

Если программист хорошо знаком только с высокоуровневыми языками, например PHP, то ему не так просто освоить некоторые идеи, свойственные низкоуровневым языкам и критичные для понимания возможностей информационно-вычислительных процессов. По большей части причина в том, что в низко- и высокоуровневых языках мы решаем разные проблемы.
Но как можно считать себя профессионалом в каком-либо (высокоуровневом) языке, если даже не знаешь, как именно работает процессор, как он выполняет вычисления, эффективным ли способом? Сегодня автоматическое управление памятью становится главной проблемой в большинстве высокоуровневых языков, и многие программисты подходят к её решению без достаточной теоретической базы. Я уверен, что знание низкоуровневых процессов сильно помогает в разработке эффективных высокоуровневых программ.
Программы многих школьных курсов по программированию до сих пор начинаются с освоения азов ассемблера и С. Это крайне важно для будущих программистов, которым подобные знания очень пригодятся в будущей карьере. Высокоуровневые языки постоянно и сильно меняются, а интенсивность и частота изменений в низкоуровневых языках на порядок ниже.
Я считаю, что в будущем появится куча применений для низкоуровневого программирования. Поскольку всё начинается с основ, то не пропадёт потребность и в людях, создающих эти основы, чтобы другие могли возводить на них новые уровни, в результате создавая цельные, полезные и эффективные продукты.
Вы действительно думаете, что интернет вещей будет разрабатываться на высокоуровневых языках? А будущие видеокодеки? VR-приложения? Сети? Операционные системы? Игры? Автомобильные системы, например автопилоты, системы предупреждения о столкновении? Всё это, как и многие другие продукты, пишется на низкоуровневых языках вроде С или сразу на ассемблере.
Вы можете наблюдать развитие «новых» архитектур, например очень интересных ARM-процессоров, которые стоят в 98 % смартфонов. Если сегодня вы используете Java для создания Android-приложений, то лишь потому, что сам Android написан на Java и С++. А язык Java — как и 80 % современных высокоуровневых языков — написан на С (или С++).
Язык С пересекается с некоторыми родственными языками. Но они используют императивную парадигму, а потому мало распространены или не столь развиты. Например, Fortran, относящийся к той же «возрастной группе», что и С, в некоторых специфических задачах более производителен. Ряд специализированных языков могут быть быстрее С при решении чисто математических задач. Но всё же С остаётся одним из наиболее популярных, универсальных и эффективных низкоуровневых языков в мире.
Приступим
Для этой статьи я воспользуюсь машиной с процессором X86_64, работающей под управлением Linux. Мы рассмотрим очень простую программу на С, которая суммирует 1 миллиард байтов из файла менее чем за 0,5 секунды. Попробуйте проделать это на любом из высокоуровневых языков — вы и не приблизитесь по производительности к С. Даже на Java, с помощью JIT, с параллельными вычислениями и хорошей моделью использования памяти в пространстве пользователя. Если языки программирования не обращаются напрямую к машинным инструкциям, а являются некой промежуточной формой (определение высокоуровневых языков), то они не сравнятся по производительности с С (даже с помощью JIT). В некоторых областях разрыв можно уменьшить, но в целом С оставляет соперников далеко позади.
Сначала мы подробно разберём задачу с помощью С, затем рассмотрим инструкции X86_64 и оптимизируем программу с помощью SIMD — разновидности инструкций в современных процессорах, позволяющей обрабатывать большие объёмы данных одной инструкцией в несколько циклов (несколько наносекунд).
Простая программа на С
Чтобы продемонстрировать возможности языка, я приведу простой пример: открываем файл, считываем из него все байты, суммируем их, а полученную сумму сжимаем в один байт без знака (unsigned byte) (то есть несколько раз будет переполнение). И всё. Ах да, и всё это мы постараемся выполнить как можно эффективнее — быстрее.
Поехали:
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
unsigned char result = 0;
unsigned char buf[BUF_SIZE] = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i++) {
result += buf[i];
}
}
close(f);
printf("Чтение завершено, сумма равна %u \n", result);
return 0;
}Для нашего примера возьмём файл на 1 Гб. Чтобы создать такой файл со случайными данными, просто воспользуемся
dd:> dd if=/dev/urandom of=/tmp/test count=1 bs=1G iflag=fullblockТеперь передадим файл в нашу программу (назовём её file_sum) в качестве аргумента:
> file_sum /tmp/file
Read finished, sum is 186Можно просуммировать байты самыми разными способами. Но для эффективности нужно понимать:
- Как работает CPU и что он умеет (какие вычисления может производить).
- Как работает ядро ОС (kernel).
Вкратце: необходимы некоторые знания по электронике и низкому уровню ОС, на которых выполняется наша программа.
Помните о ядре
Здесь мы не будем углубляться в работу ядра. Но помните, что мы не станем просить процессор взаимодействовать с диском, на котором хранится наш файл. Дело в том, что на дворе 2016 год, и мы создаём так называемые программы пользовательского пространства (ППП). Одно из определений гласит, что такие программы НЕ МОГУТ напрямую обращаться к оборудованию. Когда возникает необходимость воспользоваться оборудованием (обратиться к памяти, диску, сети, картридеру и так далее), программа с помощью системных вызовов просит операционную систему сделать это для неё. Системные вызовы — это функции ОС, доступные для ППП. Мы не будем спрашивать диск, готов ли он обработать наш запрос, просить его переместить головку, считать сектор, перенести данные из кеша в основную память и так далее. Всё это делает ядро ОС вместе с драйверами. Если бы нам нужно было заняться такими низкоуровневыми вещами, то мы писали бы программу «пространства ядра» — по сути, модуль ядра.
Почему так? Почитайте мою статью про распределение памяти. Там объясняется, что ядро управляет одновременным выполнением нескольких программ, не позволяя им обрушить систему или перейти в необратимое состояние. При любых инструкциях. Для этого ядро переводит процессор в режим третьего кольца защиты. А в третьем кольце программа не может обращаться к аппаратно отображаемой памяти (hardware mapped memory). Любые подобные инструкции будут генерировать в процессоре исключения, как и все попытки доступа к памяти за пределами совершенно конкретных границ. На исключение в процессоре ядро отвечает запуском кода исключения (Exception code). Он возвращает процессор в стабильное состояние и завершает нашу программу с помощью какого-то сигнала (возможно, SIGBUS).
Третье кольцо защиты — режим с самыми низкими привилегиями. Все ППП выполняются в этом режиме. Можете его опробовать, считав первые два бита CS-регистра в своём X86-процессоре:
gdb my_file
(gdb) p /t $cs
$1 = 110011Первые два бита (младшие) обозначают текущий уровень кольца защиты. В данном случае — третий.
Пользовательские процессы работают в строго ограниченной изолированной среде, настраиваемой ядром, которое само выполняется в нулевом кольце (полные привилегии). Поэтому после уничтожения пользовательского процесса утечка памяти невозможна. Все структуры данных, имеющие к этому отношение, недоступны для пользовательского кода напрямую. Ядро само заботится о них при завершении пользовательского процесса.
