Настоящий пост является является, фактически, резюме, подводящим итоги предыдущих «технологических» публикаций [1, 2, 3, 4, 5] и возникших дискуссий и обсуждений. Последние показали, что задач в которых применение R могло бы оказать хорошую помощь бизнесу очень и очень много. Однако, даже в тех случаях, когда R используется, далеко не всегда для этого применяются современные возможности R.
Ниша для применения R в бизнесе открыта и очень актуальна как на западе, так и в России.
Почему это утверждение особенно интересно для России?
1. Идет активный процесс импортозамещения ПО, контролируемый на уровне министерств и правительства. Многие предпочтут использовать ПО из разрешенного списка, нежели придумывать обоснования и доказывать необходимость приобретения зарубежного ПО, пусть и немного лучшего, чем российские аналоги. А к госкомпаниям внимание на порядок пристальнее.
2. К сожалению, нет реляций, что кризис закончился и начинается подъем. Затянуть пояса — это да. А значит бюджетов на дорогие игрушки и не очень-то предвидится. При этом решение задач никто не отменяет, количество и амбициозность задач скорее только увеличивается.
3. Бизнес вполне справедливо полагает, что если уж ИТ не создает конкурентных преимуществ, то хотя бы должно помогать оперативно готовить информационное поле для ручного или автоматизированного принятия решений. При этом запросы у бизнеса зачастую весьма прозаичны и непритязательны, чтобы привлекать нобелевских лауреатов для их решения.
Фактически, для уверенного плавания в «цифровом» море бизнесу необходима лишь локальная «сшивка» информационного пространства и формирование интерактивных представлений для упрощения процесса принятия решений в контексте весьма ограниченного набора вопросов и процессов.
В целом, ситуацию с принятием решений можно описать следующим образом:
- В любой компании каждый сотрудник ежедневно принимает множество важных бизнес-решений.
- Время для принятия решения невелико (секунды-часы).
- Не всегда вопрос формулируется в четкой и однозначной форме.
- Принятие решения может требовать сложной математической обработки данных.
Технологически этот процесс описывается цепочкой «Сбор — Процессинг — Моделирование и Анализ — Визуализация\выгрузка».
Локальность «сшивки» приводит к тому, что использование мощных промышленных ETL\BI\BigData решений оказывается совершенно неоправданным ни с технической, ни с экономической точки зрения.
Для того, чтобы посадить грядку морковки, не надо пахать десяток гектар земли.
С другой стороны, такой контекст является очень комфортным для экосистемы R и исполняется на раз. Для бизнеса подход «1-2-3» можно изложить следующей картинкой (бизнес ведь любит картинки):

При использовании R технологически почти все равно, какие источники данных и какие там форматы, насколько они чисты, что и как надо нарисовать и вывести. Можно практически все. Главное — иметь сформулированную бизнес-задачу.
Возвращаемся к практическому примеру
В качестве демонстрации применимости вышеуказанного подхода обратимся еще раз к теме, упоминавшейся ранее в посте «Инструменты Data Science как альтернатива классической интеграции ИТ систем», а именно, примеру консоли агронома в рамках одной из подзадач современного направления «Прецизионное Земледелие».
Сама по себе подзадача звучит весьма прозаично: «Оптимизировать ирригацию полей с учетом особенностей выращиваемой культуры, фенологических фаз и климатических условий (прошлое, настоящее, прогноз) для повышения качества урожая и снижения затрат».
Естестенно, что ИТ-аналитика подсистема является лишь одной из подсистем. Полный комплекс охватывает и задачи выбора оптимиальной методики и непосредственного измерения физических показателей влажности почвы (что само по себе является непростым) и параметров окружающей среды, автономную работу датчиков и передачу телеметрии по радиоканалу с учетом масштабов полей (единицы-десятки километров), дешевизна + компактность + работа без смены батарейки в течении всего сезона, оптимизацию размещения датчиков и защиты их от различных воздействий, включая повышенный интерес местных жителей, а также учет баланса воды в растениях (грубо, поглощение — испарение). Но все эти задачи выходят за рамки темы настоящей публикации.
