /
<= Logo $mol_icon_refresh
<= Title -
body /
<= Text $mol_text
text <= content \
Foot nullС голой грудью на амбразуру
Представьте, что вам достался старый проект, о котором вы слышали ровным счётом ничего. Всё, что у вас есть — репозиторий с исходными кодами. Документации либо нет, либо она уже давно потеряла былую актуальность. А вам нужно починить какой-нибудь назойливый баг. Ещё вчера.
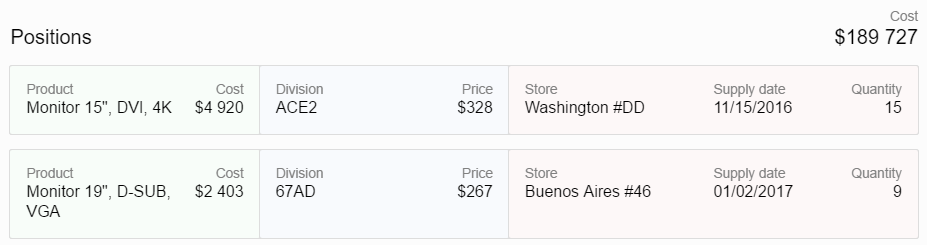
Допустим, перед вами вот это не хитрое приложение:
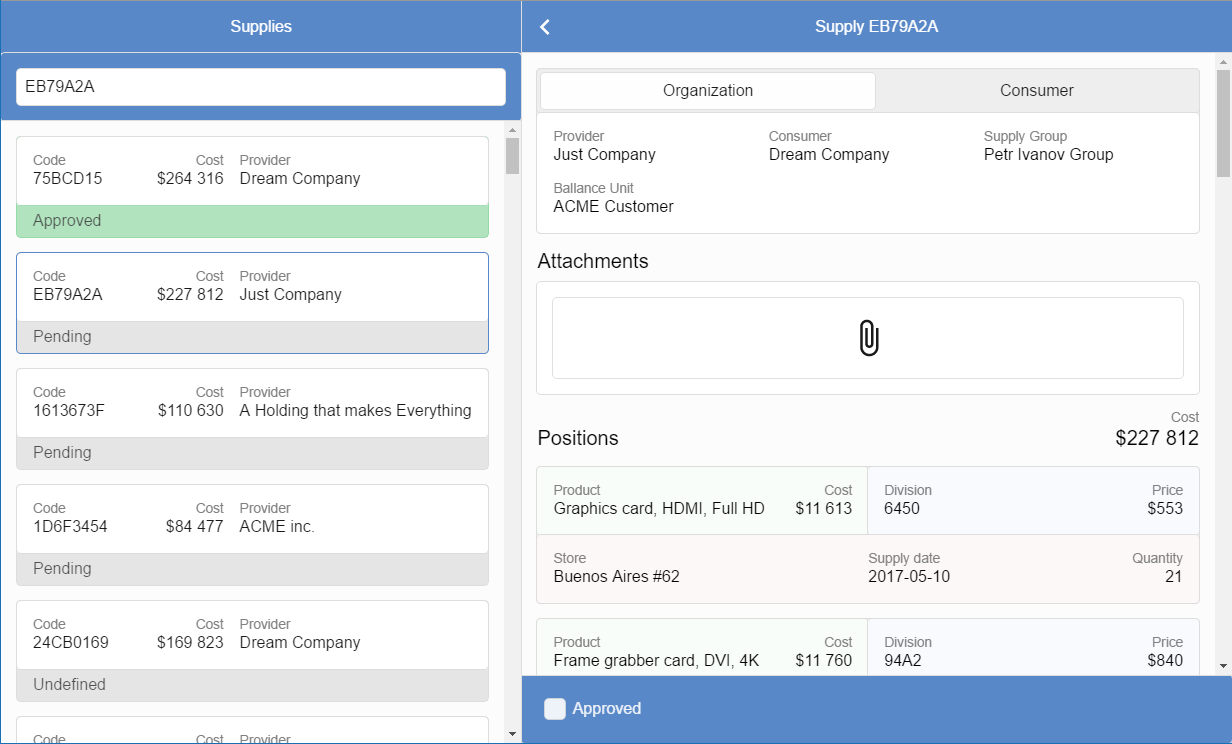
Тут слева вы видите список заявок на закупки, а справа — подробности по выбранной заявке: кому, что, когда и на какую сумму. И всё бы хорошо, да вот только дата поставки выводится в формате ISO8601 "YYYY-MM-DD", а не в привычном для целевой аудитории "MM/DD/YYYY". Кто мы такие, чтобы навязывать заказчику международные стандарты? Нет, так дело не пойдёт и нужно срочно исправить, но с чего начать, куда копать?
Единственная зацепка — DOM элемент, куда выводится дата. Возможно DOM инспектор сможет помочь найти какие-либо зацепки, которые позволят вам выйти на исполнителя:

Что за больной психопат мог придумать столь длинные идентификаторы элементам? И почему они такие странные? Словно бы являются JS кодом… А что если..
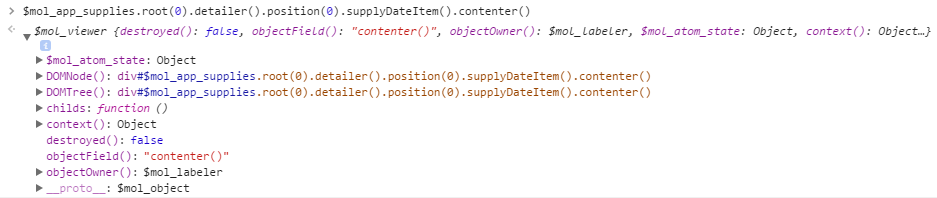
Скопировав идентификатор в консоль вы с удивлением обнаруживаете, что данный код не просто рабочий, но и возвращает какой-то объект, подозрительно напоминающий визуальный компонент: он является экземпляром класса $mol_viewer и хранит в себе ссылку на DOM элемент с которого вы и начали своё расследование.