Вернёмся к нашему коду. Мы не можем управлять производительностью чтения с диска, поскольку за это отвечают ядро, низкоуровневая файловая система и аппаратные драйверы. Мы воспользуемся вызовами
open()/read() и close(). Я не стал брать функции из libC (fopen(), fread(), fclose()), в основном потому, что они являются обёртками для системных вызовов. Эти обёртки могут как улучшать, так и ухудшать общую производительность: всё зависит от того, какой код прячется за этими инструкциями и как они используются самой программой. LibC — это прекрасно спроектированная и высокопроизводительная библиотека (ряд её ключевых функций написан на ассемблере), но всем этим функциям «ввода-вывода» нужен буфер, которым вы не управляете, и они по своему усмотрению вызывают read(). А нам надо полностью контролировать программу, так что обратимся напрямую к системным вызовам.На системный вызов ядро чаще всего отвечает вызовом
read() файловой системы, давая аппаратному драйверу команду ввода/вывода. Все эти вызовы можно отследить с помощью Linux-трассировщиков, например perf. Для программ системные вызовы затратны, потому что приводят к переключению контекста — переходу из пользовательского пространства в пространство ядра. Стоит этого избегать, поскольку переходы требуют от ядра значительного объёма работ. Но нам нужны системные вызовы! Самый медленный из них — read(). Когда он делается, процесс наверняка будет выведен из очереди выполнения в CPU и переведён в режим ожидания ввода/вывода. Когда операция завершится, ядро вернёт процесс в очередь выполнения. Эту процедуру можно контролировать с помощью флагов, передаваемых вызову open().Как вы можете знать, ядро реализует буферный кеш, в котором сохраняются недавно считанные с диска чанки данных из файлов. Это означает, что если вы несколько раз запустите одну программу, то в первый раз она может работать медленнее всего, особенно если подразумевается активное выполнение операций ввода/вывода, как в нашем примере. Так что для измерения затраченного времени мы будем брать данные, например, начиная с третьего или четвёртого запуска. Либо можно усреднить результаты нескольких запусков.
Получше узнайте своё железо и компилятор
Итак, мы знаем, что не в силах целиком управлять производительностью трёх системных вызовов:
open(), read() и close(). Но давайте здесь доверимся разработчикам пространства ядра. Кроме того, сегодня многие используют SSD-накопители, так что можно с определённой долей уверенности предположить, что наш одногигабайтный файл считается достаточно быстро.Что ещё замедляет код?
Способ сложения байтов. Может показаться, что для этого достаточно простого цикла суммирования. Но хочу ответить: узнайте получше, как работают ваш компилятор и процессор.
Давайте скомпилируем код в лоб, без оптимизаций, и запустим его:
> gcc -Wall -g -O0 -o file_sum file_sum.cЗатем отпрофилируем с помощью команды
time:> time ./file_sum /tmp/big_1Gb_file
Read finished, sum is 186
real 0m3.191s
user 0m2.924s
sys 0m0.264sНе забудьте запустить несколько раз, чтобы прогреть кеш страницы ядра. У меня после нескольких прогонов суммирование одного гигабайта с SSD заняло 3,1 секунды. Процессор ноутбука — Intel Core i5-3337U @ 1,80 ГГц, ОС — Linux 3.16.0-4-amd64. Как видите, самая обычная X86_64-архитектура. Для компилирования я использовал GCC 4.9.2.
Согласно данным
time, большую часть времени (90 %) мы провели в пользовательском пространстве. Время, когда ядро что-то делает от нашего имени, — это время выполнения системных вызовов. В нашем примере: открывание файла, чтение и закрывание. Довольно быстро, верно?Обратите внимание: размер буфера чтения равен одному килобайту. Это означает, что для одногигабайтного файла приходится вызывать
read() 1024*1024 = 1 048 576 раз. А если увеличить буфер, чтобы уменьшить количество вызовов? Возьмём 1 Мб, тогда у нас останется только 1024 вызова. Внесём изменения, перекомпилируем, запустим несколько раз, отпрофилируем:#define BUF_SIZE 1024*1024
.
> gcc -Wall -g -O0 -o file_sum file_sum.c
> time ./file_sum /tmp/big_1Gb_file
Read finished, sum is 186
real 0m3.340s
user 0m3.156s
sys 0m0.180sОтлично, удалось снизить с 264 до 180 мс. Но не увлекайтесь увеличением кеша: у скорости
read() есть определённый предел, а буфер находится в стеке. Не забывайте, что максимальный размер стека в современных Linux-системах по умолчанию 8 Мб (можно изменять).Старайтесь вызывать ядро как можно реже. Программы, интенсивно использующие системные вызовы, обычно делегируют вызовы ввода/вывода выделенному треду и/или программному вводу/выводу для асинхронности работы.
Быстрее, сильнее (и не настолько уж труднее)
Почему сложение байтов выполняется так долго? Проблема в том, что мы просим процессор выполнять его очень неэффективным способом. Давайте дизассемблируем программу и посмотрим, как процессор это делает.
Язык С — ничто без компилятора. Это лишь приемлемый для человека язык программирования компьютера. А чтобы преобразовать С-код в низкоуровневые машинные инструкции, требуется компилятор. Сегодня мы по большей части используем С для создания систем и решения низкоуровневых задач, потому что хотим иметь возможность без переписывания портировать код с одной процессорной архитектуры на другую. Именно поэтому в 1972 году был разработан С.
Так вот, без компилятора язык С — пустое место. Плохой компилятор или его неверное использование может привести к низкой производительности. То же самое справедливо и для других языков, компилируемых в машинный код, например для Fortran’а.
Процессор выполняет машинный код, который можно представить в виде инструкций языка ассемблера. С помощью компилятора или отладчика инструкции ассемблера легко извлекаются из С-программы.
Ассемблер несложно освоить. Всё зависит от архитектуры, и здесь мы рассмотрим только наиболее распространённый вариант с X86 (для 2016 года — X86_64).
В архитектуре X86_64 также нет ничего сложного. Просто в ней ОГРОМНОЕ количество инструкций. Когда я делал первые шаги в ассемблере (под Freescale 68HC11), то использовал несколько десятков инструкций. А в X86_64 их уже тысячи. Мануалы в то время были такими же, как сегодня: непонятными и многословными. А поскольку PDF тогда не было, то приходилось таскать с собой огромные книги.
Вот, к примеру, мануалы Intel по X86_64. Тысячи страниц. Это первичный источник знаний для разработчиков ядра и самых низкоуровневых разработчиков. А вы думали, что можно было бы улучшить ваши онлайн-мануалы по PHP?
К счастью, для нашей маленькой программы нет нужды читать все эти цифровые фолианты. Здесь применяется правило 80/20 — 80 % программы будет сделано с помощью 20 % общего количества инструкций.
Вот С-код и дизассемблированная часть, которая нас интересует (начиная с цикла while()), скомпилированная без оптимизаций с помощью GCC 4.9.2:
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
unsigned char result = 0;
unsigned char buf[BUF_SIZE] = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i++) {
result += buf[i];
}
}
close(f);
printf("Чтение закончено, сумма равна %u \n", result);
return 0;
}
00400afc: jmp 0x400b26 < main+198>
00400afe: movl $0x0,-0x4(%rbp)
00400b05: jmp 0x400b1b < main+187>
00400b07: mov -0x4(%rbp),%eax
00400b0a: cltq
00400b0c: movzbl -0x420(%rbp,%rax,1),%eax
00400b14: add %al,-0x5(%rbp)
00400b17: addl $0x1,-0x4(%rbp)
00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 < main+167>
00400b26: lea -0x420(%rbp),%rcx
00400b2d: mov -0xc(%rbp),%eax
00400b30: mov $0x400,%edx
00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>
00400b3f: mov %rax,-0x18(%rbp)
00400b43: cmpq $0x0,-0x18(%rbp)
00400b48: jg 0x400afe < main+158>
00400b4a: mov -0xc(%rbp),%eax
00400b4d: mov %eax,%edi
00400b4f: callq 0x4005c0 < close@plt>Видите, насколько неэффективный код? Если нет, то позвольте мне кратко рассказать вам об ассемблере под X86_64 с комментариями к вышеприведённому дампу.
