ZFS является одной из самых нафаршированных файловых систем (ФС), а главное — она заботится о сохранности нашей информации. Да, она не является «серебряной пулей», но в своей области показывает прекрасные результаты.

Проект ZFS on Linux изначально был создан для портирования существующего кода из Solaris. После закрытия его исходного кода совместно с сообществом OpenZFS проект продолжил разработку ZFS для Linux. Код может быть собран как в составе ядра, так и в виде модуля.

Сейчас пользователь может создать пул с последней совместимой с Solaris версией 28, а также с приоритетной для OpenZFS версией 5000, после которого началось применение feature flags (функциональные флаги). Они позволяют создавать пулы, которые будут поддерживаться в FreeBSD, пост-Sun Solaris ОС, Linux и OSX вне зависимости от различий реализаций.
В 2016 году был преодолён последний рубеж, сдерживавший ZFS на Linux — многие дистрибутивы включили его в штатные репозитории, а проект Proxmox уже включает его в базовую поставку. Ура, товарищи!
Рассмотрим как наиболее важные отличия, так и подводные камни, которые есть в настоящее время в версии ZFS on Linux 0.6.5.10.
Начинать знакомство с ZFS стоит с изучения особенностей CopyOnWrite (CoW) файловых систем — при изменении блока данных старый блок не изменяется, а создается новый. Переводя на русский — происходит копирование при записи. Данный подход накладывает отпечаток на производительности, зато даёт возможность хранить всю историю изменения данных.
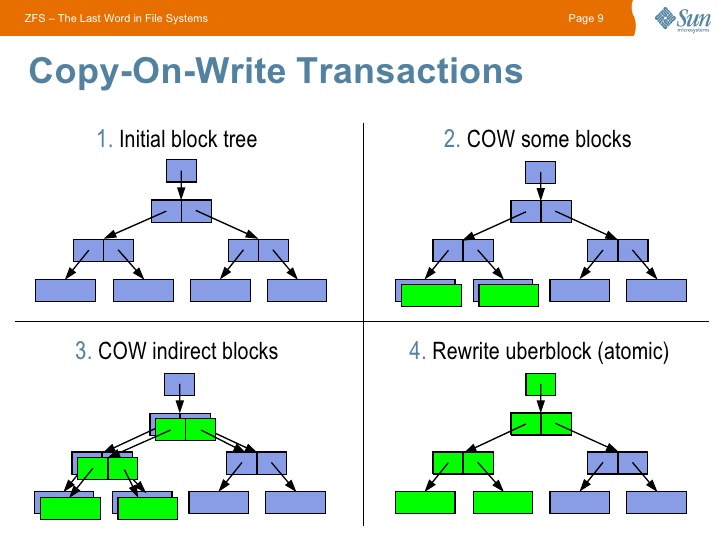
CoW подход в ZFS даёт огромные возможности: эта ФС не может иметь некорректного состояния, т.к. в случае проблем с последней транзакцией (например при отключении питания) будет использована последняя корректная.
Также сразу стоит отметить, что для всех данных считается контрольная сумма, что также оставляет свой отпечаток на производительности, но даёт гарантию целостности данных.
Защита данных:
Максимальная гибкость вашего хранилища:
В ZFS структура хранилища выглядит следующим образом:
В пуле может быть неограниченное количество vdev, что позволяет создать пул из двух и более mirror, RAID-Z или других сочетаний. Также доступны классические RAID10 и т.д.
Stripe — обычный RAID0.
Mirror — RAID1 на манер ZFS — реплицируются только занятые блоки, забудьте о синхронизации пустого места.
RAID-Z — создавался как замена RAID5-6, но имеет большие отличия:
— каждый блок данных — аналог отдельного массива (с динамической длинной);
— отсутствует проблема write hole;
— при ребилде создаются только данные (т.е. риск сбоя в этот момент уменьшается). Также в тестовой ветке уже находятся улучшения, которые дополнительно ускорят этот процесс.
Рекомендуется использовать RAID-Z2 (аналог RAID6). При создании RAID-Z стоит обязательно изучить эту статью, основные нюансы:
— IOPS равен самому медленному диску (создавайте RAID-Z с наименьшим количеством дисков);
— эффективность утилизации места увеличивается при бОльшем количестве дисков в массиве (требуется задать корректный recordsize, см. ссылку выше);
— в существующий массив RAID-Z нельзя добавить ещё один диск (пока), но можно заменить диски на более ёмкие. Эта проблема решается созданием нескольких массивов в рамках одного vdev.
dRAID (в разработке) — базируется на наработках RAID-Z, но при сбое позволяет задействовать на чтение-запись все диски массива.
CoW ухудшает производительность. Для сглаживания ситуации был создан adaptive replacement cache (ARC). Его основная особенность в проработанных эвристиках для исключения вымывания кеша, в то время как обычный page cache в Linux к этому очень чувствителен.
Бонусом к ARC существует возможность создать быстрый носитель со следующим уровнем кеша — L2ARC. При необходимости он подключается на быстрые SSD и позволяет заметно улучшить IOPS HDD дисков. L2ARC является аналогом bcache со своими особенностями.
L2ARC стоит использовать только после увеличения ОЗУ на максимально возможный объём.
Также существует возможность вынести запись журнала — ZIL, что позволит значительно ускорить операции записи.
Компрессия — с появлением LZ4 позволяет увеличить скорость IO за счёт небольшой нагрузки на процессор. Нагрузка настолько мала, что включение данной опции уже является повсеместной рекомендацией. Также есть возможность воспользоваться другими алгоритмами (для бекапов прекрасно подходит gzip).
Дедупликация — особенности: процесс дедупликации производится синхронно при записи, не требует дополнительной нагрузки, основное требование — ~ 320 байт ОЗУ на каждый блок данных (Используйте команду
Рекомендуется использовать только на часто повторяющихся данных. В большинстве случаев накладные расходы не оправданы, лучше включить LZ4 компрессию.
Снапшоты — в силу архитектуры ZFS абсолютно не влияют на производительность, в рамках данной статьи на них останавливаться не будем. Отмечу только прекрасную утилиту zfs-auto-snapshot, которая создаёт их автоматически в заданные интервалы времени. На производительности не отражается.
Шифрование (в разработке) — будет встроенным, разрабатывается с учётом всех недостатков реализации от Oracle, а также позволит штатными send/receive и scrub отправлять и проверять данные на целостность без ключа.
— Заранее продумайте геометрию массива, в настоящий момент ZFS не умеет уменьшаться, а также расширять существующие массивы (можно добавлять новые или менять диски на более объёмные);
— используйте сжатие:
— храните расширенные атрибуты правильно, по умолчанию хранятся в виде скрытых файлов (только для Linux):
— отключайте atime:
— выставляйте нужный размер блока (recordsize), файлы меньше recordsize будут записываться в уменьшенный блок, файлы больше recordsize будут записывать конец файла в блок с размером recordsize (при
— ограничьте максимальный размер ARC (для исключения проблем с количеством ОЗУ):
— дедупликацию используйте только по явной необходимости;
— по возможности используйте ECC память;
— настройте zfs-auto-snapshot.
— большинство SSD врёт системе о размере блока, для перестраховки контролируйте его (параметр ashift). Ссылка на список исключений для SSD в коде ZFS.
— многие свойства действуют только на новые данные, к примеру при включении сжатия оно не применится к уже существующим данным. В дальнейшем возможно создание программы, применяющей свойства автоматически. Обходится простым копированием.
— консольные команды ZFS не запрашивают подтверждение, при выполнении
— ZFS не любит заполнение пула на 100%, как и все другие CoW ФС, после 80% возможно замедление работы без должной настройки.
— требуется правильно выставлять размер блока, иначе производительность приложений может быть неоптимальна (примеры — Mysql, PostrgeSQL, torrents).
— делайте бекапы на любой ФС!
В настоящий момент ZFS on Linux уже является стабильным продуктом, но плотная интеграция в существующие дистрибутивы будет проходить ещё некоторое время.
ZFS — прекрасная система, от которой очень сложно отказаться после знакомства. Она не является универсальным средством, но в нише программных RAID массивов уже заняла своё место.
Я, gmelikov, состою в проекте ZFS on Linux и готов с радостью ответить на любые вопросы!
Отдельно хочу пригласить к участию, всегда рады issues и PR, а также готовы помочь вам в наших mailing lists.
Полезные ссылки:
ZFS on Linux github page
FAQ
ZFS Performance tuning
Update (12.02.2018): Добавлена информация про ashift SSD дисков.

Проект ZFS on Linux изначально был создан для портирования существующего кода из Solaris. После закрытия его исходного кода совместно с сообществом OpenZFS проект продолжил разработку ZFS для Linux. Код может быть собран как в составе ядра, так и в виде модуля.

Сейчас пользователь может создать пул с последней совместимой с Solaris версией 28, а также с приоритетной для OpenZFS версией 5000, после которого началось применение feature flags (функциональные флаги). Они позволяют создавать пулы, которые будут поддерживаться в FreeBSD, пост-Sun Solaris ОС, Linux и OSX вне зависимости от различий реализаций.
В 2016 году был преодолён последний рубеж, сдерживавший ZFS на Linux — многие дистрибутивы включили его в штатные репозитории, а проект Proxmox уже включает его в базовую поставку. Ура, товарищи!
Рассмотрим как наиболее важные отличия, так и подводные камни, которые есть в настоящее время в версии ZFS on Linux 0.6.5.10.
Начинать знакомство с ZFS стоит с изучения особенностей CopyOnWrite (CoW) файловых систем — при изменении блока данных старый блок не изменяется, а создается новый. Переводя на русский — происходит копирование при записи. Данный подход накладывает отпечаток на производительности, зато даёт возможность хранить всю историю изменения данных.
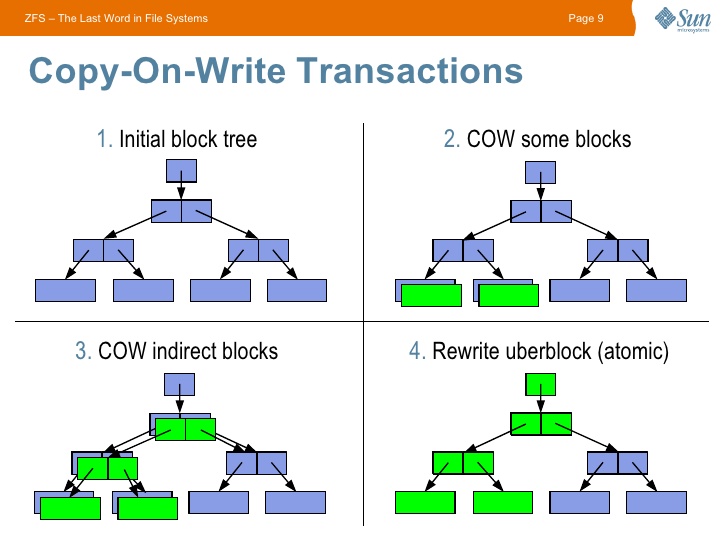
CoW подход в ZFS даёт огромные возможности: эта ФС не может иметь некорректного состояния, т.к. в случае проблем с последней транзакцией (например при отключении питания) будет использована последняя корректная.
Также сразу стоит отметить, что для всех данных считается контрольная сумма, что также оставляет свой отпечаток на производительности, но даёт гарантию целостности данных.
Кратко о главных преимуществах ZFS для вашей системы.