Тут вы подмечаете, странную закономерность: все поля именуются либо нормально, но хранят в себе функции, либо хранят не функции, но именуются со скобками в конце. Похоже, это ружьё тут тоже висит не просто так — вы пробуете вызвать у объекта метод objectOwner() и получаете ожидаемый результат — ссылку на компонент выше по иерархии:
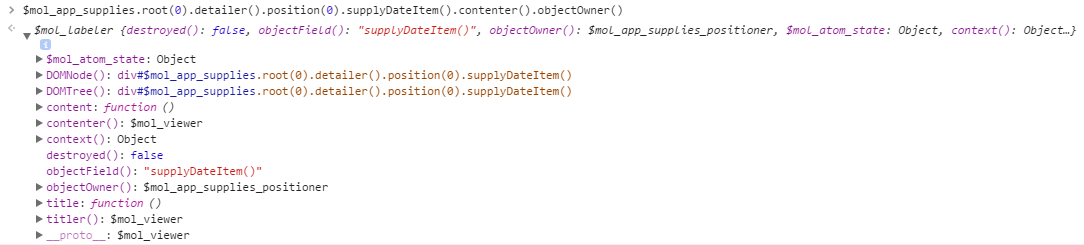
Уже лучше ориентируясь в происходящем, вы возвращаетесь к жертве неправильной локализации и окидываете взглядом её немногочисленные поля, ни одно из которых не содержит заветной даты. Ваше внимание привлекает поле с говорящим названием childs, которое содержит некую функцию возвращаемым значением которой может быть именно то, что вы ищите.

Ага! У вас есть подозреваемый. Щёлкнув правой кнопкой по функции вы в два счёта находите место её определения:
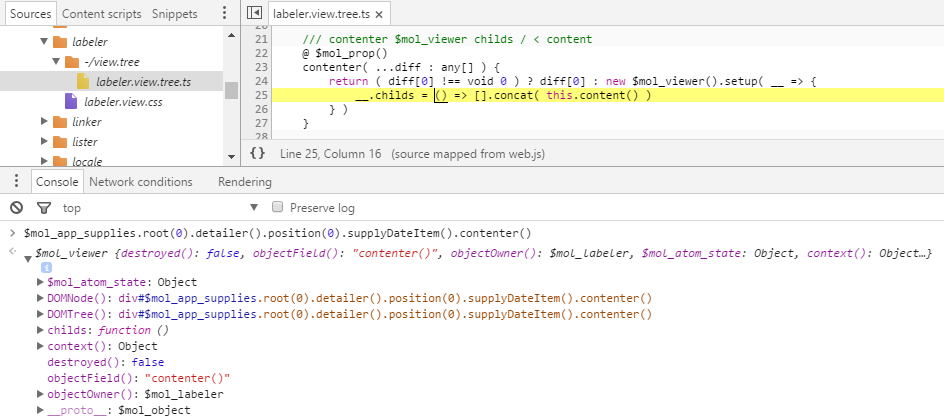
Перед вами код создания вложенного компонента, явно сгенерированный роботом. На это указывает странный путь к файлу и короткий комментарий, судя по всему, послуживший исходником для генератора. А найденная вами функция childs — не более чем посредник, передающий управление функции content компонента-владельца. Продолжая движение по цепочке улик, вы поднимаетесь всё выше, распутывая клубок интриг в высших эшелонах власти, пока, наконец, не выходите на истинного преступника под именем $mol_app_supplies.root(0).detailer().position(0).supplyDate():
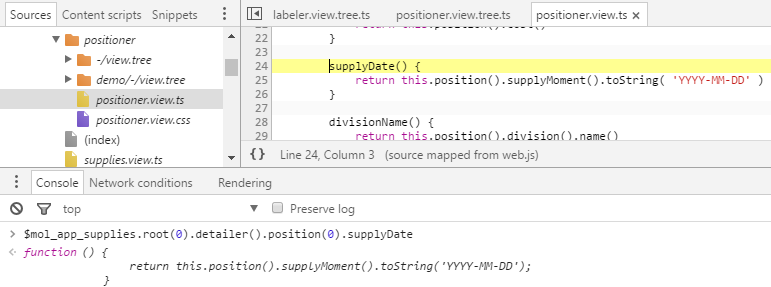
Дело за малым — направиться по указанному адресу, внести необходимые изменения и проверить их. Но с чего начать, куда копать?
Вы выкачиваете репозиторий и обнаруживаете в корне проекта package.json. Логично предположить, что это NodeJS проект, а значит нужно установить зависимости:
> npm install --depth 0
Type 'npm start' to start dev server or 'npm start {relative/path}' to build some package.
.
+-- body-parser@1.15.2
+-- compression@1.6.2
+-- concat-with-sourcemaps@1.0.4
+-- express@4.14.0
+-- mam@1.0.0
+-- portastic@1.0.1
+-- postcss@5.2.4
+-- postcss-cssnext@2.8.0
+-- source-map-support@0.4.3
`-- typescript@2.0.3Зависимостей не очень много, так что ставятся они все в течении минуты. Вы подмечаете, что в проекте активно используется транспиляция: скрипты пишутся на typescript, стили обрабатываются postcss, а для отладчика генерируются source-maps.
Cудя по подсказке, для запуска локального сервера, нужно выполнить очевидную команду:
> npm start
22:23 Built mol/build/-/node.deps.json
22:23 Built mol/build/-/node.js
22:23 Built mol/build/-/node.test.js
$mol_build.root(".").server() started at http://127.0.0.1:8080/Дальнейшие шаги не менее очевидны — открытие указанного адреса приводит вас к списку пакетов вида:
Вы идёте вглубь по пространствам имён, пока не попадаете на нужное приложение. Подозревая, что в рамках одного проекта может существовать множество приложений, вы проверяете другие пути и убеждаетесь, что это действительно так.