Основы ассемблера под X86_64
Здесь мы пробежимся по верхам, а за подробностями обратитесь к материалам один, два и три.
Мы будем оперировать байтами и степенями 2 и 16.
- Каждая инструкция хранится в памяти по определённому адресу, указанному в левой колонке.
- Каждая инструкция уникальна и имеет имя (мнемоническое): LEA — MOV — JMP и так далее. В современной архитектуре X86_64 существует несколько тысяч инструкций.
- X86_64 — это CISC-архитектура. Одна инструкция может преобразовываться в конвейере в несколько более низкоуровневых инструкций, для выполнения каждой из которых иногда требуется несколько процессорных циклов (clock cycles) (1 инструкция != 1 цикл).
- Каждая инструкция может принимать максимум 0, 1, 2 или 3 операнда. Чаще всего 1 или 2.
- Существует две основные модели ассемблера: AT&T (также называется GAS) и Intel.
- В AT&T вы читаете INSTR SRC DEST.
- В Intel вы читаете INSTR DEST SRC.
- Есть и ряд других отличий. Если ваш мозг натренирован, то можно без особого труда переключаться с одной модели на другую. Это всего лишь синтаксис, ничего более.
- Чаще используется AT&T, кто-то предпочитает Intel. Применительно к X86 в модели AT&T по умолчанию используется GDB. Подробнее о модели AT&T.
- В X86_64 применяется порядок следования байтов от младшего к старшему (little-endian), так что готовьтесь преобразовывать адреса по мере чтения. Всегда группируйте побайтно.
- В X86_64 не разрешены операции «память-память». Для обработки данных нужно использовать какой-нибудь регистр.
- $ означает статичное непосредственное значение (например, $1 — это значение '1').
- % означает доступ к регистру (%eax — доступ к регистру EAX).
- Круглые скобки — доступ к памяти, звёздочка в С разыменовывает указатель (запись (%eax) означает доступ к области памяти, адрес которой хранится в регистре EAX).
Регистры
Регистры — это области памяти фиксированного размера в чипе процессора. Это не оперативная память! Регистры работают гораздо быстрее RAM. Если доступ к оперативке выполняется примерно за 100 нс (в обход всех уровней кеша), то доступ к регистру — за 0 нс. Самое главное в программировании процессора — это понимать сценарий, который повторяется раз за разом:
- Из оперативной памяти в регистр грузятся данные: теперь процессор «обладает» значением.
- С регистром выполняется что-нибудь (например, его значение умножается на 3).
- Содержимое регистра отправляется обратно в оперативную память.
- Если хотите, то можно перемещать данные из регистра в другой регистр того же размера.
Напоминаю, что в X86_64 нельзя выполнять обращения «память-память»: сначала нужно передать данные в регистр.
Существуют десятки регистров. Чаще всего используются регистры «общего назначения» — для вычислений. В архитектуре X86_64 доступны следующие «универсальные» регистры: a, b, c, d, di, si, 8, 9, 10, 11, 12, 13, 14 и 15 (в 32-битной X86 набор другой).
Все они 64-битные (8 байтов), НО к ним можно обращаться в четырёх режимах: 64-, 32-, 16- и 8-битном. Всё зависит от ваших потребностей.
Регистр A — 64-битный доступ. RAX — 64-битный. EAX — 32-битный. AX — 16-битный. Младшая часть: AL, старшая часть: AH.
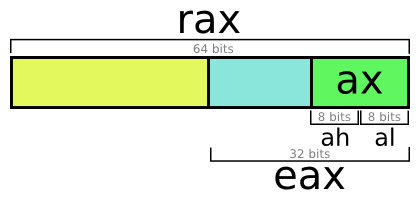
Всё очень просто. Процессор — это глупый кусок кремния, он выполняет только простейшие операции с крохотными порциями байтов. В регистрах общего назначения можно обращаться минимум к байту, а не биту. Краткий словарь:
- Один байт = 8 битов, это наименьшее доступное количество информации. Обозначается как BYTE.
- Двойной байт = 16 битов, обозначается как WORD.
- Двойной двойной байт = 32 бита, обозначается как DWORD (двойной WORD).
- 8 смежных байтов = 64 бита, обозначается как QWORD (четверной WORD).
- 16 смежных байтов = 128 битов, обозначается как DQWORD (двойной четверной WORD).
Больше информации об архитектуре X86 можно найти на http://sandpile.org/ и сайтах Intel/AMD/Microsoft. Напоминаю: X86_64 работает несколько иначе, чем X86 (32-битный режим). Также почитайте выборочные материалы из мануалов Intel.
Анализ кода X86_64
00400afc: jmp 0x400b26 JMP — это безусловный переход (unconditional jump). Перейдём по адресу 0x400b26:
00400b26: lea -0x420(%rbp),%rcx
00400b2d: mov -0xc(%rbp),%eax
00400b30: mov $0x400,%edx
00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>В этом коде делается системный вызов
read(). Если вы почитаете конвенцию вызовов в X86_64, то увидите, что большинство параметров передаются не стеком, а регистрами. Это повышает производительность вызова каждой функции в X86_64 Linux по сравнению с 32-битным режимом, когда для каждого вызова используется стек.Согласно таблице системных вызовов ядра, в
read(int fd, char *buf, size_t buf_size) первый параметр (дескриптор файла) должен быть передан в RDI, второй (буфер для заполнения) — в RSI, а третий (размер буфера для заполнения) — в RDX.Рассмотрим вышеприведённый код. Здесь используется RBP (Register Base Pointer, указатель базового регистра). RBP запоминает самое начала пространства текущего стека, в то время как RSP (Register Stack Pointer, указатель стека регистра) запоминает вершину текущего стека, на случай, если нам понадобится с этим стеком что-то сделать. Стек — это просто большой кусок памяти, выделенный для нас. Он содержит локальные переменные функции, переменные
alloca(), адрес возврата, может содержать аргументы функций, если их несколько штук.В стеке хранятся локальные переменные функции
main(), в которой мы сейчас находимся:00400b26: lea -0x420(%rbp),%rcxLEA (Load Effective Address) хранится в RBP минус 0x420, вплоть до RCX. Это наша переменная буфера —
buf. Обратите внимание, что LEA не считывает значение после адреса, только сам адрес. Под GDB вы можете напечатать любое значение и произвести вычисления:> (gdb) p $rbp - 0x420
$2 = (void *) 0x7fffffffddc0С помощью
info registers можно отобразить любой регистр:> (gdb) info registers
rax 0x400a60 4196960
rbx 0x0 0
rcx 0x0 0
rdx 0x7fffffffe2e0 140737488347872
rsi 0x7fffffffe2c8 140737488347848
... ...Продолжаем:
00400b2d: mov -0xc(%rbp),%eaxПоместим значение по адресу, указанному в RBP минус 0xc — в EAX. Скорее всего, это наша переменная
f . Это можно легко подтвердить:> (gdb) p $rbp - 0xc
$1 = (void *) 0x7fffffffe854
> (gdb) p &f
$3 = (int *) 0x7fffffffe854Идём дальше:
00400b30: mov $0x400,%edxПоместим в EDX значение 0x400 (1024 в десятичном выражении). Это
sizeof(buf): 1024, третий параметр read().00400b35: mov %rcx,%rsi
00400b38: mov %eax,%edi
00400b3a: callq 0x4005d0 < read@plt>Запишем содержимое RCX в RSI, второй параметр
read(). Запишем содержимое EAX в EDI, третий параметр read(). Затем вызовем функцию read().При каждом системном вызове его значение возвращается в регистр A (иногда ещё и в D).
