
За последнее десятилетие мы разработали и усовершенствовали несколько методов, которые позволяют дизайну баз данных эволюционировать параллельно с разработкой приложения.
Это очень ценное свойство гибких методологий. Методы опираются на применение непрерывной интеграции и автоматизированного рефакторинга к разработке баз данных, а также на тесное взаимодействие между разработчиками приложений и администраторами БД. Эти методы работают как в препродакшн и в уже стартовавших системах, в свежих проектах без легаси, так и в унаследованных системах.
В последнее десятилетие мы наблюдаем рост гибких методологий. По сравнению со своими предшественниками, они изменяют требования к дизайну баз данных. Одно из важнейших среди требований – идея эволюционной архитектуры. В гибком проекте вы предполагаете, что не можете заранее поправить требования системы. В результате, иметь детализированную, четкую стадию дизайна в начале проекта становится непрактично. Архитектура системы должна эволюционировать одновременно с итерациями софта. Гибкие методы, в частности, экстремальное программирование (XP), имеют набор методик, которые делают эту эволюционную архитектуру практичной.
Когда мы и наши коллеги из ThoughtWorks стали делать agile-проекты, мы поняли, что нам нужно решать задачу эволюции баз данных, для поддержки эволюции архитектуры. Мы начали примерно в 2000 году с проекта, база данных которого в итоге дошла почти до 600 таблиц. В процессе работы над этим проектом мы разработали методы, которые позволили поменять схему и удобно мигрировать существующие данные. Это сделало базу данных полноценно гибкой и эволюционируемой. Мы описали методы в более ранних версиях этой статьи, и её содержание вдохновило другие команды и toolsets. С тех пор мы использовали и дальше развивали методы в сотнях проектов по всему миру, от небольших групп до крупных многонациональных программ. Мы давно собирались обновить эту статью, и теперь такая возможность появилась.
Джен реализует новую юзер-историю
Для того, чтобы получить представление о том, как все это работает, давайте набросаем в общих чертах что происходит, когда разработчик (Джен) пишет код, чтобы реализовать новую пользовательскую историю. История описывает пользователя, у которого есть возможность видеть, искать и обновлять позицию, номер партии и серийный номер товаров, находящихся в наличии. Глядя на схему базы данных, Джен видит, что в настоящее время нет никаких полей в таблице наличия товара, только одно поле inventory_code, которое является конкатенацией (объединением) этих трёх полей. Она должна разделить единый код на три отдельных поля: location_code, batch_number и serial_number.
Вот шаги, которые она должна совершить:
- Добавить новые столбцы к таблице inventory в уже существующей схеме.
- Написать скрипт миграции и разделить данные из столбца inventory_code по созданным столбцам: location_code, batch_number и serial_number.
- Изменить код приложения для использования новых столбцов.
- Изменить все части кода базы данных, такие как выборки, хранимые процедуры и триггеры, чтобы они использовали новые столбцы.
- Изменить все индексы, базируемые на inventory_code.
- Закомитить скрипт миграции базы данных и все изменения кода приложения в систему управления версиями
Для добавления новых колонок и переноса данных Джен пишет скрипт миграции на SQL, который она может сравнить с текущей схемой. Это и одновременно изменит схему и перенесёт все имеющиеся данные о товарах в наличии.
ALTER TABLE inventory ADD location_code VARCHAR2(6) NULL;
ALTER TABLE inventory ADD batch_number VARCHAR2(6) NULL;
ALTER TABLE inventory ADD serial_number VARCHAR2(10) NULL;
UPDATE inventory SET location_code = SUBSTR(product_inventory_code,1,6);
UPDATE inventory SET batch_number = SUBSTR(product_inventory_code,7,6);
UPDATE inventory SET serial_number = SUBSTR(product_inventory_code,11,10);
DROP INDEX uidx_inventory_code;
CREATE UNIQUE INDEX uidx_inventory_identifier
ON inventory (location_code,batch_number,serial_number);
ALTER TABLE product_inventory DROP COLUMN inventory_code;Джен запускает скрипт миграции в локальной копии базы данных на своём компьютере. Затем она переходит к обновлению кода, чтобы использовать новые колонки. В процессе она применяет существующий набор тестов к новому коду, чтобы обнаружить любые изменения в поведении приложения. Некоторые тесты, те, которые покрывали комбинированную колонку, нужно обновить. Возможно, нужно добавить ещё какие-то тесты. После того, как Джен сделала всё это, и приложение прошло все тесты на её компьютере, она грузит изменения в общий проектный репозиторий, который мы называем mainline. Эти изменения включают в себя скрипты миграции и изменения кода приложения.
Если Джен не слишком хорошо знакома с внесением этих изменений, ей повезло, что они универсальны для баз данных. Поэтому она может заглянуть в книгу про рефакторинг баз данных. В сети есть справка по этой теме.
После того, как изменения оказываются в mainline, они подхватываются сервером непрерывной интеграции. Он запускает скрипты миграции на копии базы данных в mainline, а затем все тесты приложения. Если всё проходит успешно, этот процесс будет повторятся на каждом этапе Deployment Pipeline, включая тестирование (QA) и staging. Тот же самый код, наконец, запустится в production, на этот раз обновляя реальную схему базы данных и данные.
В небольшой пользовательской истории, как в примере, только одна миграция базы данных, крупные пользовательские истории часто разбиваются на несколько отдельных миграций для каждого изменения в БД. У нас правило — делать каждое изменение БД насколько возможно маленьким. Чем меньше, тем легче получить правильный результат, а любые ошибки быстро обнаружить и отладить. Миграции, как в примере, легко совмещать, так что лучше делать много мелких.
Работа с изменениями
Поскольку гибкие методы стали популярны в начале 2000-х годов, одна из их наиболее очевидных характеристик это склонность к изменениям. Перед тем, как они появились, чаще всего представления о софте были такими: понимание требований на раннем этапе, установление требований, использование требований как основы для дизайна, исполнение дизайна, а затем исполнение проекта. Этот управляемый планом цикл часто называют (обычно с насмешкой) водопадным подходом.
Такие подходы используют в попытках свести к минимуму изменения, что выливается в чрезмерную предварительную работу. А когда предварительная работа закончена, изменения приводят к серьезным проблемам. В результате, если требования меняются, эти подходы ведут к неисправностям, а пересмотр требований — головная боль для таких процессов.
Гибкие процессы имеют другие методические подходы к изменениям. Они дружелюбны к изменениям даже на поздних стадиях разработки проекта. Изменения контролируются, но характер процесса делает их вероятными настолько, насколько возможно. Отчасти — это ответ на встроенную нестабильность требований многих проектов, отчасти — концепция более качественной поддержки динамических бизнес-структур и помощи им с изменениями, в условиях давления конкурентов.
Для того, чтобы поставить этот процесс на колёса, вам нужно изменить отношение к дизайну. Вместо того чтобы думать о дизайне как о фазе, которая заканчивается перед фазой конструирования, вы смотрите на дизайн, как на непрерывный процесс, который чередуется с конструированием, тестированием и даже доставкой. Такой контраст между плановым и эволюционным проектированием.
Один из важнейших вкладов гибких методов — подходы, при которых у эволюционного дизайна есть возможность держать работу под контролем. И вместо привычного хаоса, который часто берёт верх, когда конструирование не запланировано заранее, эти методы рождают способы контроля эволюционного дизайна и делают их практичными.