При этом вы подмечаете, что первое открытие приложения происходит несколько секунд, а повторные заходы уже отрабатывают мгновенно. Что за тормоза на пустом месте? Открытие консоли проясняет ситуацию:
$mol_build.root(".").server() started at http://127.0.0.1:8080/
mol> git fetch & git log --oneline HEAD..origin/master
> git fetch & git log --oneline HEAD..origin/master
jin> git fetch & git log --oneline HEAD..origin/master
23:00:23 Built mol/app/supplies/-/web.css
23:00:27 Built mol/app/supplies/-/web.js
23:00:27 Built mol/app/supplies/-/web.locale=en.json
23:00:41 Built mol/app/todomvc/-/web.css
23:00:45 Built mol/app/todomvc/-/web.js
23:00:45 Built mol/app/todomvc/-/web.locale=en.jsonАга, при первом заходе в приложение происходит сборка пакетов для него. Все скрипты в один файл, все стили — в другой, тексты — в третий. Вы перезапускаете сервер, открываете браузер и проверяете эту теорию:
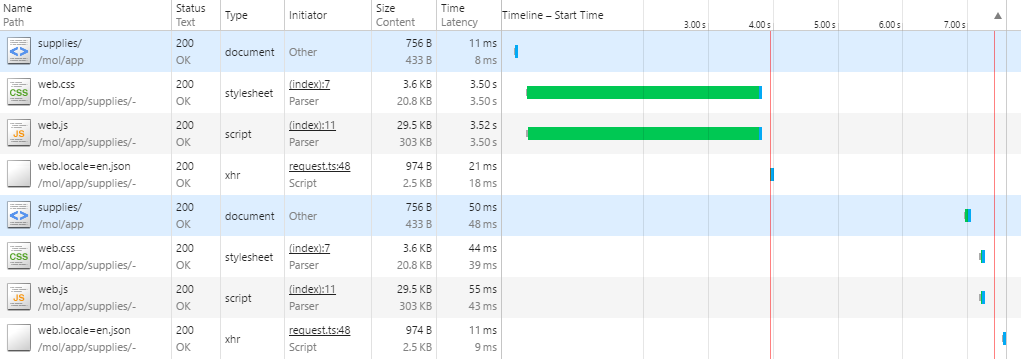
Так и есть — грузятся всего 4 файла, причём, подозрительно малого объёма в сравнении с другими популярными фреймворками: все скрипты умещаются в 30 килобайт с учётом сжатия. Чёрная магия, не иначе. В 30 килобайт даже отдельно взятая jQuery не помещается, а ведь эта библиотека — основа большинства фреймворков. Вы смотрите в сгенерированный пакет web.js и офигеваете ещё сильнее, ведь код даже не минифицирован! Совсем ничего святого!
Что ж, хватит развлекаться, пора провести исправительные работы. Вы открываете positioner.view.ts и видите там следующую картину:
namespace $.$mol {
export class $mol_app_supplies_position extends $.$mol_app_supplies_position {
position() {
return null as $mol_app_supplies_domain_supply_position
}
product_name() {
return this.position().name()
}
price() {
return this.position().price()
}
quantity() {
return this.position().quantity().toString()
}
cost() {
return this.position().cost()
}
supply_date() {
return this.position().supply_moment().toString( 'YYYY-MM-DD' )
}
division_name() {
return this.position().division().name()
}
store_name() {
return this.position().store().name()
}
}
}Как-то бедновато. Где лапша? Где фрикадельки? Всё, что делают эти 8 методов — это преобразуют хитросплетения данных доменной модели в свойства модели интерфейсной. Чтобы понять как данные выводятся, вы идёте по единственному видимому отсюда пути — зажимаете CTRL и щёлкаете по базовому классу, что приводит вас к тому самому генерированному коду, расположенному во '-/view.tree/positioner.view.tree.ts':
/// $mol_app_supplies_position $mol_card
namespace $ { export class $mol_app_supplies_position extends $mol_card {
/// heightMinimal 68
height_minimal() {
return 68
}
/// productLabel @ \Product
product_label() {
return this.text( "product_label" )
}
/// productName \
product_name() {
return ""
}
/// product_item $mol_labeler
/// title <= product_label
/// content <= product_name
@ $mol_mem()
product_item( next? : any , prev? : any ) {
return ( next !== undefined ) ? next : new $mol_labeler().make({
title : () => this.product_label() ,
content : () => this.product_name() ,
} )
}
// ...И тут куча мелких функций. Ни тебе обработчиков событий, ни создания DOM-элементов. Видя рядом расположенные куски исходного файла и сгенерированный код, вы быстро начинаете понимать этот птичий синтаксис:
- При объявлении компонента сначала указывается имя его класса, а потом имя базового класса.
- Внутри объявления комбинация имени и значения создают функцию, которая возвращает это значение.
- В качестве значения можно указать число, либо строку, если предварить её "обратной косой чертой". Эта черта ассоциируется у вас с экранированием данных. По всей видимости всё, что идёт после неё не будет разбираться генератором, а будет вставлено как строка.
- Если поставить "собачку", то текст пропадёт из кода, а вместо него будет вставлено получение его по ключу. По всей видимости именно на этом и основана генерация файла с текстами, которую вы подметили, когда игрались со сборкой проекта.
- В качестве значения можно указать имя другого компонента и тогда функция будет возвращать соответствующий экземпляр. При этом можно перегрузить свойства вложенного компонента, своими свойствами. Угловая скобка, очевидно, показывает направление движения данных.
Вроде бы всё просто, но не понятно только зачем было вводить какой-то свой формат, если то же самое в typescript занимает не сильно больше места. Вы открываете исходный positioner.view.tree в надежде увидеть там что-то ещё.
$mol_app_supplies_position $mol_card
height_minimal 68
content <= Groups $mol_view sub /
<= Main_group $mol_row sub /
<= product_item $mol_labeler
title <= product_label @ \Product
content <= product_name \
<= cost_item $mol_labeler
title <= cost_label @ \Cost
content <= Cost $mol_cost
value <= cost $mol_unit_money
valueOf 0
- ...И действительно — существенное отличие в том, что во view.tree иерархия вложенных компонент представлена наглядно, что позволяет быстро в них ориентироваться, но генерируемый класс получается вполне себе плоским, предоставляя доступ к любому вложенному компоненту за один вызов метода.
Воодушевлённый тем, как легко вы распутываете клубок внутренней архитектуры, вы берётесь за правки. Можно было бы просто поменять формат вывода в функции supplyDate и на этом закрыть дело:
supply_date() {
return this.position().supply_moment().toString( 'MM/DD/YYYY' )
}Но это бы лишь отсрочило решение настоящей проблемы — формат не зависит от установленной локали. А ведь чуть раньше вы выяснили, что локализация текстов уже вполне себе поддерживается. Вы возвращаетесь к positioner.view.tree.ts:
/// product_label @ \Product
product_label() {
return this.text( "product_label" )
}Погрузившись в text() вы доходите до места, где задаётся язык:
export class $mol_locale extends $mol_object {
@ $mol_mem()
static lang( next? : string ) {
return $mol_state_local.value( 'locale' , next ) || 'en'
}Ага, чтобы получить текущий язык, нужно выполнить:
$mol_locale.lang()Вы выполняете этот код в консоли и убеждаетесь, что он действительно работает.
Осталось создать функцию, которая бы по идентификатору языка возвращала формат представления даты. Но где её разместить? Нужно создать отдельный модуль.
