Когда Вы запускаете свой продукт — Вы совершенно не знаете, что произойдет после запуска. Вы можете так и остаться абсолютно никому не нужным проектом, можете получить небольшой ручеек клиентов или сразу целое цунами пользователей, если про Вас напишут ведущие СМИ. Не знали и мы.
Этот пост об архитектуре нашей системы, ее эволюционном развитии на протяжении уже почти 3-х лет и компромиссах между скоростью разработки, производительностью, стоимостью и простотой.
Упрощенно задача выглядела так — нужно соединить микроконтроллер с мобильным приложением через интернет. Пример — нажимаем кнопку в приложении зажигается светодиод на микроконтроллере. Тушим светодиод на микроконтроллере и кнопка в приложении соответственно меняет статус.
Так как мы стартовали проект на кикстартере, перед запуском сервера в продакшене у нас уже была довольно большая база первых пользователей — 5000 человек. Наверное многие из Вас слышали про известный хабра эффект, который положил в прошлом многие веб ресурсы. Мы, конечно же, не хотели повторять эту участь. Поэтому это отразилось на подборе технического стека и архитектуре приложения.
Сразу после запуска вся наша архитектура выглядела так:

Это была 1 виртуалка от Digital Ocean за 80$ в мес (4 CPU, 8 GB RAM, 80 GB SSD). Взяли с запасом. Так как “а вдруг лоад пойдет?”. Тогда мы действительно думали, что, вот, запустимся и тысячи пользователей ринут на нас. Как оказалось — привлечь и заманить пользователей та еще задача и нагрузка на сервер — последнее о чем стоит думать. Из технологий на тот момент была лишь Java 8 и Netty с нашим собственным бинарным протоколом на ssl/tcp сокетах (да да, без БД, spring, hibernate, tomcat, websphere и прочих прелестей кровавого энтерпрайза).
Все пользовательские данные хранились просто в памяти и периодически сбрасывались в файлы:
Весь процесс поднятия сервера сводился к одной строке:
Пиковая нагрузка сразу после запуска составила 40 рек-сек. Настоящего цунами так и не произошло.
Тем не менее мы много и упорно работали, постоянно добавляли новые фичи, слушали отзывы наших пользователей. Пользовательская база хоть и медленно, но стабильно и постоянно росла на 5-10% каждый мес. Так же росла и нагрузка на сервер.