Важная часть этого подхода — итеративная разработка, когда полный жизненный цикл софта запускается много раз за всё существование проекта. Гибкие процессы запускают полный жизненный цикл в каждой итерации, завершая итерацию рабочим, протестированным, интегрированным кодом и небольшим подмножеством требований конечного продукта. Эти итерации короткие — от нескольких часов до нескольких недель: более опытные команды используют более короткие итерации.
Хотя интерес к этим методам и их использование возросли, один из самых важных вопросов — как использовать эволюционный дизайн для баз данных. Продолжительное время группа людей из сообщества баз данных воспринимала дизайн БД как что-то обязательно требующее предварительного планирования. Изменение схемы базы данных в конечных фазах разработки, как правило, приводит к распространяющимся дефектам приложения. Кроме того, изменение схемы после деплоя приводит к болезненной миграции данных.
В течение последних десяти с половиной лет, мы участвовали во многих крупных проектах, которые использовали эволюционный дизайн БД и он успешно работал. Некоторые проекты включали в себя более 100 человек в нескольких рабочих точках по всему миру. Другие — более полумиллиона строк кода, более 500 таблиц. У некоторых из них в production было несколько версий приложения и каждое требовало круглосуточного обслуживания. В ходе этих проектов нам попадались итерации длительностью в месяц и в неделю, но более короткие итерации работали лучше. Методы, описанные ниже, позволили сделать это возможным.
С первых дней мы пытались распространить методики на большее количество своих проектов. Мы получали больше опыта от покрытия большего количества случаев, и теперь все наши проекты используют этот подход. Мы также черпаем вдохновение, идеи и опыт у других людей, пользующихся этим подходом.
Ограничения
Прежде чем мы начнём разбираться с подходами, хочу сказать, что мы не решили все проблемы эволюционного дизайна баз данных.
У нас были проекты с сотнями розничных магазинов, с их собственными базами данных, каждую из которых нужно было обновлять. Но мы еще не рассматривали ситуацию, когда у большой группы сайтов есть много настроек. Как пример, можно рассмотреть приложение для малого бизнеса, которое позволяет делать настройки схемы, задеплоенной в тысячах различных небольших компаниях.
Все чаще мы видим, как люди используют множество схем как часть единой среды БД. Мы работали с проектами, использовавшими по нескольку подобных схем, но десятки или сотни — не пробовали. Мы прогнозируем в течение следующих нескольких лет разобраться с этой ситуацией.
Мы не считаем, что эти проблемы неразрешимы. В конце концов, когда мы написали оригинальную версию этой статьи, мы не избавились от проблемы беспрерывной работы или интеграции БД. Мы нашли способы как с ними справляться и надеемся, что расширим границы эволюционного дизайна БД. Но пока этого не произошло, мы не будем утверждать, что не способны решить подобные задачи.
Методики
Наш подход к эволюционному дизайну БД построен на нескольких важных методиках.
Администраторы БД тесно взаимодействуют с разработчиками
Один из принципов гибких методов — работники с разными навыками и опытом должны очень тесно взаимодействовать друг с другом. Они не должны общаться только через официальные встречи и документы. Им нужно контактировать и работать друг с другом всё время. Это влияет на всех: аналитиков, руководителей проекта, экспертов в предметной области, разработчиков… и администраторов БД.
В каждой задаче, над которой трудится разработчик, потенциально нужна помощь администратора БД. И разработчики, и администраторы должны предусматривать, будут ли входить значительные изменения схемы базы данных в задачу разработки. Если да, то разработчик должен проконсультироваться с администратором БД, чтобы решить, как вносить изменения. Разработчик знает, какая новая функциональность требуется, а у администратора есть единое представление данных текущего приложения и других окружающих приложений. Часто разработчики имеют представление о приложении, над которым работают, но не имеют обо всех остальных upstream или downstream зависимостях схемы. Даже если это единое приложение БД, в нём могут содержаться зависимости, о которых разработчик не в курсе.
В любой момент разработчик может обратиться к администратору и попросить разобраться в изменениях базы данных. Когда используется парный стиль, разработчик узнает о том, как работает база данных, а администратор изучает особенности требований к базе данных. Чаще всего вопрос — обращаться по поводу изменений к АБД или нет — лежит на разработчике, если его беспокоит влияние изменений на базу данных. Но АБД тоже принимают инициативу. Когда они видят требования, которые, по их мнению, могут оказать значительное влияние на данные, они могут обращаться к разработчикам, чтобы обсудить воздействие на БД. АБД может также затронуть миграции, поскольку они зафиксированы в системе управления версиями. Так как обратная миграция всех раздражает, мы выигрываем от каждой маленькой миграции, которую проще реверсировать.
Чтобы сделать это возможным, АБД должен охотно идти навстречу и быть в доступности. Нужно, чтобы разработчик мог легко нагрянуть и задать несколько вопросов в слаке или хипчате — любом средстве связи, которое используют разработчики. Когда вы организуете рабочее пространство для проекта, постарайтесь чтобы АБД и разработчики сидели ближе друг к другу, чтобы им было легко контактировать. Убедитесь в том, что администраторы в курсе любых встреч, связанных с дизайном приложения, чтобы они могли легко подтянуться. В рабочих микроклиматах нам часто встречаются люди, создающие барьеры между администраторами БД и функциями разработки. Чтобы эволюционный процесс дизайна БД работал, нужно стереть эти барьеры.
Все артефакты базы данных are version controlled with application code
Разработчики значительно выигрывают от использования контроля версий всех своих артефактов: кода приложения, функциональных и модульных тестов, кода, вроде скриптов сборки, Chef или Puppet скриптов, используемых для создания рабочего окружения.
Рис 1: Все артефакты базы данных в системе управления версиями, вместе с другими артефактами проекта
Точно так же все артефакты базы данных должны быть в системе управления версиями, в том же репозитории, который используется всеми остальными. Преимущества у этого:
- Всё находится в одном месте и любому участнику проекта легко найти нужное.
- Каждое изменение базы данных сохраняется, что позволяет легко сделать проверку при возникновении любой проблемы. Мы можем отследить любой деплой базы данных и найти требуемое состояние схемы и вспомогательных данных.
- Мы не делаем деплои, если база данных не синхронизируется с приложением, что приводит к возврату ошибок и обновлению данных.
- Мы можем легко создавать новые среды: для разработки, тестирования, и конечно production. Все, что нужно для создания работающей версии приложения, должно находиться в одном репозитории, чтобы можно было быстро склонировать и собрать.
Все изменения базы данных — это миграции
Во многих организациях существует процесс, в котором разработчики вносят изменения в базу данных с помощью инструментов редактирования схемы и ad-hoc SQL для данных. После того, как они заканчивают разработку, администраторы БД сравнивают разрабатываемую базу данных с базой данных в production и вносят туда соответствующие изменения, переводя приложение в рабочее состояние. Но в production это делать сложно, потому что контекстный индикатор изменений, тот что был в разработке, потерялся. Нужно снова разбираться, зачем были сделаны изменения, но уже другой группе людей.
Чтобы этого избежать, мы предпочитаем фиксировать изменения во время разработки и сохранять их как артефакт первого уровня, который можно потом протестировать и задеплоить с тем же процессом и контролем, как для изменений в коде приложения. Мы делаем это, отображая каждое изменение в базе данных, как скрипт миграции базы данных, которые как и изменения в коде приложения, находятся в системе контроля версий. Эти скрипты миграции включают в себя: изменения схемы, изменения кода базы данных, обновления ссылочных данных, обновления данных о транзакциях и исправление проблем с данными из-за багов в production.