По аналогии с другими модулями вы создаёте новый по адресу mol/dateFormat/dateFormat.ts со следующего вида содержимым:
namespace $ {
export const $mol_dateFormat_formats : { [ key : string ] : string } = {
'en' : 'MM/DD/YYYY' ,
'ru' : 'DD.MM.YYYY' ,
}
export function $mol_dateFormat() {
return $mol_dateFormat_formats[ $mol_locale.lang() ] || 'YYYY-MM-DD'
}
}Только одно не понятно — ни в одном файле нет ни import, ни require. Как же система узнает, что этот файл нужно включить в пакет приложения? Не попадают же в пакет вообще все файлы? Чтобы проверить эту гипотезу вы перезагружаете приложение и пытаетесь вызвать свежесозданную функцию из консоли:
$.$mol_dateFormat() // Uncaught TypeError: $.$mol_dateFormat is not a functionНу не может же оно само понимать какой модуль нужен, а какой — нет? Или может? Вы добавляете использование функции в приложение:
supply_date() {
return this.position().supply_moment().toString( $mol_dateFormat() )
}Перезагрузив страницу, вы с удивлением обнаруживаете, что приложение не только не упало, но и вывело дату в локализованном формате:
Вы переименовываете файл в dateFormat2.ts — всё работает. Переименовываете директорию в dateFormat2 — снова ошибка. Переименовываете функцию в $mol_dateFormat2 — снова работает. Всё становится ясно — при обращении ко глобальной функции/классу/переменной с таким странным именованием происходит поиск пути, соответствующего частям имени. И если находится такая директория — подключаются скрипты из неё.
Отменив последние переименовывания, вы, с чувством полного удовлетворения коммитите изменения и идёте в столовую праздновать столь быстрое завершение задачи по коду, который вы увидели в первый раз в жизни, даже не читая никакой документации.

Разумеется, вы могли бы прочитать документацию по фреймворку и точно знать об используемых в нём принципах, а не строить теории и проверять их экспериментально. Но как известно, лучший способ разобраться как механизм работает — разобрать его и потыкать своими руками. Благо $mol поощряет исследование рантайма, исповедуя следующие принципы:
Все объекты доступны по ссылкам из глобальной области видимости, а не спрятаны в замыканиях. Это позволяет разработчику легко и просто исследовать внутреннее состояние приложения.
Для долгоживущих объектов автоматически генерируются уникальные человекопонятные идентификаторы, которые одновременно являются и "javascript-путями" до них из глобальной области видимости, что гарантирует их уникальность.
Изменения всех состояний логируются, с указанием идентификаторов объектов, что позволяет в точности понять, где что произошло. Например, если вы включите вывод логов всех сообщений, в идентификаторах которых есть подстрока "task", то, при завершении задачи в ToDoMVC, вы увидите следующие сообщения:
> $mol_log.filter('task')
< "task"
12:27:36 $mol_state_local.value("task=1476005250333") push Object {completed: true, title: "Hello!"} Object {completed: false, title: "Hello!"}
12:27:36 $mol_app_todomvc.root(0).task_completed(0) obsolete
12:27:36 $mol_app_todomvc.root(0).task_title(0) obsolete
12:27:36 $mol_app_todomvc.root(0).task_completed(0) push true false
12:27:36 $mol_app_todomvc.root(0).Task_row(0).completer().render() obsolete
12:27:36 $mol_app_todomvc.root(0).Task_row(0).render() obsoleteПространства имён в рантайме однозначно соответствуют структуре директорий в репозитории. Это гарантирует отсутствие конфликтов и даёт чёткое понимание как человеку, так и машине, где искать исходные файлы.
Весь код псевдосинхронен и разбит на небольшие функции, что упрощает его понимание. В следующем примере происходит неблокирующий запрос файла с текстами на нужном языке. Обратите внимание на полезный стектрейс, который не доступен при использовании "обещаний", "стримов" и тому подобных абстракций.
Прыжок без парашюта
Представьте, что перед вами внезапно вырисовалась задача разработать кроссплатформенное приложение, которое бы одинаково хорошо чувствовало себя как на мощных десктопах с огромными экранами, так и на миниатюрных смартфонах, где пол экрана то и дело закрывает клавиатура. Ах да, и сделать это надо было ещё вчера, а у вас ноутбук сломался и вам выдали девственно чистую замену.
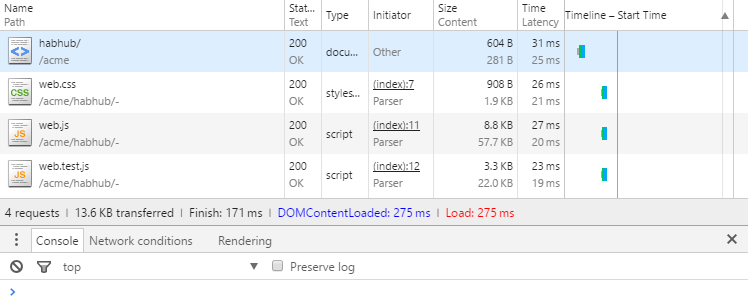
Итак, вы работаете в компании ACME (а если не работаете, то основываете свою) и вам нужно реализовать веб-приложение для гиковского социального блога HabHub. Для начала, вам нужно просто загружать с гитхаба статьи и показывать их единой лентой.
Первым делом вы устанавливаете необходимое программное обеспечение: Git, WebStorm, NodeJS и NPM.
Далее вы выкачиваете репозиторий со стартовым проектом MAM:
git clone https://github.com/eigenmethod/mam.git ./mam && cd mamСодержит он лишь общие для всех пакетов конфиги:
.idea— настройки для WebStorm: форматирование кода, статические проверки, запуск локального сервера..editorconfig— настройки для других редакторов..gitignore— указывает какие файлы git должен игнорировать..pms.tree— указывает какой пакет из какого репозитория выкачивать. Пакеты выкачиваются сборщиком автоматически по необходимости.package.json— настройки для NPM.tsconfig.json— настройки для TypeScript компилятора.
Открыв проект в WebStorm, вы запускаете локальный сервер, кнопкой "Start" на панели инструментов, либо, если вы предпочитаете другой редактор, выполнив в консоли:
npm startДалее вы создаёте для приложения директорию acme/habhub и кладёте в неё index.html, который будет служить точкой входа в ваше приложение:
<!doctype html>
<html style=" height: 100% ">
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width" />
<script src="-/web.js"></script>
<script src="-/web.test.js"></script>
<link rel="stylesheet" href="-/web.css" />
<body mol_viewer_root="$acme_habhub">Содержимое этого файла весьма типовое, разве что в атрибуте mol_viewer_root вы указываете класс компонента, который будет использован в качестве приложения. Да, компоненты на базе $mol_viewer настолько самодостаточные, что любой из них может быть отрендерен изолированно от остальных, как отдельное приложение.
