Год назад Google сваял платформу Cloud Vision API. Идея платформы — предоставить технологии Computer Vision, в которых Google является безусловным лидером, как сервис. Пару лет назад под каждую задачу существовала своя технология. Нельзя было взять что-то общее и добиться, чтобы алгоритм решал всё. Но Google замахнулся. Вот, прошёл уже год. А технология всё так же не на слуху. На хабре одна статья. Да и та ещё не про Cloud Vision api, а про Face api, которое было предшественником. Англоязычный интернет тоже не пестрит статьями. Разве что от самого Google. Это провал?

Мне было интересно посмотреть что это такое ещё весной. Но сил полноценно посидеть не хватало. Изредка что-то отдельное тестировал. Периодически приходили заказчики и спрашивали, почему нельзя применить Cloud Api. Приходилось отвечать. Или наоборот, отсылать с порога в этом направлении. И внезапно понял, что материала на статью уже достаточно. Поехали.
Гугл говорит много разных и красивых слов. Но это неинтересно. Всё что они умеют делать согласно их прайс-листу:
В статье я буду говорить про Label Detection, ORC, Facial Detection как про наиболее логичные ComputerVision задачки для которых мне известны аналогии/варианты. Немножко вскользь коснусь Landmark Detection.
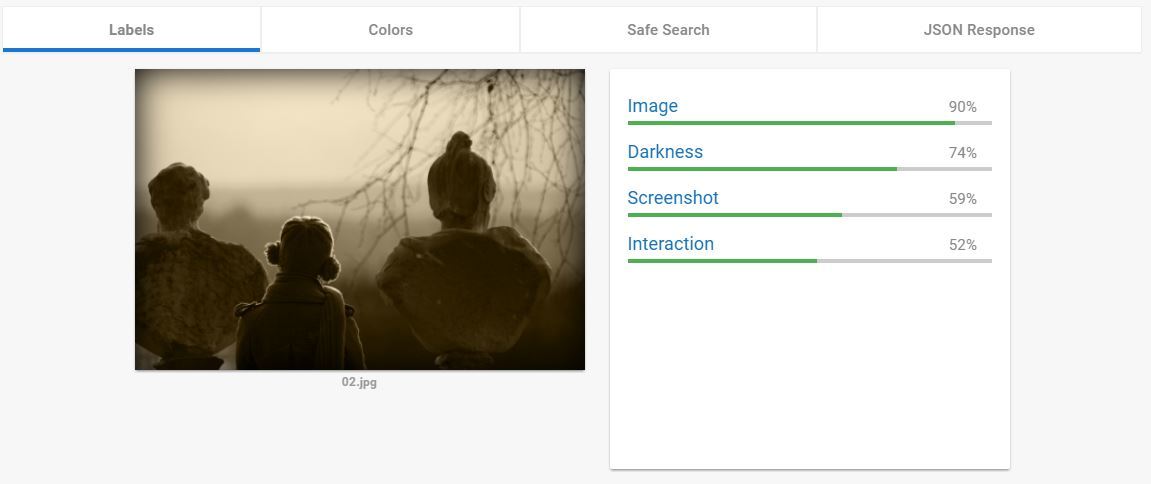
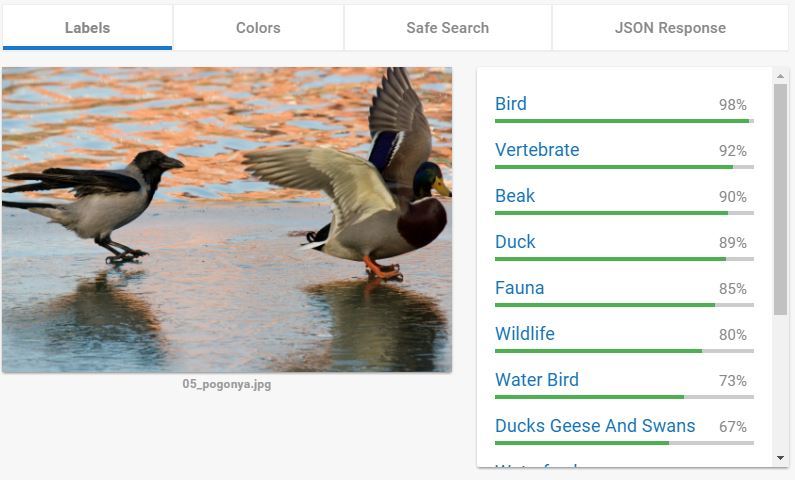
Так или иначе, этой функцией от Google пользуются все. Поиск по картинке на google.com использует именно её. По сути, Label Detection даёт изображениям характеристики. Характеристикой может быть объект, изображённый на фото. Может быть стиль фотографии, например «Макро», «Портрет», «Чёрно-белое». А может что-то очень общее: «ботанический объект», «атмосферный феномен».
Кроме поиска эта функция может решить задачи:
Аналоги. Но, как ни странно, именно в этом направлении у google есть множество конкурентов:
Microsoft. Умеет достаточно неплохо описывать что происходит на изображении, а не только его составную часть. Нет онлайн-демки, чтобы сравнить.
Вот тут есть большое и полноценное сравнение. Я приведу лишь несколько примеров:

Пример когда гугл не справился: 1. Пример когда он дал неточное, на мой взгляд, описание: 1. Нет слова «яблоко». Но только cloudsight справился. Нет слова «человек» — 2. Нет слова «ворона» — 3.
И только на этой картинке из тех, что я пробовал, гугл обошёл всех и нашёл кошку:

Остальные не справились — 1, 2, 3.
Вывод: работает неплохо. Конкурентов, идущих в ногу хоть отбавляй. В домашних условиях повторить почти невозможно.
Распознавание лица. Что умеет гугл:
Что он не умеет, но умеют конкуренты:
Конкуренты, например вот: 1, 2, 3. А вообще десятки их.
С чем имеет смысл сравнивать Google? Например с выделением лиц каскадами Хаара, как в OpenCV, или HOG, как в dLib. У них Google выигрывает. И точки лица лучше находит, чем dlib:
Dlib:

Ещё и ещё.
Google:
Ещё и ещё.
Но при этом гугл — платный, а Dlib бесплатный. Чтобы настроить нужно одинаковое количество строчек. При этом если запариться, то можно взять вместо dlib что-то state-of-art и получить точность почти не хуже гугла.
Вообщем этот раунд Google однозначно слил.
А вот этот пункт — ПЦ. и у Гугла тут нет равных. И нет аналогов. Когда я понял как это функция работает я подумал «ну, Кремль она распознает». Но не тут то было. Кроме Кремля она успешно распознаёт все мало-мальски значимые туристические объекты. Два примера которые меня выморозили:
Боровск:
Ну фиг с ним, он более-менее туристически популярный. Фотографий много. Пусть повезло.
Заключье:
Усадьба-пионерлагерь затерянная между Москвой и Питером недалеко от Боровичей.
Как он это делает, не знаю. Вот ещё куча примеров: 1, 2, 3, 4, 5, 6, 7.
Сфэйлился он только один раз. Зато эпичнейшим образом:
И, наконец, переходим к самой интересной части. Именно ради этого я и полез копаться. Насколько хорошо Google распознаёт тексты. Именно это применение наиболее промышленное, именно тут десяткам производителей и потребителей было бы интересно иметь готовые решения:
Попробуем сравнить то, чего добился гугл. Сравним с существующими решениями. И сравним с его единственным конкурентом как «общего распознавателя» — Microsoft.
Книги, тексты
Для текстов у Google есть сильный конкурент Abbyy. По тому, что я затестил, мне кажется, что уровень распознавания символов у них примерно на одном уровне:

Видно, что реально конкурируют только Google и Abbyy. Но как только дело касается навала текста на странице, то тут побеждает Abbyy: он умеет структурировать текст, переводить таблицы, колонтитулы, и.т.д. Гугл выдаёт навал текста. Плюс у Гугла мало языков в поддержке.
Вангую, что в ближайшее время появятся стартапы, которые будут использовать Google Api для перевода, а всю структурную аналитику + сбор текста будут поверху прицеплять. Учитывая, что Abbyy хочет за перевод раз в 10 больше, чем Google — это достаточно сочный навар.
Понятно, что в сегменте текстов нет ни одного хорошего софта, который можно дома запустить. Так что переходим к следующей OCR задаче.
Ценники, прочие таблички
Важный момент — google не поддерживает другие языки, в отличие от microsoft. Но в целом оба работают, когда текст хороший, не смазанный, не наклонён, не зашумлён и не бликует:

Microsoft:
Google:

Microsoft: Не распознано ничего
Google:

Microsoft: по нулям
Google:

В целом, где-то 60% этикеток — текст считывается. И это на мой взгляд просто офигенный результат. Только вот как и зачем этот текст потом собирать — непонятно.
Более того, неплохо читаются даже хорошо снятые таблички. Не весь текст, конечно, но крупный точно:
Но всё равно, тексты разного формата не очень хорошо распознаются:
Техническая информация
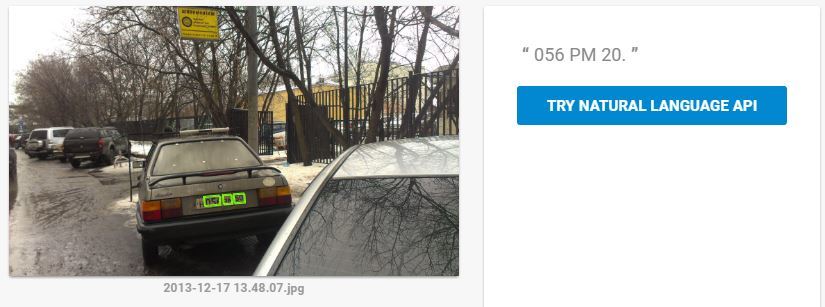
А вот тут Google и Microsoft пока конкретно лажают. Из нескольких десятков проверенных автомобильных номеров Microsoft распознал процентов 20. Google процентов 60, да и те без региона. Регион распознавал только в идеальной ситуации, когда крупный номер без грязи. Как только грязь — отдельный кусок распознаёт и всё.
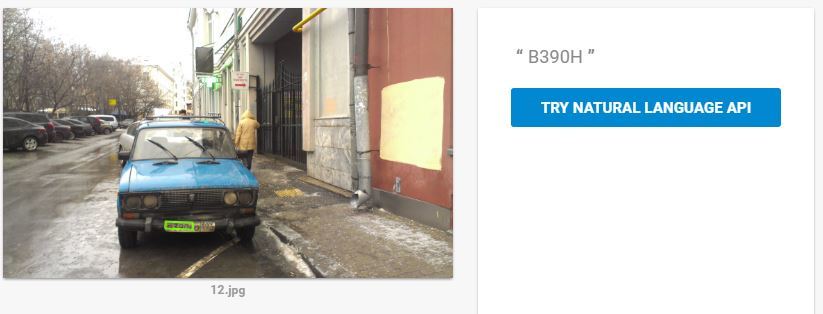
Плюс регулярные ошибки в 1-2 символа:
Системы распознавания номера опираются на априорную информацию => работают лучше. Хотя, конечно, для каких-то применений может и гугла хватит. Идеальный снимок в упор к номеру распознает.
Без априорной информации плохо. Ещё вариант технического зрения — номера поездов. Microsoft вообще не справился. Google дал только процентов 50 правильных. На остальных постоянно косячил:
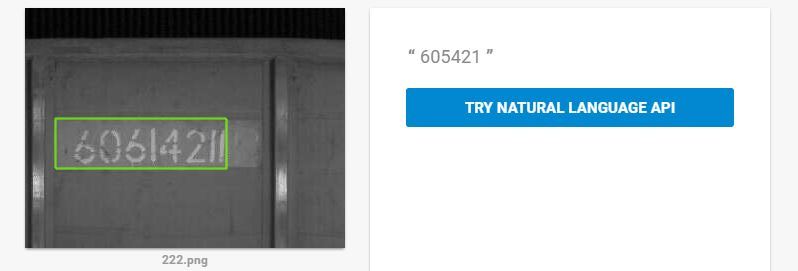
Так что в задачах контроля качества, стабильного распознавания текста Google и Microsoft годятся только для самых простых задач.
Конечно, OpenSource решений на тему таких задач нет, но зачастую их можно своими силами решить. Перебор простых гипотез, поиск контура, и.т.д. То же выделение автомобильного номера достаточно стабильно работает, например, у OpenCV. Там есть и каскад Хаара и контурное выделение. Плюс можно LBP|HOG обучить.
Пока ещё до стабильного CV решения всего и вся от гигантов далеко. Но они медленно и плавно захватывают под себя весь рынок. Да, их решения могут работать только в условиях доступа к интернету. Но ведь зачастую будет проще сделать интернет, чем запилить решение самим.