read() возвращает значение ssize_t, которое весит 64 бита. Следовательно, для чтения возвращаемого значения нам нужно проанализировать весь регистр A. Для этого воспользуемся RAX (64-битное чтение регистра A):00400b3f: mov %rax,-0x18(%rbp)
00400b43: cmpq $0x0,-0x18(%rbp)
00400b48: jg 0x400afe < main+158>Запишем возвращаемое значение
read() из RAX по адресу, указанному в RBP минус 0x18. Быстрая проверка подтверждает, что это наша переменная readed из С-кода.CMPQ (Compare Quad-Word, сравнение четверного WORD). Сравниваем значение
readed со значением 0.JG (Jump if greater, переход по условию «больше»). Переходим по адресу 0x400AFE. Это всего лишь сравнение в цикле
while() из нашего С-кода. Продолжаем читать буфер и переходим по адресу 0x400AFE, это должно быть начало цикла
for().00400afe: movl $0x0,-0x4(%rbp)
00400b05: jmp 0x400b1b < main+187>MOVL (Move a Long, копирование длинного целого). Записываем LONG (32 бита) значения 0 по адресу, указанному в RBP минус 4. Это
i — целочисленная переменная в C-коде, 32 бита, то есть 4 байта. Потом она будет сохранена как самая первая переменная в стековом фрейме main() (представленном RBP).Переходим по адресу 0x400B1B, здесь должно быть продолжение цикла
for().00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 Записываем в EAX значение, указанное в RBP минус 4 (вероятно, целое число).
CLTQ (Convert Long To Quad). CLTQ работает с регистром A. Он расширяет EAX до 64-битного целочисленного значения, получаемого RAX.
CMP (Compare value, сравнение значения). Сравниваем значение в RAX со значением, на которое указывается по адресу в RBP минус 0x18. То есть сравниваем переменную
i из цикла for() с переменной readed.JL (Jump if Lower, переход по условию «меньше»). Переходим по адресу 0x400B07. Мы на первом этапе цикла
for(), так что да, переходим.00400b07: mov -0x4(%rbp),%eax
00400b0a: cltq
00400b0c: movzbl -0x420(%rbp,%rax,1),%eax
00400b14: add %al,-0x5(%rbp)
00400b17: addl $0x1,-0x4(%rbp)
00400b1b: mov -0x4(%rbp),%eax
00400b1e: cltq
00400b20: cmp -0x18(%rbp),%rax
00400b24: jl 0x400b07 < main+167>А теперь самое интересное.
Записываем (MOV)
i в EAX (как говорилось выше, i — это –0x4(%rbp)). Затем делаем CLTQ: расширяем до 64 бит.MOVZBL (MOV Zero-extend Byte to Long). Добавляем нулевой байт к длинному целому, хранящемуся по адресу (1*RAX+RBP) минус 0x420, и записываем в EAX. Звучит сложно, но это просто математика ;-) Выходит вычисление
buf[i] с помощью одной инструкции. Так мы проиллюстрировали возможности указателей в языке C: buf[i] — это buf + i*sizeof(buf[0]) байтов. Получившийся адрес легко вычисляется на ассемблере, а компиляторы выполняют кучу математических вычислений, чтобы сгенерировать такую инструкцию.Загрузив значение в EAX, мы добавляем его в
result:00400b14: add %al,-0x5(%rbp)Помните: AL — младший байт 8-байтного RAX (RAX и AL представляют собой регистр A) — это
buf[i], поскольку buf относится к типу char и весит один байт. result находится по адресу –0x5(%rbp): один байт после i, расположенного на расстоянии 0x4 от RBP. Это подтверждает, что result — это char, весящий один байт.00400b17: addl $0x1,-0x4(%rbp)ADDL (Add a long, добавление длинного целого — 32 бита). Добавляем 1 к
iИ снова возвращаемся к инструкции 00400b1b: циклу
for().Краткий итог
Устали? Это потому, что у вас нет опыта в ассемблере. Как вы могли убедиться, расшифровка ассемблера — это всего лишь арифметика на уровне начальной школы: сложить, извлечь, умножить, разделить. Да, ассемблер прост, но очень многословен. Чувствуете разницу между «труден» и «многословен»?
Если вы хотите, чтобы ваш ребёнок стал хорошим программистом, то не делайте ошибки и не ограничивайте его изучением математики только с основанием 10. Тренируйте его переключаться с одного основания на другое. Фундаментальную алгебру можно полностью понять только тогда, когда вы можете представить любые величины с любым основанием, особенно 2, 8 и 16. Для обучения детей рекомендую использовать соробан.
Если вы чувствуете себя в математике не слишком уверенно, то лишь потому, что ваш мозг всегда натаскивали только на операции с основанием 10. Переключаться с 10 на 2 трудно, потому что эти степени не кратны. А переключаться между 2 и 16 или 8 легко. Потренировавшись, вы сможете вычислять большинство адресов в уме.
Итак, нашему циклу
for() нужно шесть адресов памяти. Он был преобразован как есть из исходного C-кода: цикл выполняется для каждого байта с побайтным суммированием. Для одногигабайтного файла цикл приходится выполнять 0x40000000 раз, то есть 1 073 741 824.Даже на 2 ГГц (в CISC одна инструкция != один цикл) прогон цикла 1 073 741 824 раза отнимает достаточно времени. В результате код выполняется около 3 секунд, потому что побайтное суммирование в считанном файле крайне неэффективно.
Давайте всё векторизуем с помощью SIMD
SIMD — Single Instruction Multiple Data, одна инструкция, множественный поток данных. Этим всё сказано. SIMD представляет собой специальные инструкции, позволяющие процессору работать не с одним байтом, одним WORD, одним DWORD, а с несколькими из них в рамках одной инструкции.
Встречайте SSE — Streaming SIMD Extensions, потоковое SIMD-расширение. Вам наверняка знакомы такие аббревиатуры, как SSE, SSE2, SSE4, SSE4.2, MMX или 3DNow. Так вот, SSE — это SIMD-инструкции. Если процессор может единовременно работать с многочисленными данными, то это существенно уменьшает общую продолжительность вычислений.

При покупке процессора обращайте внимание не только на количество ядер, размер кешей и тактовую частоту. Важен ещё набор поддерживаемых инструкций. Что вы предпочтёте: складывать каждую наносекунду один байт за другим или прибавлять 8 байтов к 8 каждые две наносекунды?
SIMD-инструкции позволяют очень сильно ускорять вычисления в процессоре. Они используются везде, где допускается параллельная обработка информации. Некоторые из сфер применения:
- Матричные вычисления, лежащие в основе графики (но GPU делает это на порядок быстрее).
- Сжатие данных, когда за раз обрабатывается по несколько байтов (форматы LZ, GZ, MP3, Divx, H264/5, JPEG FFT и многие другие).
- Криптография.
- Распознавание речи и музыки.
