Добрый день, господа! Спешу сообщить, что настают последние дни. Кажется, мир Java развился до такой степени, что то ли мы теперь можем спокойно использовать Rust вместо Java, то ли Java вместо Rust. Кровавые подробности ждут вас под катом.
Известный интернет-активист Алексей Шипилёв недавно затвитил следующее:
«Why don't we implement no-GC in HotSpot, and win every single 5-second latency benchmark. 100 GB heap is enough to survive for 10 secs.»
Круто, отличная шутка — подумали мы и пошли есть. А вернувшись с кухни, подавились сразу всеми плюшками, потому что там появились скриншоты!

Ну ладно, мы же все умеем фотошопить, верно?
А потом
Дрожащими пальцами мы открываем джаванет, и видим…
Далее перескажу кратенько, что там написано. Мне было лень делать точный перевод, грамматические воители могут пройти и прочитать оригинал :)
Фича заключается в том, что GC заботится только об аллокации новой памяти, а на умные стратегии сборки мусора можно забить. Как только доступная куча заканчивается, начинается процедура остановки JVM.
Предоставить полностью пассивную реализацию GC с ограниченным объемом памяти, которую можно выделит. В замен получаем нижайший оверхед на производительность такого GC. Реализация не должна затрагивать другие GC или сильно что-то менять в JVM.
На правах сочинителя топика для хабра, немного поспекулирую. Действительно, ведь не каждая компания — Google. Кому-то хочется просто сделать минимальный работающий продукт, и только потом заботиться о его развитии. Возможно, в будущем всё придется переписать на более продвинутой платформе. Возможно, у разработчиков раньше закончатся деньги. Для этого не нужно тащить в проект сразу огромные ынтерпрайзные штуки типа G1.
Окей, шутки в сторону, идем дальше по тексту! Предполагается, что существует как минимум 4 кейса, где такая штука как Эпсилон может реально пригодиться.
Во-первых, с Epsilon можно сравнивать какой-нибудь другой более продвинутый GC, что поможет в его разработке и вылавливании багов, привнесенных самим механизмом сборки.
Во-вторых, для истинно байтоебских (это термин, а не ругательство!) приложений на Java, такой GC просто незаменим. Представим, что вы пишете прошивку для очередного чайника или умного унитаза, и сам факт сборки мусора считается багом в приложении: вместо того, чтобы собирать мусор лучше упасть, а умные балансировщики разбалансируют нагрузку по другим нодам/VM. К чему должны готовить унитаз, используя сеть сбалансированных VM, замнем для ясности. Кроме того, использование Epsilon позволит отделаться от лишних барьеров — изюминка на торте идеального перфоманса.
В-третьих, для тестирования самого OpenJDK неплохо иметь средство ограничения выделяемой памяти, чтобы тестировать инварианты нагрузки на эту самую память. Сейчас такие данные берутся из MXBeans или даже парсятся по логам GC. Если GC будет поддерживать только ограниченное количество аллокаций, это реально упростит тестирование разработчикам OpenJDK. (Скорей всего, читатели этой статьи — не разработчики OpenJDK, но теперь можно попробовать сойти за разраба OpenJDK на очередном собеседовании.)
В-четвертых, это поможет установить абсолютный минимум для интерфейса VM-GC, и может служить доказательством корректности его работы. Что полезно, например для JDK-8163329 («GC interface») (По ссылке стена текста, желающие могут перевести на Хабр).
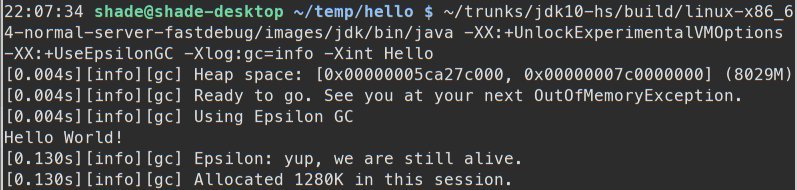
Для пользователя, Epsilon выглядит как любой другой GC для OpenJDK, подключенный с помощью -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC.
