— Синоним к слову «своенравный»? — раздался голос жены из соседней комнаты.
Треск клавиатуры стих и кот, воспользовавшись паузой, решительно заявил о своем жалком полуголодном существовании, видимо надеясь, что вот сейчас уж точно хозяева наконец-то оторвут свой зад от кресла и покормят несчастного.
— Дык посмотри у этого… как его…
— Да-да, я тоже забыла. Ну так что, скажешь мне синоним?
Но увы, я не ходячая энциклопедия, и даже не ее сидячий вариант, поэтому я не нашел ничего лучше, чем отправить жену гуглить словарь.

— Так это долго! Я думала, ты быстрее вспомнишь…
Кот, буридановым ослом метавшийся между мной и женой, в конце концов выбрал меня в качестве бОльшего добра (интересно — по весу или по каким-то другим параметрам?) и мне не оставалось ничего делать, как пойти на кухню покормить несчастную животинку. Попутно размышляя о том, как довести до жены тот факт, что “закладки" в браузере предназначены не для повального сохранения всех ее френдов из Вкантактика, а для запоминания действительно нужных ссылок. Все предыдущие попытки научить ее пользоваться закладками заканчивались сохранением если не френдов, то выложенную френдами музыку; но те ссылки, которые сохранил для нее я, оказывались окончательно погребены под этими завалами.
Но если она научилась пользоваться Вкантактиком и Телеграмом, значит… значит она уже умеет пользоваться Телеграмом и Вкантактиком! Эврика!
Кто-то говорил, что боты для Telegram это просто? А вот cейчас возьмем и попробуем…
Как регистрировать пользовательскую часть нового бота, вы скорее всего уже знаете. Если нет — просто добавьте @BotFather в Telegram и начните с ним разговор.
Первая проблема, с которой пришлось столкнуться при создании синоним-бота — поиск словаря синонимов.
Большинство нагугленных словарей пестрят грозными надписями и подписями с перечислением ужасных кар, которые непременно свалятся на голову несчастного, осмелившегося использовать “не по назначению” творение авторов. У которых, судя по количеству смачно расписанных угроз, имеется “копирайт на русский язык” целиком, полностью и безо всяких исключений. Причем “назначение” на таких ресурсах порой не определено нигде и никак, а объемы их словарей как правило составляют жалкие 5000…40 000 слов.
Часть словарей представляют собой алфавитные списки: первая страница со словами на букву “а”, вторая на “б” и так далее. Здесь не то что парсинг, даже загрузка адовой портянки превращается в отдельно стоящую проблему.
В конце концов мне удалось найти адекватный словарь объемом, как сказано в описании “591 тыс. слов и фразеологизмов и 2166 тыс. синонимических связей”, который к тому же свободно распространяется. Единственным его недостатком оказалось полное отсуствие API, что компенсировалось возможностью легально скачать сам словарь (правда в ужасном формате) и стабильно работающей онлайн-версией.
Мне показалось еще, что в этом конкретном словаре слишком много устаревших, вышедших из оборота слов и наоборот слишком мало современных. Но жена отметила, что о новомодных “селфи”, “кавер” и “транспарентность” через пять лет все забудут, зато “непременно”, “чуточку” и “капитулировать” будут жить в языке вечно, несмотря на проделки лингвистов от властей.
На этом месте уже сытый кот оторвался от вылизывания своих теплых аналоговых идентификаторов и утвердительно мявкнул как бы подтверждая, что он не собирается изменять классическому “мяу”, несмотря на то, что кто-то может заявить, что это “некруто” или “отстой”.
Вторая проблема — скорее всего подходящие вам имена ботов будут заняты. Я перепробовал целую кучу благозвучных коротких имен и все они оказались занятыми и — тадааам — ожидаемо мертвыми. В результате пришлось регистировать длинное и трудное для запоминания имя @synonim_bot: по какой-то причине сквоттеры до него не добрались и оно оказалось свободным.