Возьмём, к примеру, оценку параметров движения (Motion Estimation) с помощью Intel SSE 4. Этот критически важный алгоритм используется в каждом современном видеокодеке. Он позволяет на основе векторов движения, вычисленных по базовому кадру F, предсказать кадр F+1. Благодаря этому можно программировать только перемещение пикселей от одной картинки к другой, а не кодировать картинки целиком. Яркий пример — замечательные кодеки H264 и H265, у них открытый исходный код, можете его изучить (только сначала прочитайте про MPEG).
Проведём тест:
> cat /proc/cpuinfo
processor : 2
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3337U CPU @ 1.80GHz
(...)
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep ermsВсе эти флаги — по большей части поддерживаемые моим процессором инструкции и наборы инструкций.
Тут можно увидеть sse, sse2, sse4_1, sse4_2, aes, avx.
AES лежит в основе AES-шифрования! Прямо в CPU, с помощью кучи специализированных инструкций.
SSE4.2 позволяет одной инструкцией вычислять контрольную сумму CRC32, а с помощью нескольких инструкций — сравнивать строковые значения. Свежайшие функции
str() в библиотеке libC основаны на SSE4.2, поэтому вы можете так быстро грепать слово из гигантского текста.SIMD нам поможет
Пришло время улучшить нашу С-программу с помощью SIMD и посмотреть, станет ли она быстрее.
Всё началось с технологии MMX, которая добавляла 8 новых 64-битных регистров, от MM0 до MM7. MMX появилась в конце 1990-х, и отчасти из-за неё Pentium 2 и Pentium 3 стоили очень дорого. Теперь эта технология совершенно неактуальна.
Разные версии SSE, вплоть до последней SSE4.2, появлялись в процессорах примерно с 2000-го по 2010-й. Каждая последующая версия совместима с предыдущими.

Сегодня самая распространённая версия — SSE4.2. В ней добавлено 16 новых 128-битных регистров (в X86_64): с XMM0 по XMM15. 128 битов = 16 байтов. То есть, заполнив SSE-регистр и выполнив с ним какое-то вычисление, вы обработаете сразу 16 байтов.
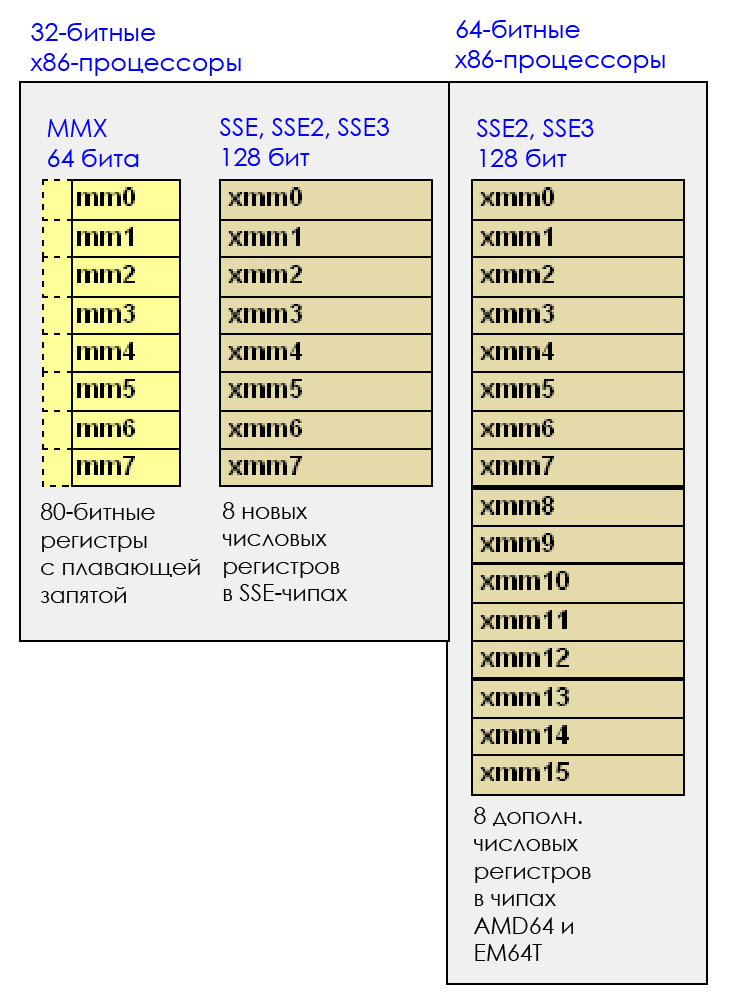
А если обработать два SSE-регистра, то это уже 32 байта за раз. Становится интересно.
С 16 байтами на регистр мы можем хранить (размеры LP64):
- 16 байтов: шестнадцать C-символов.
- Два 8-байтных значения: два длинных значения из С или два числа с двойной точностью (double precision float).
- Четыре 4-байтных значения: четыре целочисленных или четыре числа с одинарной точностью (single precision float).
- Восемь 2-байтных значения: восемь коротких значений из C.
Например:
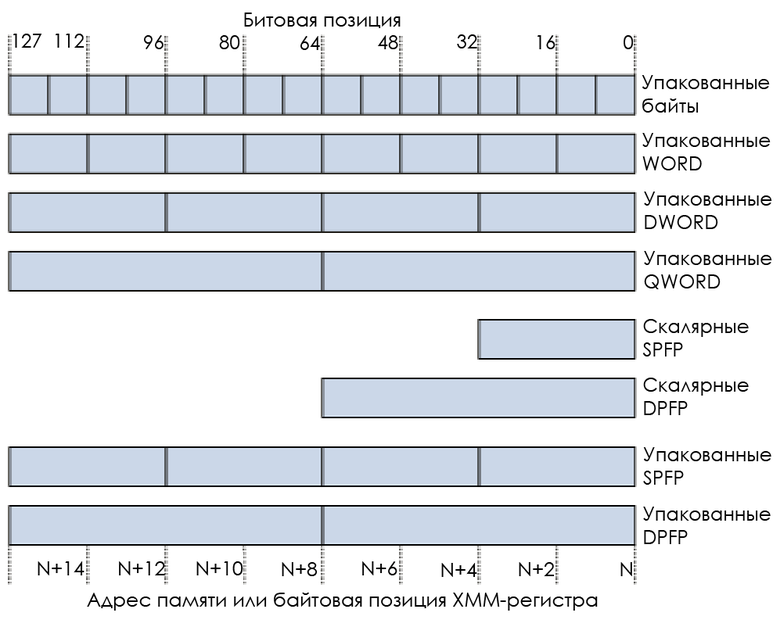
SIMD также называют «векторными» инструкциями, потому что они работают с «вектором» — областью, заполненной разными мельчайшими объектами. Векторная инструкция одновременно обрабатывает разные данные, в то время как скалярная инструкция — только одну порцию данных.
В нашей программе можно реализовать SIMD двумя способами:
- Написать на ассемблере код, работающий с этими регистрами.
- Использовать Intel Intrinsics — API, позволяющий писать C-код, который при компилировании преобразуется в SSE-инструкции.
Я покажу вам второй вариант, а первый сделаете сами в качестве упражнения.
Пропатчим наш код:
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#include <tmmintrin.h>
#define BUF_SIZE 1024
int main(int argc, char **argv)
{
int f, i;
ssize_t readed;
__m128i r = _mm_set1_epi8(0);
unsigned char result = 0;
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};
if (argc != 2) {
fprintf(stderr, "Использование: %s \n", argv[0]);
exit(-1);
}
f = open(argv[1], O_RDONLY);
if (f == -1) {
perror("Не могу открыть файл");
}
while ((readed = read(f, buf, sizeof(buf))) > 0) {
for (i=0; i < readed; i+=16) {
__m128i a = _mm_load_si128((const __m128i *)(buf+i));
r = _mm_add_epi8(a, r);
}
memset(buf, 0, sizeof(buf));
}
for (i=0; i<16; i++) {
result += ((unsigned char *)&r)[i];
}
close(f);
printf("Чтение завершено, сумма равна %u \n", result);
return 0;
}
Видите новый заголовок tmmintrin.h? Это интеловский API. Для него есть прекрасная документация.
Для хранения результата суммирования (накопительного) я решил использовать только один SSE-регистр и заполнять его строкой из памяти. Вы можете поступить иначе. Например, взять сразу 4 регистра (или вообще все), и тогда вы будете суммировать 256 байтов в 16 операциях :D
Помните размеры SSE-регистров? Наша цель — суммировать байты. Это значит, что мы будем использовать в регистре 16 отдельных байтов. Если почитаете документацию, то узнаете, что существует много функций для «упаковки» и «распаковки» значений в регистрах. Нам они не пригодятся. В нашем примере не нужно превращать 16 байтов в 8 WORD или 4 DWORD. Нам нужно просто посчитать сумму. И в целом SIMD даёт гораздо больше возможностей, чем описано в этой статье.
Итак, теперь вместо побайтового сложения мы будем складывать по 16 байтов.
В одной инструкции мы обработаем гораздо больше данных.
__m128i r = _mm_set1_epi8(0);Предыдущее выражение подготавливает XMM-регитр (16 байтов) и заполняет его нулями.
for (i=0; i < readed; i+=16) {
__m128i a = _mm_load_si128((const __m128i *)(buf+i));
r = _mm_add_epi8(a, r);
}Каждый цикл
for() теперь должен увеличивать буфер не на 1 байт, а на 16. То есть i+=16.Теперь обращаемся к буферу памяти
buf+i и наводим его на указатель __m128i*. Таким образом мы берём из памяти порции по 16 байтов. С помощью _mm_load_si128() записываем эти 16 байтов в переменную a. Байты будут записываться в XMM-регистр как «16*один байт».Теперь с помощью
_mm_add_epi8() добавляем 16-байтный вектор к нашему аккумулятору r. И начинаем прогонять в циклах по 16 байтов.В конце цикла последние байты остаются в регистре. К сожалению, нет простого способа добавить их горизонтально. Это можно делать для WORD, DWORD и так далее, но не для байтов! К примеру, взгляните на
_mm_hadd_epi16().Так что будем работать вручную:
for (i=0; i<16; i++) {
result += ((unsigned char *)&r)[i];
}Готово.
Компилируем и профилируем:
> gcc -Wall -g -O0 -o file_sum file_sum.c
> time ./file_sum /tmp/test
Read finished, sum is 186
real 0m0.693s
user 0m0.360s
sys 0m0.328sОколо 700 мс. C 3000 мс при классическом побайтовом суммировании мы упали до 700 при суммировании по 16 байтов.
Давайте дизассемблируем код цикла
while(), ведь остальной код не изменился:00400957: mov -0x34(%rbp),%eax
0040095a: cltq
0040095c: lea -0x4d0(%rbp),%rdx
00400963: add %rdx,%rax
00400966: mov %rax,-0x98(%rbp)
0040096d: mov -0x98(%rbp),%rax
00400974: movdqa (%rax),%xmm0
00400978: movaps %xmm0,-0x60(%rbp)
0040097c: movdqa -0xd0(%rbp),%xmm0
00400984: movdqa -0x60(%rbp),%xmm1
00400989: movaps %xmm1,-0xb0(%rbp)
00400990: movaps %xmm0,-0xc0(%rbp)
00400997: movdqa -0xc0(%rbp),%xmm0
0040099f: movdqa -0xb0(%rbp),%xmm1
004009a7: paddb %xmm1,%xmm0
004009ab: movaps %xmm0,-0xd0(%rbp)
004009b2: addl $0x10,-0x34(%rbp)
004009b6: mov -0x34(%rbp),%eax
004009b9: cltq
004009bb: cmp -0x48(%rbp),%rax
004009bf: jl 0x400957Нужно пояснять? Заметили
%xmm0 и %xmm1? Это используемые SSE-регистры. Как мы с ними поступим?Мы выполняем MOVDQA (MOV Double Quad-word Aligned) и MOVAPS (MOV Aligned Packed Single-Precision). Эти инструкции делают одно и то же: перемещают 128 битов (16 байтов). А зачем тогда две инструкции? Я не могу этого объяснить без подробного рассмотрения архитектуры CISC, суперскалярного движка и внутреннего конвейера.
Далее мы выполняем PADDB (Packed Add Bytes): складываем друг с другом два 128-битных регистра в одной инструкции!
Цель достигнута.
Об AVX
AVX (Advanced Vector eXtension) — это будущее SSE. Можно считать AVX чем-то вроде SSE++, вроде SSE5 или SSE6.
Технология появилась в 2011-м вместе с архитектурой Intel Sandy Bridge. И как SSE вытеснила MMX, так теперь AVX вытесняет SSE, которая превращается в «старую» технологию, присущую процессорам, из десятилетия 2000—2010.
AVX увеличивает возможности SIMD, расширяя XMM-регистры до 256 битов, то есть 32 байтов. Например, к регистру XMM0 можно обращаться как к YMM0. То есть регистры остались те же, просто были расширены.

AVX-инструкции можно использовать с XMM-регистрами из SSE, но тогда будут работать только младшие 128 битов соответствующих YMM-регистров. Это позволяет комфортно переносить код из SSE в AVX.
Также в AVX появился новый синтаксис: для одного места назначения опкоды могут брать до трёх исходных аргументов. Место назначения может отличаться от источника, в то время как в SSE оно являлось одним из источников, что приводило к «деструктивным» вычислениям (если регистр позднее должен был стать местом назначения для опкода, то приходилось сохранять содержимое регистра, прежде чем выполнять над ним вычисление). Например:
VADDPD %ymm0 %ymm1 %ymm2 : Прибавляет числа с плавающей запятой с двойной точностью из ymm1 в ymm2 и кладёт результат в ymm0Также AVX позволяет в формуле MNEMONIC DST SRC1 SRC2 SRC3 иметь в качестве адреса памяти один SRC или DST (но не больше). Следовательно, многие AVX-инструкции (не все) могут работать прямо из памяти, без промежуточной загрузки данных в регистр, а многие способны работать с тремя источниками, не только с двумя.
Наконец, в AVX есть замечательные FMA-инструкции. FMA (Fused Multiply Add) позволяет одной инструкцией выполнять такие вычисления: A = (B * C) + D.
Об AVX2
В 2013 году вместе с архитектурой Haswell появилась технология AVX2. Она позволяет добавлять байты в 256-битные регистры. Как раз то, что нужно для нашей программы. К сожалению, в AVX1 этого нет. При работе с 256-битными регистрами AVX может выполнять операции только с числами с плавающей запятой (с половинной, одинарной или двойной точностью) и с целочисленными. Но не с одиночными байтами!
Пропатчим нашу программу, чтобы использовать AVX2 и новую инструкцию VPADDB, добавляющую байты из YMM-регистров (чтобы складывать по 32 байта). Сделайте это самостоятельно, потому что мой процессор слишком старый и не поддерживает AVX2.