Epsilon линейно выделяет память в одном-единственном последовательном куске памяти. Это позволяет использовать простейший код для lock-free TLAB (thread-local allocation buffers), который может переиспользовать уже существующий код из VM. Выдача TLABов помогает поддерживать резидентную память процесса в количестве, которое было реально выделено. Поскольку при таком раскладе и выделение больших кусков памяти, и TLABов, не сильно отличается, они обрабатываются одним и тем же кодом.
Сет барьеров, использующихся Epsilon, полностью пуст, поскольку Epsilon не делает никаких настоящих циклов сборки, и следовательно ему совершенно наплевать на граф объектов, пометки объектов, копирование объектов, и весь остальной ненужный хлам. Только хардкор, только перфоманс!
Так как единственно важная часть рантайм интерфейса — та, где Epsilon выдает TLABы, его перфоманс в основном зависит от размера TLABов. Имея произвольно большие TLABы и произвольно большую кучу, оверхед производительности — произвольно маленькое положительное число, отсюда и берется название Epsilon. Авторы и пользователи golang могут начинать зеленеть от зависти и рвать волосы на дженериках.
Как только хип весь закончился, выдать TLAB уже нельзя, восстановиться никак нельзя, остается только сдаться и распечатать отчет об ошибке. Тут можно сделать что-то похожее на то, что делают другие GC:
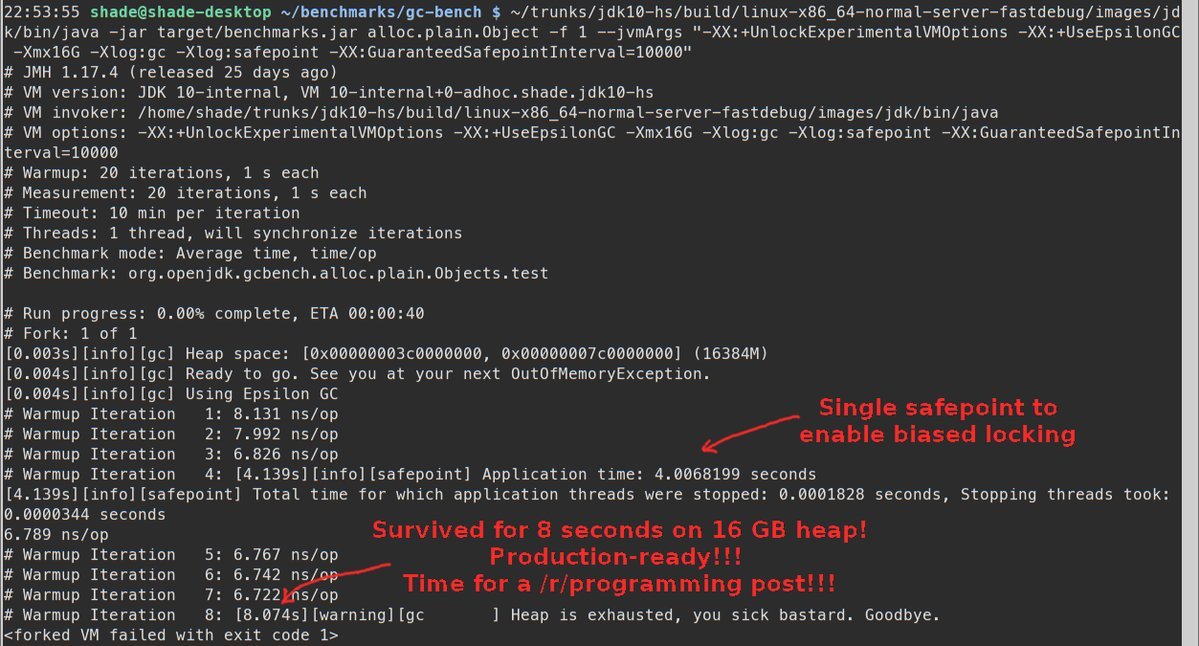
Прототип был проверен на небольших нагрузках, и планово падал на повышенных нагрузках.
Код всё еще лежит здесь, пока его не забрало НЛО: http://cr.openjdk.java.net/~shade/epsilon/
Альтернатив нет. По крайней мере таких, чтобы вырубали все барьеры. Серьезно.
Надеюсь, что наша радость и эйфория от встречи с действительно уникальным GC, в чем-то похожа на эйфорию от тех препаратов, которые употребляет автор Epsilon, создавая подобную годноту.