Если вкратце, вся схема работает так:
0. Вы устанавливаете вебхук — сообщаете API Telegram адрес скрипта на своем сервере (HTTPS!), к которому он будет обращаться, когда юзер что-нибудь напишет вашему боту.
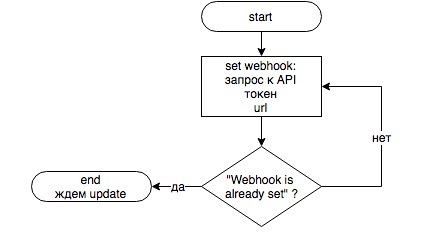
И далее реализуете свою логику. На схеме — урезанный вариант логики бота Синоним.
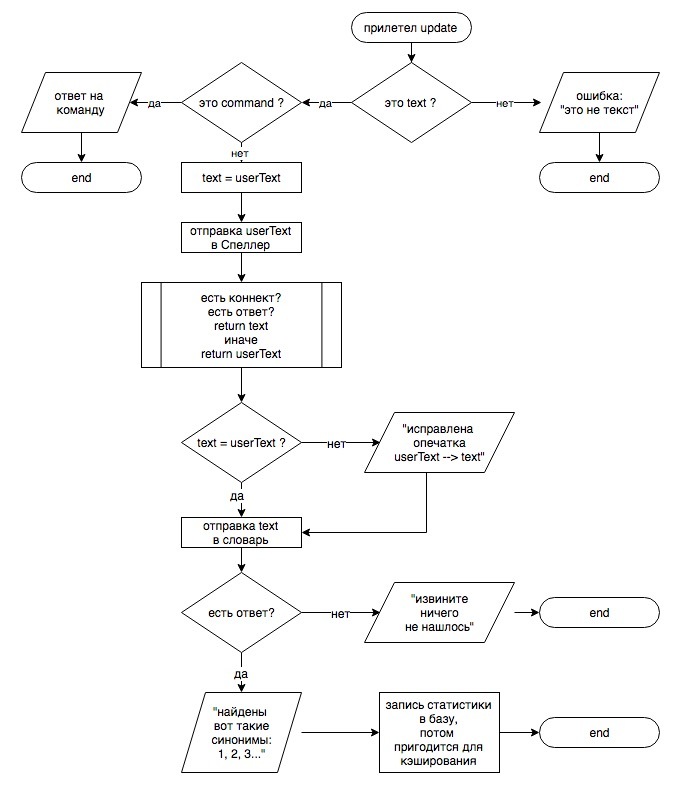
Теперь текстом:
1. Юзер пишет вашему боту что-нибудь — команду или слово.
2. API Telegram дергает ваш скрипт (он уже знает его урл из п.0) и передает ему примерно следующее:
3. Далее ваш скрипт должен разобраться что ему прислали и выдать ответ:
4. API Telegram пришлет в ответ нечто подобное:
Я понял так, что с этим ответом я могу поступать как заблагорассудится (если неверно — поправьте). Теоретически на его основе можно собирать статистику, но я собираю ее на более раннем этапе: мне так удобнее.
Пара слов об отличиях присылаемых юзером команд от, сорри за каламбур, слов.
Вы можете заготовить стандартные ответы бота на стандартные вопросы юзера, оформив это хозяйство в виде команд с помощью @BotFather — они будут видны юзеру если тот начнет строку со слэша. В скрипте бота будет достаточно отловить эти команды (API Telegram их так и передает, со слэшем спереди), выдать ответ и тут же прекратить дальнейшее выполнение скрипта.
Процедура общения бота со словарем не представляет художественной ценности и я с вашего позволения ее опущу. Единственно, что потребовалось сделать — отловить отсутствие результата, когда словарь не находил синонима на введенное слово.