Мануалы по AVX и AVX2 можно скачать тут.
Об AVX-512
По состоянию на конец 2016 года технология AVX-512 предназначена для «профессиональных» процессоров Xeon-Phi. Есть вероятность, что к 2018 году она попадёт и на потребительский рынок.
AVX-512 снова расширяет AVX-регистры, с 256 до 512 битов, то есть 64 байтов. Также добавляется 15 новых SIMD-регистров, так что становится доступно в сумме 32 512-битных регистра. Обращаться к старшим 256 битам можно через новые ZMM-регистры, половина объёма которых доступна YMM-регистрам из AVX, а половина объёма YMM-регистров доступна XMM-регистрам из SSE.
Информация от Intel.
Сегодня мы можем предсказывать погоду на 15 дней вперёд благодаря вычислениям на супервекторных процессорах.
SIMD везде?
У SIMD есть недостатки:
- Необходимо идеально выравнивать данные в области памяти.
- Не каждый код допускает такое распараллеливание.
Сначала про выравнивание. Как процессор может обращаться к области памяти для загрузки 16 байтов, если адрес не делится на 16? Да никак (в одной инструкции вроде MOV).
Конструктор Lego позволяет хорошо проиллюстрировать концепцию выравнивания данных в памяти компьютера.
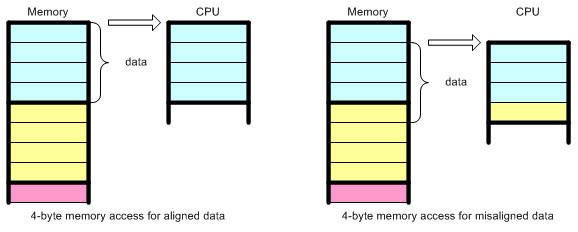
Видите проблему? Поэтому я использую в С-коде:
unsigned char buf[BUF_SIZE] __attribute__ ((aligned (16))) = {0};чтобы компьютер хранил
buf в стеке по адресу, который делится на 16.SIMD можно использовать и с невыравненными данными, но за это придётся расплачиваться так дорого, что лучше вообще не прибегать к SIMD. Вы просите процессор загрузить данные по адресу Х, затем по адресу Y, затем удалить байты из Х, затем из Y, затем вставить рядом две области памяти. Ни в какие ворота не лезет.
Подробнее о выравнивании:
Обратите внимание, что выравнивать данные в памяти рекомендуется и при работе с «классическим» С. Эту методику мы используем и в PHP. Любой автор серьёзной С-программы обращает внимание на выравнивание и помогает компилятору генерировать более качественный код. Иногда компилятор может «предполагать» и выравнивать буферы, но при этом часто задействуется динамическая память (куча), и потом приходится наводить порядок, если вас волнует падение производительности при каждом обращении к памяти. Это особенно характерно для разработки С-структур.
Другая проблема, связанная с SIMD, — ваши данные должны быть пригодны для распараллеливания. Приложение должно передавать данные в процессор в параллельных потоках. В противном случае компилятор сгенерирует классические регистры и инструкции, без использования SIMD. Однако не каждый алгоритм можно так распараллелить.
В общем, за SIMD придётся заплатить некую цену, но она не слишком велика.
Боремся с компилятором: включаем оптимизацию и автовекторизацию
В начале статьи я говорил о половине секунды на суммирование байтов. Но у нас сейчас 700 мс, это никак не 500!
Есть один трюк.
Вспомните, как мы компилировали наш С-код. Мы отключили оптимизации. Не буду вдаваться в подробности о них, но в имеющей отношение к PHP статье я рассказывал, как расширение OPCache может цепляться к PHP-компилятору и выполнять оптимизационные проходы в сгенерированном коде.
Здесь всё то же самое, но объяснять слишком сложно. Оптимизировать код непросто, это огромная тема. Погуглите некоторые термины и получите примерное представление.
Упрощённо: если приказать компилятору сгенерировать оптимизированный код, то он наверняка оптимизирует его лучше вас. Поэтому мы используем более высокоуровневый язык (в данном случае — С) и компилятор.
С-компиляторы существуют с 1970-х годов. Их оттачивали около 50 лет. В каких-то очень редких и специфических случаях вы сможете оптимизировать лучше, но и только. При этом вам придётся идеально разбираться в ассемблере.
Однако нужно знать, как компилятор работает, чтобы понимать, можно ли оптимизировать ваш код. Есть много рекомендаций, которые помогают компилятору генерировать более качественный код. Начните изучать вопрос отсюда.
Скомпилируем первую версию нашей программы — побайтное сложение без использования Intrinsics — с полной оптимизацией:
> gcc -Wall -g -O3 -o file_sum file_sum.c
> time ./file_sum /tmp/test
Read finished, sum is 186
real 0m0.416s
user 0m0.084s
sys 0m0.316sОбщее время всего 416 мс, а суммирование байтов заняло только 84 мс, тогда как на системные вызовы и доступ к диску потрачено аж 316 мс.
Мда.
Дизассемблируем. Полный код можно посмотреть здесь.
Интересный кусок:
00400688: mov %rcx,%rdi
0040068b: add $0x1,%rcx
0040068f: shl $0x4,%rdi
00400693: cmp %rcx,%rdx
00400696: paddb 0x0(%rbp,%rdi,1),%xmm0
0040069c: ja 0x400688
0040069e: movdqa %xmm0,%xmm1
004006a2: psrldq $0x8,%xmm1
004006a7: paddb %xmm1,%xmm0
004006ab: movdqa %xmm0,%xmm1
004006af: psrldq $0x4,%xmm1
004006b4: paddb %xmm1,%xmm0
004006b8: movdqa %xmm0,%xmm1
004006bc: psrldq $0x2,%xmm1
004006c1: paddb %xmm1,%xmm0
004006c5: movdqa %xmm0,%xmm1
004006c9: psrldq $0x1,%xmm1
004006ce: paddb %xmm1,%xmm0
004006d2: movaps %xmm0,(%rsp)
004006d6: movzbl (%rsp),%edx
(...) (...) (...) (...)Проанализируйте его сами. Здесь компилятор использует много трюков, чтобы повысить эффективность программы. Например, разворачивает обратно (unroll) циклы, определённым образом распределяет байты по регистрам, передавая побайтно одни и сдвигая другие.
Но здесь точно сгенерированы SIMD-инструкции, поскольку наш цикл можно «векторизовать» — превратить в векторные инструкции SIMD.
Попробуйте проанализировать весь код целиком, и вы увидите, насколько умно компилятор подошёл к решению задачи. Он знает цену каждой инструкции. Он может организовать их так, чтобы получился наилучший код. Здесь можно почитать о каждой оптимизации, выполняемой GCC на каждом уровне.
Самый трудный уровень — O3, он включает «векторизацию дерево — цикл», «векторизацию дерево — slp», а также размыкает циклы.
По умолчанию используется только O2, потому что из-за очень слишком агрессивной оптимизации O3 программы могут демонстрировать неожиданное поведение. Также в компиляторах бывают баги, как и в процессорах. Это может привести к багам в генерируемом коде или к неожиданному поведению, даже в 2016 году. Я с таким не сталкивался, но недавно нашёл баг в GCC 4.9.2, влияющий на PHP с -O2. Также вспоминается баг в управлении FPU.
Возьмём в качестве примера PHP. Скомпилируем его без оптимизации (-O0) и запустим бенчмарк. Затем сравним с -O2 и -O3. Бенчмарк должен просто перегреться из-за агрессивных оптимизаций.