Чтобы создать упомянутый компонент, вы создаёте файл ./acme/habhub/habhub.view.tree:
$acme_habhub $mol_viewПосле чего открываете http://localhost:8080/acme/habhub/ и убеждаетесь, что загружается чистая страница, а в консоли нет ни одной ошибки — это значит, что все необходимые файлы успешно сгенерировались и загрузились, а тесты не выявили проблем.
Язык описания компонент
view.tree — мощный и лаконичный декларативный язык описания компонент, позволяющий собирать одни компоненты из других, как из кубиков LEGO. Выучив этот не хитрый язык, любой верстальщик может создавать гибкие переиспользуемые компоненты, которые легко интегрируются в другие, без традиционного "натягивания вёрстки на логику". Вся логика пишется в отдельном файле view.ts и как правило не требует изменений во view.tree, что позволяет программисту и верстальщику работать над одними и теми же компонентами, не мешая друг другу. Это достигается за счёт намеренного ограничения: вы не можете просто взять и вставить div в нужном месте. view.tree требует, чтобы вы использовали компоненты и (самое главное!) каждому из них давали уникальные имена. Фактически $mol_view просто создаст div при рендеринге в DOM, но в перспективе рендеринг может быть в графический холст, нативные компоненты или даже в excel файл.
Типичный сценарий создания компонента верстальщиком выглядит так (на примере компонента показывающего ненавязчивый лейбл над блоком):
Сперва он пишет демо-компоненты, которые являются примерами использования реализуемого компонента:
- Label over simple text
$mol_labeler_demo_text $mol_labeler
title @ \Provider
content @ \ACME Provider Inc.
- Label over string form field
$mol_labeler_demo_string $mol_labeler
title @ \User name
Content $mol_string
hint <= hint @ \Jack Sparrow
value?val <=> user_name?val \Потом, собственно реализует его:
$mol_labeler $mol_view
sub /
<= Title $mol_view
sub /
<= title -
<= Content $mol_view
sub /
<= content nullА потом открывает страницу, где выводятся все демо компоненты и добавляет стили, глядя на все варианты использования компонента одновременно:
[mol_labeler_title] {
color: var(--mol_skin_passive_text);
font-size: .75rem;
}Многих смущает необычный синтаксис. То же самое можно было бы написать используя более привычный синтаксис XML:
<!-- Label over string form field -->
<component name="mol_labeler_demo_string" extends="mol_labeler">
<L10n name="title">User name</L10n>
<mol_stringer name="content">
<hint>
<String name="hint">Jack Sparrow</String>
</hint>
<value name="user_name">
<String />
</value>
</mol_stringer>
</component>Но он весьма громоздкий; во главе угла у него типы компонент, а не их имена в контексте родительского компонента; некоторые символы в строках требуют замены на xml-entities; велик соблазн просто скопипастить кусок вёрстки, без компонентной декомпозиции. Всё это приводит к осложнению работы с кодом и его поддержки, и поэтому в $mol используется именно синтаксис Tree, оптимально подходящий для задачи.
Небольшая шпаргалка по view.tree:
Объявление/использование компонента состоит из 3 частей:
- Имя компонента/свойства
- Имя базового компонента
- Список (пере)определяемых свойств
$ — префикс имён компонент. Данный префикс используется везде, кроме css, где он не допустим.
\ — с этого символа начинаются сырые данные. Содержать они могут любые символы (кроме символа конца строки), без какого-либо экранирования. Чтобы встравить несколько строк, нужно добавить символ \ перед каждой.
@ — вставленный между именем свойства и сырыми данными, он указывает вынести текст в файл с локализованными строками.
/ — объявляет список. Вставляйте элементы списка на отдельных строках с дополнительным отступом.
* — объявляет словарь. Сопоставляет текстовым ключам произвольные значения. Ключ не может содержать пробельные символы.
< — односторонне связывание (не путать с одноразовым). Указывает, что свойство слева (принадлежащее компоненту слева) должно брать значение из свойства справа (принадлежащее определяемому компоненту).
> — двустороннее связывание (не путать с обработчиками событий). Указывает, что в качестве свойства слева, должно быть взято свойство справа.
# — произвольный ключ. Указывает, что первым параметром свойство принимает некоторый ключ
Числа, логические значения и null выводятся как есть, без каких-либо префиксов.
Складываем кирпичики
Разобравшись в языке view.tree вы продолжаете пилить социальный блог. Прежде всего вы решаете, что у вас будет типичная раскладка страницы в виде шапки и скроллящейся области. Для этого вы используете готовый компонент $mol_page:
$acme_habhub $mol_page
title \HabHub
body /
\Hello HabHub!
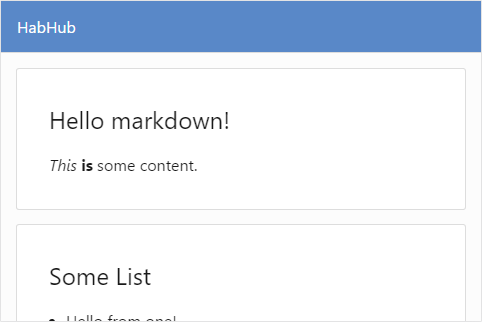
Отлично! В теле страницы должны быть статьи. Статьи на GitHub пишутся в формате markdown, поэтому вы добавляете пару примеров статей, используя компонент для визуализации markdown — $mol_texter:
$acme_habhub $mol_page
title \HabHub
body <= Gists /
<= Gist1 $acme_habhub_gist
text \
\# Hello markdown!
\
\*This* **is** some content.
< Gist2 $acme_habhub_gist
text \
\# Some List
\
\* Hello from one!
\* Hello from two!
\* Hello from three!
