 Примерно месяц назад со мной произошёл один эпизод, который заставил задуматься на тему полезности функций автодополнения, которые часто встраиваются на сайтах интернет магазинов. Обычно это выглядит так: начинаешь оформлять заказ, вводишь своё имя, телефон и адрес доставки, и пока ты неспешно набираешь адрес, перед тобой выскакивают подсказки с названиями улиц, чтобы ты не напрягал клавиатуру и выбирал нужный адрес из предложенного списка.
Примерно месяц назад со мной произошёл один эпизод, который заставил задуматься на тему полезности функций автодополнения, которые часто встраиваются на сайтах интернет магазинов. Обычно это выглядит так: начинаешь оформлять заказ, вводишь своё имя, телефон и адрес доставки, и пока ты неспешно набираешь адрес, перед тобой выскакивают подсказки с названиями улиц, чтобы ты не напрягал клавиатуру и выбирал нужный адрес из предложенного списка.Так вот, в феврале мне потребовалось оперативно накормить дома большую компанию друзей, и я решила заказать пиццу в одном достаточно популярном заведении. Вообще обычно я придерживаюсь принципов здорового питания, но ситуация была исключительной…
Вы скажете Хабр – не место для историй про пиццу, и будете абсолютно правы, но данная история не совсем про пиццу, она в большей степени про моделирование поведения человека, про нагрузочное тестирование, немного про программирование, и в большей степени про числовую оценку полезности нескольких современных ajax-сервисов автодополнения и подсказок.
Но толчком к написанию данной статьи была всё-таки пицца и тот факт, что мне пришлось оформлять её заказ дважды из-за того, что на сайте при заполнении поля с адресом доставки использовались подсказки. Хитрость была в том, что пока ты не выберешь улицу из предложенного списка, тебе не дадут указать номер дома. Поскольку по привычке свой адрес я набираю очень быстро, а подсказки на том сайте работали очень неторопливо, получилось так, что весь этот ajax-механизм с подгрузкой подсказок не успел отработать. Как следствие я не смогла указать номер дома. Пришлось нажимать F5, оформлять заказ заново и повторно вводить свой адрес медленно, но верно.
Вся эта история в итоге закончилась благополучно, и пицца была доставлена по адресу, но осадок остался. Я решила задаться вопросом, можно ли как-то измерить или оценить полезность использования такого рода сервисов, ведь функции автодополнения встречаются повсеместно.
Как следствие, этот вопрос вылился в полноценное исследование, с разработкой скриптов для тестирования полезности шести доступных в настоящий момент онлайн сервисов автодополнения почтовых адресов. Результатам этих исследований и посвящена данная статья.
Формула полезности
Исследование полезности нужно начать с определения формулы её подсчёта. Чисто интуитивно понятно следующее.
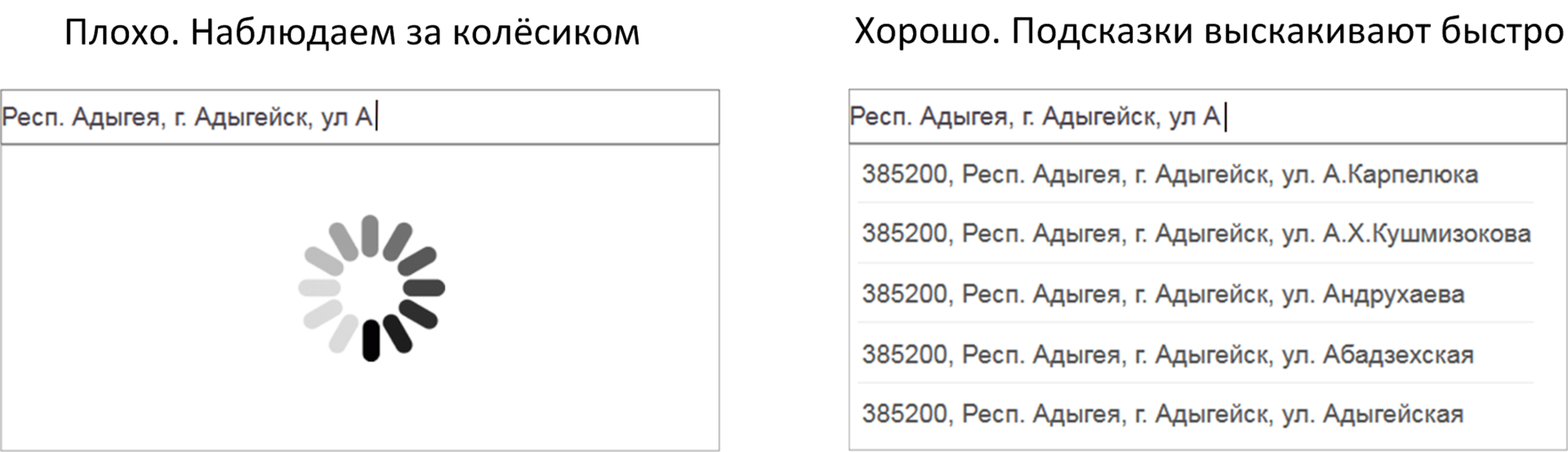
- Если ты вводишь данные, а вместо подсказок наблюдаешь крутящееся колёсико – это не очень полезно. И наоборот, если подсказки выскакивают быстрее, чем ты успеваешь набирать текст – это хорошо.