Вот изменение, добавка min_insurance_value и max_insurance_value к таблице equipment_type, с несколькими дефолтными значениями.
ALTER TABLE equipment_type ADD(
min_insurance_value NUMBER(10,2),
max_insurance_value NUMBER(10,2)
);
UPDATE equipment_type SET
min_insurance_value = 3000,
max_insurance_value = 10000000; Это изменение добавляет набор постоянных данных к таблицам location и equipment_type.
-- Create new warehouse locations #Request 497
INSERT INTO location (location_code, name , location_address_id,
created_by, created_dt)
VALUES ('PA-PIT-01', 'Pittsburgh Warehouse', 4567,
'APP_ADMIN' , SYSDATE);
INSERT INTO location (location_code, name , location_address_id,
created_by, created_dt)
VALUES ('LA-MSY-01', 'New Orleans Warehouse', 7134,
'APP_ADMIN' , SYSDATE);
-- Create new equipment_type #Request 562
INSERT INTO equipment_type (equipment_type_id, name,
min_insurance_value, max_insurance_value, created_by, created_dt)
VALUES (seq_equipment_type.nextval, 'Lift Truck',
40000, 4000000, 'APP_ADMIN', SYSDATE);При работе с помощью такого метода, нам никогда не приходится использовать инструменты редактирования схем, типа Navicat, DBArtisanor или SQL Developer, и мы никогда не запускаем беспроводные DDL или DML, чтобы добавить постоянные данные или исправить ошибки. Кроме обновлений в базе данных, которые происходят из-за приложений, все изменения делаются миграциями.
Называя миграции наборами команд SQL, мы рассказываем только часть истории, но для того, чтобы правильно их применять, нам нужно что-то ещё.
- Каждая миграция требует уникальной идентификации.
- Нужно отслеживать, какие миграции были применены к базе данных
- Нужно управлять ограничениями последовательности действий между миграциями. В приведенном выше примере мы должны применить в начале миграцию ALTER TABLE, иначе вторая миграция не сможет добавить вставку equipment type.
Мы обрабатываем эти требования, присваивая каждой миграции порядковый номер. Он действует как уникальный идентификатор и гарантирует, что можно поддерживать порядок, в котором они применяются в базе данных. Когда разработчик создает миграцию, он помещает SQL в текстовый файл внутри папки миграции, в пределах репозитория управления версиями проекта. Он смотрит на самый высокий используемый в данный момент номер в папке миграции, и использует это число вместе с описанием, чтобы дать имя файлу. Самая ранняя пара миграций может быть названа 0007_add_insurance_value_to_equipment_type.sql и 0008_data_location_equipment_type.
Для того, чтобы отслеживать применение миграций в базе данных, мы используем changelog таблицу. Фреймворки миграции БД, как правило, создают эту таблицу и автоматически обновляют её каждый раз, когда применяется миграция. Тогда база данных всегда может сообщить с какой миграцией была синхронизация. Если мы не используем такой фреймворк, потому что таких не существует, в начале работы мы автоматизируем процесс с помощью скрипта.

Рис 2: Таблица changelog, поддерживаемая фреймфорком миграции базы данных
С помощью этой схемы нумерации, мы можем отследить изменения, когда они применяются к тому множеству баз данных, с которым мы работаем.

Рисунок 3: Цикл скрипта миграции с момента его создания до деплоя в production
Некоторые из этих миграциий, вероятно, понадобится реализовать чаще, чем миграции, связанные с новыми компонентами. В этом сценарии мы заметили, что полезно иметь отдельный репозиторий миграции или папку для отладки багов, относящихся к данным.

Рис 4: Отдельные папки для управления новыми изменениями компонентов базы данных и исправлений данных в production
Каждую из этих папок можно отслеживать отдельно с помощью инструментов для миграции базы данных: Flyway, dbdeploy, MyBatis или аналогичных. У каждой должна быть отдельная таблица для хранения количества миграций. Свойство flyway.table в Flyway используется для изменения названия таблицы, где хранятся метаданные миграции.
Каждый имеет свой экземпляр базы данных
В большинстве компаний-разработчиков используется единая база данных, совместно, всеми работниками. Возможно, они используют отдельную базу данных для тестировщиков или staging, но принципиально ограничивают количество активных баз данных. Совместное использование БД подобным образом — это следствие того, что копии сложно устанавливать и управлять ими. В итоге компании минимизируют их количество. Контроль за тем, на ком ответственность менять схему в таких ситуациях разный: некоторые компании требуют, чтобы все изменения делались командами администраторов, другие позволяют разработчикам делать любые изменения, а администраторов привлекают, когда изменения переходят на следующий уровень.
Когда мы начали экспериментировать с гибкими проектами, мы заметили, что разработчики обычно работают по одной схеме — используют собственную копию кода. Так же как люди учатся, перебирая разные варианты, разработчики экспериментируют с реализацией компонентов и могут сделать несколько попыток, перед тем как выберут нужную. Нужно, чтобы у них была возможность экспериментировать в своём рабочем пространстве, а потом загружать код в общее хранилище, когда всё более стабильно. Если все работают в одном пространстве, то неизбежно мешают друг другу полуготовыми изменениями. Хоть мы и предпочитаем непрерывную интеграцию, когда интеграции происходят не чаще чем через несколько часов, личная рабочая копия играет важную роль. Системы контроля версий поддерживают эту работу, позволяя разработчикам работать независимо и поддерживают интеграцию их работы в mainline копию.
Такое разделение работает с файлами, но также может работать с базами данных. У каждого разработчика – свой экземпляр базы данных, который он может свободно изменять, не затрагивая работу других. Когда их работа будет готова, они могут загрузить и расшарить изменения, и мы это увидим в следующем разделе.
Эти отдельные базы данных могут быть либо отдельными схемами на общем сервере или, что сегодня встречается чаще, отдельными базами данных, запущенными на ноутбуке или в терминале разработчика. Десять лет назад лицензирование отдельных баз данных обходилось слишком дорого, сегодня же такое встречается редко, в том числе потому что стали популярны базы данных с открытым исходным кодом. Нам показалось удобным запускать базу данных на виртуальной машине разработчика. Мы установили билд базы данных на виртуальной машине, используя Vagrant и подход "инфраструктура как код", чтобы разработчик не разбирался в деталях установки БД и не делал это вручную.
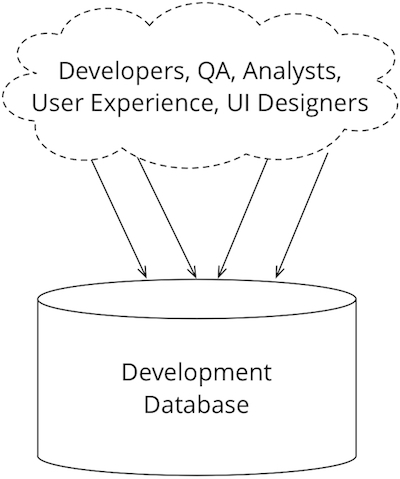
Рис 5: Проблема использования единой схемы базы данных для всей команды разработчиков

Рис 6: Каждый член команды получает свою схему базы данных для разработки и тестирования
Многие администраторы до сих пор воспринимают несколько баз данных как зло, которое нужно избегать из-за сложностей, но мы считаем, что можно легко управлять примерно сотнями экземпляров базы данных. Главное, чтобы инструменты позволяли вам управлять базами данных в том же объёме, что и файлами.