$acme_habhub_gist $mol_text[acme_habhub_gist] {
margin: 1rem;
}
Супер! Теперь вы убираете жёсткий код и оставляете лишь формулу создания карточки статьи по её номеру:
$acme_habhub $mol_page
title \HabHub
body <= Gists /
Gist!id $mol_text
text <= gist_content!id \Пришло время загрузить данные. Вы создаёте файл habhub.view.ts и пишете несколько мантр, которые позволят вам переопределить поведение уже созданного компонента:
namespace $.$mol {
export class $acme_habhub extends $.$acme_habhub {
}
}Прежде всего вы описываете формат в котором от сервера приходят статьи:
interface Gist {
id : number
title : string
body : string
}Потом вы определяете свойство, которое будет возвращать ссылку, по которой следует забирать данные. В дальнейшем можно будет добавить в него логику по учёту пользовательских предпочтений, но пока оно будет возвращать константу:
uri_source() {
return 'https://api.github.com/search/issues?q=label:HabHub+is:open&sort=reactions'
}А теперь вы задаёте свойство, которое будет возвращать собственно данные, делая запрос к серверу через модуль $mol_http_resource_json, предназначенный для работы с json-rest ресурсами:
gists() {
return $mol_http.resource( this.uri_source() ).json().items as Gist[]
}Далее вы формируете карточки для показа статей по числу этих статей через свойство gister#, которое вы объявили ещё во view.tree:
Gists() {
return this.gists().map( ( gist , index ) => this.Gist( index ) )
}gister# обращаясь к gist_content# передаёт ему тот же ключ, что передан и ему, так что осталось лишь задать, как по номеру статьи сформировать её содержимое:
gist_content( index : number ) {
const gist = this.gists()[ index ]
return `#${ gist.title }\n${ gist.body }`
}В результате у вас получается следующего вида презентатор:
namespace $.$mol {
interface Gist {
id : number
title : string
body : string
}
export class $acme_habhub extends $.$acme_habhub {
uri_source(){
return 'https://api.github.com/search/issues?q=label:HabHub+is:open&sort=reactions'
}
gists() {
return $mol_http.resource( this.uri_source() ).json().items as Gist[]
}
Gists() {
return this.gists().map( ( gist , index ) => this.Gist( index ) )
}
gist_content( index : number ) {
const gist = this.gists()[ index ]
return `#${ gist.title }\n${ gist.body }`
}
}
}Код в целом тривиальный и в тестировании не нуждается: uriSource возвращает константу, правильность обращения gists к стороннему модулю проверит typescript компилятор, Gist тривиален и опять же проверяется компилятором, и только gist_content содержит нетривиальное формирование строки, поэтому вы пишете на него тест в habhub.test.ts:
namespace $.$mol {
$mol_test({
'gist content is title + body'() {
const app = new $acme_habhub
app.gists = ()=> [
{
id : 1 ,
title : 'hello' ,
body : 'world' ,
}
]
$mol_assert_equal( app.gist_content( 0 ) , '# hello\nworld' )
}
})
}Перезагрузив страницу, вы обнаруживаете в консоли:
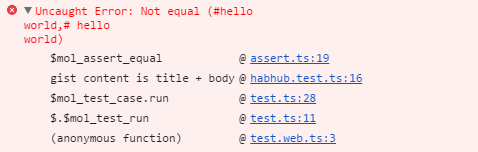
Ага, пробел потерялся. Исправив код, вы перезагружаете страницу и видите сначала индикатор загрузки, а потом собственно статьи.

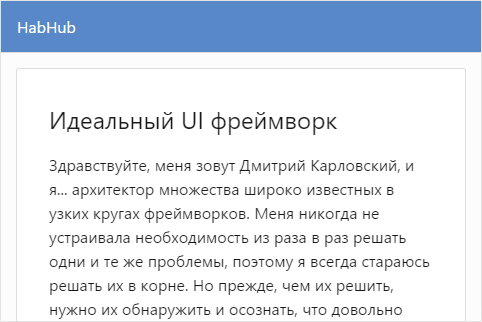
Блеск! Проверив, своё маленькое приложение на корректность, вы с чувством полного удовлетворения коммитите изменения и идёте в столовую праздновать столь быстрое завершение задачи, предполагающее неблокирующие запросы, визуализацию markdown и ленивый рендеринг...

Кое-что всё же омрачает вашу радость и вам приходится вернуться к отладчику — страница довольно долго открывается пытаясь отрендерить сразу все статьи.
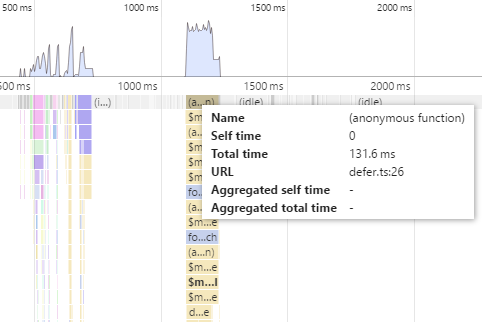
Каждый $mol_texter является наследником от $mol_lister, который умеет лениво рендерить вертикальные списки, дорендеривая их по мере прокрутки. Поэтому при открытии страницы статьи рендерятся не целиком, а лишь некоторое число первых блоков. Чтобы и сами $mol_texter исключались из рендеринга, когда точно не влезают в видимую область, достаточно их тоже засунуть в $mol_lister:
$acme_habhub $mol_page
title \HabHub
body /
<= List $mol_list
rows <= Gists /
Gist!id $mol_text
text <= gist_content!id \
Ленивый рендеринг
Работает ленивый рендеринг просто и железно. Любой компонент может предоставить информацию о своей минимальной высоте через свойство minimal_height. Например, $mol_text_row указывает минимальную высоту в 40 пикселей, меньше которых он занимать не сможет, независимо от содержимого, css правил и ширины родительского элемента. Компонент $mol_scroll отслеживает позицию скроллинга и устанавливает свойство $mol_view_visible_height контекста рендеринга таким образом, чтобы гарантированно накрыть видимую область (позиция скроллинга плюс высота окна). Контекст автоматически передаётся всем отрендеренным внутри компонентам и доступен в них через this.$.$mol_view_visible_height(). Используя всю эту информацию, компонент $mol_list рассчитывает сколько элементов списка нужно отрендерить, чтобы гарантированно накрыть видимую область. Так как все упомянутые свойства реактивны, то при изменении состава элементов, позиции скроллинга и размеров окна, происходит автоматический дорендеринг недостающих или удаление лишних элементов списка.
Именно за счёт ленивого рендеринга $mol и оказывается лидером в тестах производительности. Без него, производительность $mol была бы на уровне Angular. Кто-то может возразить, что это не честно. Однако, это не менее честно, чем Virtual DOM в React, позволяющий не делать то, что можно не делать. При этом ускорение в обоих случаях достаётся почти бесплатно, без километров хрупкой логики, описывающей когда и что нужно делать, а когда и что — не нужно.
Ленивый рендеринг позволяет быстро показывать пользователю экран, практически независимо от объёмов выводимых данных. Так как часть компонент не рендерится, то и данные для них не запрашиваются, что позволяет и грузить их лишь по мере надобности, ничего не меняя для этого в слое отображения. Единственный скользкий момент — если прокрутить страницу сразу в самый конец списка, то таки придётся подождать полного рендеринга всех элементов. Но это достаточно редкий случай в повседневном использовании, ведь благодаря фильтрам и сортировке, куда проще сделать так, чтобы нужные данные оказались наверху, чем вручную искать их огромном списке.
