Для тех, кто только познает сферу анализа многомерных данных, хочу поделиться опытом, как почувствовать себя мини информационным аналитиком.
Кто еще не знаком с сайтом Kaggle.com (англоязычный), рекомендую не полениться и провести там пару часов для общего ознакомления с данным ресурсом.
На данном сайте уже как 4 года идет конкурс на самый лучший анализатор изображений. Принять участие может каждый. Изначально конкурс был до 31.12.16, но сейчас он продлен до 2019 года.
На Хабре уже был описан способ, как написать программу и поучаствовать, но там далеко не для новичков: «Как начать работу в Kaggle: руководство для новичков в Data Science».
Я решил попробовать свои силы, и при этом не писать программу.
Мои навыки не позволяют в короткий срок самостоятельно написать программу с хорошим результатом, поэтому решено было позаимствовать код у тех, кто достиг успеха.
Вот так я получил 307 место из 1387 (на момент написания статьи). Точность алгоритма у меня была равна 0,989.
Была взята изначальная обучающая выборка 42000 картинок и разбита на 33600 и 8400 картинок( 80% и 20% ), для того чтобы испытать алгоритм, при известных результатах. 33600 картинок использовались для обучения, 8400 картинок для проверки. Алгоритм обучался при 5400 итерациях. Время работы алгоритма 33 минуты, при условии 4Гб ОЗУ и 2,33Ггц. Перейдем же к результатам.
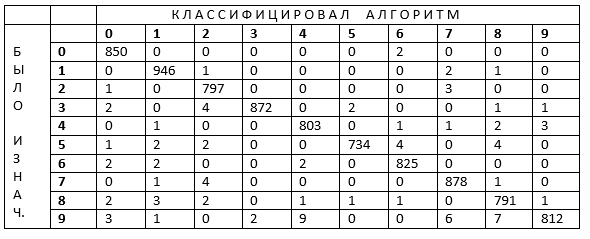
Табл.1
В таблице 1 наглядно изображен результат классификации картинок. После получения этих данных можно провести анализ. Для понимания теории можно вспомнить круги Эйлера (рис.1). Они показывают, на какие части мы разобьем результат работы алгоритма (результирующую выборку).

Рис.1
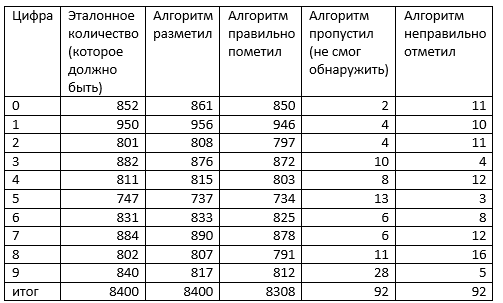
Табл. 2
В соответствии с рис.2 делим наш результат и заносим данные в таблицу 2.
Теперь у нас достаточно информации для того, чтобы говорить о качестве алгоритма. В таблицу 3 я попытался вложить основной список коэффициентов, по которым можно оценивать программу.
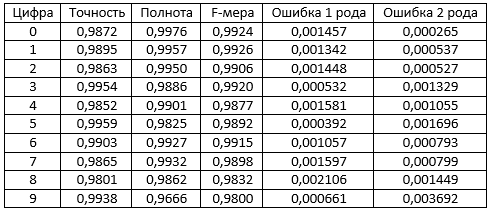
Табл. 3
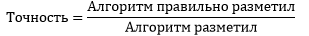
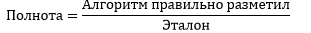
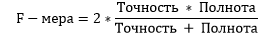

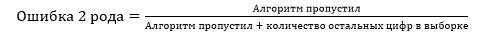
В нашем случае остальные это:
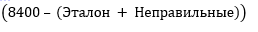
Кто еще не знаком с сайтом Kaggle.com (англоязычный), рекомендую не полениться и провести там пару часов для общего ознакомления с данным ресурсом.