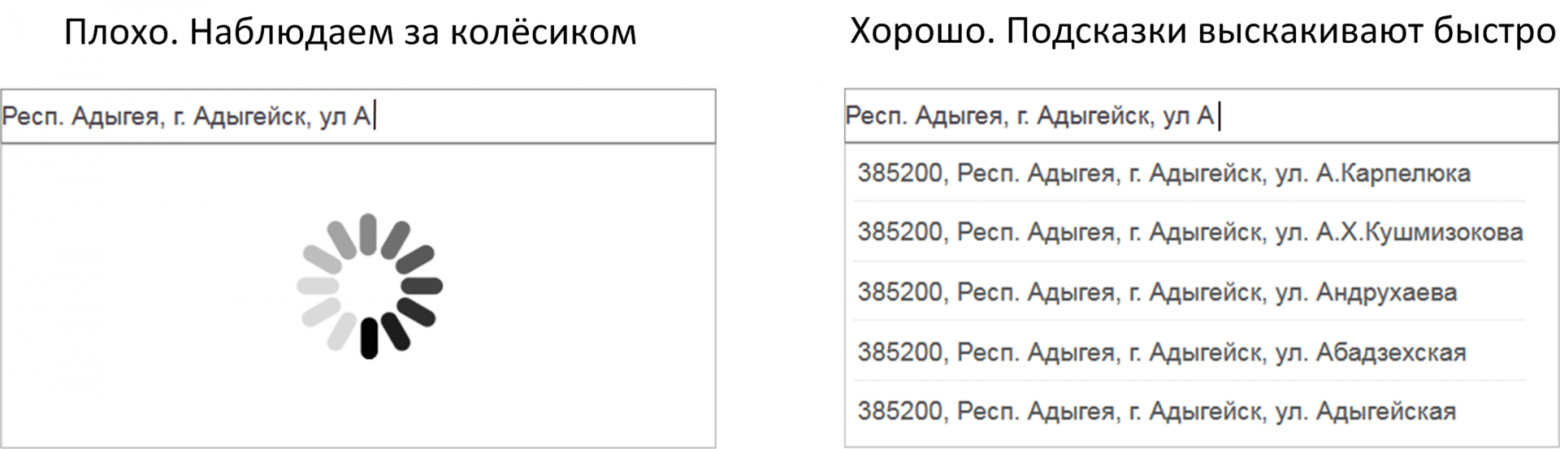
- Если ты долго и упорно заполняешь форму буква за буквой, но подсказки подсказывают не то, что надо, то польза от них сомнительна. И наоборот, если ввёл пару букв, а в подсказках уже материализовалось желаемое, то налицо очевидный профит от их использования.
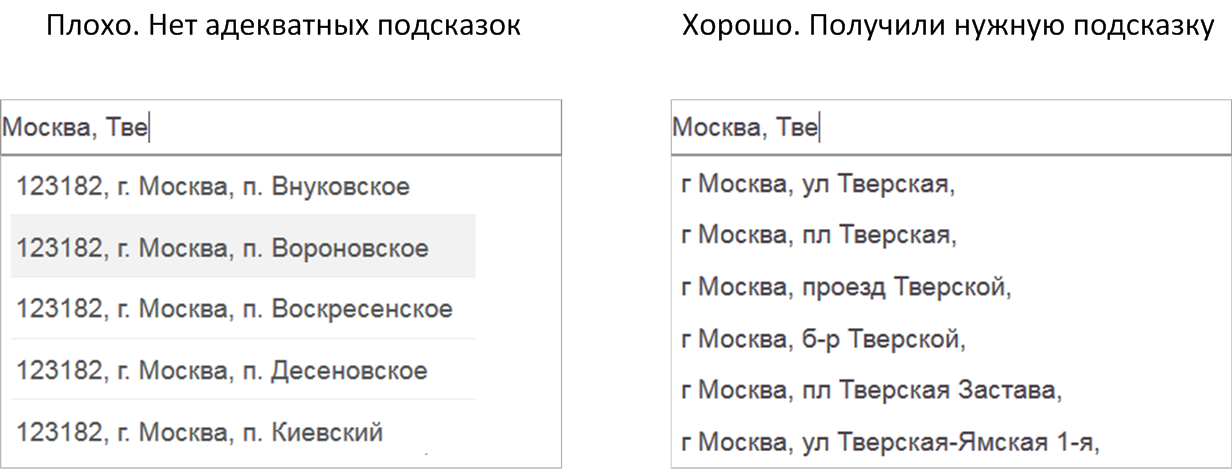
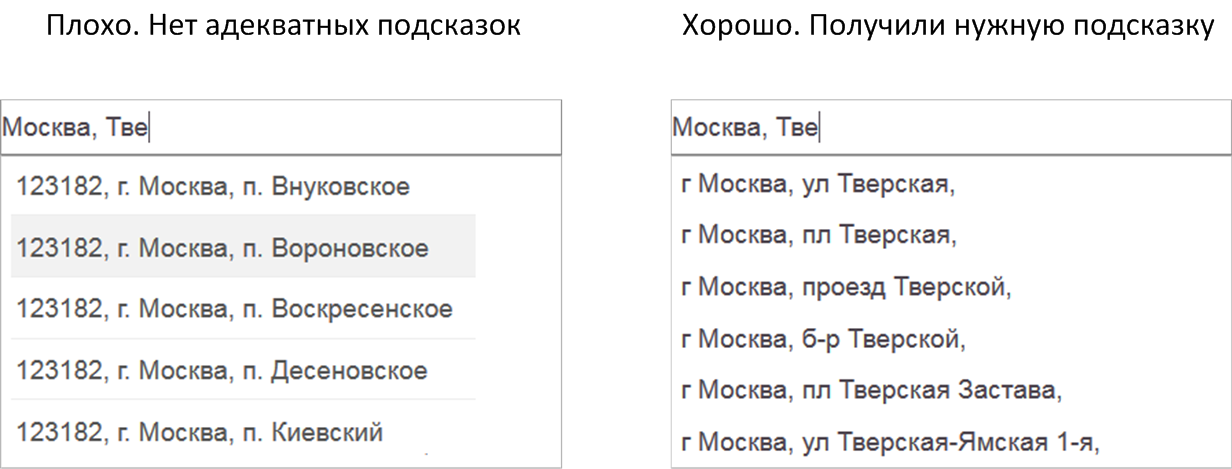
Все эти размышления привели меня к следующей формуле, оценивающей полезность сервиса автодополнения.

Здесь
 — суммарное время, которое пользователь тратит на ввод адреса при использовании подсказок,
— суммарное время, которое пользователь тратит на ввод адреса при использовании подсказок,  – суммарное время, которое пользователь тратит на ожидание подсказок от сервиса,
– суммарное время, которое пользователь тратит на ожидание подсказок от сервиса,  — общее время, которое пользователь потратил бы на ввод данных без использования подсказок.
— общее время, которое пользователь потратил бы на ввод данных без использования подсказок.Вы спросите, зачем выделять отдельно
, ведь ajax — штука асинхронная и время отклика не задерживает пользователя при наборе текста. Но, как было отмечено выше, эта статья про моделирование поведения человека. Когда пользователь видит, что ему предлагают подсказки, его работа за клавиатурой меняется, а именно – она выглядит так: - Нажал на клавишу с очередной вводимой буквой.
- Подождал подсказок.
- Убедился, что подсказок правильных нет, и вернулся к пункту 1.
Как видим, вполне себе синхронная работа получается, так что время, которое пользователь тратит на ввод данных, определяется именно суммой
 .