<target name="create_schema"
description="create a schema as defined in the user properties">
<echo message="Admin UserName: ${admin.username}"/>
<echo message="Creating Schema: ${db.username}"/>
<sql password="${admin.password}" userid="${admin.username}"
url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}"
>
CREATE USER ${db.username} IDENTIFIED BY ${db.password} DEFAULT TABLESPACE ${db.tablespace};
GRANT CONNECT,RESOURCE, UNLIMITED TABLESPACE TO ${db.username};
GRANT CREATE VIEW TO ${db.username};
ALTER USER ${db.username} DEFAULT ROLE ALL;
</sql>
</target>Создание схем разработки можно автоматизировать, используя скрипт сборки, чтобы уменьшить нагрузку на администраторов. Эту автоматизацию также можно ограничить только средой разработки.
<target name="drop_schema">
<echo message="Admin UserName: ${admin.username}"/>
<echo message="Working UserName: ${db.username}"/>
<sql password="${admin.password}" userid="${admin.username}"
url="${db.url}" driver="${db.driver}" classpath="${jdbc.classpath}"
>
DROP USER ${db.username} CASCADE;
</sql>
</target>Например, разработчик присоединяется к проекту, проверяет код и начинает устанавливать свою среду разработки. Он использует файл-шаблон build.properties и вносит изменения, например устанавливая Jen в качестве db.username, и так далее для остальных настроек. После того, как настройки сделаны, он может просто запустить create_schema и у него будет своя схема на общем сервере БД или на сервере БД его ноутбука.
С помощью созданной схемы, он может запустить скрипт миграции базы данных, чтобы собрать весь контент БД и наполнить свой экземпляр БД таблицами, индексами, представлениями, последовательностями, хранимыми процедурами, триггерами, синонимами и другими специфическими объектами базы данных.
Подобные скрипты существуют и для удаления схем, если они больше не нужны, или просто потому, что разработчик хочет всё почистить и начать заново с новой схемы. Среды баз данных должны быть фениксами — регулярно сгорать и перестраиваться при желании. При таком подходе меньше рисков для накопления характеристик среды, не приспособленных к повторению или проверке.
Потребность в приватном рабочем пространстве удобна разработчикам, но она удобна и всему остальному коллективу. QA должны создавать свои собственные базы данных, чтобы можно было работать без рисков запутаться в изменениях, о которых они не знают. У администраторов должна быть возможность экспериментировать со своей копией базы данных, потому что они экспериментируют с вариантами моделирования или повышения производительности.
Разработчики постоянно интегрируют изменения базы данных
Несмотря на то, что разработчики часто экспериментируют в песочнице, важный момент — так же часто интегрировать изменения, которые они совершают через непрерывную интеграцию (CI). CI включает настройку сервера интеграции, который автоматически собирает и тестирует mainline приложения. У нас есть железное правило: каждый разработчик делает интеграцию в mainline, хотя бы один раз в день. Среди инструментов, помогающих с интеграцией — GoCD, SNAP CI, Jenkins, Bambooand Travis CI.
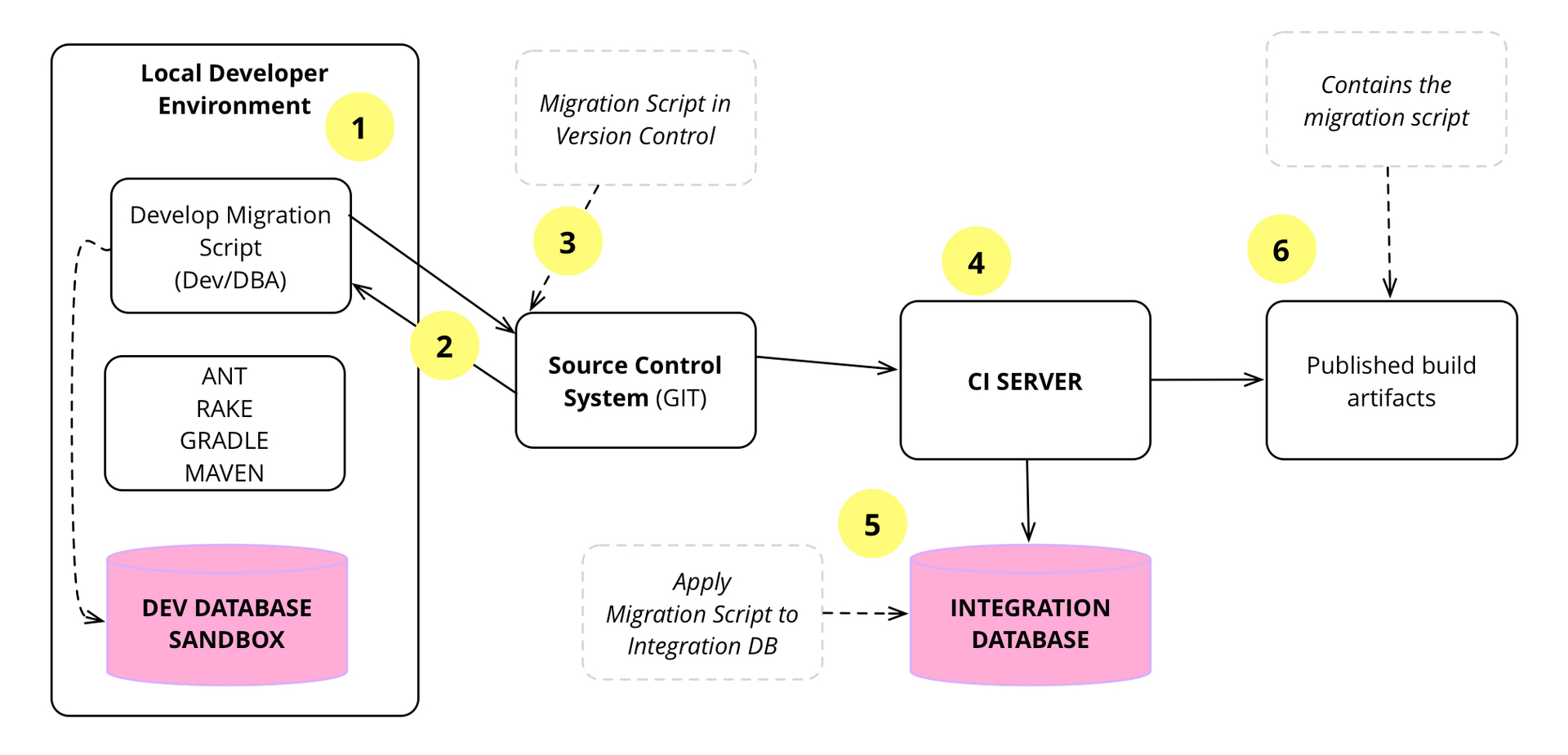
Рис 7: База данных изменяется, создаются миграции и интегрируются аналогично коду приложения
На 7 изображении показан флоу того, как происходит разработка миграций базы данных, локальное тестирование, проверка в системе управления версиями, подхватывание сервером CI и применение к интеграционной базе данных, повторное тестирование и упаковка для использования.
Давайте посмотрим на пример
1) Джен приступает к разработке, которая включает изменение схемы базы данных. Если изменение простое, например, добавление колонки, Джен думает, как внести изменения напрямую. Если сложное, она находит администратора БД и обсуждает вопрос с ним.