Исключительные ситуации
Всё бы хорошо, но после последних оптимизаций куда-то пропал индикатор загрузки. Вы открываете DOM-инспектор и видите там следующую картину:
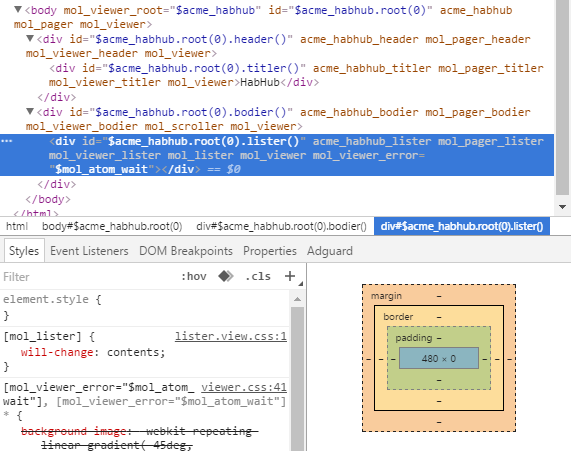
Блок $acme_habhub.root(0).list() в который выводится список статей не смог отрендериться так как список статей ещё не загружен, поэтому для него автоматически был установлен атрибут mol_view_error с типом ошибки в качестве значения. Для типа ошибки $mol_atom_wait по умолчанию рисуются бегущие полоски. Но вот беда, в отсутствии содержимого этот блок схлопнулся до нулевой высоты, и поэтому не видно индикатора загрузки. Самое простое решение — задать для этого блока минимальную высоту:
[acme_habhub_list] {
min-height: 1rem;
}
Но что если загрузка оборвётся или произойдёт её какая-либо ошибка?
Так дело не пойдёт! Надо сообщить пользователю что пошло не так. Вы могли бы просто перехватить исключение в Gists() и нарисовать вместо списка статей сообщение об ошибке. Но это достаточно типовой код, который удобнее вынести в отдельный компонент, который бы принимал некоторое свойство, и если при его вычислении происходила бы ошибка — не просто падал, а показывал сообщение пользователю. Именно так и работает $mol_status:
$acme_habhub $mol_pager
title \HabHub
body /
<= Status $mol_status
status <= Gists /
<= List $mol_list
rows <= Gists /
Gist!id $mol_text
text <= gist_content!id \
Как можно заметить, особое внимание в $mol уделено толерантности к ошибкам. Если какой-то компонент упал, то только он и выйдет из строя, не ломая всё остальное, не зависящее от него, приложение. А если источник проблемы устранён, то и компонент следом возвращается к нормальной работе.
Так как код на $mol в подавляющем большинстве случаев синхронен, то и try-catch работает как полагается. Но что если данные ещё не загружены и за ними нужно сходить на сервер? Это самая натуральная исключительная ситуация для синхронного кода. Поэтому, модуль загрузки данных делает как полагается асинхронный запрос, но вместо немедленного возврата данных (которых ещё нет), кидает специальное исключение $mol_atom_wait, которое раскручивает стек до ближайшего реактивного свойства, которое его перехватывает и запоминает в себе. А когда данные придут, то это свойство будет вычислено повторно, но на этот раз вместо исключения, будут уже синхронно возвращены данные. Таким не хитрым способом достигается абстрагирование кода всего приложения от асинхронности отдельных операций, без необходимости выстраивать цепочки обещаний и превращения половины функций в "асинхронные" (async-await).
Тут же стоит отметить элегантную магию, доступную во всех современных браузерах благодаря Proxy API. В общем случае, при обращении к реактивному свойству, в котором сохранён объект исключения, это самое исключение бросается незамедлительно. Но если поддерживается Proxy API, то возвращается лишь прокси, который бросает исключение, при попытке взаимодействия с результатом. Это позволяет продолжить выполение кода, отложив "синхронизацию" до момента, когда возвращаемые данные реально понадобятся.
Например, вам нужно вывести приветственное сообщение, но само сообщение взять из конфига, а имя пользователя из его профиля. При первом вычислении свойства greeting, будет следующая картина:
@ $mol_mem()
greeting() {
const config = $mol_http.resource( './config.json' ).json()
// Запущен асинхронный запрос, а в config помещён Proxy
const profile = $mol_http.resource( './profile.json' ).json()
// Запущен асинхронный запрос, а в profile помещён Proxy
// В этот момент исполнение будет остановлено, а в свойство greeting будет помещено исключение $mol_atom_wait
const greeting = config.greeting.replace( '{name}' , profile.name )
// Сюда исполнение уже не дойдёт
return greeting
}Не имеет значения в какой последовательности придут ответы от сервера, потому что код функции является идемпотентным, то есть допускающим множественные перезапуски. После получения каждого ответа, свойство будет перевычисляться и снова останавливаться на недостающих данных, пока все необходимые данные не будут загружены:
@ $mol_mem()
greeting() {
const config = $mol_http.resource( './config.json' ).json()
// В config помещён json, полученный с сервера
const profile = $mol_http.resource( './profile.json' ).json()
// В profile помещён json, полученный с сервера
const greeting = config.greeting.replace( '{name}' , profile.name )
// greeting будет вычислен на основе config и profile
// Наконец, дошли до конца и вернули актуальное значение
return greeting
}Свистелки и блестелки
Как можно было заметить, $mol содержит всё необходимое, чтобы просто взять и начать делать приложение. Не нужно ничего конфигурировать, а в комплекте идёт библиотека стандартных адаптивных компонент, содержащая как тривиальные компоненты типа $mol_filler, который выводит небезызвестный "Lorem ipsum", так и комплексные компоненты, типа $mol_grider, который предназначен для отображения огромных таблиц с плавающими заголовками.
При рендеринге DOM-элементу устанавливается атрибут с именем класса компонента, а также именами всех классов-предков. Это позволяет, например, задать для всех кнопок общие стили:
[mol_button] {
cursor: pointer;
}А потом для какого-то конкретного типа кнопки перегрузить их:
$mol_button_major $mol_button[mol_button_major] {
background: var(--mol_skin_accent);
color: var(--mol_skin_accent_text);
}Кроме того, в соответствии с методологией БЭМ для всех вложенных компонент устанавливаются контекстно-зависимые атрибуты вида my_signup_submit, где my_signup — имя класса владельца, а submit — имя свойства, в которое объект сохранён:
$my_signup $mol_page
body /
<= Submit $mol_button_major
sub /
<= submit_label @ \Submit[mol_signup_submit] {
font-size: 2em;
}Такая логика работы позволяет избавить разработчика от необходимости вручную дописывать к каждому dom-элементу "css-классы" и поддерживать порядок в их именовании. В то же время, она даёт высокую гибкость при композиции компонент — всегда можно как-то по особенному стилизовать конкретный компонент в конкретном контексте его использования, без риска сломать что-то в других местах.