В любом случае, если барьеры — не проблема, то Serial или Parallel (old) GC могут дать похожий профиль производительности — если вы, конечно, сможете их так настроить, чтобы сборка мусора никогда не запускалась (например, выставляя огромные значения young gen, выключая адаптивную эвристику, итп). Учитывая как много там опций, трудно гарантировать, что это выйдет.
Дальнейшие улучшения в современных GC, таких как Shenandoah, могут привести к снижению оверхеда до уровня, пренебрежительно малого по сравнению с полностью no-op GC. Если/кода это произойдет, Эпсилон всё еще можно будет использовать для внутреннего функционального/нагрузочного тестирования (если на пенсии вы всё еще будете хотеть заниматься внутренним тестированием GC).
Обычные тесты нафиг не нужны, и не годятся для Эпсилона. Большинство из них считают, что можно разбрасывать произвольное количество мусора. Поэтому для тестирования Эпсилона придется делать новые тесты — нужно проверить что он работает на задачах с низким выделением памяти, а при исчерпании кучи падает не абы как, а предсказуемо. Для проверки корректности хватит новых jtreg тестов, лежащих в hotspot/gc/epsilon.
Одноразовой проверки, произведенной во время разработки Epsilon, вполне достаточно, чтобы предположить характеристики производительности на интерпретаторе, C1 и C2. Дальнейшее тестирование нафиг не нужно, так как текущая реализация с самого начала разработки была стабильней и железобетонней сталинских бункеров.
Полезность супротив стоимости поддержки. Можно предположить, что эта реализация не стоит свеч, потому что всё равно никому не нужна. С другой стороны, исходя из опыта, многие игроки джава-экосистемы экспериментировали с выбрасыванием GC из собственных кастомных JVM. Значит, если у нас будет готовый no-op GC, это поможет данной части сообщества. Ну или по крайней мере, позволит гордиться, что мы использовали no-op GC, когда это еще не было мэйстримом. Учитывая общую дешевизну реализации, риски минимальны.
Публичные ожидания. Учитывая, что этот мусоросборщик на самом деле не собирает никакой мусор, кто-то мог бы воспринять это как опасную практику. Включи ненароком Эпсилон на продакшене, и сразу же после переполнения кучи, деятелей ждут пренеприятнейшие известия. Автор предполагает, что никакого реально риска нет, пока фича проходит под флагом experimental, т.е требует включения -XX:+UnlockExperimentalVMOptions.
Сложность реализации. Можно представить ситуацию, когда в общем c другими подсистемами коде придется поменять больше, чем изначально предполагалось — например, в компиляторе, или в бэкендах конкретных платформ. С другой стороны, по прототипу видно, что все такие изменения с самого начала были жестко изолированы. Если это окажется реальным риском, то может помочь JDK-8163329 («GC interface»), о котором уже упоминалось выше.
В целях уменьшения количества изменений во внешнем коде, эта работа зависит от JDK-8163329 («GC Interface»). Если изменения в общем коде минимальны, то оно не должно требовать изменений в интерфейсе GC.
Честно, я весьма устал всё это писать. Поэтому просто оставлю это здесь. Да пребудет с вами сила! Она вам понадобится в новом светлом будущем, с Java без сборки мусора.
P.S.: у Шипилёва есть ссылка на этот пост, и он следит за тобой, юзернейм
Известный интернет-активист Алексей Шипилёв недавно затвитил следующее:
«Why don't we implement no-GC in HotSpot, and win every single 5-second latency benchmark. 100 GB heap is enough to survive for 10 secs.»
Круто, отличная шутка — подумали мы и пошли есть. А вернувшись с кухни, подавились сразу всеми плюшками, потому что там появились скриншоты!
Ну ладно, мы же все умеем фотошопить, верно?
А потом
появился код
, и дело начало принимать крутой оборот. Вы понимаете, когда Шипилёв что-то выкладывает в паблик, то через месяц об этом уже положено спрашивать на собеседовании.Дрожащими пальцами мы открываем джаванет, и видим…
JEP: Epsilon GC: The Arbitrarily Low Overhead Garbage (Non-)Collector
Далее перескажу кратенько, что там написано. Мне было лень делать точный перевод, грамматические воители могут пройти и прочитать оригинал :)
О б-же, что это, Бэрримор?