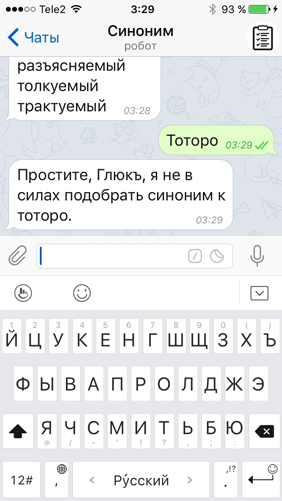
…а также случай, когда юзер вводил целую фразу — ведь словарь этого не умеет:
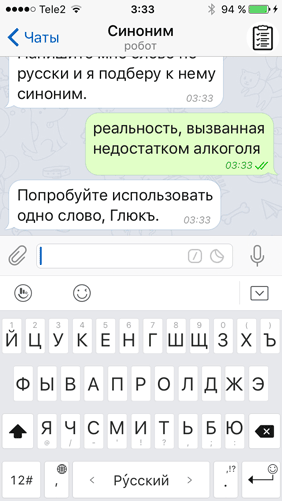
Третья проблема поджидала меня, когда ботом начали пользоваться реальные люди:
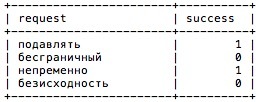
Да уж… Современные технологии порой позволяют нам творить чудеса, но начисто лишают нас познаний о фундаментальных вещах. Практически половина запрашиваемых слов содержали ошибки и опечатки и с этим нужно было что-то делать.
С робкой надеждой я сразу же кинулся к любимой Dadata, но обломался: она прекрасно выполняет свои задачи и не замахивается на весь языковой корпус. Гугление, как ни странно, не принесло никакого адекватного результата и я по-быстрому прикрутил Яндекс.Спеллер как временный вариант. Теоретически, пока он не стал платным и не потребовал нотариально заверенной копии паспорта, им тоже можно как-то пользоваться.
Здесь обнаружилась четвертая проблема: если слово набрано без ошибок, Яндекс.Спеллер не выдает ничегошеньки. Просто молчит как партизан, что немного затрудняет ведение статистики.
Было бы неплохо как-то обозначить исправление пользовательского ввода, не крича об этом во всю ивановскую. Из-за скудного html-инструментария бота я выбрал вот такой вариант оповещения (возможно, в будущем подкорректирую):
Посадил жену тестировать, попросил раздать по сети коллегам. Если бот окажется кому-то нужным, буду его развивать.
P.S.: При написании бота кот Юникс (реальный персонаж) не голодал. А также ни до, ни после.
Ссылки:
Бот Синоним: telegram.me/synonim_bot
Словарь синонимов Тришина: www.trishin.ru/left/dictionary
API Telegram: tlgrm.ru/docs/bots/api#authorizing-your-bot
Треск клавиатуры стих и кот, воспользовавшись паузой, решительно заявил о своем жалком полуголодном существовании, видимо надеясь, что вот сейчас уж точно хозяева наконец-то оторвут свой зад от кресла и покормят несчастного.
— Дык посмотри у этого… как его…
— Да-да, я тоже забыла. Ну так что, скажешь мне синоним?
Но увы, я не ходячая энциклопедия, и даже не ее сидячий вариант, поэтому я не нашел ничего лучше, чем отправить жену гуглить словарь.

— Так это долго! Я думала, ты быстрее вспомнишь…
Кот, буридановым ослом метавшийся между мной и женой, в конце концов выбрал меня в качестве бОльшего добра (интересно — по весу или по каким-то другим параметрам?) и мне не оставалось ничего делать, как пойти на кухню покормить несчастную животинку. Попутно размышляя о том, как довести до жены тот факт, что “закладки" в браузере предназначены не для повального сохранения всех ее френдов из Вкантактика, а для запоминания действительно нужных ссылок. Все предыдущие попытки научить ее пользоваться закладками заканчивались сохранением если не френдов, то выложенную френдами музыку; но те ссылки, которые сохранил для нее я, оказывались окончательно погребены под этими завалами.
Но если она научилась пользоваться Вкантактиком и Телеграмом, значит… значит она уже умеет пользоваться Телеграмом и Вкантактиком! Эврика!