Первой серьезной фичей стал репортинг. В момент когда мы начали его внедрять — нагрузка на систему уже составляла 1 млрд реквестов в месяц. Причем большинство запросов были реальные данные, такие как показания датчиков температуры. Было очевидно, что хранить каждый запрос — очень дорого. Поэтому мы пошли на хитрости. Вместо сохранения каждого реквеста — мы рассчитываем среднее значение в памяти с минутной гранулярностью. То есть, если вы послали в течении минуты числа 10 и 20, то на выходе получите значение 15 для этой минуты.
Сначала я поддался хайпу и реализовал данный подход на apache spark. Но когда дело дошло до деплоймента, понял что овчинка не стоит выделки. Так конечно было “правильно” и по “энтерпрайзному”. Но теперь мне предстояло деплоить и мониторить 2 системы вместо моего уютного монолитика. Кроме того добавлялся оверхед на сериализацию данных и их передачу. В общем я избавился от спарка и просто подсчитываю значения в памяти и раз в минуту сбрасываю на диск. На выходе выглядит это так:

Система с одним сервером монолитом отлично работала. Но были и вполне очевидные минусы:
Спустя 8 мес после запуска — поток новых фич немного спал и у меня появилось время, чтобы изменить эту ситуацию. Задача была проста — уменьшить задержку в разных регионах, снизить риск падения всей системы одновременно. Ну и сделать все это быстро, просто, дешево и минимальными усилиями. Стартап, все-таки.
Вторая версия получилась такой:
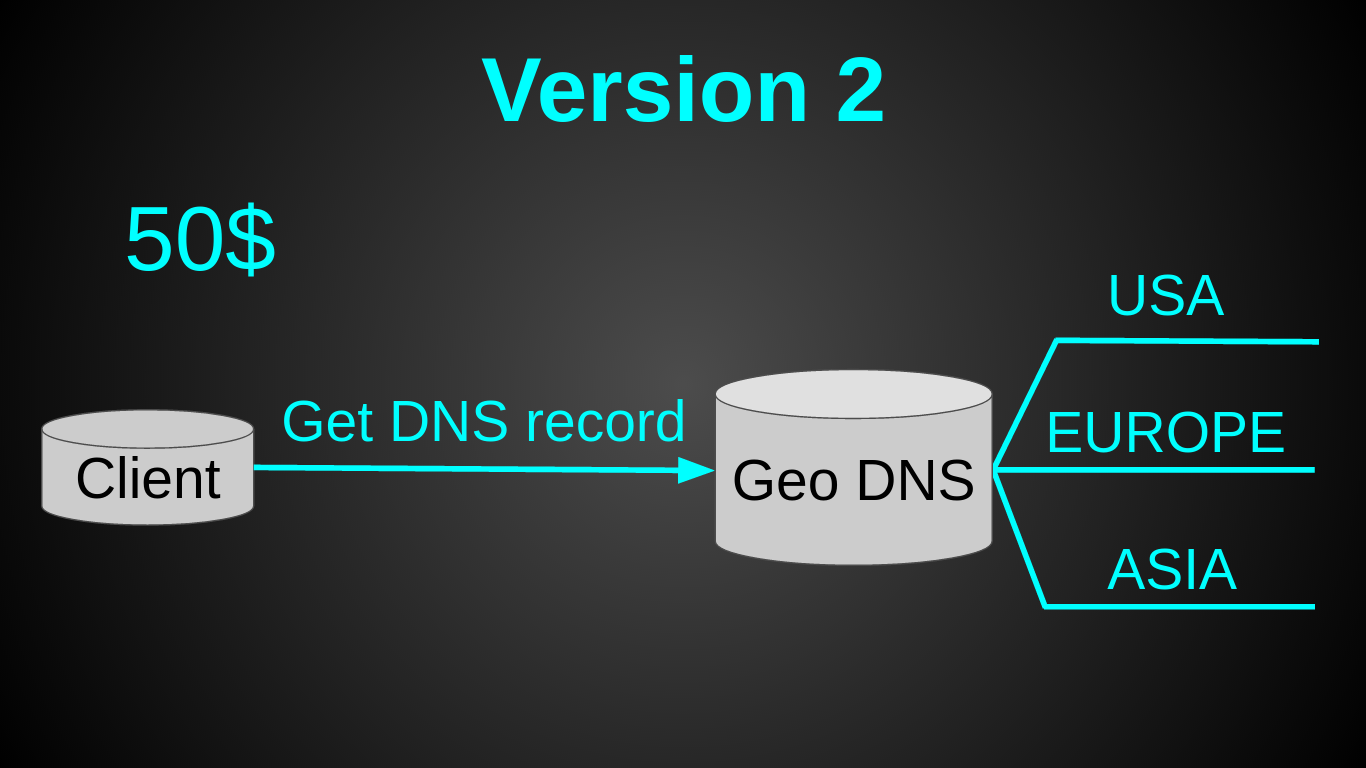
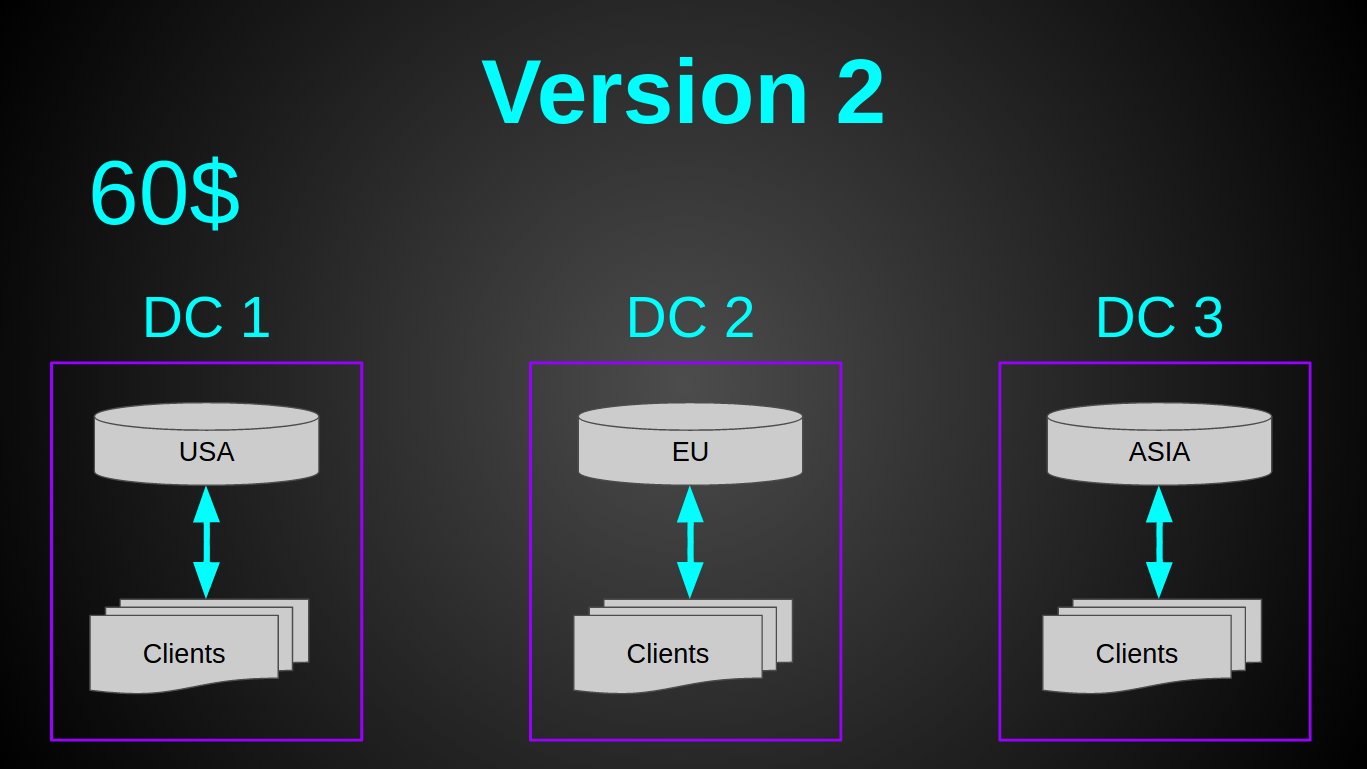
Как Вы, наверное, заметили — я остановил свой выбор на GeoDNS. Это было очень быстрое решение — вся настройка 30 мин в Amazon Route 53 на почитать и настроить. Довольно дешевое — Geo DNS роутинг у амазона стоит 50$ в мес (я искал альтернативы дешевле, но не нашел). Довольно простое — так как не нужен был лоад балансер. И требовало минимум усилий — пришлось лишь немного подготовить код (заняло меньше дня).
Теперь у нас было 3 монолитных сервера по 20$ (2 CPU, 2 GB RAM, 40 GB SSD) + 50$ за Geo DNS. Вся система стоила 110$ в мес, при этом она имела на 2 ядра больше за цену на 20$ дешевле. В момент перехода на новую архитектуру нагрузка составляла 2000 рек-сек. А прежняя виртуалка была загружена лишь на 6%.