Фича заключается в том, что GC заботится только об аллокации новой памяти, а на умные стратегии сборки мусора можно забить. Как только доступная куча заканчивается, начинается процедура остановки JVM.
Цели
Предоставить полностью пассивную реализацию GC с ограниченным объемом памяти, которую можно выделит. В замен получаем нижайший оверхед на производительность такого GC. Реализация не должна затрагивать другие GC или сильно что-то менять в JVM.
Мотивация
На правах сочинителя топика для хабра, немного поспекулирую. Действительно, ведь не каждая компания — Google. Кому-то хочется просто сделать минимальный работающий продукт, и только потом заботиться о его развитии. Возможно, в будущем всё придется переписать на более продвинутой платформе. Возможно, у разработчиков раньше закончатся деньги. Для этого не нужно тащить в проект сразу огромные ынтерпрайзные штуки типа G1.
Окей, шутки в сторону, идем дальше по тексту! Предполагается, что существует как минимум 4 кейса, где такая штука как Эпсилон может реально пригодиться.
Во-первых, с Epsilon можно сравнивать какой-нибудь другой более продвинутый GC, что поможет в его разработке и вылавливании багов, привнесенных самим механизмом сборки.
Во-вторых, для истинно байтоебских (это термин, а не ругательство!) приложений на Java, такой GC просто незаменим. Представим, что вы пишете прошивку для очередного чайника или умного унитаза, и сам факт сборки мусора считается багом в приложении: вместо того, чтобы собирать мусор лучше упасть, а умные балансировщики разбалансируют нагрузку по другим нодам/VM. К чему должны готовить унитаз, используя сеть сбалансированных VM, замнем для ясности. Кроме того, использование Epsilon позволит отделаться от лишних барьеров — изюминка на торте идеального перфоманса.
В-третьих, для тестирования самого OpenJDK неплохо иметь средство ограничения выделяемой памяти, чтобы тестировать инварианты нагрузки на эту самую память. Сейчас такие данные берутся из MXBeans или даже парсятся по логам GC. Если GC будет поддерживать только ограниченное количество аллокаций, это реально упростит тестирование разработчикам OpenJDK. (Скорей всего, читатели этой статьи — не разработчики OpenJDK, но теперь можно попробовать сойти за разраба OpenJDK на очередном собеседовании.)
В-четвертых, это поможет установить абсолютный минимум для интерфейса VM-GC, и может служить доказательством корректности его работы. Что полезно, например для JDK-8163329 («GC interface») (По ссылке стена текста, желающие могут перевести на Хабр).
Подробности
Для пользователя, Epsilon выглядит как любой другой GC для OpenJDK, подключенный с помощью -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC.
Epsilon линейно выделяет память в одном-единственном последовательном куске памяти. Это позволяет использовать простейший код для lock-free TLAB (thread-local allocation buffers), который может переиспользовать уже существующий код из VM. Выдача TLABов помогает поддерживать резидентную память процесса в количестве, которое было реально выделено. Поскольку при таком раскладе и выделение больших кусков памяти, и TLABов, не сильно отличается, они обрабатываются одним и тем же кодом.
Сет барьеров, использующихся Epsilon, полностью пуст, поскольку Epsilon не делает никаких настоящих циклов сборки, и следовательно ему совершенно наплевать на граф объектов, пометки объектов, копирование объектов, и весь остальной ненужный хлам. Только хардкор, только перфоманс!
Так как единственно важная часть рантайм интерфейса — та, где Epsilon выдает TLABы, его перфоманс в основном зависит от размера TLABов. Имея произвольно большие TLABы и произвольно большую кучу, оверхед производительности — произвольно маленькое положительное число, отсюда и берется название Epsilon. Авторы и пользователи golang могут начинать зеленеть от зависти и рвать волосы на дженериках.