.В нормальном состоянии, когда сумма
меньше знаменателя , значение функции попадает в диапазон [0 … 1] и, фактически, показывает процент времени, которое пользователь экономит, используя подсказки. Но есть и ненормальные состояния (вспоминаем про пиццу), которые мы рассмотрим чуть позже. А пока распишем, что из себя представляет и .Примем
 , где
, где  – число букв, из которых состоит адрес и которые пользователю нужно ввести,
– число букв, из которых состоит адрес и которые пользователю нужно ввести,  – время, которое в среднем пользователь тратит на поиск буквы на клавиатуре и нажатие соответствующей кнопки. Данное время зависит от умений пользователя работать с клавиатурой. Мы выделим три класса пользователей: «тихоход», «середнячок» и «торопыжка». Для каждого из этих классов позже мы зададим соответствующее значение , в результате для каждого класса пользователей будет отдельно получено значение полезности.
– время, которое в среднем пользователь тратит на поиск буквы на клавиатуре и нажатие соответствующей кнопки. Данное время зависит от умений пользователя работать с клавиатурой. Мы выделим три класса пользователей: «тихоход», «середнячок» и «торопыжка». Для каждого из этих классов позже мы зададим соответствующее значение , в результате для каждого класса пользователей будет отдельно получено значение полезности.Примем
 где
где  – количество букв адреса, которые пользователю фактически приходится вводить с использованием подсказок. При получении правильной подсказки пользователь перестаёт набирать адрес, вместо этого он просто выбирает его из предложенного списка. В этом случае
– количество букв адреса, которые пользователю фактически приходится вводить с использованием подсказок. При получении правильной подсказки пользователь перестаёт набирать адрес, вместо этого он просто выбирает его из предложенного списка. В этом случае  . Если пользователь не получил подходящую подсказку, то ему приходится вводить адрес полностью, в таких ситуациях
. Если пользователь не получил подходящую подсказку, то ему приходится вводить адрес полностью, в таких ситуациях  . Второе слагаемое
. Второе слагаемое  отражает время, которое пользователь тратит на выбор из предложенного списка подходящих подсказок. В общем случае пользователь может воспользоваться подсказками
отражает время, которое пользователь тратит на выбор из предложенного списка подходящих подсказок. В общем случае пользователь может воспользоваться подсказками  раз, например, при вводе города – первый раз, и при вводе улицы – второй раз. При выборе подсказки пользователь, как правило, нажимает несколько раз на клавиатуре кнопку со стрелкой «вниз», чтобы выбрать нужную подсказку, после чего нажимает на какую-то кнопку (например, Enter), чтобы подтвердить свой выбор. Эти действия не требуют поиска нужных кнопок на клавиатуре, поэтому данное время можно принять за константу, которая зависит от класса пользователя: «тихоход» плохо владеет клавиатурой, поэтому стрелки нажимать он будет медленнее в сравнении с «торопыжкой». Поэтому данную константу я привязала к , а коэффициент
раз, например, при вводе города – первый раз, и при вводе улицы – второй раз. При выборе подсказки пользователь, как правило, нажимает несколько раз на клавиатуре кнопку со стрелкой «вниз», чтобы выбрать нужную подсказку, после чего нажимает на какую-то кнопку (например, Enter), чтобы подтвердить свой выбор. Эти действия не требуют поиска нужных кнопок на клавиатуре, поэтому данное время можно принять за константу, которая зависит от класса пользователя: «тихоход» плохо владеет клавиатурой, поэтому стрелки нажимать он будет медленнее в сравнении с «торопыжкой». Поэтому данную константу я привязала к , а коэффициент  был подобран эмпирически (см. результаты экспериментов в конце статьи). Важно помнить, что
был подобран эмпирически (см. результаты экспериментов в конце статьи). Важно помнить, что  в ситуациях, когда сервис не вернул подходящих подсказок и, как следствие, пользователь не выполнял действий, связанных с выбором подсказки из списка.
в ситуациях, когда сервис не вернул подходящих подсказок и, как следствие, пользователь не выполнял действий, связанных с выбором подсказки из списка.Подставив все эти выражения в формулу полезности, получим следующее

, которое он тратит на генерацию и выдачу подсказок, получить число букв , которые пользователю фактически приходится вводить при наборе адреса, а также количество раз , которые пользователю приходится выбирать подсказки. Из формулы следует, что чем меньше эти показатели, тем выше будет полезность подсказок. В идеальной ситуации, когда пользователь ещё ничего не начал вводить, а форма с адресом уже заполнена правильными данными, имеет место  ,
,  и . В этом случае полезность равна 1. Эта ситуация идеальна и на данный момент, вероятно, достичь её с использованием земных технологий не представляется возможным, однако есть к чему стремиться.
и . В этом случае полезность равна 1. Эта ситуация идеальна и на данный момент, вероятно, достичь её с использованием земных технологий не представляется возможным, однако есть к чему стремиться.В самом худшем случае, пользователь вводит адрес целиком, при этом после ввода каждой буквы он дополнительно ожидает подсказку в надежде, что она избавит его от дальнейшего ввода. В этом случае
и , как следствие получаем отрицательную полезность  , которая отражает дополнительные затраты времени, которые пользователь понёс из-за бесполезного ожидания подсказок. В такой ситуации, если бы подсказок вообще не было, пользователь ввёл бы адрес быстрее.
, которая отражает дополнительные затраты времени, которые пользователь понёс из-за бесполезного ожидания подсказок. В такой ситуации, если бы подсказок вообще не было, пользователь ввёл бы адрес быстрее.Обзор сервисов автодополнения
Итак, изобретённую мной формулу нужно было на чём-то проверить. Поискав в интернете, я нашла шесть подходящих сервисов, позволяющих через REST API отсылать фрагменты адресных данных и получать для них подсказки (ещё один сервис мне порекомендовали в комментариях, так что в итоге их получилось семь штук). Все рассмотренные мной сервисы работают однотипно, а именно:
- Методом GET или POST получают HTTP запрос с уже введённым фрагментом адреса.
- Возвращают в JSON формате массив с предлагаемыми подсказками.
Конечно структура JSON-ответа у каждого сервиса своя, но семантика более менее одинаковая. Чтобы промоделировать работу пользователя с каждым из этих сервисов, я написала соответствующий скрипт. Этот скрипт имитирует набор почтового адреса на клавиатуре, а в процессе такой имитации анализирует возвращаемые подсказки на предмет их адекватности. Исходники всех скриптов можно взять на гитхабе, ссылка прилагается в конце статьи.