Однако -O2 не активирует автовекторизацию. Теоретически при использовании -O2 GCC не должен генерировать SIMD. Раздражает факт, что каждая программа в виде Linux-пакета по умолчанию скомпилирована с -O2. Это как иметь очень мощное оборудование, но не использовать его возможности целиком. Но мы же профессионалы. Вы знаете, что коммерческие Linux-дистрибутивы могут распространяться с программами, которые при компилировании сильно оптимизируются под оборудование, с которым распространяются? Так делают многие компании, в том числе IBM и Oracle.
Вы тоже можете самостоятельно компилировать их из исходных кодов, используя -O3 или -O2 с нужными флагами. Я использую -march=native для создания ещё более специализированного кода, более производительного, но менее портируемого. Но он иногда работает нестабильно, так что тщательно тестируйте и готовьтесь к сюрпризам.
Кроме GCC, есть и другие компиляторы, например LLVM или ICC (от Intel). На gcc.godbolt.org можно в онлайне протестировать все три. Компилятор Intel генерирует лучший код для процессоров Intel. Но GCC и LLVM быстро догоняют, к тому же у вас могут быть свои идеи относительно методики тестирования компиляторов, разных сценариев и кодовых баз.
Работая со свободным ПО, вы свободны. Не забывайте: вас никто не будет подбадривать.
Вы же не покупаете коммерческую суперпрограмму, которая неизвестно как скомпилирована, и если её дизассемблировать, то можно попасть в тюрьму, поскольку это запрещено во многих странах. Или вы всё же это сделали? Ой.
PHP?
А при чём тут вообще PHP? Мы не кодим PHP на ассемблере. При генерировании кода мы полностью полагаемся на компилятор, потому что хотим, чтобы код был портируем на разные архитектуры и ОС, как и любая С-программа.
Однако мы стараемся использовать хорошо проверенные хитрости, чтобы компилятор генерировал более эффективный код:
- Многие структуры данных в PHP выравнены. Диспетчер памяти, выполняющий размещения куч, всегда выравняет по вашей просьбе буфер. Подробности.
- Мы используем alloca() только там, где она работает лучше кучи. Для старых систем, не поддерживающих alloca(), у нас есть собственный эмулятор.
- Мы используем встроенные команды GCC. Например, __builtin_alloca(), __builtin_expect() и __builtin_clz().
- Мы подсказываем компилятору, как использовать регистры для основных обработчиков виртуальной машины Zend Virtual. Подробности.
В PHP мы не используем JIT (ещё не разработали). Хотя планируем. JIT — это способ генерирования ассемблерного кода «на лету», по мере выполнения некоторых машинных инструкций. JIT улучшает производительность виртуальных машин, таких как в PHP (Zend), но при этом улучшения касаются только повторяющихся вычислительных паттернов. Чем больше вы повторяете низкоуровневые паттерны, тем полезнее JIT. Поскольку сегодня PHP-программы состоят из большого количества разнообразных PHP-инструкций, JIT оптимизирует только тяжёлые процессы, обрабатывающие большие объёмы данных в секунду в течение долгого времени. Но для PHP такое поведение нехарактерно, потому что он старается обрабатывать запросы как можно скорее и делегировать «тяжёлые» задачи другим процессам (асинхронным). Так что PHP может выиграть от внедрения JIT, но не настолько, как та же Java. По крайней мере, не как веб-технология, а при использовании в качестве CLI. CLI-скрипты сильно улучшатся, в отличие от Web PHP.
При разработке PHP мы редко обращаем внимание на сгенерированный ассемблерный код. Но иногда мы это делаем, особенно столкнувшись с «неожиданным поведением», не относящимся к С. Это может говорить о баге компилятора.
Чуть не забыл про SIMD-расширение Джо для PHP. Не спешите осуждать: это проверка концепции, но зато хорошая проверка.
У меня есть много идей относительно PHP-расширений, связанных с SIMD. Например, я хочу портировать на С часть проекта math-php и внедрить SIMD. Можно сделать расширение с публичными структурами, позволяющими PHP-пользователям применять SIMD для линейных алгебраических вычислений. Возможно, это поможет кому-то создать полноценную видеоигру на PHP.
Заключение
Итак, мы начали с создания простенькой программы на С. Увидели, что компилирование без оптимизаций привело к генерированию очень понятного и дружественного к GDB ассемблерного кода, при этом крайне неэффективного. Второй уровень оптимизации по умолчанию в GCC не подразумевает включения автовекторизации, а следовательно, не генерирует SIMD-инструкции. С использованием -O3 GCC по производительности превзошёл результаты от нашей реализации SIMD.
Также мы увидели, что наша реализация SIMD — всего лишь проверка концепции. Для дальнейшего улучшения производительности мы могли бы прибегнуть к AVX и ряду других регистров. Также при доступе к файлу можно было бы использовать mmap(), но в современных ядрах это не дало бы эффекта.
Создавая код на С, вы возлагаете работу на компилятор, потому что он её сделает лучше вас. Смиритесь с этим. В каких-то случаях вы можете взять бразды правления в свои руки и написать ассемблерный код напрямую или с помощью API Intel Intrinsics. Также каждый компилятор принимает «расширения» из языка С, которые помогают сгенерировать желаемый код. Список GCC-расширений.
Кто-то предпочитает использовать Intel Intrinsics, кто-то сам пишет ассемблерный код и считает, что так проще. Действительно несложно вставлять ассемблерные инструкции в С-программу, это позволяет делать каждый компилятор. Либо можно написать один файл проекта на ассемблере, другие на С.
Вообще С — действительно классный язык. Он стар и мало изменился за 45 лет, что доказывает его устойчивость, а значит, наше железо работает на твёрдом фундаменте. У С есть конкуренты, но он справедливо занимает львиную долю рынка. На нём написаны все низкоуровневые системы, которые мы сегодня используем. Да, теперь у нас больше потоков, несколько ядер и ряд других проблем вроде NUMA. Но процессоры по-прежнему обрабатывают так же, как и раньше, и только невероятно талантливые инженеры Intel и AMD умудряются следовать закону Мура: теперь мы можем использовать очень специализированные инструкции, одновременно обрабатывая много данных.
Я написал эту статью, потому что недавно встретил талантливых специалистов, которые полностью игнорируют всё, что здесь написано. Я подумал, что они многое упускают и даже не понимают этого. Вот и решил поделиться своими знаниями о том, как выполняются низкоуровневые вычисления.
Будучи пользователями высокоуровневых языков, не забывайте, что вы создаёте свои продукты на фундаменте из миллионов строк С-кода и миллиардов процессорных инструкций. Проблема, которую вы встретите на высоком уровне, может решаться на более низких. Процессор не умеет врать, он очень глуп и выполняет простейшие операции с крохотными объёмами данных, но зато с огромной скоростью и совсем не так, как это делает наш мозг.
Полезные ссылки:
- Intel: The significance of SIMD, SSE and AVX
- NASM
- GCC SIMD switches
- Online JS based X86 compilers
- ARM Processor Architecture
- Modern X86 Assembly Language Programming: 32-bit, 64-bit, SSE, and AVX
- X86 Opcode and Instruction Reference
- Dragon Book
- X264 Assembly with SIMD
- LAME MP3 quantizer SIMD
- Mandelbrot Set with SIMD Intrinsics
- ASM.js
- Joe's PHP SIMD