Кто-то говорил, что боты для Telegram это просто? А вот cейчас возьмем и попробуем…
Как регистрировать пользовательскую часть нового бота, вы скорее всего уже знаете. Если нет — просто добавьте @BotFather в Telegram и начните с ним разговор.
@BotFather — официальный интерфейс управления ботами. Кроме него по запросам о создании ботов прогугливаются Manybot, YourBot, и еще несколько. Судя по описанию, это какие-то прокладки, т.к. при работе с ними все равно придется обращаться к @BotFather. Я не разбирался с ними и буду благодарен за разъяснение пользы от них.
Первая проблема, с которой пришлось столкнуться при создании синоним-бота — поиск словаря синонимов.
Большинство нагугленных словарей пестрят грозными надписями и подписями с перечислением ужасных кар, которые непременно свалятся на голову несчастного, осмелившегося использовать “не по назначению” творение авторов. У которых, судя по количеству смачно расписанных угроз, имеется “копирайт на русский язык” целиком, полностью и безо всяких исключений. Причем “назначение” на таких ресурсах порой не определено нигде и никак, а объемы их словарей как правило составляют жалкие 5000…40 000 слов.
Часть словарей представляют собой алфавитные списки: первая страница со словами на букву “а”, вторая на “б” и так далее. Здесь не то что парсинг, даже загрузка адовой портянки превращается в отдельно стоящую проблему.
И, разумеется, ни о каком API нет даже и речи.
В конце концов мне удалось найти адекватный словарь объемом, как сказано в описании “591 тыс. слов и фразеологизмов и 2166 тыс. синонимических связей”, который к тому же свободно распространяется. Единственным его недостатком оказалось полное отсуствие API, что компенсировалось возможностью легально скачать сам словарь (правда в ужасном формате) и стабильно работающей онлайн-версией.
Мне показалось еще, что в этом конкретном словаре слишком много устаревших, вышедших из оборота слов и наоборот слишком мало современных. Но жена отметила, что о новомодных “селфи”, “кавер” и “транспарентность” через пять лет все забудут, зато “непременно”, “чуточку” и “капитулировать” будут жить в языке вечно, несмотря на проделки лингвистов от властей.
В который раз убеждаюсь, что у хорошего продукта как правило ужасная упаковка, а за красивыми “ле-ендингами” с большими кнопками и воздушными полями прячется обыкновенное фуфло.
На этом месте уже сытый кот оторвался от вылизывания своих теплых аналоговых идентификаторов и утвердительно мявкнул как бы подтверждая, что он не собирается изменять классическому “мяу”, несмотря на то, что кто-то может заявить, что это “некруто” или “отстой”.
Вторая проблема — скорее всего подходящие вам имена ботов будут заняты. Я перепробовал целую кучу благозвучных коротких имен и все они оказались занятыми и — тадааам — ожидаемо мертвыми. В результате пришлось регистировать длинное и трудное для запоминания имя @synonim_bot: по какой-то причине сквоттеры до него не добрались и оно оказалось свободным.

Если вкратце, вся схема работает так:
0. Вы устанавливаете вебхук — сообщаете API Telegram адрес скрипта на своем сервере (HTTPS!), к которому он будет обращаться, когда юзер что-нибудь напишет вашему боту.
И далее реализуете свою логику. На схеме — урезанный вариант логики бота Синоним.
Я намеренно не привожу ни строчки кода, дабы исключить холивары и взаимополивание. Пишите на том, что знаете — боту все равно.
Теперь текстом:
1. Юзер пишет вашему боту что-нибудь — команду или слово.
2. API Telegram дергает ваш скрипт (он уже знает его урл из п.0) и передает ему примерно следующее:
{
"update_id":12345678,
"message":
{
"message_id":1234,
"from":
{
"id":0123456789,
"first_name":"Vasya",
"username":"vapupkin"
},
"chat":
{
"id":1234567890,
"first_name":"Vasya",
"username":"vapupkin",
"type":"private"
},
"date": 1451606400,
"text":"preved"
}
}
3. Далее ваш скрипт должен разобраться что ему прислали и выдать ответ:
https://api.telegram.org/bot123456789:boLshoiogRomnIycOLlaideR/sendMessage?chat_id=1234567890&text=Taki%20PrevedНаверное правильнее будет переписать это в POST дабы иметь запас по размеру отправляемого текста, но в моем случае вполне хватает и этого: все-таки мессенджеры не предназначены для лонгридов.