На данном сайте уже как 4 года идет конкурс на самый лучший анализатор изображений. Принять участие может каждый. Изначально конкурс был до 31.12.16, но сейчас он продлен до 2019 года.
На Хабре уже был описан способ, как написать программу и поучаствовать, но там далеко не для новичков: «Как начать работу в Kaggle: руководство для новичков в Data Science».
Я решил попробовать свои силы, и при этом не писать программу.
Мои навыки не позволяют в короткий срок самостоятельно написать программу с хорошим результатом, поэтому решено было позаимствовать код у тех, кто достиг успеха.
Опишу все поэтапно
- Регистрируемся на сайте Kaggle.com
- Ищем там ссылку на Digit Recognized
- Заходим на список участников и смотрим, кто из них выложил код. Мне понравился код пользователя
daryadedik. Но проблема в том, что на windows для компиляции кода не хватает ряд библиотек. Решил не париться и Запустить его в Linux Ubuntu, для него все найдется.
Шаг 4 — 12 описывает как создать виртуальную машину с Linux и установить все необходимые для Python приложения.
Если у вас есть linux, Pycharm, Anaconda, библиотека tensorflow то переходите к шагу 13.
- Скачиваем программу для создания виртуальных машин. (я скачал VMware)
- Скачиваем Linux (Ubuntu 16.04.1 LTS Desktop) http://ubuntu.ru/get
- Далее устанавливаем ее через VMware. (VMware, new virtual machine, выбираем скаченный Linux, параметры можно выбрать 2-3 Гб оперативки и 20 Гб выделить на виртуальную машину)
- Следуем инструкциям и запоминаем ПАРОЛЬ пользователя в Линуксе.
- Если вы видите это:

Значит пока вы на верном пути. Вводим пароль и заходим.
- Это важный шаг. Для запуска программы на Python нам необходимы две вещи:
PyCharm (среда разработки) и Anaconda (набор библиотек).
Дабы не копировать написанное, для установки PyCharm следуем инструкциям. Для установки Anaconda выполняем только пункт 1 (wget……).
После установки пишем в терминале ту фразу, которая вылезла после (You may wish to edit……). У меня это (export PATH=/home/adminv/anaconda3/bin:$PATH)

(Для Python 3.5)
- Открываем новый терминал пишем еще раз фразу
export PATH=/home/adminv/anaconda3/bin:$PATH
- Вводим туда же
conda install -c https://conda.anaconda.org/jjhelmus</a> tensorflow
- Если вы видите это:
Значит вы все сделали правильно.
У нас теперь есть PyCharm, Anaconda, библиотека tensorflow можем перейти к программе и конкурсу.
- Заходим на сайт Kaggle и скачиваем файлы с тестовой выборкой и выборкой конкурсной (3 файла).
- Далее запускаем через терминал PyCharm (просто вводим в терминал pycharm) и создаем новый проект, куда кидаем наш код.
В папку с проектом кидаем и скаченные 3 файла.
- Запускаем прогу и вуаля – получаем модель, обученную на выборке и файл столбец с результатом распознавания (submission).
- https://www.kaggle.com/c/digit-recognizer/submit — кидаем сюда свой один файл результирующий (submission) и ждем результат проверки (она занимает ~ 20 секунд). Теперь вы тоже в числе участвующих.



Вот так я получил 307 место из 1387 (на момент написания статьи). Точность алгоритма у меня была равна 0,989.
Справочная информация:
- Картинки все формата 28х28 поэтому test файл это таблица где 784 столбцов.
Одна строчка – один рисунок, просто записан попиксельно.
(train – 785 столбцов, тк там первый столбец это результат известный) - Точность алгоритма зависит от того, какие параметры ты пропишешь в коде (количество итераций обучения)
- Алгоритм считал 40 минут при условии 5400 итераций обучения и 4 Гб оперативной памяти, выделенной для виртуальной машине
Аналитический эксперимент
Была взята изначальная обучающая выборка 42000 картинок и разбита на 33600 и 8400 картинок( 80% и 20% ), для того чтобы испытать алгоритм, при известных результатах. 33600 картинок использовались для обучения, 8400 картинок для проверки. Алгоритм обучался при 5400 итерациях. Время работы алгоритма 33 минуты, при условии 4Гб ОЗУ и 2,33Ггц. Перейдем же к результатам.

Табл.1
В таблице 1 наглядно изображен результат классификации картинок. После получения этих данных можно провести анализ. Для понимания теории можно вспомнить круги Эйлера (рис.1). Они показывают, на какие части мы разобьем результат работы алгоритма (результирующую выборку).

Рис.1

Табл. 2
В соответствии с рис.2 делим наш результат и заносим данные в таблицу 2.
Теперь у нас достаточно информации для того, чтобы говорить о качестве алгоритма. В таблицу 3 я попытался вложить основной список коэффициентов, по которым можно оценивать программу.

Табл. 3





В нашем случае остальные это:

