
О семантическом поиске говорят уже на протяжении нескольких лет. Любая технология, которая сможет сместить Google с вершины, вызывает всеобщий интерес. Особенно если речь идет о долгожданной и часто обсуждаемой возможности семантического поиска. Однако нас ни столько интересует прогресс в этой области, сколько огорчает отсутствие реальных результатов проводимых исследований, ведь итоги поиска не так уж и сильно отличаются от итогов поиска Google. В чем же дело?
Например, при вводе в строку поиска «Столица Франции», оба метода дают один и то же правильный ответ: «Париж». Кроме того, большинство запросов, которые мы вбиваем в строку поиска в виде аббревиатур, дают те же результаты, если вводить термин полностью. Очевидно, что тут что-то не так. Всем известно, что семантические технологии способны на многое, но почему? И как они работают? Ознакомившись с этой статьей, вы узнаете, что на самом деле, мы просто-напросто задаем не те вопросы.
Ошибка заключается в том, что семантические поисковые системы, по сути, обладают аналогичной с Google строкой ввода, которая позволяет нам вводить запросы в свободной форме. Поэтому мы вводим запросы так, как привыкли – в простейшей форме. Мы никогда не будем вводить в строку поиска «Какой актер снимался в фильмах «Криминальное чтиво» и «Лихорадка субботним вечером»? или «Какие два сенатора США брали взятки от иностранных компаний?». Мы всегда вбиваем простые фразы, но сила семантического поиска не в этом. Чтобы понять, как все работает, предлагаем рассмотреть несколько технологий семантического поиска от Google, SearchMonkey, Powerset и Freebase.
Какую проблему мы пытаемся решить?
Первая сложность возникает, когда семантический поиск начинают считать решением всевозможных задач – от современной системы поиска, где доминирует Google, до задач, которые нельзя решить вычислительным путем. Все еще более усложняется тем, что в настоящее время есть лишь несколько областей знания, где семантический поиск действительно справляется лучше — это сложные запросы о выводах и рассуждениях о сложных системах данных.
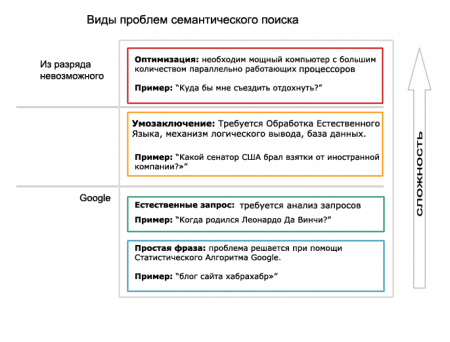
Как видно из приведенных данных, Google легко справляется с основными видами запросов. К сожалению, автоматическая обработка естественного языка дает в этом лишь небольшое преимущество. Google даст верный ответ на вопрос о годе рождения Леонардо, не предоставляя никаких шансов усовершенствовать процесс поиска пониманием существительных и глаголов, которые вбивает пользователь в строку поиска.
Перед тем, как рассмотреть задачи, с которыми легко справляется семантический поиск, рассмотрим самые сложные задачи. Существуют требующие вычисления задачи, которые не имеют ничего общего с пониманием семантики слова. На ранней стадии существования Семантического Веба бытовало мнение, что с его помощью мы сможем решать даже сверхсложные задачи, но, к сожалению это не так. Есть пределы того, что мы можем вычислить, и есть класс задач с огромным числом возможных решений, и мы не можем волшебным способом решить эти задачи только потому, что представили информацию в RDF.
Но есть также и пласт задач, с которыми семантический веб справляется великолепно. Мы решали их при помощи тематической базы данных. Но не стоит забывать, что семантические технологии помогают нам отыскать тематическую информацию, рассредоточенную по всей сети – потому для нас нет ничего удивительного в том, что семантические поисковые системы превзойдут тематические запросы.
Обзор семантических поисковых систем
Суть семантического поиска не только в вопросах, задаваемых нами. По причине того, что веб – это набор неструктурированных HTML-страниц, в основе семантического поиска лежит еще и базовая информация. Самой четкой и понятной из всех мы нашли Freebase – семантическая база данных. Freebase работает не только через текстовый поиск, а что наиболее важно, и через — MQL (Metaweb Query Language). MQL это почти тот же JSON (текстовый формат обмена данными), но с более широкими возможностями. С его помощью вы можете составить любой запрос в Freebase и ответом будет тот же запрос, но уже со вставленными результатами поиска.

Powerset, по сути, это тематическая база данных, которая работает с определенной структурированной информацией. С другой стороны есть Google, который в первую очередь ориентируется на статистическую частоту запросов и почти не принимает во внимание семантику. Вызывает интерес новая система SearchMonkey от Yahoo! Эта система ничего не добавляет к найденным результатам, но использует семантические аннотации для более полного, интерактивного и полезного пользовательского интерфейса.
Компании Hakia и Powerset явно работают с максимальной отдачей. Они пытаются создать подобные Freebase структуры, а потом по топовым результатам провести поиск на естественном языке. Отличие в том, что Hakia (как и другие) использует технологию для поиска по всей сети, а Powerset замкнул свой поиск на Wikipedia.
Что общего и где различия?
В связи с этим появляется вопрос: «Какие из этих технологий схожи, а какие кардинально отличаются?» Давайте начнем с простого. SearchMonkey ничем не отличается от Google и любой другой поисковой системы, т.к. суть у них одна, а разница присутствует лишь во внешнем виде. Сервис SearchMonkey хорош тем, что позволят издателям представить результаты поиска в наилучшем виде.
Что же касается Hakia, Powerset и Freebase, то тут ситуация иная. На первый взгляд они совершенно разные: Hakia в поиске использует весь веб, Powerset – лишь Wikipedia и Freebase, а Freebase обладает двумя поисковыми интерфейсами: поисковая строка и язык поиска. Но существует одна проблема: естественный язык не имеет ничего общего с репрезентативностью базовой информации.
Дело в том, что все технологии семантического поиска позволяют пользователям вбивать произвольные сложные вопросы, а затем интерпретируют их и применяют к имеющимся базам данных. Hakia, Powerset, Freebase такими базами являются, и все они обладают системой автоматической обработки естественного языка, которая «переводит» вопрос на стандартный запрос, понятный для базы.
Чтобы понять, как это все устроено, представьте Freebase и его язык поиска MQL. В отличие от естественного языка, который позволяет задать вопрос разными способами, MQL двусмысленности не предполагает. Этот JSON-подобный язык позволяет пользователям формулировать четкие запросы для поиска в базе Freebase. То, что Powerset позволяет строить вопросы на естественном языке, еще не значит, что Powerset не является базой данных. Powerset – это база, т.к. в ее основе лежит поисковая строка Freebase. Отличие Freebase от Powerset заключается в подходах к поиску и способам предоставления его результатов.
Назад в будущее: все дело в пользовательском интерфейсе
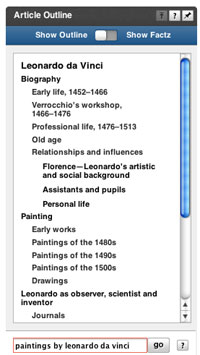
Возможно, самым важным моментом в семантическом поиске является пользовательский интерфейс. В Powerset поняли, что в нем должна быть отражена семантика. После поиска в Powerset, контекстуальный гаджет, который знаком с семантикой результатов, поможет пользователю завершить весь процесс.
Слабым местом Powerset является интерфейс. Поисковая строка, с которой знакомы все, кто когда-либо что-то искал в сети, устарела. Слишком простой интерфейс Powerset и Hakia не приносит им пользы, но и не слишком отражается на Freebase, который не позиционирует себя, как поисковая система.
Вспомните недавний старт Powerset. Компания предоставила лучший способ для поиска в одном из самых мощных источников информации в сети — в Wikipedia. Но что говорят критики? Можно ли назвать эту систему главным конкурентом Google? Ответ однозначен — нет.
А что если на Powerset наложены некие ограничения по поиску? Что если вместо поисковой строки использовался другой интерфейс или компания сказала пользователям не искать то, что они легко могут найти в Google? Может, новые компании должны улучшить алгоритм поиска, который существует уже более 10 лет? В любом случае, любые идеи должны быть нацелены на то, чтобы решить задачи, которые не может на сегодняшний день решить Google.
Заключение
Семантический поиск – это технология будущего, поставившая перед собой слишком высокие цели. Все мы думали, что он поможет свергнуть Google и предоставить наиболее качественные результаты поиска. Оба эти утверждения оказались ложными. Правда в том, что семантический поиск — явление многофакторное, и он поможет нам решать те задачи, которые мы не можем решить сейчас: сложные, логически обоснованные запросы, которые сплошь и рядом встречаются в сети.
Для того, чтобы технологии семантического поиска заняли свою нишу на рынке, компаниям необходимо пересмотреть поставленные цели и улучшить пользовательский интерфейс. Поисковая строка не актуальна и сулит убытки, т.к. она ассоциируется с простыми вопросами, с которыми легко справляется Google. Разработчикам необходимо предложить совершенно новый интерфейс, чтобы пользователи смогли полностью ощутить всю мощь семантического поиска.