4. API Telegram пришлет в ответ нечто подобное:
{
"ok":true,
"result":
{
"message_id”:1234,
"from":
{
"id”:9876543210,
"first_name":"Бот",
"username":"my_bot"
},
"chat":
{
"id": 0123456789,
"first_name":"Vasya",
"username":"vapupkin",
"type":"private"
},
"date": 1451606500,
"text":"Taki Preved"
}
}
Я понял так, что с этим ответом я могу поступать как заблагорассудится (если неверно — поправьте). Теоретически на его основе можно собирать статистику, но я собираю ее на более раннем этапе: мне так удобнее.
Пара слов об отличиях присылаемых юзером команд от, сорри за каламбур, слов.
Вы можете заготовить стандартные ответы бота на стандартные вопросы юзера, оформив это хозяйство в виде команд с помощью @BotFather — они будут видны юзеру если тот начнет строку со слэша. В скрипте бота будет достаточно отловить эти команды (API Telegram их так и передает, со слэшем спереди), выдать ответ и тут же прекратить дальнейшее выполнение скрипта.

Процедура общения бота со словарем не представляет художественной ценности и я с вашего позволения ее опущу. Единственно, что потребовалось сделать — отловить отсутствие результата, когда словарь не находил синонима на введенное слово.

…а также случай, когда юзер вводил целую фразу — ведь словарь этого не умеет:
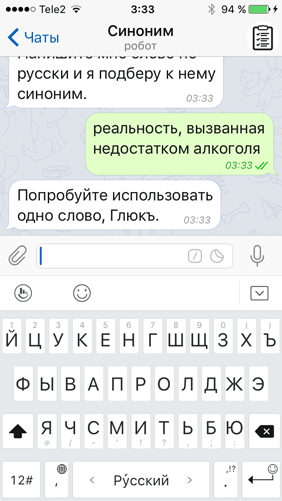
Третья проблема поджидала меня, когда ботом начали пользоваться реальные люди:
Да уж… Современные технологии порой позволяют нам творить чудеса, но начисто лишают нас познаний о фундаментальных вещах. Практически половина запрашиваемых слов содержали ошибки и опечатки и с этим нужно было что-то делать.
С робкой надеждой я сразу же кинулся к любимой Dadata, но обломался: она прекрасно выполняет свои задачи и не замахивается на весь языковой корпус. Гугление, как ни странно, не принесло никакого адекватного результата и я по-быстрому прикрутил Яндекс.Спеллер как временный вариант. Теоретически, пока он не стал платным и не потребовал нотариально заверенной копии паспорта, им тоже можно как-то пользоваться.
Буду благодарен за подсказку: требуется бесплатный сервис проверки орфографии в русском языке с API.
Здесь обнаружилась четвертая проблема: если слово набрано без ошибок, Яндекс.Спеллер не выдает ничегошеньки. Просто молчит как партизан, что немного затрудняет ведение статистики.
Было бы неплохо как-то обозначить исправление пользовательского ввода, не крича об этом во всю ивановскую. Из-за скудного html-инструментария бота я выбрал вот такой вариант оповещения (возможно, в будущем подкорректирую):

Посадил жену тестировать, попросил раздать по сети коллегам. Если бот окажется кому-то нужным, буду его развивать.
P.S.: При написании бота кот Юникс (реальный персонаж) не голодал. А также ни до, ни после.
Пруф

Ссылки:
Бот Синоним: telegram.me/synonim_bot
Словарь синонимов Тришина: www.trishin.ru/left/dictionary
API Telegram: tlgrm.ru/docs/bots/api#authorizing-your-bot