Все проблемы монолита выше — решались, но появлялась новая — при перемещении человека в другую зону — он будет попадать на другой сервер и у него ничего не будет работать. Это был осознанный риск и мы на него пошли. Мотивация очень простая — юзеры не платят (на тот момент система была полностью бесплатной), так пусть терпят. Так же мы воспользовались статистикой, согласно которой — лишь 30% американцев хоть раз в жизни покидали свою страну, а регулярно перемещаются лишь 5%. Поэтому предположили, что данная проблема затронет лишь небольшой % наших пользователей. Предсказание оправдалось. В среднем мы получали около одного письма в 2-3 дня от пользователя у которого “Пропали проекты. Что делать? Спасите!”. Со временем такие письма начали очень сильно раздражать (несмотря на детальную инструкцию как быстро пользователю это пофиксить). Тем более такой подход врядли бы устроил бизнес, на который мы только начали переключатся. Нужно было что-то делать.
Вариантов решения проблемы было много. Я решил, что самым дешевым способом это сделать будет направлять микроконтроллеры и приложения на один сервер (чтобы избежать оверхед при передаче сообщений из одного сервера другому). В общем требования к новой системе вырисовывались такими — разные соединения одного пользователя должны попадать на один сервер и нужен shared state между такими серверами, чтобы знать куда конектить пользователя.
Я слышал очень много хороших отзывов о кассандре, которая отлично подходила под эту задачу. Поэтому решил попробовать ее. Мой план выглядел так:

Да, я нищеброд и наивный чукотский юноша. Я думал что смогу поднять одну ноду кассандры на самой дешевой виртуалке у ДО за 5$ — 512 MB RAM, 1 CPU. И я даже прочитал статью счастливчика, который поднимал кластер на Rasp PI. К сожалению, мне не удалось повторить его подвиг. Хотя я убрал/урезал все буферы, как было описано в статье. Поднять одну ноду кассандры мне удалось лишь на 1Гб инстансе, при этом нода сразу же упала с OOM (OutOfMemory) при нагрузке в 10 рек-сек. Более-менее стабильно кассандра себя вела с 2ГБ. Нарастить нагрузку одной ноды касандры до 1000 рек-сек так и не удалось, опять OOМ. На этом этапе я отказался от касандры, так как даже если бы она показала достойный перформанс, минимальный кластер в одном датацентре обходился бы в 60уе. Для меня это было дорого, учитывая что наш доход тогда составлял 0$. Так как сделать надо было на вчера — я приступил к плану Б.

Старый, добрый постгрес. Он еще никогда меня не подводил (ну ладно, почти никогда, да, full vacuum?). Постгрес отлично запускался на самой дешевой виртуалке, абсолютно не кушал RAM, вставка 5000 строк батчем занимала 300мс и нагружала единственное ядро на 10%. То что надо! Я решил не разворачивать БД в каждом из датацентров, а сделать одно общее хранилище. Так как постгрес скейлить/шардить/мастер-слейвить труднее, чем ту же касандру. Да и запас прочности это позволял.
Теперь предстояло решить другую проблему — направлять клиента и его микроконтроллеры на один и тот же сервер. По сути, сделать sticky session для tcp/ssl соединений и своего бинарного протокола. Так как вносить кардинальные изменения в существующий кластер не хотелось, я решил переиспользовать Geo DNS. Идея была такая — когда мобильное приложение получает IP адрес от Geo DNS, приложение открывает соединение и шлет login по этому IP. Сервер в свою очередь или обрабатывает команду логина и продолжает работать с клиентом в случае если это “правильный” сервер или возвращает ему команду redirect с указанием IP куда он должен конектится. В худшем случае процесс соединения выглядит так:

Но был один маленький ньюанс — нагрузка. Система на момент внедрения обрабатывала уже 4700 рек-сек. К кластеру постоянно были подключены ~3к устройств. Периодически конектилось ~10к. То есть при текущем темпе роста через год это уже будет 10к рек-сек. Теоретически могла возникнуть ситуация, когда много девайсов одновременно подключаются к одному серверу (например при рестарте, ramp up period) и если, вдруг, все они коннектились “не к тому” серверу, то могла возникнуть слишком большая нагрузка на БД, что может привести к ее отказу. Поэтому я решил подстраховаться и информацию о user-serverIP вынес в редис. Итоговая система получилась такой.

При текущей нагрузке в 12 млрд рек в месяц вся система нагружена в среднем на 10%. Сетевой трафик ~5 Mbps (in/out, благодаря нашему простому протоколу). То есть в теории такой кластер за 120$ может выдержать до 40к рек-сек. Из плюсов — не нужен лоад балансер, простой деплой, обслуживание и мониторинг довольно примитивные, есть возможность вертикального роста на 2 порядка (10х за счет утилизации текущего железа и 10х за счет более мощных виртуалок).
Проект опен-сорс. Исходники можно глянуть тут.
Вот, собственно, и все. Надеюсь статья Вам понравилась. Любая конструктивная критика, советы и вопросы — приветствуются.
Этот пост об архитектуре нашей системы, ее эволюционном развитии на протяжении уже почти 3-х лет и компромиссах между скоростью разработки, производительностью, стоимостью и простотой.
Упрощенно задача выглядела так — нужно соединить микроконтроллер с мобильным приложением через интернет. Пример — нажимаем кнопку в приложении зажигается светодиод на микроконтроллере. Тушим светодиод на микроконтроллере и кнопка в приложении соответственно меняет статус.
Так как мы стартовали проект на кикстартере, перед запуском сервера в продакшене у нас уже была довольно большая база первых пользователей — 5000 человек. Наверное многие из Вас слышали про известный хабра эффект, который положил в прошлом многие веб ресурсы. Мы, конечно же, не хотели повторять эту участь. Поэтому это отразилось на подборе технического стека и архитектуре приложения.
Сразу после запуска вся наша архитектура выглядела так:

Это была 1 виртуалка от Digital Ocean за 80$ в мес (4 CPU, 8 GB RAM, 80 GB SSD). Взяли с запасом. Так как “а вдруг лоад пойдет?”. Тогда мы действительно думали, что, вот, запустимся и тысячи пользователей ринут на нас. Как оказалось — привлечь и заманить пользователей та еще задача и нагрузка на сервер — последнее о чем стоит думать. Из технологий на тот момент была лишь Java 8 и Netty с нашим собственным бинарным протоколом на ssl/tcp сокетах (да да, без БД, spring, hibernate, tomcat, websphere и прочих прелестей кровавого энтерпрайза).