Мне было интересно посмотреть что это такое ещё весной. Но сил полноценно посидеть не хватало. Изредка что-то отдельное тестировал. Периодически приходили заказчики и спрашивали, почему нельзя применить Cloud Api. Приходилось отвечать. Или наоборот, отсылать с порога в этом направлении. И внезапно понял, что материала на статью уже достаточно. Поехали.
Что входит в Cloud Vision API
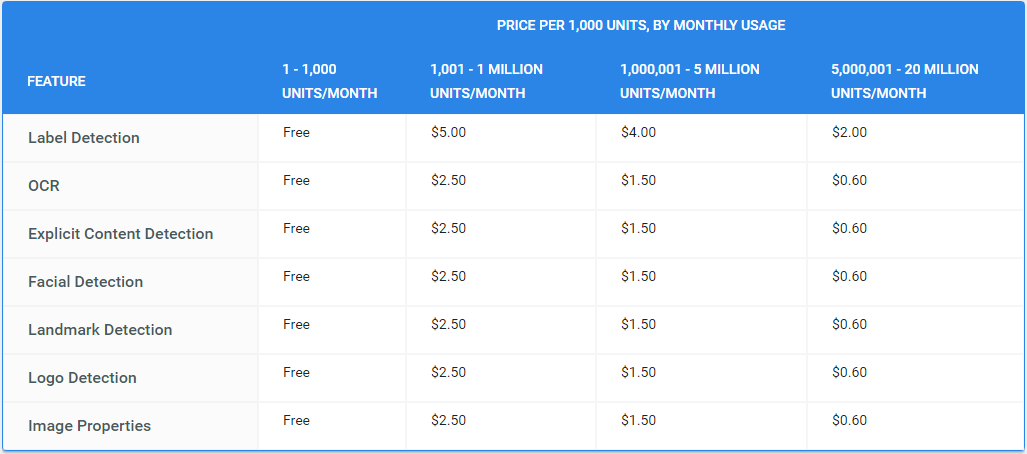
Гугл говорит много разных и красивых слов. Но это неинтересно. Всё что они умеют делать согласно их прайс-листу:
- Label Detection — детектирование класса к которому относится изображение, детектирование того, что изображено на изображении: котики, собачки, слоники, безмятежность, и.т.д.
- OCR — распознавание текста
- Explicit Content Detection — детектирование всякого нехорошего контента: вайп неграми и прочие ужасы жизни.
- Facial Detection — детектирование лиц, черт лиц, особых точек на лицах
- Landmark Detection — детектирование геолокации по фоточке
- Logo Detection — детектирование символов и значков
- Image Properties — так и не понял, что это означает
В статье я буду говорить про Label Detection, ORC, Facial Detection как про наиболее логичные ComputerVision задачки для которых мне известны аналогии/варианты. Немножко вскользь коснусь Landmark Detection.
Label Detection
Так или иначе, этой функцией от Google пользуются все. Поиск по картинке на google.com использует именно её. По сути, Label Detection даёт изображениям характеристики. Характеристикой может быть объект, изображённый на фото. Может быть стиль фотографии, например «Макро», «Портрет», «Чёрно-белое». А может что-то очень общее: «ботанический объект», «атмосферный феномен».
Кроме поиска эта функция может решить задачи:
- Сортировки базы изображений
- Подписи тэгов к каком-нибудь фотобанку
- Анализу интересов по фотографиям
- И.т.д.
Аналоги. Но, как ни странно, именно в этом направлении у google есть множество конкурентов:
Microsoft. Умеет достаточно неплохо описывать что происходит на изображении, а не только его составную часть. Нет онлайн-демки, чтобы сравнить.
- IBM куда более бедная и плохая распозновалка.
- Cloud Sight — мутное разводилово. Типо прикидываются, что у них автоматическая система, которая в 100% правильно распознаёт. В реальности сидят индусы. Хотят по 50 баксов за 800 изображений. У меня распознавало очень плохо. Но, может, просто все вышли покурить.
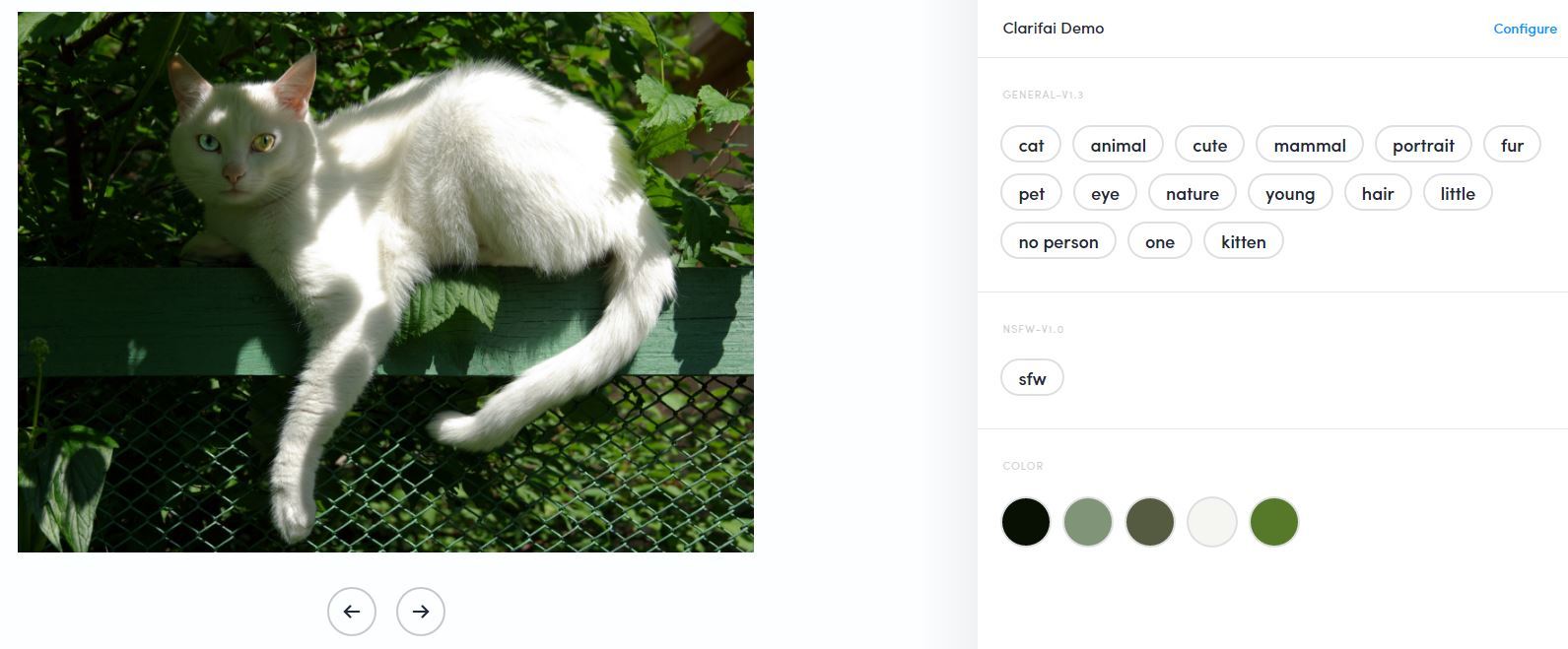
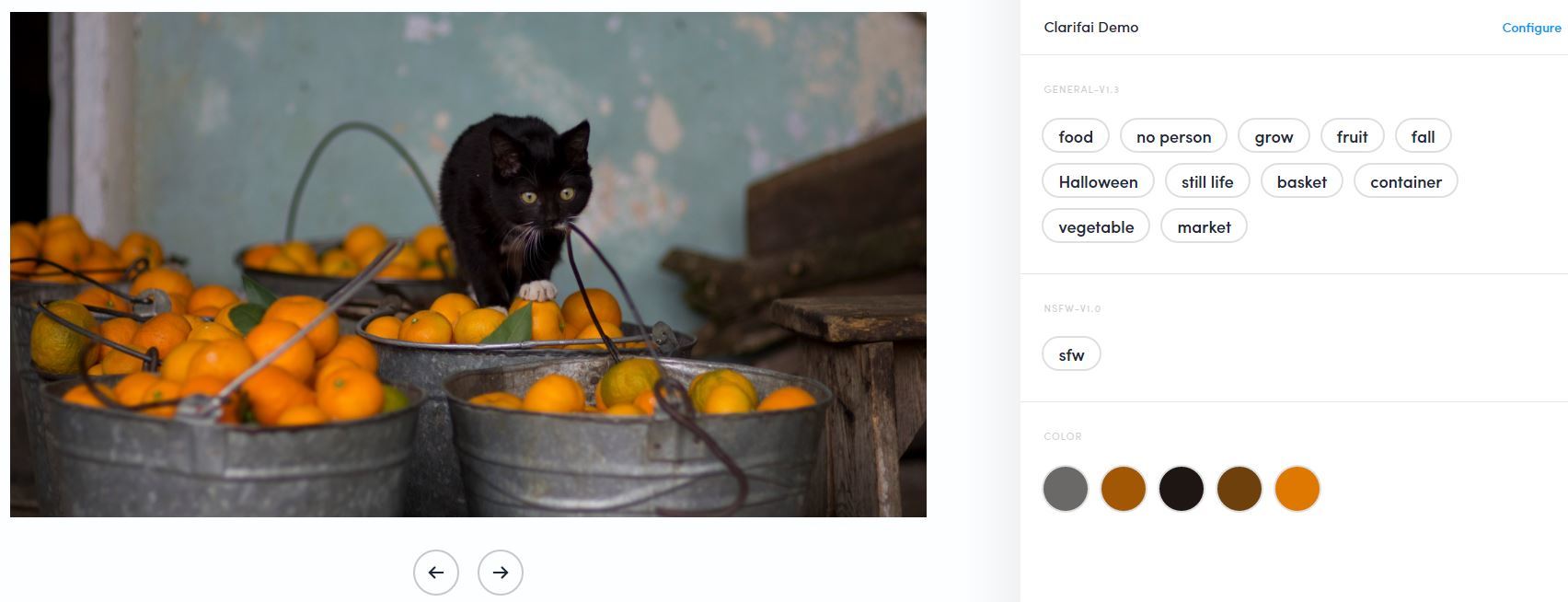
- Clarifai. Работает офигенно. Я даже не поверил. Но распознаёт и подписывает лучше всех в течении 2-3 секунд. Иногда, правда, гугл побеждал
- Есть ещё несколько более мелких игроков с хуже работающим распознаванием
- Есть обученные на ImageNet открытые сетки, которые у себя можно настроить. Дешево и сердито. Но работать будет не очень.
Вот тут есть большое и полноценное сравнение. Я приведу лишь несколько примеров:

- По мнению гугла.
- По мнению IBM.
- По мнению CloudSight.
- По мнению Clarifi.
- По мнению обученной на ImageNet GoogleNet выложенной в открытом доступе у Caffe это Сибирский Хаски.
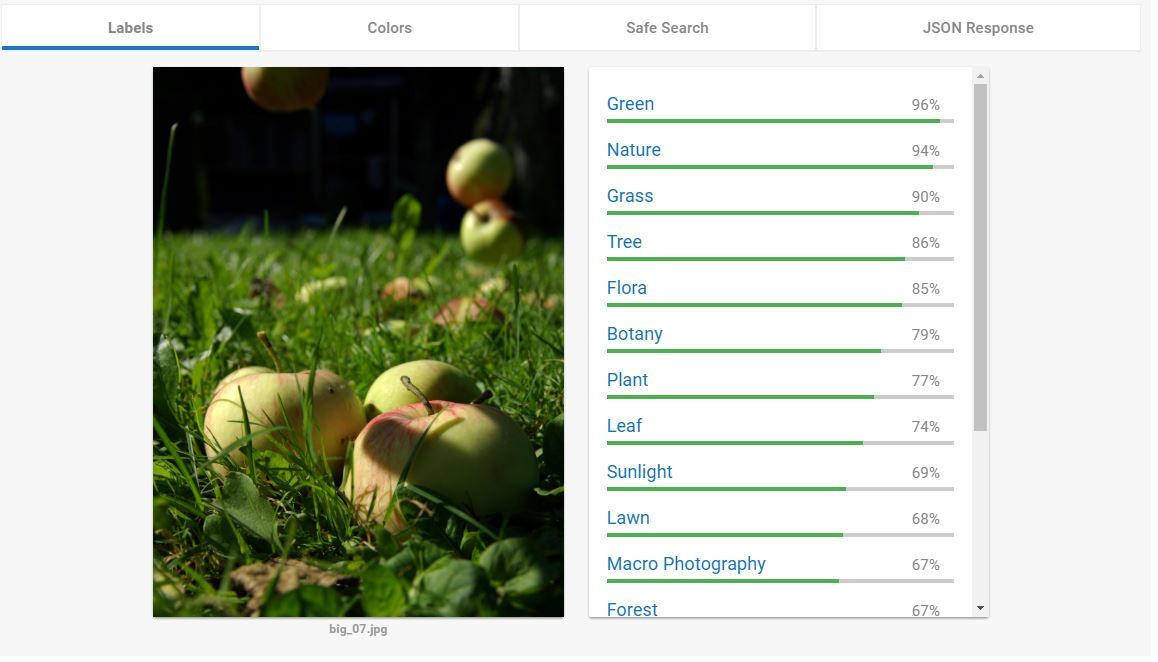
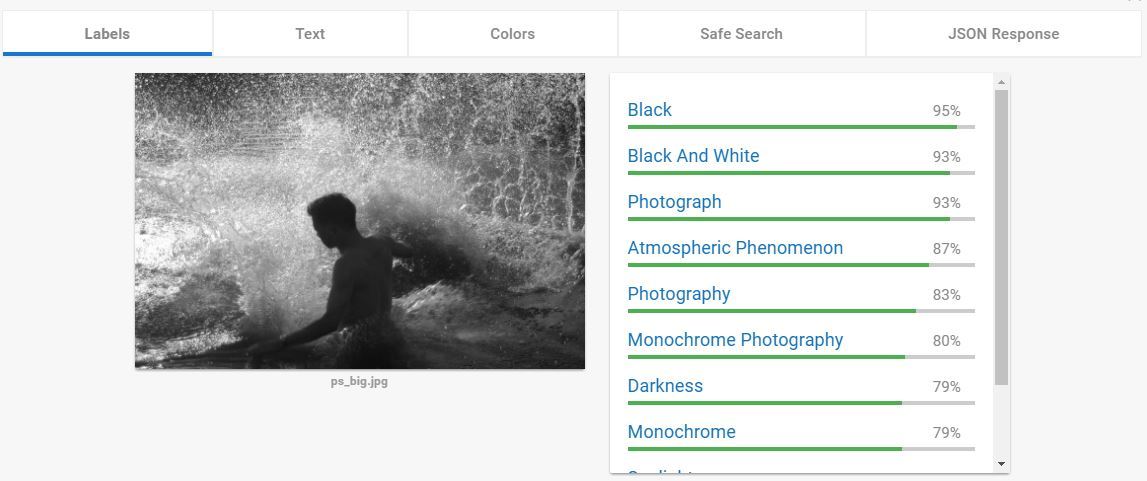
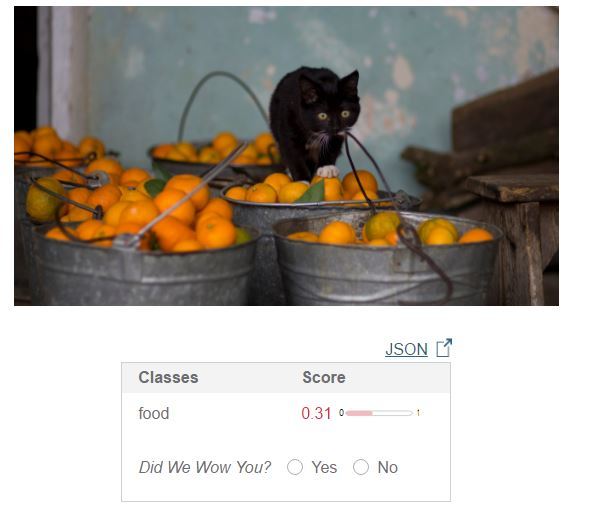
Пример когда гугл не справился: 1. Пример когда он дал неточное, на мой взгляд, описание: 1. Нет слова «яблоко». Но только cloudsight справился. Нет слова «человек» — 2. Нет слова «ворона» — 3.
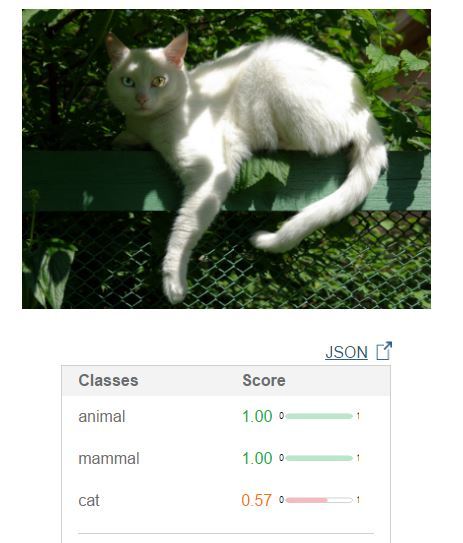
И только на этой картинке из тех, что я пробовал, гугл обошёл всех и нашёл кошку:

Остальные не справились — 1, 2, 3.
Вывод: работает неплохо. Конкурентов, идущих в ногу хоть отбавляй. В домашних условиях повторить почти невозможно.
Facial Detection
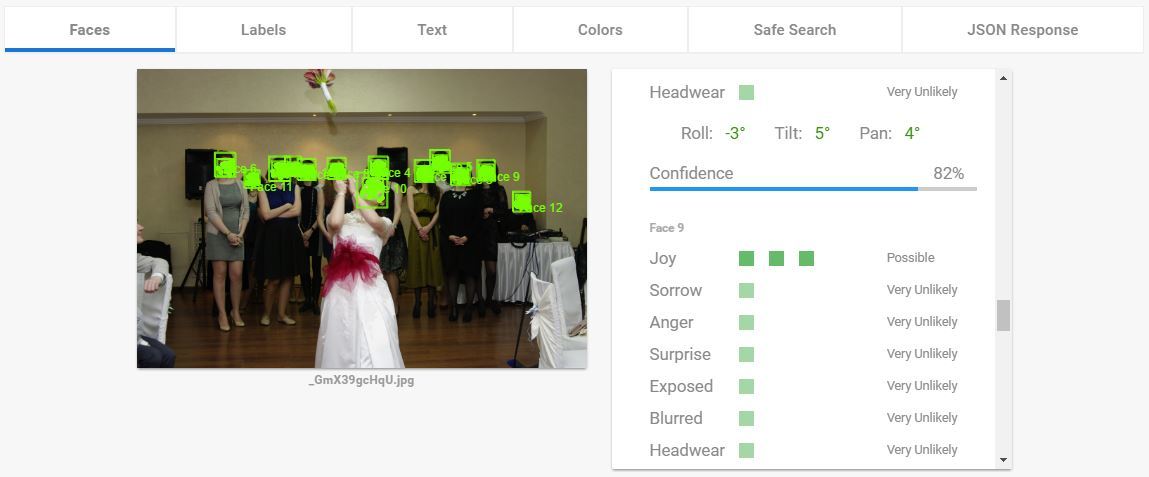
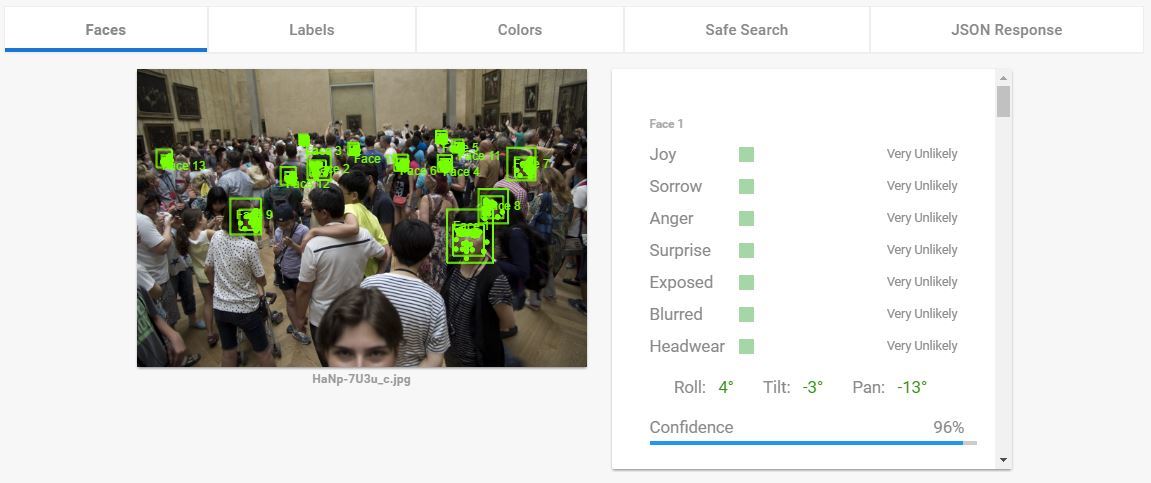
Распознавание лица. Что умеет гугл:
- Найти лицо
- Найти особые точки
- Определить выражение лица
Что он не умеет, но умеют конкуренты:
- Определить пол
- Определить возраст
- Сравнить два лица и принять решение одинаковые они или нет
Конкуренты, например вот: 1, 2, 3. А вообще десятки их.
С чем имеет смысл сравнивать Google? Например с выделением лиц каскадами Хаара, как в OpenCV, или HOG, как в dLib. У них Google выигрывает. И точки лица лучше находит, чем dlib:
Dlib:

Ещё и ещё.
Google:
Ещё и ещё.
Но при этом гугл — платный, а Dlib бесплатный. Чтобы настроить нужно одинаковое количество строчек. При этом если запариться, то можно взять вместо dlib что-то state-of-art и получить точность почти не хуже гугла.
Вообщем этот раунд Google однозначно слил.
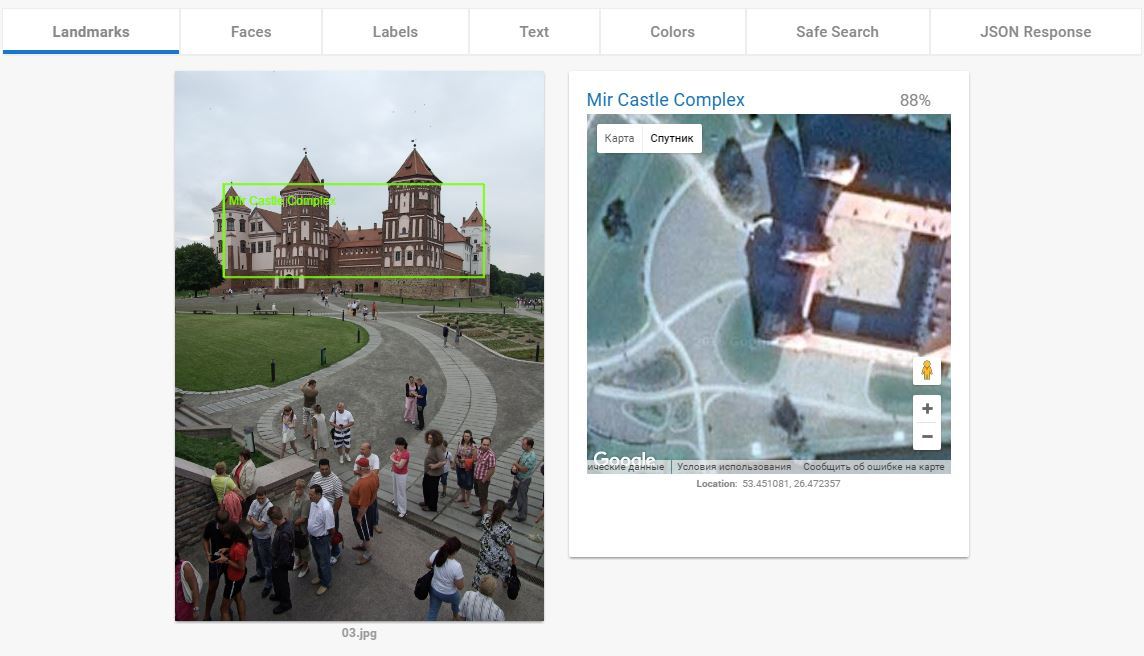
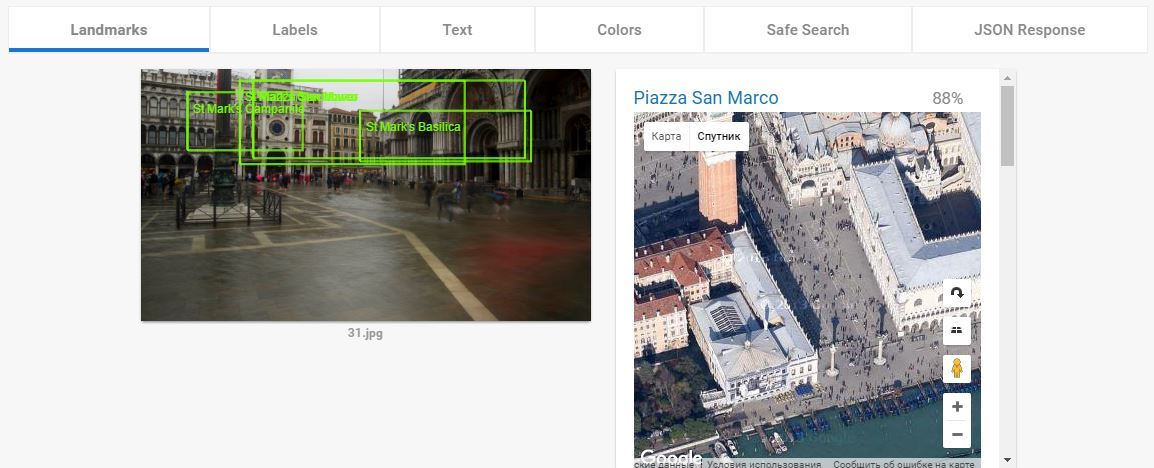
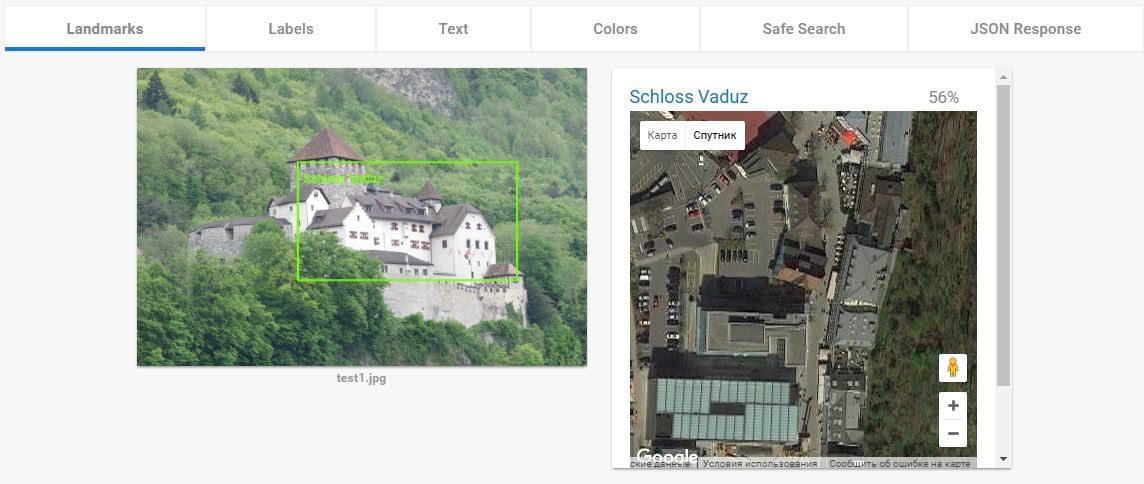
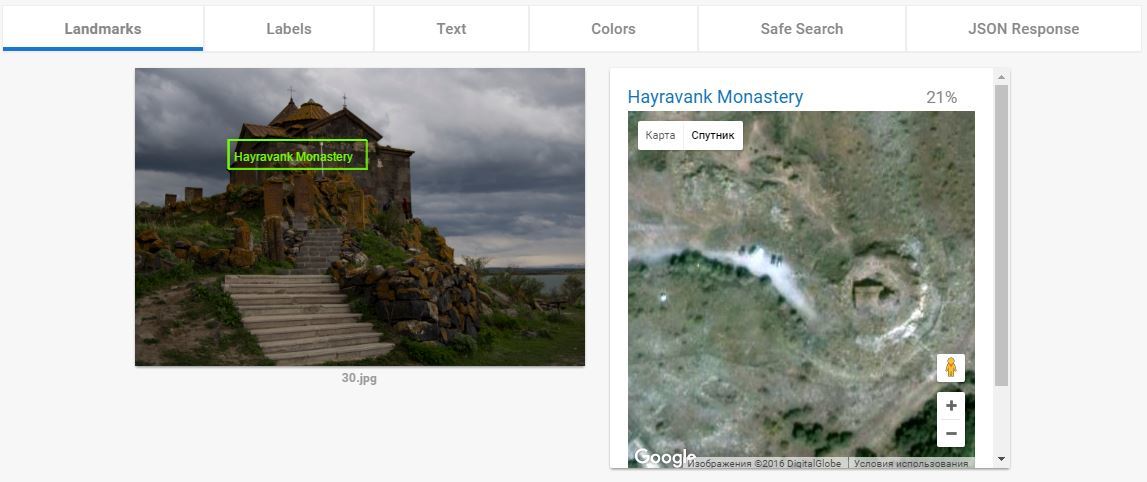
Landmark Detection
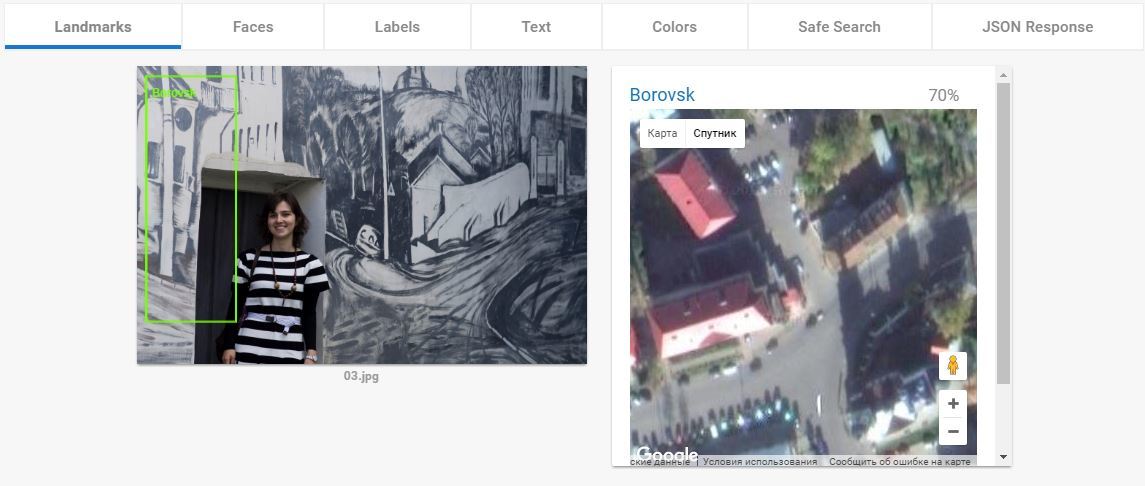
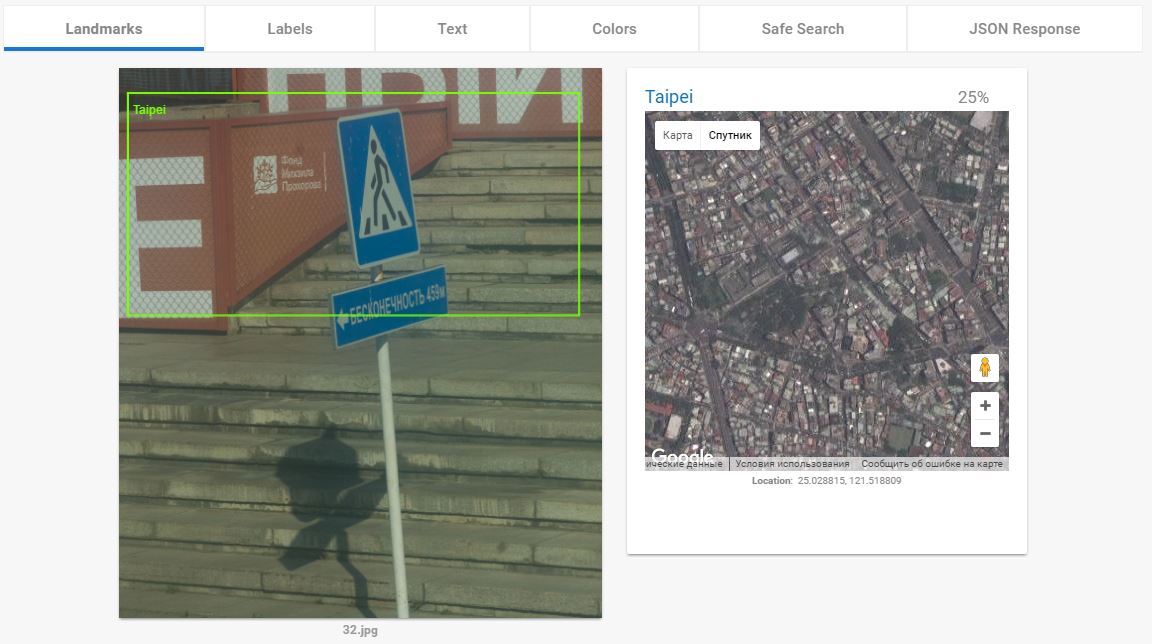
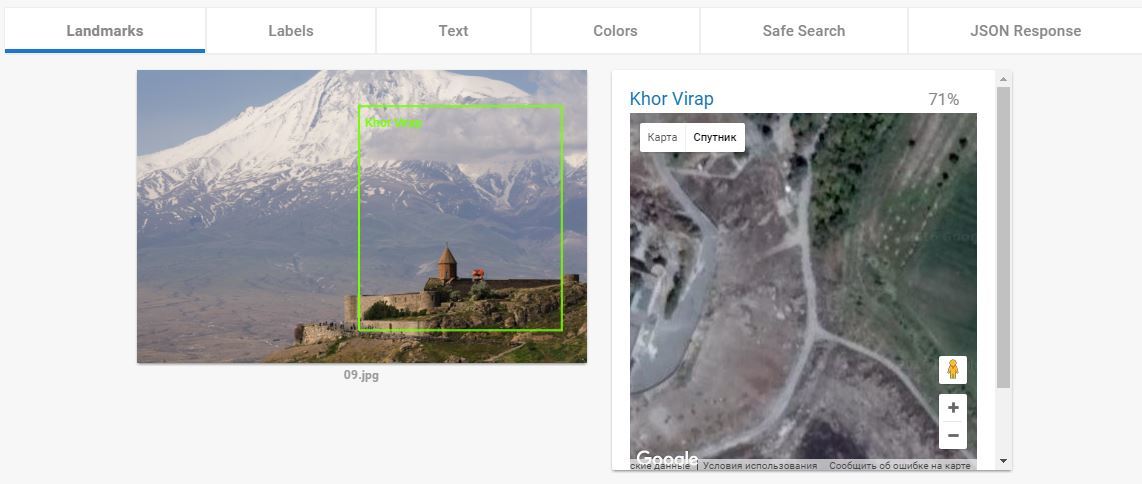
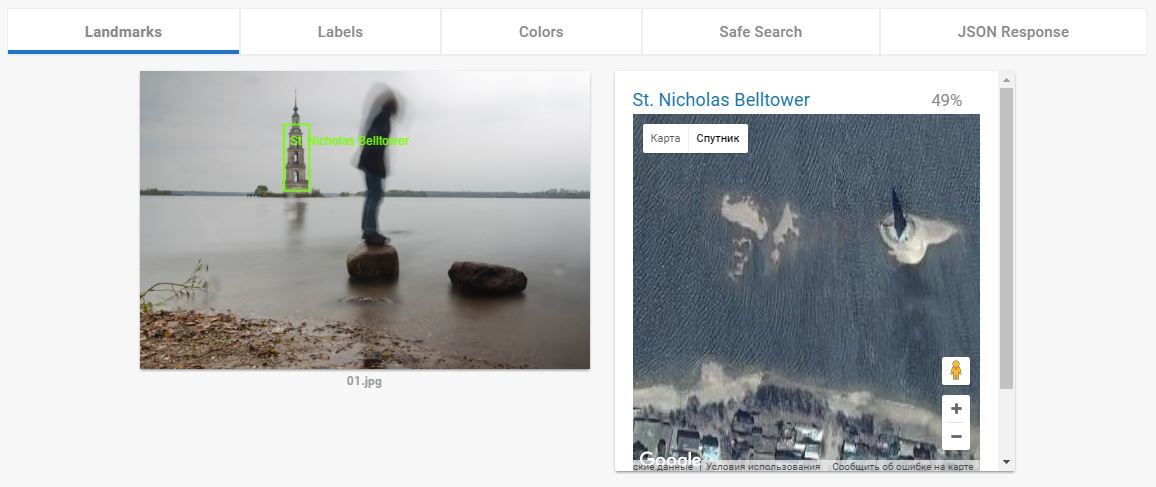
А вот этот пункт — ПЦ. и у Гугла тут нет равных. И нет аналогов. Когда я понял как это функция работает я подумал «ну, Кремль она распознает». Но не тут то было. Кроме Кремля она успешно распознаёт все мало-мальски значимые туристические объекты. Два примера которые меня выморозили:
Боровск:
Ну фиг с ним, он более-менее туристически популярный. Фотографий много. Пусть повезло.