Все рассмотренные сервисы, за исключением Яндекса и Гугла, в качестве источника данных используют адресные справочники КЛАДР или ФИАС, либо одновременно их оба. Оба справочника ведутся ФНС России. Найти информацию по ним можно на следующих сайтах: КЛАДР — http://gnivc.ru, ФИАС – fias.nalog.ru. Яндекс и Гугл для генерации подсказок используют, скорее всего, данные со своих карт.
Краткий обзор всех сервисов, принимавших участие в моих экспериментах, приведен ниже. В ходе обзора и в результатах экспериментов сервисы упорядочены в алфавитном порядке.
Ахантер
Сервис доступен по адресу ahunter.ru. Судя по данным whois, сервис появился в Рунете в начале 2009 года. Подсказки для адресов предлагаются на бесплатной основе, по поводу лимитов на сайте отдельно сказано, что их нет.
Протестировать подсказки можно непосредственно в демо разделе сервиса здесь. Для внедрения подсказок на сторонние сайты веб-мастерам рекомендуют использовать плагин jQuery-Autocomplete, который можно взять на гитхабе по следующей ссылке. Для написания бот-скрипта я использовала непосредственно документацию на API сервиса, почитать которую можно здесь.
Дополнительно кроме подсказок для адресов авторы сервиса предлагают исправлять и структурировать адреса по КЛАДР и ФИАС и получать для них геокоординаты, но это уже за отдельную плату.
Google Places API Web Service
На самом деле под этим названием скрывается несколько сервисов, из которых нас интересуют «Подсказки мест». Информация по этому сервису доступна здесь. На использование сервиса установлены довольно серьёзные квоты, бесплатно можно обработать только 1000 запросов в сутки. Однако если указать в аккаунте данные своей кредитной карты, то будет доступно 150 000 запросов в сутки бесплатно. Всё что свыше этого оплачивается отдельно.
Для встраивания на своем сайте нужно использовать JavaScript библиотеку адресов в Google Maps. Информация по ней доступна здесь. Там же имеется возможность протестировать и посмотреть демо. Для написания бот-скрипта я использовала документацию на API сервиса, доступную по ссылке выше.
Дополнительно с помощью других сервисов этой группы можно отдельно запрашивать геокоординаты получаемых в подсказках адресов.
Дадата
Сервис доступен по адресу dadata.ru. По данным whois сервис появился в Рунете в конце 2012 года. Для использования подсказок нужно покупать подписку на год, либо укладываться в суточный бесплатный лимит.
Демо страница подсказок имеется, она доступна по следующей ссылке. Для внедрения на своём сайте авторы сервиса предлагают использовать jQuery плагин собственной разработки. Для написания бот-скрипта я использовала документацию на API сервиса, доступную по следующей ссылке.
За отдельную плату по части адресов на сайте предлагают такие же дополнительные опции, как и на Ахантере.
КЛАДР в облаке
Сервис доступен по адресу kladr-api.ru. По данным whois сервис появился в начале 2012 года. Авторы предлагают купить подписку на три месяца или на год, либо укладываться в бесплатные суточные лимиты.
Демо страница, где можно пощупать подсказки, доступна по следующей ссылке. Для использования подсказок на сторонних сайтах авторы предлагают использовать разработанный специально под данный сервис jQuery плагин, который можно взять на гитхабе здесь.
Для разработки бот-скрипта я использовала документацию на сайте сервиса, доступную здесь, она не очень подробная, однако разобраться можно.
Fias24
Сервис доступен по адресу fias24.ru. Судя по данным whois, это пока молодой сервис, он появился в Рунете в конце 2016 года. Для использования подсказок нужно покупать подписку на год.
Демо страница подсказок имеется, она доступна на главной странице сервиса. Для внедрения на сайтах авторы сервиса предлагают использовать jQuery плагин собственной разработки. Полноценной документации на REST API на сайте нет, поэтому для написания бот-скрипта мне пришлось включить интуицию и накопленный опыт по работе с другими сервисами.
Яндекс Карты
Здесь, я думаю, дополнительных описаний не требуется, поскольку сервис хорошо известен даже среди домохозяек. Явных лимитов в условиях использования данного сервиса замечено не было, однако Яндекс предупреждает, что для больших проектов нужно договариваться отдельно, ну и в случае чего может в любой момент ограничить доступ на своё усмотрение. При проведении моих экспериментов отказов в доступе замечено не было.
Как работают подсказки в Яндекс Картах, можно посмотреть на… Яндекс Картах, поэтому ссылку на «демо» давать не буду. Для встраивания на сторонних веб сайтах у подсказок Яндекса есть отдельный API, документацию можно найти здесь https://tech.yandex.ru/maps/doc/jsapi/2.1/ref/reference/SuggestView-docpage/.
Невероятно, но факт, кроме подсказок сервис предлагает дополнительные опции по работе с координатами, правда для этого нужно использовать другой API.
Iqdq
Данный сервис был добавлен в статью по просьбе его авторов уже после публикации статьи на Хабре. Сервис доступен по адресу iqdq.ru. По данным whois сервис появился в конце 2013 года. Подсказки для адресов предлагаются бесплатно.
Демо страница, где можно пощупать подсказки, доступна по следующей ссылке. Для использования подсказок на сторонних сайтах авторы дают примеры JavaScript кода с использованием jQuery. Для написания бот-скрипта я использовала документацию на API сервиса, доступную здесь.
За отдельную плату по части адресов на сайте предлагают дополнительные опции, такие же как и на сервисах Ахантер и Дадата.
Описание эксперимента
Для каждого сервиса из этого обзора нам нужно измерить время отклика
и число букв , которые пользователю приходится вводить прежде, чем он получит подходящую подсказку, либо пока адрес не будет набран целиком. Для этого я подготовила тестовую выборку. В неё суммарно была включена 3591 улица из 406 городов России. Для каждого города отбиралось не более 10 улиц, причём улицы выбирались так, чтобы по возможности охватить весь алфавит. В тестовую выборку не включались небольшие населенные пункты (деревни и посёлки) поскольку потенциальной целевой аудиторией сервисов подсказок являются всё-таки жители достаточно крупных городов. Описание тестовой выборки
Тестовую выборку можно скачать вместе с исходниками. Выборка представляет собой JSON-массив, каждому элементу которого соответствует тестовый адрес, ввод которого мы будем эмулировать для получения подсказок. Пример с описанием полей этих адресов приведён ниже:
{
"id" : 1,
"reg" : "Адыгея",
"reg_type" : "Респ",
"reg_kladr" : "0100000000000",
"city" : "Адыгейск",
"city_type" : "г",
"city_kladr" : "0100000200000",
"street" : "8 Марта",
"street_type" : "ул",
"street_kladr" : "01000002000003800"
}
Здесь id – уникальный идентификатор тестового адреса в пределах выборки, reg – имя региона, которому принадлежит адрес, reg_type – тип региона, reg_kladr – код по КЛАДР региона. Аналогично для города введены поля city, city_type, city_kladr и для улицы введены поля street, street_type, street_kladr.