Защита данных:
- контрольные суммы — гарантия корректности данных;
- возможность резервирования как на уровне создания зеркал и аналогов RAID массивов, так и на уровне отдельного диска (параметр
copies); - в отличие от многих файловых систем с их fsck на уровне журнала, ZFS проверяет все данные по контрольным суммам и умеет проводить их автоматическое восстановление по команде scrub (если в пуле есть живая копия битых данных);
- первая ФС, разработчики которой честно признались во всех возможных рисках при хранении — везде при упоминании ZFS можно встретить требование оперативной памяти с поддержкой ECC (любая ФС имеет риск повреждения при отсутствии ECC памяти, просто все, кроме ZFS, предпочитают не задумываться об этом);
- ZFS создавалась с учетом ненадёжности дисков, просто помните это и перестаньте волноваться о вашем
WD GreenSeagateetc(только, если рядом трудится ещё один выживший диск).
Максимальная гибкость вашего хранилища:
- закончилось место? Замените диск на более объёмный, и ваш покорный ZFS сам займёт новоотведённое ему место (по параметру autoexpand);
- лучшая реализация снапшотов среди файловых систем для Linux. На это подсаживаешься. Инкрементально по сети, в архив,
/dev/null, да хоть раздвойте личность вашего дорогого Linux в реальном времени (clone); - нужно больше
золотаместа? 256 зебибайт хватит всем!
Структура.
В ZFS структура хранилища выглядит следующим образом:
- pool
-- vdev (virtual device) - объединяет носители (в mirror, stripe и др.)
--- block device - диск, массив, файлВ пуле может быть неограниченное количество vdev, что позволяет создать пул из двух и более mirror, RAID-Z или других сочетаний. Также доступны классические RAID10 и т.д.
Типы массивов:
Stripe — обычный RAID0.
Mirror — RAID1 на манер ZFS — реплицируются только занятые блоки, забудьте о синхронизации пустого места.
RAID-Z — создавался как замена RAID5-6, но имеет большие отличия:
— каждый блок данных — аналог отдельного массива (с динамической длинной);
— отсутствует проблема write hole;
— при ребилде создаются только данные (т.е. риск сбоя в этот момент уменьшается). Также в тестовой ветке уже находятся улучшения, которые дополнительно ускорят этот процесс.
Рекомендуется использовать RAID-Z2 (аналог RAID6). При создании RAID-Z стоит обязательно изучить эту статью, основные нюансы:
— IOPS равен самому медленному диску (создавайте RAID-Z с наименьшим количеством дисков);
— эффективность утилизации места увеличивается при бОльшем количестве дисков в массиве (требуется задать корректный recordsize, см. ссылку выше);
— в существующий массив RAID-Z нельзя добавить ещё один диск (пока), но можно заменить диски на более ёмкие. Эта проблема решается созданием нескольких массивов в рамках одного vdev.
dRAID (в разработке) — базируется на наработках RAID-Z, но при сбое позволяет задействовать на чтение-запись все диски массива.
ARC — умное кеширование в ZFS.
CoW ухудшает производительность. Для сглаживания ситуации был создан adaptive replacement cache (ARC). Его основная особенность в проработанных эвристиках для исключения вымывания кеша, в то время как обычный page cache в Linux к этому очень чувствителен.
Бонусом к ARC существует возможность создать быстрый носитель со следующим уровнем кеша — L2ARC. При необходимости он подключается на быстрые SSD и позволяет заметно улучшить IOPS HDD дисков. L2ARC является аналогом bcache со своими особенностями.
L2ARC стоит использовать только после увеличения ОЗУ на максимально возможный объём.
Также существует возможность вынести запись журнала — ZIL, что позволит значительно ускорить операции записи.
Дополнительные возможности.
Компрессия — с появлением LZ4 позволяет увеличить скорость IO за счёт небольшой нагрузки на процессор. Нагрузка настолько мала, что включение данной опции уже является повсеместной рекомендацией. Также есть возможность воспользоваться другими алгоритмами (для бекапов прекрасно подходит gzip).