Все пользовательские данные хранились просто в памяти и периодически сбрасывались в файлы:
try (BufferedWriter writer = Files.newBufferedWriter(fileTo, UTF_8)) {
writer.write(user.toJson());
}Весь процесс поднятия сервера сводился к одной строке:
java -jar server.jar &Пиковая нагрузка сразу после запуска составила 40 рек-сек. Настоящего цунами так и не произошло.
Тем не менее мы много и упорно работали, постоянно добавляли новые фичи, слушали отзывы наших пользователей. Пользовательская база хоть и медленно, но стабильно и постоянно росла на 5-10% каждый мес. Так же росла и нагрузка на сервер.
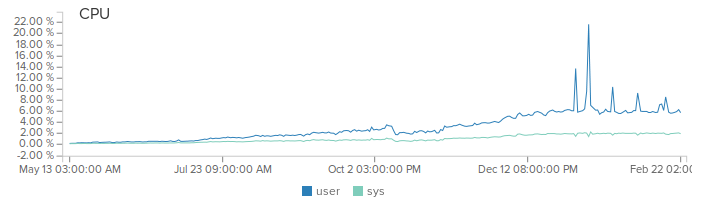
Первой серьезной фичей стал репортинг. В момент когда мы начали его внедрять — нагрузка на систему уже составляла 1 млрд реквестов в месяц. Причем большинство запросов были реальные данные, такие как показания датчиков температуры. Было очевидно, что хранить каждый запрос — очень дорого. Поэтому мы пошли на хитрости. Вместо сохранения каждого реквеста — мы рассчитываем среднее значение в памяти с минутной гранулярностью. То есть, если вы послали в течении минуты числа 10 и 20, то на выходе получите значение 15 для этой минуты.
Сначала я поддался хайпу и реализовал данный подход на apache spark. Но когда дело дошло до деплоймента, понял что овчинка не стоит выделки. Так конечно было “правильно” и по “энтерпрайзному”. Но теперь мне предстояло деплоить и мониторить 2 системы вместо моего уютного монолитика. Кроме того добавлялся оверхед на сериализацию данных и их передачу. В общем я избавился от спарка и просто подсчитываю значения в памяти и раз в минуту сбрасываю на диск. На выходе выглядит это так:
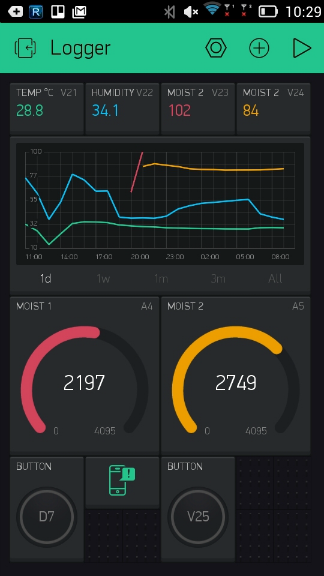
Система с одним сервером монолитом отлично работала. Но были и вполне очевидные минусы:
- Так как сервер был в Нью-Йорке — в удаленных районах, например, Азии были визуально видны лаги при интерактивном использовании приложения. Например, когда вы меняли уровень яркости лампы с помощью слайдера. Ничего критического и ни один из пользователей на это не жаловался, но мы же изменяем мир, черт побери.
- Деплой требовал обрыва всех соединений и сервер был недоступен на ~5 сек при каждом перезапуске. В активную фазу разработки мы делали около 6 деплоев в мес. Что забавно — за все время таких вот рестартов — ни один пользователь не заметил недоступность серверов. То есть рестарты были настолько быстрыми (привет спринг и томкат), что пользователи вообще не замечали их.
- Отказ одного сервера, датацентра ложил всё.
Спустя 8 мес после запуска — поток новых фич немного спал и у меня появилось время, чтобы изменить эту ситуацию. Задача была проста — уменьшить задержку в разных регионах, снизить риск падения всей системы одновременно. Ну и сделать все это быстро, просто, дешево и минимальными усилиями. Стартап, все-таки.