Алгоритм тестирования
Для каждого адреса нашей выборки нужно создать имитацию его ввода, для отслеживания подсказок, получаемых от тестируемого сервиса. При этом мы полагаем, что пользователь вводит только название города и улицы, название региона ему вводить не нужно, ведь он проживает в одном из 406 достаточно крупных городов России. В нашей имитации сначала, буква за буквой, набирается название города. Каждая новая буква, добавленная в конец вводимого названия, порождает новый запрос к сервису. Среди полученных подсказок ищется ожидаемый адрес, который мы заранее знаем, ведь именно для этого он и присутствует в тестовой выборке.
Если среди первых пяти подсказок полученного списка находится вводимый город, то дальнейшая имитация набора названия города прекращается. Полагается, что пользователь увидел название и выбрал его. Поэтому дальше пользователь переходит к набору названия улицы. Для этого имитирующий скрипт последовательно, буква за буквой, наращивает название улицы и добавляет её к выбранному на предыдущем шаге городу. После каждой добавленной буквы получившийся фрагмент адреса вновь отсылается сервису.
Ну и дальше по аналогии с городом мы ищем среди первых пяти подсказок вводимую улицу, если она попала в выдачу, то дальнейшая имитация ввода улицы прекращается, иначе – переходим к следующей букве и снова отсылаем запрос.
Такой нехитрый тест позволяет измерить время отклика сервиса
и число букв , которые требуется ввести пользователю для того, чтобы получить в подсказках желаемый адрес. Отдельно следует оговорить ситуации, когда пользователь не получил подходящую подсказку вплоть до конца ввода названия города. В этом случае наш моделируемый пользователь понимает, что сервис не в состоянии помочь ему при вводе конкретно этого адреса. Поэтому дальнейший ввод улицы выполняется без использования подсказок. В этом случае пользователь уже ничего не ждёт от сервиса, так что время отклика перестаёт влиять на его поведение и в этом случае можно принять , однако пользователю придётся набрать название улицы полностью, так что будет совпадать с .Исходные тексты
Все скрипты написаны на Perl. Исходники имеют следующую структуру.
- Скрипт run_test.pl – основной и единственный скрипт, который нужно запускать для прогона теста для любого сервиса.
- Пакет TestWorker.pm содержит реализацию алгоритма тестирования, описанную выше.
- Пакет TestStorage.pm нужен для работы с хранилищем результатов тестирования. Все результаты сохраняются в базе данных sqlite, чтобы после прохождения всех тестов можно было выполнить все необходимые вычисления.
- Пакеты AhunterAPI.pm, GoogleAPI.pm, DadataAPI.pm, KladrAPI.pm, Fias24API.pm, YandexAPI.pm и IqdqAPI.pm содержат реализацию работы с API соответствующего сервиса. Какому сервису соответствует каждый пакет можно догадаться по его названию.
- suggest_test_full.json – файл, содержащий наш 3591 тестовый адрес.
Строка запуска тестирования для некоторого сервиса имеет следующий вид:
run_test.pl <полный путь к файлу с тестами> <Имя API-пакета сервиса> <Ключ API>Например, для тестирования сервиса от Google нужно запустить тест следующим образом.
run_test.pl /home/user/suggest_test_full.json GoogleAPI ABCDEFGЗдесь /home/user/suggest_test_full.json – полный путь к файлу с тестами, GoogleAPI – имя пакета, соответствующего тестируемому сервису, ABCDEFG – ключ для работы с сервисом через API, который нужно получить в личном кабинете своего аккаунта. Сервисы Ахантер и Яндекс не требуют регистрации, поэтому для них можно передавать в качестве ключа API произвольную строку.
Особенности прохождения тестов
При прохождении тестов у каждого сервиса были выявлены
У Ахантера в подсказках для адресов из Чувашской Республики возвращается название этого региона следующим образом «Респ Чувашская (Чувашия)». Поэтому в рамках AhunterAPI.pm пришлось особым образом реализовать сравнение подсказок для этой республики с её эталонным названием.
У Google также есть особенности в названиях нескольких регионов, например, «Тыва» возвращается как «Тува», а «Удмуртская республика» возвращается как «Удмуртия». Для них также пришлось писать отдельное сравнение. Кроме этого не удалось получить подсказки для всех адресов из Республики Крым. Все адреса из этого региона потенциальному пользователю придётся вводить целиком без подсказок, это автоматически увеличивает
и снижает суммарную полезность сервиса. Аналогично обстоит дело с городами Новой Москвы, для которых Google возвращает подсказки из Московской области. Все эти тесты не были пройдены, т.к. формально сервис подсказывает не тот адрес, который имеет место на самом деле.У сервиса Дадата наблюдается проблема с подсказками для городов, названия которых совпадают с названиями улиц или районов в других городах. Например, для города «Мирный» предлагает адреса типа «Самарская обл, г Тольятти, проезд Мирный 2-й», а для города «Березовский» предлагает адрес «г Краснодар, Березовский сельский р-н». При этом название города так и не удалось получить в подсказках, даже если ввести его полностью. Из-за этого
растёт, а полезность падает, поскольку при отсутствии подсказок, такие адреса вводятся полностью.У Fias24 были обнаружены аналогичные проблемы с городами, названия которых совпадают с районами, либо когда название города является префиксом для названия региона, которому этот город принадлежит. Например, для города «Краснодар» сервис возвращает варианты из Краснодарского края, но самого города в подсказках нет. Это можно увидеть и на демо-странице сервиса.