После того, как она выясняет что делать с изменением, она пишет миграцию.
ALTER TABLE project ADD projecttypeid NUMBER(10) NULL;
ALTER TABLE project ADD (CONSTRAINT fk_project_projecttype
FOREIGN KEY (projecttypeid)
REFERENCES projecttype DEFERRABLE INITIALLY DEFERRED);
UPDATE project
SET projecttypeid = (SELECT projecttypeid
FROM projecttype
WHERE name='Integration');Добавление обнуляемого столбца — это обратно совместимое изменение, поэтому она может интегрировать изменение, не изменяя код приложения. Но если это не обратно совместимое изменение, вроде разделения таблицы, то Джен понадобится изменить код приложения.
2) После того, как Джен закончит изменения, она готова к интеграции. Первый шаг — обновление локальной копии Джен из mainline. Это те изменения, которые сделали другие члены команды, пока она работала над своей задачей. Затем она проверяет свои изменения, работает с обновлениями, пересобирая базу данных и прогоняя все тесты.
Если она сталкивается с проблемами из-за изменений, сделанных другими разработчиками — изменений, которые конфликтуют с её изменениями — она должна исправить эти проблемы в своей копии. Как правило, такие конфликты легко поправить, но иногда они оказываются запутанными. Часто такие усложнённые конфликты ведут к необходимости обсуждения между Джен и её коллективом, чтобы разобраться в накладках.
После того, как её локальная копия снова в рабочем состоянии, она проверяет, появились ли дополнительные изменения пока она делала исправления. Если были, Джен нужно повторить интеграцию с новыми изменениями. Обычно происходит не больше одного или двух подобных циклов, перед тем, как её код полностью интегрируется в mainline.
3) Джен пушит изменения в mainline. Поскольку изменение обратно совместимо с существующим кодом приложения, она может интегрировать изменения базы данных перед обновлением кода приложения — это обычный пример Parallel Change.
4) Сервер CI обнаруживает изменения в mainline и начинает новую сборку, которая содержит миграцию базы данных.
5) Сервер CI использует свою копию базы данных для сборки, поэтому применяет скрипт миграции базы данных к этой базе данных, чтобы произвести изменения в миграции. Кроме того, он запускает остальные шаги сборки: компилирование, модульные тесты, функциональные тесты и подобные.
6) После того, как сборка успешно завершается, сервер CI пакетирует артефакты сборки и передаёт их. Артефакты сборки содержат скрипты миграции базы данных, для применения их к базам данных в downstream средах, таких как Deployment Pipeline. Артефакты сборки также содержат код приложения, пакетированный в jar, war, dll и другие.
Именно такой метод непрерывной интеграции обычно используется в управлении исходным кодом приложения. Вышеуказанные шаги показывают что код базы данных рассматривается как часть исходного кода. Подобный код БД — DDL, DML, Data, выборки, события, запускающие процедуру, хранимые процедуры — находятся под управлением конфигурации, так же как и исходный код. Каждый раз, когда происходит успешная сборка, собирая артефакты БД и артефакты приложения в единое, мы получаем полную синхронизированную историю версий как приложений, так и баз данных.
Имея исходный код приложения, большую часть мучений от интеграции с изменениями можно ликвидировать, если использовать системы управления исходным кодом и различные тесты в локальных средах. В отношении баз данных усилий применяется немного больше, потому что в базе данных есть данные (состояния), которые должны сохранять своя бизнес логика. (Мы поговорим подробнее об автоматизированном рефакторинге базы данных позже). Кроме того, администратор БД должен следить за любыми изменениями БД и убеждаться, что они вписываются в общую картину схемы базы данных и архитектуру данных. Чтобы всё это чётко работало, крупные изменения не должны быть сюрпризом в момент интеграции, поэтому администраторам нужно теснее сотрудничать с разработчиками.
Мы настаиваем на более частых интеграциях, потому что поняли, что гораздо проще делать множество небольших интеграций, а не редкие крупные, это тот случай, когда Частота Снижает Сложность. Муки от интеграции растут экспоненциально с увеличением объёма интеграции, так что множество небольших изменений оказываются намного легче на практике, даже если это кажется многим нелогичным.
База данных состоит из схемы и данных
Когда мы говорим о базе данных, мы подразумеваем не только схему базы данных и её код, но и значительное количество данных. Эти данные состоят из обычных обязательных данных приложения, таких как неизменный список всех государств, стран, валют, типов адресов и различных специфических данных. Мы также можем включить некоторые образцы тестовых данных, например, несколько шаблонов клиентов, заказов и т.д. Эти данные-образцы не попадут в production, если только специально не потребуются для теста работоспособности или семантического мониторинга.
Эти данные существуют по нескольким причинам. Основная причина — запуск тестирования. Мы преданные поклонники использования внушительного набора автоматизированных тестов, для стабилизации разработки приложения. Такой набор тестов — распространённый подход гибких методов. Чтобы такие тесты проходили эффективно, имеет смысл работать над базой данных, которая заполнена тестовой информацией, которую все тесты ожидают увидеть.
Эти образцы данных должны управляться версиями, чтобы знать, где их найти, когда понадобится заполнить новую базу данных, поэтому у нас есть запись изменений, которая синхронизируется с тестами и кодом приложения.
Образец тестовых данных позволяет тестировать миграции, когда меняется схема базы данных и помогает тестировать код. Когда есть тестовые данные, мы просто вынуждены следить за тем, что любые изменения схемы также обрабатывают образцы данных.
В большинстве проектов, которые мы видели, эти образцы данных были фиктивными. Но попалось несколько проектов, где использовались реальные данные. В этих случаях данные были извлечены из предшествовавших унаследованных систем с автоматизированными скриптами преобразования данных. Очевидно, что конвертировать все данные сразу же невозможно, потому что в ранних итерациях собирается только маленькая часть новой базы данных. Но мы можем использовать Incremental Migration для разработки скриптов преобразования и получить необходимые данные вовремя.
Это не только поможет избавиться от проблем преобразования данных на ранних этапах, это упростит работу с растущей системой узким специалистам, поскольку они знакомы с данными, на которые они смотрят, и часто могут помочь выявить скрипты, вызывающие проблемы с базами данных и архитектурой приложений. В результате мы пришли к выводу, что нужно пытаться вводить реальные данные с самой первой итерации проекта. Jailer показался нам полезным инструментом в таком процессе.
Все изменения базы данных — это рефакторинг базы данных
Изменения, которые мы делаем в базе данных, меняют способ хранения в ней информации, устанавливают новые способы хранения или удаляют хранилище, которое больше не нужно. Но ни одно из изменений базы данных, само по себе, не меняет общее поведение приложения. Следовательно, мы можем рассматривать их как подходящие под определение рефакторинга.
изменение, внесенное во внутреннюю структуру программы, которое делает его более понятным и легко изменяемым, без изменения его наблюдаемого поведения
Признавая это, мы собрали и задокументировали множество рефакторингов. Составляя каталог, мы предлагаем облегчённые пути для корректных изменений, так как мы можем следовать шагам, которые мы успешно делали раньше.
Одно из самых заметных различий в рефакторингах базы данных в том, что они включают три различных изменения, которые должны протекать одновременно.
- Изменение схемы базы данных
- Миграция данных в базе данных
- Изменение кода доступа к базе данных
Таким образом, когда мы описываем рефакторинг базы данных, мы должны описать все три аспекта изменений и убедиться, что все три применяются, перед тем как применять другие рефакторинги.