Как только хип весь закончился, выдать TLAB уже нельзя, восстановиться никак нельзя, остается только сдаться и распечатать отчет об ошибке. Тут можно сделать что-то похожее на то, что делают другие GC:
- Бросить OutOfMemoryError с увесистым описанием
- Сдампить кучу (как всегда, включается через -XX:+HeapDumpOnOutOfMemoryError
- Жестко уронить JVM, и опционально выполнить какое-то внешнее действие (как обычно, -XX:OnError=...), например запустить отладчик, оповестить систему мониторинга, или хотя бы написать письмо в Спортлото
Прототип был проверен на небольших нагрузках, и планово падал на повышенных нагрузках.
Код всё еще лежит здесь, пока его не забрало НЛО: http://cr.openjdk.java.net/~shade/epsilon/
Альтернативы
Альтернатив нет. По крайней мере таких, чтобы вырубали все барьеры. Серьезно.
Надеюсь, что наша радость и эйфория от встречи с действительно уникальным GC, в чем-то похожа на эйфорию от тех препаратов, которые употребляет автор Epsilon, создавая подобную годноту.
В любом случае, если барьеры — не проблема, то Serial или Parallel (old) GC могут дать похожий профиль производительности — если вы, конечно, сможете их так настроить, чтобы сборка мусора никогда не запускалась (например, выставляя огромные значения young gen, выключая адаптивную эвристику, итп). Учитывая как много там опций, трудно гарантировать, что это выйдет.
Дальнейшие улучшения в современных GC, таких как Shenandoah, могут привести к снижению оверхеда до уровня, пренебрежительно малого по сравнению с полностью no-op GC. Если/кода это произойдет, Эпсилон всё еще можно будет использовать для внутреннего функционального/нагрузочного тестирования (если на пенсии вы всё еще будете хотеть заниматься внутренним тестированием GC).
А это вообще работает? А это вообще легально?
Обычные тесты нафиг не нужны, и не годятся для Эпсилона. Большинство из них считают, что можно разбрасывать произвольное количество мусора. Поэтому для тестирования Эпсилона придется делать новые тесты — нужно проверить что он работает на задачах с низким выделением памяти, а при исчерпании кучи падает не абы как, а предсказуемо. Для проверки корректности хватит новых jtreg тестов, лежащих в hotspot/gc/epsilon.
Одноразовой проверки, произведенной во время разработки Epsilon, вполне достаточно, чтобы предположить характеристики производительности на интерпретаторе, C1 и C2. Дальнейшее тестирование нафиг не нужно, так как текущая реализация с самого начала разработки была стабильней и железобетонней сталинских бункеров.
Риски и предположения
Полезность супротив стоимости поддержки. Можно предположить, что эта реализация не стоит свеч, потому что всё равно никому не нужна. С другой стороны, исходя из опыта, многие игроки джава-экосистемы экспериментировали с выбрасыванием GC из собственных кастомных JVM. Значит, если у нас будет готовый no-op GC, это поможет данной части сообщества. Ну или по крайней мере, позволит гордиться, что мы использовали no-op GC, когда это еще не было мэйстримом. Учитывая общую дешевизну реализации, риски минимальны.
Публичные ожидания. Учитывая, что этот мусоросборщик на самом деле не собирает никакой мусор, кто-то мог бы воспринять это как опасную практику. Включи ненароком Эпсилон на продакшене, и сразу же после переполнения кучи, деятелей ждут пренеприятнейшие известия. Автор предполагает, что никакого реально риска нет, пока фича проходит под флагом experimental, т.е требует включения -XX:+UnlockExperimentalVMOptions.
Сложность реализации. Можно представить ситуацию, когда в общем c другими подсистемами коде придется поменять больше, чем изначально предполагалось — например, в компиляторе, или в бэкендах конкретных платформ. С другой стороны, по прототипу видно, что все такие изменения с самого начала были жестко изолированы. Если это окажется реальным риском, то может помочь JDK-8163329 («GC interface»), о котором уже упоминалось выше.
Зависимости
В целях уменьшения количества изменений во внешнем коде, эта работа зависит от JDK-8163329 («GC Interface»). Если изменения в общем коде минимальны, то оно не должно требовать изменений в интерфейсе GC.
Заключение
Честно, я весьма устал всё это писать. Поэтому просто оставлю это здесь. Да пребудет с вами сила! Она вам понадобится в новом светлом будущем, с Java без сборки мусора.
P.S.: у Шипилёва есть ссылка на этот пост, и он следит за тобой, юзернейм