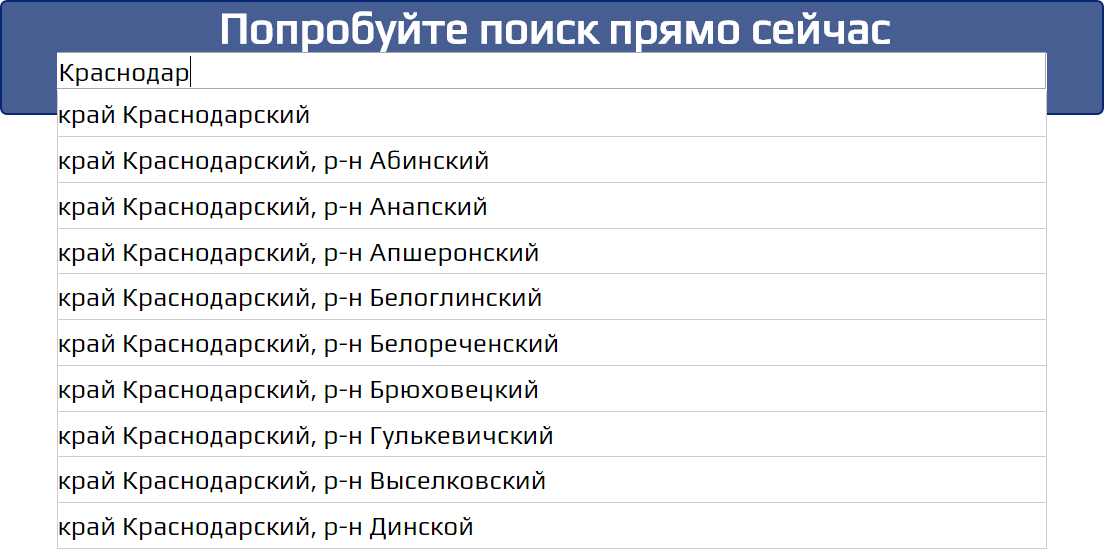
Из-за этой проблемы примерно для 370 тестов не было получено подсказок для названия города. Как следствие при расчёте формулы полезности, исходя из нашего алгоритма, набор улиц для этих тестовых адресов осуществлялся без учёта подсказок. Это сказывается на увеличении
.У сервиса «КЛАДР в облаке» ситуация аналогичная, только тестов не было пройдено порядка 700. Также данный сервис не подсказывает улицы без явного указания их типов. Примеры можно посмотреть на демо-странице сервиса:
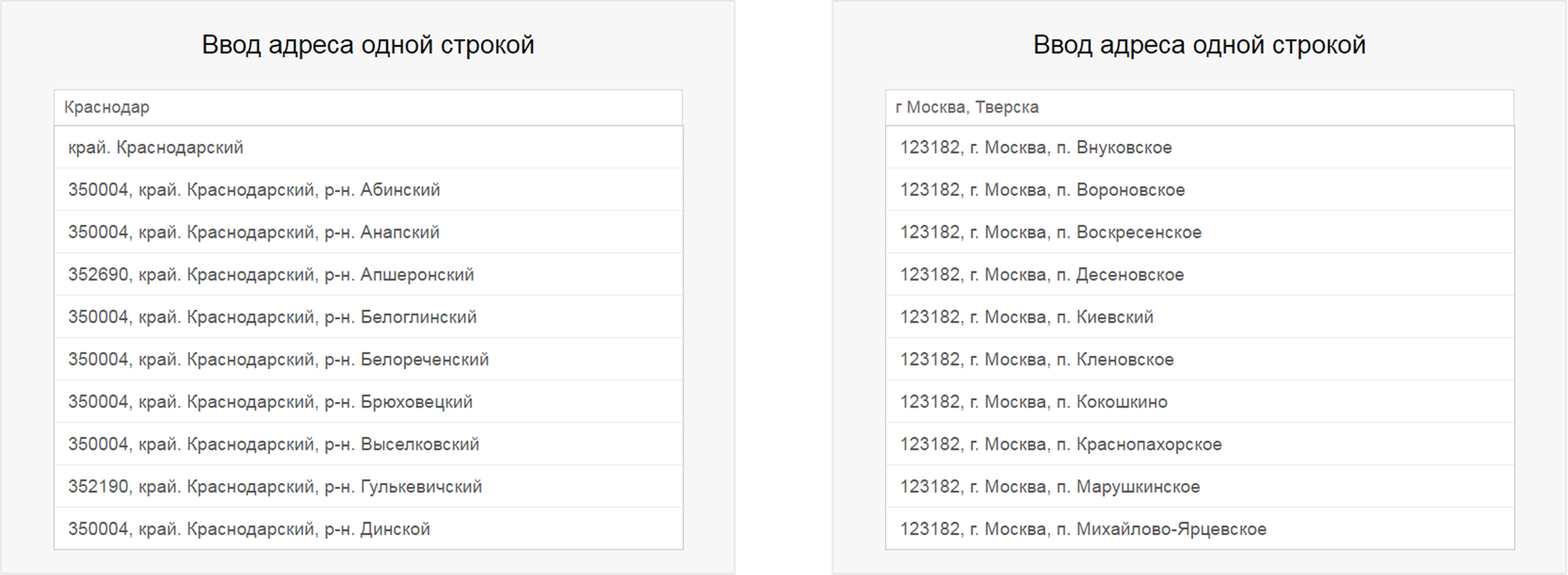
Поэтому специально для данного сервиса было сделано исключение, при формировании запросов по названию улицы перед каждым названием предварительно вставлялся её тип. Как следствие
для данного сервиса всегда будет больше на число букв, составляющих наименование типа улицы.Примерно столько же тестов не было пройдено сервисом Iqdq. В основном это связано с аналогичными проблемами – название города даже после полного ввода либо совсем не попадает в выдачу (например, «Ижевск), либо не попадает в первые 5 подсказок выдачи (например, «Брянск»).

Кроме этого встречаются такие же проблемы, как и у сервиса Дадата, когда вместо города возвращается одноименный район, например для «города Жуковский» получаем «Брянская обл, Жуковский р-н». Дополнительно можно выделить адреса, где вместо ожидаемого города возвращается одноименная деревня, например, вместо «город Пионерский» сервис возвращает «Респ Удмуртская, Игринский р-н, высел Пионерский». Всё это приводит к тому, что такие проблемные города приходится вводить полностью без подсказок. По условиям наших тестов улицы в таких адресах тоже приходится вводить без подсказок. В результате у всех таких адресов
возрастает до , а это снижает полезность.У Яндекса также как и у других рассмотренных выше сервисов есть проблемы с некоторыми городами. Он вместо них возвращает названия улиц других городов. Например, для города «Октябрьский» возвращает «Россия, Московская область, Люберцы, Октябрьский проспект». Также была обнаружена проблема с подсказками для улиц, в названиях которых есть инициалы. Например, по запросу «Россия, Республика Адыгея, Адыгейск, Чича» можно получить ответ «Россия, Республика Адыгея, Адыгейск, улица П.С. Чича». Если этот ответ повторно отправить в качестве запроса, то Яндекс возвращает пустой результат. Из-за этой особенности пришлось из тестовой выборки исключить все названия улиц с инициалами и повторять все тесты для всех сервисов заново.
Отдельно следует сделать оговорку для сервисов, которые в качестве источников подсказок используют карты. Эти источники покрывают адресное пространство России хуже остальных участников обзора. Как следствие одной из главных причин, из-за которой эти сервисы не возвращали подсказки, является отсутствие тестового адреса на карте. Это в свою очередь автоматически увеличивает
, так как без подсказки пользователю приходится вводить все буквы адреса.Результаты экспериментов
После выполнения теста скрипт run_test.pl выводит на экран различные статистические показатели, характеризующие результат прохождения теста. Также на экран выводятся три итоговых значения полезности сервиса для трёх соответствующих классов пользователей – «тихохода», «середнячка» и «торопыжки».
Первые четыре показателя, которые выводятся на экран, имеют следующий смысл.
- city_avg() – среднее время ожидания подсказок от сервиса при вводе названия города, измеряется в миллисекундах.
- street_avg() – аналогично предыдущему, но для названий улиц.
- city_avg() – среднее число букв, по которым сервис угадывает название города.
- street_avg() – среднее число букв, по которым сервис угадывает название улицы.
Эти показатели не участвуют непосредственно в формуле полезности, они интересны сами по себе. Ниже привожу таблицу с их значениями для всех протестированных сервисов.
| Ахантер | Дадата | КЛАДР в облаке |
Fias24 | Яндекс | Iqdq | ||
|---|---|---|---|---|---|---|---|
| city_avg() (мс) |
15.98 | 85.93 | 78.55 | 104.05 | 73.88 | 22.46 | 176.73 |
| street_avg() (мс) |
18.69 | 86.76 | 106.79 | 154.68 | 189.70 | 30.67 | 277.28 |
| city_avg() (буквы) |
2.48 | 2.71 | 3.89 | 4.27 | 3.68 | 4.42 | 4.75 |
| street_avg() (буквы) |
1.63 | 2.18 | 1.61 | 3.28 | 1.90 | 2.20 | 1.84 |
Первые два показателя отражают усреднённую отзывчивость сервиса. По ним можно судить, будет ли полезен данный сервис для пользователей с высокой скоростью набора текста на клавиатуре. Чем меньше время отклика сервиса, тем большему числу пользователей он будет полезен. Ещё здесь заметно, что все сервисы тратят меньше времени на формирование подсказок для города, тогда как подсказки для улицы отнимают у них больше сил и времени.
Но особый интерес вызывают показатели city_avg(
) и street_avg(). Оказывается, для угадывания названия города достаточно менее пяти букв, поскольку для всех сервисов имеет место city_avg() < 5. В лучшем случае для правильного угадывания названия города достаточно примерно две с половиной буквы! По крайней мере, именно столько демонстрирует Ахантер и Google, у первого city_avg()=2.48, а у второго city_avg()=2.71. Для правильного угадывания названия улицы требуется ещё меньше букв. Четыре рассмотренных сервиса (Ахантер, Дадата, Fias24 и Iqdq) предсказывают улицу меньше, чем за две буквы. Теперь рассмотрим характеристики, которые нужно непосредственно подставлять в формулу полезности, поэтому приведу эту формулу еще раз, чтобы она была перед глазами.
должно содержать суммарное число букв, которые пользователю пришлось набрать на клавиатуре в ходе ввода всех адресов нашей выборки. Данному значению соответствует показатель  , который скрипт выводит на экран. Данный показатель рассчитывается следующим образом.
, который скрипт выводит на экран. Данный показатель рассчитывается следующим образом.Для всех тестов определяется общая сумма букв в именах городов и улиц, которые были набраны в ходе теста. Если для какого-то города или улицы не была получена подсказка, то в данную сумму включается длина всего названия этого города или улицы, т.к. полагается, что без подсказки пользователь вводит название целиком. В противном случае в общую сумму включается лишь то число букв, которые были фактически набраны до получения подсказки.
Дополнительно в эту сумму включаются длины регионов от тех тестов, для которых не удалось получить подсказку для города. Я исхожу из того, что если пользователь не получил подсказку для города, то ему приходится вводить целиком не только название города, но и название региона, в котором этот город находится. Для городов, по которым была получена правильная подсказка, регион вводить не надо, поэтому регионы успешных тестов не вносят вклад в данную сумму.
Далее в числителе первой дроби формулы полезности присутствует слагаемое
 . Коэффициент отражает затраты времени, связанные с самим выбором подсказки из предложенного списка. Ранее я говорила, что этот коэффициент был выбран эмпирически. Эта константа зашита в коде скрипта и имеет значение 3. То есть на выбор подсказки пользователь тратит времени столько же, сколько у него уходит на ввод 3-ёх произвольных букв адреса. Данный коэффициент умножается на — число раз, когда в ходе набора были задействованы подсказки. Для этого тестовый скрипт выдает характеристику
. Коэффициент отражает затраты времени, связанные с самим выбором подсказки из предложенного списка. Ранее я говорила, что этот коэффициент был выбран эмпирически. Эта константа зашита в коде скрипта и имеет значение 3. То есть на выбор подсказки пользователь тратит времени столько же, сколько у него уходит на ввод 3-ёх произвольных букв адреса. Данный коэффициент умножается на — число раз, когда в ходе набора были задействованы подсказки. Для этого тестовый скрипт выдает характеристику  , так что имеем
, так что имеем  . В идеале должен быть равен удвоенному числу адресов нашей выборки, т.к. в идеале подсказки должны быть задействованы дважды для каждого адреса – один раз при вводе города, а второй раз – при вводе улицы. Но на практике сервисы показали меньшее значение .
. В идеале должен быть равен удвоенному числу адресов нашей выборки, т.к. в идеале подсказки должны быть задействованы дважды для каждого адреса – один раз при вводе города, а второй раз – при вводе улицы. Но на практике сервисы показали меньшее значение .Далее в формуле полезности встречаем
, это суммарное время, которое пользователь ждал подсказок от сервиса. Для его получения скрипт выдает характеристику  , так что
, так что  . В ходе выполнения тестов скрипт засекает время, которое уходит на ожидание ответа от сервиса на каждый отправленный запрос. Вся эта информация по всем запросам сохраняется в локальной sqlite базе данных, а в конце теста суммируется.
