Хочу рассказать вам еще об одном способе балансировки нагрузки. Про Pacemaker и IPaddr (ресурс-агент) и настройке его для Active/Passive кластера сказано уже и так достаточно много, но информации по организации полноценного Active/Active кластера, используя этот модуль я нашел крайне мало. Постараюсь исправить эту ситуацию.
Для начала расскажу подробнее чем такой метод балансировки примечателен:
- Отсутсвие внешнего балансировщика — На всех нодах в кластере настраивается один общий виртуальный IP-адрес. Все запросы отправляются на него. Ноды отвечают на запросы на этот адрес случайно и по договоренности между ссобой.
- Высокая доступность — Если одна нода падает ее обязаности подхватывает другая.
- Простота настройки — Настройка осуществляется всего в 3-5 команд.
Вводные данные
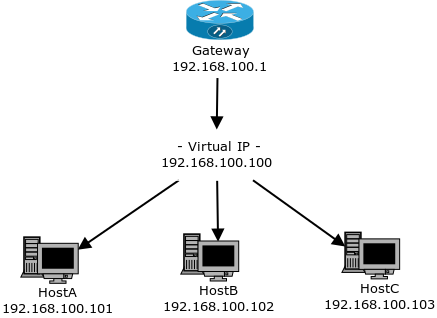
Давайте посмотрим на картинку в начале статьи, мы увидим следующие устройства:
- Gateway — IP: 192.168.100.1
- HostA — IP: 192.168.100.101
- HostB — IP: 192.168.100.102
- HostC — IP: 192.168.100.103
Клиенты будут обращаться на внешний адрес нашего шлюза, тот будет перенаправлять все запросы на виртуальный IP 192.168.100.100, который будет настроен на всех трех нодах нашего кластера.
Подготовка
Для начала нам нужно убедиться в том, что все наши ноды могут обращаться друг к другу по single hostname, для надежности лучше сразу добавить адреса нод в /etc/hosts:
192.168.100.101 hostA
192.168.100.102 hostB
192.168.100.103 hostCУстановим все необходимые пакеты:
yum install pcs pacemaker corosync #CentOS, RHEL
apt-get install pcs pacemaker corosync #Ubuntu, DebianПри установке pcs создает пользователя hacluster, давайте зададим ему пароль:
echo CHANGEME | passwd --stdin hacluster Дальше операции выполняются на одном узле.
Настраиваем аутентификацию:
pcs cluster auth HostA HostB HostC -u hacluster -p CHANGEME --force Создаём и запускаем кластер “Cluster” из трех узлов:
pcs cluster setup --force --name Cluster hostA hostB hostC
pcs cluster start --allСмотрим результат:
pcs cluster statusCluster Status:
Last updated: Thu Jan 19 12:11:49 2017
Last change: Tue Jan 17 21:19:05 2017 by hacluster via crmd on hostA
Stack: corosync
Current DC: hostA (version 1.1.14-70404b0) - partition with quorum
3 nodes and 0 resources configured
Online: [ hostA hostB hostC ]
PCSD Status:
hostA: Online
hostB: Online
hostC: OnlineНекоторые шаги были позаимствованы из статьи Lelik13a, спасибо ему за это.
В нашем конкретном случае ни кворум ни stonith нашему кластеру не требуется, так что смело отключаем и то и другое:
pcs property set no-quorum-policy=ignore
pcs property set stonith-enabled=falseВ дальнейшем, если у вас появятся ресурсы для которых это необходимо, вы можете обратиться к статье Silvar.
Пара слов о MAC-адресах
Прежде чем мы приступим, нам нужно понимать что на всех наших нодах будет настроен одинаковый IP и одинаковый mac-адрес, по запросу на который они будут поочередно давать ответы.
Проблема в том, что каждый коммутатор работает таким образом, что во время работы он составляет свою таблицу коммутации, в которой каждый mac-адрес связывается с определенным физическим портом. Таблица коммутации составляется автоматически, и служит для разгрузки сети от "ненужных" L2-пакетов.
Так вот, если mac-адрес есть в таблице коммутации, то пакеты будут отправляться только в один порт за которым и закреплен этот самый mac-адрес.
К сожалению, нам это не подходит и нам необходимо удостовериться в том, что бы все наши хосты в кластере одновременно "видели" все эти пакеты. В противном случае эта схема работать не будет.
Для начала нам нужно удостовериться в том, что используемый нами mac-адрес является multicast-адресом. То есть находится в диапазоне 01:00:5E:00:00:00 — 01:00:5E:7F:FF:FF. Получив пакет для такого адреса наш коммутатор будет передавать его во все остальные порты, кроме порта источника. Кроме того, некоторые управляемые коммутаторы позволяют настроить и определить несколько портов для конткретного MAC-адреса.