Дедупликация — особенности: процесс дедупликации производится синхронно при записи, не требует дополнительной нагрузки, основное требование — ~ 320 байт ОЗУ на каждый блок данных (Используйте команду
zdb -S название_пула для симуляции на существующем пуле) или ~ 5гб на каждый 1 тб. В ОЗУ хранится т.н. Dedup table (DDT), при недостатке ОЗУ каждая операция записи будет упираться в IO носителя (DDT будет читаться каждый раз с него).Рекомендуется использовать только на часто повторяющихся данных. В большинстве случаев накладные расходы не оправданы, лучше включить LZ4 компрессию.
Снапшоты — в силу архитектуры ZFS абсолютно не влияют на производительность, в рамках данной статьи на них останавливаться не будем. Отмечу только прекрасную утилиту zfs-auto-snapshot, которая создаёт их автоматически в заданные интервалы времени. На производительности не отражается.
Шифрование (в разработке) — будет встроенным, разрабатывается с учётом всех недостатков реализации от Oracle, а также позволит штатными send/receive и scrub отправлять и проверять данные на целостность без ключа.
Основные рекомендации (TL;DR):
— Заранее продумайте геометрию массива, в настоящий момент ZFS не умеет уменьшаться, а также расширять существующие массивы (можно добавлять новые или менять диски на более объёмные);
— используйте сжатие:
compression=lz4— храните расширенные атрибуты правильно, по умолчанию хранятся в виде скрытых файлов (только для Linux):
xattr=sa— отключайте atime:
atime=off— выставляйте нужный размер блока (recordsize), файлы меньше recordsize будут записываться в уменьшенный блок, файлы больше recordsize будут записывать конец файла в блок с размером recordsize (при
recordsize=1M файл размером 1.5мб будет записан как 2 блока по 1мб, в то время как файл 0.5мб будет записан в блок размером 0.5мб). Больше — лучше для компрессии:recordsize=128K— ограничьте максимальный размер ARC (для исключения проблем с количеством ОЗУ):
echo "options zfs zfs_arc_max=половина_ОЗУ_в_байтах" >> /etc/modprobe.d/zfs.conf
echo половина_ОЗУ_в_байтах >> /sys/module/zfs/parameters/zfs_arc_max— дедупликацию используйте только по явной необходимости;
— по возможности используйте ECC память;
— настройте zfs-auto-snapshot.
— большинство SSD врёт системе о размере блока, для перестраховки контролируйте его (параметр ashift). Ссылка на список исключений для SSD в коде ZFS.
Важные моменты:
— многие свойства действуют только на новые данные, к примеру при включении сжатия оно не применится к уже существующим данным. В дальнейшем возможно создание программы, применяющей свойства автоматически. Обходится простым копированием.
— консольные команды ZFS не запрашивают подтверждение, при выполнении
destroy будьте бдительны!— ZFS не любит заполнение пула на 100%, как и все другие CoW ФС, после 80% возможно замедление работы без должной настройки.
— требуется правильно выставлять размер блока, иначе производительность приложений может быть неоптимальна (примеры — Mysql, PostrgeSQL, torrents).
— делайте бекапы на любой ФС!
В настоящий момент ZFS on Linux уже является стабильным продуктом, но плотная интеграция в существующие дистрибутивы будет проходить ещё некоторое время.
ZFS — прекрасная система, от которой очень сложно отказаться после знакомства. Она не является универсальным средством, но в нише программных RAID массивов уже заняла своё место.
Я, gmelikov, состою в проекте ZFS on Linux и готов с радостью ответить на любые вопросы!
Отдельно хочу пригласить к участию, всегда рады issues и PR, а также готовы помочь вам в наших mailing lists.
Полезные ссылки:
ZFS on Linux github page
FAQ
ZFS Performance tuning
Update (12.02.2018): Добавлена информация про ashift SSD дисков.