Вторая версия получилась такой:
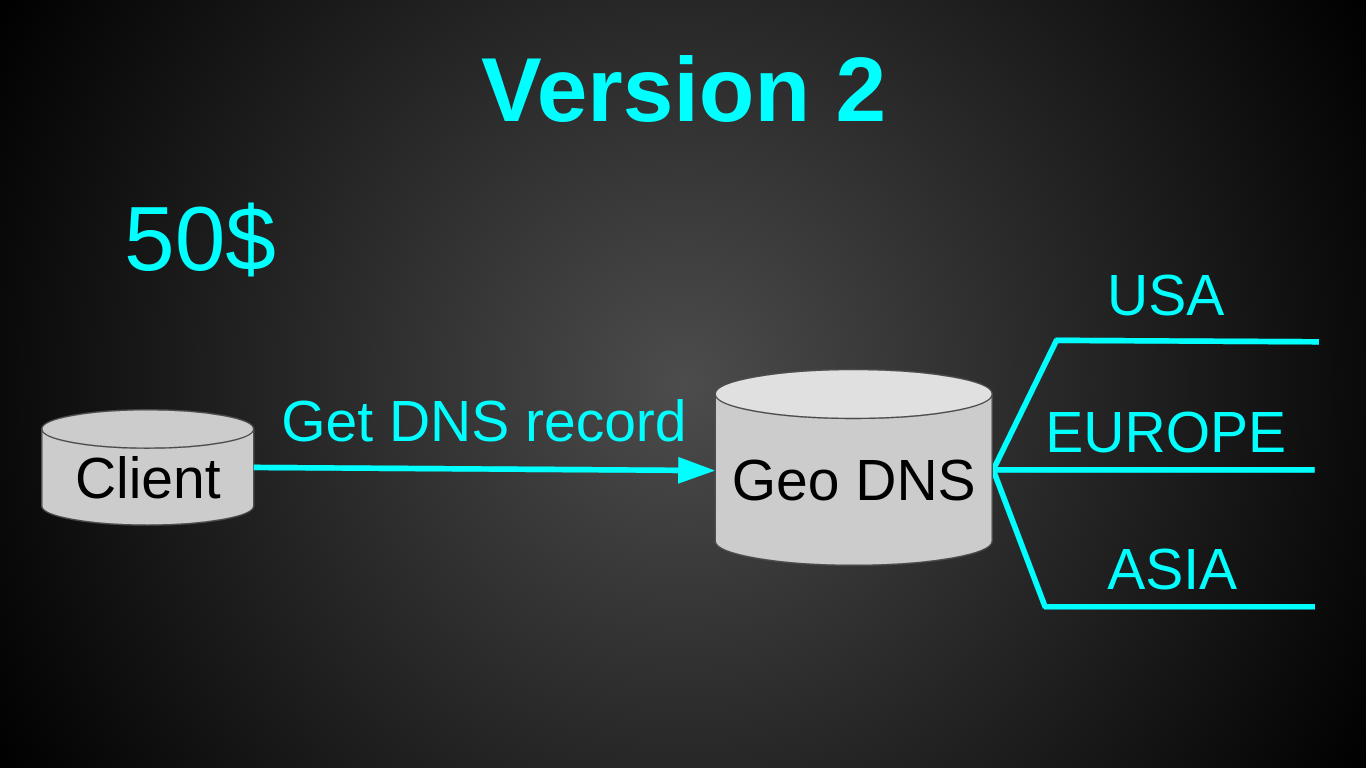
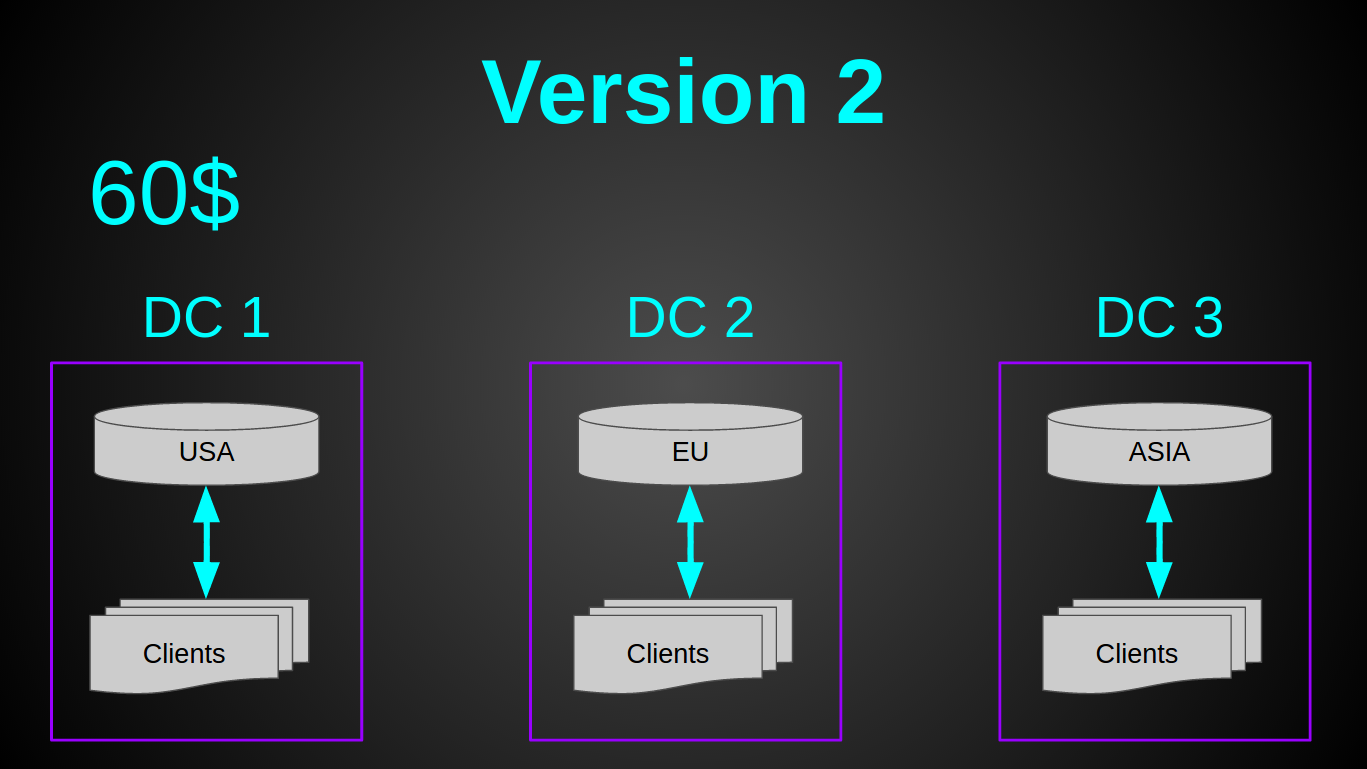
Как Вы, наверное, заметили — я остановил свой выбор на GeoDNS. Это было очень быстрое решение — вся настройка 30 мин в Amazon Route 53 на почитать и настроить. Довольно дешевое — Geo DNS роутинг у амазона стоит 50$ в мес (я искал альтернативы дешевле, но не нашел). Довольно простое — так как не нужен был лоад балансер. И требовало минимум усилий — пришлось лишь немного подготовить код (заняло меньше дня).
Теперь у нас было 3 монолитных сервера по 20$ (2 CPU, 2 GB RAM, 40 GB SSD) + 50$ за Geo DNS. Вся система стоила 110$ в мес, при этом она имела на 2 ядра больше за цену на 20$ дешевле. В момент перехода на новую архитектуру нагрузка составляла 2000 рек-сек. А прежняя виртуалка была загружена лишь на 6%.
Все проблемы монолита выше — решались, но появлялась новая — при перемещении человека в другую зону — он будет попадать на другой сервер и у него ничего не будет работать. Это был осознанный риск и мы на него пошли. Мотивация очень простая — юзеры не платят (на тот момент система была полностью бесплатной), так пусть терпят. Так же мы воспользовались статистикой, согласно которой — лишь 30% американцев хоть раз в жизни покидали свою страну, а регулярно перемещаются лишь 5%. Поэтому предположили, что данная проблема затронет лишь небольшой % наших пользователей. Предсказание оправдалось. В среднем мы получали около одного письма в 2-3 дня от пользователя у которого “Пропали проекты. Что делать? Спасите!”. Со временем такие письма начали очень сильно раздражать (несмотря на детальную инструкцию как быстро пользователю это пофиксить). Тем более такой подход врядли бы устроил бизнес, на который мы только начали переключатся. Нужно было что-то делать.
Вариантов решения проблемы было много. Я решил, что самым дешевым способом это сделать будет направлять микроконтроллеры и приложения на один сервер (чтобы избежать оверхед при передаче сообщений из одного сервера другому). В общем требования к новой системе вырисовывались такими — разные соединения одного пользователя должны попадать на один сервер и нужен shared state между такими серверами, чтобы знать куда конектить пользователя.
Я слышал очень много хороших отзывов о кассандре, которая отлично подходила под эту задачу. Поэтому решил попробовать ее. Мой план выглядел так:
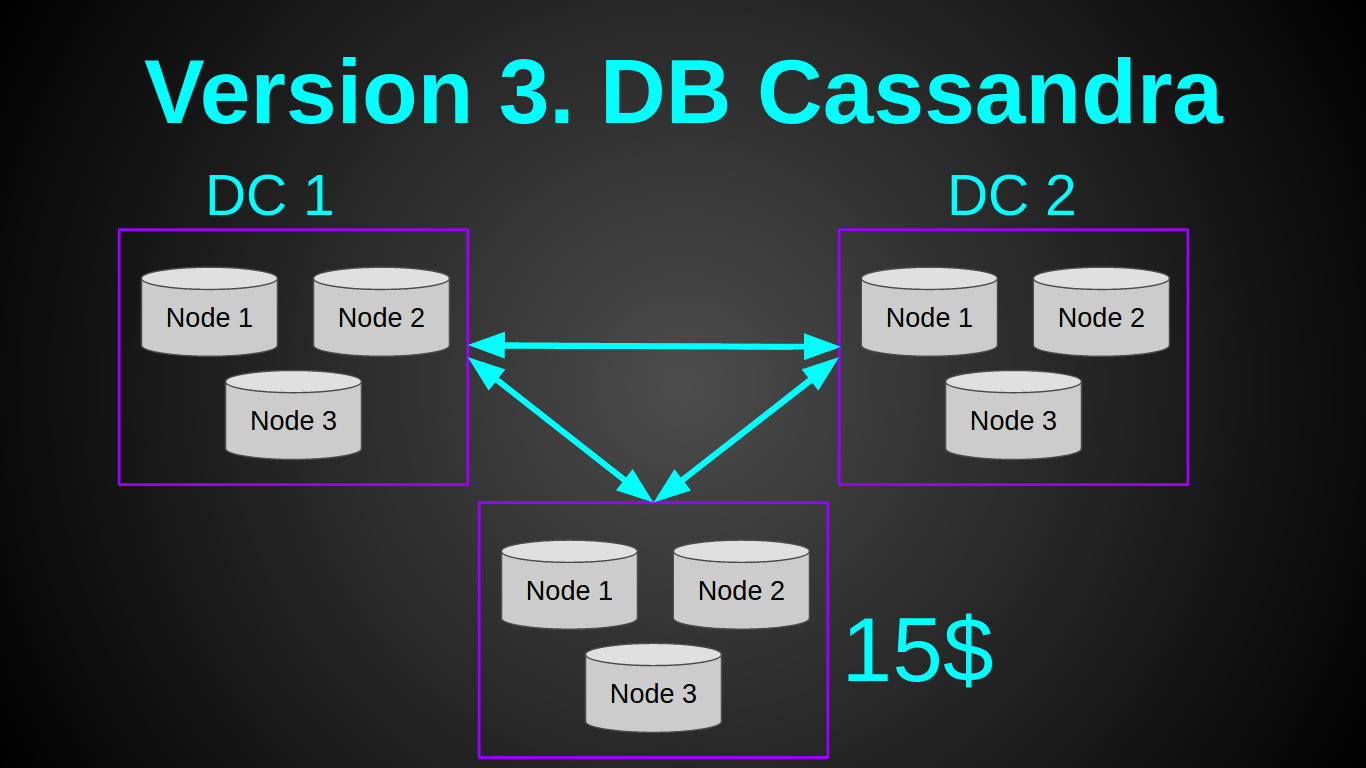
Да, я нищеброд и наивный чукотский юноша. Я думал что смогу поднять одну ноду кассандры на самой дешевой виртуалке у ДО за 5$ — 512 MB RAM, 1 CPU. И я даже прочитал статью счастливчика, который поднимал кластер на Rasp PI. К сожалению, мне не удалось повторить его подвиг. Хотя я убрал/урезал все буферы, как было описано в статье. Поднять одну ноду кассандры мне удалось лишь на 1Гб инстансе, при этом нода сразу же упала с OOM (OutOfMemory) при нагрузке в 10 рек-сек. Более-менее стабильно кассандра себя вела с 2ГБ. Нарастить нагрузку одной ноды касандры до 1000 рек-сек так и не удалось, опять OOМ. На этом этапе я отказался от касандры, так как даже если бы она показала достойный перформанс, минимальный кластер в одном датацентре обходился бы в 60уе. Для меня это было дорого, учитывая что наш доход тогда составлял 0$. Так как сделать надо было на вчера — я приступил к плану Б.
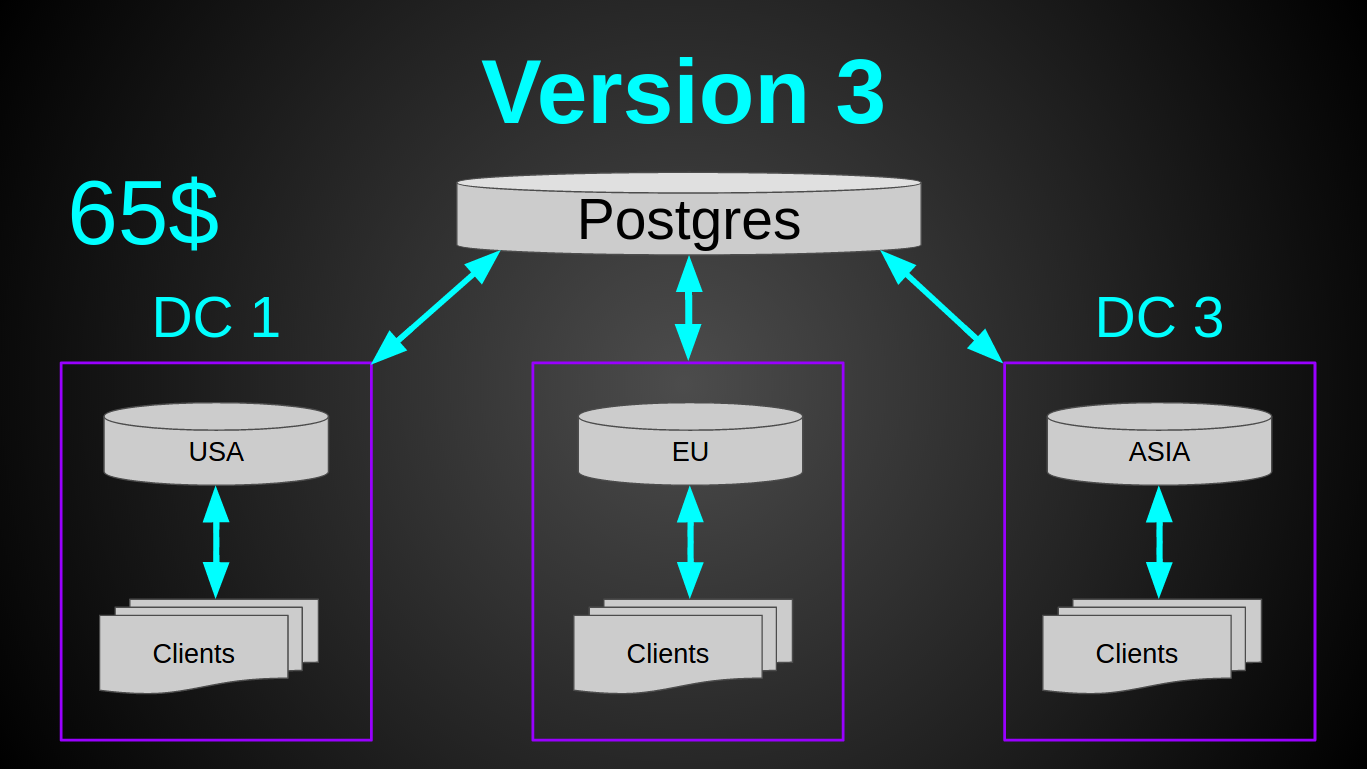
Старый, добрый постгрес. Он еще никогда меня не подводил (ну ладно, почти никогда, да, full vacuum?). Постгрес отлично запускался на самой дешевой виртуалке, абсолютно не кушал RAM, вставка 5000 строк батчем занимала 300мс и нагружала единственное ядро на 10%. То что надо! Я решил не разворачивать БД в каждом из датацентров, а сделать одно общее хранилище. Так как постгрес скейлить/шардить/мастер-слейвить труднее, чем ту же касандру. Да и запас прочности это позволял.
Теперь предстояло решить другую проблему — направлять клиента и его микроконтроллеры на один и тот же сервер. По сути, сделать sticky session для tcp/ssl соединений и своего бинарного протокола. Так как вносить кардинальные изменения в существующий кластер не хотелось, я решил переиспользовать Geo DNS. Идея была такая — когда мобильное приложение получает IP адрес от Geo DNS, приложение открывает соединение и шлет login по этому IP. Сервер в свою очередь или обрабатывает команду логина и продолжает работать с клиентом в случае если это “правильный” сервер или возвращает ему команду redirect с указанием IP куда он должен конектится. В худшем случае процесс соединения выглядит так:
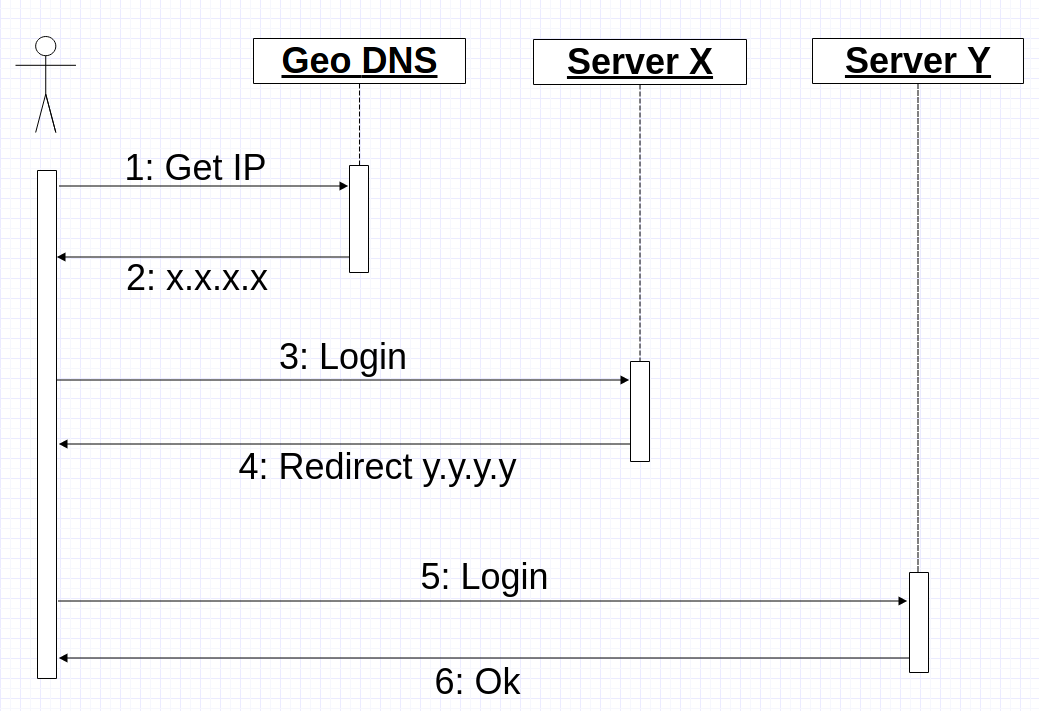