. В ходе выполнения тестов скрипт засекает время, которое уходит на ожидание ответа от сервиса на каждый отправленный запрос. Вся эта информация по всем запросам сохраняется в локальной sqlite базе данных, а в конце теста суммируется.Последний участник формулы полезности —
, это просто суммарное количество букв всех адресов выборки. Это значение не зависит от результата теста, оно всего лишь характеризует саму выборку. Скрипт выводит это число под именем  . Для нашей выборки оно имеет значение 137704. Ровно столько букв содержится в именах регионов, городов и улиц всех тестов выборки, а также в именах их типов.
. Для нашей выборки оно имеет значение 137704. Ровно столько букв содержится в именах регионов, городов и улиц всех тестов выборки, а также в именах их типов.Итоговые значения описанных выше характеристик показаны в следующей таблице. Для наглядности время
переведено в минуты.| Ахантер | Дадата | КЛАДР в облаке |
Fias24 | Яндекс | Iqdq | ||
|---|---|---|---|---|---|---|---|
|
14808 | 33191 | 22397 | 50863 | 32820 | 36549 | 50092 |
|
7180 | 5848 | 7043 | 5588 | 6387 | 6057 | 5415 |
|
4.20 (мин) | 39.29 (мин) | 29.19 (мин) | 58.81 (мин) | 39.29 (мин) | 14.67 (мин) | 82.70 (мин) |
для каждого из трёх классов пользователей: «тихохода», «середнячка» и «торопыжки». В своих расчётах я использовала следующие значения. Для «тихохода»  миллисекунд, для «середнячка» — 500 миллисекунд, а для «торопыжки» — 300 миллисекунд. Эти значения я подобрала опытным путем, попросив нескольких моих знакомых набрать на клавиатуре их почтовые адреса, измеряя при этом, сколько времени у них уходит на поиск и ввод одной буквы. Итоговые результаты представлены в следующей таблице, для удобства значения полезности в таблице переведены в проценты.
миллисекунд, для «середнячка» — 500 миллисекунд, а для «торопыжки» — 300 миллисекунд. Эти значения я подобрала опытным путем, попросив нескольких моих знакомых набрать на клавиатуре их почтовые адреса, измеряя при этом, сколько времени у них уходит на поиск и ввод одной буквы. Итоговые результаты представлены в следующей таблице, для удобства значения полезности в таблице переведены в проценты.| Ахантер | Дадата | КЛАДР в облаке |
Fias24 | Яндекс | Iqdq | ||
|---|---|---|---|---|---|---|---|
| Тихоход | 73 % | 61 % | 67 % | 48 % | 60 % | 59 % | 48 % |
| Середнячок | 73 % | 60 % | 66 % | 46 % | 59 % | 59 % | 46 % |
| Торопыжка | 72 % | 57 % | 64 % | 42 % | 56 % | 58 % | 40 % |
Проблемы «КЛАДР в облаке» были описаны выше, основной вклад в низкую полезность внесло большое значение
, поскольку при наборе улицы у этого сервиса нужно вводить её тип – «ул», «пер» и т.д. Так что суммарно пользователь тратит на ввод больше времени. Тем не менее, даже с учётом этого, экономия времени в 42% является неплохим показателем.У Iqdq на низкие показатели повлияло большое время отклика, а также проблемы с непопаданием крупных городов в выдачу с подсказками. Из-за этого все адреса из этих городов вводились полностью, это привело к увеличению числа букв
, которые пользователю приходилось набирать.Удивило, что на полезность подсказок от Google не сильно повлияли проблемы с адресами из Новой Москвы и Крыма, по которым данный сервис не выдал правильных подсказок. Здесь сказалась общая хорошая способность к угадыванию у данного сервиса. Если посмотреть на первую таблицу (см. выше), то будет видно, что Google угадывает город по меньшему числу букв, чем некоторые из рассмотренных сервисов, которые в силу своей специализации должны делать это по идее лучше.
Получившиеся значения полезности у Яндекса в первую очередь обусловлены тем, что данный сервис угадывает город по большему числу букв, чем все остальные сервисы. Раньше я писала, что вместо подсказок для города его тянет предлагать улицы из других городов.
Если анализировать полезность сервисов в разрезе классов пользователей, то тут видно, что все сервисы имеют бОльшую полезность в отношении пользователей, слабо владеющих клавиатурой. Действительно, «тихоходы» будут рады любым подсказкам, лишь бы не вводить данные вручную. Однако для пользователей, умело пользующихся клавиатурой, полезность подсказок чуть ниже. Чтобы принести максимум пользы для них, сервис должен иметь малое время отклика.
В данном разрезе все сервисы можно разделить на три группы – быстрые, средние и медленные. У быстрых сервисов (Ахантер и Яндекс) полезность не сильно зависит от скорости работы пользователя. Действительно, даже если пользователь шустро печатает на клавиатуре, быстрые сервисы успевают вернуть правильные подсказки, в результате тот получает возможность их использовать. Средние сервисы (Google, Дадата, Fias24) чуть более чувствительны к скорости работы пользователя, «торопыжкам» эти сервисы принесут меньше пользы, чем «тихоходам» и «середнякам». Ну а у медленных сервисов этот эффект заметен ещё сильнее.
Заключение
Возвращаясь к вопросу, поставленному в заголовке статьи, можно однозначно ответить «Да», современные веб-сервисы подсказок подсказывают хорошо. Мне удалось количественно измерить пользу, которую они приносят для рядовых обывателей Рунета. Полученные цифры отражают экономию времени, которую можно достичь при подключении такого рода сервисов к веб-формам, где требуется набирать почтовые адреса. В этом случае можно сэкономить до 70% пользовательского времени.
Вместе с тем, памятуя о моей истории с пиццей, хочется напомнить, что предложенная в начале статьи формула подразумевает и отрицательные значения полезности. Мне известен, по крайней мере, один сервис подсказок, для которого полезность будет близка к нулю, а может быть даже и отрицательной. Поэтому хотелось бы обратиться с просьбой к авторам, которые уже сделали или делают похожие решения: воспользуйтесь моим тестом и проверьте, а настолько ли полезна ваша разработка, как вы думаете.
Исходники тестов и тестовую выборку можно взять на гитхабе здесь. Также хочу обратиться к тем, кто планирует повторить мои эксперименты. Если вам удастся найти неточности или ошибки в алгоритмах, сообщите, пожалуйста, мне, я с готовностью буду вносить исправления и корректировать полученные результаты.
Ну а читателей благодарю за внимание. Буду рада ответить на вопросы в комментариях.