Как и рефакторинг кода, рефакторинги базы данных очень маленькие. Идея сбора групп маленьких изменений в последовательности, точно такая же как и в случае с кодом. Трехмерный характер изменений делает такую практику более важной.
Многие рефакторинги базы данных, вроде добавить новую колонку, можно делать без обновления всего кода, имеющего доступ к системе. Если код станет использовать новую схему, не зная об этой схеме, колонка просто не будет использоваться. У многих изменений, правда, нет такого свойства и мы называем их деструктивными. Деструктивным изменениям нужно немного больше внимания, степень которого зависит от степени деструктивности.
Примером незначительного деструктивного изменения служит сделать колонку non nullable, которое превращает колонку, допускающую значение null, в не допускающую такое значение. Деструктивное оно потому, что если любой существующий код не установит её значение, то мы получим сообщение об ошибке. У нас также возникнут проблемы, если в существующих данных присутствуют null.
Мы можем избежать проблем с существующими нулями (ценой немного других проблем), присваивая базовые данные любым рядам, содержащим нули. Для проблемы не присвоения (или присвоения нуля) у нас есть два варианта. Один из них установить для колонки значение по умолчанию.
ALTER TABLE customer
MODIFY last_usage_date DEFAULT sysdate;
UPDATE customer
SET last_usage_date =
(SELECT MAX(order_date) FROM order
WHERE order.customer_id = customer.customer_id)
WHERE last_usage_date IS NULL;
UPDATE customer
SET last_usage_date = last_updated_date
WHERE last_usage_date IS NULL;
ALTER TABLE customer
MODIFY last_usage_date NOT NULL;Другой — менять код приложения во время рефакторинга. Мы предпочитаем такой вариант, если можем гарантированно иметь доступ ко всему коду, который обновляет базу данных, что обычно легко сделать, если база данных используется только одним приложением, и трудно, если она общая.
Более сложный случай — разделение таблицы, в частности, если доступ к таблице раскидан по всему коду приложения. Если случай именно такой, нужно чтобы все знали, что скоро будет изменение и могли подготовиться к нему. Обдуманным поступком будет подождать сравнительно спокойного момента, например, начала итерации.
Любое деструктивное изменение намного проще, если доступ к базе данных проложен через несколько модулей системы. Так легче найти и обновить код доступа к базе данных.
В общем, самое главное выбрать процедуру, оптимальную именно для того вида изменений, которые делаете вы. Если сомневаетесь, попробуйте перейти на сторону упрощения изменений. По опыту мы обжигались реже, чем думают другие, и имея строгое конфигурационное управление всей системой не трудно откатиться назад, в случае самого страшного сценария.
Фаза перехода
Мы уже упоминали те трудности, которые появляются, когда мы сталкиваемся с деструктивным рефакторингом базы данных и не можем легко изменить код доступа. У этих проблем растут рога и клыки, когда у вас база данных общая и, возможно, её использует множество приложений и отчетов. В таком случае вам нужно серьёзнее позаботиться о чём-то, вроде переименовании таблицы. Чтобы обезопасить себя от рогатых проблем, обратимся к фазе перехода.
Фаза перехода — это период времени, когда база данных одновременно поддерживает и старый шаблон доступа, и новые. Это даёт более старым системам время мигрировать на новые структуры с их собственной скоростью. (Забота об изменениях в базе данных, включая DDL, DML и миграции данных в процессе разработки, обеспечивает максимальный смысл для группы данных, избегая пакетной миграции всех изменений группы данных во время деплоя без контекста.)
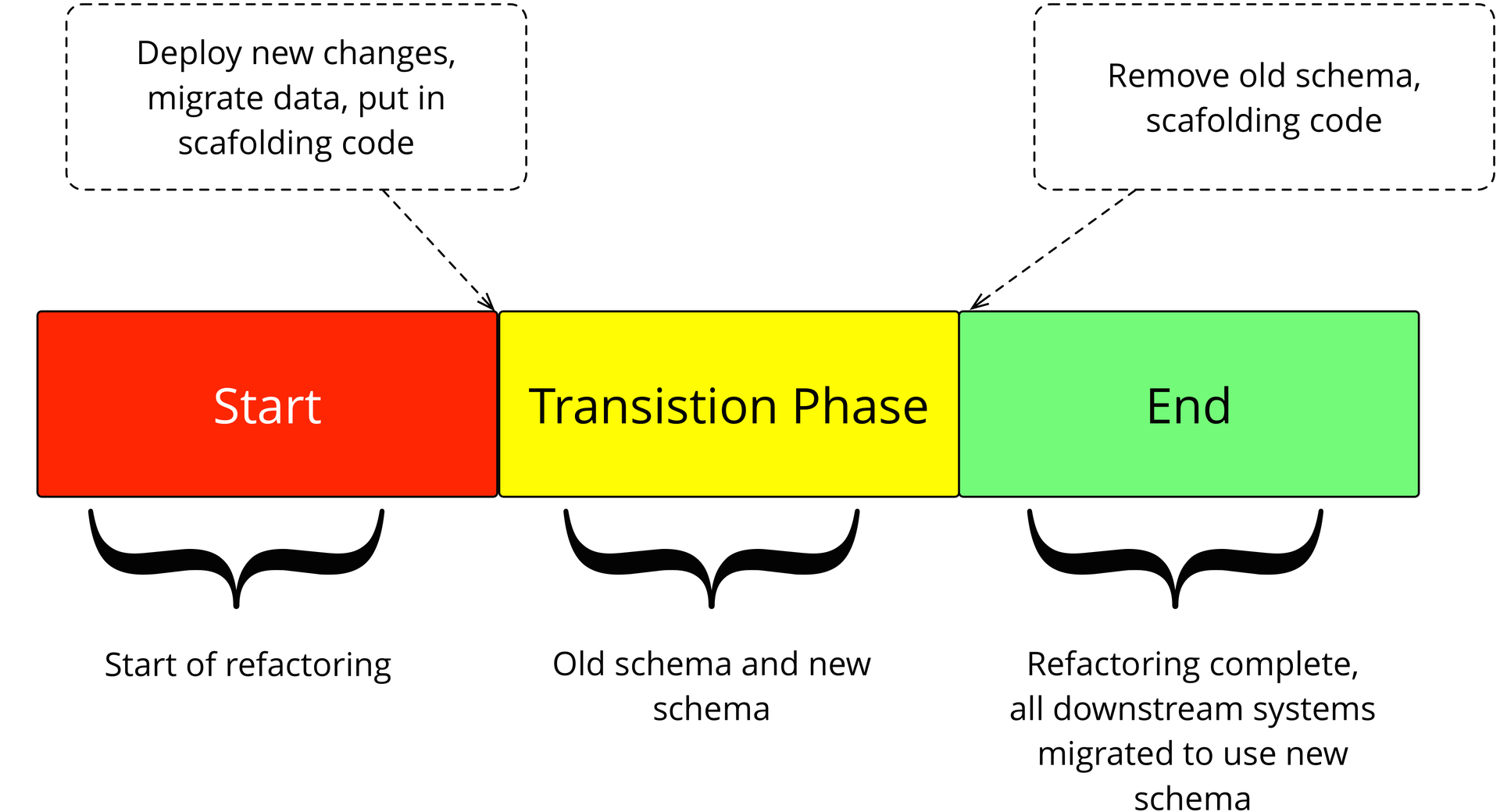
Рис 8: Рефакторинг базы данных, применённый к унаследованной базе данных и фазы, которые она должна пройти перед реализацией
ALTER TABLE customer RENAME to client;
CREATE VIEW customer AS
SELECT id, first_name, last_name FROM client;Для примера с переименованием, разработчик может создать скрипт, который переименовывает таблицу customer в таблицу client, а также создает выборку customer, которую могут использовать существующие приложения. Это параллельное изменение поддерживает новый и старый доступ. Правда он добавляет сложность, поэтому важно его удалить когда придёт время миграции в downstream системы. В некоторых компаниях это можно сделать за несколько месяцев, а в некоторых такое может занять годы.