Итак, консоль агронома. Все сделано на R + Shiny + DeployR. Пример рабочей версии консоли приведен на следующем скриншоте:
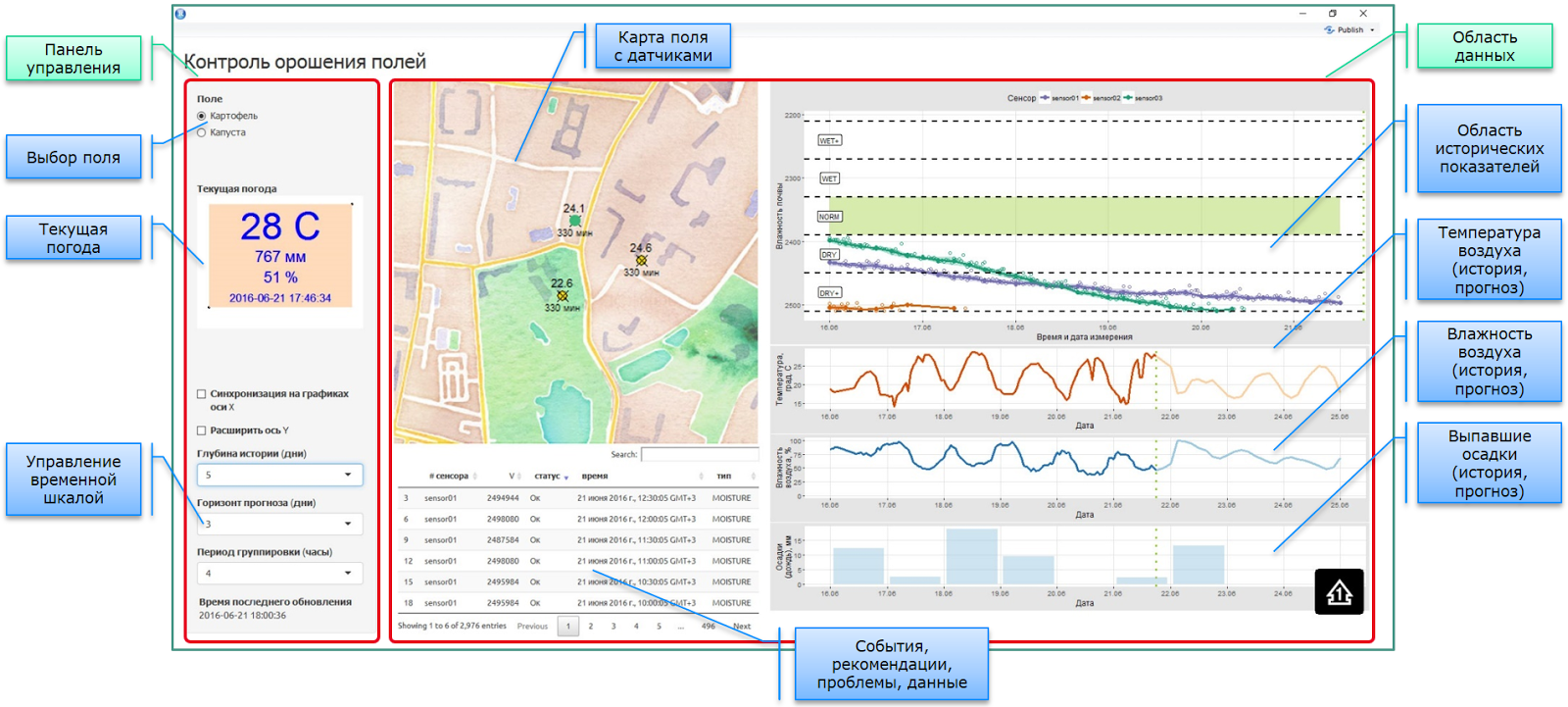
Все выглядит просто и тривиально ровно до тех пор, пока не погрузишься в детали. А именно в деталях и проявляется предлагаемый подход локальной сшивке данных.
1. Нет никакого глобального хранилища с жесткой моделью данных, содержащего всю-всю-всю информацию. Наоборот, есть набор автономных или полуавтономных подсистем, содержащих подмножество информации в своем собственном виде.
2. Поскольку консоль агронома и отображаемая в ней информация нужна тогда, когда есть кому смотреть, то само приложение выступает в качестве бесконечного цикла для диспетчера сообщений. Консоль динамичесая, проверка необходимости пересчета производится по таймеру, обновление элементов происходит автоматически, с использованием реактивных (reactive) элементов платформы Shiny. При этом автономная операционная аналитика живет на R сервере в независимом от консоли режиме.
3. Текущая погода. Данные берутся из нескольких источников, включая веб источники (REST API) и данные фактических сенсоров на поле (log\csv + git). Так как все датчики на поле экономят батарейки и выходят на связь в своем собственном режиме, данные в консоль поступают в асинхронном режиме. В качестве хранилища полевых данных использовался репозиторий git.