Также вам вероятно придется отключить функцию Dynamic ARP Inspection, если она поддерживается вашим коммутатором, так как она может стать причиной блокировки arp-ответов от ваших хостов.
Настройка IPaddr-ресурса
Вот мы и добрались до самого интересного.
На данный момент существует две версии IPaddr с поддержкой клонирования:
IPaddr2 (
ocf:heartbeat:IPaddr2) — Стандартный ресурс-агент для создания и работы виртуального IP-адреса. Как правило устанавливается вместе со стандартным пакетомresource-agents.
- IPaddr3 (
ocf:percona:IPaddr3) — Улучшенная версия IPaddr2 от Percona.
В эту версию включены исправления ориентированные на работу именно в режиме clone.
Требуется отдельная установка.
Для установки IPaadr3 выполните эти команды на каждом хосте:
curl --create-dirs -o /usr/lib/ocf/resource.d/percona/IPaddr3 \
https://raw.githubusercontent.com/percona/percona-pacemaker-agents/master/agents/IPaddr3
chmod u+x /usr/lib/ocf/resource.d/percona/IPaddrДальше операции выполняются на одном узле.
Создадим ресурс для нашего виртуального IP-адреса:
pcs resource create ClusterIP ocf:percona:IPaddr3 \
params ip="192.168.100.100" cidr_netmask="24" nic="eth0" clusterip_hash="sourceip-sourceport" \
op monitor interval="10s"clusterip_hash — здесь нужно указать желаемый тип распределения запросов.
Всего может быть три варианта:
sourceip— распределение только по IP-адресу источника, это гарантирует что все запросы от одного источника всегда будут попадать на один и тот же хост.sourceip-sourceport— распределение по IP-адресу источника и исходящему порту. Каждое новое соединение будет попадать на новый хост. Оптимальный вариант.sourceip-sourceport-destport— распределение по IP-адресу источника исходящему порту и порту назначения. Обеспечивает наилучшее распределение, актуально если у вас работает несколько сервисов на разных портах.
Для IPaddr2 обязательно нужно указать параметр mac=01:00:5E:XX:XX:XX с mac-адресом из multicast-диапазона. IPaddr3 устанавливает его автоматически.
Теперь склонируем наш ресурс:
pcs resource clone ClusterIP \
meta clone-max=3 clone-node-max=3 globally-unique=trueЭто действие создаст следующее правило в iptables:
Chain INPUT (policy ACCEPT)
target prot opt source destination
all -- anywhere 192.168.100.100 CLUSTERIP hashmode=sourceip-sourceport clustermac=01:00:5E:21:E3:0B total_nodes=3 local_node=1 hash_init=0Как вы можете заметить, здесь используется модуль CLUSTERIP.
Работает он следующим образом:
На три ноды приходят все пакеты, но все три Linux-ядра знают сколько нод получает пакеты, все три ядра нумеруют получаемые пакеты по единному правилу, и, зная сколько всего нод и номер своей ноды, каждый сервер обрабатывает только свою часть пакетов, остальные пакеты сервером игнорируются — их обрабатывают другие сервера.
Подробнее об этом написанно в этой статье.
Давайте еще раз посмотрим на наш кластер:
pcs cluster statusCluster Status:
Cluster name: cluster
Last updated: Tue Jan 24 19:38:41 2017
Last change: Tue Jan 24 19:25:44 2017 by hacluster via crmd on hostA
Stack: corosync
Current DC: hostA (version 1.1.14-70404b0) - partition with quorum
3 nodes and 0 resources configured
Online: [ hostA hostB hostC ]
Full list of resources:
Clone Set: ClusterIP-clone [ClusterIP-test] (unique)
ClusterIP:0 (ocf:percona:IPaddr3): Started hostA
ClusterIP:1 (ocf:percona:IPaddr3): Started hostB
ClusterIP:2 (ocf:percona:IPaddr3): Started hostC
PCSD Status:
hostA: Online
hostB: Online
hostC: OnlineIP-адреса успешно запустились. Пробуем обратиться к ним снаружи.
Если все работает как надо, то на этом настройку можно считать законченой.
Ссылки
- Кластер высокой доступности (HA-cluster) на базе Pacemaker
- HA-Cluster на основе Pacemaker под контейнерную виртуализацию LXC и Docker
- pacemaker: как добить лежачего
- The use of Iptables ClusterIP target as a load balancer for PXC, PRM, MHA and NDB
- Pacemaker load-balancing with Clone
- Распределение нагрузки на LDAP-сервера средствами iptables CLUSTERIP
- pacemaker/Ch-Active-Active.txt at master · ClusterLabs/pacemaker
- 9.5. Clone the IP address