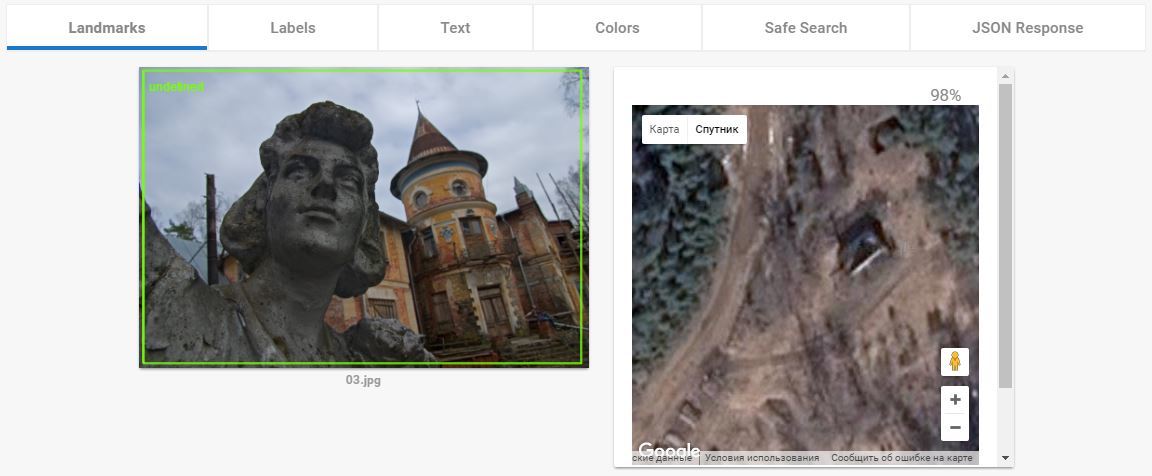
Заключье:
Усадьба-пионерлагерь затерянная между Москвой и Питером недалеко от Боровичей.
Как он это делает, не знаю. Вот ещё куча примеров: 1, 2, 3, 4, 5, 6, 7.
Сфэйлился он только один раз. Зато эпичнейшим образом:
OCR — Optical Carecter Recognition
И, наконец, переходим к самой интересной части. Именно ради этого я и полез копаться. Насколько хорошо Google распознаёт тексты. Именно это применение наиболее промышленное, именно тут десяткам производителей и потребителей было бы интересно иметь готовые решения:
- Распознавать книги
- Распознавать ценники
- Распознавать таблички
- Распознавать автономера, номера поездов, номера домов, ...
- И.т.д., применений не счесть
Попробуем сравнить то, чего добился гугл. Сравним с существующими решениями. И сравним с его единственным конкурентом как «общего распознавателя» — Microsoft.
Книги, тексты
Для текстов у Google есть сильный конкурент Abbyy. По тому, что я затестил, мне кажется, что уровень распознавания символов у них примерно на одном уровне:

Google
Perform a wireless installation (wireless models only
Before starting the installation, verify that the
wireless access point is working correctly, the computer is connected to the
network, and the product is turned on
If there is not a solid blue light on the top of the to process A
If there is a solid blue light on the top of process ⟨B 1⟩
3. Connect the USB cable between the computer and the product.
The ⟨HP⟩1 ⟨Smart Install⟩4 program (see picture should start
automatically within 30 seconds. Note: If ⟨HP⟩1 Smart Install does not
start automatically. ⟨AutoPlay⟩6 might be disabled on your computer
⟨Browse My Computer⟩5and double-click the ⟨HP⟩1 Smart Install CD drive.
Double-click the ⟨SISetup.⟩7exe file to run the program to install the
product. If you cannot find the ⟨HP⟩1 Smart Install CD drive,
use the software CD to install the product.
2. Follow the onscreen instructions.
3. When prompted to select a connection type, select the ⟨Configure⟩11
to print over ⟨Wireless Network⟩10 option.
1. From the product control panel, press and hold the cancel button X
for 5 seconds, and then release it to print a Configuration page. This
page will have an ⟨lP⟩8address in the ⟨Network Information⟩9 section.
2. At the computer, open a Web browser, type the product IP address
in the address field, and press the Enter key to open the product
embedded web server page.
3. Click the ⟨HP⟩1 Smart Install tab, and then click the Download button.
4. Follow the onscreen instructions.
Before starting the installation, verify that the
wireless access point is working correctly, the computer is connected to the
network, and the product is turned on
If there is not a solid blue light on the top of the to process A
If there is a solid blue light on the top of process ⟨B 1⟩
3. Connect the USB cable between the computer and the product.
The ⟨HP⟩1 ⟨Smart Install⟩4 program (see picture should start
automatically within 30 seconds. Note: If ⟨HP⟩1 Smart Install does not
start automatically. ⟨AutoPlay⟩6 might be disabled on your computer
⟨Browse My Computer⟩5and double-click the ⟨HP⟩1 Smart Install CD drive.
Double-click the ⟨SISetup.⟩7exe file to run the program to install the
product. If you cannot find the ⟨HP⟩1 Smart Install CD drive,
use the software CD to install the product.
2. Follow the onscreen instructions.
3. When prompted to select a connection type, select the ⟨Configure⟩11
to print over ⟨Wireless Network⟩10 option.
1. From the product control panel, press and hold the cancel button X
for 5 seconds, and then release it to print a Configuration page. This
page will have an ⟨lP⟩8address in the ⟨Network Information⟩9 section.
2. At the computer, open a Web browser, type the product IP address
in the address field, and press the Enter key to open the product
embedded web server page.
3. Click the ⟨HP⟩1 Smart Install tab, and then click the Download button.
4. Follow the onscreen instructions.
Abbyy
Perform a wireless installation (wireless models only)
Before starting the installation, verify that the
point is working correctly, the computer is connected to the
network, and the product is turned on.
If there is not a solid blue light on the top of ?t u pfod-; to process A.
If there is a solid blue light on the top of the proa ct, g< f process B.
A.
1. Connect the USB cable between the computer and the product. The HP Smart Install program (see picture above) should start automatically within 30 seconds Note: If HP Smart Install does not start automatica ly AutoPlay might be disabled on your computer Browse My Computer and double-click the HP Smart Install CD drive. Double-click the SISetup.exe file to run the program to instal the product. If you cannot find the HP Smart Install CD drive, use the software CD to install the product
2. Follow the onscreen instructions.
3. When prompted to select a connection type, select the Configure to print over Wireless Network option
1. From the product control panel, press and hold the cancel button X for 5 seconds, and then release it to print a Configuration page. This page will have an IP address in the Network Information section
2. At the computer, open a Web browser, type the product IP address in the address field, and press the Enter ke>» to open the product embedded web server page
3. Click the HP Smart Install tab, and then dick the Download button
4. Follow the onscreen instructions.
Before starting the installation, verify that the
point is working correctly, the computer is connected to the
network, and the product is turned on.
If there is not a solid blue light on the top of ?t u pfod-; to process A.
If there is a solid blue light on the top of the proa ct, g< f process B.
A.
1. Connect the USB cable between the computer and the product. The HP Smart Install program (see picture above) should start automatically within 30 seconds Note: If HP Smart Install does not start automatica ly AutoPlay might be disabled on your computer Browse My Computer and double-click the HP Smart Install CD drive. Double-click the SISetup.exe file to run the program to instal the product. If you cannot find the HP Smart Install CD drive, use the software CD to install the product
2. Follow the onscreen instructions.
3. When prompted to select a connection type, select the Configure to print over Wireless Network option
1. From the product control panel, press and hold the cancel button X for 5 seconds, and then release it to print a Configuration page. This page will have an IP address in the Network Information section
2. At the computer, open a Web browser, type the product IP address in the address field, and press the Enter ke>» to open the product embedded web server page
3. Click the HP Smart Install tab, and then dick the Download button
4. Follow the onscreen instructions.
Microsoft
Perform a wireless instanotion (wir&ss models 0+)
Before starting the installation. verify that the
pant is working correctly, the cornputer •s connected the
network. and the product is turned on.
If there is not a solid blue light on the top product.
to process A.
If there is 0 sohd blue light on the bp the product. 90 to
process B.
l. Connect the USB cable between the computer and
the product. The HP Smart Install program (see p•dure
above) should skirt automatically within 30 seconds-
Note: If HP Smart Install does not start automatically
AutoPlay rmght be disabled on your computer
Browse My Computer and double-click the
HP Smart Install CD drive. Double-click the
SISetup.exe file to run the program the
product. If you cannot find the HP Smart Install CD
drive, use the software CD to install the product.
2.
Follow the onscreen instructions.
3.
When prompted to select a connection type, select the
Configure to print over Wireless Network opt.on.
B.
. From the product control panel, press and hold the
cancel button X for 5 seconds, and then release it to
print a Configuration page. This page will have an IP
address in the Network Information section.
2. At the computer, open a Web browser, type
IP address in the address field. and press the Enter key
to open the product embedded web server page.
3. Click the HP Smart Install tab, and then click the
Download button.
4. Follow the onscreen instructions.
Before starting the installation. verify that the
pant is working correctly, the cornputer •s connected the
network. and the product is turned on.
If there is not a solid blue light on the top product.
to process A.
If there is 0 sohd blue light on the bp the product. 90 to
process B.
l. Connect the USB cable between the computer and
the product. The HP Smart Install program (see p•dure
above) should skirt automatically within 30 seconds-
Note: If HP Smart Install does not start automatically
AutoPlay rmght be disabled on your computer
Browse My Computer and double-click the
HP Smart Install CD drive. Double-click the
SISetup.exe file to run the program the
product. If you cannot find the HP Smart Install CD
drive, use the software CD to install the product.
2.
Follow the onscreen instructions.
3.
When prompted to select a connection type, select the
Configure to print over Wireless Network opt.on.
B.
. From the product control panel, press and hold the
cancel button X for 5 seconds, and then release it to
print a Configuration page. This page will have an IP
address in the Network Information section.
2. At the computer, open a Web browser, type
IP address in the address field. and press the Enter key
to open the product embedded web server page.
3. Click the HP Smart Install tab, and then click the
Download button.
4. Follow the onscreen instructions.
Видно, что реально конкурируют только Google и Abbyy. Но как только дело касается навала текста на странице, то тут побеждает Abbyy: он умеет структурировать текст, переводить таблицы, колонтитулы, и.т.д. Гугл выдаёт навал текста. Плюс у Гугла мало языков в поддержке.
Вангую, что в ближайшее время появятся стартапы, которые будут использовать Google Api для перевода, а всю структурную аналитику + сбор текста будут поверху прицеплять. Учитывая, что Abbyy хочет за перевод раз в 10 больше, чем Google — это достаточно сочный навар.
Понятно, что в сегменте текстов нет ни одного хорошего софта, который можно дома запустить. Так что переходим к следующей OCR задаче.
Ценники, прочие таблички
Важный момент — google не поддерживает другие языки, в отличие от microsoft. Но в целом оба работают, когда текст хороший, не смазанный, не наклонён, не зашумлён и не бликует:

Microsoft:
175766
AHAHAC B AHAHACE
tıııışııııııı 175T
Google:
175 AHAHAC BAHAHACE 340167 000000 900708249

Microsoft: Не распознано ничего
Google:
K)cpeacrao ainocya. AOS Aqua Aqua ban.aasa an03 Depa Pocowe 100or — 912 mov

Microsoft: по нулям
Google:
В целом, где-то 60% этикеток — текст считывается. И это на мой взгляд просто офигенный результат. Только вот как и зачем этот текст потом собирать — непонятно.
Более того, неплохо читаются даже хорошо снятые таблички. Не весь текст, конечно, но крупный точно:
оригинал

Google
Microsoft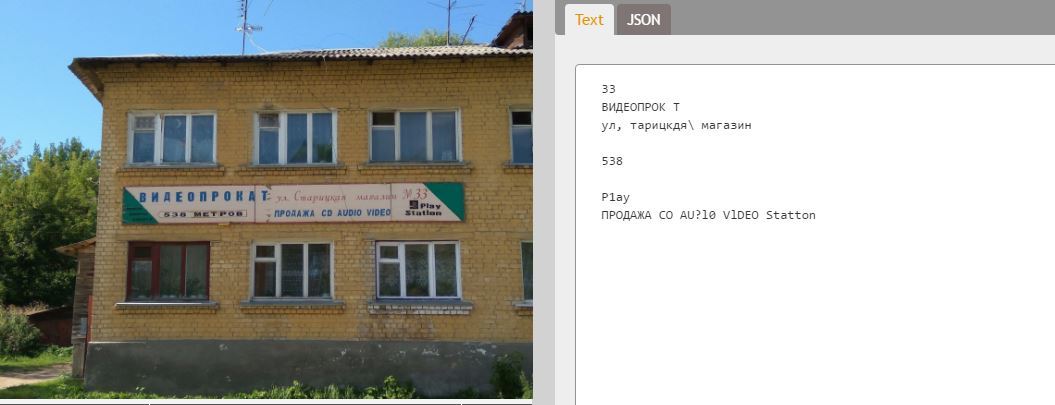
Но всё равно, тексты разного формата не очень хорошо распознаются:
Google
Microsoft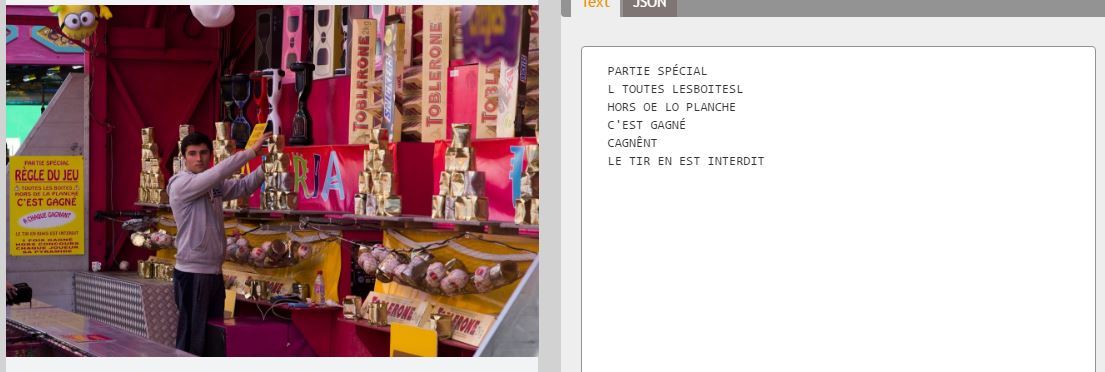
Техническая информация
А вот тут Google и Microsoft пока конкретно лажают. Из нескольких десятков проверенных автомобильных номеров Microsoft распознал процентов 20. Google процентов 60, да и те без региона. Регион распознавал только в идеальной ситуации, когда крупный номер без грязи. Как только грязь — отдельный кусок распознаёт и всё.
Плюс регулярные ошибки в 1-2 символа:
Системы распознавания номера опираются на априорную информацию => работают лучше. Хотя, конечно, для каких-то применений может и гугла хватит. Идеальный снимок в упор к номеру распознает.
Без априорной информации плохо. Ещё вариант технического зрения — номера поездов. Microsoft вообще не справился. Google дал только процентов 50 правильных. На остальных постоянно косячил:
Так что в задачах контроля качества, стабильного распознавания текста Google и Microsoft годятся только для самых простых задач.
Конечно, OpenSource решений на тему таких задач нет, но зачастую их можно своими силами решить. Перебор простых гипотез, поиск контура, и.т.д. То же выделение автомобильного номера достаточно стабильно работает, например, у OpenCV. Там есть и каскад Хаара и контурное выделение. Плюс можно LBP|HOG обучить.
Итого
- Label Detection — Google впереди, но в тесной и плотной борьбе.
- Facial Detection — Google отстал. Не понятно о чём вообще его решение.
- Landmark Detection — Обожание! Этого нигде нет!
- OCR — Настоящая баталия развивается здесь. Google начал наступать на пятки серьёзным решениям, но пока что не может обойти. При этом в области где чёткая постановка задачи отсутствует идёт впереди. Microsoft достаточно далеко позади, но пытается догнать.
Пока ещё до стабильного CV решения всего и вся от гигантов далеко. Но они медленно и плавно захватывают под себя весь рынок. Да, их решения могут работать только в условиях доступа к интернету. Но ведь зачастую будет проще сделать интернет, чем запилить решение самим.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}