4. Для оперативного анализа интерфейс содержит, в том числе, элементы управляющие отображаемыми срезами. Весь пересчет происходит по факту изменения настроек.
5. GIS-карта с установленными датчиками на поле. Многослойная карта (именно здесь в качестве подложки OpenStreet) с наложенной инфраструктурой полевых датчиков, и динамически пересчитываемыми показателями этих датчиков, такими как: текущий статус, текущие показания, время последнего съема показаний. Метаинформация о датчиках получается из облачной системы учета IoT оборудования. Из-за достаточно сложной внутренней логической структуры объектов IoT платформы для получения данных о сенсорах необходимо выполнить цепочку из 3-4 REST API запросов с промежуточной обработкой.
6. Табличное представление для вывода событийной информации: показания, логи, рекомендации, проблемы, прогнозы. Каждый тип выводимой информации получается либо из отдельного источника (подключение, сбор, парсинг, предобработка), либо является результатом работы мат. алгоритмов (например, прогнозы и рекомендации).
7. Область данных (справа) объединяет в единой консоли информацию, полученную и обработанную из десятка различных источников:
Данные об исторических показателях погоды. Используются данные полевых сенсоров (txt + git) и данные о погоде с открытых веб-источников. В силу того, что на бесплатных аккаунтах (после предварительного анализа нескольких веб-источников) далеко не везде есть глубокая история, а идея платить $100-150 в месяц за доступ к погодным данным сельхозпроизводителей никак не радует, был поднят отдельный процесс накопления исторических веб-данных на основе мониторинга текущих (REST API -> txt + git). И, естественно, при конфликте данных из разных источников необходимо его разрешать. В качестве одного из основных источников мы остановились на Open Weather Map — OWM
Прогнозная часть также вызывала ряд вопросов. Разные источники дают разную информацию с различной гранулярностью. Не все источники дают прогноз осадков в мм. Если дают, то не все дают почасовую. Могут выдавать агрегаты. Их надо как-то сводить.
В частности, OWM при запросе осадков выдает 3-х часовой агрегат в мм, начиная с момента фиксации. Если говорить о прошлом, то момент фиксации также может быть выдан случайный. Таким образом, получаем произвольный временной ряд с 3-х часовыми агрегатами и большим количеством повторов, по которым необходимо восстановить почасовую картину.
Данные от сенсоров поступают по различным каналам. Сами датчики «живут» в асинхронном режиме (экномия батареек), поэтому данные от них поступают в режиме потока, без возможности принудительного опроса. Негарантированность каналов связи (все в поле, иногда в плохой зоне покрытия) и различные версии аппаратных платформ датчиков приводят к тому, что для анализа необходимо забирать данные со всех потенциальных хранилищ. На настоящий момент данные по сенсорам поступают в git (структурированный вид и логи) и в облачную платформу управления IoT устройствами.
- Данные с сенсоров (а на поле их стоит не 2 и не 5) проходят предварительную математическую обработку. В силу специфики измерения влажности почвы и невозможности прямых измерений (с определенной оговоркой для ЯМР или радиометрических методов), результат косвенных измерений сильно зависит от стуктурных свойств почвы. Необходимо определить достоверность показаний каждого из датчиков, опираясь как на его частные калибровочные кривые, так и на исторические данные, ожидаемые показатели, данные по осуществленному поливу и информации от других датчиков на поле.
Заключение
На западе сообщество R, а также круг решаемых задач, экспоненциально развивается. Open-source активно наступает. Для ознакомления с новинками в части R можно в качестве стартовой площадки использовать агрегатор R-bloggers. Вот, например, весьма интересный свежий бизнес-пост: «Using R to detect fraud at 1 million transactions per second».
В России есть все предпосылки к использованию R в задачах бизнеса, но пока относительно слабое community. С другой стороны, активная и любознательная аудитория Хабра является наилучшим проводником современных ИТ технологий на территории нашей страны.
Самое время попробовать решить существующие в ваших компаниях задачи по-новому, с применением новых инструментов, и начать обмениваться полученным опытом. Обсуждение вопросов и непонятных моментов в открытых дискуссиях этому только поспособствует.
P.S. Кстати, теперь семантика пакета dplyr доступна и для работы с Apach Spark. Вышел пакет sparkly, обеспечивающий эту прозрачность.
Предыдущий пост: "Вам не хватает скорости R? Ищем скрытые резервы"
Следующий пост: "Применение R для подготовки и передачи «живой» аналитики другим бизнес-подразделениям"