Но был один маленький ньюанс — нагрузка. Система на момент внедрения обрабатывала уже 4700 рек-сек. К кластеру постоянно были подключены ~3к устройств. Периодически конектилось ~10к. То есть при текущем темпе роста через год это уже будет 10к рек-сек. Теоретически могла возникнуть ситуация, когда много девайсов одновременно подключаются к одному серверу (например при рестарте, ramp up period) и если, вдруг, все они коннектились “не к тому” серверу, то могла возникнуть слишком большая нагрузка на БД, что может привести к ее отказу. Поэтому я решил подстраховаться и информацию о user-serverIP вынес в редис. Итоговая система получилась такой.
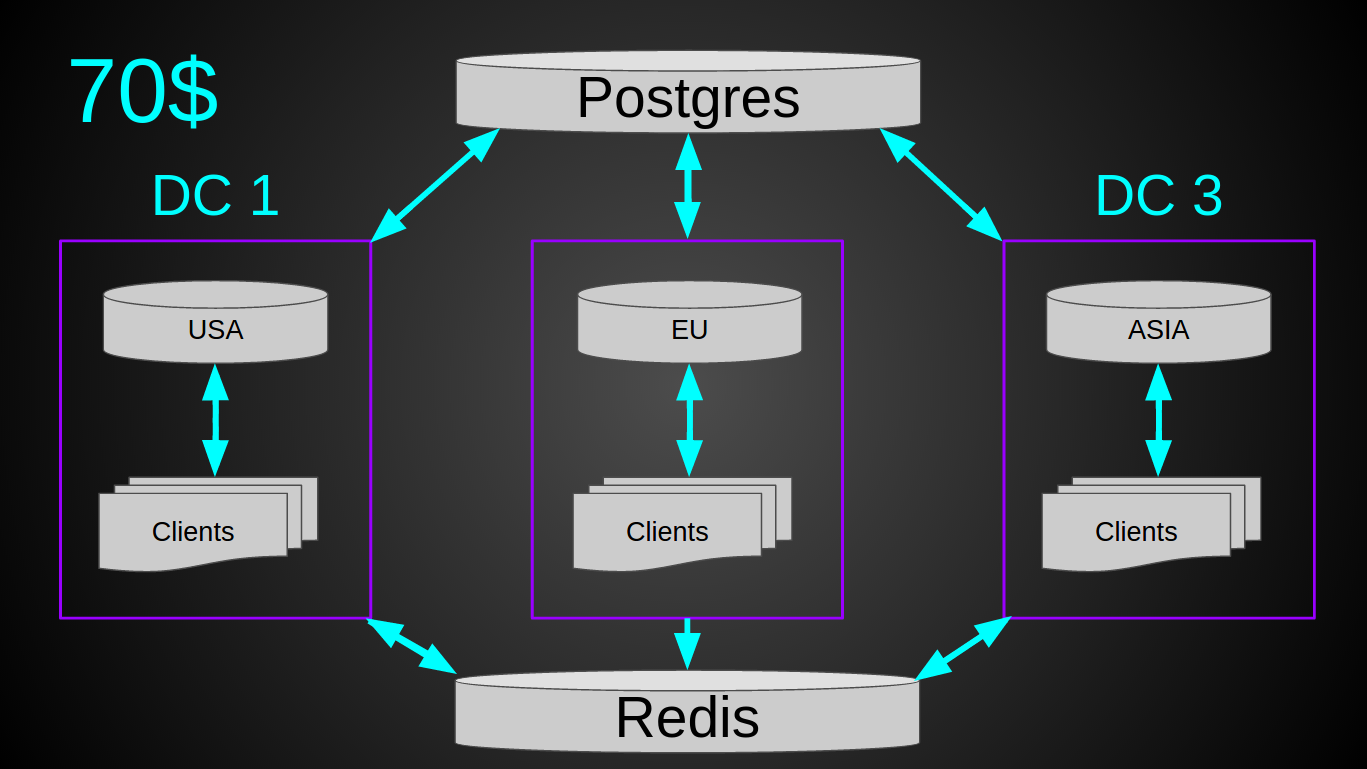
При текущей нагрузке в 12 млрд рек в месяц вся система нагружена в среднем на 10%. Сетевой трафик ~5 Mbps (in/out, благодаря нашему простому протоколу). То есть в теории такой кластер за 120$ может выдержать до 40к рек-сек. Из плюсов — не нужен лоад балансер, простой деплой, обслуживание и мониторинг довольно примитивные, есть возможность вертикального роста на 2 порядка (10х за счет утилизации текущего железа и 10х за счет более мощных виртуалок).
Проект опен-сорс. Исходники можно глянуть тут.
Вот, собственно, и все. Надеюсь статья Вам понравилась. Любая конструктивная критика, советы и вопросы — приветствуются.