Выборки – это один метод для осуществления фаз перехода. Мы также используем переключающие события базы данных, которые удобны для таких случаев, как переименование колонки.
Автоматизация рефакторингов
Поскольку рефакторинг стал популярным для кода приложения, многие языки получили хорошую поддержку для автоматических рефакторингов. Автоматизация упрощает и ускоряет рефакторинг быстрым выполнением различных шагов без вмешательства человека и поэтому исключает человеческие ошибки. Такая автоматизация также существует для баз данных. Фреймфорки вроде LiquiBase и Active Record Migrations позволяют использовать DSL для применения рефакторингов базы данных, что позволяет применять миграции баз данных стандартным способом.
Но такие виды стандартизированных рефакторингов не слишком подходят для баз данных, так как правила работы с миграцией данных и унаследованными данными очень сильно зависят от специфической практики команды. А мы предпочитаем проводить рефакторинг базы данных с помощью скриптов миграции и фокусируемся на инструментах автоматизации.
Мы пишем каждый скрипт, как вы видели, объединяя SQL DDL (для изменения схемы) и DML (для миграции данных) и помещаем результат в репозиторий. Автоматизация у нас гарантирует, что мы никогда не применим эти изменения вручную, только с помощью инструментов автоматизации. Таким способом мы поддерживаем порядок рефакторингов и обновляем метаданные базы данных.
Мы можем применять эти рефакторинги к любому состоянию базы данных, чтобы держать их синхронизированными с последней рабочей или любой предыдущей версией. Инструмент использует метаинформацию из базы данных, чтобы узнать её текущую версию, а затем применяет каждый рефакторинг между найденной и требуемой версией. Мы можем использовать этот подход для обновления версий разработки, версий тестирования и баз данных в production.
Обновление БД в production ничем не отличается от тестирования БД, мы применяем один и тот же набор скриптов к различным данным. Мы предпочитаем делать частые релизы, тогда обновления остаются мелкими, а значит протекают значительно быстрее и решать любые возникающие проблемы легче. Самый простой способ делать эти обновления, отключать БД production пока обновления применяются, это работает в большинстве ситуаций. Можно применять обновления и при активной БД, но о методах такого подхода придётся написать отдельную статью.
Кроме автоматизации предстоящих изменений, можно обдумать возможность автоматизации обратных изменений для каждого рефакторинга. В этом случае у вас будет возможность обратить изменения в базе данных таким же автоматизированным способом. Мы не доказали экономическую эффективность и достаточную пользу этой методики, к тому же, в ней не оказалось острой потребности, но тут работает тот же самый основной принцип. Обычно мы стараемся писать миграции так, чтобы фрагмент доступа к БД мог работать как со старой так и с новой версией базы данных. Это позволяет обновлять БД, поддерживая будущие потребности и держать её в активном состоянии, оставлять её запущенной в production, и только потом, как только мы увидим, что всё работает без проблем, загружать обновление, которое использует новые структуры данных.
Инструментов, которые автоматизируют применение миграций БД, сегодня много, среди них Flyway, LiquiBase, миграции MyBatis, DBDeploy. Вот применение миграции с Flyway.
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully validated 9 migrations (execution time 00:00.021s)
Creating Metadata table: "JEN_DEV"."schema_version"
Current version of schema "JEN_DEV": << Empty Schema >>
Migrating schema "JEN_DEV" to version 0 - base version
Migrating schema "JEN_DEV" to version 1 - asset
Migrating schema "JEN_DEV" to version 2 - asset type
Migrating schema "JEN_DEV" to version 3 - asset parameters
Migrating schema "JEN_DEV" to version 4 - inventory
Migrating schema "JEN_DEV" to version 5 - split inventory
Migrating schema "JEN_DEV" to version 6 - equipment type
Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type
Migrating schema "JEN_DEV" to version 8 - data location equipment type
Successfully applied 9 migrations to schema "JEN_DEV" (execution time 00:00.394s).
psadalag:flyway-4 $ Разработчики могут обновлять свои базы данных по требованию.
Как объяснялось выше, первый шаг интеграции изменений в mainline — извлечь любые изменения, случившиеся пока мы выполняли свою часть работы. Это не только основная часть стадии интеграции, она часто бывает полезной, перед тем, как мы закончим, потому что тогда мы сможем оценить влияние любых изменений, о которых говорили коллеги. В обоих случаях главное — иметь возможность легко вытащить изменения из mainline и применить их к своей локальной базе данных.
В начале мы пуллим изменения в своё рабочее пространство. Обычно это довольно просто, но иногда оказывается, что кто-то из коллег загрузил миграцию в mainline пока мы работали над своей. Если мы писали миграцию с идентификатором 8, мы увидим как другая миграция с этим же номером появится в папке миграций. Инструмент миграции должен это обнаружить.
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
ERROR: Found more than one migration with version 8
Offenders:
-> /Users/psadalag/flyway-4/sql/V8__data_location_equipment_type.sql (SQL)
-> /Users/psadalag/flyway-4/sql/V8__introduce_fuel_type.sql (SQL)
psadalag:flyway-4 $Как только мы заметим конфликт, первый шаг будет простым: нам нужно перенумеровать свою миграцию в 9, тогда она переприменится поверх новой миграции в mainline. После перенумерации нужно протестировать существующие миграции на конфликт. Для этого нужно почистить базу данных, а потом применить все миграции, включая новую 8 и свою перенумерованную 9 к пустой копии БД.
psadalag:flyway-4 $ mv sql/V8__introduce_fuel_type.sql sql/V9__introduce_fuel_type.sql
psadalag:flyway-4 $ ./flyway clean
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully cleaned schema "JEN_DEV" (execution time 00:00.031s)
psadalag:flyway-4 $ ./flyway migrate
Flyway 4.0.3 by Boxfuse
Database: jdbc:oracle:thin:@localhost:1521:xe (Oracle 11.2)
Successfully validated 10 migrations (execution time 00:00.013s)
Creating Metadata table: "JEN_DEV"."schema_version"
Current version of schema "JEN_DEV": << Empty Schema >>
Migrating schema "JEN_DEV" to version 0 - base version
Migrating schema "JEN_DEV" to version 1 - asset
Migrating schema "JEN_DEV" to version 2 - asset type
Migrating schema "JEN_DEV" to version 3 - asset parameters
Migrating schema "JEN_DEV" to version 4 - inventory
Migrating schema "JEN_DEV" to version 5 - split inventory
Migrating schema "JEN_DEV" to version 6 - equipment type
Migrating schema "JEN_DEV" to version 7 - add insurance value to equipment type
Migrating schema "JEN_DEV" to version 8 - data location equipment type
Migrating schema "JEN_DEV" to version 9 - introduce fuel type
Successfully applied 10 migrations to schema "JEN_DEV" (execution time 00:00.435s).
psadalag:flyway-4 $Обычно это работает на ура, но периодически случаются конфликты, просто потому, что кто-то из разработчиков переименовал таблицу, в которую мы вносили изменения. В таком случае нужно выяснить, как разрешить конфликт. Тут и открывается ценность небольших миграций: с ними легче обнаружить и разобраться с конфликтами.
Как только изменения базы данных интегрированы, нужно повторно запустить пакет тестов, на случай, если миграция из mainline приведёт к поломке какого-нибудь теста.
Эта процедура позволяет нам работать независимо друг от друга короткими промежутками, даже без подключения к сети, а затем интегрировать, когда нам это удобно. Когда и как часто мы делаем эту интеграцию, полностью зависит от нас, при условии, что мы синхронизировались перед загрузкой в mainline.
Чётко разделить весь код доступа к базе данных
Для того, чтобы понять последствия рефакторингов базы данных, нужно видеть, как база данных используется приложением. Если SQL разбросан как попало по базе исходного кода, это сделать очень трудно. Поэтому очень важно иметь чистый уровень доступа к базе данных, показывающий где и как она использовалась. Для этого мы советуем следовать одному из структурных паттернов хранилища данных из книги Patterns of Enterprise Application Architecture.
Наличие чистого уровня базы данных имеет несколько ценных побочных преимуществ. Он минимизирует количество блоков в системе, управлять которыми могут только разработчики со знанием SQL, и облегчает жизнь тем разработчикам, которые часто не слишком квалифицированны в SQL. Администратору он даёт чистый блок кода, в котором тот может увидеть, как использовалась база данных. Это помогает подготавливать индексы, оптимизировать базу данных, и рассматривать SQL, чтобы понять, как её можно изменить для лучшей работы. Это позволяет администратору базы данных лучше понимать, как используется база данных.
Делайте больше релизов
Когда мы писали первую версию этой статьи более десяти лет назад, концепция более частого релиза софта имела мало поддержки. Но рост интернет-гигантов показал, что частые релизы — ключевая часть успешной стратегии цифровой индустрии.
Для каждого изменения зафиксированного в миграции, мы можем легко задеплоить новые изменения в тестовой и production среде. Тот тип эволюционного проектирования баз данных, который мы обсуждаем здесь, одновременно позволяет делать частые релизы, а также извлекает пользу из фидбека, получаемого от реального использования софта.
Вариации
Как и любой другой набор методов, они должны быть разнообразными в зависимости от обстоятельств, вот некоторые из тех, с которыми столкнулись мы.
Несколько версий
Простой проект может выжить только с единственной веткой, а значит, одной версией базы данных. В более сложных проектах нужна поддержка нескольких версий для AB тестирования или запуска деплоев когда происходят Canary Releases и, следовательно, нескольких разновидностей баз данных проекта. Каждому релизу могут требоваться свои тестовые данные, изменения для тестирования конкретного компонента или исправление определенных багов. Это ничем не отличается от управления несколькими версиями кода production, но с небольшой изюминкой, суть которой в том, что база данных должна поддерживать несколько релизов приложения.
Ещё один метод, который мы считаем полезным — единый репозиторий для базы данных и всех остальных версий приложения, зависящих от репозитория базы данных. Вам нужно контролировать, что все версии кода работают с той же версией базы данных, а значит, форсировать базу данных иметь обратную совместимость со всеми предыдущими версиями приложений, которые находятся в production.
Доставка изменений с приложением
В некоторых проектах мы уже видели, что изменения применённые к продукту должны быть распространены среди тысяч конечных потребителей. В таких видах проектов лучше давать приложению обновлять себя самому, пакетированием всех изменений базы данных вместе с приложением (потому что мы не имеем даже примерного представления с какой версии обновляется клиент), и дать приложению обновить базу данных при запуске, используя фреймворки, например, Flyway или один из его многочисленных подобий.
Несколько приложений, использующих одну базу данных
Во многих корпорациях множество приложений оказываются в итоге с одной общей базой данных — паттерн интеграции Shared Database. В таких ситуациях, когда одно приложение вносит изменение в базу данных, вполне вероятно, что изменение сломает другие приложения. Чтобы избежать этого, лучше извлечь базу данных, которая используется всеми зависимыми приложениями, в виде отдельного репозитория кода. Этот общий репозиторий базы данных должен быть покрыт автоматизированными поведенческими тестами, которые дают уверенность, что перекрестные зависимости приложений протестированы, и останавливать сборку, если зависимые приложения затронуты. Это не отличается от варианта, когда есть расшаренный программный компонент, со своим хранилищем кода.
NoSQL базы данных
Наша статья концентрируется на реляционных базах данных отчасти потому, что оригинал был о них, и отчасти потому, что до сих пор мы убеждаемся в их большей распространённости. И мы, можно сказать, знакомы с NoSQL базами данных, которые в последнее время стали более распространёнными. Полноценное обсуждение того, как их обслуживать эволюционным путем, тянет на ещё одну статью, но мы попытаемся дать им поверхностный обзор.
Базы данных NoSQL заявлены как инструменты лучше приспособленные к эволюционному пути, поскольку большинство из них "бессхемные". Но их бессхемность не избавляет нас от необходимости обсуживать схемы, поскольку неявная схема в них существует. Любой код, имеющий доступ к базе данных, косвенно выражает такую схему. Этой схемой нужно управлять, фактически используя те же методы миграции данных в репозитории исходного кода. Отсутствие схемы хранения даёт нам другую технику для поддержания нескольких стратегий чтения разных версий. Это может упростить управление эволюцией баз данных, но нам всё ещё есть о чём беспокоиться.
Вам не нужна армия администраторов БД
Использование перечисленных методов по ощущениям требует много работы, но по факту не требует гигантского коллектива. Во многих проектах у нас было по тридцать с лишним разработчиков, а во всей команде (включая QA, аналитиков и управляющих) было около сотни сотрудников. В любой день у нас появлялось около сотни экземпляров различных схем, собранных на персональных рабочих станциях. При этом вся активность требовала одного полного рабочего дня администратора и нескольких разработчиков, понимающих рабочий процесс и последовательность, которые выполняли бы частичную поддержку и проверку.
В небольших проектах не требуется даже такое. Мы использовали такие методы в небольших проектах (около десятка человек), и поняли, что в полном рабочем дне администратора нет необходимости. Вместо этого мы полагаемся на пару разработчиков, любопытных к проблемам БД, которые выполняют задачи администратора парт-тайм и, в случае необходимости, привлекаем администраторов, чтобы принять решение по дизайну или архитектуре.
Это возможно благодаря автоматизации. Если вы решили автоматизировать все задачи, вы можете выполнять много работы, не задействуя большого количества людей. Особенно когда такие инструменты как DevOps и похожие (Puppet, Chef, Docker, Rocket, and Vagrant) стали популярными.
С тех пор, как мы работаем в этом стиле много лет, мы решили полагаться на базы данных, которые могут эволюционировать так же, как код приложения, учащать циклы релизов и двигать софт в production быстрее. Описанные методы теперь — часть нашего привычного способа работы. Но наша цель не только улучшить собственные методы, но и поделиться своим опытом с программной индустрией. Чем больше подобных техник осваивают другие, тем больше софта реализует потребности людей, а прогресс, который достигается с помощью такого софта обогащает жизнь в целом.
(Перевод Наталии Басс)