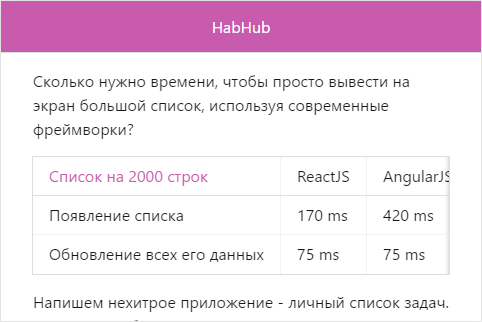
Так как один и тот же компонент может использоваться в совершенно разных местах, в совершенно разных приложениях, выполненных в совершенно разных дизайнах, то критически важно, чтобы компонент мог адекватно мимикрировать под общий дизайн приложения. Основным аспектом этой мимикрии являются цвета. Поэтому, как минимум стандартные компоненты, не содержат в себе никакой цветовой информации, вместо этого беря её из глобальных констант. В $mol эти константы сгруппированы в модуле $mol_skin. Реализуя своё приложение, вы можете переопределить эти константы и все компоненты перекрасятся в соответствии с ними:
:root {
--mol_skin_base: #c85bad;
}
Если вам не хватит стандартных констант — вы всегда можете завести свои. Это позволит тем, кто будет использовать ваши компоненты, так же просто интегрировать их в свой дизайн, как и стандартные.
Экстренное торможение
$mol весьма прост и гибкок, однако, как и любой фреймворк, он имеет и некоторые жёсткие рамки, которые поощряют "хорошие" практики и препятствуют "плохим". Что такое "хорошо", а что такое "плохо", зависит от целей. И для $mol они ставились такие:
- Создание быстрых приложений. С быстрым приложением работать — одно удовольствие. Как конечному пользователю, так и изначальному разработчику.
- Быстрое создание приложений. Это даёт не только удешевление производства, но и больше времени на другие этапы: от согласования, до внедрения.
- Создание кроссплатформенных приложений. Веб платформа как ничто лучше подходит для этих целей.
- Долгосрочная поддержка созданных приложений. Она не должна превращаться в снежный ком из костылей и заплаток.
- Минимизация багов в созданных приложениях. Они и по репутации больно бьют, и внедрение затягивают.
- Создание компактных приложений. Чем меньше кода, тем быстрее он стартует, тем меньше в нём багов, тем быстрее его писать.
- Создание межпроектной кодовой базы. Это и профессионала ускоряет, и новичку позволяет быстрее влиться в процесс.
- Расспараллеливание разработки приложений. Горизонтальная и вертикальная декомпозиция, позволяют большему числу людей работать над одним приложением используя наработоки друг друга, что приводит к ускорению поставки новых версий.
По итогу, на текущий момент можно выделить следующие свойства $mol, которые в других фреймворках либо не встречаются вообще, либо встречаются, но в несколько куцем виде:
- Минимум конфигурирования — только несколько простых соглашений и максимальная автоматизация.
- Микромодульность — приложение собирается из множества маленьких модулей. Нет строго выделенного ядра.
- Автоматические зависимости между модулями — детектирование зависимости по факту использования и автоматическое включение зависимостей в пакет при сборке.
- Многоязычные модули — нет какого-то выделенного языка, все языки равноправны при поиске зависимостей и сборке пакета.
- Статическая типизация — по возможности используется TypeScript для исходников и промежуточных файлов.
- Множество приложений и библиотек в одной кодовой базе — сборка любого модуля как независимого пакета для деплоя куда бы то ни было.
- Полная реактивность — автоматическое обнаружение и эффективная актуализация зависимостей между состояниями.
- Синхронный код, но неблокирующие запросы — в том числе и параллельные запросы, когда это возможно.
- Полная ленивость — ленивая отрисовка, ленивая инициализация свойств, ленивая загрузка данных, ленивая сборка.
- Контроль жизненного цикла объектов — автоматическое уничтожение при утрате зависимостей от него.
- Высокая компонуемость — легко соединять даже те компоненты, которые написаны без оглядки на настраиваемость.
- Толерантность к ошибкам — исключительные ситуации не приводят к нестабильной работе приложения.
- Кроссплатформенность — модуль может содержать разные версии кода под разные окружения и для разных окружений собираются отдельные пакеты.
- Ориентация на исследование рантайма — везде есть "хлебные крошки" помогающие найти концы.
- Человекопонятные идентификаторы объектов — генерируются автоматически на основании имён свойств, которые ими владеют.
- Логирование изменения всех состояний — поддерживается фильтрация по содержимому идентификатора.
- Пространства имён вместо изоляции — простой доступ из консоли к любому состоянию, пространства имён соответствуют расположению модулей в файловой системе.
- Автогенерация BEM-атрибутов — не нужно вручную прописывать классы, имена в CSS гарантированно соответствуют именам в JS/TS/view.tree, поддерживается наследование.

На этом наша история… не заканчивается. Возможно именно вы станете соавтором её продолжения, привнесёте с собой свежих идей, а может даже и сочных запросов на слияние. На этом распутье у вас есть несколько дорог:
- Налево пойдёшь — карму автору сольёшь, чтобы не пиарил тут свои велосипеды: Хабрацентр им. vintage
- Направо пойдёшь — изучишь документацию и попробуешь что-нибудь сваять: eigenmethod/mol: Fast reactive micromodular ui framework
- Прямо пойдёшь — обнаружишь ошибку, фатальный недостаток или отсутствие улучшения, и тут же спросишь с ответчика по всей строгости: Issues · eigenmethod/mol
- Назад пойдёшь — вернёшься в пучину неоправданной сложности: Каково оно учить JavaScript в 2016, Идеальный UI фреймворк
- Никуда не пойдёшь — примешь участите в дискуссии в комментариях к этой статье :-)
UPD: Имена и явки с момента написания статьи изменились, так что приведённые примеры кода хоть и обновлены, но могут не соответствовать текущему положению дел, а скриншоты — точно не актуальны.
